
一种基于云模型的文摘单元选取方法研究
2016-05-04 02:54陈劲光
中文信息学报 2016年5期
陈劲光
(湖州师范学院 教师教育学院,浙江 湖州 313000)
一种基于云模型的文摘单元选取方法研究
陈劲光
(湖州师范学院 教师教育学院,浙江 湖州 313000)
该文提出了一种基于云模型的文摘单元选取方法,利用云模型,全面考虑文摘单元的随机性和模糊性,提高面向查询的多文档自动文摘系统的性能。首先计算文摘单元和查询条件的相关性,将文摘单元和各个查询词的相关度看成云滴,通过对云的不确定性的计算,找出与查询条件真正意义相关的文摘单元;随后利用文档集合重要度对查询相关的结果进行修正,将文摘句和其他各文摘句的相似度看成云滴,利用云的数字特征计算句子重要度,找出能够概括尽可能多的文档集合内容的句子,避免片面地只从某一个方面回答查询问题。为了证明文摘单元选取方法的有效性,在英文大规模公开语料上进行了实验,并参加了国际自动文摘公开评测,取得了较好的成绩。
云模型;自动文摘;不确定性
1 引言
互联网的飞速发展极大方便了人们对信息的获取和使用,但同时也带来了信息过载的问题。在这些海量信息中快速、准确地找到所需要的信息变得越来越困难。面向查询的多文档自动文摘将查询返回的文档集合的内容提炼成包含与查询主题相关、满足个性化需求的摘要,它能够显著提高信息获取和利用的效率。
在生成面向查询的多文档自动文摘过程中,需要选择有代表性的词和句子组成摘要,通常的方法是利用概率[1]、图[2]、主题[3]、共现、节点重要度、语言模型等统计信息判断词和句子的重要度,而这些统计信息中包含的不确定性却很少被考虑。云模型利用数字特征很好地将统计信息(随机性)和模糊性整合在一起。
数学上一般采用熵、模糊集、粗糙集来研究不确定性问题。在文摘领域,目前已有关于将熵和模糊集用于生成自动文摘的研究。利用熵[4-5]生成文摘的方法主要是最大熵方法,但该方法一般需要训练语料,并且只考虑了文摘单元在训练语料中分布的不确定性,而没有考虑当前文档集合分布的不确定性。利用模糊集生成摘要的方法大致可以分为两类: 利用模糊性规则的方法[6-7],以及语义模糊共指链[8]的方法。但是,应用模糊集的方法往往将随机分布的模糊性和随机性孤立开来,对随机分布的统计结果一般被用于决定隶属度函数的隶属度,从而实现对模糊问题的精确求解,随机性和模糊性之间的内在联系却很少被注意。
李德毅院士提出了云模型[9-10]理论来实现自然语言表达的定性概念与定量值的相互转换。该理论融合熵、模糊集等不确定性理论的思想,以基本语言值为突破口,重视随机性和模糊性的内在联系,可以用来体现语言思考中的软推理能力。云模型已经在知识表示[11]、关联规则挖掘[12]、时间序列预测[13]、自动控制[14]等多个领域有着广泛应用。文献[15]提出了一种利用云模型进行自动文摘评价的方法, 但该方法实验语料规模偏小。
本文主要研究如何用云模型来表示面向查询的多文档自动文摘中的不确定性度量,把这种定量表示的不确定性知识平滑融入到经典的文摘方法中,从而改善面向查询的多文档自动文摘的效果。
2 基于云模型的面向查询多文档自动摘要
2.1 文摘原型系统
原型系统采用一种多特征融合的方法,同时考虑句子的查询相关性和句子在文档集合中的重要程度两方面的因素来抽取句子并生成摘要。句子和查询越相关,在文档集合中的地位越重要,越有可能被选择为文摘句。这是面向查询的多文档自动文摘常用的方法。
首先,计算句子的查询独立特征(Query-independent, QI),即不考虑查询条件的情况下,句子在文档集合中的重要度。
本文采用向量空间模型[16](Vector Space Model, VSM)计算句子之间的相似度。对于给定文档集合,将每个句子表示为m维的向量(wi1,wi2,……,wim),其中m是文档集合的词种数,向量空间中的每一维对应着词表中的一个词。向量中每个元素的权重用该元素所在的维所对应的词语的TF-ISF[17]得分来表示,即式(1)。
wik=TF·ISF
(1)
其中,TF表示词w在句子S中的词频,ISF为倒排句子频率,由式(2)计算。
(2)
其中,N表示文档集合中句子的总数,n表示含有词w的句子数。
句子之间相似度可以用向量之间的内积计算,如式(3)所示。
(3)
句子的查询独立特征值可以用该句子与所有句子的相似度之和来表示,如式(4)所示。
(4)
其次,计算每个句子的查询相关特征(Query-focused, QF),即句子与查询条件之间的相关程度。
Hyperspace Analogue to Language (HAL)理论[18]认为自然语言素材中词与词之间的关系提供了足够的语义信息。文献[19]首次将这种方法应用到自动文摘领域。本文沿用该方法获取句子和查询之间的相关特征,不同的是,该文献在计算了词与查询相关特征后,采用复杂的语言模型系统计算句子与查询之间的相关度,而本文则采用相对简单的统计方法计算句子与查询之间的相关度。
首先利用HAL 模型计算文档集合中的词语与查询词之间的关联度,该方法可以被形象地称为窗口共现的方法,利用词与查询词在一定窗口长度内的共现情况计算词语与查询词之间的相关程度,从而获取词语与查询词之间的语义关联信息。在一个长度为K(文献[19]中K=8, 本文沿用了这个参数值)的窗口范围内观察文档集合中的词语(w)与查询词(w′)的共现情况,然后将这个窗口在整个文档集合范围内移动,每次向前移动一个词语。统计词语与查询词在一定距离的共现情况,距离越小,共现次数越多,则说明该词语与查询词越相关。
设n(w,k,w′)代表w与w’在距离为k的共现次数,W(k)=K-k+1 代表词语w与w′的共现强度。则词语与查询词的相关程度可表示为式(5)。
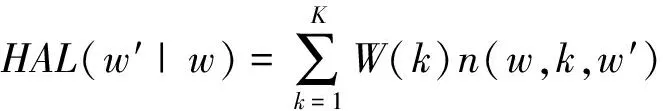
(5)
词语与查询条件的相关程度可表示为词语与每个查询词相关程度的累加和,如式(6)所示。
(6)
文档集合中的句子的查询相关得分可表示为句子中每个词语与查询条件相关程度的累加和,如式(7)所示。
(7)
句子的最终得分由查询独立得分与查询相关得分线性组合得到,如式(8)所示。
(8)
其中σ是调节两部分比例的调节参数。
2.2 查询独立云
针对2.1节的句子的查询独立特征,我们提出了查询独立云,通过对查询独立过程中的不确定性的把握来改进原型系统中计算句子的查询独立得分的过程。
在原型系统中,一个句子如果与文档集合中所有句子相似度之和最高,就会获得最高的查询独立得分。然而,相似度之和最高并不意味着该句子就能很好地概括文档集合中所有的句子的内容。图1给出了查询独立云可视化化的例子。
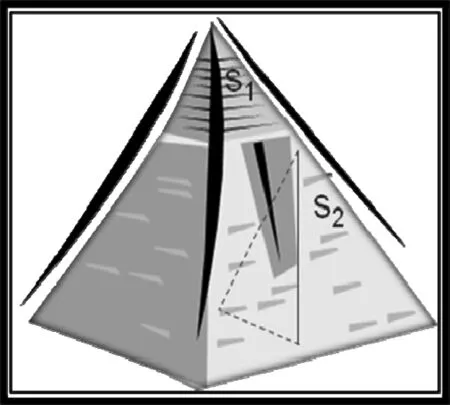
图1 查询独立云可视化的例子
在文档集合中,句子的概括能力是不尽相同的,有些句子可以概括文档集合中大多数句子的内容,而有些则只能概括很少几句话的内容。这种情况可以用金字塔结构来表达,越有概括能力的句子越居于塔顶,而那些没有概括能力的句子则居于塔的底部。
在图1中,句子1能够概括文档集合所要表达的所有句子,居于塔顶,而句子2仅能概括小部分句子的内容,居于塔的中部。如果不考虑查询相关方面的问题,句子1一般来说更适合被选做文摘句;但由于句子2是局部聚焦,不像句子1要概括很多方面的内容,有时更容易取得高得分(例如,和几个句子相似度达到接近1的程度),如果按通常的统计方法,同样有可能被选为文摘句。
该问题可以通过引入云模型来解决,因为从云的角度看,句子1和其他所有句子的相似度云比句子2更均匀,即熵和超熵更小。如果选择那些期望大,熵和超熵小的句子作为文摘句,挑选句子2作为文摘句的可能性就会大大降低,从而提高摘要的质量。
查询独立云的思想是:
将句子和文档集合中每个句子的相似度看成云滴,用这些云滴构成的云的不确定性来评价句子概括文档集合内容的能力。一个句子所对应的云的期望越大,熵和超熵越小,就认为该句子越能代表文档集合的内容,查询独立得分也越高。
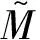
(9)
将期望、熵、超熵按一定的权值线性组合,就可以用一个N×1的列向量表示句子的查询独立得分,如式(10)所示。
(10)
上式通过每一列除以该列的最大值进行了归一化处理。α1,β1,γ1是线性组合的权值参数,由于期望作用一般大于熵和超熵,而熵的作用一般大于超熵,因此α1>β1>γ1≥0。当α1=1,β1=γ1=0时,查询独立得分仅考虑了句子与所有句子之间相似度的期望值,其结果与原型系统一致。
虽然这里给出了具体的计算方法,但还是显得不够直观。利用正向云发生器可以将云模型直观化,因此在图2中给出了一组句子的数字特征和由这组数字特征生成的正态云图,以及这些句子的查询独立云得分。值得注意的一点是,云摘要 本 身 不需要用到正向云发生器,这里用到正向云发生器只是为了直观理解的需要。
在图中可以看出,虽然句子S7(期望为0.06)、S8(期望为0.065)大于句子S3(期望为0.058)、S4(期望为0.057)、S5(期望为0.058)、S6(期望为0.053),但由于它们的熵和超熵也大,得分反而低于S3、S4、S5、S6。从正向云图上看,S8最为明显,其云图幅度最宽,云滴也最分散,反映了该句和其他句子的相似度分布的极不均匀性,即和一部分句子密切相关,和另一些句子毫无关联。通过运用查询独立云,可以减少选择类似S8这样的句子作为文摘句的可能性。
2.3 查询相关云
针对2.1节提到的句子的查询相关特征,我们提出查询相关云,通过对查询相关过程中的不确定性的把握来改进原型系统中计算查询相关得分的过程。
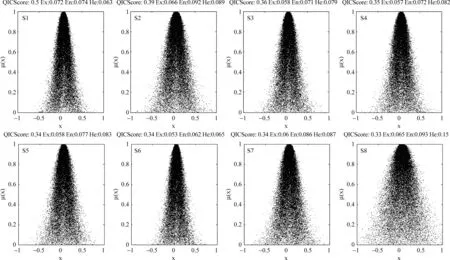
图2 查询独立云的正向云图,期望大但熵和超熵也大的句子可能会获得低得分,其中,正向云云滴个数n=50 000,查询独立云的参数α1=0.7,β1=0.2,γ1=0.1
查询相关云由词语级查询相关云、句子级查询相关云两部分组成,这两块云分别处理词语、句子两个层面的查询相关问题。
(1) 词语级查询相关云
面向查询的过程中,往往需要判断哪些词语是与查询条件密切相关的。在面向查询的多文档自动文摘中,查询条件往往是一句话,经过预处理后一般由多个词构成。判断词语和多个查询词的相关度,最常用的方法之一就是平均相关度,就像原型系统中那样。即首先比较词语和查询条件中的每个词的相关度,然后取平均值。
但这种方法显然是存在很大的局限性的。例如,当查询条件为“毛泽东的故乡是哪里?”,可能有很多词语与“毛泽东”有关,或者与“故乡”有关,但只有同时与“毛泽东”和“故乡”两个词语都有关的词语如“韶山”才是准确的回答。利用云模型可以比较好地解决这一问题。
词语级查询相关云的基本思想是:
将文档集合中的词语与各个查询词之间的相关度看作是云滴,用这些云滴构成的云来描述词语与查询条件之间的相关性。期望相同的情况下,一个词语和越多的查询词相关,它所对应的云的熵和超熵越小,该词语就被认为和查询条件越相关。
图3给出了TAC09中D0901A-A文档集合中的一个例子。该集合主题为“印巴冲突”,一共有七个查询词: “描述”、“努力”、“和平”、“印度”、“巴基斯坦”、“冲突”、“克什米尔”。文档集合中有五个词语与以上七个查询词查询相关得分的期望相同,它们是: “努力”、“会谈”、“信号”、“maharajah”、“停火”,在原型系统中,以上五个词语将得到相同的打分,而实际上它们和查询的关联程度是不相同的。
从图3中我们可以发现,利用云模型,期望相同的词语得到了不同的打分,与越多的查询词语共现,熵和超熵越小,词语级查询相关云得分越高。

(11)
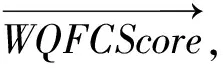
(12)

在获取了每个词语与查询条件相关程度以后,需要给文档集合中的句子打分,原型系统中通过计算句子中各个词语与查询条件相关程度得分的期望计算句子的得分,这种做法同样可以通过引入云模型加以改进。
(2) 句子级查询相关云
句子级查询相关云给那些包含多个查询相关词语的句子更高的得分,减少错误聚焦的可能。
句子级查询相关云的基本思想为:
将句子中由前一阶段获得的词语与查询句之间的相关度看作是云滴,用这些云滴构成的云来描述句子与查询条件之间的相关性。期望相同的情况下,一个句子中有越多和查询句相关的词,它所对应的云的熵和超熵越小,该句子就被认为和查询条件越相关。
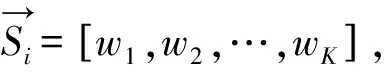
(13)
有多少个句子就有多少片云,这些云叠加在一起构成了云团,可以用一个N×3的矩阵来表示,如式(14)所示。
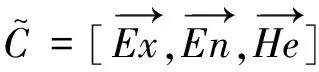
(14)

(15)
2.4 云摘要模型——CloudSum
将查询独立云和查询相关云的计算结果按类似原型系统的方法进行线性叠加,就构成了完整的云摘要模型(Cloud Summarization,简称CloudSum),如式(16)所示。
(16)
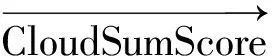
3 实验效果评测
3.1 实验语料
本文采用了DUC*http://duc.nist.gov/2005、2006、2007(简称DUC05、DUC06、DUC07)的面向查询多文档自动文摘任务语料,以及DUC 2007、TAC*http://www.nist.gov/tac/2008、TAC 2009文摘任务A集合(简称DUC07-U、TAC08-U、TAC09-U)的语料作为实验语料。表1列出了实验语料基本情况。
3.2 实验过程
为了专注于研究云模型在自动文摘中的作用,以及便于研究者重复我们的实验,在整个实验过程中,除了采用云方法,我们在实验的其他环节尽可能采取比较简单且开源的方法进行实验。实验的预处理阶段主要包括三个部分的内容: 句子切分、去停用词、词干化。DUC 为参赛队伍提供了开源的句子切分工具, breaksent-multi.pl*www-nlpir.nist.gov/projects/duc/duc2007/tasks.html,我们采用该工具将文档集合中的句子以及查询条件切分成句子。在去停用词后,我们采用斯坦福大学开发的词干化工具Morphology*http://nlp.stanford.edu/software/tagger.shtml对词语进行词干化,Morphology是基于由Minnen等人[20]提出的采用有限状态自动机的原理获取英文单词的原型形态的方法开发的一种开源词干化工具。Morphology的词干化效果一般来说优于传统的基于规则的词干化工具,词干化后的词语只是转化为原始形态,但仍然是完整的单词形式。例如,前面图3提到的“India”就被词干化为“Indium”。在词干化以后,所有单词被转换为小写的形式,包含连接符“-”的词语被转换切分为两部分,其他的标点符号被去掉。另外,长度少于三个字母的词语一般来说包含的有效信息较少,因而也被从词表中去掉。
句子经过打分以后,后期处理过程主要是去冗余。我们采用一种改进的MMR(Maximal Marginal Relevance)[21]方法去冗余,如式(17)所示。其基本思想是: 每选择好一个文摘句,就将该文摘句对剩下的候选文摘句的影响去除掉;循环地进行这样的操作,相当于去除了即将选择的文摘句与所有已经选择好的文摘句的相关信息。
(17)
其中R是所有句子的集合,而F是所有已经选择好的文摘句的集合,因而Si表示候选文摘句;SL表示最近选取的文摘句。上式所表示的过程是循环进行的,不断选择文摘句,直到达到指定的文摘长度。
本文的方法有大量的参数需要训练,但由于以上参数都有约束条件,我们发现只需要使用简化的训练过程就取得了满意的实验效果。详细的训练过程,这里由于篇幅的限制不能展开。具体训练过程中, 我们采用DUC06的语料作为训练语料训练DUC05、DUC07的参数,采用TAC08-U的语料作为训练语料训练DUC07和TAC09-U的参数。最终,我们采用
作为DUC05、DUC07的参数,
作为DUC07和TAC09-U的参数。
3.3 实验结果
表2显示了CloudSum方法与当年参加评测得分最高的机器系统的ROUGE-2[22]得分。从表2中我们可以看出, CloudSum在DUC05、DUC07-U中位列所有机器系统第三位,在DUC07、TAC09-U中也取得了接近前五位的得分。
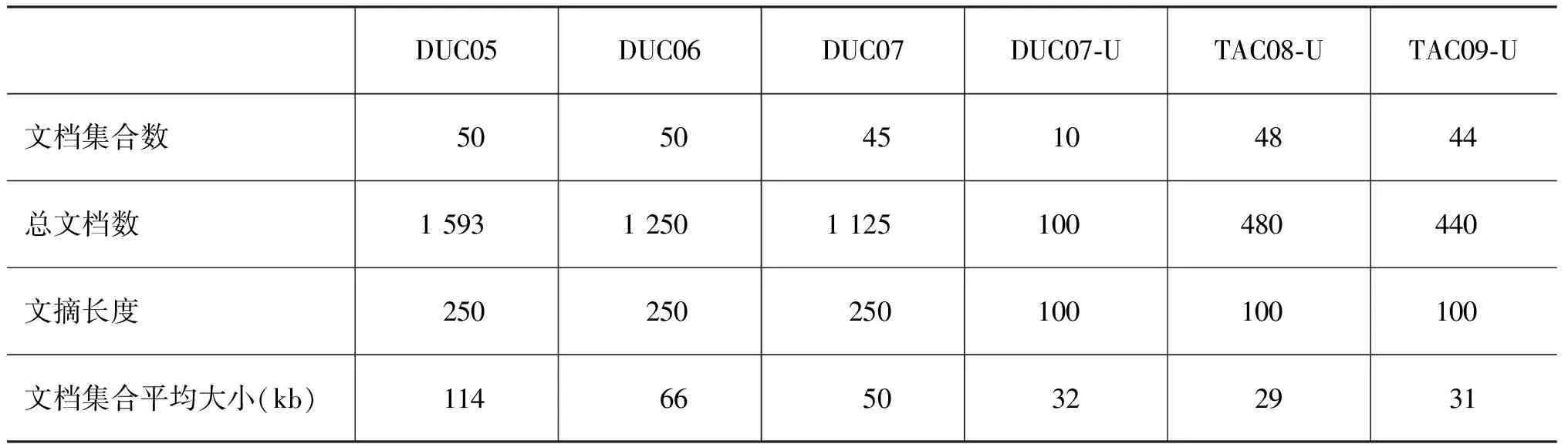
表1 实验语料基本情况
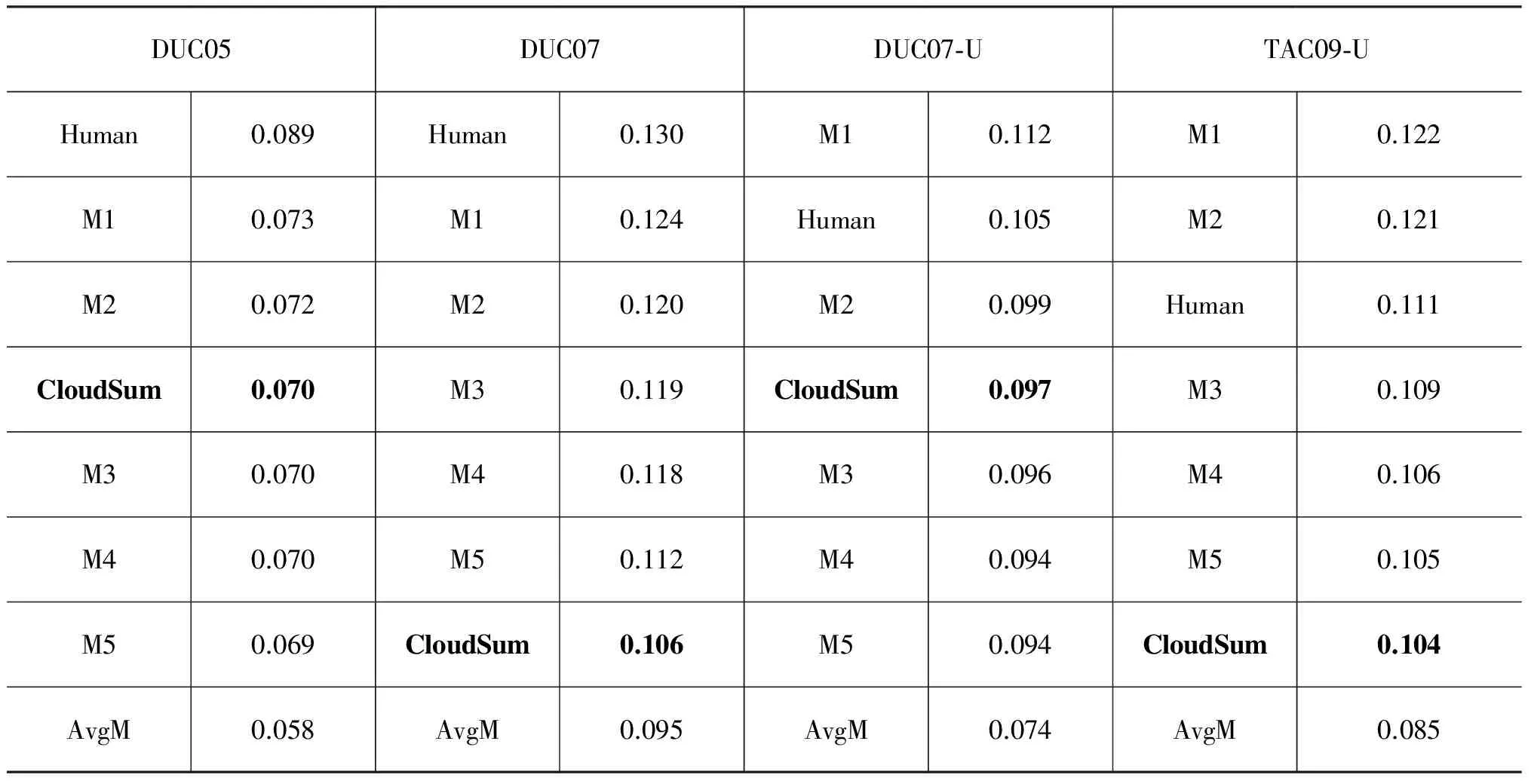
表2 CloudSum的ROUGE-2得分,其中Human是得分最低的人工系统,M1, M2, M3, M4,M5得分最高的前五个自动文摘系统,AvgM是机器系统的平均得分

表3 原型系统与CloudSum的ROUGE-2得分比较
表3显示了原型系统与CloudSum的ROUGE-2得分情况比较。从表中可以看出,在所有实验语料中,CloudSum的表现都优于原型系统。
2010年我们采用CloudSum参加TAC 2010有导文摘国际比赛,为了将有导的任务与面向查询自动文摘任务相联系,我们仅将组委会给定的类别提示信息作为查询条件,其他方面都与之前的实验保持一致。我们提交了两个系统,ID分别为6、23号,CloudSum编号为23号。图4显示了各项评测结果。

图4 TAC 2010评测数据集A(任务与面向查询的多文档自动文摘相似)上,其ROUGE-2、ROUGE-SU4、Basic Elements、人工评测Average Overall Responsiveness分别取得了43个参评系统中排名第3、2、2、3的成绩说明: A到H为人工摘要,1到43为机器摘要(仅列前十)
4 结论
本文提出了一种利用云模型直接生成文摘的方法,采用相对简单的不确定性方法,同时发挥语言的软推理特性,将云模型应用于文摘生成过程中。大规模公开评测的语料上进行的实验表明了本文方法的有效性[23]。鉴于不确定性在自然语言处理中存在的普遍性,以及云模型理论在数据挖掘等相关领域的应用,本文做出的尝试将有可能被应用于自动文摘以外的自然语言处理的其他领域。
[1] K Toutanova, C Brockett, M Gamon, et al.The Pythy Summarization System: Microsoft Research at DUC 2007[C]//Proceedings of Document Understanding Conference, 2007.
[2] X J Wan, J W Yang. Improved affinity graph based multi-document summarization[C]//Proceedings of HLTANNCL,2006: 181-184.
[3] A Haghighi, L Vanderwende. Exploring content models for multi-document summarization[C]//Proceedings of NAACL-HLT, 2009: 362-370.
[4] L Ferrier. A Maximum Entropy Approach to Text Summarization[D]. School of Artificial Intelligence, Division of Informatics, University of Edinburgh,2001.
[5] G Ravindra, N Balakrishnan, K R Ramakrishnan. Multi-Document Automatic Text Summarization Using Entropy Estimates[C]//Proceedings of SOFSEM, 2004: 289-300.
[6] F R Isfahani, F Kyoomarsi, H Khosravi, et al. Application of Fuzzy Logic in the Improvement of Text Summarization[C]//Proceedings of IADIS International Conference Informatics, 2008: 347-352.
[7] M S Binwahlan, N Salim, L Suanmali. Fuzzy Swarm Based Text Summarization Journal of Computer Science[J] 2009,5(5): 338-346.
[8] R Witte,S Bergler. Fuzzy Coreference Resolution for Summarization[C]//Proceedings of International Symposium on Reference Resolution and Its Applications to Question Answering and Summarization (ARQAS), 2003: 43-50.
[9] D Y Li, X Shi, M M Gupta. Soft Inference Mechanism Based on Cloud Models[C]//Proceedings of the 1st International Workshop on Logic Programming and Soft Computing: Theory and Applications (LPSC), 1996: 38-62.
[10] 李德毅, 杜鹢.不确定性人工智能[M], 国防工业出版社, 2005年第1版。
[11] 邸凯昌, 李德毅.云理论及其在空间数据发掘和知识发展中的应用[J].中国图象图形学报: A辑,1999,4(11): 930-935.
[12] 杜鹢, 宋自林, 李德毅. 基于云模型的关联规则挖掘方法[J].解放军理工大学学报(自然科学版), 2000,1(1): 29-34.
[13] 蒋嵘, 李德毅.基于形态表示的时间序列相似性搜索[J].计算机研究与发展,2000,37(5): 601-608.
[14] D Y Li, H Chen, J H Fan, et al. A Novel Qualitative Control Method to Inverted Pendulum Systems[C]//Proceedings of the 14th International Federation of Automatic Control World Congress, 1999.
[15] H Long, Z H He, S Q Li, et al. Automated Summarization Evaluation Based on Clouds Model[C]//Proceedings of China Information Retrieval Conference (CCIR 2009), 2009: 9-16.
[16] G Salton, A Wong, C S Yang. A Vector Space Model for Automatic Indexing[J]. In Communications of the ACM, 1975,18(11): 613-620.
[17] J L Neto, A D Santos, C A A Kaestner, et al. Document clustering and text summarization[C]//Proceedings of 4th Int. Conf. Practical Applications of Knowledge Discovery and Data Mining, 2000: 41-55.
[18] K Lund, C Burgess. Producing high-dimensional semantic spaces from lexical co-occurrence[J]. Behavior Research Methods, Instrumentation, and Computers, 1996,28: 203-208.
[19] J Jagarlamudi, P Pingali, V Varma. A Relevance-Based Language Modeling Approach to DUC 2005[C]//Proceedings of Document Understanding Conference, 2005.
[20] G Minnen, J Carroll, D Pearce.Applied morphological processing of English[J]. Natural Language Engineering, 2001,7(3): 207-223.
[21] J G Carbonell,J Goldstein. The use of MMR, diversity-based re-ranking for reordering documents and producing summaries[C]//Proceedings of SIGIR, 1998: 335-336.
[22] C Y Lin E Hovy. “Automatic evaluation of summaries using n-gram co-occurrence statistics[C]//Proceedings of NLT-NAACL, 2003: 71-78.
[23] 陈劲光.基于云模型的中文面向查询多文档自动文摘研究[D].华中师范大学,2011.
A Summarization Unit Selecting Method Based on Cloud Model
CHEN Jinguang
(College of Teacher Education, Huzhou University, Huzhou,Zhejiang 313000, China)
This paper proposes a summarization unit selection method based on the cloud model. The cloud model is used to consider randomness as well as fuzziness on distribution of summarization unit. In obtaining relevance between summarization unit and query, the scores of relevance between the word and each query word are seen as cloud drops. According to the uncertainty of cloud, a summarization unit which is more relevant to the query is given higher score. After that, the importance in the document set is also considered to evaluate the sentence’s ability to summarize content of the document set. Similarities between a sentence and all sentences in document set are considered as cloud drops. All these cloud drops become a cloud, which indicates the sentence’s ability to summarize content of the document set. The effectiveness of the proposed method is demonstrated on large-scale open benchmark corpus in English. The method was also examined by TAC (Text Analysis Conference) 2010 with satisfactory results.
cloud model; query-focused multi-document summarization; uncertainty

陈劲光(1980—),博士,副教授,主要研究领域为自然语言处理,多媒体学习,机器人。E⁃mail:136966885@qq.com
1003-0077(2016)05-0187-08
2016-00-00 定稿日期: 2016-00-00
教育部人文社会科学一般项目(13YJCZH013)、湖州师范学院人文社科预研究项目(KY27015A )
猜你喜欢
通信技术(2021年12期)2022-01-25
小资CHIC!ELEGANCE(2021年45期)2021-01-11
环境影响评价(2020年2期)2020-12-02
英美文学研究论丛(2018年2期)2018-08-27
剑南文学(2016年14期)2016-08-22
人间(2015年20期)2016-01-04
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
祝您健康(1988年4期)1988-12-30
