
基于LDA模型的论坛热点话题识别和追踪
2016-05-04 00:58徐佳俊姚天昉付中阳
中文信息学报 2016年1期
徐佳俊,杨 飏,姚天昉,付中阳
(萨尔州大学-上海交通大学 语言技术联合实验室,上海交通大学 计算机系,上海 200240)
基于LDA模型的论坛热点话题识别和追踪
徐佳俊,杨 飏,姚天昉,付中阳
(萨尔州大学-上海交通大学 语言技术联合实验室,上海交通大学 计算机系,上海 200240)
在当今处于信息数量爆炸式增长的互联网时代,如何分析海量文本中的信息并从而提取出所蕴含的有利用价值的部分,是一个值得关注的问题。然而论坛语料作为网络语料,其结构和内容较一般语料相比更为复杂,文本也更加短小。该文提出的方法利用LDA模型对语料集进行建模,将话题从中抽取出来,根据生成的话题空间找到相应的话题支持文档,计算文档支持率作为话题强度;将话题强度反映在时间轴上,得到话题的强度趋势;通过在不同时间段上对语料重新建模,并结合全局话题,得到话题的内容演化路径。实验结果说明,上述方法是合理和有效的。
论坛;话题模型;趋势分析;话题追踪;LDA
1 引言
随着互联网上信息量的不断增大,微博、各大网站、BBS、搜索引擎等网络信息载体已经成为人们获取新闻信息的主要途径。这些载体包含了日常生活中能够谈论到的大部分话题,对其中的热点话题也能够进行连续的跟踪报道。如果可以实现话题的自动识别及追踪,那么可以节省大量的人工时间和精力,能够帮助用户理解新闻话题之间的内在相关性。
话题的识别与追踪(Topic Detection and Tracking),简称TDT,为解决这一问题提供了一个方向。TDT的目的是对大量的具有新闻性质的文本进行组织、分类、结构化,最后将所有的文本归结为若干个话题及话题间的前后关系。
随着时间的推移,话题本身由于颗粒度较粗,已经不能够满足现实的需要,如何自动识别话题的演化[1],成了当前研究的新热点。话题的演化通常是指话题随着时间的变化,而表现出的从开始到高潮再到衰落的过程。话题在这个过程中的内容和强度的变化描述了该话题的演化过程。从语料库的角度来看,论坛语料有着其特殊性,短小的文本和较为复杂的结构使得在这些语料中提取话题的难度提高,而语料中含有大量重复信息也是论坛类语料的一大缺陷。
本文的目标是针对论坛语料的热点话题识别进行研究,并需要对抽取出的相应话题进行追踪。在本次研究过程中我们选用汽车领域的论坛语料作为研究用材料。
2 研究背景
2.1 基于话题模型的话题发现方法
2.2 基于话题模型的话题追踪方法
目前基于LDA的话题追踪方法,可以归结为三种不同的方法: 第一种方法是在LDA中将时间作为可观测变量结合起来;第二种方法是先在整个文本集合上用LDA模型生成话题,然后根据文本的时间信息,根据话题的后验分布,离散地分析话题随时间的变化;第三种方法将文本集合先按一定时间粒度离散化,然后在每个时间段上分别运用LDA模型来获取结果。Shan等人[5]对基于LDA的话题追踪方法进行了总结,其结果见表1。
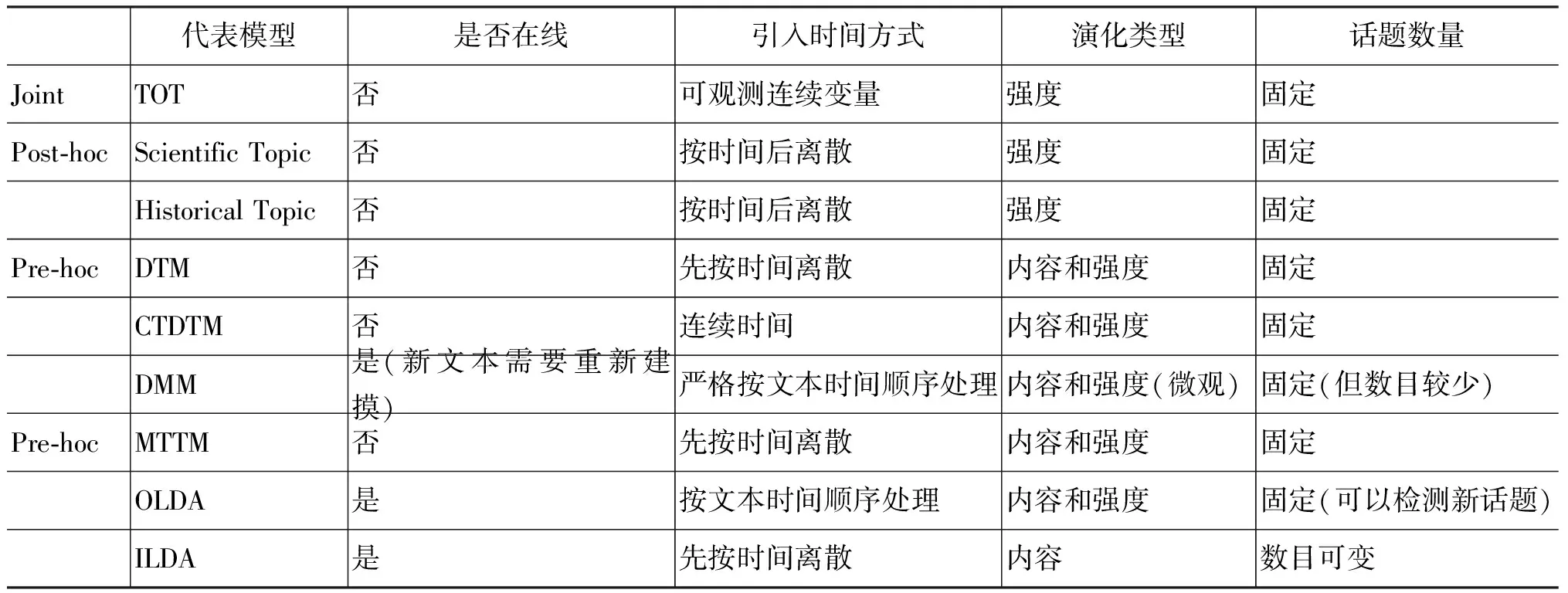
表1 基于LDA话题追踪方法比较
以Topic Over Time(TOT)模型为代表的方法将文本的时间信息作为可观测变量,结合到LDA话题模型中,指导文本集合上话题的分布。TOT模型是将时间看作连续的可观测变量,不依赖于马尔科夫假设。虽然同LDA模型一样,话题内容是不变的,但是由于TOT模型将文本的时间信息考虑在内,所以可以表示话题在不同时刻的分布强度,使得TOT模型生成的话题比原始LDA模型生成的话题在时间分布上更准确,也具有更好的可解释性。
另外一种常用的话题强度分析方法是事后检验分析法(Post-hoc Analysis),该方法是对某一话题发生在某一时间窗口内的后验概率p(z=zi|t=ti)进行计算,用后验概率来表示话题的强度,从而对话题的趋势进行描述。由Griffiths等人[6]提出了一种比较简洁的估算后验概率的方法。该方法先在整个文集上用LDA话题模型获取所有的话题。对于某个话题t的强度由所有属于这个时间窗口的文档的平均值决定,表示为式(1)。
(1)
其中,Dt表示属于时间窗口t的文档的数量。从而显示了话题随时间变化的整体趋势。
另一种方法由Hall等人[7]提出,通过计算话题在以年为单位的离散时间上分布的后验概率来计算话题分布的强度变化如式(2)所示。
(2)

3 基于话题模型的话题发现与话题追踪
3.1 话题聚类
本文采用LDA模型作为话题模型,并沿用LDA中对话题的定义: 一组语义上相关的词及这些词在该话题上的概率分布。具体可以表示为式(3)。
(3)
其中z表示话题,wi表示词空间中的第i个词,v表示词的个数,即词空间的大小,p(wi|z)表示词i在话题z上的概率分布,表示话题与这个词语的相关程度,概率越大,表示该话题与该词语越相关。
由于无法直接对LDA模型的未知参数进行求解,在这里我们使用Gibbs Sampling的方法来近似求解。Gibbs Sampling通过迭代采样来达到逼近真实结果的效果。其关键点在于对当前单词采样概率的求解,如式(4)所示。
(4)

通过Gibbs Sampling方法,可以估计出得到θ,φ的后验值为式(5)。
(5)
在推导参数之前,需要预先将话题的数目K设置好,数值越大则话题越多,话题的颗粒度越小,反之亦然。可以利用模型选择的方法,通过估计概率p(w|K)的似然值[8]来确定话题数目。本文选择了利用模型选择的方法来确定话题的数目。具体到LDA模型,推导可以得式(6)。
(6)
确定话题的个数K,需要计算p(w|K),但是直接计算复杂度过高,所以我们通过估计p(w|z,K)的值来确定话题个数,而这个值可以通过式(3)得到,并且使得这个概率值最大的K,就是最满足模型选择结果的话题个数。
3.2 热点话题的识别
根据LDA话题抽取的结果,每篇文档都由数个不同的话题按照一定比例生成。如果一个文档中有不少于某百分比的词是由话题z生成的,我们就认为该文档是话题z的支持文档。之后,便可以根据公式(7)得到话题的支持率。
(7)

3.3 话题的追踪
LDA模型产生的话题词是通过在整个时间段的文集建模得到的,话题的内容最终通过概率最高的一些话题词来表现出来。在这个基础上,通过对不同时间段分别进行建模,并把不同时间段中话题词的特点考虑进来,从而可以得到话题内容的变化趋势。
本文在传统的只将在不同时间段中建模得到的话题通过匹配串联起来的基础上,将在整个时间段上建模得到的话题信息也考虑进来。传统的只在不同时间段建模的方法,例如,DTM,只能适用于时间颗粒度较大的语料集,这是由模型本身的缺陷所限定的。因为对于时间颗粒度较小的语料集,时间轴上的区段会很多,每一个时间段上话题的偏差积累到最后,会使得最终得到的话题和最开始出发点的话题毫无关系。
本文在计算相邻时间段上话题的距离时采用KL divergence来衡量。KL divergence是非对称的,但在实际中两个文档的距离是相等的,与顺序无关。所以更进一步,我们使用对称的KL divergence来衡量两者的距离。假设时间段t话题z的支持文档d与后一时间段t’话题z’的支持文档d’,在话题空间中的分布分别为θd和θd′,则它们的对称KLdivergence计算公式如式(8)所示。
(8)
在得到了相邻时间段内文档的关联信息之后,相邻时间段的话题便可以通过支持文档的关联程度而得到。具体来讲就是对两个相邻话题z和z′,它们的支持文档的集合分别用D和D′来表示,在D中与D′相关的文档集合表示为Dz′,则z与z′的相关程度表示为式(9)。
(9)

(10)

4 实验结果及分析
4.1 实验语料和参数设置
本文从易车网、搜狐汽车、爱卡汽车和汽车之家四个论坛上收集了2011年1月到2012年12月共40 000个论坛文本作为本文的实验数据,每季度5 000条,平均每条帖子约200字。
本实验利用Gibbs Sampling方法进行参数的推理。实验使用了开源的Gibbs Sampling工具3,模型参数α,β分别设置为50/K和0.01。
对于话题个数K,我们综合考虑了公式(6)所述的模型选择方法,并对生成话题的效果进行人工评判,最终选择在全语料集上设置话题个数为100,在内容演化部分的实验,我们将时间段设为10天,在子语料集上设置话题个数为15。
4.2Baseline方法
在话题识别的结果分析中,我们采用TFIDF方法作为baseline方法(baseline-Identify),挖掘的常用加权技术;在对话题强度趋势的分析中,我们采用斯坦福大学提供的一个开源话题建模工具TMT(TopicModelingToolbox)对实验语料进行实验。使用该工具得到话题强度变化趋势作为baseline方法(baseline-TMT);在对话题内容趋势的分析中,我们采用文献[9]中Chu提出的方法作为baseline方法(baseline-Chu)。
4.3 语料预处理
论坛语料与一般新闻语料的区别在于文本更加短小,语料中也包含着大量重复与相似的数据,本文使用Gurmeet提出的Hammingdistances方法[10]对论坛实验语料进行镜像去重,剔除重复的语料数据来减少“论坛水军”等的影响,移除“虚假”的热点话题因素。

图1 论坛语料话题聚类纯度
4.4 话题聚类实验结果分析
本文采用纯度(purity)来进行聚类结果评估,纯度代表了聚类算法的准确性,纯度越高代表聚类划分越好。相比baseline方法,本文使用两种不同的LDA聚类方法,一是基于全部语料的建模后在时间上进行离散化;另一个是基于局部时间段(季度)的文集建模,可以得到更为精确的话题词。如话题“车祸事故”,表2给出了不同方法的话题词分布。分析可知使用LDA的方法较Baseline相比有更好的话题词,而局部建模LDA能获得详细的信息,更具有时效性。可以发现,LDA方法整体效率较Baseline方法有一定程度的提高,局部建模的LDA方法和全局建模的方法相比纯度略有提高,但是效果不明显。

表2 话题词对比
4.5 热点话题识别实验结果分析
根据前文给出的方法,如果一个文档当中有不少于k%的词是由话题z生成的,则我们认为该文档是话题z的支持文档。这里我们取k=5作为支持文档的阈值,并将支持文档率不低于4%,即支持文档数不低于1 600的话题定义为热点话题。
从表3的结果中可以看出,论坛车友对于汽车的价格、配置、油耗等更为在意,并且在这么多话题中,对于汽车的问题(异响,故障等)非常敏感。
4.6 话题追踪实验结果分析
图2给出了热点话题的强度变化趋势,我们可以发现热点话题的变化趋势会有一个大的峰值,但随着时间的推移,总体强度呈下降趋势。

表3 论坛话题及其支持文档数,其中加粗的为热点话题
图3给出了非热点话题的强度变化趋势,可以看出,非热点话题强度很平均,没有明显的峰值。
数据出现以上变化,究其原因,是因为热点话题往往与时事和政策相关,即政策刚刚出台的时候会有一个大的峰值,但随着时间的推移关于此类话题的文本就渐渐变少,偶尔可能会出现些零星的讨论,但总体强度呈下降趋势。而非热点话题主要是因为并没有相关的政府政策在这一时间段内出台,导致没有大量的新闻报道在短时间内出现,从而导致了这种情况的出现。

图2 热点话题强度变化趋势

图3 非热点话题强度变化趋势
通过对不同的话题进行趋势分析,可以发现它们的强度变化趋势与实际情况吻合的很好,可以在一定程度上达到我们对话题强度追踪的要求。
5 结论及展望
在课题研究的过程中,我们通过实测说明了本文的研究在基于论坛语料的热点话题的识别与追踪问题上具有一定的成果。
在语料处理上,使用Hamming distances方法对论文文本进行镜像去重,使得重复的文本信息不会影响话题聚类,造成虚假的热点话题。使用局部建模的方法提高话题聚类的纯度,得到了较好的效果。
在话题模型方面,现有的话题模型都是基于VSM的,即把话题看作若干词的集合。这与我们理解的话题这个概念还有一定的偏差。如何能够利用论坛元素,把更多的语义信息融合到话题模型之中将是未来研究的一个方向。
[1] T L Griffiths, M Steyvers. Finding scientific topics[C]//Proceedings of the Natl Acad Sci USA, 2004,101(1): 5228-5235.
[2] Thomas Minka, John Lafferty. Expectation-Propagation for the Generative Aspect Model[J]. Uncertainty in Artificial Intelligence (UAI), 2002.
[3] S Mark, G Tom. Probabilistic Topic Models. In: In T Landauer, D McNamara, S Dennis, et al. eds[J]. Latent Semantic Analysis: A Road to Meaning. 2006.
[4] DM Blei, A Y Ng, M I Jordan. Latent Dirichlet Allocation[J]. The Journal of Machine Learning Research, 2003, 3: 993-1022.
[5] D M Blei, J D Lafferty. Dynamic Topic Model[C]//Proceedings of the International Conference on Machine Learning, 2006: 113-120.
[6] T I Griffiths, M Steyvers. Finding scientific topics[C]//Proceedings of the National Academy of Sciences, 2004,5: 5228-5235.
[7] D Hall, D Jurafsky, C D Manning. Studying the History of Ideas Using Topic Models[C]//Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, 2008:363-371.
[8] D M Blei, J D Lafferty. Dynamic topic model[C]//Proceedings of the 23rd International Conference on Machine Learning. Pittsburgh, Pennsylvania. 2006: 113-120.
[9] 楚克明,李芳. 基于LDA的新闻话题的演化[C]//CCIR2009, 2009.
[10] GS Manku, A Jain, A Das Sarma. Detecting Near-Duplicates for Web Crawling [C]//Proceedings of the conference on World Wide Web, 2007.
[11] Voorhees E, Harman D. Overview of the Eighth Text Retrieval Conference (TREC-8)[M]. NIST Special Publication, The Eighth Text Retrieval Conference (TREC 8),1999: 500-246.
[12] Fiscus J, Doddington G, Garofolo J, et al. NIST’s 1998 Topic Detection and Tracking Evaluation (TDT)[M]. Fifth European Conf. On Speech Comm. and Tech., 1999, 4: 247-250.
[13] Fiscus J, Doddington G. Results of the 1999 Topic Detection and Tracking Evaluation in Mandarin and English[C]//Proceedings of the 6th International Conference on Spoken Language Processing, 2000.
[14] TDT 2000 Evaluation Website, (Includes presentations and papers) http://www.nist.gov/TDT/tdt2000
[15] S Deerwester, S Dumais, T Landauer, et al. Indexing by Latent Semantic Analysis[J]. Journal of the American Society of Information Science, 1990,41(6):391-407.
[16] Thomas Hofmann. Probabilistic latent semantic indexing[C]//Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Berkeley, CA, USA, 1999: 50-57.
[17] L Alsumait,D Barbara,C Domeniconi. Online LDA: Adaptive topic models of mining text streams with applications to topic detection and tracking[C]//Proceeding of the 8th IEEE International Conference on Data Mining. Washington, DC,USA: IEEE Computer Society, 2008: 312.
[18] Charles L Wayne.Multilingual Topic Detection and Tracking: Successful Research Enabled by Corpora and Evaluation [C]//Proceedings of the Language Resources and Evaluation Conference (LREC), 2000: 1487-1494.
[19] The National Institute of Standards and Technology (NIST). The 2002 Topic Detection and Tracking (TDT2002)Task Definition and Evaluation
[20] 单斌,李芳. 基于LDA话题演化研究方法综述[J].中文信息学报, 2010,24(6):43-49.
[21] Ali Daud, Juanzi Li, Lizhu Zhou, et al. A Generalized Topic Modeling Approach for Maven Search[J]. APWeb/WAIM 2009, LNCS 2009: 138-149.
LDA Based Hot Topic Detection and Tracking for the Forum
XU Jiajun, YANG Yang, YAO Tianfang, FU Zhongyang
(UDS-SJTU Joint Research Lab for Language Technology, Department of Computer Science and Engineering, Shanghai 200240, China)
As the information on the Internet blooming, it becomes a valuable question that how to analysis and extract the useful information from the large-scale data. As a kind of online corpora, the forum corpora and microblog corpora bringnew difficulties with the complex structure and content in very brief text. This paper proposes a method to use LDA to model corpus and extract topics from it. Then we find support documents and estimate the topic strength, which is cast on the timeline to reflect the topic tendency. Finally, we re-model the copus within each period, reflecting the variation of each topic in contrast to the overall topics. The experimental result has shown that the above approach is reasonable and effective.
forum; topic model; tendency analysis; topic tracking; LDA

徐佳俊(1990—),硕士,主要研究领域为自然语言处理、机器学习等。E⁃mail:pily900714@gmail.com杨飏(1988—),硕士,主要研究领域为自然语言处理、文本检索等。E⁃mail:yangyang339113@gmail.com姚天昉(1957—),博士,副教授,主要研究领域为计算语言学和语言技术。E⁃mail:yao⁃tf@cs.sjtu.edu.cn
1003-0077(2016)01-0043-07
2013-09-22 定稿日期: 2014-05-21
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
今日农业(2020年13期)2020-08-24
动漫界·幼教365(大班)(2018年6期)2018-05-14
意林(2017年8期)2017-05-02
新东方英语(2016年11期)2016-11-11
网络空间安全(2016年3期)2016-06-15
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中国药业(2014年21期)2014-05-26
中国有色金属(2014年23期)2014-03-13
