
基于同义词词林信息特征的语义角色自动标注
2016-05-04 00:59李国臣王瑞波李济洪
中文信息学报 2016年1期
李国臣,吕 雷,王瑞波,李济洪,李 茹
(1. 太原工业学院 计算机工程系,山西 太原 030008;2. 山西大学 计算机与信息技术学院,山西 太原 030006;3. 山西大学 计算中心,山西 太原 030006)
基于同义词词林信息特征的语义角色自动标注
李国臣1,2,吕 雷2,王瑞波3,李济洪3,李 茹2
(1. 太原工业学院 计算机工程系,山西 太原 030008;2. 山西大学 计算机与信息技术学院,山西 太原 030006;3. 山西大学 计算中心,山西 太原 030006)
该文使用同义词词林语义资源库,以词林中编码信息为基础构建新的特征,使用条件随机场模型,研究了汉语框架语义角色的自动标注。该文在先前的基于词、词性、位置、目标词特征的基础上,在模型中加入不同的词林信息特征,以山西大学的汉语框架语义知识库为实验语料,研究了各词林信息特征分别对语义角色边界识别与分类的影响。实验结果表明,词林信息特征可以显著提高语义角色标注的性能,并且主要作用在语义角色分类上。
语义角色标注;同义词词林;条件随机场;正交表
1 引言
自20世纪70年代末以来,中文信息处理进入了快速发展时期,大致可分为两个阶段:分词和词性标注以及句法语义分析阶段。目前,中文信息处理的主要瓶颈是词义、句义的表示和语义理解问题。
语义角色标注(Semantic Role Labeling,SRL)是浅层语义分析的一种实现方式,总结近几年国内外基于统计方法的语义角色标注研究的内容,主要可以归结为特征提取及特征选择的研究。在英文语义角色标注中,Gildea等人[1]在语义角色标注中使用了七个基本特征:谓词、句法类型、次范畴框架、路径、位置、语态和中心词;Pradhan等人[2]在基本特征的基础上引入了中心词、词性、谓词类别、部分路径等12种新特征。在之后的研究中,虽然Xue等人[3]对组合特征进行了尝试,但这些特征也都是在基本特征集合上面进行的。
在中文语义角色标注实验中,大多效仿英文的做法,刘挺等人在文献[4]中用最大熵分类器对句子中谓词的语义角色同时进行识别和分类;李济洪[5]的正交表选特征的方法在语义角色标注技术得到了有效地应用;在文献[6-7]中,刘怀军,李世奇等人针对中文的特点,在英文语义角色标注特征的基础上,提出了一些更有效的新特征和组合特征;而Sun等人在文献[8]中也将英文中短语结构句法分析的特征移植到中文语义角色标注上,然后利用在宾州中文树库上训练的Collins句法分析器进行句法分析,并利用SVM分类器在手工标注的小规模语料上进行了实验。这些工作基本上都是用不同的机器学习方法,针对基本特征及其组合对语义角色标注进行了研究。
从以上文献可以发现,目前在语义角色标注任务上所使用的特征中,谓词、中心词以及谓词的前一个词、后一个词在标注任务中起着重要的作用,但这些特征在使用的过程中,存在严重的词特征稀疏问题[9-10]。缓解词特征的稀疏问题应有助于提高标注器的性能。
《同义词词林》是一部优秀的汉语词义分类词典,它通过对词进行编码,许多同义词、近义词将会被编为一类,在语义角色标注中引入《同义词词林》语义资源,提取相应特征,将改善训练集和测试集中词特征的稀疏性,使语义角色标注任务有可能提高。
《同义词词林》按照树状的层次结构把所有收录的词条组织到一起,把词汇分成大、中、小三类,大类有12个,中类有97个,小类有1 400个。每个小类里都有很多的词,这些词有根据词义的远近和相关性分成了若干个词群(段落)。每个段落中的词语又进一步分成了若干个行,同一行的词语要么词义相同(有的词义十分接近),要么词义有很强的相关性。小类中的段落可以看作第四级的分类,段落中的行可以看作第五级的分类。这样,词典《同义词词林》就具备了五层结构。例如,
Ba01A02= 物质 质 素
Cb02A01= 东南西北 四方
Ba01A03@ 万物
Cb06E09@民间
Ba01B08# 固体 液体 气体 流体 半流体
Ba01B10# 导体 半导体 超导体
具体的标记参见表1。
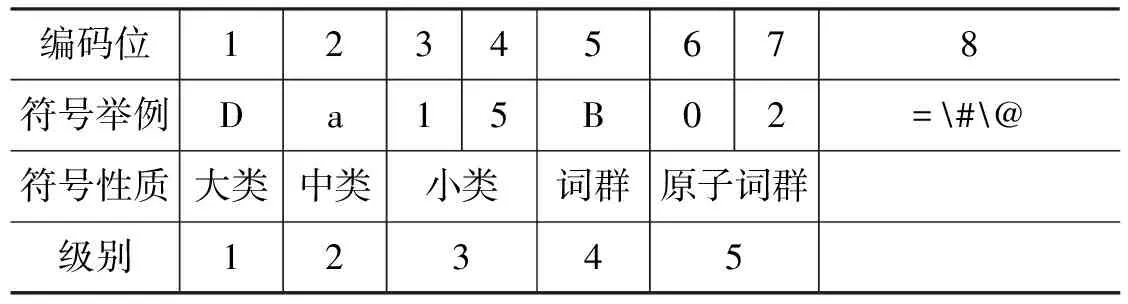
表1 词语编码表
表1中的编码位是按照从左到右的顺序排列。第八位的标记有三种,分别是“=”、“#”、“@”,“=”代表“相等”、“同义”。末尾的“#”代表“不等”、“同类”,属于相关词语。末尾的“@”代表“自我封闭”、“独立”,它在词典中既没有同义词,也没有相关词。本文将以词林对词的编码信息,提取不同特征,以提高标注的性能。
目前,国内语义角色标注的研究中,同义词词林的语义信息的研究还为数不多,本文在李济洪[10]所选特征基础上,融入同义词词林信息,使用条件随机场模型建立汉语框架语义角色标注模型,并使用统计正交表的特征模板优选方法[5]进行语义角色标注的研究。
本文结构如下:第二节给出汉语框架语义角色标注的任务描述;第三节说明相应的特征提取及选择方法;第四节给出实验结果及分析;最后对全文进行总结,并给出下一步的研究方向。
2 融合同义词词林信息的语义角色标注任务
考虑到汉语框架CFN的建设仍然属于初始阶段,可用的语料规模还比较小。为此,本文的CFN语义角色(框架元素)标注的任务定为:对给定的一个汉语句子,在已知目标词及其所属框架的前提下,自动识别语义角色的边界,标出该目标词所支配的语义角色(框架元素,包括核心框架元素、非核心框架元素及通用语义角色)。
通过BIO标注策略,将语义角色标注看作是以词为基本标注单位的序列标注问题。其标记集合可表示为式(1)。

(1)
这里FESet为给定目标词的所属框架的框架元素。本文可以使用条件随机场(Conditional Random Fields,CRFs)模型对汉语框架语义角色标注进行处理。
条件随机场(CRFs)模型是由Lafferty[11]在2001年提出的一种典型的判别式模型。它在观测序列的基础上对目标序列进行建模,重点解决序列化标注的问题。条件随机场模型既具有判别式模型的优点,又具有产生式模型那样要考虑到上下文标记间的转移概率,以序列化形式进行全局参数优化和解码的特点,解决了其他判别式模型(如最大熵马尔科夫模型)难以避免的标记偏置问题。
不同于传统的分类问题,序列标注任务有着独特的特点。本文采用CRF模型,主要考虑到以下特点。
1) CRF模型是解决序列标注和分割问题的,而语义角色标注任务通过BIO策略可转化为序列标注问题。
2) 序列标注模型中,一个序列中的每个标注单位有着较强的相关性,而序列和序列之间是独立的。很多研究者在进行序列标注时,假设序列中的每个元素之间是独立同分布的,并将序列标注任务看作是对每个序列中每个元素进行单点分类任务。在此基础上,使用最大熵或者支撑向量机模型进行训练。显然,这样的假设不太符合实际。而条件随机场模型便考虑到了元素之间的相关性,并将一个序列看作是一个整体。
3) 正是由于序列之间各个元素具有相关性,开窗口技术才被广泛用于序列标注问题,而相应窗口大小的选择也是应当考虑的。
本文考虑到汉语框架语义角色标注模型的构造及其特点满足以上特点,故使用CRF模型,以期达到较好的标注结果。
3 特征提取与特征选择
事实上,模型特征是影响机器学习性能的重要因素。构建良好的特征,以及特征信息的有效利用是提高机器学习性能的关键。
3.1 特征提取
本文假设语料库中的汉语句子已经经过了正确的分词、词性标注,并且已经识别出正确的目标词和相应的框架信息。再以哈尔滨工业大学信息检索中心的《同义词词林》为依托,自动为每个句子的每个词语标上同义词词林编码,根据编码的层级提取出五种词林信息。从给定的这些信息中,本文可以总结出如表2所示的几种特征。

表2 词层面特征与词林信息特征描述
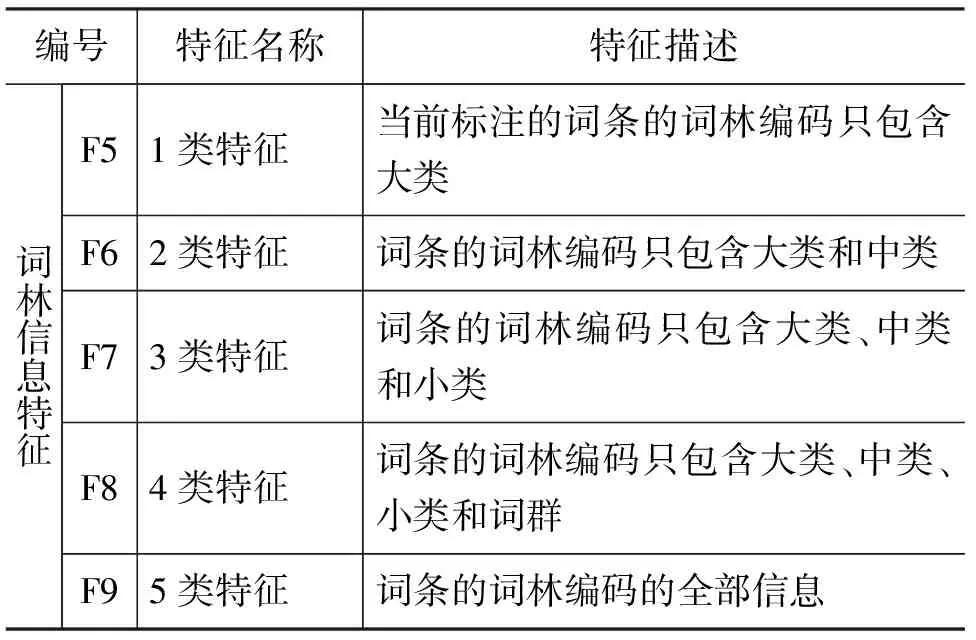
续表
根据目前语料库的状况,候选特征除了以上九个特征以外,还有这些特征的二元组合、三元组合特征, 这些特征的两两组合特征。本文将这些特征的窗口大小限定在三以内。可选窗口大小的表示与文献[10]中表1相同。
3.2 特征选择
本文以文献[10]中基于词特征的语义角色标注实验为Baseline系统,将五种词林信息特征(F5,F6,F7,F8,F9)逐一替换Baseline系统中的词特征进行试验,得到的系统记为CL1、CL2、CL3、CL4、CL5。
考虑到特征的组合数非常庞大,以Baseline系统为例,所有特征的不同窗口大小组合可以构成410×2种特征模板,在所有模板上进行训练、测试,显然不现实。因此,文献[10]中提出使用正交表L32(49×24)来进行特征选择。具体方法可参见文献[10]中的描述。
本文在文献[10]的Baseline系统基础上,为了进一步的验证词林信息特征对语义角色标注结果的影响,采用李济洪在文献[11]中提出基于分批正交表特征模板选优方案,对系统Baseline+CL(Baseline所选特征与所有词林信息的组合)进行了特征选择。第二个正交表采用L54(21×325)。
该方案是在Baseline系统标注结果最好的模板的基础上,再确定下一个正交表中的特征的窗口。即后部分实验需要在前部分32个实验选出最优模板的基础上,再确定L54(21×325)表中的水平所对应的窗口。实验方案能确保新选模板的性能不低于Baseline系统所选出的最优模板。详见文献[5]中描述。实验所设系统如表3所示。
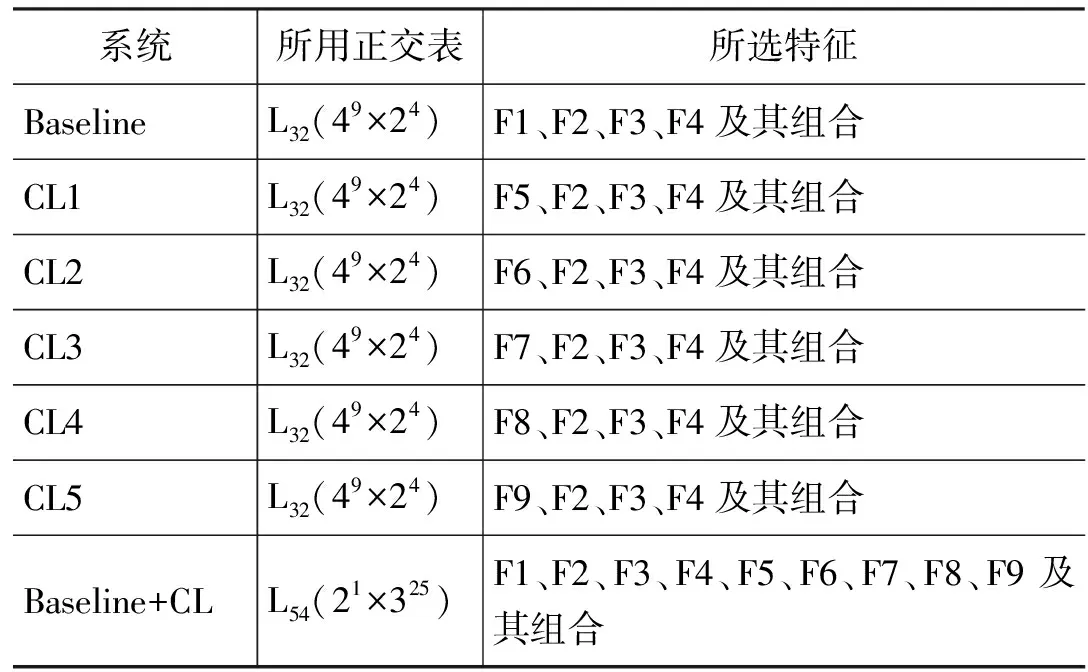
表3 实验所设系统
4 实验结果及分析
4.1 语料来源
为了能够得到与文献[10]中可以对比的实验结果,本文采用与文献[10]相同的语料,该语料包含25个框架,这25个框架来自于“认知”领域和其他领域,包含6 692条正确标注的句子。由于目前语料规模不大,本文采用三组2-fold 交叉验证进行实验,即任取两份作为训练集,其他两份作为测试集,这样共可以做三组2-fold交叉验证。最终的评价指标以三组交叉验证实验的F-值的平均值来评价标注模型的性能。本文对于三组2-fold交叉验证中的词信息进行了统计,统计结果如表4所示。
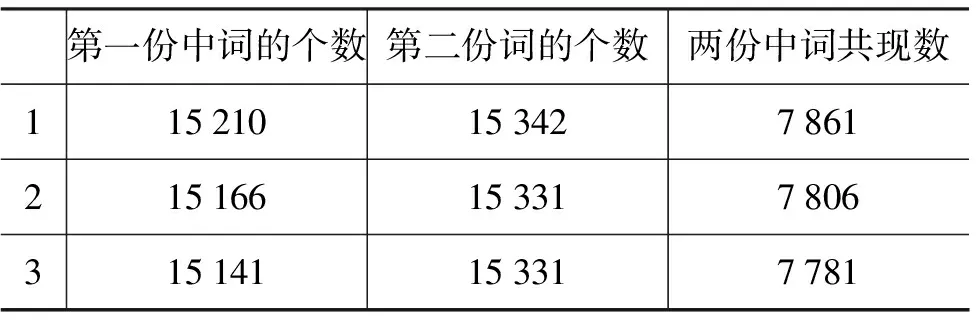
表4 语料中词信息统计结果
从表4我们可以发现,在语义角色标注实验中,测试集中有一半左右的词信息没有出现在训练集中,相应的词特征稀疏问题严重。本文使用同义词词林信息特征后,经统计,词林信息特征的特征数得到有效的缩减,如表5所示。

表5 特征数统计结果
词林信息特征的引入为语料中词义相近的词搭建了桥梁,使训练语料与测试语料中共现特征数量大幅度的增多。
4.2 评价方法
4.2.1 评价指标
正确识别一个语义角色块指的是语义角色块的边界正确,并且语义角色块的类型也识别正确。为此,本文使用准确率(Precision),召回率(Recall)和F-值(F-Score)来评价汉语框架语义角色标注模型的性能。
假设模型标注出的语义角色块数为Cp,其中正确的块(左右边界正确,且语义角色类型正确)数目为Cc,测试集中的语义角色块的数目为Co,那么,准确率如式(2)所示。
(2)
召回率如式(3)所示。
(3)
F值如式(4)所示。
(4)
最终以三组2-fold交叉验证的平均F-值(记为mF)来评价模型的性能。
4.2.2 显著性检验
因为有随机误差因素存在,传统的直接用F-值的平均值来评判系统优劣的方法是不恰当的。应当构造合理的统计检验来实施正确推断。在语义角色标注的相关文献中,常常需要分析新加入某个特征对系统性能的影响是否显著,每类特征重要性的分析一般是在基线模型B的基础上,加入某类特征X得到模型A进行实验,然后对模型A和B进行t检验,来评判特征X的重要程度(是否显著)。在给定的一组交叉验证的实验下,如果将评价指标F-值近似看作服从正态分布,相应的检验统计量的构造主要是其方差的估计。为此,本文利用文献[12]中给出的3×2交叉验证下方差的估计以及t-检验方法。下面简要叙述显著性检验的方法。
假设系统A,系统B(Baseline系统)在三组2-fold交叉验证下的平均F-值为mFA,mFB,记式(5)。
(5)
这个问题的正确的假设检验提法为:
基于分批正交表实验时,由于实验的配置特点确保模型A的结果不会低于模型B的结果,因此检验应为单边检验:
原假设H0: CV3×2≥0
备选假设H1:CV3×2<0
其他情况下,检验应为双边检验:
原假设H0: CV3×2=0
备选假设H1:CV3×2≠0
两种检验均使用式(6)。
(6)
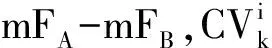
4.3 语义角色标注边界识别与角色分类同时做的实验结果
从表6中,本文可以得到如下几点结论。
(1) 从表6中可以看出,在Baseline系统的基础上加上CL信息,结果提高了0.69%,P-值结果为0.046,在α=0.05下是显著的,证明词林信息特征

表6 各系统与Baseline结果的对比
注:Baseline系统得到的实验结果(58.86%)与文献[10]中不同,是因为本文实验包含通用语义角色,文献[10]中的实验不包含通用语义角色。
对语义角色标注结果的提高有作用。
(2) 从五个加入不同的词林信息特征系统的实验结果看出,CL3和CL4系统上比Baseline系统有显著提高,说明词林信息特征编码选在第三或第四类较为合理。
再分别看25个框架下的详细实验结果(表7)。
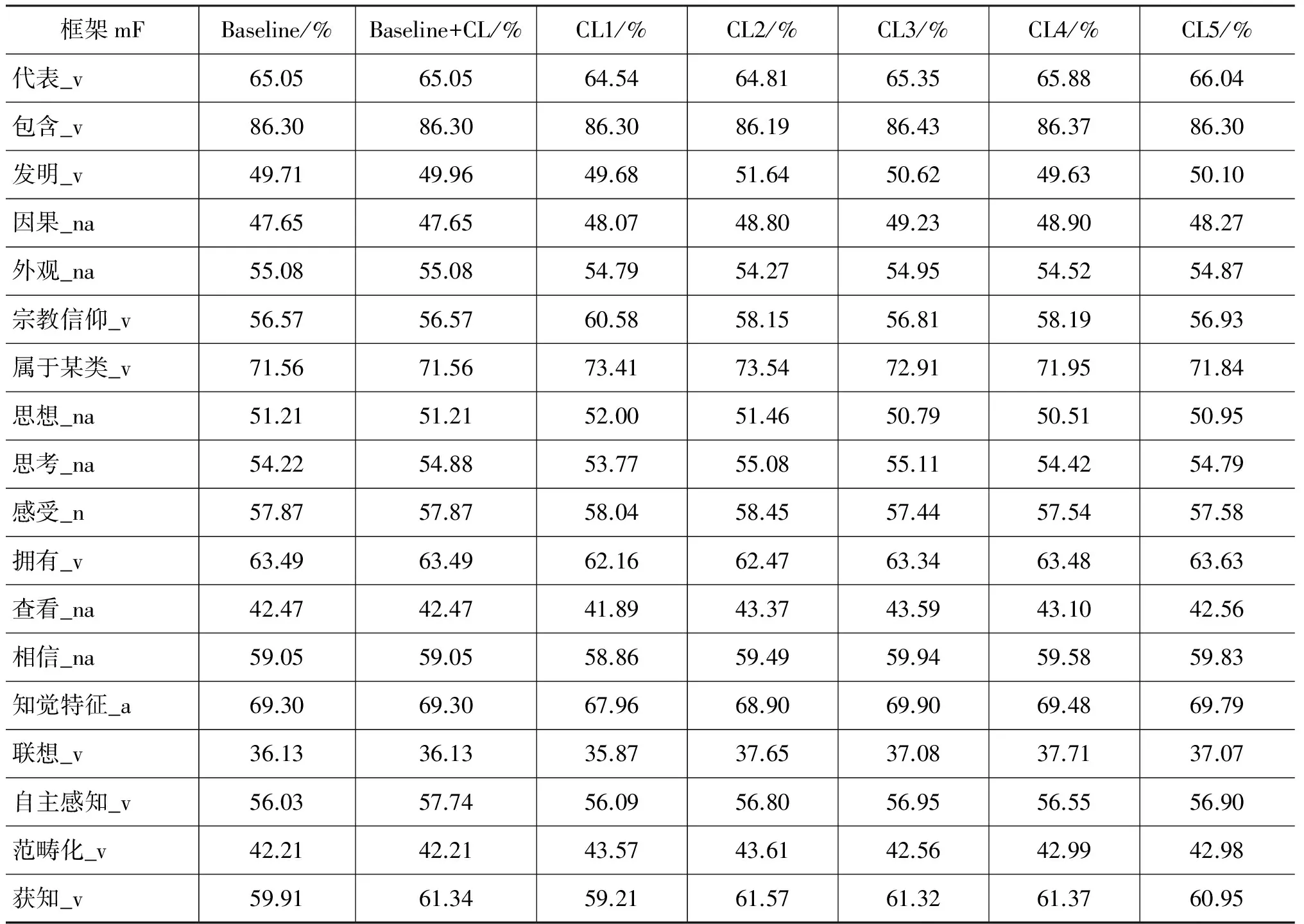
表7 25个框架下的所有系统的实验结果

续表
表7中最后一行的总计结果是在25个框架的测试集上的微平均的标注准确率、召回率和F-值,而不是25个框架的宏平均结果。从表7中,本文可以得到如下几点结论。
(1) 在25个框架上总体的标注F-值在Baseline+CL系统下可以达到59.55%,可以看出来,虽然总结果有所提高,但是从结果中可以发现,只有八个框架的F-值有提升,并不是所有的结果都好于Baseline系统。初步分析,这可能主要是因为语料相对较少的原因。
(2) 从CL1到CL5的结果看,25个框架中的11个框架在CL3时最大,7个在CL2最大,3个在CL4最大,4个在CL5最大,1个在CL1最大,说明词林信息特征编码选在第三类较为合理。
4.4 给定边界下角色分类的实验结果
从前面的实验可以发现,加入词林信息特征对语义角色标注性能的提高是显著的,而语义角色标注任务可以分为边界识别和角色分类。下面将进一步深入分析词林信息特征分别对边界识别和角色分类的影响。
在本节中,本文将给出给定边界的情况下做语义角色分类的实验结果,实验结果如表8所示。
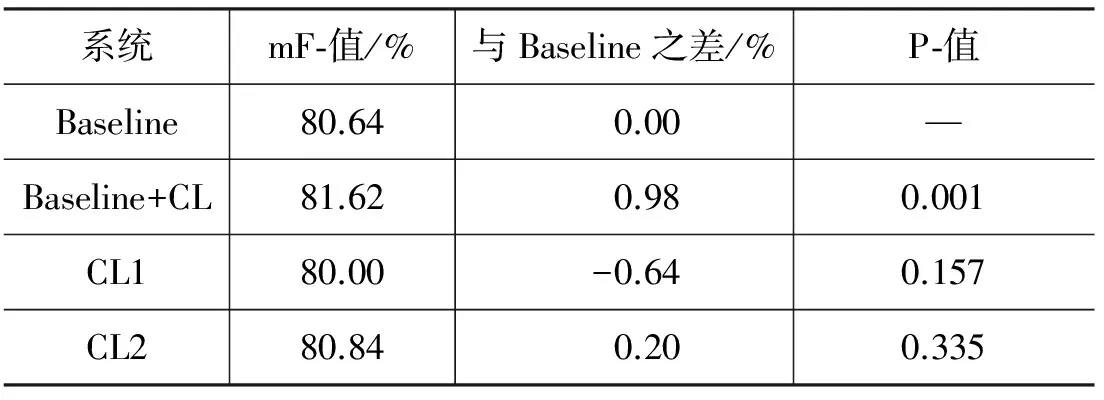
表8 给定边界的情况下做语义角色分类的实验结果
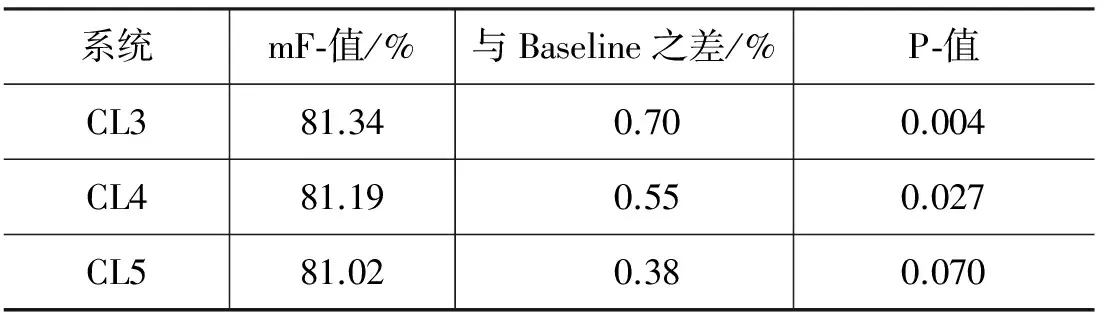
续表
表8中给出了Baseline系统以及词林信息特征替换词特征所得到的给定边界下角色分类的平均F-值。从表8中可以得到以下结论。
(1) 词林信息特征对角色分类有显著作用。
(2) CL3最高,且与Baseline系统有显著差异,说明词林信息特征编码选在第三类较为合理。
4.5 边界识别实验结果
对于汉语框架语义角色的边界识别,本文将25个框架的所有训练集进行统一训练,并在测试集上进行测试。表9中给出了六组实验的平均指标。
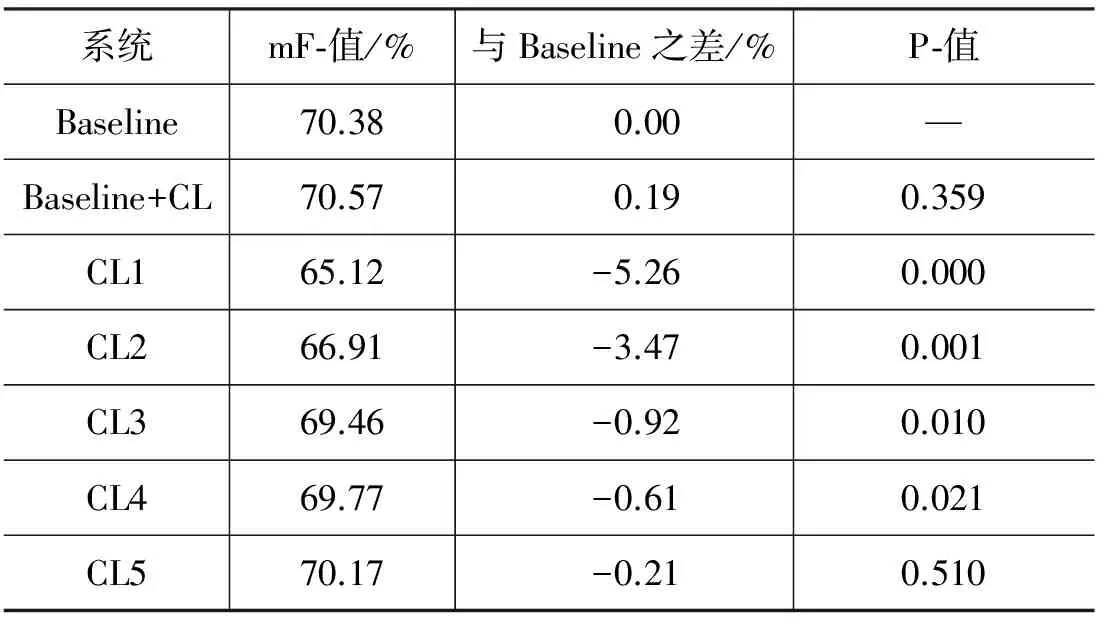
表9 边界识别的实验结果
表9中统计的是Baseline系统以及词林信息特征替换词特征所得的在25个框架的测试集上的微平均的标注F-值。从表9中可以得到如下几点结论。
(1) 从表中的结果可以看出,词林信息特征替换词特征所得到的边界识别结果并不理想,说明词林信息特征在边界识别中的作用没有词特征的作用大。
(2) 在Baseline+CL系统中,边界识别的性能比Baseline系统提高了0.19%,但并不显著,说明词林信息特征在边界识别中的作用不大。
(3) 通过表6、表8、表9,可以得出,词林信息特征的加入只对语义角色分类提高有显著作用,对于边界识别的作用不大。
从以上实验结果及分析中,可以看出,Baseline+CL系统的标注结果最好,但CL包含了词林信息特征的所有的各类编码,特征的训练测试耗时。从CL1到CL5的实验结果中我们发现,三类词林信息特征的结果较好,因此,本文以分批正交表构建Baseline+CL3系统进行实验,实验结果如表10所示。
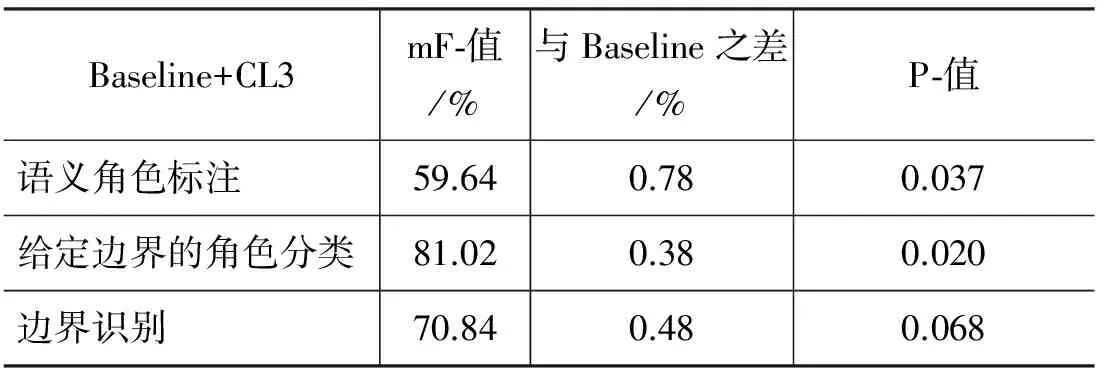
表10 Baseline+CL3系统实验结果
表10中可以看到,在显著水平0.05下,数据显示与上文中分析结果一致,这就是:
(1) Baseline+CL3系统比Baseline系统的标注结果有显著提高。
(2) 在给定边界下的角色分类也有显著提高。因此,词林信息特征的加入作用主要在角色分类。
(3) Baseline+CL3系统的边界识别与Baseline系统没有显著差异。
5 结论与展望
本文针对词林信息特征,用交叉验证的方法对其在语义角色标注中的作用做了深入的研究,并将词林信息特征加入到Baseline系统中,与Baseline系统的标注结果做了对比,研究表明,同义词词林信息一定程度上提高了语义角色标注的结果,但是只在语义角色分类上作用显著,而在边界识别中的效果并不明显,从而证明,词林信息特征对语义角色标注系统性能的提高有着一定的作用。
下一步,本文将对同义词词林信息做进一步研究学习,拟将同义词词林信息加入到句法分析中,以期得到更好的标注结果。
致谢:本文采用了山西大学汉语框架网络知识库的语料资源,所使用的《同义词词林》是由哈尔滨工业大学信息检索中心提供的,并且本文使用了山西省网络科技环境高性能计算平台,在此表示衷心的感谢!
[1] Gildea D, Jurafsky D. Automatic Labeling of Semantic Roles[J]. Computational Linguistics. 2002,28(3): 245-288.
[2] Pradhan S, Hacioglu K, Krugler V, et al. Support vector learning for semantic argument classification[J]. Machine Learning Journal, 2005,60(3):11-39.
[3] Xue N, Palmer M. Calibrating features for semantic role labeling[C]//Proceedings of the EMNLP-2004, 2004: 88-94.
[4] Liu T, Che W X, Li S. Semantic role labeling with maximum entropy classifier[J]. Journal of Software, 2007,18(3):565-573.
[5] 李济洪. 汉语框架语义角色的自动标注技术研究[D]. 山西大学博士学位论文, 2010.
[6] 刘怀军, 车万翔, 刘挺. 中文语义角色标注的特征工程[J]. 中文信息学报, 2007,21(1):75-80.
[7] 李世奇, 赵铁军, 李晗静, 等. 基于特征组合的中文语义角色标注[J]. 软件学报, 2011,22 (2):222-232.
[8] Sun H, Jurafsky D. Shallow semantic parsing of Chinese[C]//Proceedings of the NAACL 2004, Boston, USA, 2004: 249-256.
[9] 刘挺, 车万翔, 李生. 基于最大熵分类器的语义角色标注[J].软件学报,2007,18(3):565-573.
[10] 李济洪, 王瑞波, 王蔚林, 等. 汉语框架语义角色的自动标注[J]. Journal of Software, 2010,21(4):597-611.
[11] Lafferty J, McCallum A, Pereira F. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the ICML-01, 2001:282-289.
[12] Wang Y, Wang R B, Jia H C, et al. Blocked 3×2 cross-validated t-test for comparing supervised classification learning algorithms[C]//Proceedings of the Submitted to Neural Computation. 2013.
Semantic Role Labeling Based on TongYiCi CiLin Derived Features
LI Guochen1,2,LV Lei2,WANG Ruibo3,LI Jihong3,LI Ru2
(1. Department of Computer Engineering, Taiyuan Institute of Technology, Taiyuan, Shanxi 030008,China; 2. School of Computer and Information Technology, Shanxi University, Taiyuan, Shanxi 030006, China; 3. Computer Center, Shanxi University, Taiyuan, Shanxi 030006, China)
This paper presents an approach to label the semantic roles automatically by using a lexical resource named Tongyici Cilin, in which a CRFs model is constructed by a series of new features derived from the encoded information of Cilin. Compared with the features of word, part-of-speech and word positions, the proposed method investigates the Cilin features on the corpus of Chinese FrameNet (CFN), developed by Shanxi University to describe semantic knowledge. Experimental results show a significant improvement in the performance after adding the features of Cilin information.
semantic role labeling; TongYiCi CiLin; conditional random fields; orthogonal array

李国臣(1963—),教授,主要研究领域为中文信息处理。E⁃mail:lgc1017@163.com吕雷(1988—),硕士,主要研究领域为中文信息处理。E⁃mail:lvlei@sxu.edu.cn王瑞波(1985—),博士,主要研究领域为中文信息处理。E⁃mail:wangruibo@sxu.edu.cn
1003-0077(2016)01-0101-07
2014-01-05 定稿日期: 2014-04-20
国家语委“十二五”科研规划项目(YB125-19);国家自然科学基金(61373082);国家自然科学基金(60873128,60970053);山西省回国留学人员科研项目(2013-015),国家863高技术研究发展计划(2006AA01Z142)
TP391
A
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2021年1期)2021-03-29
开放教育研究(2020年2期)2020-03-31
当代陕西(2019年10期)2019-06-03
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
