
利用维基百科实体增强基于图的多文档摘要
2016-05-04 03:10陈维政闫宏飞李晓明
中文信息学报 2016年2期
陈维政,严 睿,闫宏飞,李晓明
(北京大学 信息科学技术学院,北京 100871)
利用维基百科实体增强基于图的多文档摘要
陈维政,严 睿,闫宏飞,李晓明
(北京大学 信息科学技术学院,北京 100871)
针对基于图的多文档摘要,该文提出了一种在图排序中结合维基百科实体信息增强摘要质量的方法。首先抽取文档集合中高频实体的维基词条内容作为该文档集合的背景知识,然后采用PageRank算法对文档集合中的句子进行排序,之后采用改进的DivRank算法对文档集合和背景知识中的句子一起排序,最后根据两次排序结果的线性组合确定文档句子的最终排序以进行摘要句的选取。在DUC2005数据集上的评测结果表明该方法可以有效利用维基百科知识增强摘要的质量。
多文档摘要;维基实体;基于图
1 引言
在线信息的快速增长使得自动文档摘要技术不断发展,在过去的六十多年里,从不同的领域和模式出发,自动文档摘要技术得到了广泛研究和应用。比如,搜索引擎会对用户查询返回的文档生成一个短摘要供用户筛选查询结果。雅虎2013年收购了新闻摘要应用Summly,该应用可以将整篇英文新闻文章的内容提炼成一个不到400词的新闻摘要。
自动文本摘要可分为普适摘要和面向查询的摘要。面向查询的多文档摘要需要用户在给出一个查询的条件下,针对用户的信息需求生成与用户查询相关且内容冗余度尽量小的摘要。普适摘要则与查询无关。由于自然语言处理技术的限制,当前的摘要生成主要采用抽取式(extractive)的方法,即从原文档中选取一定数量的句子组成摘要,本文的方法是一种抽取式的面向查询的摘要算法。
抽取式摘要主要需要解决两个问题,一是如何对句子进行排序,二是由于摘要长度的限制如何对排序后的句子进行筛选。基于图排序的算法是解决面向查询的多文档摘要问题的一类经典算法。在文档中,句子与句子、句子与查询之间的相似度启发我们可以用图来表示文档。基于图排序的文本摘要方法的一般思想是把文章分解为若干单元(句子或段落等),每个单元对应一个图的顶点,单元间的关系作为边,最后通过图排序的算法得出各顶点的得分,并在此基础上生成文本摘要。在多数工作中,节点一般是句子,节点之间的边的权值表示句子之间的相似度,绝大多数文献中表明余弦相似度是使用最多的测量标准。
在多文档摘要的应用中,文档通常都是和一个特定的主题或者事件相关的,这些主题或事件从属于一个普遍的知识结构体系中。以新闻摘要为例,新闻一般都与特定的人物、机构或者事件相关。因此基于背景知识或者本体知识库的摘要方法得到了广泛研究[1-2]。维基百科是当前世界上最大的在线百科知识库,其内容以词条的的形式进行组织,每一个词条代表一个维基实体。近年来,各种自然语言研究领域陆续开始使用维基百科。
本文的出发点在于从文档中抽取出高频维基实体作为文档集合的相关实体,利用这些实体的维基词条内容作为摘要生成的背景知识,通过两次图排序的方法将背景知识加入到原文档句子的排序过程中。在DUC2005评测数据上的实验结果表明了本文方法可以有效利用维基知识,并且生成的摘要可以达到较高的质量。
2 相关工作
近年来,抽取式多文档摘要算法得到广泛的研究。这些方法的主要思想都在于对原文档中的句子进行打分,并将得分最高的句子组成最后的摘要。四类主流的多文档摘要算法分别是基于特征的方法、基于聚类的方法、基于图排序的方法、基于知识库的方法。
首先简要介绍基于特征和聚类的方法,文档摘要中常用的文档特征包括词频、特定段落(如首末段)、段落的特定句子(如首末句)等。Luhn在1958 年发表的论文中[3]指出,频繁出现的单词与文章主题有比较大的关联,因此可以根据各单词出现的频率给文中的句子打分,以得分最高的几个句子组成文章的摘要。聚类的思想在于把相似的对象纳入到同一类中。具体而言,对于多文档摘要问题,这里的聚类对象是句子,类别则代表句子所从属的类。Radev[4]在2004年首先提出了使用聚类质心的多文档摘要系统MEAD。簇的质心是指最能代表这个簇的tf-idf向量,然后可以用这个质心确定最能代表这个簇的重要句子,也就是和簇最相关的句子。
在多文档摘要领域经常被使用的图排序模型包括,Kleinberg[5]在1999年提出的HITS算法,Brin和Page提出的著名的PageRank算法[6],这两种算法的传统使用领域是在互联网链接分析和社会网络分析。LexRank[7]和Mihalcea提出的TextRank[8]是将前面的两种算法应用到摘要领域的有效尝试改进。耿焕同[9]等人则利用句子间的共现词,提出了一种基于词共现图的文档摘要算法,通过词共现图形成的主题信息以及不同主题间的连接特征信息自动地提取文档摘要。梅俏竹[10]等在2010年提出了PageRank的一个变种DivRank,在传统的Page-Rank 的计算中,节点之间的转移概率是固定的,可以看作时齐的马尔科夫链。而这篇文章提出了针对现实中存在的“richer get richer”现象,需要在排序中体现出多样性,这样节点之间的转移概率应该是变化的,而且应该和节点被访问的次数成正比。基于图排序的摘要算法的核心在于改进排序算法。Wan和Yang[11]给文档间句子链接和文档内句子链接分配不同的权重,特别地对文档间的链接分配更高的先验概率。
基于背景知识或者本体知识库的摘要方法的出发点在于文档通常都是对某一特定主题或事件的描述,Khelif[12]的研究表明,本体库包含了精确概念和丰富的领域相关信息,有助于获取隐含的语义信息,特别是对于具体领域新的相关理解。近年来随着维基百科成为最大的在线百科全书,多文档摘要领域与维基百科相关的工作也越来越多。Ramanatha[13]使用Lucence引擎查找句子中的维基概念,通过统计概念的句子频次,将包含高频概念的句子选为文摘句。Nastase[14]提取查询中的维基实体然后查找对应维基词条中的链接词对查询进行扩展。
3 算法流程
3.1 抽取维基百科知识

DUC(DocumentUnderstandingConference)会议,自2001年起都会举办针对单文档自动摘要和多文档自动摘要的评测任务。图1给出DUC2005中面向查询的多文档摘要任务中的主题示例。一个主题有一个ID标号即num域,title给出了主题的标题,narr域给出了主题对应的查询内容。

图1 DUC 2005的主题示例
表1给出了对图1中的主题d301i抽取出的符合条件的相关维基实体,涵盖了一些国家名以及和毒品犯罪有关的词语,和d301i的narr域中的查询问题是高度对应的,也印证了高频词与文档主题有较大的关联性。
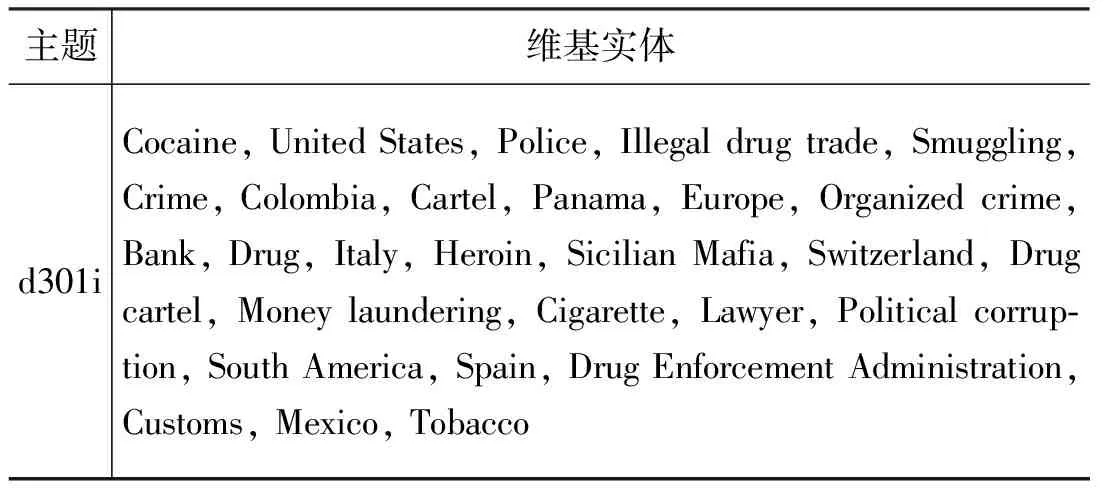
表1 DUC 2005主题的维基实体示例
3.2 原文档句子排序
3.2.1 基于图的句子排序算法
基于图排序的摘要算法的基本思想是一个句子的得分与该句子和查询的相似度以及该句子和文档集中其它句子的相似度有关。设文档集C={si|i=1,2,...,N},si表示C中的第i个句子,C中共有N个句子。对于一个文档集C中的句子s,s在给定查询q下的得分可以表示为:
(1)
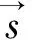
(2)
因为查询q也是一个句子,句子s和查询q的相似度sim(s,q)也是通过式(2)给出。我们令sim(s,s)=0以避免一个句子到其自身的转移。为了给出式(1)的矩阵形式,定义矩阵A=(Aij)N×N,矩阵B=(Bij)N×N,其中:
(3)
(4)

(5)
则式(1)的矩阵形式为:
(6)

3.2.2 查询扩展
由于在面向查询的多文档摘要中原始查询通常较短,对查询进行扩展可以有效补充原始查询的语义信息。文献[14]使用WordNet和维基百科词条的首段链接对查询进行扩展。文献[16]提出了一种基于PageRank分数的从原文档集中选取扩展词的方法,在选取扩展词时同时考虑句子本身的重要性以及句子和词之间的关系。本文采用该方法对查询进行扩展,该方法可以归纳为如下三步。
1. 计算矩阵W=(Wij)N×m,用Wij表示词tj在句子si中的权重,其中:
(7)
式(7)中进行了行归一化,即使得W中每行的和都为1。需要指出的是,这里只考虑名词、动词、形容词和副词,别的词都不参与查询扩展。

利用以上算法得到新查询q′,我们采用3.2.1中的算法重新计算所有句子的得分,然后按照得分对文档集中的句子降序排列,从而对每个句子si得到一个排序ri1。
3.3 加入维基百科知识后排序
3.1中抽取的维基百科词条的内容给出了一个话题的背景知识,我们希望选取出的摘要句可以与对应的背景知识相符合,为此下面对文档集中句子与背景知识的相关程度进行排序。对一个文档集C={si|i=1,2,...,N},其对应的维基百科知识即使用3.1中的方法从C中抽取的维基词条中的句子所组成的集合,记为K={ki|i=1,2,...,H}。为了表示方便,将C与K的交集记为Q=C∪K={si|i=1,2,...,N,N+1,....,N+H},其中si(1≤i≤n)表示的是原文档集合C中的句子,si(N+1≤i≤N+H)表示的是维基百科知识K中的句子。仍然采用基于图排序的算法对Q中的句子一起排序,但此处的方法与3.2.1中有所不同,一是不再考虑句子与查询q的相似度,因为只是计算原文档句子与背景知识的相关程度;二是原文档句子之间的相似度都置为0,即对1≤i,j≤N,令sim(si,sj)=0,C与K中句子之间的相似度、K中句子的相似度依然采用3.2.1中方法进行计算。则Q中一个句子s的得分为:
(8)
式(8)中的μ为一个在[0,1]取值的参数,在本文中取值为PageRank算法中的常用值0.85。为了把式(8)写成矩阵形式,重新定义矩阵A=(Aij)(N+H)×(N+H),其中
(9)

(10)
多文档摘要任务的一个重要指标是多样性,摘要中的句子表达的信息应该有所差异,即摘要句之间的信息冗余应该尽量小。式(10)作为一个标准的PageRank算法将导致相似的句子拥有十分接近的得分,从而得分靠前句子之间存在很强的相似性。MMR即最大边缘相关算法是解决该问题的的经典贪心算法,该算法首先将排序中最靠前的句子作为第一个摘要句,然后迭代地选择与查询最相关且与摘要中现有句子冗余度最小的句子作为摘要句。DivRank算法可以在排序中融入句子的多样性,使得相似的句子在排序的过程中存在“吸收”作用,而使得其得分的差距被拉大。该算法的思想在于使式(10)中的矩阵A在每次迭代过程中都动态变化而不是保持不变。Yan[17]等在为新闻文档生成时间线摘要时结合了DivRank算法取得了良好的效果。式(11)给出了A的更新算法。
(11)
3.4 排序合并与摘要生成
现在对C中的每个句子si我们得到排序ri1和ri2,ri1衡量了si在C中的重要性以及和查询q的相似度,ri2衡量了si与维基百科知识的相关程度。本文用两次排序次序的线性组合作为句子的最终排序。记si的最终排序为ri,则ri如式(12)所示。
(12)
式(12)中的λ是在[0,+∞)取值的参数,λ越大则维基百科知识对排序结果的影响越大。尽管第一轮排序中使用的PageRank排序算法使得内容相似的句子之间的排序十分接近,但第二轮排序时使用的DivRank算法使得内容相似的句子获得了差异明显的排序结果。通过选取合适的λ组合两轮排序结果,可以保证最终排序结果的多样性。根据最终排序次序,我们对C中所有句子进行升序排列,然后依次选入最终排序最小即最靠前的句子加入到摘要中,直到摘要的长度达到最大长度限制。
4 实验与评测
4.1 数据集
本文采用DUC2005提供的数据集进行实验。DUC2005数据集共包含50个话题以及50个相关的查询问题,数据来源是TREC数据集,查询问题的形式如图1所示。每个话题包含25—32篇新闻文档,对应数篇由专家人工编写的摘要作为评测答案。任务目标是针对查询问题对每个话题分别生成一个250个词的摘要。在本文的实验中,所有文档都首先被分割成独立的句子,然后进行去除停用词和词干化等预处理。
4.2 评价标准
本文使用ROUGE-1.5.5工具包对生成的摘要进行自动评价,ROUGE[18]标准的全称是Recall-
OrientedUnderstudyforGistingEvaluation即面向召回率的要点评估,现在已经成为文档自动摘要领域的标准评测方法。在DUC多文档摘要任务中,通常被采用的评价指标是ROUGE-1、ROUGE-2以及ROUGE-SU4的召回率,因为这三项指标与人工判断最为相关。ROUGE-N指标比较了两个摘要中N-grams(N元词)的重复情况,以此评价两个摘要的相似性。用N表示N-gram的长度,RS表示人工编辑的参考摘要,S是RS中的一个句子,则针对计算机生成的摘要CS,ROUGE-N召回率分数的计算公式为:
ROUGE-NRecall
(13)
式(13)中分母上的Count(N-gram)表示计算RS中出现的N-gram的总个数,分子上Countmatch(N-gram)表示计算在CS里出现的RS中的N-gram的总个数。在4.3中我们将报告本文方法在DUC2005数据集上得到ROUGE-1、ROUGE-2以及ROUGE-SU4三项指标的召回率。
4.3 实验结果
图2给出了参数λ的取值对最终结果ROUGE-1、ROUGE-2和ROUGE-SU4三项召回率指标的影响,我们实验了λ在区间[0.000 1,1 000]中的八个取值,当λ<0.01时随着λ增大ROUGE召回率在增大,当λ>0.01时随着λ增大ROUGE召回率在减小,并且当λ>10之后第二轮排序结果所占比重越来越大,结果趋于稳定。结果表明λ=0.01时结果最好,最终的排序结果中第一轮排序的结果占有更大的权重。

图2 不同λ下ROUGE召回率的变化
取λ=0.01,表2给出了本文方法与DUC2005评测中得分最高的三个摘要系统的得分比较,例如“S15”表示DUC2005评测中系统标号为15的系统,结果表明本文方法的性能优于DUC2005评测中最好的系统。
表2中PageRank系统对应式(12)中λ=0时得到的结果,此时最终排序结果等价于第一轮排序结果,没有在摘要生成中结合维基百科知识。表2中DivRank系统系统以3.3中排序结果作为最终排序得到的结果,式(12)中λ取大于10以上的值时句子的排序与3.3中得到的排序相同。可以看出只考虑句子与维基背景知识的相关性生成的摘要质量明显低于其它系统。通过选取合适的λ调整两次排序结果的比重,在λ=0.01时得到的结果明显优于不考虑维基百科背景知识的PageRank系统以及只考虑维基百科背景知识的DivRank系统,从而说明我们提出的基于图排序的方法可以有效利用维基百科知识提升摘要质量。这主要得益于两点:首先,加入维基百科知识的排序中使用了DivRank算法保证了最终排序结果的多样性,即排序靠前的句子间信息冗余尽量小;其次,和背景知识相关度高的句子在最终排序结果中排序得到了提升,这也说明文档话题的背景知识在摘要的生成过程中是一个值得考虑的重要因素。
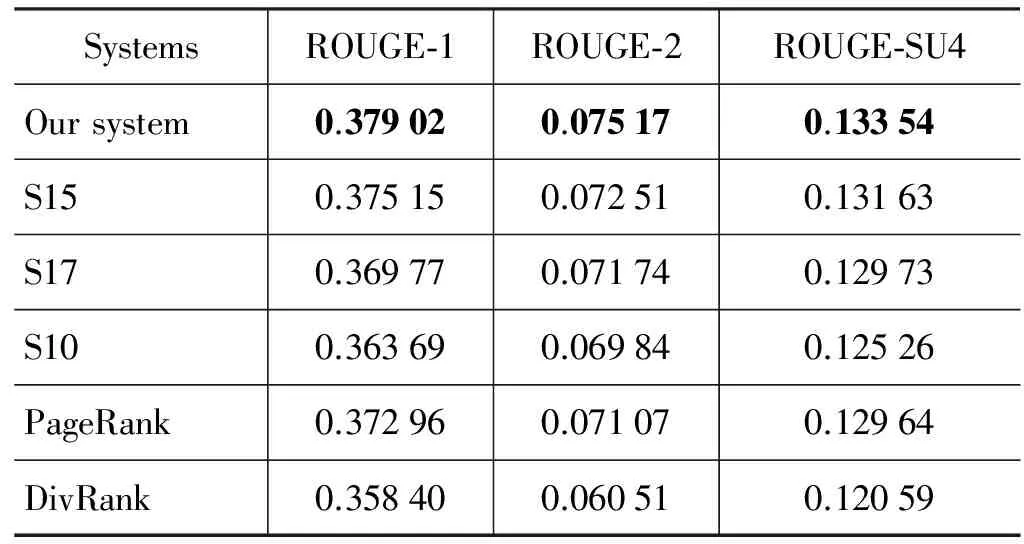
表2 DUC2005上的实验结果比较
5 结束语
本文提出了一种在基于图排序的多文档摘要算法中融入维基百科知识的方法,该方法使用两次图排序算法结果的线性组合作为句子的最终排序。DUC2005数据集上的实验结果表明,本文的方法可以有效利用维基百科知识,并且生成的摘要具有较高的质量。由于在定义话题的相关维基实体时,只是简单利用实体在文档中的出现的次数作为判断标准,缺乏深层次的语义分析,使得维基百科知识会包含和话题相关度并不高的内容。
在今后的工作中,我们将进一步研究如何更精确地选取维基实体,以及如何从相关维基实体的维基文档中筛选有效内容作为话题的背景知识。
[1] Shareha A A A, Rajeswari M, Ramachandram D. Multimodal integration (image and text) using ontology alignment[J]. American Journal of Applied Sciences, 2009, 6(6): 1217-1224
[2] Nasir S A M, Noor N L M. Automating the mapping process of traditionalmalay textile knowledge model with the core ontology[J]. American Journal of Economics and Business Administration, 2011, 3(1): 191-196.
[3] Luhn H P. The automatic creation of literature abstracts[J]. IBM Journal of research and development, 1958, 2(2): 159-165.

[5] Kleinberg J M. Authoritative sources in a hyperlinkedenvironment[J]. Journal of the ACM (JACM), 1999, 46(5): 604-632.
[6] Brin S, Page L. The anatomy of a large-scale hypertextual Web search engine[J]. Computer networks and ISDN systems, 1998, 30(1): 107-117.
[7] Erkan G, Radev D R. LexRank: Graph-based lexical centrality as salience in text summarization[J]. J. Artif. Intell. Res. (JAIR), 2004, 22: 457-479.
[8] Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]//Proceedings of EMNLP. 2004, 4(4).
[9] Geng H, Cai Q, Zhao P, etal. Research on Document Automatic Summarization Based on Word Co-occurrence[J].Journal of the china society for scientific and technical information,2005,24(6):652.
[10] Mei Q,Guo J, Radev D. Divrank: the interplay of prestige and diversity in information networks[C]//Proceedings of the 16th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2010: 1009-1018.
[11] Wan X, Yang J. Improved affinity graph based multi-document summarization[C]//Proceedings of the Human Language Technology Conference of the NAACL, Companion Volume: Short Papers. Association for Computational Linguistics, 2006: 181-184.
[12] Khelif K, Dieng-Kuntz R, Barbry P. An ontology-based approach to support text mining and information retrieval in the biological domain[J]. Universal Computer Science, Special Issue on Ontologies and their Applications, 2007, 13(12): 1881-1907.
[13] Ramanathan K, Sankarasubramaniam Y, Mathur N, et al. Document summarization using Wikipedia[C]//Proceedings of the First International Conference on Intelligent Human Computer Interaction. Springer India, 2009: 254-260.
[14] Nastase V. Topic-driven multi-document summarization with encyclopedic knowledge and spreading activation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2008: 763-772.
[15] Milne D, Witten I H. An open-source toolkit for miningWikipedia[J]. Artificial Intelligence, 2013,194:222-239.
[16] Zhao L, Wu L, Huang X. Using query expansion in graph-based approach for query-focused multi-documentsummarization[J]. Information Processing & Management, 2009, 45(1): 35-41.
[17] Yan R, Kong L,Huang C, et al. Timeline generation through evolutionary trans-temporal summarization[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 433-443.
[18] Lin C Y. Rouge: A package for automatic evaluation of summaries. Text Summarization Branches Out[C]//Proceedings of the ACL-04 Workshop. 2004: 74-81.
Wikipedia Entity to Enhanced Graph-based Multi-document Summarization
CHEN Weizheng, YAN Rui, YAN Hongfei, LI Xiaoming
(School of Electronics Engineering and Computer Science, Peking University, Beijing 100871,China )
This paper presents a novel method to enhance graph-based multi-document summarization by incorporating Wikipedia entities. The Wikipedia contents of high-frequency entities are extracted and arranged as the document collections’ background knowledge. Then the PageRank algorithm is used to sort these sentences in the document collections and an improved DivRank algorithm is applied to sort the sentences both in the document collections and the background knowledge. Finally the summary sentences are chosen based on a liner combination of these two ranking results. Results of experiments on the data of document understanding conference (DUC) 2005 show that the method proposed in this paper can effectively make use of the Wikipedia knowledge to improve the summary quality.
multi-document summarization; Wikipedia entity; graph-based
1003-0077(2016)02-0153-07
2013-10-11 定稿日期: 2014-03-20
国家自然科学基金(61272340, 61073082);教育部科技发展中心“网络时代的科技论文快速共享专项”研究资助课题(FSSP 2012 Grant 2012115)
TP391
A
猜你喜欢
英语文摘(2021年8期)2021-11-02
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
意林·少年版(2018年22期)2018-12-05
文理导航·阅读与作文(2015年1期)2015-07-13
读者·原创版(2015年11期)2015-03-01
意林(2014年2期)2014-02-11
互联网天地(2012年12期)2012-11-18
计算机世界(2009年24期)2009-07-30
