
基于维基百科的双语可比语料的句子对齐
2016-05-03 13:03胡弘思姚天昉
中文信息学报 2016年1期
胡弘思,姚天昉
(上海交通大学 计算机科学与工程系,上海 200240)
基于维基百科的双语可比语料的句子对齐
胡弘思,姚天昉
(上海交通大学 计算机科学与工程系,上海 200240)
该文提出了一种从维基百科的可比语料中抽取对齐句子的方法。在获取了维基百科中英文数据库备份并进行一定处理后,重构成本地维基语料数据库。在此基础上,统计了词汇数据、构建了命名实体词典,并通过维基百科本身的对齐机制获得了双语可比语料文本。然后,该文在标注的过程中分析了维基百科语料的特点,以此为指导设计了一系列的特征,并确定了“对齐”、“部分对齐”、“不对齐”三分类体系,最终采用SVM分类器对维基百科语料和来自第三方的平行语料进行了句子对齐实验。实验表明:对于语言较规范的可比语料,分类器对对齐句的分类正确率可达到82%,对于平行语料,可以达到92%,这说明该方法是可行且有效的。
句子对齐;可比语料;维基百科;SVM
1 引言
在自然语言处理中,对齐是指从互译的不同文本中找出互译片段的过程[1]。对齐的单位包括篇章、段落、句子、短语、单词等。句子对齐(Sentence Alignment)就是寻找两篇文本中互为翻译的句子对之间关系的一类问题[2]。许多应用如机器翻译、复述生成、跨语言查询扩展等都需要大量双语句对来支持处理。对于大规模语料库,语句的手工对齐是不现实的,近年来人们一直在研究用计算机实现自动对齐[3]。
然而,对于构建大规模双语句对语料库的目标来说,首先就需要一个大型的、由源语文本和从源语文本翻译的译语文本构成的平行语料库(Parallel Corpus)[4]。1995年,Baker首次提出了可比语料库(Comparable Corpus)的概念[4-5]。它又被称为非平行而可比语料库(Non-parallel Corpus but Comparable)[6]。与以句或段对齐的平行语料相比,可比语料提供了更大的自由度,对语料的要求也更低。
Smith[7]等人的研究折射出了维基百科作为可比语料的巨大潜力。维基百科有着严格的分类体系,甚至可以直接从中抽取出完备的本体库(Ontology)。同时,它又天然地有着篇章级对齐的组织结构,是跨语言可比语料极佳的研究对象。
另一方面,在单语言的自然语言处理中,命名实体(Named Entity)的识别和利用往往对处理效果有着至关重要的作用。维基百科的条目天然就是一个巨大的命名实体库,而多语言版本的组织结构,让它成为双语命名实体对精确识别的极佳资源。
从上述两方面考虑,可以利用维基百科的优势,使其作为基础语料库以及命名实体库,帮助进行可比语料中句子的对齐工作,这就成为了一种非常有潜力的研究方向。然而针对中英文的此类研究非常稀少。在这个方向进行深入探索,无疑是非常有价值的。
2 基于维基百科的双语可比语料的对齐句抽取
2.1 维基百科语料的特点
建立可比语料库的首要问题就是文本级别的对齐。维基百科从一开始就致力于建设多语言的百科全书,因此,它的条目是天然文本对齐的。然而,由于贡献者的地域、文化背景和语境不同,同样的词条不同语言版本往往并不是直接翻译的平行语料,而是各有侧重、表述各不相同、长短详略不一的文档对。因此,可以认为这是一个文档级别对齐的双语可比语料库。
此外,由于维基百科是以“条目”为基本单位的,而条目往往可以认为等同于命名实体。因此,通过维基百科的其他语言版本的链接,可以直接找到一个命名实体在其他语言中的精确表达,这就省去了通过庞大的语料库识别抽取、或者进行大量人工标注来取得双语命名实体词典的工作,而直接得到一个高准确率的标准词典。
2.2 系统架构概述
图1描述了本系统的架构。它的核心由标注器(Annotator)、候选抽取器(Candidate Extractor)和特征抽取器(Feature Extractor)组成,借助于开源的访问Wikipeida数据的Java API包JWPL(Java Wikipedia Library),词汇处理器(Lexicon Processor)和文本处理器(Article Processor)可以完成基本词汇和文本的处理,然后调用分类管理器(Classifier Manager)对候选句对进行分类处理。需要指出的是,本文的分类模型采用了SVM分类模型[8]。

图1 系统架构
2.3 候选平行句的抽取
候选平行句(Candidate Parallel Sentences)的抽取是指从原始语料中抽取潜在的可对齐的句对。本文采用的方法借鉴了被大部分可比语料的句子对齐工作所采用的Munteanu等人的方法[9],通过以下三个步骤获取候选句对。
(1) 将文本对齐后同一主题的中英文语料中的句子,两两配对。
(2) 过滤停用词后,比较句对中两个句子的实词数量,若其比例在[0.5, 2.0]范围之外,则将其滤除。
(3) 使用中英文词典,若中文句SC中的词wCi能在目标句SE中找到相应的单词,则认为找到一个匹配。若匹配数超过阈值T(至少找到三个匹配,即T≥ 3),则将(SC,SE)作为一对候选平行句。T的计算如式(1)所示。
(1)
其中,|WC|和|WE|分别为SC和SE的实词数量,取(|Wc||WE|)的1/4次方是经验值。此外,对于每句中文句SC,总是只保留匹配数最大的五句英文候选匹配句。
2.4 特征设计
由于篇幅关系,在介绍下述特征时,每种特征仅列举一种计算公式,其余的均省略。
2.4.1 完全匹配特征
在双语句子对齐中,有一类特征能够带来最直接的匹配,也就是在源文本中直接出现目标语言的语句或词汇。这样的现象主要有两种情况:一种是原文的引用,另一种是作为补充语或者括号中的注释来表明源自目标语言的特定命名实体。 前者可以直接进行句子的对齐,后者可以直接跳过命名实体识别以及词法语义扩展,在目标文本中寻找完全匹配。本文只着眼于这种现象对句子对齐的贡献,故此特征的计算公式如式(2)所示。
(2)
其中,SC,SE分别表示中文句子和英文句子词汇的集合,WEinC表示中文句子中英文单词集合,WCinE表示英文句子中中文单词集合。α为平滑参数,防止分母为0的情况发生。本文取0.1。
2.4.2 翻译匹配特征
完全匹配毕竟属于比较稀疏的数据。句子对齐主要依赖的还是翻译匹配的特征。本文定义了五个基于辞典和翻译的特征,分别是翻译后英文词共现率、翻译后中文字共现率、词典匹配特征、英文余弦相似度特征和中文余弦相似度特征。下面介绍一下翻译后英文词共现率。
本文使用微软在线翻译API,将中文句子翻译成英文,并在过滤掉停用词、提取词干以后,与经过同样处理的英文句子进行比较。此特征计算公式如式(3)所示。
(3)
其中,TCE(S)表示使用翻译工具对句子S进行中文到英文的翻译,W(S)表示英文句子S中除去停用词后的词干集合。其中,取交集、并集和取模操作,都是基于多集(Multi-Set)的概念,即集合中允许重复元素的出现。
2.4.3 数字匹配特征
数字的匹配在句子对齐中至关重要。对于科技、历史等数字出现比较频繁的文本中,一个特定的数字往往已经足够成为两句句子匹配的决定性因素。但是,纯粹的阿拉伯数字匹配要求过高,会导致较低的召回率。本文设计了一个转换算法,将大部分中文数字表述转换成阿拉伯数字串。对于英文,由于英文包含序数词、连词、逗号和连字符,表达方式更是多种多样。因此,本文所采取的办法是利用翻译引擎将英文翻译成中文以后,再利用上述算法提取数字串。
于是得到此特征的计算公式如式(4)所示。
(4)
其中,NE和NC分别是从英文句和中文句中提取出来的数字串集合。为了处理句子中没有数字的情况,本文为平滑参数设置了经验值α= 0.01,β= 0.03。
2.4.4 命名实体匹配特征
由于维基语料得天独厚的优势,本文放弃了使用命名实体识别工具,而直接使用最大正向匹配的方法,并利用根据维基百科条目生成的命名实体词典进行匹配。为了避免噪音,在匹配命名实体时,不考虑包含数字符号的命名实体,也不考虑长度为1的命名实体。对长度为2的命名实体,匹配以后不直接跳过,而从该命名实体第二个字处再一次试探匹配,以防止匹配错误。得到中文命名实体集后,从命名实体字典得到它们全部的英文对应实体、英文别名,与英文句进行匹配。此特征的计算公式如式(5)所示。
FExactNE(SC,SE)=
(5)
其中,nec是中文命名实体,E(nec)是对应于nec的英文命名实体。NEC是中文命名实体集,NEE是英文命名实体集。为了处理句子中没有命名实体的情况,本文为平滑参数设置了经验值α= 0.01,β= 0.03。
3 实验结果与分析
3.1 实验数据
本文从维基百科数据备份中,共获得中英文条目近480万个,其中中英文匹配的条目313 412对。在抽取环节共获得7 998 058对平行候选句对。本文随机选择了其中200对文档共4 873对候选对,考虑到对齐对的稀疏,又在此基础上进行了一定的人工选择(舍弃了部分特征重复、对分类帮助不大的非对齐对),最后对3 000对候选对进行了标注。其中不对齐句2 283对,部分对齐句639对,对齐句158对。
为了进行参照对比,本文从babel汉英平行语料库[10]中获取了经过对齐标注的江泽民在十六大上所作的报告《全面建设小康社会,开创中国特色社会主义事业新局面》。该报告中文共721句,英文共838句,划分成709个对齐段,通过候选抽取得到 2 223对候选对。
3.2 实验结果及分析
3.2.1 对齐效果
因为双语语料具有十分复杂的语言现象,使得在标注过程中预定的“对齐/不对齐”二元分类的可行性受到了质疑。如果只寻找平行度很高的句子,将导致训练正例极其稀疏,以至于无法进行有效地分类(在本文所标注的3 000对候选句对中,只有158对可以算“完全平行”,仅占5.2%,且分布不均匀,在平行度较高的文本对中,常常密集出现)。因此本文增加了“部分对齐”(PartialAlignment)的概念,将目标语言和源语言直观语义上有完整的重叠部分,但又不完全平行的句对归入此类,而将需要推理演绎才能有匹配涵义的句对全部归入不对齐类。
根据这个分类体系,所得到的分类性能如表1所示。

表1 加入较优参数后的SVM分类器性能
然而,这中间的精确率和召回率是针对候选集的,为了得到它针对原始语料的精确率和召回率,并进行更深入地评估,本文采用了上述babel汉英平行语料进行测试, 并与Munteanu的中英文对齐实验进行了对比,其结果如表2所示。
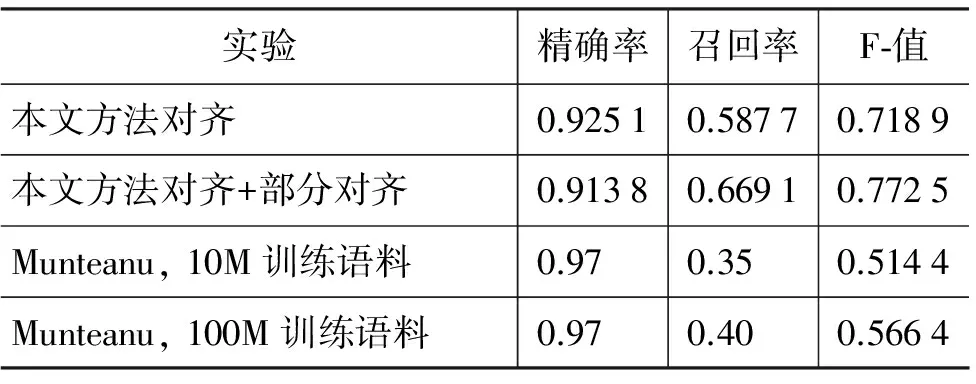
表2 实验结果对比
3.2.2 特征分析
在SVM分类的过程中,不同的特征选择是影响分类算法性能的关键,本节考察不同的特征组合对分类效果的影响。虽然已在2.4节中对特征进行了描述,但为了此处阅读的方便,在此进行了特征标记,如表3所示。
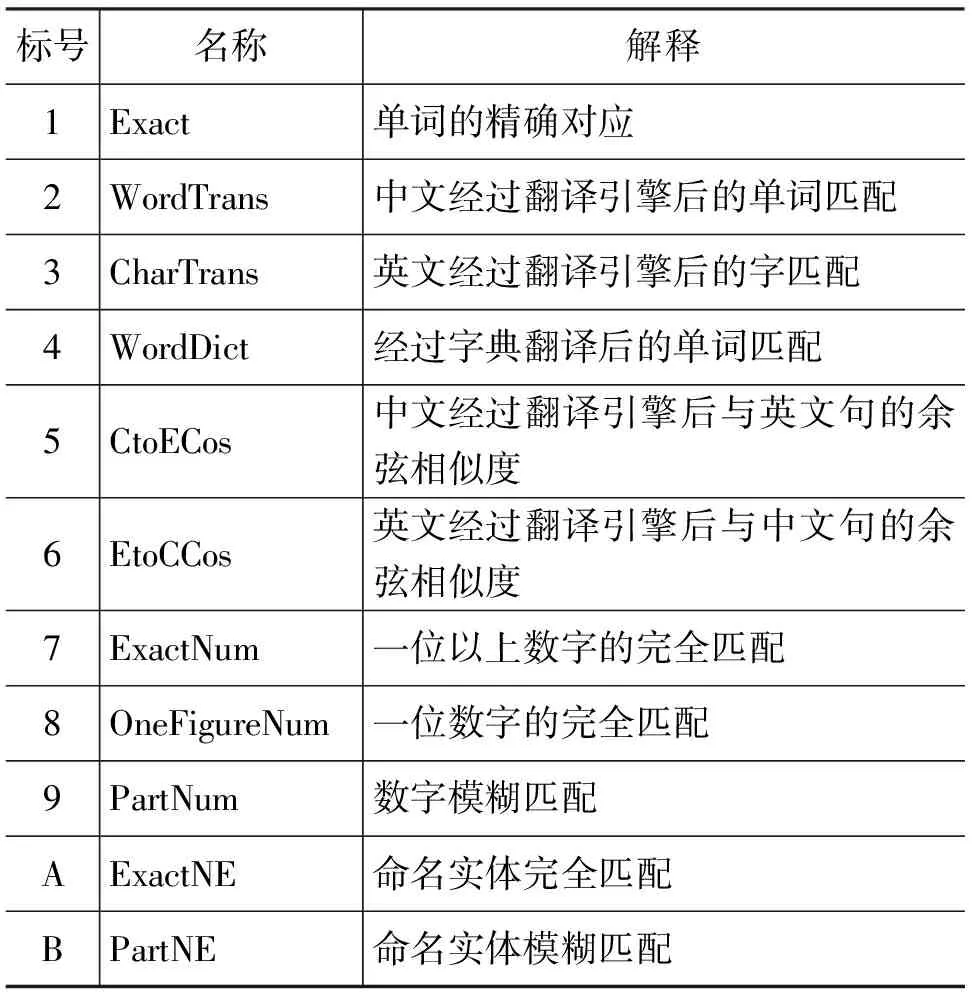
表3 特征列表
在考察不同特征值影响时,本文对不同特征进行了组合,比如组合形式“234”代表WordTrans、CharTrans、WordDict的组合,然后依然使用五折交叉验证对标注好的数据进行SVM分类。实验结果如表4所示,从中可以看出:

表4 不同特征组合对分类效果的影响

续表
注: AP=对齐句精确率 AR=对齐句召回率 AF=对齐句F值 PP=部分对齐句精确率PR=部分对齐句召回率 PF=部分对齐句F值 APF=对齐+部分对齐句F值
(1) 全特征分类结果可以达到最好的分类效果。这体现了SVM算法能够较好地支持冗余特征,也说明了本文所选择的特征组合是合理的。
(2) 在第二组数据删除了“完全匹配”这一特征后,可以发现精确率反而有所上升,可以认为是相同的命名实体的原文引述会带来精确率上的混淆(如描述同一人物的不同事件等)。但是在召回率和F值上都有一定的下降。后面有多组数据都出现了这个现象,即正确率提升越高,召回率及F值上的下降越严重。
(3) 第三组数据删除了“词典及翻译匹配”数据,显然召回率和F值达到了最低点,但这与这一组数据担任的语义相似度的概念是吻合的。
(4) 第四组数据删除了“数字匹配”,可以看到,对齐+部分对齐的F值降低到了全局最低点,部分对齐的正确率和召回率都极大地下降,这和本文所用语料来自维基百科,其中语言叙述比较客观、数据较多有关,数据可以体现很好的区分度。
(5) 第五组数据删除了“命名实体匹配”,可以看到对齐句精确率有较大提升,整体下降不是十分明显。这可能是因为基于维基百科的命名实体词典太过繁杂,使得许多命名实体色彩不是很鲜明的词汇都变成了命名实体。
(6) 第六组数据删去了所有精确匹配的特征,得到了全局最差的对齐+部分对齐F值,从后面的数据可以发现,其实单独删除各组精确匹配特征,下降都不是特别明显。由此可见,这些精确匹配特征虽然相互之间没有冗余,但有一定的相互补充作用,如果出现两个精确匹配特征,句子平行可能性较大。
(7) 第七组数据删去了两个模糊匹配特征,效率也有一定的下降,但没有删除精确匹配特征后的效率下降明显。从后面几组也可以看到,命名实体模糊匹配的贡献要大于命名实体的精确匹配,而数字的精确匹配的贡献要大于模糊匹配。这也和这两者在自然语言中对精确度的要求以及自由度空间是吻合的。
(8) 第八组到第十四组数据分别考察了各组中特征的重要性。可以看到,在本文的实验中,翻译和词典的特征匹配有一定的冗余和补充作用,单独删去时下降不明显,而全部删去时下降十分剧烈;余弦相似度贡献较小,它和翻译及词典特征构成一定的冗余和补充,余弦相似度的特征还是明显优于剔除全部词典翻译特征的数据的表现。
4 结论与展望
本文提出了一种基于维基百科的双语可比语料的句子对齐方法。作为一个运营良好、专业性强、规模庞大、用户群体庞大的跨语言平台,维基百科提供了极其丰富的多语言语义信息。首先,本文获取了维基百科的中文及英文的数据库备份,进行了一定的处理后,重构成本地维基语料数据库,并统计了词汇数据、构建了命名实体词典,并通过维基百科本身的对齐机制获得了双语可比语料文本。然后,采用通用的方法,使用一个双语词典,过滤和筛选得到了候选对齐句对,在标注的过程中分析了维基百科语料的特点,以此为指导设计了一系列的特征,并确定了“对齐”、“部分对齐”、“不对齐”三分类体系。最终采用SVM分类器对维基百科语料和来自第三方的平行语料进行了句子对齐实验。实验表明,对于语言较规范的可比语料,分类器对对齐句的分类正确率可以达到82%,对于平行语料,更可以达到92%,这说明了本文所采用的方法是可行且有效的。
[1] 张孝飞, 陈肇雄, 黄河燕, 等. 基于锚点词对的双语词对齐算法[J]. 小型微型计算机系统,2006,27(2):330-334.
[2] Simard M, Plamondon P. Bilingual Sentence Alignment: Balancing Robustness and Accuracy[J]. Machine Translation, 1998, 13(1): 59-80.
[3] 吕学强, 李清隐, 黄志丹, 等. 基于统计的汉英句子对齐研究[J]. 小型微型计算机系统, 2004,25(6):990-992.
[4] Baker M. Corpora in Translation Studies: An Overview and Some Suggestions for Future Research[J]. Target, 1995, 7(2): 223-243.
[5] 康小丽, 章成志, 王惠临. 基于可比语料库的双语术语抽取研究述评[J]. 现代图书情报技术, 2009,10:7-13.
[6] Cheung P, Fung P. Sentence alignment in parallel, comparable, and quasi-comparable corpora[A]. Lino M T et al. Proceedings of 4th International Conference on Language Resources and Evaluation (LREC) [C]//Proceedings of the Paris, France: European Language Resources Association, 2004: 30-33.
[7] Smith J R, Quirk C, Toutanova K. Extracting Parallel Sentences from Comparable Corpora using Document Level Alignment[C]//Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, USA: Association for Computational Linguistics, 2010: 403-411.
[8] 王建会, 王洪伟, 申展, 等. 一种高效的文本分类算法[J]. 计算机研究与发展,2005,42(1): 85-93.
[9] Munteanu D S, Marcu D. Improving machine translation performance by exploiting non-parallel corpora[J]. Computational Linguistics, 2005, 31(4): 477-504.
[10] 柏晓静, 常宝宝, 詹卫东. 构建大规模的汉英双语平行语料库[C]//2002全国机器翻译研讨会文集:机器翻译研究进展. 中国北京:电子工业出版社,2002: 124-131.
Sentence Alignment for Bilingual Comparable Corpus from Wikipedia
HU Hongsi, YAO Tianfang
(Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240,China)
We propose a method that can extract aligned sentences for comparable corpus derived from Wikipedia. First, we retrieve Wikipedia data dump of English and Chinese and re-construct it into a local Wikipedia corpra database. Second, we extract the lexicon, esp. the build named entity lexicon, and obtain bilingual comparable corpus through alignment mechanism provided by Wikipedia. Third, we analyze the characteristics of Wikipedia corpus manually, and designe a series of features. Adopting a taxonomic of alignment/partial alignment/non-alignment, we finally apply SVM classifier to identify the sentences alignment. Experimented on the Wikipedia corpus and a third-party parallel corpus, the proposed method achieves the precision of 0.82 and 0.92, respectively.
sentence alignment; comparable corpus; wikipedia; SVM

胡弘思(1983—),硕士,主要研究领域为自然语言处理和机器学习等。E⁃mail:crazyindark@outlook.com姚天昉(1957—),博士,副教授,主要研究领域为计算语言学和语言技术。E⁃mail:yao⁃tf@cs.sjtu.edu.cn
1003-0077(2016)01-0198-06
2013-06-05 定稿日期: 2014-03-20
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
英语文摘(2021年8期)2021-11-02
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
读者·原创版(2015年11期)2015-03-01
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
意林(2014年2期)2014-02-11
互联网天地(2012年12期)2012-11-18
