
在线社交网络中的新兴话题检测技术综述
2016-05-04 02:42笱程成程学旗
中文信息学报 2016年5期
笱程成,杜 攀, 刘 悦, 程学旗
(1. 中国科学院 计算技术研究所, 中国科学院网络数据科学与技术重点实验室,北京100190; 2. 中国科学院大学, 北京 100190)
在线社交网络中的新兴话题检测技术综述
笱程成1,2,杜 攀1, 刘 悦1, 程学旗1
(1. 中国科学院 计算技术研究所, 中国科学院网络数据科学与技术重点实验室,北京100190; 2. 中国科学院大学, 北京 100190)
新兴话题检测是社交网络研究的热点问题之一。在线社交网络特别是微博的开放性,给话题的流行和爆发提供了前所未有的便利条件。新兴话题是即将流行或爆发的话题,往往伴随着重大的事件或新闻的发生,会产生重大的社会影响,如何在早期识别此类话题,是新兴话题检测研究的主要内容。该文回顾了近年来在新兴话题检测方面的主要进展,分析了新兴话题检测领域面临的挑战,阐述了相关的概念、方法和理论,重点从内容突发特征和信息传播模型两个方面对影响新兴话题检测的方法进行了分析和讨论,并对新兴话题检测的前景做了展望。
新兴话题;话题检测;信息传播;社交网络
1 引言
近年来,以Twitter、Facebook、微博和微信为代表的在线社交网络的迅速发展极大地影响了人们的社交和工作方式。在社交网络中,个人可以随时随地和朋友进行互动,分享自身的相关信息,关注感兴趣的用户,订阅信息,查看各式各样的新闻,各种组织和官方机构也可以利用社交网络发布新产品和新闻。
由于社交网络的开放性和共享性,人们在其中共享的信息或谈论的话题可能会在网络中广泛传播,造成巨大的社会影响。对个人和公司来讲,新兴话题检测是公司进行在线信誉监控(online reputation monitoring)的重要手段,如果公司可以在早期检测到社交网络中产生的与自身有关的事件和观点,就可以较早地发现与公司有关的话题,及时采取相应措施,若为负面话题则及时公关,降低公司信誉损失,若为正面话题则可借机营销,提升公司业绩。对于政府部门来讲,尽早地发现社交网络中的虚假信息、欺诈信息、诽谤谣言等不良甚至反动信息,可以采取有针对性的措施净化网络环境,打击犯罪,及时处置紧急事态,避免恶性群体性事件的发生;同时,对于弘扬正能量,宣扬社会主义道德的消息则可以因势利导,扩大在社会中造成的影响,有助于在整个社会中树立正确的价值导向。因此,社交网络时代,在网络话题产生的早期及时地发现它们,即新兴话题发现技术,具有十分重要的研究和实践价值。
新兴话题(emerging topic)就是在话题流行或爆发之前话题的早期存在状态,也常常被称为趋势话题(trending topic)或突发话题(burst topic)。新兴话题检测和话题检测与跟踪[1-2](topic detection and tracking,TDT)中的首篇报道检测[3](first story detection,FSD)比较相似,但是存在两个显著差别: (1)从分析目标看,FSD的目标主要是判断某篇新闻是否是某个话题的首篇报道,并不关注该话题是否会爆发,会不会引起广泛关注,而新兴话题检测任务的主要目标除了需要识别消息是否是新的,还要预测该消息可能造成的影响; (2)从处理对象看,FSD最初是针对静态的新闻报道提出的话题检测任务,而新兴话题检测主要关注社交网络上的用户产生内容及其传播网络要素。
不同的社交网络,其信息传播的特性是不同的。以微信和Facebook为代表的社交网络是基于双向朋友关系构建的网络,个人发布的信息只在朋友之间进行共享。而以微博和Twitter为代表的社交网络是以用户兴趣为纽带构建的网络,微博中的用户可以关注任何感兴趣的用户,几乎不受限制地发布或转发任何感兴趣的信息。由于微博网络开放的社交网络结构,微博上的消息具有传播速度快,辐射范围广、实时性高的显著特点,微博中的信息常常在短时间内大规模的传播,产生巨大的社会影响。因此,以微博平台为主要研究场景,在微博中的事件或话题大规模爆发之前或爆发早期对其进行检测是一个具有重要理论价值和现实意义的问题,近年来引起了信息检索、数据挖掘、复杂网络等领域学者的普遍关注,产生了许多一系列特色鲜明的研究成果。本文主要针对社交网络中的微博平台上的新兴话题检测技术展开调研。
与传统的话题检测任务相比,在线社交网络上的新兴话题检测技术主要面临以下三个新的核心挑战。首先,新兴话题检测的核心问题是话题的早期发现,传统的基于聚类[4-10]、主题模型[11-13]、矩阵分解[14-15]、混合模型[16]、神经网络[17]等技术的话题发现方法,常常需要足够的语料规模才能保证话题发现的性能。然而,在话题产生早期,话题尚未成为热点话题之初,其相关的语料,往往极为稀少,不足以保证上述技术能够产生足够好的发现效果。以K-means聚类方法为例,当某一类的样本较少时,该类样本常常会被误认为噪音而不是新的类别。因此,如何在稀疏的样本中准确发现新兴话题,是新兴话题检测任务面对的第一个新的核心挑战。
其次,社交网络洪泛式信息传播造成的海量数据流,给实时分析带来挑战。以Twitter为例,目前Twitter上有五亿多用户,每天产生多达五亿条的实时推文。一方面,如此海量且快速演化的信息中,小体量的新兴话题很容易被众多大体量的热点话题所吞噬,从而难以捕捉。另一方面,巨大的数据规模本身对传统的话题分析技术的计算效率和实时性也提出了新的挑战。因此,从海量且快速流动变化的社交网络信息中,区分热点话题,迅速捕捉刚刚发生的新话题,是新兴话题任务的又一个重大挑战。
第三,社交网络上用户产生内容(user generated content, UGC)具有文本短、内容杂、语言质量差等独特性质。如微博中的内容是普通用户产生的,缺乏专业的编辑,用词比较随意,有很多的缩写和不规范的语法,其中还混杂着很多个人状态信息和大量的垃圾信息[18];微博消息的长度大都非常短,导致数据非常稀疏,词与词之间的共现关系在统计意义上的显著性不强,许多常用的文本分析技术在其上的效果较差[19]。因此,社交网络上的用户产生数据的特性对新兴话题的发现也提出了极大的挑战。
按照解决新兴话题发现问题的角度不同,目前的研究方法主要分为两类: 一类是基于内容特征的突发性分析方法;另一类是基于信息传播特征的流行度预测方法。内容特征又分为文本特征和非文本特征两类,文本特征主要包括关键词、Hashtag、用户名、提及(mentioning)行为标识等;非文本特征主要包括URL、图像、视频等,现有的方法有的对一种特征进行重点分析,有的则从多个特征综合考虑。基于内容特征的方法主要通过分析关键词的使用趋势,或者图像的转发变化趋势等判断话题是否新兴话题。信息传播特征则包括用户网络拓扑结构、传播者兴趣模型、用户兴趣网络社区等。基于信息传播模型的方法则主要通过分析信息的可能传播路径,以及潜在参与用户的影响力等,预测信息的传播发展趋势,判断话题是否可能成为新兴话题。
2 基于内容特征的方法
新兴话题检测的研究涉及到话题的定义,Gullie等人[20]定义了话题的三种表示方式: 1)一个词就是一个话题; 2)多个词表示一个话题; 3)词集合上的概率分布。早期的研究从内容特征的角度入手,结合时间因素,通过分析社交网络中的内容特征随时间的突发变化找出新兴话题。Kleinberg[21]首次利用自动机建模随时间顺序到达的文档流,用自动机之间的状态转换识别话题中的突发特征。Leskovec等人[22]进一步研究发现新闻和博客中的话题随时间呈现出起起落落的动态变化,并从全局和局部两个角度进行定量的分析,虽然文中没有提及到如何检测新兴话题,但是让研究人员对话题随时间的变化关系有了清晰的认识。
基于内容特征的方法主要是通过观察话题的内容特征随时间的变化趋势,识别特征突发改变的时间点[23-36]。根据处理内容的不同,可以分为基于文本特征的方法和基于非文本特征的方法。根据对时间的处理方式不同,可以分为离散时间模型和连续时间模型,目前大部分方法都采用离散时间模型。所谓的离散时间模型,就是把时间划分成连续的时间窗口,以时间窗口作为话题分析的基本时间单位。根据任务的服务对象不同,又可分为通用目的话题检测和针对特定组织机构的话题检测。
Mathioudakis等人[24]观察到新话题的兴起会引起话题相关的关键词特征的突发改变,并将这类关键词定义为突发关键词(burst keyword),据此提出了一种在Twitter上进行新兴话题分析的框架TwitterMonitor,并被以后的研究广泛的采用,如图1所示。该框架分为突发关键词检测、关键词聚类和趋势分析等关键步骤。突发关键词检测的目的是找到新兴话题突发特征词集合,关键词聚类则把属于同一个话题的关键词组合在一起,趋势分析根据检测出的关键词组,检索出关键词所属的微博内容,利用内容摘要方法给出话题的详细描述。下面介绍一些基于内容特征的新兴话题检测模型。
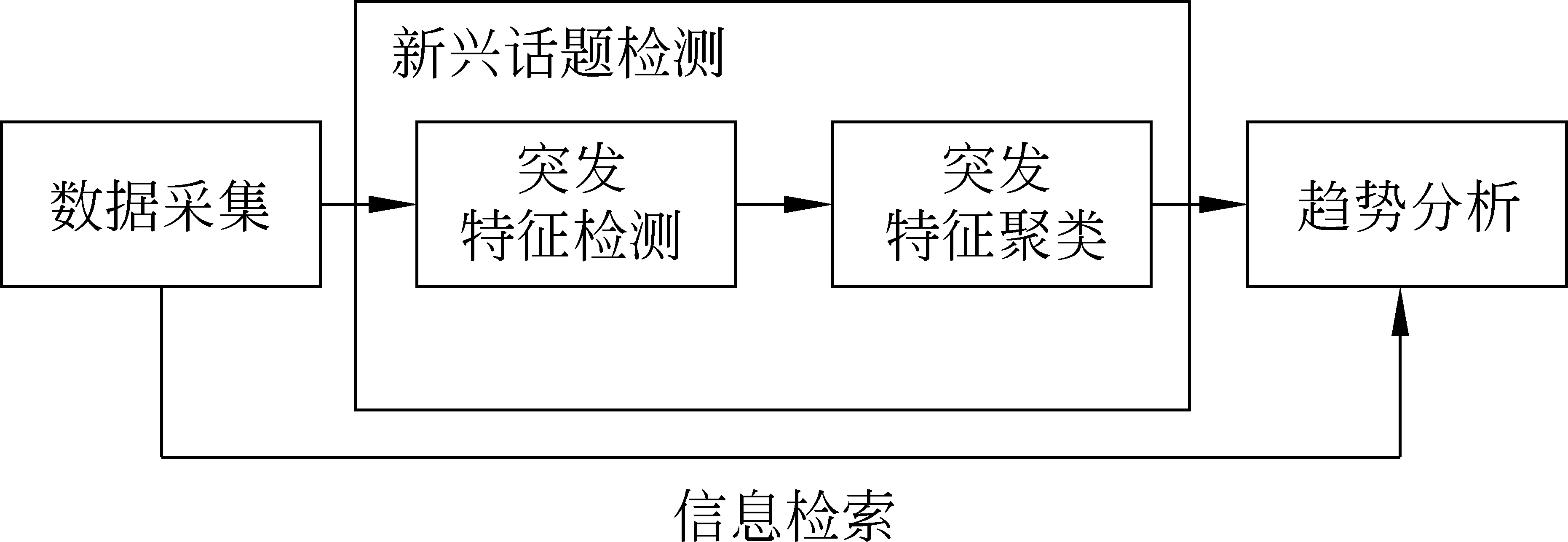
图1 基于内容特征的新兴话题检测框架
2.1 文本特征方法
文本特征方法是指利用微博消息中的文本内容等特征随时间的变化来检测新兴话题。该类方法研究重点在于文本特征的定义和抽取,垃圾文本特征的过滤,与外部知识库的融合,以及话题的发展趋势预测等方面。按照话题定义,可以分为基于突发关键词的方法和基于主题模型的方法。
Shamma等人[25]提出了在微博中检测PT(peaky topics)和PCT(persistent conversational topics)两种话题的方法,采用单个词表示一个话题。其文本特征的计算方法是将微博按时间切分到一个个时间窗口中,将每个时间窗口中的所有微博消息看成是一个伪文档,通过计算不同时间片中单词的正规化词频ntf(normalized term frequency)特征的变化来检测两类话题 ,ntf的定义如式(1)所示。
(1)
ntft,i表示时间窗口t中标号为i的单词的正规化词频,tft,i表示时间窗口t内含有单词i的消息数量,cfi表示当前语料中包含单词i的所有消息数量。PT话题通过识别ntf短时间内达到峰值,然后又迅速回归常态的单词来判定的,具有高度的时间局部性,表现出文本突发特征的话题;PCT话题是通过识别ntf短时间内达到峰值之后频率虽有降低但仍显著高于均值并持续一段时间的单词来判定的。从算法的描述中可以看出该算法执行简单,适合大规模语料集合,但是只用一个单词表示话题,描述能力较弱。
Cataldi等人[26]提出的方法也是基于文本特征—增强正规化词频antf(augmented normalized term frequency)[27],但是同时考虑了用户在社交网络中的权威性,利用PageRank算法得到用户的权威值,最后结合antf计算出每个词的能量特征,观察比较词能量特征在不同时间窗口的变化找出具有突发特征的词,最后通过聚类的方法找出相关的新兴话题,该方法采用词集合的方式表示一个话题,与上述两种方法的不同点在于考虑了用户的社交属性,提高了内容特征的精度。
主题模型(latent dirichlet allocation,LDA)在文本处理领域取得了巨大的成功,其话题表示方式采用的是词集合上的概率分布,相比较Shamma提出的方法,话题的表示更清晰,因此,基于LDA的主题模型的社交网络新兴话题检测方法得到了广泛的研究[28-29]。由于用户产生内容的特点,传统的LDA模型在微博语料上的效果并不理想,Mehrotra提出了四种微博消息聚合的方法来改进LDA在用户产生内容上的效果,分别是将属于同一作者的所有微博、将检测出具有突发特征的词所属的微博,将属于预定时间间隔的微博或将属于同一Hashtag的微博聚合成一个文档。在不改变标准LDA结构的情况下,将聚合后的微博文档作为输入,取得了比不聚合之前更好的效果,其中Hashtag聚合方式效果提升最明显。但是,由于主题模型训练和推断时间在实际处理海量数据过程中开销较大,离实际使用还有较大距离。
为了应对微博内容的文本短、垃圾多、用语不规范等特点,EDCoW[30]方法利小波分析方法对微博中出现单词的频率构建信号,通过检测自相关(auto-correlation)的词来去除垃圾词,大大降低了备选词集的大小。TwEvent[31]利用n-grams分析Twitter中消息的内容特征,同时借助Wikipedia和微软的“Web N-gram Services”中的统计信息过滤掉不重要的特征。该方法采用外部知识库的信息来过滤微博消息中大量的垃圾和噪音,是对TwitterMonitor框架的扩展,有助去除微博内容中的噪音,但是对知识库有较大的依赖性,可能会遗漏部分话题或事件。贺敏等人[32]提出了一种基于有意义串的微博新兴话题发现方法,利用词频、上下文、规则等多种策略发现表示话题突发特征的有意义串,通过聚类有意义串发现有关的话题。该方法与传统基于文本特征不同在于其将文本特征表示为有意义串。有意义串是包含具体语义、灵活独立的语言单元,能在多种语境中使用,克服了微博数据高维稀疏导致内容关系难以准确计算的问题。
2.2 非文本特征方法
文本特征方法以社交网络内容中的关键词特征为基础进行研究,但是随着非文本媒体如图像、视频、URL的流行,仅采用关键词特征的方法已经不能全面准确反映话题的内容信息,因此,有必要结合社交网络中丰富的用户关系数据(如提及行为,好友关系等)来进行新兴话题的检测。
目前,在利用非文本内容信息的检测方法上,Takahashi等人提出了通过检测用户社交过程中提及行为的异常来检测新兴话题的方法[33],该方法利用概率模型建模每个用户的提及行为,设T为训练集,T中的提及行为总数为m,用户v在T中的提及行为数为mv,则用户v的提及行为的概率P(v|T)=mv/m,为了估计不在训练集T中出现用户的提及行为概率,采用了基于CRP(Chinese Restaurant Process)估计方法,引入了一个参数γ,则对于在T中出现的用户,其提及行为概率如式(2)所示。
(2)
对于不在T中出现的用户,其提及行为概率为如式(3)所示。
(3)
Chen等人[35]提出了一种基于特定组织的新兴话题检测方法,与之前方法的不同之处在于除了考虑微博内容外,与组织相关的用户及其社会关系也被考虑进来。作者定义了话题相关的用户和微博影响,并由此计算出话题的六个关键特征,包括用户数量增长率、微博数量增长率、转发微博数量增长率、组织关键用户中高影响力用户的比例、组织关键词中高影响力关键词的比例、当前时间窗口内的微博积累权重,把新兴话题检测看成为一个分类问题,先通过增量聚类方法发现候选的话题,接着利用SVM(support vector machine)分类算法找出新兴话题。在话题趋势预测方面,Lu等人[36]利用股票交易中一种常见的技术分析工具MACD(moving average convergence divergence)来分析Twitter中词随时间的变化特征,与之前的方法相比,该方法不仅能够预测话题的兴起,还可以预测话题的衰亡。
2.3 小结
基于内容特征的在线社交网络新兴话题检测方法,旨在通过捕捉话题相关的内容特征发生的异常变化,找到相关的新兴话题,而内容特征的变化从概率上讲是通过观测值和期望值之间的背离来衡量的。该方法通过首先过滤出具有突发特征的消息,大大降低了数据的规模,进一步的处理可以借鉴传统话题检测手段,因此,该方法从本质上讲是对传统话题检测手段的延伸和扩展。
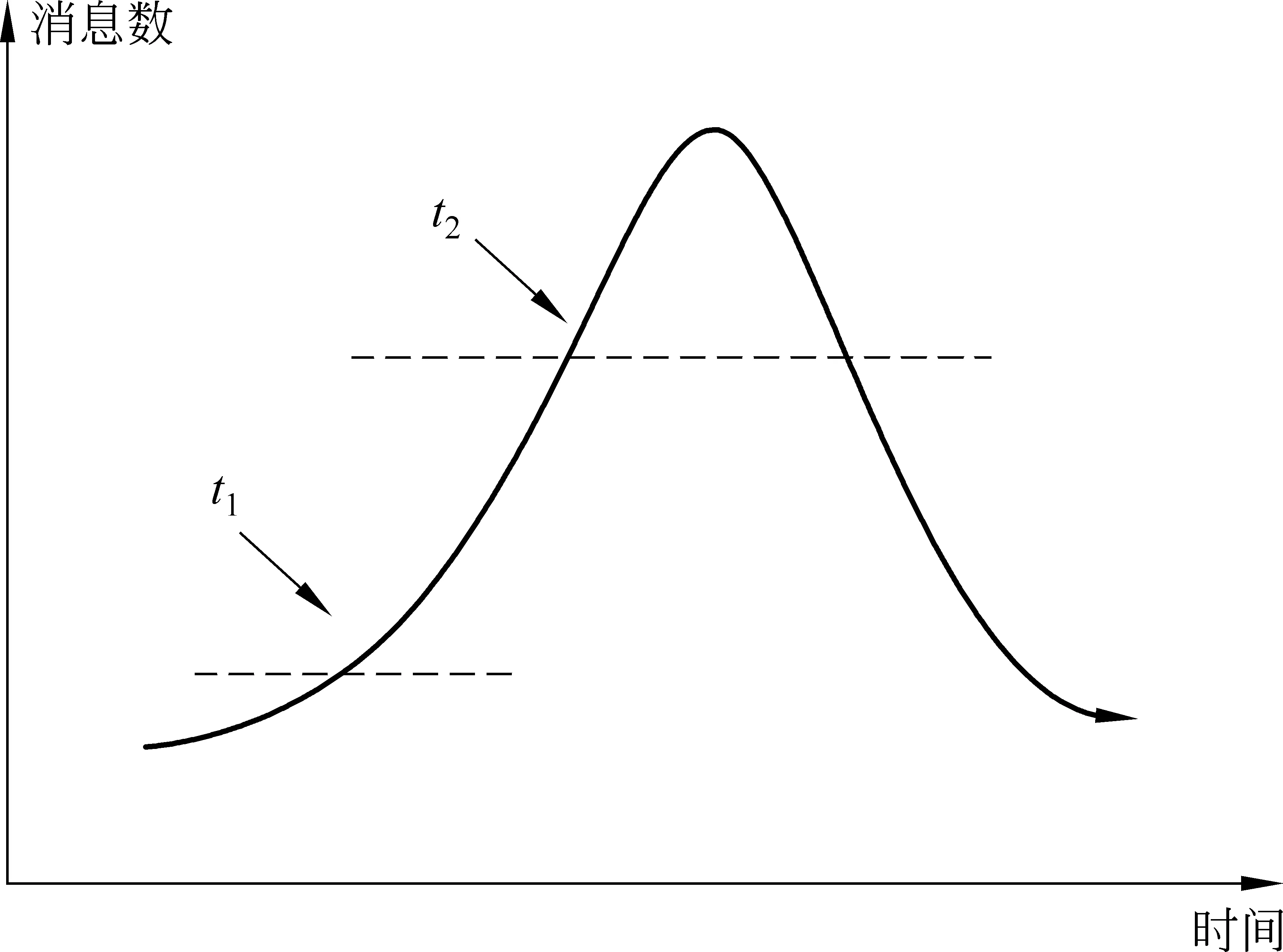
图2 某话题消息数随时间变化关系
应该指出的是,基于内容特征的方法需要检测到内容特征的突发改变,即观测值和期望值之间的背离,也就是说社交网络中对某一话题产生了一定数量的转发和评论,并且已经达到了显著的水平。这在客观上造成了新兴话题被检测出的时间较大地滞后于话题实际发生的时间。如图2所示,坐标轴中的曲线表示某一话题相关的消息数随时间变化的趋势,基于内容特征的检测方法一般会在t2时刻做出响应,此时离话题发生已经过了较长的时间。因此,如何在更早的时间,如t1时刻附近检测出话题是一个需要进一步研究的问题,t1时刻与话题相关的消息在网络中刚刚出现零星的传播,还没有形成一定的规模。此外,基于内容特征的方法也不能预测话题的参与者以及最终话题传播的范围,在需要预测话题参与者和爆发规模的场景中,可以采用基于信息传播模型的话题发现方法。
3 基于信息传播模型的方法
传播问题在流行病学中已经研究了较长的时间,如对病毒扩散机制的研究等。社交网络中用户转发消息的行为,造成了承载信息的消息在网络的节点之间和社区之间传播,是新兴话题形成的客观条件。因此,研究社交网络上的信息传播或扩散(information diffusion or propagation)现象的规律,对于新兴话题的检测有重要作用的。
从信息传播的角度考虑,话题之所以流行,是因为有大量的用户转发了相关消息,引起了广泛的关注和评论。因此,如何将信息传播的模型运用于社交网络的新兴话题检测也是目前新兴话题检测研究的热点。归纳起来,可以分为两类,即基于关键节点的检测和基于消息初始传播动态的检测。首先,介绍在线社交网络中经典的信息传播模型。
3.1 信息传播模型
针对不同的应用领域,研究人员提出了各种各样的模型,如建模疾病传播的SIS(susceptible infected susceptible)、SIR(susceptible infected removed)等;对于在线社交网络,可以看成一个图结构,如微博网络可以看一个有向图G(V,E),顶点集V表示用户的集合,边集E为用户之间的关系,假设用户u关注了用户v,则
1) 单调假设,一个节点被激活后不能再变成非激活状态。
2) 每次信息传播过程都是由若干个种子节点组成的初始集合开始的。
3) 每一个节点只能从他的邻居节点中接收到传播消息。
4) 网络结构是静态的,不随时间动态改变。
运用IC模型需要事先计算节点之间的传播概率,而LT模型需要事先定义加点之间的影响度并设置每个节点的激活阈值。IC模型认为节点之间的影响是独立的,设
Saito等人[39-40]进一步打破了上述两种模型中离散时间和同步传播假设,分别提出考虑到传播中时间延迟影响的CTIC和CTLT(continuoustimedelayindependentcascadeandcontinuoustimedelaylinearthreshold)模型,以及考虑到传播中异步性的AsIC和AsLT(asynchronousindependentcascadesandasynchronouslinearthreshold)模型。王巍等人[41]在消息传播模型的基础上,提出了一种基于微博粉丝关系、用户活跃度和影响力的话题传播模型,提出了“内外场强”的概念来描述影响信息传播的内在和外在因素。
3.2 基于关键节点的检测
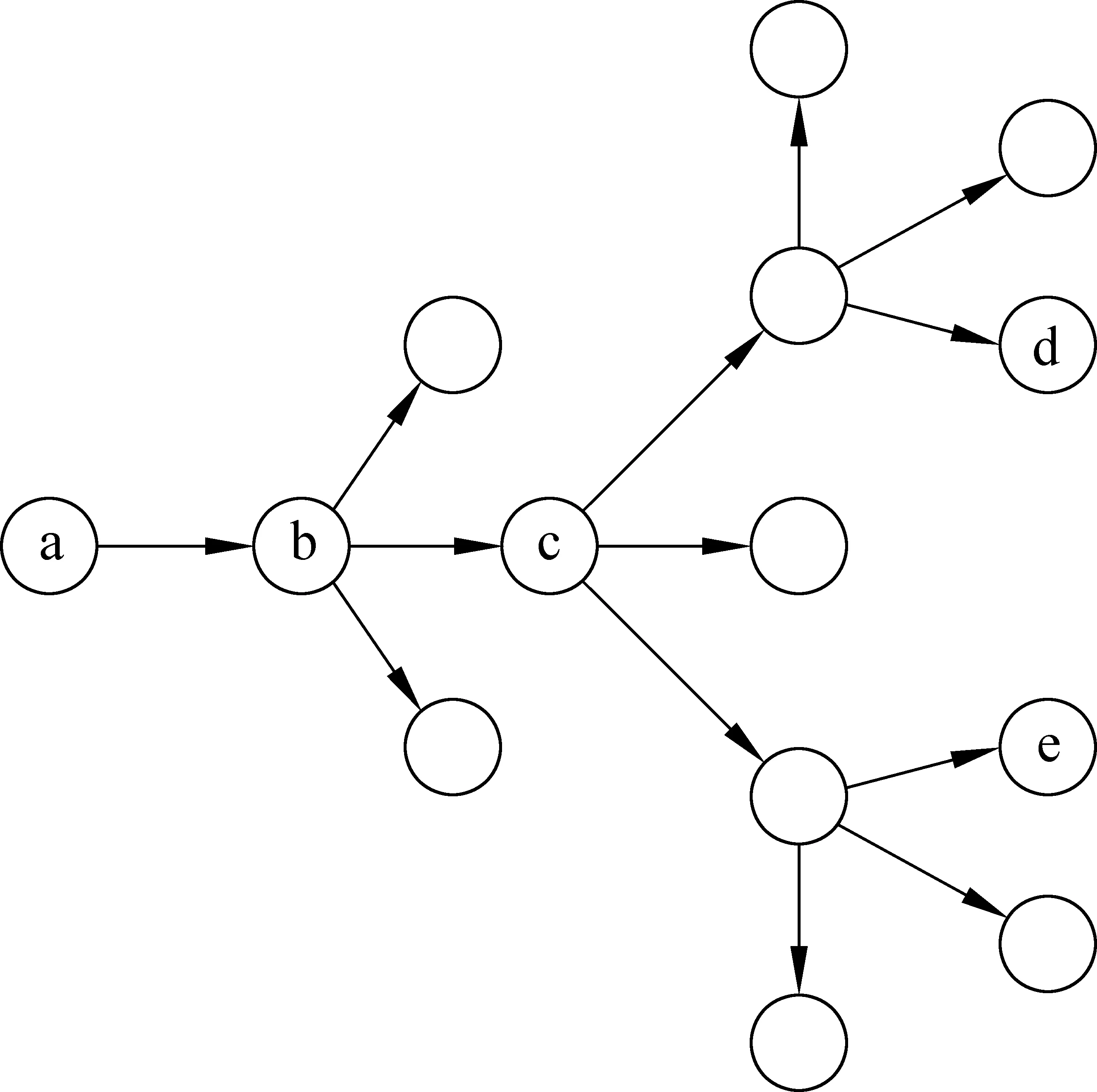
图3 某话题消息传播级联示意图
运用信息传播模型进行新兴话题检测,最直接的方式就是在社交网络中选取关键的节点集合,图3展示了某话题的消息传播轨迹,消息从节点a发出经多个节点的转发不断传播。虽然传感器在节点b、c、d和e都可以检测到该消息,但是时效存在巨大的差异。新兴话题的检测,就是尽可能早的检测到流行或爆发的话题,对于该话题来说,节点b和c是好的检测点。这个问题可以定义为: 选取网络中的关键节点,使得能够在新兴话题爆发之前尽可能早的覆盖到新兴话题的传播[42],即影响最大化问题。影响最大化问题是建立在传播模型上的最优化问题[38],其研究重点在于传播模型建模,传播概率的学习以及算法时间复杂度的优化。
3.3 基于消息初始传播动态的检测
与基于节点选择的方法不同,基于消息初始化的传播方法假设已经观测到某话题消息被前k个节点转发,预测话题将来是否可能爆发。如图4所示,观察到某话题的消息的初始传播动态为节点集合{a, b, c},需要预测消息可能的传播范围。可以借助影响最大化问题中求k个节点传播范围的方法,但是,在影响最大化问题中,对用户之间的传播概率没有做过多的探究,基本都是人为设定的统一概率,这种对问题的简化和真实的社交网络有很大区别。真实的社交网络中,用户和用户间的传播影响力存在很大的差异,如同一用户和他的不同好友之间的交互频度不同,存在亲疏之别。因此,为了在真实的社交网络中利用消息的初始传播动态来检测新兴话题,首先面临的问题是如何准确估计用户的传播影响力,下面简要介绍影响力估计的相关工作。
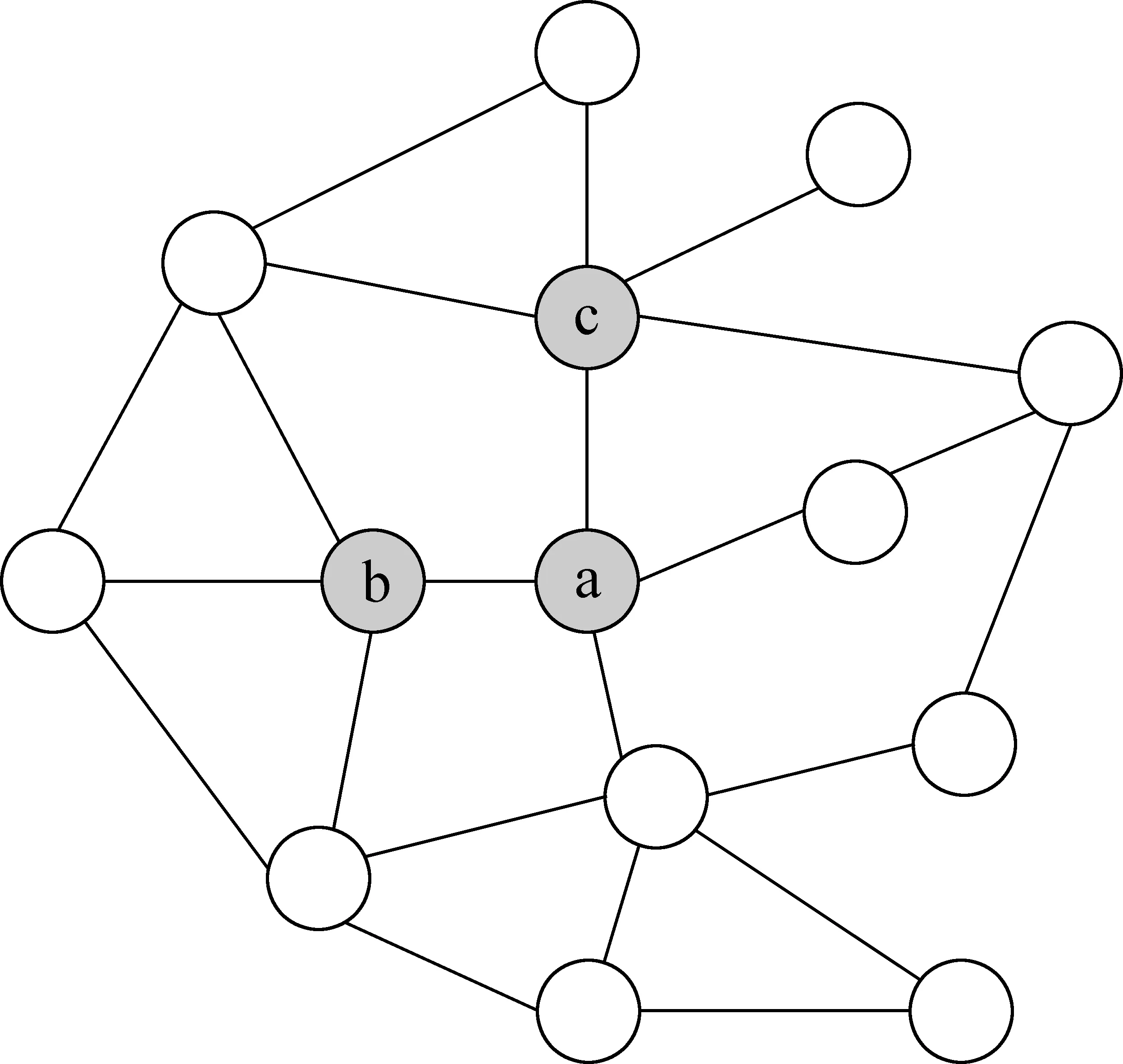
图4 某话题消息的初始传播动态
用户的影响力估计是目前学术界研究的热点[43-47]。基于网络结构的影响力分析方面,Kitsak等人[48]发现最有效的转播者不一定是节点度数高的节点,也不一定是介数中心度高的节点,而是通过k-shell分解得到的核心节点。Garas等人[49]意识到网络中边的权重是描述网络结构的重要因素,据此提出了一种带权重的k-shell分解的方法,发现带权重的k-shell分解方法找到的核心节点在信息扩散方面的影响力一致优于不带权重的k-shell分解方法。Kwak等人[50]对Twitter数据集Twitter7[51]上的用户进行了排序分析,用Kendall相关系数[52]进行了比较,实验结果和Kitsak的发现是一致的。Weng等人[53]综合考虑了用户的消息内容和关系结构,基于PageRank算法[54]提出了TwitterRank算法来识别Twitter上话题相关的关键用户。Lv等人[55]提出了LeaderRank算法,通过加一个背景节点(ground node)解决了PageRank中用户排序不唯一的问题,具有较好的抗干扰性和鲁棒性。
Tang等人[56-57]从话题的角度提出了TAP(Topical Affinity Propagation)模型来计算科学合作网等社会网中的用户影响力,其方法是利用因子图联合建模用户节点的话题分布和结构,并提出了有效的分布式的模型训练算法。Liu等人[58]研究了异质网络结构中的影响力问题,提出了一种概率产生式模型,联合利用消息内容和社交网络结构信息来建模用户历史数据的话题分布来表示用户的兴趣,借此可以计算出用户之间的影响力。Bian等人[59]从用户行为的角度研究了在微博网络中预测新兴话题和传播者的问题,方法从用户的转发行为入手,定义了基于信息扩散的影响力的三个方面,即流行度相关的影响力,兴趣相关的影响力和社交相关的影响力,最后利用因子图(factor graph)联合建模用户的影响力。Saito等人[37]联合建模用户的影响力和传播模型,将用户的影响力转化为模型的参数,根据社交网络上的信息传播的历史数据,利用极大似然方法来学习用户的社交影响力。
3.4 小结
基于信息传播模型的新兴话题方法,其优势是可以从微观层面更早地检测出新兴话题,且能预测话题传播的参与者,因而逐渐成为研究热点。但是,应该指出,基于传播模型方法的性能在很大程度上取决于传播模型的好坏和用户间传播影响力的计算,在这点上,学术界目前的研究还没有能很好的和新兴话题发现应用结合起来;此外,该类方法需要丰富的历史传播数据进行模型的训练,这对数据的采集和处理也提出了较高的要求。
4 未来研究方向
(1) 信息传播和社交网络的共同演化: 在线社交网络结构的变化对现有传播模型的影响需要进一步探讨。事实上,社交网络结构不是一成不变的,而是动态变化的[60],Myers等人[61]研究了Twitter网络中用户的发帖和转发行为与网络结构之间的动态关系,发现网络中的信息级联传播会极大改变用户的局部结构(即朋友关系),并表现出突发性。而现有的传播模型还没有考虑到网络结构随时间的变化因素,因此,设计新的传播模型来建模时变的社交网络是一个有价值的研究内容。
(2) 封闭世界假设的突破: 目前研究社交网络中信息传播的一个公认的假设是封闭世界假设[20]: 即一个社交网络就是一个封闭的世界,节点之间的信息传播只会沿着网络中的边进行,节点不会受到网络之外的环境的影响。但是Myers等人[61]观察到网络中的信息存在跳跃传播的现象,并指出在Twitter网络中,29%的信息传播受到外部环境的影响,如何定量的分析外部因素对社交网络中信息传播的影响,进而更好地指导新兴话题的检测,是一个有待深入研究的问题。
(3) 多源点的信息传播: 目前针对社交网络中信息传播的研究,大部分仅考虑单源信息的传播情况。而在实际的传播过程当中,话题中消息的传播过程往往是多传播源共同作用的结果。多个传播源之间既有竞争又存在协作关系[62],较好的理解和建模多源点信息传播问题将有助于提高网络中关键节点选取和消息传播范围预测的准确性。
(4) 大规模分布式检测算法: 目前的研究主要集中在如何提高话题发现和预测的准确性,但是社交网络产生的数据规模十分巨大,如Twitter和新浪微博各自有五亿多用户,每天新产生数亿条消息,如此海量的数据给现有的计算机体系结构和算法带来了不小的挑战。未来的新兴话题发现算法有赖于大规模文档快速聚类算法和大规模社交网络信息传播算法的进步。
5 结论
本文回顾了社交网络中新兴话题发现领域的最新进展,首先,内容突发特征选取和基于突发特征的时序分析方法是研究的主流,但是,突发特征的出现依赖于话题相关的消息数量达到一定的显著水平,因而基于内容突发特征的检测往往不能在第一时间发现新兴话题。接着,阐述了从信息传播模型的角度进行新兴话题发现的有关方法,该方法与主流方法相比,具有实时性高、描述性强等优点,目前已成为研究热点。利用信息传播模型涉及到对用户的影响力的定量表示,现在的方法主要从内容特征、网络拓扑结构特征和话题特征等角度对影响力进行研究,从历史数据中学习出用户的影响力,然而如何估计用户的影响力目前仍然是一个开放的问题。最后,探讨了该领域进一步研究的方向,如社交网络中海量实时数据处理给现有处理手段带来了巨大的挑战,需要从算法和体系结构进行革新,社交网络结构的动态变化和外部环境对社交网络中新兴话题检测造成的影响还需要进一步评估等。
[1] Victor Lavrenko, James Allan, Edward DeGuzman, et al. Relevance models for topic detection and tracking[C]// Proceedings of the 2nd International Conference on Human Language Technology Research. San Francisco, USA, 2002: 115-121.
[2] 洪宇, 张宇, 刘挺等. 话题检测与跟踪的评测及研究综述[J]. 中文信息学报, 2007, 21(6): 71-87.
[3] James Allan, Victor Lavrenko, Daniella Malin, et al. Detections, bounds, and timelines: Umass and tdt-3[C]// Proceedings of Topic Detection and Tracking Workshop. Vienna, VA, 2000: 167-174.
[4] James Allan, Jaime G Carbonell, George Doddington, et al. Topic detection and tracking pilot study final report[C]// Proceedings of the DARPA Broadcast News Transcription and Understanding Workshop. 1998: 194-218.
[5] Yiming Yang, Thomas Pierce, Brian T Archibald, et al. Learning approaches for detecting and tracking news events[J]. IEEE Intelligent Systems, 1999, 14(4): 32-43.
[6] Douglass R Cutting, David R Karger, Jan O Pedersen, et al. Scatter/gather: A cluster-based approach to browsing large document collections[C]//Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval. 1992: 318-329.
[7] 于满泉, 骆卫华, 许洪波等. 话题识别与跟踪中的层次化话题识别技术研究[J]. 计算机研究与发展, 2006, 43(3): 489-495.
[8] David Arthur and Sergei Vassilvitskii. k-means++: The advantages of careful seeding[C]//Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, Society for Industrial and Applied Mathematics. Philadelphia, USA, 2007: 1027-1035.
[9] D. Sculley. Web Scale K-Means clustering[C]//Proceedings of the 19th international conference on World Wide Web. New York, USA, 2010: 1177-1178.
[10] 张小明,李舟军,巢文涵.基于增量型聚类的自动话题检测研究[J]. 软件学报, 2012, 23(6): 1578-1587.
[11] Thomas Hofmann. Probabilistic latent semantic indexing[C]//Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval. New York, USA, 1999: 50-57.
[12] David M. Blei, Andrew Y. Ng, Michael I. Jordan. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research , 2003, 3: 993-1022.
[13] 单斌, 李芳. 基于LDA话题演化研究方法综述[J]. 中文信息学报, 2010, 24(6): 43-68.
[14] Scott Deerwester, Susan T. Dumais, George W. Furnas, et al. Indexing by latent semantic analysis[J]. Journal of the American society for information science, 1990, 41(6): 391-407.
[15] Wei Xu, Xin Liu, and Yihong Gong. Document clustering based on non-negative matrix factorization[C]//Proceedings of the 26th annual international ACM SIGIR conference on Research and development in information retrieval. New York, USA, 2003: 267-273.
[16] 路荣, 项亮, 刘明荣等. 基于隐主题分析和文本聚类的微博客中新闻话题的发现[J]. 模式识别与人工智能, 2012, 25(3): 382-387.
[17] Kanagasabi Rajaraman, Ah-Hwee Tan. Topic Detect ion, Tracking, and Trend Analysis Using Self-Organizing Neural Networks[C]//Proceedings of the 5th Pacific-Asia Conference on Knowledge Discovery and Data Mining. London, UK, 2001: 102-107.
[18] Xia Hu, Jiliang Tang, Huan Liu. Leveraging knowle dge across media for spammer detection in microblogging[C]//Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval. New York, USA, 2014: 547-556.
[19] X.-H. Phan, L.-M. Nguyen, S. Horiguchi. Learning to classify short and sparse text & web with hidden topics from large-scale data collections[C]//Proceeding of the 17th WWW. Beijing, China, 2008: 91- 100.
[20] Adrien Guille, Hakim Hacid, Cecile Favre, et al. Information diffusion in online social networks: A survey[J]. ACM SIGMOD Record, 2013, 42(2): 31-36.
[21] Jon Kleinberg. Bursty and Hierarchical Structure in Streams[C]//Proceedings of the eighth ACM SIGKDD international conference on knowledge discovery and data mining. Edmonton, Canada, 2002: 91- 101.
[22] Jure Leskovec, Lars Backstrom, Jon Kleinberg. Meme-tracking and the dynamics of the news cycle[C]// Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. Paris, France, 2009: 497-506.
[23] Ruchi Parikh, Kamalakar Karlapalem. ET: events from tweets[C]//Proceedings of the 22nd international conference on World Wide Web. Republic and Canton of Geneva, Switzerland, 2013: 613-620.
[24] Michael Mathioudakis, Nick Koudas. TwitterMonitor: Trend Detection over the Twitter Stream[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of data. New York, USA, 2010: 1155-1158.
[25] David A Shamma Lyndon Kennedy, Elizabeth F Churchil. Peaks and persistence: modeling the shape of microblog conversation[C]//Proceedings of the ACM 2011 conference on Computer supported cooperative work. New York, NY, USA, 2011: 355-358.
[26] Mario Cataldi, Luigi Di Caro, Claudio Schifanella. Emerging Topic Detection on twitter based on temporal and social terms evaluation[C]//Proceedings of the Tenth International Workshop on Multimedia Data Mining. New York, USA, 2010: 4-13.
[27] G Salton, C Buckley. Term-weighting approaches in automatic text retrieval[J]. Information Processing and Management, 1988: 513-523.
[28] Matthew D Hoffman, David M Blei, Francis R Bach. Online Learning for Latent Dirichlet Allocation[C]// Proceedings of NIPS Vancouver, Canada, 2010: 856-864.
[29] Rishabh Mehrotra, Scott Sanner, Wray Buntine, et al. Improving LDA topic models for microblogs via tweet pooling and automatic labeling[C]//Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. New York, USA, 2013: 889-892.
[30] Jianshu Weng, Bu-Sung Li. Event Detection in Twitter[C]//Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media. Barcelona, Spain, 2011: 401-408.
[31] Chenliang Li, Aixin Sun, Anwitaman Datta. Twevent: segment-based event detection from tweets[C]//Proceedings of the 21st ACM international conference on Information and knowledge management. New York, USA, 2012: 155-164.
[32] 贺敏, 王丽宏, 杜攀等. 基于有意义串聚类的微博热点话题发现方法[J]. 通信学报, 2013, (Z1): 256-262.
[33] Toshimitsu Takahashi, Ryota Tomioka, Kenji Yamanishi. Discovering Emerging Topics in Social Streams via Link Anomaly Detection[C]//Proceedings of the 2011 IEEE 11th International Conference on Data Mining. Washington, DC, USA, 2011: 1230-1235.
[34] Adrien Guille, Cécile Favre. Mention-anomaly-based Event Detection and Tracking in Twitter[C]//Proceedings of the IEEE/ACM International Conference on Advances in Social Network Analysis and Mining. Beijing, China, 2014.
[35] Yan Chen, Hadi Amiri, Zhoujun Li, et al. Emerging Topic Detection for Organization from Microblogs[C]// Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. New York, USA, 2013: 43-52.
[36] Rong Lu, Qing Yang. Trend Analysis of News Topics on Twitter[J]. International Journal of Machine Learning and Computing, 2012, 2(3): 327-332.
[37] Jacob Goldenberg Barak Libai, Eitan Muller. Talk of the network: A complex systems look at the underlying process of word-of-mouth[J]. Marketing Letters, 2001, 12(3): 211-223.
[38] David Kempe, Jon Kleinberg, éva Tardos. Maximizing the spread of influence through a social network[C]// Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. New York, USA, 2003: 137-146.
[39] Kazumi Saito, Masahiro Kimura, Kouzou Ohara, et al. Learning Continuous-Time Information Diffusion Model for Social Behavioral Data Analysis[C]//Proceedings of the 1st Asian Conference on Machine Learning: Advances in Machine Learning. Berlin, Heidelberg, 2009: 322-337.
[40] Kazumi Saito, Masahiro Kimura, Kouzou Ohara, et al. Selecting information diffusion models over social networks for behavioral analysis[C]//Proceedings of the 2010 European conference on Machine learning and knowledge discovery in databases. Berlin, Heidelberg, 2010.
[41] 王巍, 李锐光, 周渊等. 基于用户与节点规模的微博突发话题传播预测算法[J]. 通信学报, 2013, (Z1): 84-91.
[42] Jure Leskovec, Andreas Krause, Carlos Guestrin, et al. Cost-effective Outbreak Detection in Networks[C]// Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. New York, USA, 2007: 420-429.
[43] 赫南, 李德毅, 淦文燕等. 复杂网络中重要性节点发掘综述[J]. 计算机科学, 2007, 34 (12): 1-5.
[44] 孙睿, 罗万伯. 网络舆论中节点重要性评估方法综述[J]. 计算机应用研究, 2012, 29(10): 3606-3608.
[45] 刘建国, 任卓明, 郭强等. 复杂网络中节点重要性排序的研究进展[J]. 物理学报, 2013, 62(17): 178901.
[46] 赵之滢, 于海, 朱志良等. 基于网络社团结构的节点传播影响力分析[J]. 计算机学报, 2014, 37(4): 753-766.
[47] 汪小帆, 李翔, 陈关荣. 网络科学导论[M]. 北京: 高等教育出版社, 2012.
[48] Maksim Kitsak, Lazaros K. Gallos, Shlomo Havlin, et al. Identifying influential spreaders in complex networks[J]. Nature Physics, 2010, 6(11): 888-893.
[49] Antonios Garas, Frank Schweitzer, Shlomo Havlin. A k-shell decomposition method for weighted networks[J]. New Journal of Physics, 2012, 14(8): 083030.
[50] Haewoon Kwak, Changhyun Lee, Hosung Park, et al. What is Twitter, a Social Network or a News Media?[C]// Proceedings of the 19th international conference on World Wide Web. New York, USA, 2010: 591-600.
[51] J. Yang, J. Leskovec. Patterns of temporal variation in online media[C]//Proceedings of the fourth ACM international conference on web search and data mining. New York, USA, 2011: 177-186.
[52] Ronald Fagin, Ravi Kumar, D. Sivakumar. Comparing top k lists[C]//Proceedings of the fourteenth annual ACM-SIAM symposium on discrete algorithms. Philadelphia, USA, 2003: 28-36.
[53] Jianshu Weng, Ee-Peng Lim, Jing Jiang et al. TwitterRank: Finding Topic-sensitive Influential Twitterers[C]// Proceedings of the third ACM international conference on Web search and data mining. New York, USA, 2010: 261-270.
[54] Sergey Brin, Lawrence Page. The anatomy of a large-scale hypertextual Web search engine[C]//Proceedings of the seventh international conference on World Wide Web. Amsterdam, The Netherlands, 2013: 107-117.
[55] Liyuan Lü, Yi-cheng Zhang, Chi Ho Yeung. et al. Leaders in Social Networks, the Delicious Case[J]. PLoS One, 2011, 6: e21202.
[56] Jie Tang, Jimeng Sun, Chi Wang, et al. Social Influence Analysis in Large-scale Networks[C]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. New York, USA, 2009: 807-816.
[57] Jie Tang, Sen Wu, Jimeng Sun. Confluence: Conformity Influence in Large Social Networks[C]// Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. New York, USA, 2013: 347-355.
[58] Lu Liu, Jie Tang, Jiawei Han, et al. Learning Influence from Heterogeneous Social Networks[J]. Data Mining and Knowledge Discovery, 2012, 25(3): 511-544.
[59] Jingwen Bian, Yang Yang, Tat-Seng Chua. Predicting Trending Message and Diffusion Participants in Microblogging Network[C]//Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval. New York, USA, 2014: 537-546.
[60] M. Farajtabar, M. Gomez-Rodriguez, Y. Wang, et al. Co-evolutionary Dynamics of Information Diffusion and Network Structure[C]//Proceedings of the 24th International Conference on World Wide Web Companion. Republic and Canton of Geneva, Switzerland, 2015: 619-620.
[61] S. A. Myers, J. Leskovec. The Bursty Dynamics of the Twitter Information Network[C]//Proceedings of the 23rd international conference on World Wide Web. New York, USA, 2014: 913-924.
[62] S. A. Myers, J. Leskovec. Clash of the contagions: Cooperation and competition in information diffusion[C]// Proceedings of the 12th International Conference on Data Mining. Brussels, Belgium, 2012: 539-548.
Emerging Topic Detection in Online Social Networks: A Survey
GOU Chengcheng1,2, DU Pan1, LIU Yue1, CHENG Xueqi1
(1. CAS Key Lab of Network Data Science and Technology,Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China) (2. University of Chinese Academy of Sciences, Beijing 100190, China)
Emerging topic detection is one of the major research focus in Social Network Analysis. The openness of social networks, microblog in particular, provides unprecedented favorable conditions on which the topics might rage and outbreak. The emerging topics are often accompanied by big news or events, which are about to outbreak and have a significant social impact. How to identify these topics in the early stages is the major research content of the emerging topic detection. The main developments in the field of the emerging topic detection in the recent years are reviewed and the relevant concepts, methods and theory are elaborated. The methods of the emerging topic detection are analyzed and discussed form the perspective of the content bursty feature and information diffusion models. Finally we conclude the paper with an exploration of future research directions.
emerging topic; topic detection; information diffusion; social network

笱程成(1985—),博士研究生,主要研究领域为社交网络,数据挖掘,机器学习。E⁃mail:gouchengcheng@software.ict.ac.cn杜攀(1981—),博士,助理研究员,主要研究领域为信息检索,数据挖掘,机器学习。E⁃mail:dupan@software.ict.ac.cn刘悦(1971—),博士,副研究员,主要研究领域为信息检索,数据挖掘,机器学习。E⁃mail:liuyue@ict.ac.cn
1003-0077(2016)05-0009-10
2015-05-04 定稿日期: 2016-02-03
国家“九七三”重点基础研究计划基金(2012CB316303,2014CB340401);国家“八六三”高技术研究发展计划基金(2015AA015803,2014AA015204);中国科学院重点部署项目(KGZD-EW-T03-2);国家自然科学基金(61232010,61572473,61303156);国家242信息安全计划基金(2015F028);山东省自主创新及成果转化专项(2014CGZH1103);欧盟第七科技框架计划项目(FP7)(PIRSES-GA-2012-318939)
TP
A
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
机械工业标准化与质量(2022年6期)2022-08-12
意林彩版(2022年2期)2022-05-03
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
好日子(2021年8期)2021-11-04
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
第一财经(2020年4期)2020-04-14
当代陕西(2019年10期)2019-06-03
文苑(2018年17期)2018-11-09
