
异源语料融合研究
2016-05-04 02:54:41吕学强仵永栩
中文信息学报 2016年5期
吕学强,仵永栩,,周 强,刘 殷,
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;2. 清华信息科学与技术国家实验室(筹),清华大学信息技术研究院语音与语言技术中心, 北京 100084)
异源语料融合研究
吕学强1,仵永栩1,2,周 强2,刘 殷1,2
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;
2. 清华信息科学与技术国家实验室(筹),清华大学信息技术研究院语音与语言技术中心, 北京 100084)
语料资源与自然语言处理领域的各项研究息息相关,具有很大的应用价值。由于不同的研究机构对于语料标注的规则和标记的类型不尽相同,使得不同的语料库很难组合为一个更大的语料库来进行使用。针对该问题,该文从不同标注库及词类映射层面考虑,对其产生的词性歧义问题进行了研究,提出了一种将异源语料融合到一种体系下的方法,对词类信息进行映射和消歧,并进行了实验验证,融合后的词性信息准确率可达87%,实验结果表明该方法具有一定的有效性和可扩展性。
语料建设;语料融合;词类映射;词性消歧;
1 引言
自然语言处理领域的分析技术可以分为两个方面,一个是浅层分析,如词法分析;另一个是深层分析,如句法分析。目前针对词法分析的语料库已有很多高质量的、大规模的语料库存在,在基于语料库语言学的研究方面,已发挥了比较好的效用。而针对一个汉语句子进行深层次的、全局的分析与处理的语料库还很少,且标准不统一、规模不大,这也制约了句法分析研究应用的发展。
由于汉语句子不像英语语句那样有天然的空格分割,需要对汉语句子进行词法层面的分析,对其进行词语切分和词性标注。对于同一个自然语言处理任务,往往存在多个不同风格的人工标注语料库[1]。不同风格的标注库在资源层面存在标注不一致的问题,在语料标注中没有一个统一的标准,不能保证在词性标注以及人工标注的一致性。在构建大规模的汉语树库的过程中,需要有比较大规模的已分词和标注完善的基础语料库,再对这些基础语料库进行自动分析和人工标注,最终形成汉语树库。由于现有的语料库的规模并不是很大,而且不同研究机构对于词性的标注规范不同,不能直接组合为一个大规模基础语料库。这也限制了语料的多领域适应性,限制了语料库发展的规模,阻碍了基于语料库语言学的发展。因此,需要采用一定的方式,将语料的标注标准进行统一化,使得异源的语料库可以融合起来利用,发挥多语料综合利用的效用。
在语料融合方面,国内也已有相关研究,Meng 等[2]提出了一种异种语料的自动融合策略。将源语料的分词和词性标注标准进行转化,使其与目标语料一致,再将转化后的语料与目标语料融合,训练一个新词法分析器,利用这个新的词法分析器进行解码。Jiang 等[3]实现了一种转换分类器,以原标注信息作为指导、目标标注作为学习目标来自动地构建一个有噪声的平行标注语料,并用此分类器处理另一个语料库。但是以上方法在测试集大于训练集的情况下,在转化过程中会因训练数据限制而出现分类错误。
针对以上方法的不完备性以及异源语料标注信息不一致问题,本文提出了一种异种语料自动融合方法,将不同体系的语料融合到一个体系下,以此来扩展语料库的规模,统一标注标准。经过多语料的融合,扩充了语料资源建设过程中的语料规模,扩大汉语树库建设过程中用到的基础语料库规模,提高后续基于语料库语言学的研究分析的准确性。本方法的思想是: ①手工建立一套映射标准,将不同来源、不同领域的语料的词性标记进行映射,使其与目标语料一致; ②将转化后的语料的标记进行错误纠正。在最大程度地保留原词性信息的基础上,将不同的标记进行归一化处理; ③将词性标记信息结果还原到原语料中,生成融合后的语料。
针对上述问题,将属于同一个类别、标注不同的标记建立一个映射表,再将同词类的词性标记映射到同一个标准下,并对其映射结果进行置信度评定,确定属于同一个类别、标记不同的词语的预测标记。具有多词性标记的词语,要利用上下文信息确定该词语在句子中的词性类别,将推测结果属于不同类别的概率值进行拟合,选取与当前上下文最相关的词性标记作为初步的预测标记,然后对预测标记进行置信度评定,确定该词的最终预测标记结果,最后根据映射规则,将结果映射到同一个标准下。
本文在第二部分提出了语料自动融合的方法;第三部分是实验结果与分析,详细阐述了语料融合过程中所做的工作以及对融合后的效果进行评定;第四部分是总结与展望。
2 语料融合方法
2.1 语料体系
将需要融合的语料称为源体系,融合生成的语料称为目标体系[2]。实验中采用的语料体系包括: TCT体系、PKU体系和XD973体系。其中,TCT语料体系是从大规模的经过基本信息标注的汉语平衡语料库中提取出100万汉字规模的文本为语料,经过自动句法分析和人工校对,形成高质量的汉语句法树库语料;PKU语料是北京大学对人民日报语料进行词语切分和词性标注形成的语料体系;XD973语料是山西大学按照其制定的汉语文本语料库分词、词性标注加工规范进行加工形成的语料体系。在语料融合之前,需要将源体系的标注进行归一化处理,形成归一化词类映射表UNP,UNP是根据不同词类体系对应表: TCT、PKU、YWGB、XD等,在尽可能保留功能类词性的基础上,共保留了58个归一化词类标记,UNP中的部分标记如表1所示。
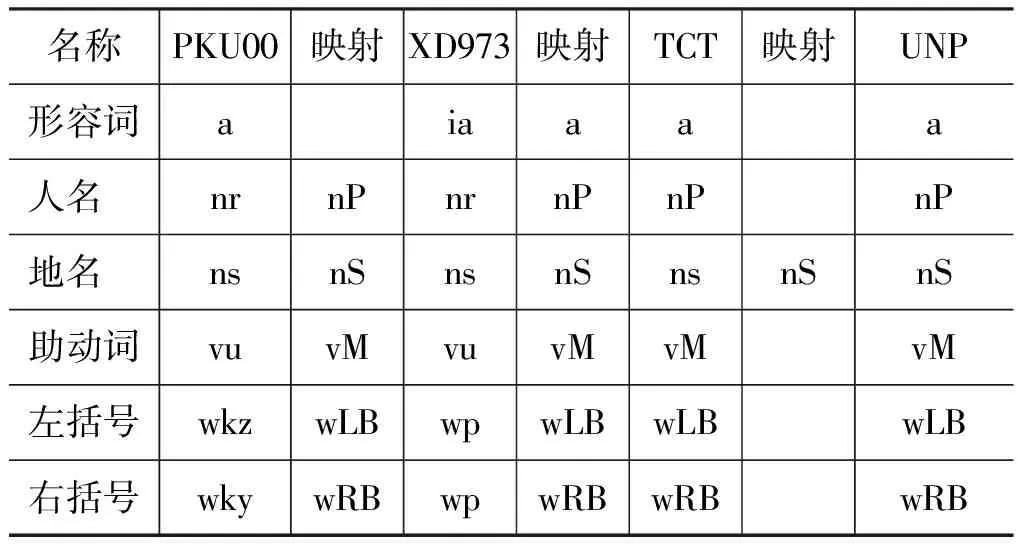
表1 UNP映射词表
2.2 融合思想解析
在语料的融合过程中,需要解决两个问题: 一、转化前的标注问题。对于原语料标注不符合当前要融合的体系的语料,要对其标记进行修正; 二、转化后的问题。在融合的过程中,由于体系的差异,某些词在不同库中的标记有所不同,使得在融合过程中,词性产生歧义。在每个库中,都存在单类词和多类词情况。融合后出现的新问题是: 某些词在各个体系中是单类词,但融合后变成了多类词,其形成原因是不同库中对词类标记分布特定的不同界定标准。研究的重点是为这些融合多类词选择确定一个合适的单词类标记。
例如,词“党支部”、“北边”、“门边”和“夜半”,在不同的体系下的标注信息不同。如表2所示。
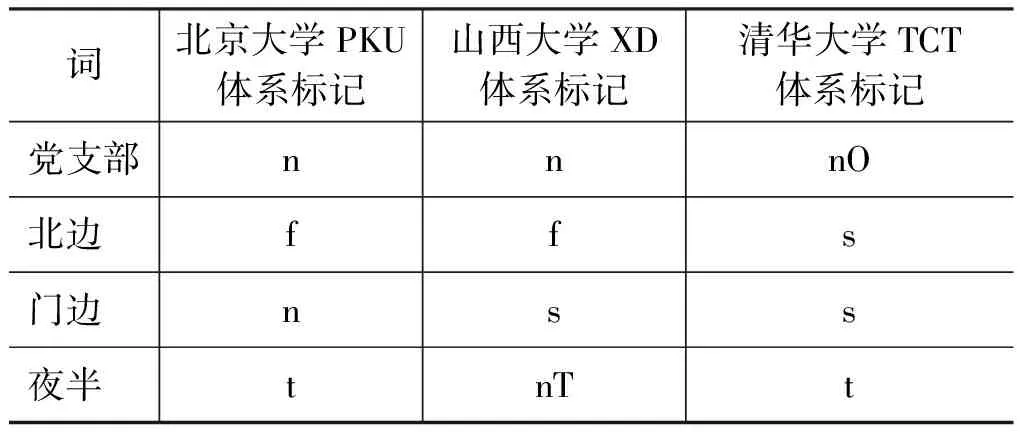
表2 不同体系的词类标记
在PKU体系以及XD体系中,党支部标记为名词n,在TCT体系中,标记为机构团体词nO;在PKU体系以及XD体系中,北边标记为方位词f,在TCT体系中,标记为处所词s;“夜半”在PKU和TCT体系中,标记为时间词t,在XD体系中,标记为时间名词nT。这在几个例子中,可以看到,同一个词在不同的标记体系下的词性标记有所不同,这些差异会导致语料融合过程中的词性标记的不一致。
又例如,在某体系下,有句子序列“贯彻/v 江泽民/nr 同志/n “/wkz 三/m 个/qN 代表/v ”/wky 重要/a 思想/n”,根据映射表的内容,需要将人名的nr标记修正为nP,将左引号wkz标记修正为wLB,将右引号wky标记修正为wRB。经过映射表,可以将其中的一些专属标记规范化,融合后不会产生无关标记。
映射示意图如图1所示。
在某体系下,有句子序列“为/p 夺取/v 现代化/vN 建设/vN 的/uJDE 胜利/vN”、“以/p 经济/n 建设/vN 为/v 中心/n”。句子描述如图2所示。
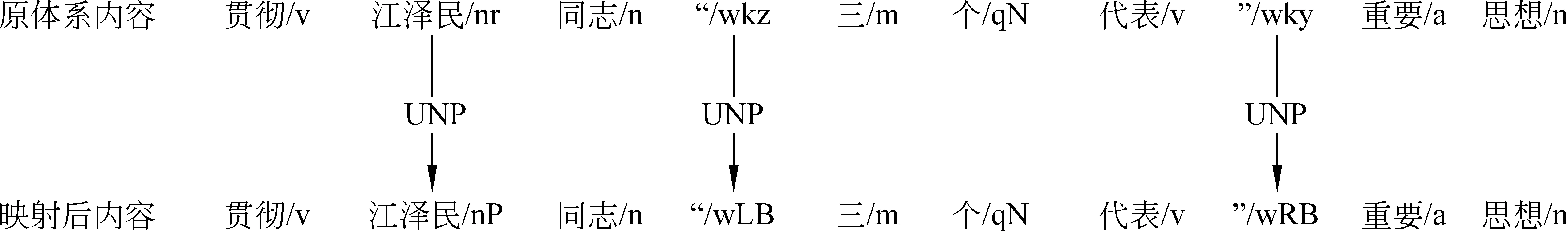
图1 UNP映射实例

图2 UNP映射实例
在这两个句子序列中,词语“为”呈现出不同的词性,在句子序列1中是动词词性,在小句中作谓语成分。在句子序列2中是介词词性,介词修饰的部分做后续成分的状语。
对于该问题,实际上要做的就是确定在语料融合的过程中产生歧义的词的词性。词的词性是由一个词在一句话中所起的作用决定的,与它所在的上下文相关。实验中,由词性标记联系到词在上下文中的词义,再由词义联系到该词的概念。一个词所能体现的不同词义也是由其本身所拥有的不同概念决定的。利用知网[4]中的词语的概念定义,对语料体系中词的词义进行评判,进而确定词的词性标记。对于不同的语料体系,将其中需要进行词性排歧的词抽取出来。首先,明确几个定义。
2.3 语料组织形式
语料在融合的过程中,主要就是对这些多类词和单类词进行处理。在融合的过程中要考虑的主要问题就是词性的歧义[5-6]。确定一个词的词性标记,属于分类问题,基于一种迁移学习的思想,一般认为一个词的词性与其上下文窗口有关联,可以将部分词及其上下文信息作为特征,训练出一个模板,来对其他的词进行分类。
语料形式如下示:
1) 开创/v 思想/n 政治/n 工作/vN 的/uJDE 新/a 局面/n
2) 今天/t 是/v 中国/nS 共产党/n 成立/v 79/m 周年/qT 纪念日/nT 。/wE
3) 企业/n 转账/v 结算/v 中/f 的/uJDE 大部分/m 支出/n
语料的标注规范是不同的语料体系经过词性映射之后的标注规范。在本实验使用机器学习模型进行分类时,采用的特征模板是当前词在知网中的概念的义原,及其左右四个词的词条及其词性作为特征。特征输入模板如表3所示。
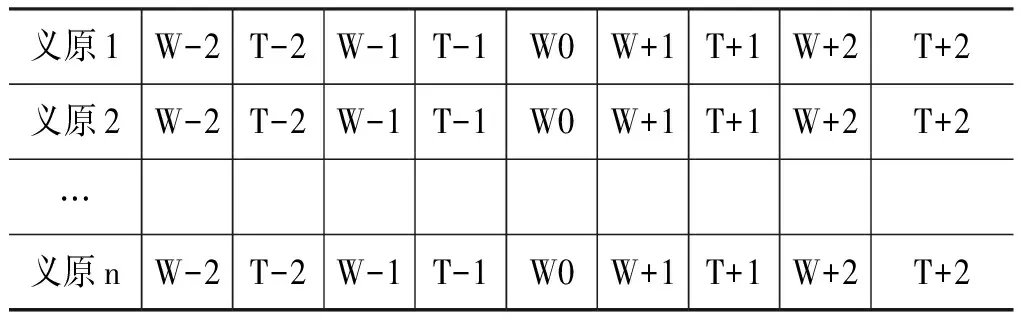
表3 特征输入模板
其中,n表示某个词的概念中的义原总数。根据上述输入模板,上述3)语料句子中的词“结算/v”在知网中的概念为“V calculate|计算, commercial|商”,对应的特征输入为:
1) calculate|计算 企业 n 转账 v 结算 中 f 的 uJDE
2) commercial|商 企业 n 转账 v 结算 中 f 的 uJDE
使用该特征模板对目标词汇集合中的单类词进行训练,然后用该模板对多类词进行预测,预测的结果输出为概率分布。对输出的概率值的分布曲线进行拟合,选择合适数量义原组合为一个概念。
2.4 曲线拟合
词的概念是由不同的义原构成,代表了该词所具有的某些属性,也标示出词可以承担的词类属性,将模型预测的义原结果,通过曲线拟合的方式,选取合适的义原项作为该词的属性,从而确定该词的概念和充当的词类属性。曲线拟合[7]的过程描述为: 根据义原的概率比值,对于不同的比值,选取不同的义原组合为一个概念作为对该词的初步预测概念。拟合值的公式描述为式(1)。
(1)
式(1)中,Tf表示输出的概率分布中的最大概率值,Ts表示输出的概率分布中次最大概率值。对取值的描述如下述式(2)。
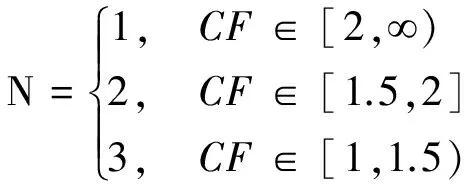
(2)
通过程序统计,当数值大小排序在第一的概率值与排序在第二的概率值的比值在区间[1,1.5]时选取三个义原,比值落在区间(1.5,2)时选取两个义原,当比值大于2时选取一个义原时,可以获得较好的实验效果。
2.5 置信度
由以上描述所得,对于一个预测的结果,首先根据曲线拟合生成的阈值空间,选取不同数目的义原组合为一个概念,然后将组合形成的概念与该词在知网下的各个概念进行相似度比较,选择知网中相似度最大的概念作为当前多类词的推荐结果,并使用推荐结果的词性标记作为该多类词的推荐标记。在得出预测的结果之后,需要对预测的结果进行置信度评价,以此来提高预测结果的准确性。
置信度概念定义如下:
定义3 置信度 针对知网对于某个词的推荐词性,在结果评定时,认为其为正确的可靠度。
对于一个词w标注为c的置信度得分需要考虑如下几个方面的因素:
(1) 该标注词本身标记因素Pmark
Pmark表示在以往的标记中,该词被标注为c的数量与该词的所有数目的一个比值。
(2) 该词的上下文环境因素Fcontext
Fcontext=(1+CL)×(1+CR)
(3)
习近平强调:“人类只有遵循自然规律才能有效防止在开发利用自然上走弯路,人类对大自然的伤害最终会伤及人类自身,这是无法抗拒的规律[1]”。伴随社会经济的发展,生态环境对于人类发展的重要性日益凸显。马克思的众多著作中闪烁着生态思想的光芒,相关生态思想对生态旅游建设有着重要的现实启示。马克思的生态实践理论是解决当前生态问题和遵循现代实践方法论的当代转向,是在保证生态系统整体性的前提下对人的行为的内在制约,是强调人与自然和谐发展的物质性实践思想。马克思的生态实践理论对当前如何正确处理人与自然的关系以及如何在“美丽中国”新时代背景下促进中俄界江生态旅游价值的实现具有重要的指引意义。
对经过置信度评价后获得的结果,选取特定的几个词类进行正确性验证,例如,助词、系动词、动词、介词等。对标注后的词及词性信息还原到原始语料中,此时的各个体系下的语料库即可直接融合为一个更大规模的语料库。
上述语料融合方法的流程图描述如图3所示。
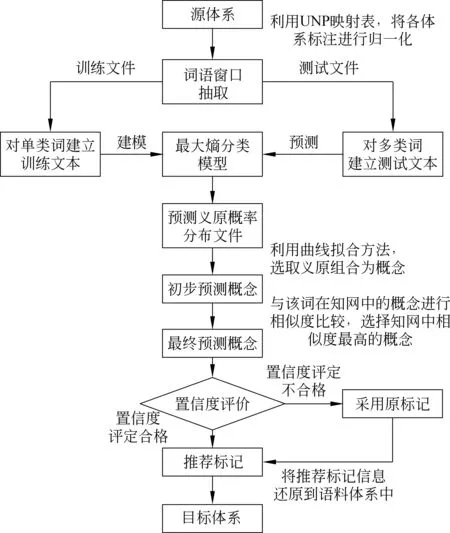
图3 实验过程流程图
3 实验结果与分析
3.1 实验语料
实验中,使用到的三个不同的体系下的语料分别是山西大学XD973语料标注体系、北京大学PKU语料标注体系以及清华大学TCT语料标注体系。经统计所得,除去只在一个体系下出现的词后,剩余的词在这三个体系下的需要处理的单类词和多类词总数,即目标词汇集合为19 110。目标词汇集合中的单类词数目为9 604,多类词的数目为3 774。利用建立的UNP映射表,可以确定单类词的词性。
将单类词的概念中的各个义原作为这个词的特征,并取该词在所在的上下文信息作为模板来训练出一个模型,充分利用单类词的上下文信息对多类词的上下文进行分类。训练以及测试模块的步骤如下。
1) 根据第四部分介绍的模板,从三个语料体系中,抽取出9 604个单类词的上下文窗口作为训练语料,一共有4 230 439条训练输入,记为train_simple。
2) 从三个语料体系中,抽取出3 774个多类词的上下文窗口,一共有4 599 546条测试输入,记为test_multi。
3) 使用最大熵工具进行分类,对train_simple训练后得到模型文件train_simple.model,使用这个模型对test_multi进行预测,预测结果输出为所有义原及其预测概率值,将该文件记为multi_rate。
3.2 概率拟合
对测试结果multi_rate进行分析,该文件的每一行是某个多类词的所有义原及其对应的预测概率值,试验中抽取前十个预测概率最大的义原进行分析,将其中的概率分布进行统计得出如图4的分布状况。
图4中表示的是概率最大的前两个义原的分布曲线。由图4可知,在绝大多数结果中,第一概率与第二概率的间距比较大,可通过第三部分介绍的曲线拟合方法,将输出的概率进行拟合,选取合适数目的义原组合为一个概念作为对多类词的初步预测结果。
得到对多类词的初步预测结果后,将预测的概念与多类词在知网中的所有概念进行相似度比较,选取相似度比最大的概念作为对多类词的最终预测结果,并选取最终概念的词性标记作为多类词的预测标记。
相似度[13]是被定义为一个0到1之间的实数。将预测的概念与该词的所有概念进行相似度值计算,得到一个在0到1的相似度数值,根据该数值选取相似度最大的概念作为最终概念。实验中使用的是知网中的语义相似度计算工具WordSimilarity来对数据进行相似度计算。
3.3 实验结果与分析
根据词类信息在语料标注过程中对标注结构和标注层次的影响程度,对经过试验处理后的结果进行分 析,试 验 中 抽 取 动 词v、系动词vM、助词u、以及介词p这四个对标注工作影响因子较大的词类来进行评价。评价的标准采用的是实际正确率,实际正确率的概念定义如下。
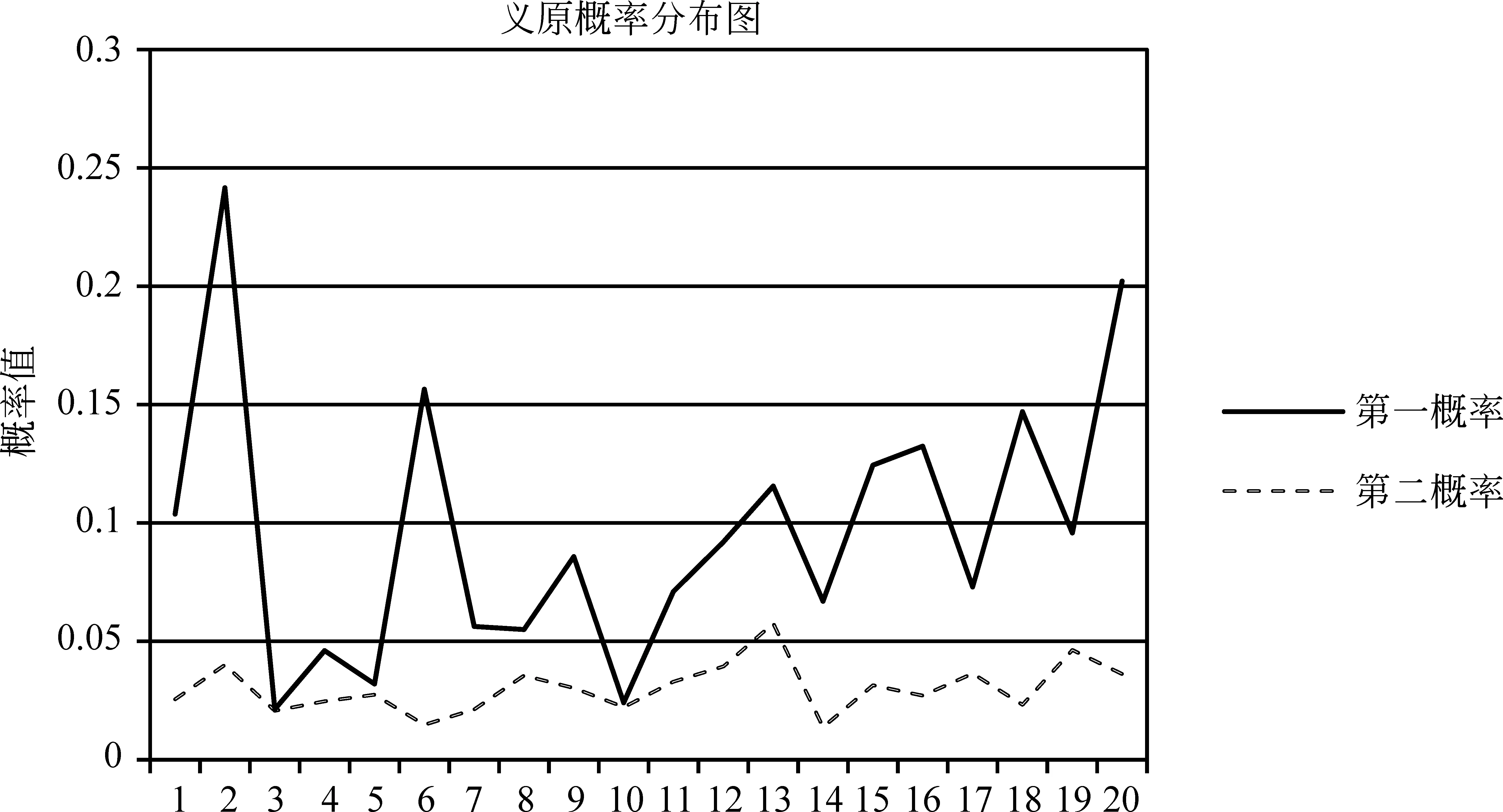
图4 义原概率分布图
定义4 实际正确率 正确条目Rc与结果总数Rall的比值Rc/Rall,用来反映实验结果的准确度表示为式(5)。
(5)
在标注结果中,各类词性所含的词的规模如表4所示。

表4 采用的数据
经过统计,未加入置信度概念评定的标注结果的实际正确率如图5所示。
由图5可知,对于最大熵预测的概念,在经过选取与知网中相似度最大的概念的步骤后,对多类词的消歧效果平均值可达到77%。这样的准确度在语料建设中还是不够的,需要采取一定的策略对消歧效果进行提升。
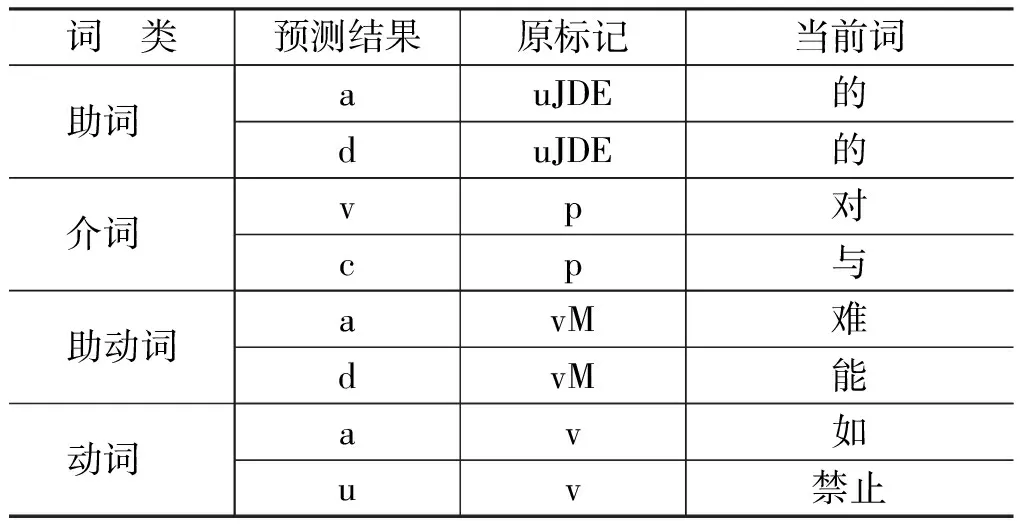
抽取部分实验结果数据进行观察,结果如表5所示。
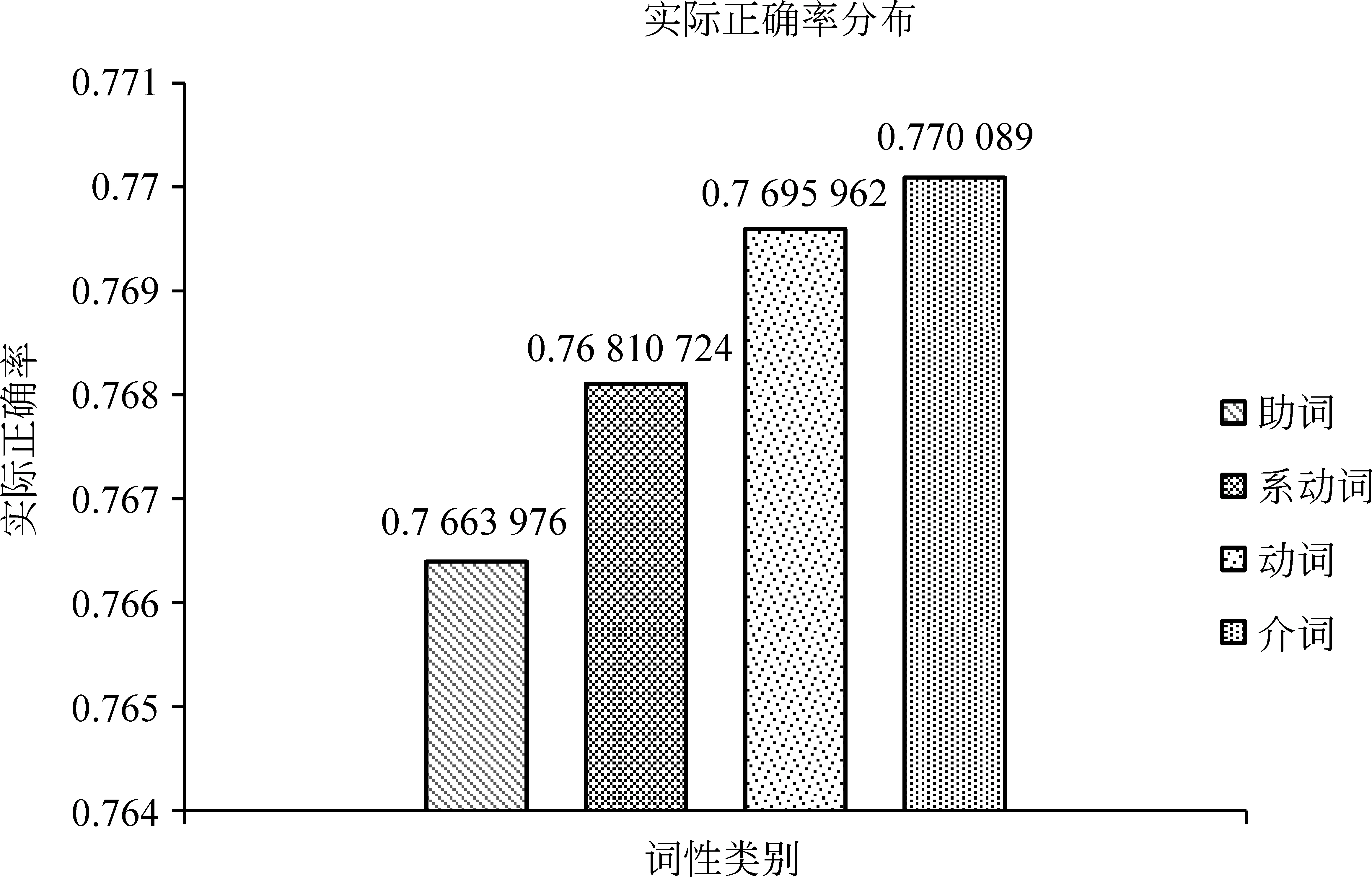
图5 未加入置信度概念的实际正确率分布
词 类预测结果原标记当前词助词auJDE的duJDE的介词vp对cp与助动词avM难dvM能动词av如uv禁止
由表6可知,在助词的预测标记中,将属于助词uJDE的标记预测为a或d,这是由于在选取的窗口中,存在相同或相似的上下文环境,而在该上下文中,有多种不同的标记,造成预测标记不准确。在系动词的预测标记中可以看出,将属于系动词vM的词标记预测为v,出现这种状况是由于系动词紧邻动词做状语,在类似的窗口下,预测为动词标签。动词的情况与助词基本类似。而在介词的预测结果中,“对”和“与”在语料中分别拥有动词v以及连词c的属性,导致分类结果不够准确。
实验引入置信度的概念对结果进行评定,先对置信度划分为十个区间,然后统计每个区间的词的数目。实验选取223 833条输出结果并对其置信度值进行统计,结果如图6所示。
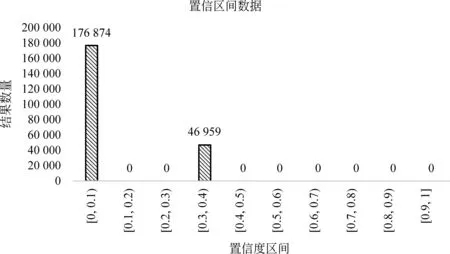
图6 置信度值数据统计结果
统计得出所有的词的在置信度值均落在区间[0,0.1]和[0.3,0.4],对于落在区间[0.3,0.4]的标记结果进行观测,评判落在该区间的词的词性标记的正确性,得出在该区间的标记结果具有较好的正确性,而对于落在区间[0,0.1]的标记结果进行统计分析时发现,当采用原标记时,会得到较好的标注结果。对经过置信度评定后的结果进行统计,选取实验结果中的几个词类进行正确性评测,得出的实际正确率如图7所示。
从实验结果来看,经过置信度评定后,选取的四个词性类别的实际正确率均有提升,对初步的标记结果进行了错误排查,降低了模型预测结果的错误率,同时也说明了置信度评定设计的合理性。对加入置信度评定的实验结果数据结果抽样,数据结果如表6所示。

表6 加入置信度后的结果及其置信度DC值
由表6可知,对预测的结果加入置信度值评定后,可以将那些置信度值比较低的预测结果进行过滤,置信度低表明该预测标记的正确性就略低,对过滤掉的预测条目选取原标记作为其输出结果。
实验最后对所有的单类词和多类词的所有类别词类的平均标记正确率进行统计,得到如图8的实验结果。
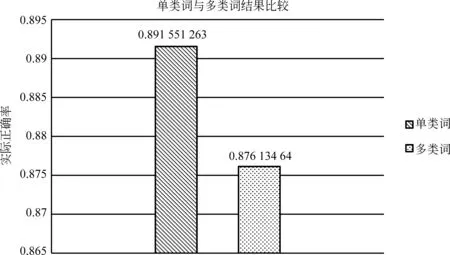
图8 单类词与多类词最终正确率的对比
从结果可知,通过本实验的语料融合的方法,先对词法分析阶段的标注进行归一化,并根据词的概念及其在上下文中所体现的语义进行来推测具有歧义性的词语的标记,可以获得较好的实验结果,在一定程度上解决了语料库标注规范不统一的问题,扩展了语料库的规模,使得多领域的语料可以融合到一个标准下来使用。
4 总结与展望
语料库资源的建设在自然语言处理领域是非常重要的,大规模、高质量的语料库资源的稀少,也使得语料融合的工作变得非常有意义。本文提出了一种异源语料库的融合方法,初步解决了语料库规范不同、标注不同的问题。在一定程度上扩充了语料库的规模,为后期语料库资源的建设做好准备工作。最终实验结果表明,该方法在一定程度上解决了语料库建设中标注规范不同的问题,最终的标注正确率可以达到87%以上,获得了较好的效果。在本文研究的基础上,可以借助知网对词语语义的描述,对词在句子中的语义进行具体评判,提升初步标注结果的实际准确率,使得语料融合的方法变得更准确、高效、通用,来更好地解决建设语料库中遇到的问题,为以后基于语料库的研究工作打好基础。
[1] 宗成庆. 统计自然语言处理[M]. 清华大学出版社, 2008.
[2] 孟凡东, 徐金安, 姜文斌, 等. 异种语料融合方法: 基于统计的中文词法分析应用[J]. 中文信息学报, 2012, 26(2): 3-7.
[3] Jiang W, Huang L, Liu Q. Automatic adaptation of annotation standards: Chinese word segmentation and POS tagging: a case study[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP,2009: 522-530.
[4] 刘群, 李素建. 基于《知网》 的词汇语义相似度计算[C].第三届汉语词汇语义学研讨会, 2002.
[5] 卢志茂, 刘挺, 李生. 统计词义消歧的研究进展[J]. 电子学报, 2006, 34(2): 333-343.
[6] 何径舟, 王厚峰. 基于特征选择和最大熵模型的汉语词义消歧[J]. 软件学报, 2010, 21(6): 1287-1295.
[7] 乔立山, 王玉兰, 曾锦光. 实验数据处理中曲线拟合方法探讨[J]. 成都理工大学学报: 自然科学版, 2004, 31(1): 91-95.
[8] 刘群. 汉语词法分析和句法分析技术综述[J]. 第一届学生计算语言学研讨会 (SWCL2002) 专题讲座, 2002.
[9] 周强. 汉语基本块描述体系[J]. 中文信息学报, 2007, 21(3): 21-27.
[10] 周强,汉语语篇标注库的初始语料准备[R].清华大学信息技术研究院语音和语言技术中心,技术报告 TH-RIIT-CSLT-TR-20131205.
[11] 马金山. 基于统计方法的汉语依存句法分析研究[D]. 哈尔滨工业大学博士毕业论文, 2007.
[12] 葛斌, 李芳芳, 郭丝路, 等. 基于知网的词汇语义相似度计算方法研究[J]. 计算机应用研究, 2010 (9): 3329-3333.
[13] 李峰, 李芳. 中文词语语义相似度计算——基于《知网》 2000[J]. 中文信息学报, 2007, 21(3): 99-105.
[14] 吴瑞红, 吕学强. 基于互联网的术语定义辨析[J]. 北京大学学报,自然科学版, 2014, 50(1): 33-40.
[15] 钱揖丽, 郑家恒. 汉语语料词性标注自动校对方法的研究[J]. 中文信息学报, 2004, 18(2): 30-35.
A Research on the Fusion of Heterologous Corpus
LV Xueqiang1,WU Yongxu1,2, ZHOU Qiang2,LIU Yin1,2
(1. Beijing Key Laboratory of Internet Culture and Digital Dissemination Research, Beijing Information Science and Technology University, Beijing 100101, China; 2. Tsinghua National Laboratory for Information Science and Technology(TNList) Center for Speech and Language Technologies, Research Institute of Information Technology, Tsinghua University, Beijing 100084, China)
Corpus resources are closely related to Natural Language Processing. However, different research institutions have different rules and tags when constructing the copus, which prevents a unified big corpus. This paper investigates the different annotation scheme and presents a method for heterogeneous corpus integration. The experiments on part-of -speech mapping and and disambiguation indicate anaccuracy of 87% after the integration, showing the validness of this method.
corpus construction; data fusion; word mapping; POS disambiguation;

吕学强(1970—),博士,教授,主要研究领域为中文与多媒体信息处理。E⁃mail:lvxueqiang@aliyun.com仵永栩(1989—),硕士研究生,主要研究领域为自然语言处理。E⁃mail:372281543@qq.com周强(1967—),博士,研究员,主要研究领域为自然语言理解。E⁃mail:zq⁃lxd@mail.tsinghua.edu.cn
1003-0077(2016)05-0160-09
2015-10-08 定稿日期: 2016-05-25
国家自然科学基金(61271304,61671070);北京成像技术高精尖创新中心项目(BAICIT-2016003);国家社会科学基金(14@ZH036)
TP391
A
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
计算机应用(2018年5期)2018-07-25 07:41:26
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
轴承(2015年2期)2015-07-25 03:51:04
语言与翻译(2015年4期)2015-07-18 11:07:45
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
