
网页搜索中查询时效性的实时计算模型
2016-05-04 00:58刘云峰段建勇熊展志乔建秀张梅
中文信息学报 2016年1期
胡 熠,刘云峰,段建勇,熊展志,乔建秀,张梅
(1. 阿里巴巴(中国)网络技术有限公司, 浙江 杭州 310052; 2. 腾讯公司, 广东 深圳 200230; 3. 北方工业大学 信息工程学院, 北京 100144)
网页搜索中查询时效性的实时计算模型
胡 熠1,刘云峰2,段建勇3,熊展志2,乔建秀2,张梅3
(1. 阿里巴巴(中国)网络技术有限公司, 浙江 杭州 310052; 2. 腾讯公司, 广东 深圳 200230; 3. 北方工业大学 信息工程学院, 北京 100144)
网页搜索中的查询时效性是指查询对新闻网页的需求。这种时间相关的因素,在网页排序过程中用于平衡其他非时间性因素,使排序更好地满足用户体验。为此该文提出了一种查询时效性的实时计算模型: 从用户搜索和媒体报道两个角度,分别对时效性建模,然后这两种不同来源的时效性相互补充,综合计算某个时刻用户搜索某个查询时,其综合时效性得分。这个量化得分在网页排序阶段用于提高或抑制新闻网页的露出;同时也为网页搜索结果中展现新闻直达区提供依据。在人工评测以及用户点击通过率统计上,该模型均取得了不错的实际效果。
查询时效性;时效性用户模型;时效性媒体模型
1 前言
网页搜索中的查询(Query)时效性是指查询对新闻网页的需求。用户在搜索框里输入一个查询时,有很多潜在的意图,其中很重要的是对时效性的需求。例如,用户搜索“钓鱼岛”,更倾向于了解当前钓鱼岛争端引发的中日局势,而不是几年前钓鱼岛的情况,或者钓鱼岛的百科、地理、人文知识。所以搜索引擎需要识别查询是否和时下受关注的热门事件相关,即它的时效性,为之后搜索的各个阶段提供帮助。查询时效性发挥两个主要作用:
1. 新闻加强(News Boost)。时效性较高的查询,对应的新闻网页通常刚出现不久,没有积累足够的Page Rank, Click等信息,在排序竞争中容易排在后面,但是这些新闻网页又是用户此时此刻最希望看到的。所以通过时效性因素把新闻网页调整到搜索结果的合适位置,使得新闻网页能及时露出,是恰当和必要的。
2. 新闻直达区(News Box)。决定是否需要在网页搜索结果中展现特定的聚合信息,即新闻直达区。如果时效性较高的查询能召回相关度较高的近期新闻网页,则会在搜索结果页中展现新闻直达区,提高用户的关注度和体验。
本文提出了一种实时计算查询时效性的模型,应用到搜索引擎中,并做了评测。由于时效性有一定的主观性,对模型的评价,本文既使用了人工评测的方式,同时也参考用户搜索后的点击通过率指标,验证了模型的有效性。综合来看,本文的贡献在于:
1. 根据发现时效性的源头,引入时效性用户模型和时效性媒体模型,互为补充,使得查询时效性计算对时效性查询的识别覆盖度、准确性都有较好的表现。
2. 时效性因素实际应用于搜索引擎,为调整排序、生成新闻直达区提供了量化依据。
2 相关研究
对查询时效性的计算,从本质上来讲是对时序流数据[1]的数据挖掘,其相关研究由来已久。流数据有别于传统数据库数据的地方在于,流数据(在本文是查询的流和新闻数据的流)持续到达,而且速度快、规模大。而基于流数据模型的数据挖掘技术,包括聚类分析[2]、密度估计[3]等在实际应用中得到了广泛的应用。文献[4]则综合介绍了基于流数据模型挖掘的一些算法。
在基于流数据的任务中,和本文查询时效性计算相关的研究有话题发现(Topic Detection,TD)。话题定义: 一个话题由一个种子事件或活动以及与其直接相关的事件或活动组成[5]。话题检测的主要任务是检测预先未知的话题, 在“未知”这个属性上和查询时效性相似。所以TD和本文研究的查询时效性都需要在毫不知情的情况下构造检测模型,也就是需要预先设计一个检测模型,并根据这一模型检测陆续到达的数据流,从中鉴别最新的话题或查询时效性。 对于TD而言,更麻烦的在于随时间发展,媒体对话题的报道随时间逐渐漂移。需要利用后续报道不断检测相关而新颖的信息对话题模型进行调整[6],同时屏蔽话题模型更新过程中引入的噪声。
查询时效性计算在用户查询数据流和媒体报道流中,把查询作为一个特征,这和流数据特征提取的工作,也有相似之处。R Swan等人[7]研究了从普通文档(非结构化文档)中,发现随时间频率有显著变化的名实体特征,只考察某个时间段内新闻报道中出现的人名,组织名等实体名词,并在最后的评测中采用人工评测的方法。只关注名实体,就不能对任意一个查询计算其时效性。俞晓明等人的研究工作[8],从短文本(如手机短信)中抽取时间敏感的字串,结合流数据的Deltoid算法[9],应用于海量短文本的实时在线处理。文献[8]在各个时间段形成大量的候选子串,再使用Deltoid算法判断候选字符串在某个时间段上是否具有时效性,这种判断主要依赖绝对频率的比较。由于每个时间段采样数据量不同,绝对频率不能客观的反映某时间段上的这个候选字符串的重要程度。
3 查询时效性计算模型
在本节,我们提出了一种从用户搜索和媒体报道两方面建模的方法,命名为UMM(User and Media Model)。本文考虑的出发点是: 时效性比较高的事件,在用户搜索的查询流上,会有搜索次数上的显著差异;新闻媒体也会对时下热门事件集中报道。而媒体和用户又有不一样的地方: 媒体更主流和权威,更侧重于有影响力的大事件,而用户的搜索则更草根,可以兼顾到比较小众的事件。基于这样的数据理解,本文分别设计了时效性用户模型和时效性媒体模型。在用户模型中,我们主要观察搜索引擎查询流中查询的搜索频次的变化;对新闻媒体的报道,则是查看和查询相关新闻的篇数。这两种数据来源的模型,相互印证和补充,使得对查询时效性的计算不遗漏、不偏颇。
3.1 查询时效性计算模型
本文把条件概率P(x|q)作为查询时效性建模的初始对象。其中q表示查询,x表示是否具有时效性:x∈{0,1}。0表示没有时效性,1表示具有时效性。我们关心P(x=1|q),采用如式(1)所示的分解形式。
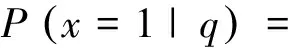
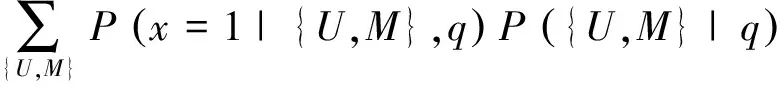
(1)
{U,M}表示计算q时效性的来源的集合,目前只有两个,一个是用户(U),一个是媒体(M)。本文假定用户搜索一个事件和媒体报道一个事件,相互之间独立。尽管用户的搜索可能会受到媒体报道的影响,但为了处理上的方便,认为这种独立性假设是合理的。由此,得到式(2)。
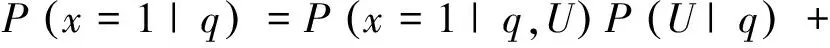
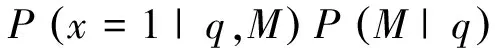
(2)

(3)
本文设定U和M的重要程度相当,即α=β=0.5。下面分别阐述时效性用户模型和媒体模型的计算。
3.2 查询时效性的用户模型
概率P(x=1|q,U)表示在用户模型下,一个查询具有时效性的概率。从本质来讲,这是一个基于时序的模型: 在一定的时间窗口T内,用一个查询q搜索频次的“变化趋势”作为时效性计算的依据。我们把时间窗口T划分为T个原子的,不可再分的时间片段。定义第一个时间片段的时间戳是1,最后一个时间片段的时间戳是T。对其中某个时间片段t而言,其表示的单位时间范围内,用户搜索查询q的频次占除q之外的其他所有查询搜索频次之和的比例如式(4)所示。
(4)
t和上个片段t-1的“比例差”是计算时效性用户模型的基础特征。前后两个时间片段的比例差值,可正可负,如式(5)所示。
(5)

(6)
整个T时间段内的累积比例差RsumT(q)反映了整体搜索引擎用户在T时间内对事件关注程度的“上升”和“下降”之间的博弈。累积比例差代入到Sigmoid函数作为一个查询的用户模型时效性值如式(7)所示。
(7)
用户模型在实际应用时,时间窗口T取12小时(在实验环节有进一步阐述),时间片段取1分钟。这个算法描述了整体用户搜索查询次数的变化趋势,并把这种趋势抽象出特征进行累积。一般来讲,持续报道中的热门事件,会累积越来越大的比例差值,使得时效性在不断增加,趋近于1。而随着整体搜索引擎用户对这个事件的关注度降低,累积的比例差会被慢慢抵消,从而使得时效性降低。显然,这是一个O(T)时间复杂度的算法。
3.3 查询时效性媒体模型
媒体模型主要观察新闻媒体对查询的“报道”情况。本文定义一个新闻网页“报道”了查询,是指这个新闻网页标题对查询的全覆盖,即查询中的所有词在标题中都出现,且和这个标题具有一定的相关度。
一段时间窗口内对查询报道的新闻网页标题的篇数,在时间轴上形成有一个报道数量的分布。如“曹操墓”在某时间点,前溯180天内的每天报道数量如图1所示。

图 1
在疑似曹操墓被发现之前,新闻网页提及“曹操墓”的非常少,而在疑似曹操墓被发现之后,报道“曹操墓”的数量急剧增长。随着时间的流逝,新闻媒体对“曹操墓”的关注开始降温,出现了后期报道篇数总体下降的趋势。在这个时间轴上任意一个时间点上,透过新闻媒体报道来看“曹操墓”的新闻时效性,得到符合用户主观认知的时效性值,是媒体模型设计的目的。
为了计算一个查询的时效性值,媒体模型按某个时间戳把从当前时间向前回溯的180天(或30天,10天)划分成两个子时间窗口。这两个子时间窗口互为对比。对比的时间子段分别是从当天算起向过去追溯的时间段Tnew和进一步向前追溯的时间段Told。Tnew和Told的比例根据需要设定。如Tnew取最近的时间跨度30天(或10天、3天),Told取Tnew之前时间跨度150天(或20天、7天)。确定了子时间窗口后,根据新闻网页的创建时间把新闻网页分配到这两个子时间窗口内,计算查询每天的报道数量。这两个子时间窗口上每天查询的报道篇数是媒体模型需要的基础数据,其实质是利用报道了查询的新闻网页的篇数来间接估计查询本身的时效性。
媒体模型通过卡方检验判断这个查询在这两个子时间窗口内的发生比率是否具有显著差异。这个变化的显著性作为查询的时效性值。表1是媒体模型用到的基础数据。
表1 卡方校验中的四分表
其中,a表示在Tnew时间段中报道了查询的网页篇数;b在Tnew时间段中没有报道查询的网页篇数;c在Told时间段中报道查询的网页篇数;d在Told时间段中没有报道查询的网页篇数。四分表卡方检验的基础算法为式(8)。
(8)
本文的媒体模型从两个方面对卡方算法做了针对时效性计算的优化。
1. 按命中的新闻网页出现的时间不同,以权重的方式修正a,b,c,d: 在Tnew子时间窗口内,越靠近当前时间的时间戳,权重越高,报道或没有报道的篇数作适当的放大;在Told子时间窗口越远离现在的时间戳,权重越高,报道或没有报道篇数作适当的放大。以180天时间跨度为例,今天的时间戳定义为tnow, 180天前的时间戳定义为tstart, 时间界限的时间戳定义为tline, 某一天的时间戳定义为tx,这一天报道q或没有报道的篇数为m,按上述原则,m将修正为m′,如式(9)所示。
(9)
每一天m→m′的变化,会使得调整后的a′,b′,c′,d′,n′代替原来的无权重的a,b,c,d,n。 另外,媒体模型只关心查询时效性值的相对大小,所以固定值n在真正计算时可以忽略。调整后的卡方统计量的计算如(10)所示。
(10)
2. 在媒体模型中,本文使用了三个时间跨度,分别是180天、30天、10天。同时,定义了三个时间界线,分别是30天、10天、3天。在这三套卡方值计算的基础上,选择最大的输出。选最大的原因是为了对突发事件有较好的敏感性,另一方面对稍过气的查询q,时效性值不至于急剧下降,整体有较好的平滑性,如式(11)所示。
χ2(q)*=
(11)
同样的,使用Sigmoid函数对计算得到的卡方值做归一化处理,得到式(12)。
(12)
由于卡方计算存在对称性,对Told大量报道,而Tnew较少报道的查询,说明热度已过,算法对卡方值折半,即式(11)中μ=0.5,否则μ=1。媒体模型是O(T)时间复杂度的算法。
4 实验和结果
4.1 实验设置
我们设计了两个实验来验证本文提出的查询时效性计算模型。第一个实验从搜索引擎的实际查询日志中随机挑选一定数量的查询,作为人工评测对象,由三个评测人员分别对每一个查询进行时效性判定。本文和参考文献中的一些方法做了对比。因为人工评测数据少且有一定的主观性,所以本文设计了第二个实验,用基于搜索结果页中新闻直达区和新闻网页的点击通过率,即大量用户搜索后的点击行为,从另一个方面反映模型的好坏。
4.2 评价方法
4.2.1 人工评测
从用户的检索日志中,排重后随机挑选1 000个query作为评测对象,由三个评测人员对每一个查询进行判定是否具有时效性。由于每个人的主观性和知识面不同,对一个查询是否具有时效性的判断有一定主观性,所以采用少数服从多数的原则: 两人以上认为一个查询具有时效性,则是一个正例,反之,是一个反例。
本文在新闻媒体数据上使用Chi[7],以及Deltoid算法[9],作为和本文模型的对比。Deltoid没有设定绝对阈值,而是设定差值比例超过20%这样的相对阈值。同时,只使用用户模型或媒体模型,也作为对比的模型加入到了实验中。是否具有时效性可看成是一个0-1分类的判定,所以本文使用常用的召回率、准确率和F1-measure指标。实验结果见表2。

表2 五种时效性计算模型的召回率、准确率和F1-measure对比
表2中UMM(用户媒体模型)在人工验证集上的性能是所有结果中最优的,相比Deltoid和Chi,有显著提高;而对比两个单来源的时效性模型 (OnlyU或者OnlyM),性能也有明显改善。另一方面,正如之前的分析,文献[7,9]中的方法有自身的缺点,对时效性查询覆盖不好或者准确性不够。人工评测的方式能在一定程度上验证模型的差异, 但由于评测数据规模和评测人员的知识背景、对事件认知的不同,对一个查询是否是具有时效性会有意见相左的情况。所以,另一个实验是基于大量用户的点击行为来验证时效性模型。
4.2.2 点击通过率(Click Through Rate, CTR)评测

表3 五种时效性计算模型的新闻直达区、新闻网页加强展现比例以及CTR对比
表3中各个方法对新闻直达区的触发和新闻网页加强的应用,适应各自的最佳阈值。可以看到UMM在用户点击通过率指标上也具有明显的优势。这主要是因为结合用户模型和媒体模型比单用一个模型覆盖度更好,而且通过相互校验,准确性也更高。 而直接移植过来的方法[7,9]由于受限于自身方法的缺点,表现不佳。
4.2.3 时间窗口大小选择实验
为了选择用户模型和媒体模型各自的时间窗口,本文还通过从某个初始窗口大小开始,逐步增加时间窗口的方法,观察时间窗口大小对时效性整体性能的影响,即时间窗口不断增加时F1-measure的表现。由于用户模型和媒体模型相对独立,所以通过两次实验分别确定时间窗口的大小。
我们使用不同时间跨度的窗口来研究时间窗口对时效性整体性能的影响。表4第二行表示用户模型从初始的T=2小时开始,每次增加两个小时得到F1-measure曲线图。 而表4第三行则是媒体模型从初始的T=40天开始,每次增加20天得到的F1-measure曲线图。由于OnlyU和OnlyM时间窗口增加的时间点的个数相同,所以把两列数据合并表示,如表4所示。
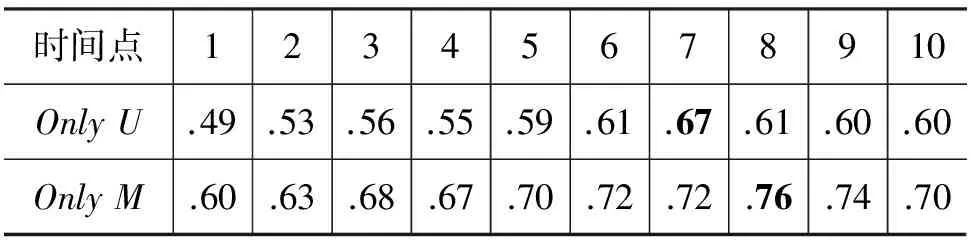
表4 Only U和Only M的时间窗口大小变化时F1-measure对比
表4中第二行的结果表明OnlyU在时间跨度逐渐增大的过程中,F1-measure逐渐上升,到了大约12个小时的时候,获得了相对较高的性能。而在表4第三行中,表明OnlyM也是随着F1-measure先升后降,大致确定其时间窗口在180天的时候,可以得到相对较好的性能。实验显示时间窗口不是极端大或极端小时能取得最优的性能。这是因为窗口小的时候,虽然在事件爆发时,有足够的敏感度,但由于窗口小,很容易被填充,使得在流数据到来的过程中,对查询热度识别能力反而下降。同样的,时间窗口过大,会导致敏感度不足。适当的窗口,既可以保证相对高的敏感度,也可以增强对数据震荡的抗干扰能力。
5 结论
本文考察了查询时效性计算的两个来源,即用户搜索行为和媒体报道,针对这两个数据来源设计了相应的时效性模型。通过计算查询的时效性,对搜索的返回结果进行适当调整: 把时效性较高的查询对应的新闻网页排名提高;展现新闻直达区。
综合来看,对查询表达的意义,本文的UMM可以给出一个合理的时效性打分。对有时效性的查询,在其热度过去之后,能保有并衰减其时效性,使得持续追踪报道的页面也有机会露出。然后随着时间推进,新闻页面的其他非时间因子(Page Rank, Click等)累积足够之后,在没有时效性的帮助时,也不妨碍它们的露出。
本文相比以往工作的优势在于:
1. 通过两个来源相互校验和补充,提高了对查询时效性识别的覆盖能力和准确性;
2. 给每个查询计算一个合理的分值,柔性处理,应用到实际搜索引擎中,效果良好;
3. 便于扩展,可以加入新来源,或者通过查询聚类等手段,扩大UMM的覆盖能力;
4. 实时性好,能满足在线大流量的搜索访问。
需要特别说明的是,本文虽然用整个查询作为时效性的计算单位,但是完全可以把计算范围推广到查询中的任意语言单元,也就是可以先计算查询中单个查询词的时效性,再组合生成整个查询的时效性,实现灵活搭配。
[1] Babcock B, Babu S, Datar M, et al. Models and issues in data streams[C]//Proceedings of the 21st ACM SIGACT-SIGMOD-SIGART Symp. on Principles of Database Systems. Madison: ACM Press, 2002: 1-16.
[2] Guha S, Mishra N, Motwani R, et al. Clustering data streams[C]//Proceedings of the 41st Annual Symposium on Foundations of Computer Science, FOCS 2000. Redondo Beach: IEEE Computer Society, 2000: 359-366.
[3] Zhou A, Cai Z, Wei L, et al. M-Kernel merging: Towards density estimation over data streams[C]//Proceedings of the 8th International Conference on Database Systems for Advanced Applications (DASFAA 2003). Kyoto: IEEE Computer Society, 2003: 285-292.
[4] Garofalakis M, Gehrke J, Rastogi R. Querying and mining data stream: you only get one look-A tutorial[C]//Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data. Madison: ACM Press, 2002: 635.
[5] 郑伟,张宇,邹博伟,等. 基于相关性模式的中文话题跟踪研究[C]//全国第九届计算语言学学术会议, 2007.
[6] 李保利,俞士汶. 话题识别与跟踪研究[J ]. 计算机工程与应用, 2003,39(17):6-10.
[7] R Swan, J Allan. Extracting significant time varying features from text[C]//Proceeding of the 8th International Conference on Information and Knowledge Management, New York: ACM Press, 1999: 38-45.
[8] 俞晓明,许洪波. 短文本时间敏感字串的提取[C]//第三届全国信息检索与内容安全学术会议. 2007.
[9] G Cormode, S Muthukrishnan. What’s New: Finding Significant Difference in Network Data Stream[J]. IEEE/ACM Transactions on Networking, 2005, 13(6): 1219-1232.
The Real-time Computing Model of Time-sensitive Queries in Web Search
HU Yi1, LIU Yunfeng2, DUAN Jianyong3, XIONG Zhanzhi2, QIAO Jianxiu2, ZHANG Mei3
(1. Alibaba Inc, Hangzhou, Zhejiang 310052, China; 2. Tencent Inc, Shenzhen, Guangdong 200230,China; 3. College of Information Engineering, North China University of Technology, Beijing 100144,China)
The time-sensitive of queries in web search refer to the requirement of news webs. This time-related factor is used to balance the other factors in the ranking of webs to satisfy users’ search needs. In this paper, the author presents a computing model for time-sensitive of queries by modeling users’ search behaviors and the media reports, separately. Then, these two kinds of sub-models are combined to compute final time-sensitive scores of queries in the searching process. The time-sensitive scores give the ranking a quantified evidence to boost or reduce the weights of news webs and, further, provide supports for special news information box appeared on the result page after searching. The proposed model yields satisfactory performances and effective feedback from users in both artificial and clicks through rate experiments.
time-sensitive queries; user model of time-sensitive queries; media model of time-sensitive queries

胡熠(1978—),博士,高级技术专家,主要研究领域为电子商务、搜索引擎及自然语言处理。E⁃mail:erwin.huy@alibaba⁃inc.com刘云峰(1977—),博士,专家工程师,主要研究领域为自然语言处理和机器学习。E⁃mail:glen@vip.qq.com段建勇(1978—),博士,副教授,主要研究领域为中文信息处理。E⁃mail:duanjy@hotmail.com
1003-0077(2016)01-0079-06
2013-09-25 定稿日期: 2014-04-15
国家自然科学基金(61103112);国家社会科学基金(11CTQ036);国家语委十二五规划基金(YB125-10);北京市哲学社会科学规划基金(13SHC031)
TP391
A
猜你喜欢
——以澳大利亚莫斯维尔社区花园为例
中国园林(2022年1期)2022-02-19
家庭影院技术(2021年2期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
河北果树(2020年4期)2020-11-26
都市生活(2019年5期)2019-08-01
中国自行车(2018年11期)2018-12-03
唐都学刊(2018年4期)2018-09-05
中国自行车(2017年1期)2017-04-16
中国铁道科学(2015年2期)2015-06-26
资源导刊(2014年1期)2014-03-05
