
基于地域特征和异构社交关系的事件推荐算法研究
2016-05-04 02:54:31纪现才曹亚男
中文信息学报 2016年5期
乔 治,周 川,纪现才,曹亚男,郭 莉
(1. 中国科学院 计算技术研究所 北京100190; 2. 中国科学院大学 北京100049; 3. 中国科学院 信息工程研究所 北京100093)
基于地域特征和异构社交关系的事件推荐算法研究
乔 治1,2,周 川2,3,纪现才3,曹亚男3,郭 莉3
(1. 中国科学院 计算技术研究所 北京100190; 2. 中国科学院大学 北京100049; 3. 中国科学院 信息工程研究所 北京100093)
近几年,在基于事件的社交网络(EBSNs)服务中,为便于增强用户体验,事件推荐任务一直被广泛研究。本文基于对EBSN中用户行为数据的详细分析,提出了一种新型的融合多种数据特征的潜在因子模型。该模型综合考虑EBSN中两种新型的数据特征: 异构的社交关系特征(线上社交关系+线下社交关系)和用户参与行为的地域性特征。基于真实的Meetup数据集,实验结果表明我们的算法在解决事件推荐问题时比传统的算法有更好的性能。
事件推荐;基于事件的社交网络;用户行为倾向;协从过滤;地域特征;异构社交关系
1 引言
近年来,基于事件的社交网络(EBSN)快速发展,积累了大量的用户群体并深受广大用户的喜欢。这种新型社交网络服务的主要应用包括国内的豆瓣同城以及美国的Meetup等网站。这种服务主要给用户提供一种组织、参与、评论和分享线下事件(如酒会、沙龙、演唱会等)的平台。面向该应用场景的事件推荐任务,获得国内外研究者的广泛研究和探索。事件推荐任务旨在为用户推荐最相关、最感兴趣以及用户最有可能参与的事件。从网络服务的宏观角度看,该任务无论对于线下事件的组织者还是事件的参与者都提供便利。对于事件的组织者,线下活动可以被自动地推送给合适的用户群从而吸引更多感兴趣的用户参与;对于事件的参与者,推荐任务可以过滤不相关事件,使得用户可以从海量的信息中快速发现自己可能喜欢的事件。
区别于已有的推荐问题[1-4],在EBSN中的事件推荐任务面临以下数据特征所带来的挑战。
• 地域特征。根据数据分析,我们发现用户在选择参与线下事件时,存在区域倾向性。即用户除了对事件内容有个体性兴趣倾向外,用户对于事件举办地点的喜好也会影响用户对于某一事件的参与行为。
• 异构社交关系特征。在基于事件的社交网络中存在两种社交关系。一种是线上社交关系,即传统社交网络应用中关联用户的社交关系。用户通过EBSN中的线上社交网络可以互相沟通、分享感兴趣的事件以及体验。第二种社交关系是线下社交关系。在数据挖掘顶级会议KDD-12[5]上,IBM研究院的研究人员在分析基于事件的社交网络数据时提出并定义了这种新型的社交关系。这种关系的纽带是线下事件。当用户参与了同一线下事件时,他们势必会有面对面的交流与互动,这种线下的关联是对虚拟社交关联的补充,被定义为线下社交关系。在EBSN中,同时存在着两种异构的社交关联。
EBSN数据的上述两种特征给我们的问题分析和建模带来了新的挑战。为设计有效的推荐算法,我们需要联合考虑上述两种数据特征。在本文中,我们提出了一种新型的潜在因子模型(简写为HeSi),该模型综合考虑了异构社交信息与区域倾向性,有效地解决了事件推荐问题。实验表明,我们所设计的HeSi算法在解决事件推荐问题时比传统的算法在精度上提高了近5%。
2 基于事件的社交网络数据分析
在本文中,我们选择Meetup数据集作为重点分析对象。Meetup网站是世界知名的EBSN应用,该数据集主要取自Meetup网站的用户对线下活动的参与行为的数据。IBM研究人员在采集和清洗后开源了该数据集供研究者使用,并在KDD-12[5]中针对以Meetup网站为代表的一类EBSN应用做了详细的数据分析工作。该论文的研究成果表明线下事件与参与者多在同一个地理区域。因此,我们从该数据集中选取五个有代表性的城市进行数据分析,(包括纽约、洛杉矶、休斯顿、芝加哥和旧金山)。首先,统计这些城市中的用户和事件数量,如表1所示;然后,分析数据集的地域特性和异构社交关系特性。数据分析结果将在下文进行详细介绍。

表1 数据集信息统计[6]
2.1 地域特性
在文献[6]中,作者清洗并获得了北美五座城市的事件数据(表1),并对基于事件的社交网络数据的地域特征做了详细的分析,图1展示了休斯顿 数据的聚类结果。直观上来看,每个类簇内的大多数事件呈中央集中型分布,同一颜色的点越密集表示该区域内发生的事件越多。采用均值法求出每个类簇的中心点坐标,发现中心点所在区域大多位于休斯顿当地的步行街、购物中心等繁华场所。因此,本文提出假设,社交事件一般发生在繁华区域并以这些区域为中心呈集中型分布。
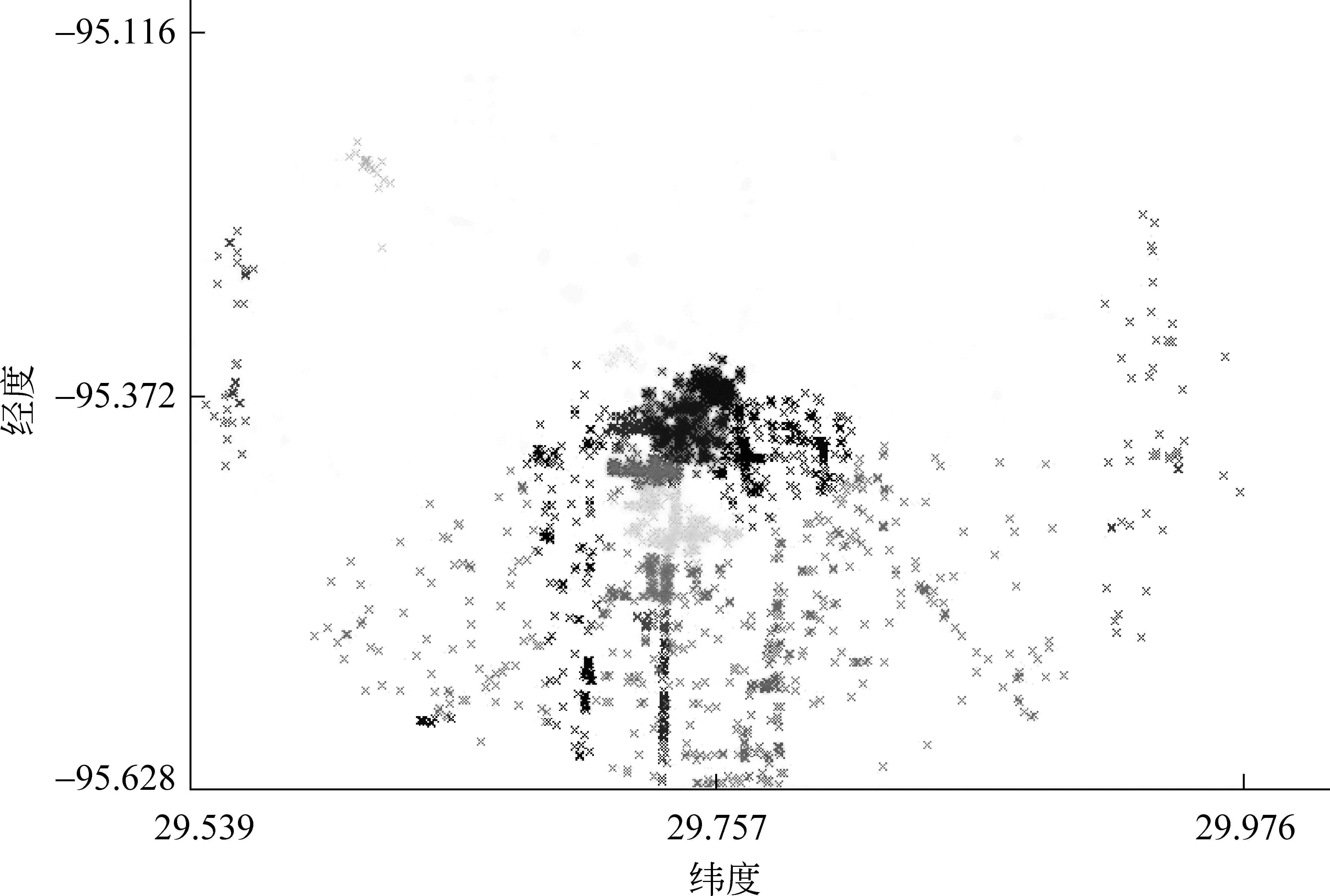
图1 基于事件地理坐标的休斯顿数据的聚类分析注: 置类簇数目为20,将不同类簇的事件用不同颜色进行标记;每一个点表示在该城市内组织的一个事件,横纵坐标分别表示纬度和经度,相同颜色的点表示从属同一个聚类[6]
区域倾向性 线下事件区域呈集中性特点的基础上,在文献[6]中,作者又进一步分析数据发现了区域倾向性。假设将每一个类簇看作一个区域,那么每个城市均被划分为20个区域,以用户为关注点,我们分别统计每个城市中用户参与事件的行为数据。分析结果表明: (1)超过80%以上的用户仅访问了不到六个区域,如图2所示; (2)大多数用户对每个访问区域的平均访问次数超过一次,如图3所示。可见,用户对不同区域事件的参与并不是随机的,而是带有明显的个体倾向性,即较频繁地访问自己感兴趣的区域。
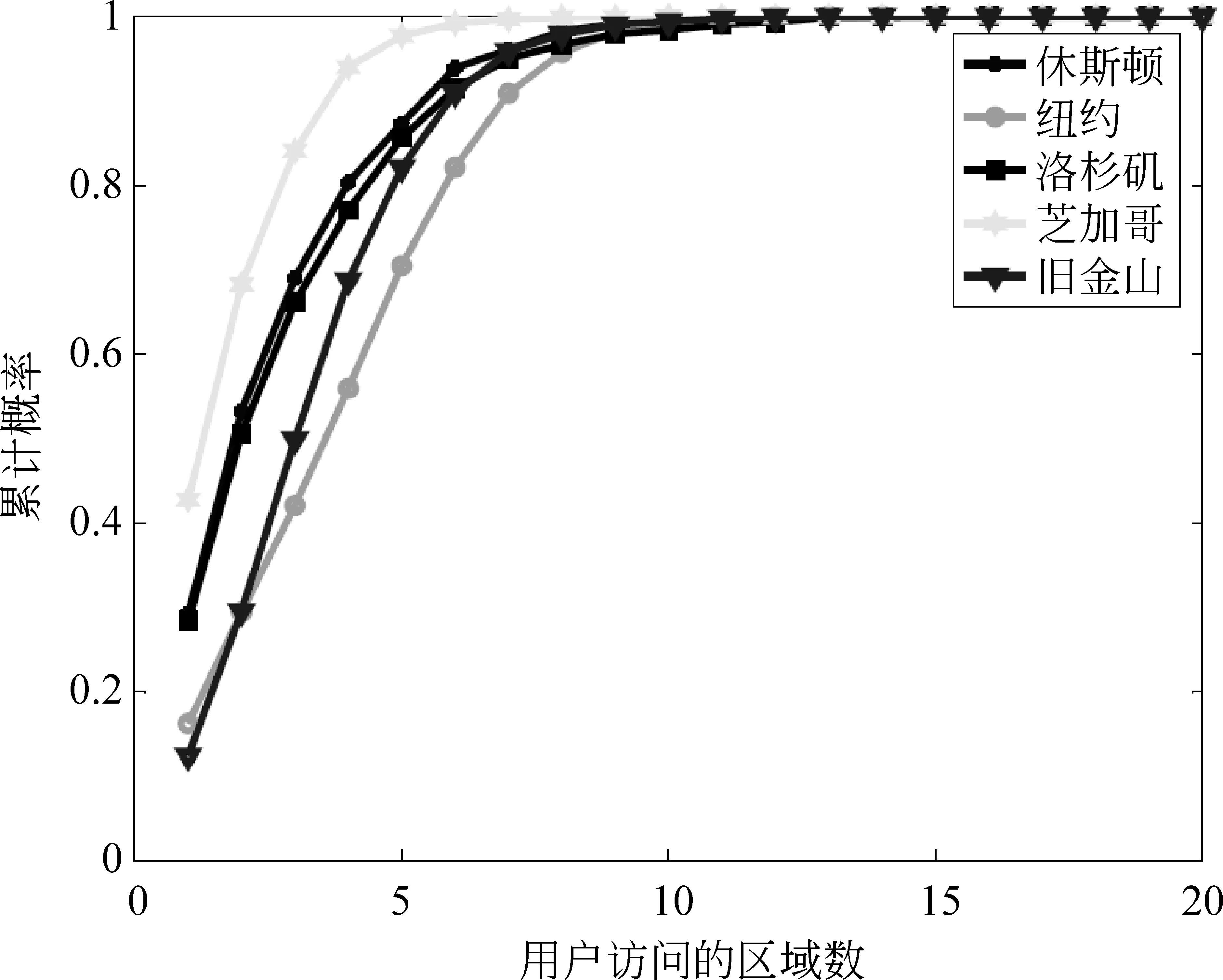
图2 用户访问区域数的累计概率[6]
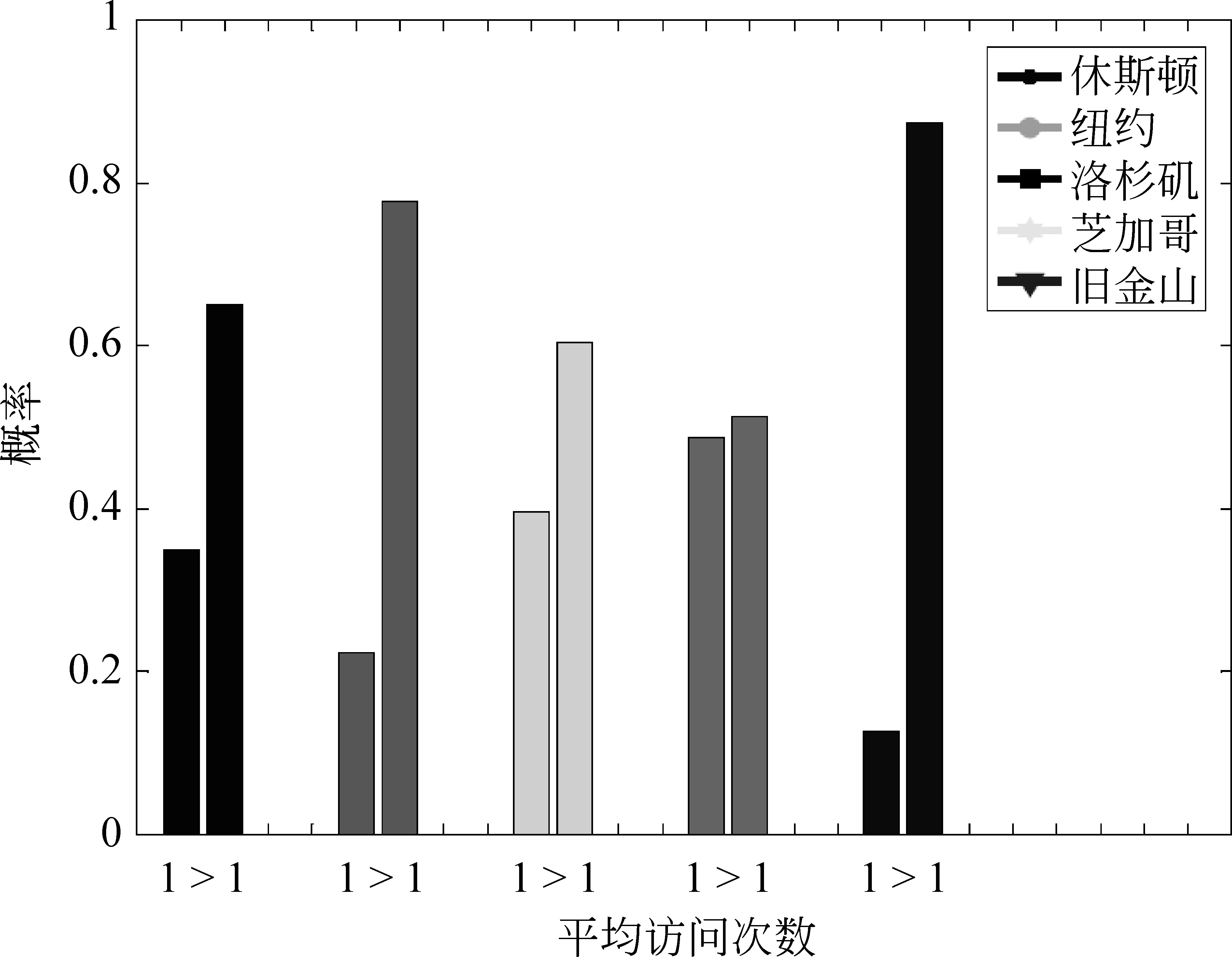
图3 用户平均访问次数在1和>1两种情况下的概率分布[6]
2.2 异构社交关系
针对本文的事件推荐任务,我们首先定义三种实体集合,包括用户U、事件V和事件位置VL,以及两种异构的社交网络: 线上社交网络Gon和线下社交网络Goff。其中U={u1,u2,…,un}表示用户集合,V={v1,v2,…,vm}表示事件集合,对于每一个事件vi都具有描述该事件的位置信息。线上社交网络Gon描述所有用户的线上社交关系,线下社交网络Goff描述所有用户的线下社交关系。
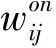
(1)
其中,G(ui)表示任意用户ui参与的线上社交组的集合;|G(ui)∩G(uj)|表示用户ui和uj参与的相同社交组的数量;分母|G(ui)∪G(uj)|表示用户ui和uj各自参与的社交组的并集的基数。
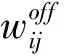
(2)
其中,E(ui)表示用户ui参与的线下事件的集合;|E(ui)∩E(uj)|表示用户ui和uj参与的相同线下事件的数量;分母|E(ui)∪E(uj)|表示用户ui和uj各自参与的事件并集的基数。
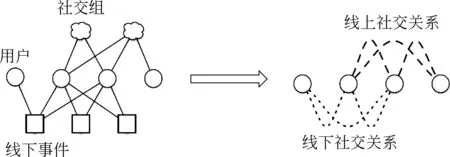
图4 EBSN中的异构社交关系
2.3 问题定义
事件推荐任务旨在为用户推荐其可能感兴趣的事件。本文将推荐问题转变为排序问题,即根据用户对于各个事件的感兴趣程度对事件排序,将排名靠前的事件推荐给用户。因此,事件推荐的核心任务即如何估计用户对事件的感兴趣程度。我们定义评分r(ui,vj)度量用户ui对事件vj的感兴趣程度。基于本节数据分析结果,我们提出了一种基于矩阵因子分解技术的混合评分模型,将区域倾向性特征和异构社交关系特征引入兴趣评估模型。矩阵因子分解模型是一种简单、实用、高效的方法,可以灵活内嵌异构属性,目前已被广泛应用。我们希望通过引入两种新的特征来提高事件推荐的性能。
3 相关工作
近年来,推荐问题已经受到了国内外研究者的广泛关注。推荐算法可大致分为基于上下文的推荐和协从过滤两大类。其中矩阵因子分解模型被广泛地应用到推荐系统应用中并获得了较好的性能。在矩阵因子分解模型中,通过计算模型预测值与实际值的差值来度量估计误差,如下式所示。
(3)
其中第一项为最小二乘的误差评估函数,r(ui,vj)是模型预测值,Rij是实际评分值,Iij是指示变量,用来描述用户ui是否参与了对事件vj的评分;为防止过拟合,我们引入了两项正则化项‖Ui‖2和‖Vj‖2,它们分别是变量Ui和Vj的二范式。
目前,随着各种新型网络应用的出现和发展,为了应对新型网络特征带来的挑战,推荐算法得到了进一步的增强和改进[6-12]。这些研究工作将多种新特征引入到推荐算法中从而提高推荐精度,包括社交关联、地理信息等。
引入社交关联的推荐算法主要包括基于社交关系的协从过滤和通过社交正则对评分行为做纠正的方法[13-16]。Fengkun Liu等[14]将社交关系应用于用户间相似度的计算,提出了一种新型的协从过滤算法。该算法与传统的基于行为相似度的协从过滤算法相比可以获得精度的提升;然而当评分数据较稀疏时,算法性能并没有明显的优势。Irwin King等[15]将用户看作节点,将社交关系看作节点间的关联提出了一种基于连续条件随机场的社交推荐框架,以高昂的时间开销换取了较高的精度。Hao Ma等[16]提出了一种社交正则的协从推荐方法,巧妙地将社交关系引入矩阵因子分解模型从而有效提高了算法精度。因此,在本文中,我们也采用社交正则的方法,将异构社交关系引入误差函数,对模型参数作纠正。
考虑地理信息的推荐算法主要包括基于距离的协从推荐和面向位置信息的用户行为倾向建模[17-23]。移动互联网的兴起使人们意识到位置信息对于用户行为估计的影响,因此协从地理位置信息的推荐算法研究得到了广泛的关注。其中,大多数研究工作仅依据位置信息进行推荐,例如S Chaudhuri等[24]采用KNN方法为用户推荐最近的其他用户信息。然而,在事件推荐问题中,推荐的核心在于事件位置信息只是辅助问题研究的特征之一。另外,有一类研究工作探索位置信息对于推荐性能的影响,例如N Bruno等[25]提出了Top-K的改进算法为用户推荐距离较近的商品;Peng Zhang等[27]使用用户的地理位置信息对用户分组,探索不同用户组对于商品类别的倾向性,提出了新型的评分算法。然而基于位置的用户分组并不适用于基于事件的社交网络中的事件推荐任务,相比之下基于位置的事件分组所呈现的用户行为具有更明显的区域倾向的特征。
我们基于事件推荐问题特有的数据特点,尝试联合建模地域特性和社交关系两种特征提高推荐算法的性能。
4 联合建模地域特性和社交关系的事件推荐框架
4.1 混合评分
为了便于联合建模用户个体兴趣与区域倾向,我们使用文献[6]中的混合评分模型,它由个体兴趣评分和区域倾向评分两部分加权生成。
(4)
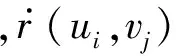
个体兴趣评分 类似于基于矩阵分解的潜在因子模型,假设因子向量的维度为l,定义每一个用户ui有一个潜在的维因子向量Ui∈Rl,每一个事件vj也有一个潜在的l维因子向量Vj∈Rl。我们将因子空间看作兴趣空间,使用因子向量描述用户或事件在因子空间的投影,那么用户的个体特性决定了其在因子空间的兴趣分布,线下事件在因子空间的投影反应了事件的兴趣分布。因此,可以使用向量内积来计算用户对于事件的个体兴趣评分,如下所示:
(5)
区域倾向评分 由于用户对事件所处地理位置的喜好也会影响用户参与该事件的行为倾向,因此我们我们需要对用户的区域倾向性进行评价。通过2.1节的数据分析,我们发现事件呈区域集中式分布,即是图中同种颜色的类簇由中心向外的发散特点。分析类簇中心点所在的具体位置,发现类簇多集中在城市内的商业街或金融街一类繁华的地段。因此,可以将事件聚类结果看作对相应城市的区域划分。我们可以使用聚类的方法获得事件的近似区域。我们使用文献[6]中区域倾向评分的建模方式去建模此处的区域倾向评分。与个体兴趣评分类似,我们为每一个用户ui定义区域相关的因子向量Πi,为每个区域定义区域相关的因子向量Mk。用向量Πi和Mk的内积表示用户ui对第k个区域的倾向评分。由于事件类簇只是对实际区域的近似,因此我们引入从属因子Cjk来表示第j个事件属于第k个区域的概率。最终,用户对区域的倾向性评分是通过对事件所处各个区域的评分加权求得的,赋予权值的依据是事件对区域的从属概率。
(6)
为了求解Cjk,我们首先假设每一个区域内的事件呈高斯分布,定义参数(μ,∑)描述区域特征,其中μ表示均值向量,∑表示协方差矩阵。因此,可以通过式(7)对Cjk进行求解。
(7)
其中,N(Li|μk,Σk)表示用户ui的位置Li出现在区域k的概率密度。
4.2HeSi模型
鉴于矩阵因子分解模型在精度和效率等方面的优越性,我们将上一节中的混合评分函数嵌入矩阵因子分解模型中,误差评估函数中的模型预测值采用式(4),并为参数Π和M增加二范式正则项以便约束参数的取值范围。从而获得以下目标函数。
(8)
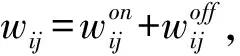
(9)
HeSi目标优化函数 将异构社交正则[见公式(8)]应用到基于混合评分的矩阵因子分解模型[见公式(9)]中, 获得最终的目标优化函数,如式(10)所示。
(10)
4.3 参数学习
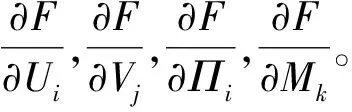
5 实验结果及分析
本节主要通过使用真实网络应用数据集来验证事件推荐算法的性能。在本节中,首先介绍实验数据集和评价指标,然后介绍对比方法,最后对实验结果进行讨论。
5.1 数据集
我们主要采用Meetup数据集作为我们的实验数据集。如文章第三部分所示,我们首先抽取出美国五座代表型城市的相关数据构造五个实验数据集合,每座城市的数据集合包括该城市内注册的用户、注册的事件以及发生的参与行为。数据的详细信息已在表1中详细阐述。
5.2 评价指标
为了便于评价事件推荐算法的性能,我们采用三种标准的评价方法AUC、P@k以及MAP。
1) AUC评价方法可以用来度量整体的分类结果。在本实验数据集中未评分事件占较大比例,AUC评价方法恰适合于不平衡数据。具体计算过程如式(9)所示。
(19)
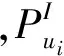
2) P@k指Top-k个估计值中正确估值的比例,多用于排序问题。在事件推荐任务,把评分较高的事件推荐给用户,也可看作为排序问题。
3) MAP是P@k的均值,指算法在选择不同Top-k时的精度的均值,可根据式(20)计算。
(20)
其中L(u)描述采用模型估计出的用户u对各个事件评分的降序排列,Lk(u)描述这个排序中兴趣度第k大的事件,函数I是指示函数。

算法1:HeSi模型学习输入:评分数据R、线上社交关系Won、线下社交关系Woff、地理位置信息、参数Θ、区域数K输出:用户兴趣因子U、事件兴趣因子V、用户区域倾向因子Π、区域因子M01 初始化模型参数U,V,Π,M02 使用K⁃Means算法聚类事件产生K个区域03 计算每个区域的特有参数(μ,∑i),i=1,…,K04 计算事件与区域的从属概率Cij,参见公式(7)

05 定义并初始化变量P=006 计算当前参数下模型误差值Q(使用公式(8)的第一部分)07 WhileQ-P>ε08 P=Q09 采用公式计算目标函数在当前参数值下的偏导数,参见公式(15)~(18)10 采用公式更新模型参数,参见公式(11)~(14)11 计算模型误差值Q12 EndWhile13 返回当前的参数值计算模型误差值Q14 EndWhile
5.3 对比方法
我们使用以下四种模型与Hesi模型进行对比,它们分别是: 1)矩阵因子分解(MF)[26]; 2)基于社交正则的矩阵因子分解(MFs); 3)基于异构社交正则的矩阵因子分解(MFh); 4)基于区域倾向的矩阵因子分解(gMF)。
5.4 实验结果
参数α讨论 在混合评分中,参数α联合个体兴趣评分和区域倾向评分,并决定两种评分的比重,见等式(4)。因此,我们首先讨论参数α的取值对于模型性能的影响。此处,使用AUC评价方法,在五个数据集上,分别测试模型在不同的α取值(0.91~0.99)下,模型精度的变化。实验结果显示图5中。如图所示,在五个数据集上,模型精度伴随着α取值的变化而轻微变化,在0.95附近出现明显的波动,并取得近似局部最优值。因此,在后边的实验中,我们定义α取值为0.95。
整体性能评价 为了便于验证算法整体的分类性能,我们首先在五个实验数据集上,使用AUC评价标准,对比HeSi算法与其他四种算法的性能优劣。实验结果如表2所示。从实验结果中,我们可以发现以下五个特征: 1)矩阵因子分解的算法可以获得比基于用户/对象相似度的协从过滤算法更高的精度; 2)使用社交正则后的矩阵因子分解算法的性能优于未使用社交正则的矩阵因子分解算法; 3)异构社交正则的方法除了增加了线上社交关系的约束也增加了线下社交关系的约束,比起单纯使用线上社交关系有更好性能; 4)只使用基于区域倾向的矩阵因子分解算法在性能上比其他算法并没有明显优势; 5)基于混合个体兴趣与区域倾向性的矩阵因子分解方法在异构社交正则的约束下可以获得更好的性能。
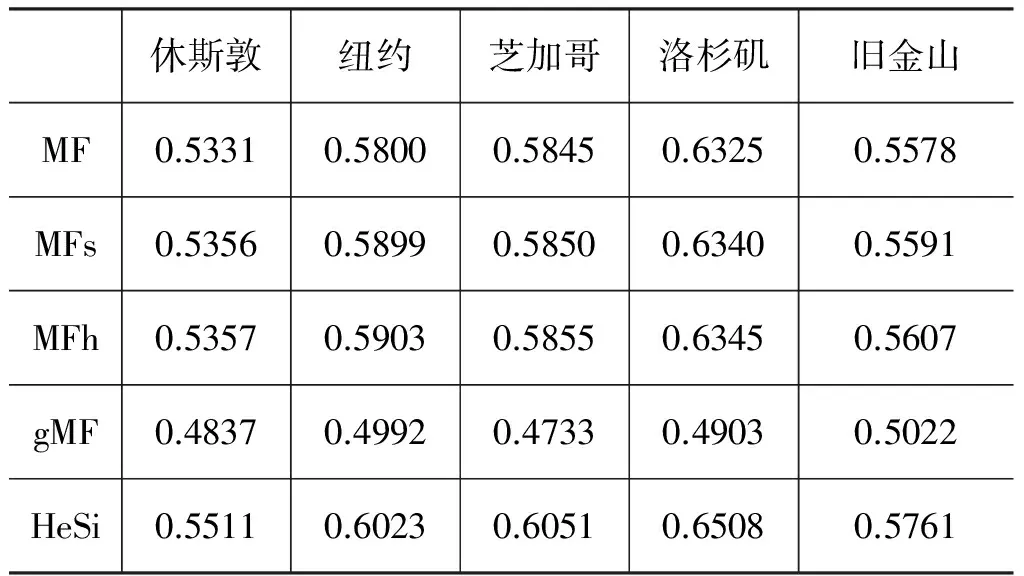
表2 AUC度量的算法准确度评价
推荐结果评价 在真实的应用场景中,用户关注的是被展示的推荐结果,它的准确与否决定了用户体验的优劣。因此,我们采用P@k和MAP方法去评价几个算法的推荐性能。鉴于页面信息的丰富性和用户浏览的随机性,用户通常仅对排名靠前的结果感兴趣而忽略大量剩余的推荐结果,因此我们主要测试了P@1和P@3。此外,我们使用MAP评价算法整体的推荐结果。在之前的性能评价中,我们已经发现矩阵因子分解算法在性能上的优势。因此,我们只是比较HeSi算法和MF、MFh两种算法,实验结果如图6,7,8,9,10所示,采用P@1、P@3和MAP三种指标进行评价,HeSi算法比其他三种算法能得到更好的推荐性能。
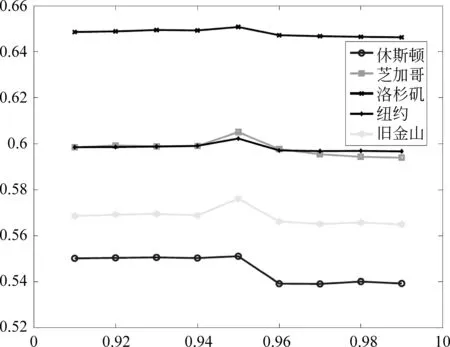
图5 混合因子α在不同取值下对于模型AUC精度的影响
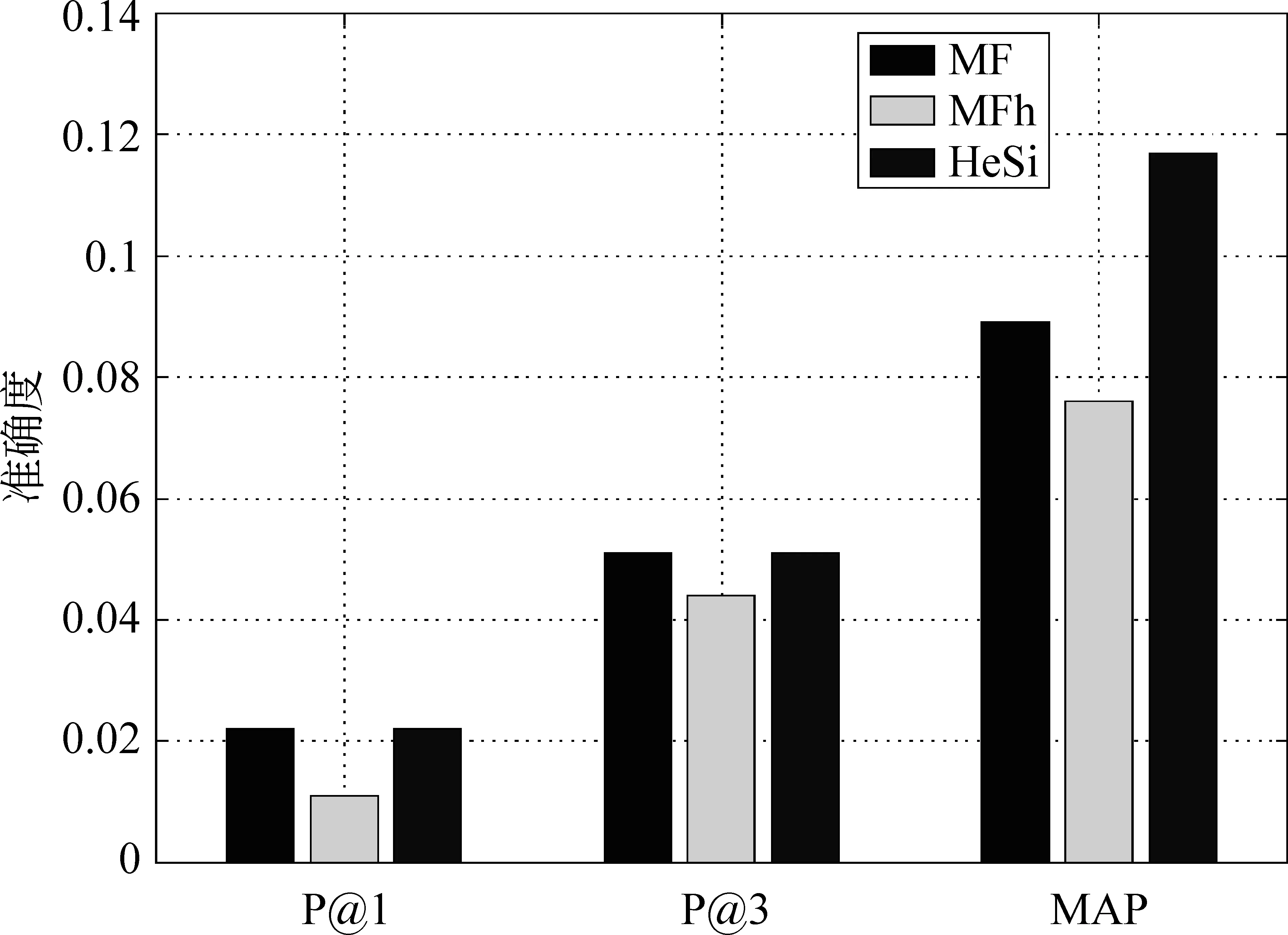
图6 休斯敦数据集在三种不同评价下的算法精度度量
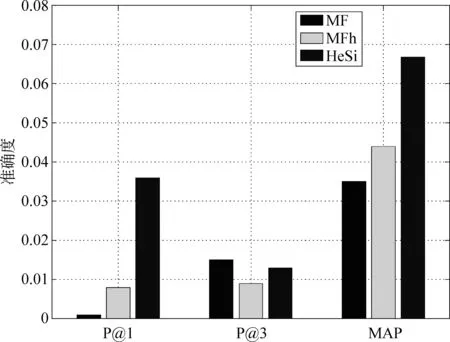
图7 芝加哥数据集在三种不同评价下的算法精度度量
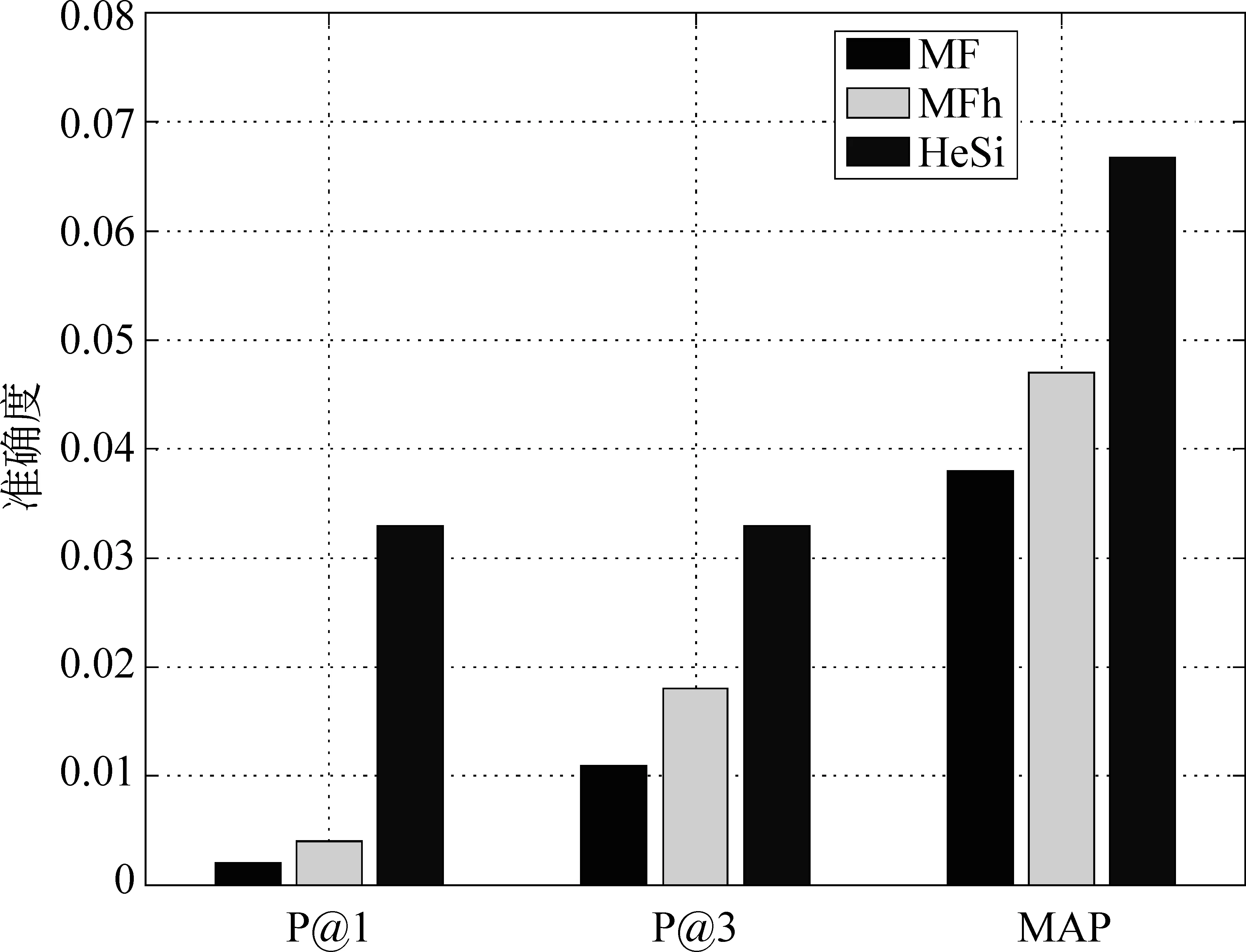
图8 洛杉矶数据集在三种不同评价下的算法精度度量
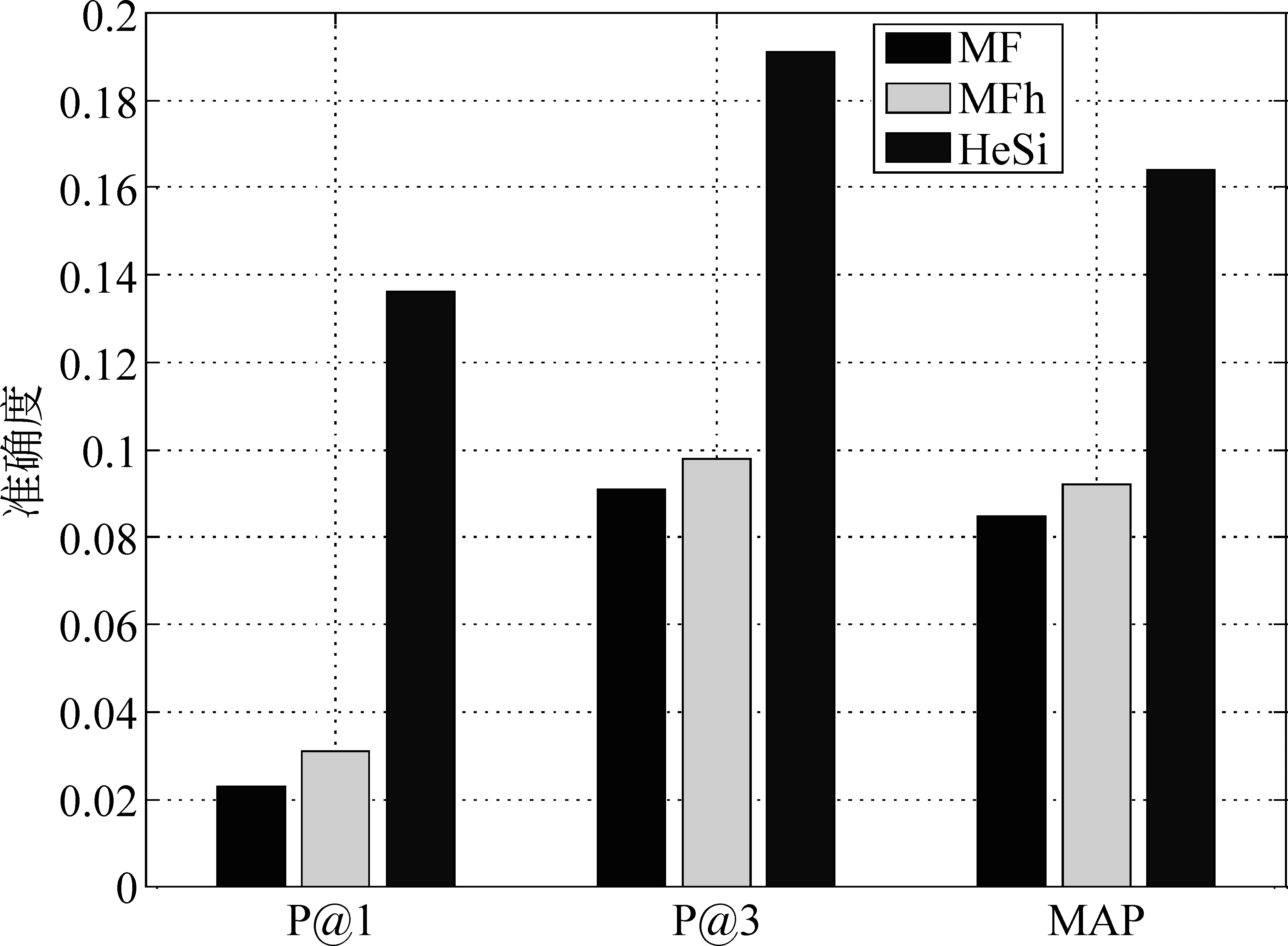
图9 纽约数据集在三种不同评价下的算法精度度量
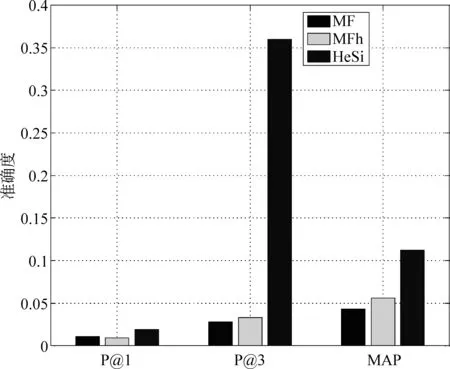
图10 旧金山数据集在三种不同评价下的算法精度度量
6 结论及展望
本文主要探索了社交网络应用中的事件推荐问题。首先,通过分析Meetup数据,发现了EBSN数据的社交关系异构性和区域倾向性。然后,针对这些属性我们提出了融合地理特征和社交关系的HeSi模型,有效地提高了事件推荐的性能。
然而,在真实的应用场景中,新用户行为数据以数据流的形式持续实时到达,数据规模逐步增大。批处理学习难以应对流式数据的挑战。因此,在未来的研究工作中,我们主要关注事件推荐算法的在线学习策略。
[1] 彭泽环,孙乐,韩先培,石贝. 基于排序学习的微博用户推荐[J].中文信息学报, 2013, 27(4):96-102.
[2] 孙建凯,王帅强,马军. Weighted-Tau Rank:一种采用加权Kendall Tau的面向排序的协同过滤算法[J].中文信息学报, 2014, 28(1): 33-40.
[3] 罗成,刘奕群,张敏,马少平,茹立云,张阔. 基于用户意图识别的查询推荐研究[J].中文信息学报, 2014, 28(1): 64-72.
[4] 李锐,王斌.一种基于作者建模的微博检索模型[J].中文信息学报, 2014, 28(2): 136-143.
[5] Liu X, Hey Q, Tiany Y, et al. Event-based social networks linking the online and offline social worlds[C]//Proceeding of the 18th ACM SIGKDD international conference on knowledge discovery and data mining, 2012: 1032-1040.
[6] Qiao Z, Zhang P, Cao Yanan,et al. Combining Heterogeneous Social and Geographical Information for Event Recommendation[C]//Proceeding of 28th AAAI Conference on Artificial Intelligence, 2014: 145-151.
[7] Salakhutdinov R, Mnih A. Probabilistic matrix factorization[C]//In Neural Information Processing Systems, 2008: 880-887.
[8] Somekh O, Aizenberg N, Koren Y. Build your own music recommender by modeling internet radio streams[C]//Proceedings of the 21st international conference on World Wide Web, 2012: 1-10.
[9] Wang C, Blei D M. Collaborative topic modeling for for recommending scientific articles[C]//Proceeding of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, 2011: 448-456.
[10] Zhang P, Zhou C, Wang P,et al. E-tree: An efficient indexing structure for ensemble models on data streams[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(2): 461-474.
[11] Rendle S, Freudenthaler C, Gantner Z,et al. Bpr: Bayesian personalized ranking from implicit feedback[C]//Proceeding of the 25 Conference on Uncertainty in Artificial Intelligence, 2009: 452-461.
[12] Pan W, Xiang E, Yang Q. Transfer learning in collaborative filtering with uncertain ratings[C]//Proceeding of Twenty-Sixth AAAI Conference on Artificial Intelligence, 2012: 662-668.
[13] Ma H, Yang H, Lyu M R,et al. SoRec: social recommendation using probabilistic matrix factorization[C]//Proceeding of the 17th ACM conference on information and knowledge management, 2008: 931-940.
[14] Liua F, and Lee H J. Use of social network information enhance collaborative filtering performance[J]. Expert Systems with Applications, 2010, 37(7): 4772-4778.
[15] Xin X, King I, Deng H,et al.A social recommendation framework based on multi-scale continuous conditional random fields[C]//Proceeding of the 18th ACM conference on information and knowledge management, 2009: 1247-1256.
[16] Ma H, Zhou D, Liu C, et al.Recommender systems with social regularization[C]//Proceeding of the 4 ACM international conference on Web search and data mining, 2011:287-296.
[17] Lu Y, Tsaparas P, Ntoulas A,et al. Exploiting social context for review quality prediction[C]//Proceeding of the 19th International Conference on World Wide Web, 2010: 691-700.
[18] Cheng C, Yang H, King I,et al. Fused matrix factorization with geographical and social influence in location-based social networks[C]//Proceeding of the 26 AAAI Conference on Artificial Intelligence, 2012: 542-548.
[19] Ye M, Yin P Y, Lee W-C L,et al. Exploiting geographical influence for collaborative point-of-interest recommendation[C]//Proceeding of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2011: 325-334.
[20] Zheng V W, Zheng Y, Xie X, et al. Collaborative location and activity recommendations with gps history data[C]//Proceeding of the 19th international conference on World Wide Web, 2010: 1029-1038.
[21] Qiao Z, Zhang P, He J,et al. Combining geographical information of users and content of items for accurate rating prediction[C]//Proceeding of 23rd International World Wide Web Conference, 2014: 361-362.
[22] Takeuchi Y, Sugimoto M. Cityvoyager: An outdoor recommendation system based on user location[J]. ubiPCMM, 2005, 4(3):625-636.
[23] Borzsonyil S, Kossmann D, Stocker K. The skyline operator[C]//Proceeding of 17th International Conference on Data Engineering, 2011:421-430.
[24] Chaudhuri S, Gravano L. Evaluating top-k selection queries[C]//Proceeding of the 25th International Conference on Very Large Data Bases, 1999: 397-410.
[25] Bruno N, Gravano L, Marian A. Evaluating top-k queries over web-accessible databases[J]. In ACM Transactions on Database Systems, 2004, 29(2): 369-369.
[26] Koren Y, Bell R, Volinsky C. Matrix factorization technology for recommendation system[J]. Journal of Computer, 2009, 42(8), 30-37.
Event Recommendation Based on Geographical Features and Heterogeneous Social Relationships
QIAO Zhi1,2, ZHOU Chuan2,3, JI Xiancai3, CAO Yanan3, GUO Li3
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190,China) (2. University of Chinese Academy of Sciences, Beijing 100049,China) (3. Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093,China)
In order to improve users’ experience in event-based social networks (EBSNs) services, the event recommendation task has been studied in the recent years. In this paper, the user motivation data of EBSN applications is analyzed, and a novel latent factor model unifying multiple data features is proposed. This method considers two new types of features, i.e., heterogeneous online& offline social relationships and regional preference of users, and applies them for event recommendation. Experimental results on real-world data sets showed our method had better performance than some traditional methods.
event recommendation; event-based social network; collaborative filtering; regional preference; heterogeneous social relationship

乔治(1986—),博士,主要研究领域为数据挖掘。E⁃mail:qxs1986@126.com周川(1984—),博士,副研究员,主要研究领域为社会计算。E⁃mail:zhouchuan@iie.ac.cn纪现才(1976—),博士研究生,主要研究领域为数据挖掘与机器学习。E⁃mail:jixiancai@iie.ac.cn,
1003-0077(2016)05-0047-10
2015-03-09 定稿日期: 2015-07-22
国家重点基础研究发展计划(973计划)(2013CB329605);国家自然科学基金(61502479,61403369);中国科学院战略先导科技专项(XDA06030200)
TP
A
猜你喜欢
英语世界(2023年6期)2023-06-30 06:28:28
意林彩版(2022年2期)2022-05-03 10:25:08
数学物理学报(2021年4期)2021-08-30 08:27:50
现代装饰(2021年1期)2021-03-29 07:08:22
当代水产(2021年1期)2021-03-19 05:16:46
中等数学(2020年1期)2020-08-24 07:57:42
计算机教育(2020年5期)2020-07-24 08:52:38
第一财经(2020年4期)2020-04-14 04:38:56
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年8期)2020-01-02 04:45:23
