
细粒度意见挖掘中维吾尔语文本情感分析研究
2016-05-04 00:59罗亚伟田生伟吐尔根依布拉音艾斯卡尔艾木都拉
中文信息学报 2016年1期
罗亚伟, 田生伟, 禹 龙, 吐尔根·依布拉音, 艾斯卡尔·艾木都拉
(1. 新疆大学 信息科学与工程学院, 新疆 乌鲁木齐 830046; 2. 新疆大学 软件学院, 新疆 乌鲁木齐 830008; 3. 新疆大学 网络中心, 新疆 乌鲁木齐 830046)
细粒度意见挖掘中维吾尔语文本情感分析研究
罗亚伟1, 田生伟2, 禹 龙3, 吐尔根·依布拉音1, 艾斯卡尔·艾木都拉2
(1. 新疆大学 信息科学与工程学院, 新疆 乌鲁木齐 830046; 2. 新疆大学 软件学院, 新疆 乌鲁木齐 830008; 3. 新疆大学 网络中心, 新疆 乌鲁木齐 830046)
传统的情感分析研究通过分析, 确定词语、句子或篇章的情感, 但忽略了情感表达的主题。针对这一不足, 该文提出了一种基于双层CRFs模型的细粒度意见挖掘中维吾尔语意见型文本陈述级情感分析方法。第一层模型识别意见型文本中的主题词和意见词, 确定意见陈述的范围, 并将识别结果传递给第二层模型, 将其作为重要特征之一, 用于陈述级情感分析。细粒度意见挖掘中情感分析的目标是构建<意见陈述, 主题词, 意见词, 情感>四元组。该方法用于维吾尔语陈述级情感分析的准确率为77.41%, 召回率为78.51%, 证明了该方法在细粒度意见挖掘中情感分析任务上的有效性。
细粒度; 陈述级; 情感分析; CRFs; 维吾尔语
1 引言
随着Web2.0的迅速发展, 互联网用户数量急剧增加。大量的用户不再只是被动接受互联网的信息, 而是更加主动地对产品、服务和人物等进行意见型评论。这些意见型评论具有极大的研究价值和应用价值: 一方面, 潜在用户可以通过浏览这些意见型评论来了解大众舆论对于某一事件或产品的看法; 另一方面, 这些来自网民真实情感的反馈又能使决策者们迅速而广泛地了解到大众的意见或支持率, 以便及时调整相应政策。但是面对网络上海量的评论信息, 单纯依靠人工方式对其进行收集和处理是低效的, 因此, 自动情感分析技术是现在研究的重点。
为了便于读者把握文章脉络, 现说明文章结构如下:第二节介绍了国内外情感分析研究的相关工作; 预备知识将在第三节予以详细说明; 本文所采用的基于双层CRFs模型的特征提取和特征选择以及维吾尔语陈述级情感分析的方法在第四节予以详细介绍; 实验结果和分析在第五节全面展开; 最后在第六节将总结本文的工作, 提出下一步研究方向。
2 相关研究
目前, 情感分析的大部分工作集中在句子级和篇章级别上[1]。国外学者对情感分析的研究开展得比较早,情感资源已有了一定积累,且研究成果也很丰硕。Turney[2]应用情感词组对文档进行情感分类,该方法首先对包含形容词或副词的词组进行词性标注,然后采用PMI-IR(Pointwise Mutual Information-Information Retrieval)的方法计算候选情感词组的倾向,最后使用文档中所有情感词组极性的平均值代表整体的情感倾向。B Pang等[3]采用NB、ME和SVM对电影评论进行情感分类,结果显示,用机器学习的方法优于基于人工标记特征的方法。国内的情感分析研究虽然起步较晚,但也取得了一定成果。赵军等[4]运用CRFs对句子级情感进行分类,此方法利用分层的框架借助增加冗余特征获取标记冗余,且考虑了上下文语境的依赖性。林政等[5]提出一种情感关键句的自动抽取算法,将抽取的关键句分别用于监督和半监督的情感分类,特别是其中采用分类器融合的方法进行监督的情感分类和使用Co-training算法进行半监督的情感分类效果较为理想。
上述情感分析的方法大多针对句子或文档的情感进行分类。但是,该类方法忽视了情感倾向性是由意见词及其所修饰的主题词共同决定的这一客观规律。所幸的是部分学者已经注意到了这一点,为了弥补该缺陷,他们提出了基于主题词和意见词对的情感分析方法。有些学者基于LDA模型拓展出其他模型,将句子中的主题词和意见词统一起来,然后利用意见词的极性判定句子或文档的情感倾向[6-8]。一些学者运用句法关系,依据句子中特定方面的情感判断句子的极性[9-10]。还有一些学者研究多种情感分析的方法,最终实验结果都证明了在引入主题相关的信息后,准确率比不依赖主题信息时有明显的提升[11-13]。赵妍研等[14]利用句法路径来描述评价对象及其评价词语之间的修饰关系,但是该方法没有识别句子的情感倾向性。
综上所述,发现针对主题的情感分析研究已经取得了一定的成果,但是针对本文所研究的问题仍然存在着如下不足: (1)现有的情感分析研究工作大多集中在句子级或篇章级,将整个句子或文档作为情感表述的最小单元,分析比较粗糙,对细腻的情感描述不是十分准确,难以进行高准确度的情感分析,而对于陈述级细粒度的情感分析研究还很少。(2)现有的研究语种主要是英语和汉语等大语种,而对于像维吾尔语这样小语种的情感分析研究还不够深入。本文提出了细粒度意见挖掘中意见型文本陈述级情感分析方法,将意见陈述作为情感表述的最小单元,分析意见陈述的主题词和意见词,并确定意见表达的范围及意见陈述的极性,用以构建<意见陈述,主题词,意见词,情感>四元组。
3 预备知识
为了便于读者理解本文对细粒度意见挖掘中维吾尔语文本情感分析研究的方法,先明确以下定义:
定义1 意见挖掘: 针对主观性文本主动获取有用的意见信息和知识[15]。其中意见由主题(Topic)、持有者(Holder)、陈述(Claim)和情感(Sentiment)四个元素组成[16]。
定义2 陈述: 能够完整地表述观点的一个短语、子句或者整个句子。
针对只包含一个陈述的单一陈述句,可以将整个句子作为一个陈述考虑。针对包含两个或两个以上陈述的多陈述句,由于其中包含了多个意见倾向,并且它们可能针对不同的主题,如果将整个句子作为情感表述的最小单元,则判断不出具体的主题所表达的情感,因此对这类句子不能将整个句子作为陈述,我们将依据不同的主题对其意见倾向进行分析。
定义3 意见陈述的选择: 能够对意见元素的边界进行界定,精确找出各个意见元素之间的对应关系,确定意见陈述表达的范围。
经过深入分析和研究,结合维吾尔语具体的语言特点,在参考相关文献后,实验组维吾尔语语言学专家将意见陈述的选择分为四类。我们引入一个标签集Ψ={T, O, E}对文本中的词进行标注,其中T表示主题词,O表示意见词,E表示其他词。这四类意见陈述的选择如表1所示(其中i>=1)。

表1 意见陈述的选择类型及比重
下面我们举例子详细介绍这四类意见陈述的标注以及选择。
Type1 例如(维吾尔语的书写规范是从右向左):
(手机很漂亮)
Type2 例如:
(葡萄干和大枣都有营养)
Type3 例如:
(这款手机既实用又漂亮)
Type4 例如:
(葡萄干和大枣既营养又好吃)
定义4 动态意见词: 一种具有语境依赖性的意见词,在不同的语境里它的极性也随之发生变化[17]。
(这款手机长13公分)
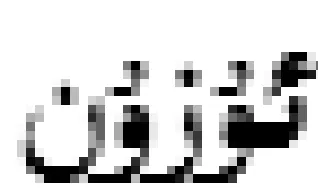
(这款手机太长了,拿着不方便)
(这款手机的电池寿命很长)
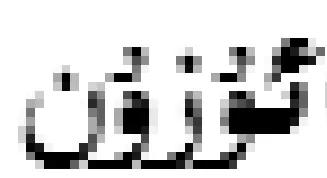
根据维吾尔语的语言特点,实验组维吾尔语语言学专家制定一个动态意见词库,限于篇幅,此处仅列举出部分动态意见词,如表2所示。
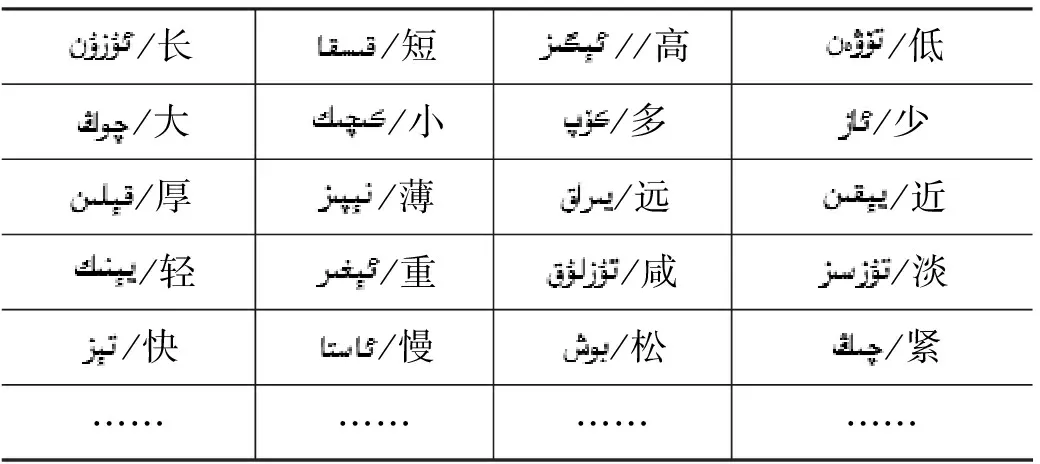
表2 动态意见词
4 基于双层CRFs模型的情感分析
4.1 CRFs模型
给定数据序列随机变量X,标注结果序列随机变量Y的条件概率分布P(Y|X),要求条件概率P(Y|X)最大。设x=(x1,x2,...,xn)表示待标注的观察序列,y=(y1,y2,...,yn)表示标注的输出序列,则CRFs定义为:
(1)
其中,fk是观察序列x中位置为i和i-1的输出节点的特征,gk是位置为i的输入节点和输出节点的特征,λ和μ是特征函数的权重,Z是归一化因子。
基于双层CRFs模型的情感分析研究,是在第一层模型中运用标签集Ψ对文本中的词进行标注,依据标注出的结果以及定义3确定意见陈述的范围,然后将第一层识别出来的结果作为第二层模型重要的输入特征之一,并结合定义4中动态情感词的特征等对意见陈述进行情感分析,构建出<意见陈述,主题词,意见词,情感>四元组。在第二层,我们对意见陈述的情感分析如式(2)所示。

(2)
其中,SO(claim)代表意见陈述的情感倾向。
双层CRFs模型流程如图1所示。
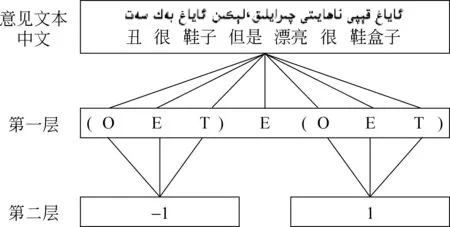
图1 意见文本标注过程

4.2 特征提取
提取的特征对本文采用的CRFs模型有直接的影响,提取恰当的特征对文本进行描述,可以提高实验效果。因此需要依据维吾尔语中表达情感的语言特点选取合适的特征。本文在第一层模型中选取如下特征。
(1) 词本身: 维吾尔语和汉语一样可以将词分为实词和虚词两类,实词大部分有比较实在的意义,可以表达具体的主题和情感; 虚词里的语气词仅有少部分能表达出说话者的情感[18]。
(2) 词性: 词性是能够标识语义信息的重要语法特征。在维吾尔语中,主要由名词来标识意见陈述的主题,表达情感意义的词语主要由形容词和动词构成,有些副词、名词、语气词等也可以表达情感。例如:
(刚买的床单上有个洞)

(5) 互信息(MI): 互信息不需要对特征词和类别之间关系的性质作任何假设,因此其非常适合于作为文本分类的特征。MI的计算公式如下:
(3)
(4)
(5)
式(4)中C(x,y)是指词x与通过意见词词典识别出来的意见词y在文本中共同出现的频率; 式(5)中C(x)是指词x在文本中出现的频率。通过对C(x,y)和C(x)的统计,再利用式(3)就可以计算出其他词与意见词之间的互信息。
在第一层CRFs模型中使用以上几个特征识别出意见型文本中的主题词和意见词,并根据定义3确定意见陈述的范围,再将识别出来的结果作为重要的输入特征传递给第二层CRFs模型。第二层CRFs模型中除了运用到第一层模型中的特征以外,还选取了以下特征:
(6) 主题词和意见词(即第一层识别出来的结果): 不同的意见词修饰不同的主题可以表达不同的情感,相同的意见词修饰不同的主题或者同一个主题也可以表达不同的情感。
(7) 动态意见词: 根据动态意见词库判断意见陈述中是否包含动态情感词。动态意见词的极性依赖于不同的语境。

我们将运用以上语法特点和规律以及如下公式建立否定成分词典D(w)。
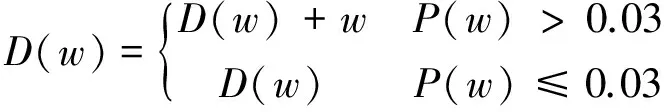
(6)
(7)
(8)
其中,M是由否定词、否定词缀和否定构形语素组成的集合,w′代表词w所包含的字母串m或部分包含m的字符串,‖w′⊕m‖表示w′和m相异或的模,‖m‖代表字母串m的模,即字母串m的长度。经多次实验验证,当阈值取0.03时,词w属于否定成分的准确度最高。所以,当P(w)>0.03时,将词w添加至否定成分词典; 否则,否定成分词典不变。利用最终的否定成分词典来判断意见陈述中是否包含否定成分。
4.3 特征选择
表达情感的自然语言具有复杂多变的特点,上述特征之间的组合可以描述情感分析中的复杂关系。但是,用文本表示方法生成的特征以及特征之间的组合都可能存在很多噪声。所以,我们需要通过特征选择去除噪声,提高分类的精度,并且特征选择可以通过减少特征空间获取更有效的特征,提高分类训练和应用的效率。
研究证实,特征选择可以看作一个搜索寻优问题。本文采用双向搜索策略并以信息增益(InformationGain,IG)作为特征评估函数进行特征选择。双向搜索即序列前向选择(SequentialForwardSelection,SFS)和序列后向选择(SequentialBackwardSelection,SBS)同时进行。IG的计算公式如下:
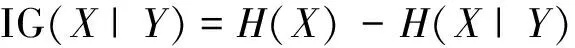
(9)
(10)
(11)
(12)
其中P(xi)代表随机变量X的先验概率,C代表观测到随机变量Y后随机变量X的后验概率.H(X)是X的信息熵,H(X|Y)为引入随机变量Y的信息后,随机变量X的信息熵。IG(X|Y)越大,则Y与X的相关性越强。
该方法通过计算特征的增益,再依据一定的规则构造出一个候选特征集,然后利用双向搜索策略从候选特征集选出最优的特征子集。具体算法步骤如下:
Step1 保留特征全集Ω; 置空特征子集Φ。
Step2 利用SFS将特征加入Φ,评估每一个特征的增益。同时利用SBS从Ω剔除一个特征x,使得剔除x后IG值达到最优。
Step3 组合具有高增益的特征(Top 6),加入候选特征集。
Step4 评估候选特征集中的特征,选取高增益的特征(Top 12)加入最优特征子集。
Step5 重复Step2-Step4,当SFS和SBS搜索到同一个特征子集时停止。
采用该算法对每层CRFs模型分别进行了特征选择,第一层CRFs得到2 159个特征,第二层CRFs得到2 684个特征。
4.4 情感分析双层模型识别
目前情感分析的目标不仅要识别出情感的类别,还需要针对具体的主题对其情感进行细粒度的分析。单一的模型或机器识别方法不能完全满足要求,本文提出的基于双层CRFs模型,对维吾尔语文本进行细粒度情感分析的方法可以很好地解决这一问题。首先,在第一层模型中运用4.2节所提到的前五个特征,识别出主题词和意见词,再结合定义3确定意见陈述的范围。将第一层识别出来的结果作为新的特征传递给第二层模型,再结合第一层的原有特征以及动态情感词和否定成分特征,识别出意见陈述的情感。示例流程如图2所示。

图2 情感分析双层模型识别
5 实验和分析
实验的语料来源于人民网、天山网以及一些论坛等维吾尔语版网页,我们对这些抓取的网页进行了去重和去噪处理,在必要的规范化整理后得到了本文所采用的维吾尔语意见陈述句。这些意见陈述句的情感类型分布比例如表3所示。
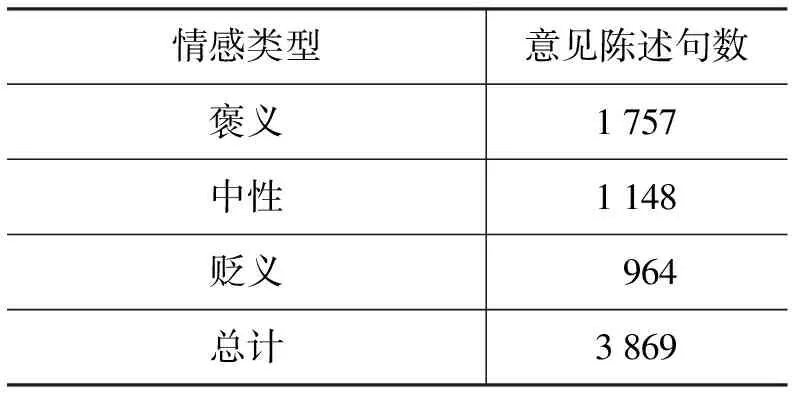
表3 意见陈述句情感类型分布
实验结果采用自然语言处理实验中常用的准确率P、召回率R、F-measure值F1作为评测标准。
(1) 实验识别结果和分析
为了尽量避免实验结果的随机性和偶然性对实验判别的影响,实验采用三倍交叉法进行。图3是第一层CRFs模型对主题词和意见词识别的结果。图4是第二层CRFs模型对意见陈述的情感分析结果。
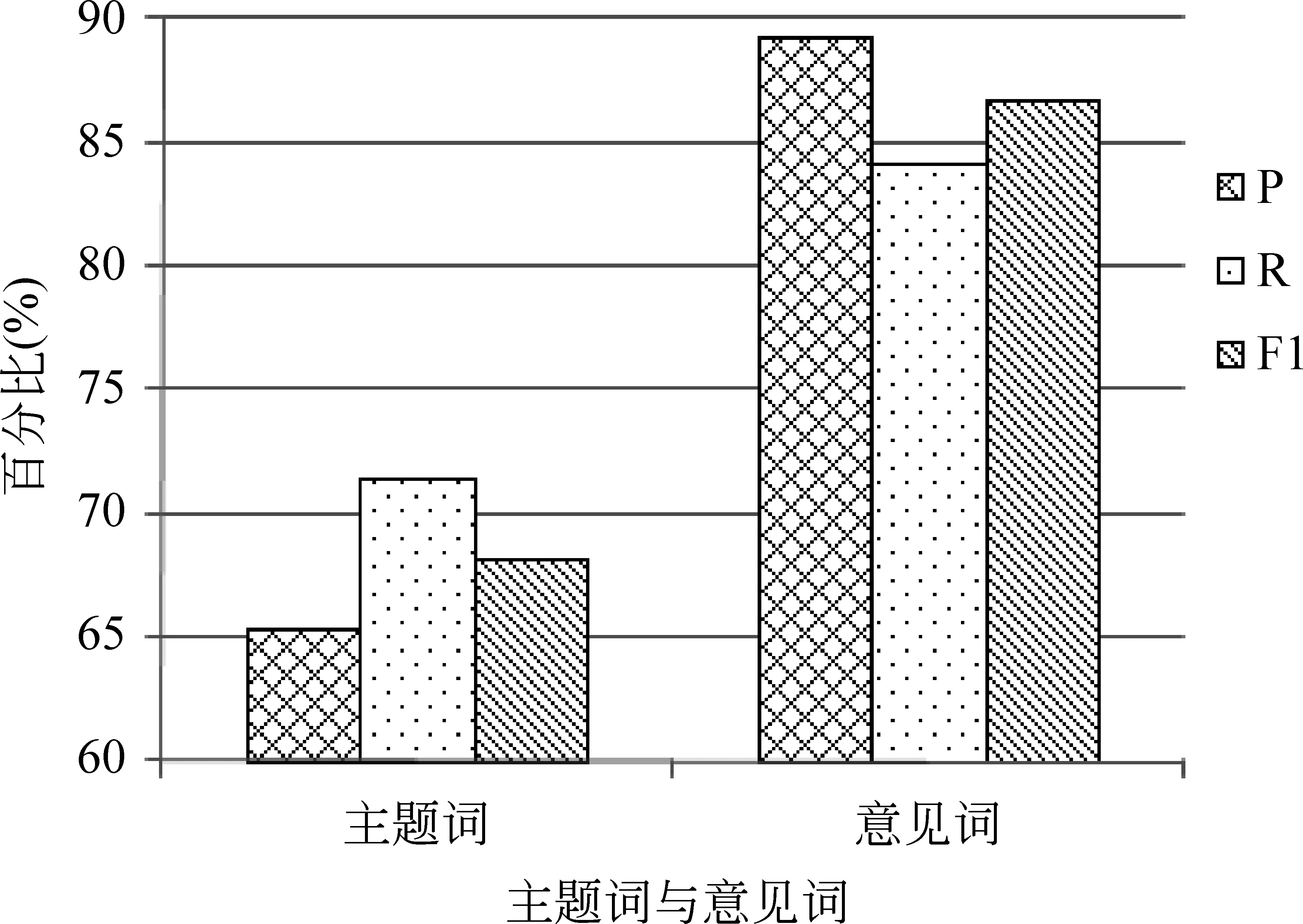
图3 主题词与意见词识别结果
从图3可以看出,意见词的识别效果优于主题词,这是因为有些意见陈述的主题是隐性的。例如,
(这个手机太长了)
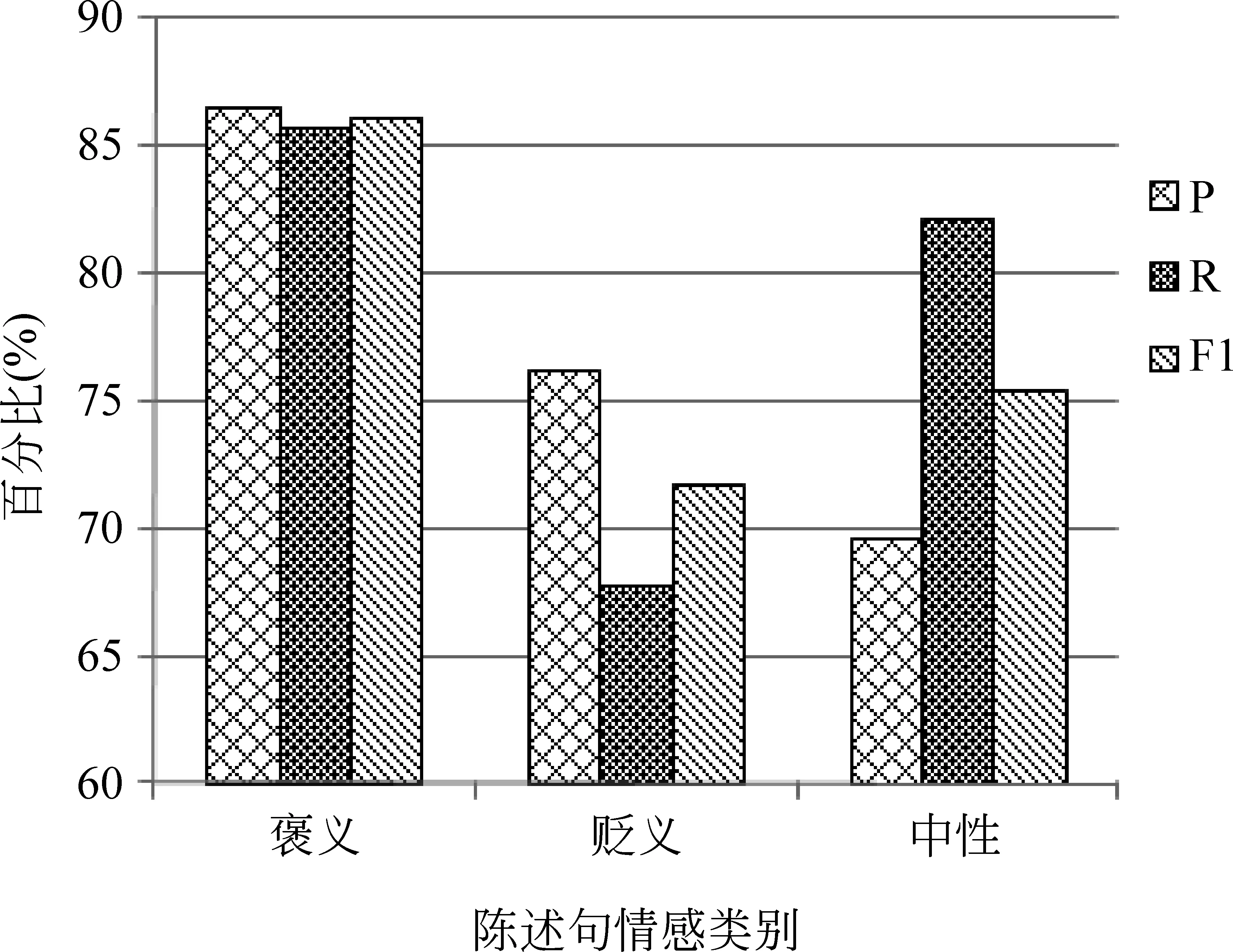
图4 意见陈述的情感识别结果
从图4可以看出,本文方法对意见陈述的情感分析可以取得较好的效果。我们可以发现褒义的分类效果要好于贬义和中性的,这是因为意见持有者习惯用比较显式且固定的意见词对主题进行褒扬,并且语料中褒义类的陈述句较多,所以比较容易识别。由图可知,中性的准确率最低,这是因为中性类即客观类的句子没有明显的特征,识别难度要高于褒义和贬义类的意见陈述。另外,贬义类召回率最低,这与人们习惯用隐晦的方式表达贬义的情感有关。例如,上面我们所提到的陈述⑧,此句表达的是贬义的情感,但是由于此句中没有明显的意见词,所以其情感很难被准确地识别。
(2) 语料规模对结果的影响
机器学习对语料规模有一定的要求,由于实验标记的语料相对较多,所以实验在逐步扩大语料的情况下也做了一组对比实验,实验结果如图5所示。
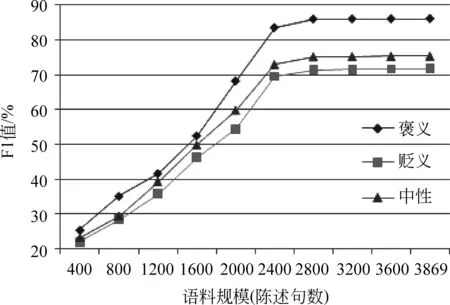
图5 语料规模对结果的影响
从图5可以清楚地看出,随着语料规模的扩大,褒义、贬义和中性的F1值都不断提高,但是当语料规模达到2 800个意见陈述句左右时结果趋于稳定。说明我们实验标注的语料规模适中,能够满足实验的要求。
(3) 特征集对结果的影响
特征集之间的搭配对机器学习的效果有很大的影响,我们实验采用的特征集逐步在上一级特征集扩展,即下级采用的特征集包含上级所有特征集,实验结果如表4所示。
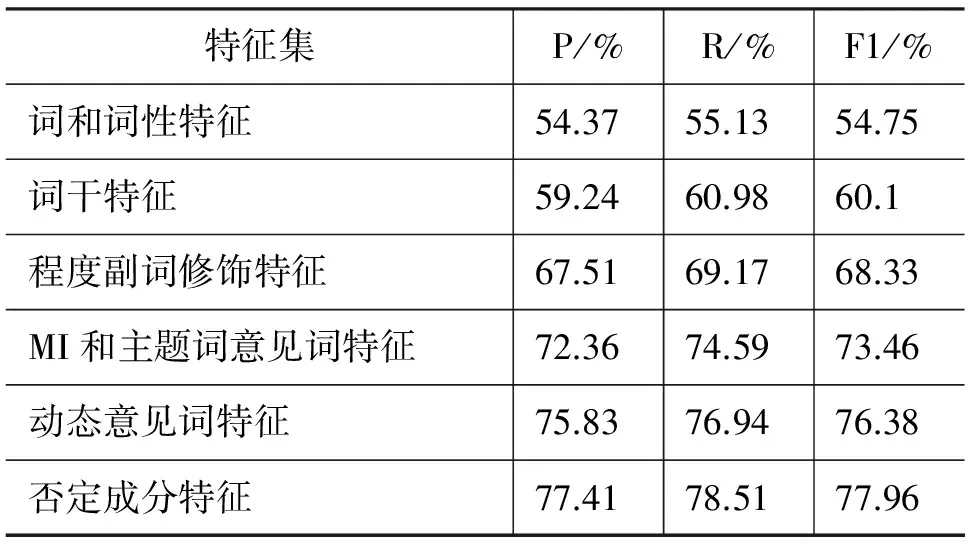
表4 特征集对结果的影响
从表中可以看出,随着特征集的不断扩展,情感分析的识别结果不断提高。词和词性特征集的识别率达到了54.37%,加入词干特征集和程度副词修饰特征集后,准确率和召回率都有明显的提升,这是因为词干的提取会解决词汇的多形态造成特征稀疏的问题,而且维吾尔语中的意见词大部分都会被程度副词所修饰。随着后面特征集的加入,F1值达到了77.96%的最高值。实验证明我们寻找的特征集合是有效的。
(4) 本文实验结果和其他学者实验结果比较
我们将主题词、意见词的识别结果和赵妍研的方法[14](以下简称“赵的方法”)做了对比实验。赵的方法提出了基于句法路径自动识别情感评价单元: <评价词语,评价对象>,该方法能够抽取类似本文通过第一层模型构造的<意见陈述,主题词,意见词>情感单元三元组。我们将赵的方法应用于本实验标注的语料进行主题词和意见词的识别,并和本文方法的实验结果作比较,具体情况如图6所示。
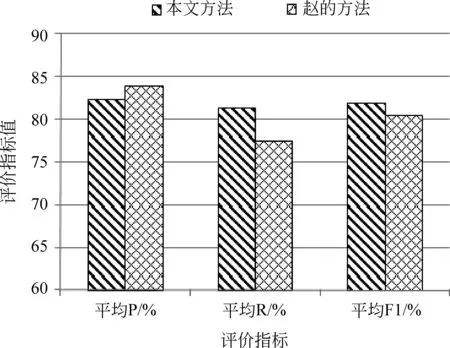
图6 情感单元识别结果对比
从图中可以看出,在准确率上本文方法低于赵的方法1.48个百分点,在召回率上却高于赵的方法3.95个百分点。这是因为赵的方法采用了基于编辑距离的句法路径改进策略,可以提高情感单元的识别性能,实验识别的准确率较高。但是赵的方法没有考虑维吾尔语文本在情感表达时一些自带的重要语言特征,且匹配情感单元的限制较为严格,因而赵的方法在召回率的表现上欠佳。综合比较发现,赵的方法F1值低于本实验方法1.36个百分点,从而也证明了本文第一层模型识别情感单元的可行性和有效性。
我们将情感分析的结果分别与顾正甲的方法[10]、Thet的方法[9](以下简称“顾的方法”、“Thet的方法”)做了对比实验。顾的方法和Thet的方法都是运用句法之间的关系,针对句子中特定的方面判断其倾向性,与本文针对主题考虑其情感倾向类似。我们将顾的方法和Thet的方法分别应用于本实验标注的语料进行情感分析。具体情况如表5所示。
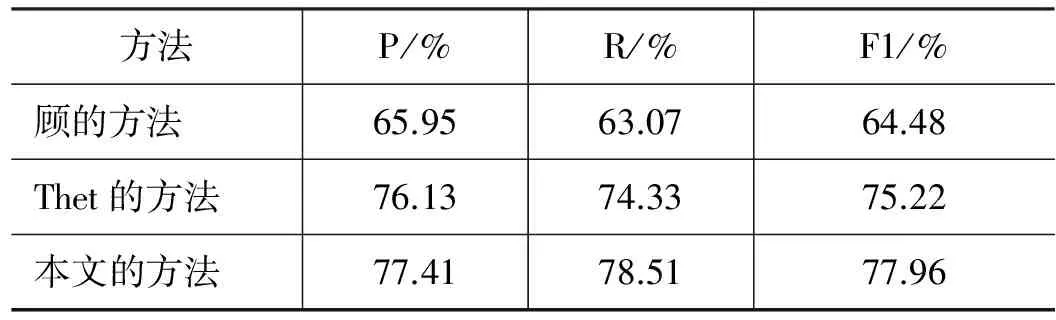
表5 情感分析结果对比
从表中可以看出,顾的方法效果不太理想,这是因为顾的方法对LTP句法分析结果的依赖性较大。Thet的方法稍逊于本文方法,这是因为Thet的方法只针对电影这一特定领域,不能完全考虑本实验所标注的开放领域意见型文本。而且顾的方法和Thet的方法都没有深入考虑动态意见词对情感倾向的影响。综合比较发现,本文方法F1值分别高于顾的方法和Thet的方法13.48%、2.74%。
6 结论和展望
情感分析对于自然语言处理技术的发展具有很大的研究价值和实用价值。现有的研究主要针对英语、汉语等大语种,而对于维吾尔语情感分析的研究还很少,并且对意见型文本细粒度分析的研究不多。针对以上不足,本文提出了细粒度意见挖掘中维吾尔语文本情感分析的方法,与以往研究方法不同的是,该方法不仅可以识别主题词、意见词以及确定意见陈述的范围,而且可以针对主题考虑其对应情感,构造出<意见陈述,主题词,意见词,情感>四元组,对维吾尔语意见陈述进行多层次和细粒度的情感分析。实验结果表明,本文采用的方法适用于维吾尔语陈述情感分析,取得了较好的效果。实验对隐式主题以及反语、隐喻等隐含情感的陈述的情感分析效果不是特别理想,我们下一步将对这些问题进行深入的研究。
[1] 赵妍妍, 秦兵,刘挺. 文本情感分析[J]. 软件学报, 2010, 21(8): 1834-1848.
[2] Turney P D. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (ACL). Philadelphia, USA, 2002: 417-424.
[3] Pang B, Lee L, Vaithyanathan S. Thumbs up? Sentiment Classification using Machine Learning Techniques[C]//Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP). Philadelphia, USA, 2002: 79-86.
[4] Zhao J, Liu K, Wang G. Adding redundant features for CRFs-based sentence sentiment classification[C]//Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing (EMNLP). Honolulu, Hawaii, 2008: 117-126.
[5] 林政, 谭松波, 程学旗. 基于情感关键句抽取的情感分类研究[J]. 计算机研究与发展, 2012, 49(11): 2376-2382.
[6] Lin C H, He Y L. Joint sentiment/topic model for sentiment analysis[C]//Proceeding of the 18th ACM conference on Information and knowledge management. New York, 2009: 375-384.
[7] Jo Y, Oh A. Aspect and sentiment unification mode for online review analysis[C]//Proceedings of the 4th ACM international conference on Web search and data mining. New York, 2011: 815-824.
[8] 孙艳, 周学广, 付伟. 基于主题情感混合模型的无监督文本情感分析[J]. 北京大学学报 (自然科学版), 2013, 49(1): 102-108.
[9] Thet T, Na J, Khoo C. Aspect-based sentiment analysis of movie reviews on discussion boards[J]. Journal of Information Science, 2010, 36(6): 823-848.
[10] 顾正甲, 姚天昉. 评价对象及其倾向性的抽取和判别[J]. 中文信息学报, 2012, 26(4): 91-97.
[11] Tony M, Nigel C. Sentiment analysis using support vector machines with diverse information sources[C]//Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP), Barcelona, Spain, 2004: 412-418.
[12] Jiang L, Yu M, Zhou M, Liu X H, Zhao T J. Target-dependent Twitter Sentiment Classification[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics(ACL). Portland, Oregon, 2011: 151-160.
[13] 谢丽星, 周明, 孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J]. 中文信息学报, 2012, 26(1): 73-83.
[14] 赵妍研, 秦兵, 车万翔, 等. 基于句法路径的情感评价单元识别[J]. 软件学报, 2011, 22(5): 887-898.
[15] 姚天昉, 程希文, 徐飞玉, 等. 文本意见挖掘综述[J]. 中文信息学报, 2008, 22(3): 71-80.
[16] Kim S-M, Hovy E. Determining the Sentiment of Opinions[C]//Proceedings of the Conference on Computational Linguistics (COLING). Geneva, Switzerland, 2004: 1367-1373.[17] Liu R, Xiong R, Song L. A Sentiment Classification Method for Chinese Document[C]//Proceedings of the 5th International Conference On Computer Science & Education (ICCSE). Hefei, China, 2010: 918-922.
[18] 易坤秀, 高士杰. 维吾尔语语法[M]. 北京: 中央民族大学出版社, 1998: 10-70.
Sentiment Analysis of Uyghur Text for Fine-grained Opinion Mining
LUO Yawei1, TIAN Shengwei2, YU Long3, Turgun·Ibrahim1, Askar·Hamdulla2
(1. School of Information Science and Engineering, Xinjiang University, Urumqi, Xinjiang 830046, China; 2. School of Software, Xinjiang University, Urumqi, Xinjiang 830008, China; 3. Network Center, Xinjiang University, Urumqi, Xinjiang 830046, China)
Traditional research on sentiment analysis is to determine the sentiment of word, sentence or the whole text, ignoring the topics involved in the sentimental expressions In contrast, this paper proposes a method based on cascade CRFs model to analyze the sentiment at claim level of Uyghur opinioned text. The first layer extracts the topic word and its corresponding opinion word, and determines the scope of opinioned claim, and the result is then passed to the second layer as one of the key features which contributes to sentiment analysis at the claim level. The goal of the sentiment analysis on fine-grained opinion mining is to build a quadruple, which is
fine-grained; claim level; sentiment analysis; CRFs; Uyghur

罗亚伟(1990-),硕士研究生,主要研究领域为人工智能。E⁃mail:ywLuo_pleasant@126.com田生伟(1973-),博士,教授,主要研究领域为计算机智能技术及自然语言处理。E⁃mail:tianshengwei@163.com禹龙(1974-),通信作者,硕士,教授,硕士研究生导师,主要研究领域为计算机智能技术及计算机网络。E⁃mail:yul_xju@163.com
1003-0077(2016)01-0140-08
2013-07-22 定稿日期: 2013-11-18
国家自然科学基金(61563051,61262064,61331011,60963017,61063026,61063043);国家社科基金(10BTQ045, 11XTQ007)
TP391
A
猜你喜欢
考试与评价·七年级版(2021年5期)2021-08-14
实用医药杂志(2021年4期)2021-01-11
中国医学计算机成像杂志(2020年6期)2020-03-14
中国民族博览(2019年10期)2019-11-29
心声歌刊(2018年4期)2018-09-26
北方文学(2018年2期)2018-01-27
自动化学报(2017年4期)2017-06-15
中华诗词(2017年9期)2017-04-18
自动化学报(2017年11期)2017-04-04
中国骨与关节杂志(2016年12期)2016-01-23
