
融合显性和隐性特征的中文微博情感分析
2016-05-03 13:02陈铁明缪茹一王小号
中文信息学报 2016年4期
陈铁明,缪茹一,王小号
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
融合显性和隐性特征的中文微博情感分析
陈铁明,缪茹一,王小号
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
微博情感分析是研究社交网络舆情的一项关键技术。微博表情符号和情感词汇等是一类直观显性的情感特征,而微博的内容语义则可视为隐性特征,且对情感判定往往具有决定性作用,因此本文提出将两类特征因素融合的微博情感分析方法。首先构建情感分析词典、网络用语词典以及表情符号库,定义微博频繁特征词集,再根据频繁特征词集,利用最大频繁项集获得微博初始情感簇;针对初始簇间存在文本重叠情况,提出基于短文本扩展语义隶属度的簇间重叠消减算法,获得完全分离的初始簇;最后根据簇语义相似度矩阵,给出一种凝聚式情感聚类方法。利用NLPCC2013 评测所提供的训练语料进行情感分类实验,说明了分析该文方法的性能优势,并以2014年3月8日马航事件微博数据为例,给出了利用微博情感分析公众随事态发展的情感变化,说明了该文方法的实用效果。
表情符号;情感词典;语义;频繁项集;聚类
1 引言
近年来,微博已成为一种新兴社会网络媒体,用户可在微博上发布个人观点、分享生活体验、与朋友交流互动等。目前,新浪微博拥有超过五亿注册用户,日均发布超过一亿条新微博内容,包括社会热点问题,用户对产品、品牌或热门事件观点。微博用户数量庞大,用户表达的观点、情感更具普遍性,也更具说服力。因此,掌握微博用户的情感倾向,无论对政府正确引导舆论,还是对企业改进产品体验等都有极大参考价值,也更利于社会舆论监控、突发事件应对以及网络信息安全保障等。
微博具有原创性、不可预见性等特点,单条微博字数在140以内,融合了网络用语和表情符号等显性特征以及微博语义情感等隐性特征,这给微博情感分析带了新的挑战。微博中广泛存在谐音词、简写词等,如“稀饭”代表“喜欢”、“杯具”代表“悲剧”等,且这些词汇随时间不断变化,并不断有新词出现,有必要建立特定的网络用语词典;微博表情符号通常可直接表达情感,但表情符号五花八门,需要建立特定的表情符号情感分类;另外,一条微博中可能包含多个不同情感,情感分析一般以博主的主要情感为准。本文将针对这些问题,对微博情感因素开展全面研究与分析,提出一种融合显性特征和隐性特征的情感分析方法。
2 相关工作
情感分析是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,目的是从用户发布的带有主观感情色彩的文本信息中提取用户观点,并判断其情感极性。情感分析过程分为情感类别划分和情感信息抽取。
由于人类情感复杂,故情感类别划分没有统一标准。常见如赵妍妍等[1]把情感划分任务分为两种: 主、客观信息的二元分类,对主观信息的情感分类,包括最常见的褒贬二元分类以及更细致的多元分类。对于多元分类,Jichang Zhao和Li Dong[2]等提出了四类情感: angry愤怒,disgusting厌恶,happy高兴,sad悲伤;贺飞艳等[3-4]提出了七类情感: anger 愤怒、disgust 厌恶、fear 恐惧、happiness 高兴、like 喜好、adness 悲伤、surprise 惊讶。
对于情感信息抽取,Go和Bhayani[5]提出了一种距离监督学习方法,对Twitter中的消息进行情感分类。给定一个检索词,消息自动被分为正面或负面信息。抽取Twitter中含有表情图标的消息作为训练集,利用朴素贝叶斯,最大熵以及支持等分类算法进行实验;谢丽星等人[6]提出了基于层次结构的多策略方法对新浪微博数据展开情感分析研究,并在特征提取时采用了主题相关特征,实验结果显示,使用主题相关的特征后所获得的最高准确率由66.467%提升到了 67.283%。Dmitry Davidov、Oren Tsur 等[7]利用 twitter 上已有常用标记和表情符号做标签,通过监督学习的方法构建了一个情感分类系统,这种方法不需要太多的人工注释。
表情符号和情感词典等方法均属于表达情感的显性特征,尤其对短文本的微博更能体现情感特性。同时,由于文本词义的表现力极强,蕴含在微博短文本中的语义作为一种关键的隐性特征,也可直接决定微博内容表达的情感。基于文本隐含语义的情感分析研究已较为常见[8],但由于语义通常随上下文本、时间环境等动态变化,基于语义的分析方法一般仅处理正负两分情感分类问题,并且针对微博包含社交网络专用语言等特点,基于语义这一隐性特征的分析方法还面临较大挑战[9]。
因此,本文将以表情符号为基础,结合大连理工大学信息检索研究室整理和标注的中文本体资源以及HowNet 提供的情感分析词汇集,构建表情符号库、情感词语词典以及网络用语词典,从中提取显性情感特征,并同时融合隐性语义特征,采用基于同类情感微博文本相似度较大、不同情感微博文本相似度较小的聚类方法进行情感分析。聚类无需训练过程和预先对微博手工标注类别,直接基于频繁项集和语义聚类算法,具有较好的灵活性和自动化处理能力。
3 微博显性情感特征
3.1 表情符号

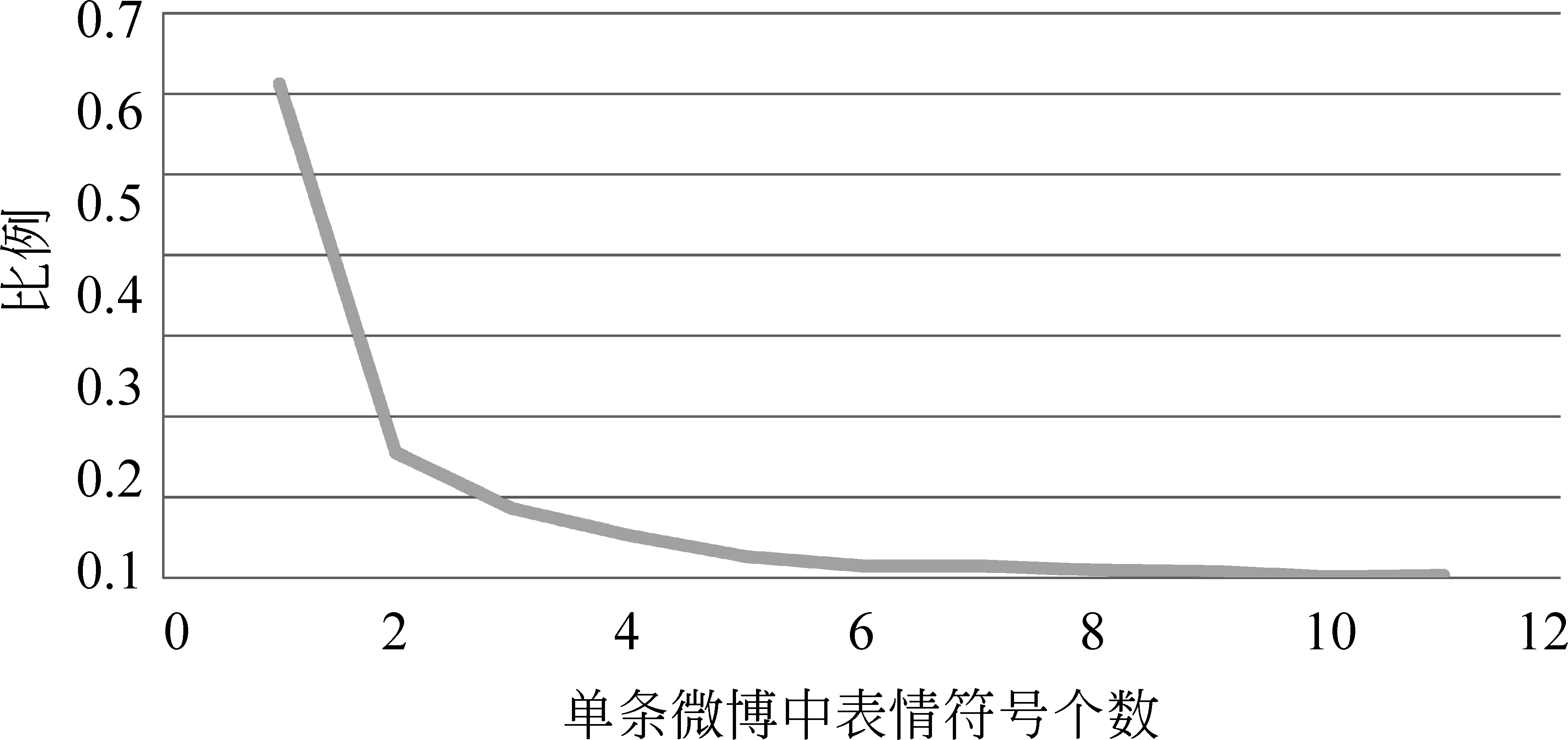
图1 包含不同表情符号数目的微博消息的比例
本文采用新浪微博自带的表情构建情感符号库,再依据七类情感分类方法[3],将情感分为高兴、喜好、愤怒、悲伤、恐惧、厌恶、惊讶七个类别。对出现频率排在前150的表情符号,作统一化处理,即先建立情感符号表,将150个表情符号放入情感符号表中,如表1所示。然后,通过查表方式判断该情感符号是否属于情感符号表,若是则提取情感符号,通过转换成情感类别后写入情感特征表。实验表明对表情符号统一化处理有利于产生更好聚类效果,从而实现更精准的情感分析。

表1 情感类别和每个类别的典型表情符号
3.2 情感词
情感词最能体现微博的文本情感,故情感词典和网络词汇词典的构建是微博情感倾向性判定的基础工作。
3.2.1 中文情感词汇
情感词汇复杂、词性较多,包括形容词、名词、副词等,仅考虑词性选择情感词并不科学,如名词(“垃圾”、“棒槌”)都带有负面情感,而大多数名词并不带情感色彩,选用会降低分类性能。本文采用大连理工大学信息检索研究室提供的中文本体资源[3],包含27 467个中文情感词。如表2所示,先建立一个情感词典的情感词表,将这些情感词放入词表中。通过查表的方式判断通过文本分词后是否是情感词,若是则提取情感词,并写入情感特征表。
此外,还收集了“不”、“没有”、“不可能”、“很难”等微博中的否定词集,实验表明,否定词直接使微博文本情感发生了迁移,所以否定词也是微博情感分析重要因素。
例如,“雾霾天,一点都不开心”,包含情感词汇“开心”表达“高兴”情感,但因否定词“不”修饰,句子表达“悲伤”情感。基于传统情感分类分为三大类(正面、负面、中性),正面情感否定词修饰后为负面情感,负面情感否定修饰后转为中性情感或正面情感,本来七类情感,将“高兴”、“喜好”作为正面情感,其余五类作为负面情感,本文将否定词情感转移情况如表3所示。
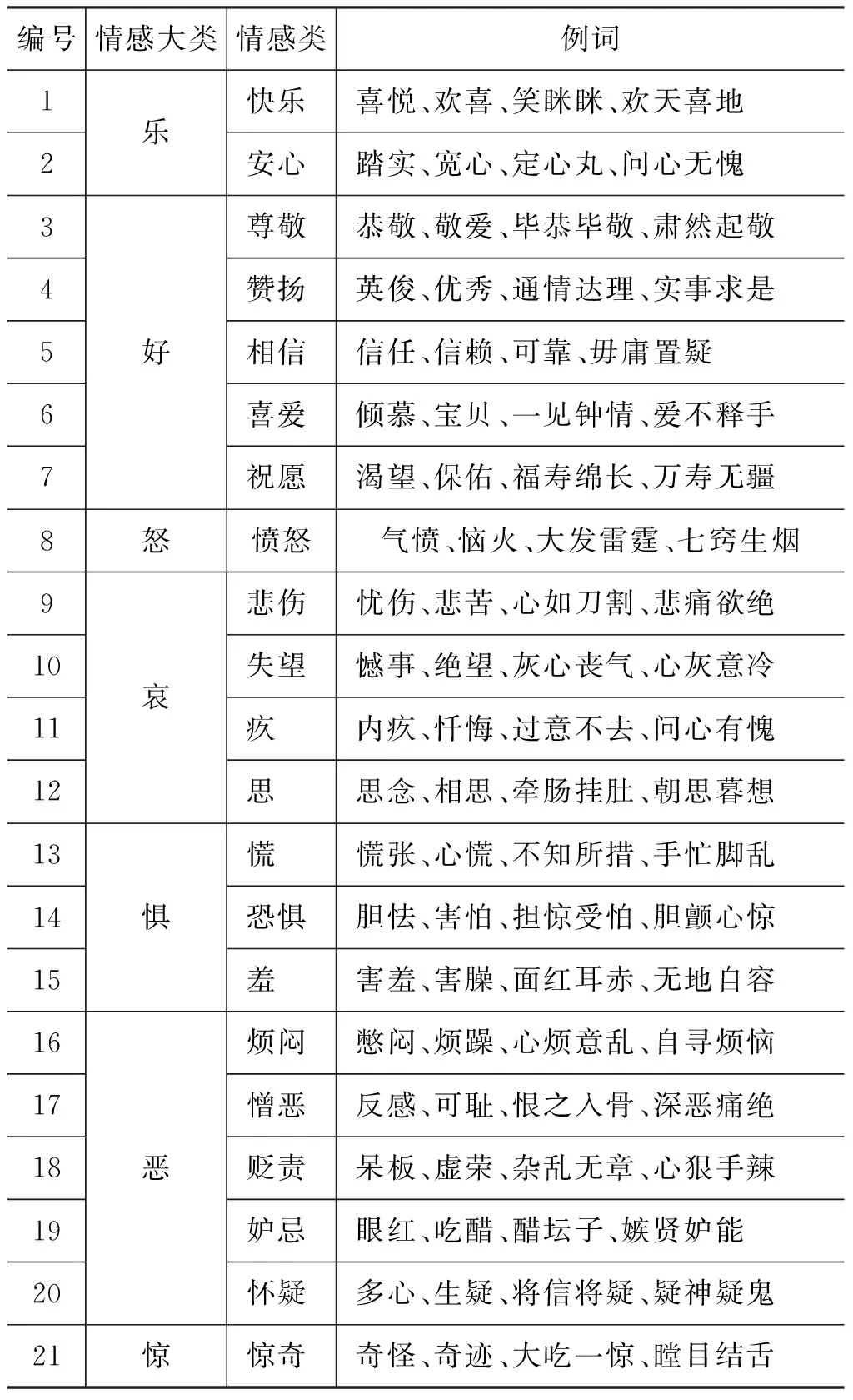
表2 本文选用的中文本体资源情感分类表摘要[3]
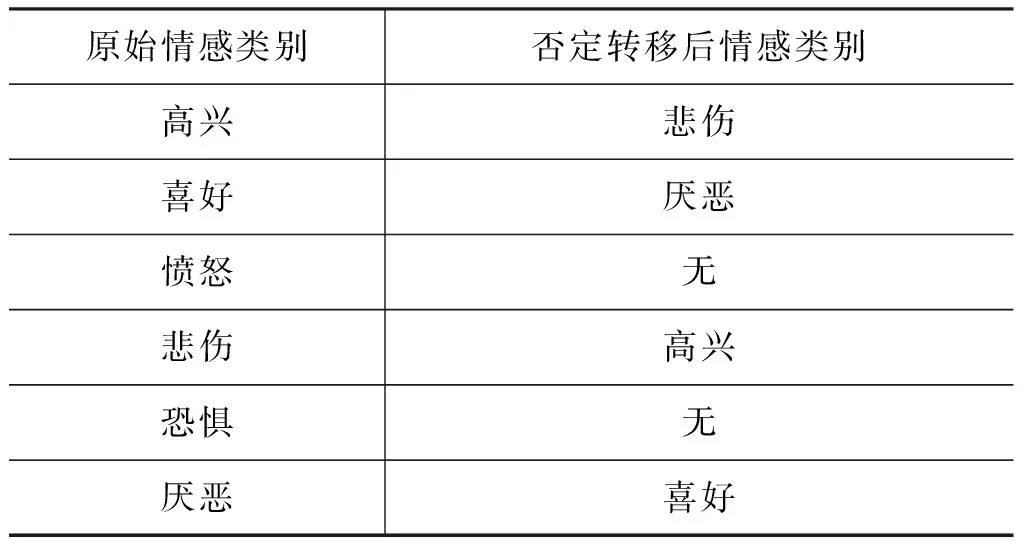
表3 否定词修饰后情感转移
对于双重否定情况,根据语料统计,在微博短文本中出现较少,故不作考虑。
3.2.2 网络词汇词典构建
微博情感往往具有原创性,随着网络发展不断有新词出现,包括谐音词、简写词、网络语言等,因此本文构建了网络词汇词典用于微博情感的情感倾向性判定。通过社交网络搜集、整理,共采用141个网络用词,分别进行情感标注以及作统一化处理,即先建立一个网络词汇的情感词表,将这些网络词汇放入词表中。许多网络用词在没有上下文的语境下,情感倾向性是有歧义的,文本只保留情感明显的网络用词,部分网络用词及其情感倾向性标注如表4 所示。同样,基于网络词汇词典也可通过查表方式直接判定部分微博内容的情感类别。
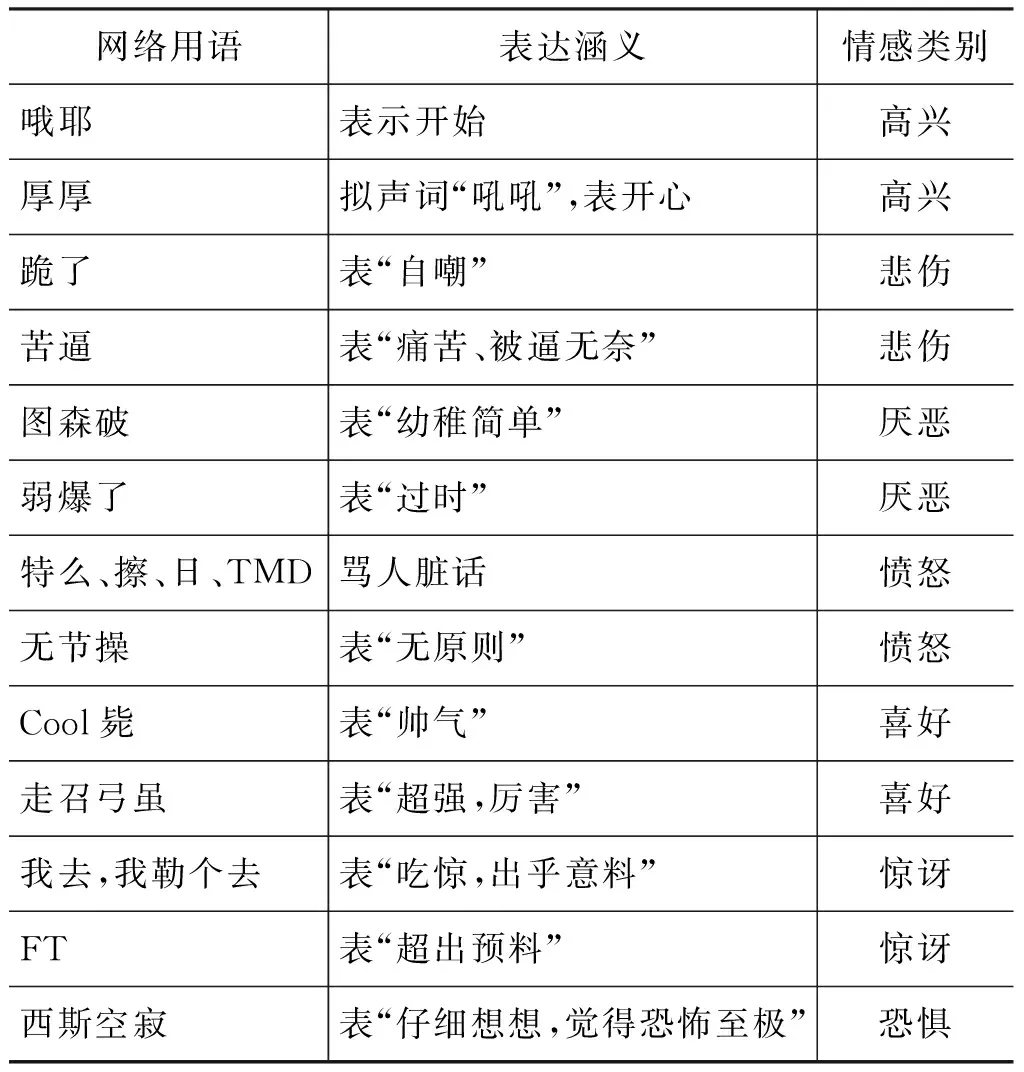
表4 部分网络用词及其倾向性
4 基于频繁项集和语义的微博隐性情感聚类
Benjiamin等提出的FIHC(Frequent Itemset-based Hierarchical Clustering[10]-基于频繁项集的层次聚类算法)是目前应用最广的文本聚类算法。该算法以聚类簇为中心,并且直接用频繁项集来衡量簇之间聚合程度,并且认为隶属于相同关系文档之间共享较多频繁项集,隶属于不同关系共享较少频繁项集,使用频繁项集的概念来对文本进行划分。
微博内容词性和语义都可视为微博的隐性情感特征,具有相同情感特征的词汇聚到同一情感类中,即具有相同情感类的微博之间共享较多的频繁项集。本文采用FIHC算法 “先建簇后消重再凝聚”的思想,提出一种结合频繁项集和语义聚类的新方法(Semantics FIHC,简称S-FIHC),聚类主要过程如图2所示。

图2 结合频繁项集和语义聚类的FIHC算法
此算法主要流程为: 首先,基于频繁项集创建初始情感簇,每个初始情感簇文本都含有频繁项集,这导致初始情感簇间产生重叠文本;其次,为了更精准消除初始情感簇间文本重叠,采用知网的中文语义相似度模型,根据最大语义隶属度原则分离各个初始情感簇;最后,通过定义簇间语义相似度矩阵,完成微博情感簇的凝聚式层次聚类,并优化得到最终的情感簇,实现微博情感分析。
4.1 获取频繁项集
定义1 对数据库E中某个项集X,若项集X在数据库E中出现的次数大于预设比例,则称X是数据库E的频繁项集,这个预设比例称作最小支持度。
若将文本看成一条事务,文本词汇对应事务中的项目,则可将文本d表示为:
d=
定义2 对文本集D的某个词集W,若W在D中的支持度s(W) ≥ min_s,则称势集W是文本集D的频繁词集,min_s为全局最小支持度。本文采用频繁集挖掘算法Apriori来计算挖掘频繁词集。
算法: Apriori算法
输入: 微博数据,最小簇支持度min_s
输出: 微博数据中的频繁项集
方法:
(1) 扫描文本集D,利用词频趋势度统计候选项
集出现的次数,收集满足最小支持度min_s设定的项集,记为频繁项集;
(2) 利用产生的频繁k-项集构造强关联规则,利用频繁k-项集构造候选(k+1)-项集,反复迭代直至候选(k+1)-项集为空。
频繁项集描述微博中情感信息。本文利用频繁项集划分构造初始情感簇,将包含频繁趋势词集微博划分为一个簇,得到基于频繁项集初始情感簇,同时,将描述初始情感簇的频繁项集作为对应情感簇临时标识,通过抽取各个初始情感簇的频繁项集来代表这个初始情感簇情感语义。
4.2 微博语义隶属度初始簇重叠消减
微博文字表达具有简洁、随意性,同一情感微博具有不同表述,一条微博中可能包含多个不同情感,导致初始情感簇之间存在大量文本重叠,情感分析应以博主主要情感为准,需要将每条微博归属到一个情感簇。
从语义层面出发,本文引入《知网》语义库扩展语义信息[11],计算簇间重叠部分对初始情感簇的情感语义隶属度,最后按最大语义隶属度原则进行簇分配。
定义3 若微博docj被分配到初始情感簇Ci中,则称微博docj支持簇Ci。.
定义4 记Di和Dj是支持簇Ci和Cj微博集合,并且Di∩Dj≠0,则称簇Ci和簇Cj存在簇间重叠。
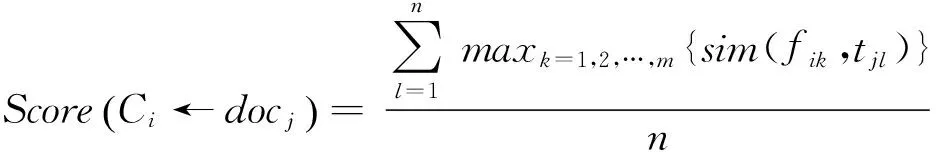

(1)
其中,簇频繁1-项集{fi1,fi2,…,fim}表示初始簇Ci的情感特征项,{tj1,tj2,…,tjn}表示初始簇Ci中微博文本docj的特征项;sim(fik,tjl)为簇特征项fjk和文本特征项tjl在《知网》中定义的语义相似度[12],n为微博文本docj特征项数目,m为簇特征项数目。
算法: 微博语义隶属度初始簇重叠消减算法
输入: 带有重叠的初始簇C1,C2,…,Cn
输出: 重叠消减后的初始簇C′1,C′2,…,C′n
方法:
1 记m个重叠的微博文本初始簇集合为CD1,CD2,…,CDm
2 初始化一个二维数组向量clusterStoreHash
3 FOR eachiform 1 tom
4 FOR each weibodocjinCDi
5FOReachclusterCk⊂CDi
7IFdocj∉clusterStoreHash
8 添加
9ElSEIFcurrScore≥currScore’
currScore‘ofdocj∈
clusterStoreHash
10 更新
到clusterStoreHash
11ELSE
12 从初始簇Ck中删除文档docj
13ENDIF
14C′k=Ck
15ENDFOR
16ENDFOR
算法复杂度为O(n),n为微博文本docj特征项数目。最后,再删除那些初始簇分离后大小为0的空簇,称为候选情感簇。
4.3 基于语义相似度的凝聚式情感聚类
通过初始情感簇间重叠消减可得到微博聚类情感检测的候选情感簇,但这些情感簇都可归属于某一个大情感,因此有必要再对候选情感簇进行凝聚式层次聚类,合并情感簇。
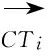
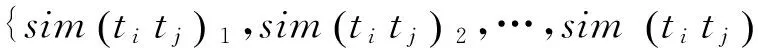
(2)

表5 定义CTi和CTj的语义相似度
算法: 候选情感簇层次聚类
输入: 候选情感簇CT{CT1,CT2..CTi},λ(两个簇合并最小阀值),μ(最小簇数目)
输出: 情感簇CT′
方法:
Step 1 抽取各个候选情感簇的特征向量,计算候选情感簇的语义相似度。
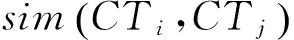
Step 5 若簇间语义相似度矩阵的行数或列数小于等于预设的最小簇数目μ,执行Step6;否则,聚类尚未结束,重新回到Step3。
Step 6 凝聚式层次聚类结束,得到情感聚类簇CT′。
5 实验结果与应用效果
实验采用NLP2013的测试数据,该数据共有14 000条已标注微博(4 000条作为训练数据集,10 000条作为测试数据集),分为八个类别(愤怒、悲伤、喜乐、恐惧、高兴、惊奇、厌恶,以及无情感),如表6所示,各类别情感微博包含表情符号数量如表7所示。
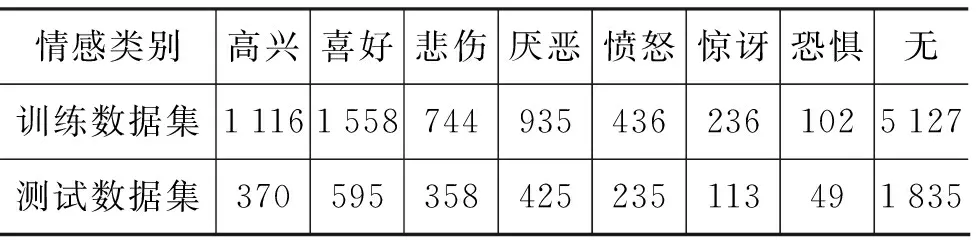
表6 微博数据类别详情
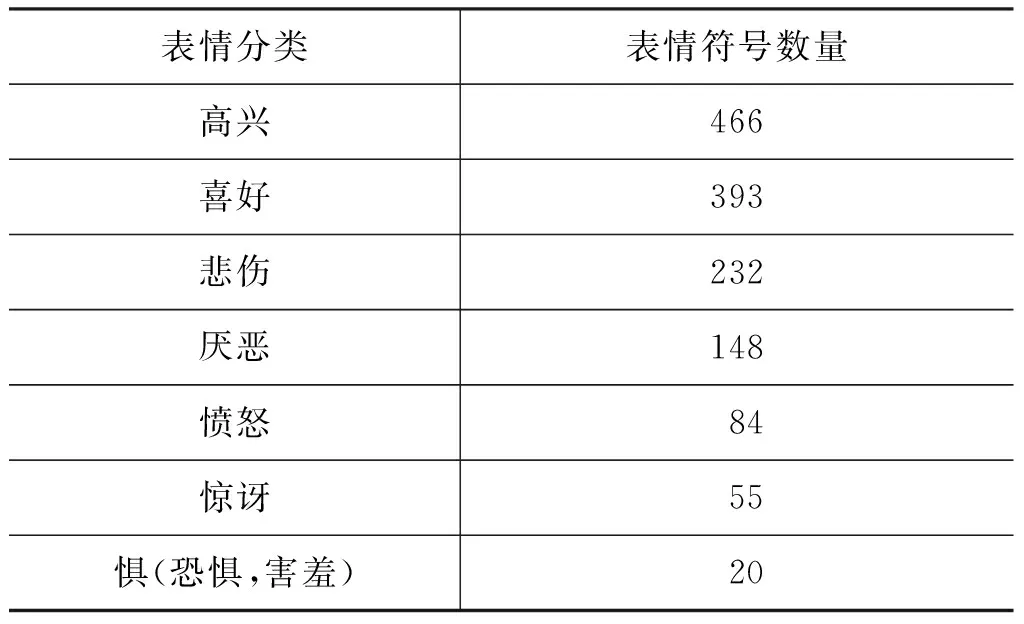
表7 情感微博各类别包含表情符号数量
5.1 预处理
在数据分析前需对微博文本进行一系列的预处理,主要包括中文分词及词性标注、停用词过滤、特征选择等步骤。
中文分词是文本预处理时的第一个关键问题,分词效果将直接影响文本聚类效果。本文采用中国科学院的ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)系统;保留了微博表情符号,并做了统一化处理;去除停用词,包括代词、助词等,使文本表示更准确,同时降低文本特征维度、提高文本聚类等算法效率。
5.2 微博聚类实验及其效果分析
采用NLP2013评价标准[13],使用宏平均(Macro)和微平均(Micro)的准确率(Precision)、召回率(Recall)、F值(F-measure)作为评价指标,具体计算方法见式(3)~式(8)。
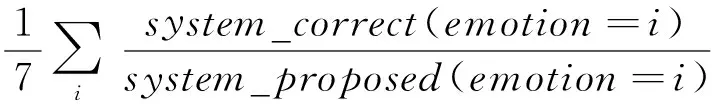
(3)
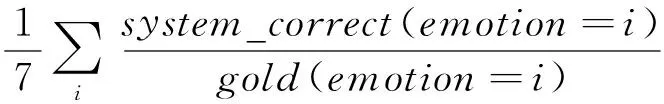
(4)

(5)

(6)
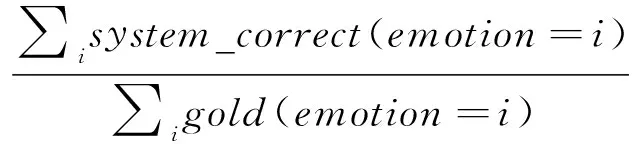
(7)
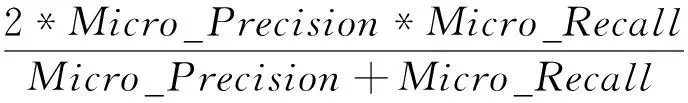
(8)
其中,gold是人工标注结果的数目,system_correct是预测与人工标注匹配的数目,system_proposed是预测数目,i为本文七类情感之一,一般来说F值(F-measure)越大,表示聚类效果越好。
表8为本文方法的情感聚类结果,从表中可以看出本文融合显性和隐性语义聚类方法可以有效地对微博情感进行分析。
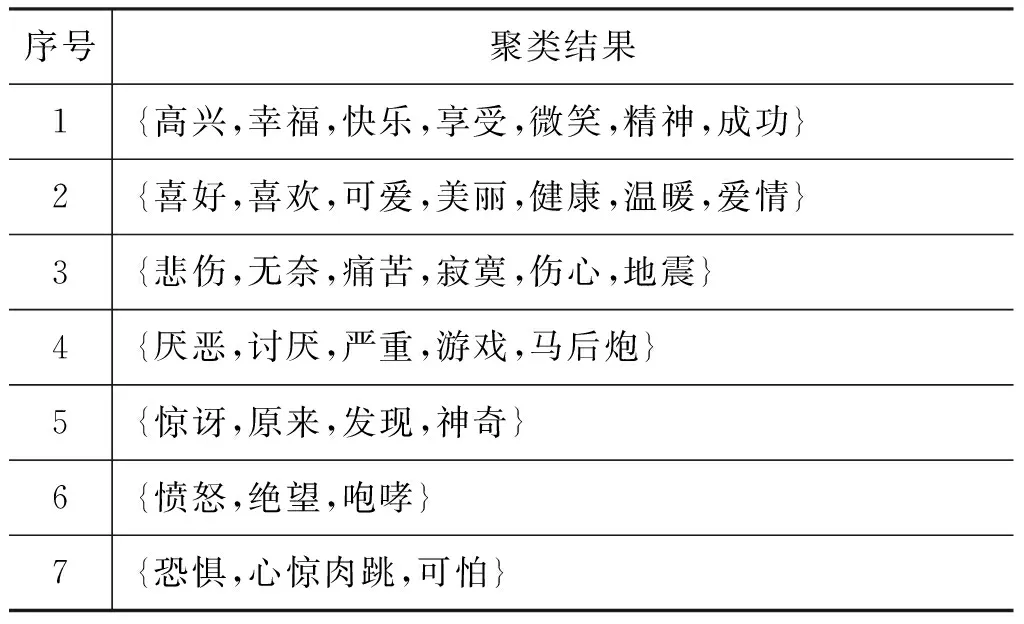
表8 聚类簇结果
为了验证本文提出的融合显性和隐性聚类情感分析方法的有效性,分别通过表9中方法对数据进行了对比实验。
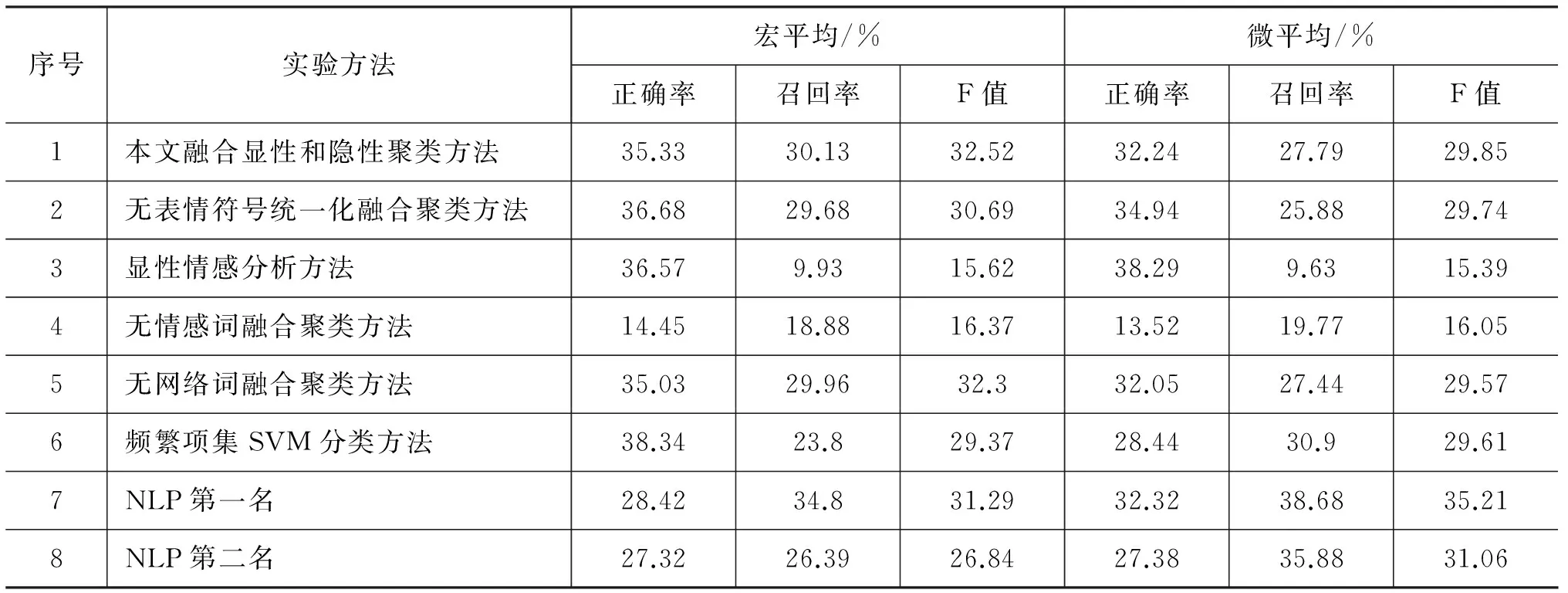
表9 算法评测指标结果
根据以上的实验结果,对宏平均和微平均的正确率、召回率、F值变化等数据进行以下分析:
(1) 实验1采用融合显性和隐性聚类方法,进行了表情符号统一化处理,实验2没有表情符号的统一化处理。对比实验结果,表情符号统一化可提高算法性能。
(2) 实验3直接利用微博显性情感特征进行情感类别判定,并考虑了否定词。该方法获取的情感微博量较少,故实验结果中宏平均,微平均中的正确率值较高,召回率偏低,总体F值较低。
(3) 实验4不考虑情感词的融合聚类分析,实验5不考虑网络词汇的融合聚类分析。比较实验2、实验4和实验5发现对于情感分析的影响,情感词>表情符>网络词。
(4) 实验6将融合显性特征提取的频繁项集,经过归一化后的向量即为该微博最终向量表示,然后,将向量化的4 000条微博训练集调用Libsvm[14]中进行训练,设置RBF核函数参数c和g,得到分类模型,将10 000条微博测试集预处理并向量化,利用分类模型,得到测试微博的分类结果,比较SVM方法与本文聚类方法,本文方法有略微优势,因训练数据集仅4 000条,对分类模型建立会有一定的影响,本文方法相对更为灵活。
(5) 此外,本文提出的方法还与NLP2013情感类别判定方法中排名前两名的方法进行了比较。本文方法宏平均较高,微平均较低,这是由于本文采用频繁项集聚类方法,七种情感的识别效果有明显差异: 高兴、喜好、悲伤这三种情感的微平均F值较高,而恐惧、惊讶情感的微平均F值都较低(因恐惧情感不容易识别,且该类情感预料较少)。
此外,本文从新浪微博广场上通过关键字搜索,获取2013年3月8日至2013年5月12日之间关于“马航事件”的44 524条微博数据。图3描述了“马航”事件每日微博数据量的变化趋势。
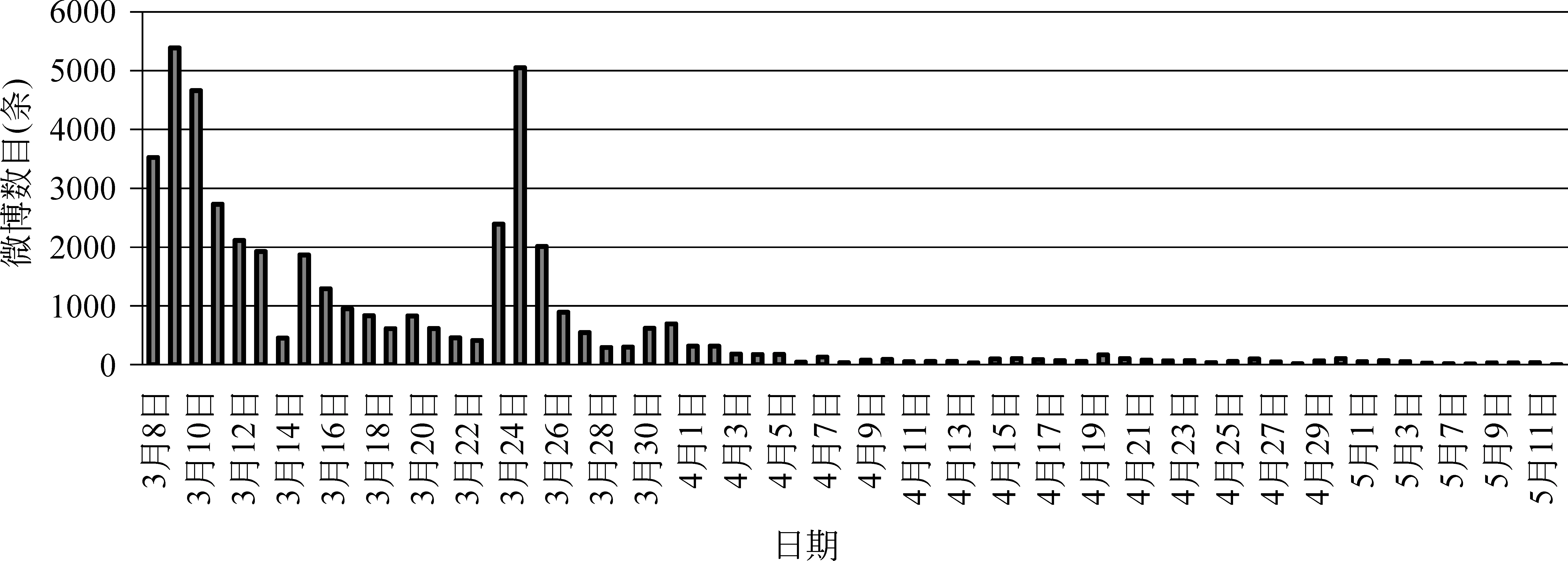
图3 “马航”事件每日微博数据量发展趋势
从图3可以发现,4月8日后“马航”事件微博量较少,平均低于100条,所以本文主要分析3月8日到4月8日“马航”事件微博。图4表述了3月8日到4月8日民众对“马航”事件情感变化趋势。
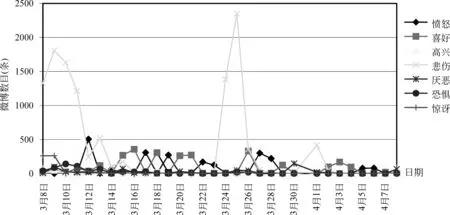
图4 “马航”事件情感变化趋势
结合图4“马航”事件情感变化趋势与“马航”事件实际发展状况,下面就几个关键时间点进行分析:
3月8日,马航官网发布第一份声明: 确认北京时间8日2时40分MH370航班与塔台失去联系。微博情感为“悲伤”、“惊讶”、“恐惧”,表现民众对受难乘客的担心、对该航空安全的震惊和恐惧心理,“高兴”和“喜好”情感处于较低水平。
3月9日,马来交通部长确认两位持假护照者票号相连。因失联飞机已经40多个小时没有消息,民众“悲伤”情感明显上升,且出现持假护照事件,“恐惧”、“厌恶”情感同时上升。
3月10日,马来西亚官方承认失联航班有被劫机可能。民众“悲伤”情感持续,因存在“劫机”情况,疑似恐怖袭击事件,民众“恐惧”情感继续上升。
3月12日,马来西亚方面被质疑是否刻意隐瞒信息或拖延搜救进程。故“愤怒”情感大幅度升高,且占当天微博量的58%。
3月24日,马总理召开新闻发布会,失联多日的马航MH370客机坠入南印度洋,机上无人幸存。“悲伤”情感达到最高,民众对该噩耗深表痛心。
随着时间的推移,整个马航事件进入后期的反省、处理阶段,民众关注点开始逐渐转移。
6 结论
本文提出融合显性和隐性特征的聚类方法。首先将微博表情符号进行统一化处理,引入大连理工大学情感词汇表、知网情感字典和网络情感词典;然后采用频繁项集聚类方法构建初始情感簇;针对初始情感簇间的微博重叠问题,提出一种基于语义隶属度划分的初始簇重叠消减算法,克服了微博短文本语义表达简短及形式多样化等引起的情感二义性问题;最后给出一种面向微博情感凝聚式层次聚类方法,利用聚类参数调整获得最佳微博情感分类。
因微博具有独特性,情感分析仍面临诸多问题,情感之间的关联性、句子中词语的权重以及适当的词语组合或句式特征等方面还有进一步研究的空间。
[1] 赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报,2010, 21(8): 1834-1848.
[2] Jichang Zhao, Li Dong, Junjie Wu, et al. MoodLens: An Emoticon-Based Sentiment Analysis System for ChineseTweets[C]//Proceedings of the Eighteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD),2012: 1528-1531.
[3] 徐琳宏, 林鸿飞, 潘宇, 等. 情感词汇本体的构造[J].情报学报, 2008, 27(2): 180-185.
[4] 贺飞艳,何炎祥,刘楠.面向微博短文本的细粒度情感特征抽取方法[J].北京大学学报,2014,50(1):48-54.
[5] Go A, Bhayani R, Huang L. Twitter Sentiment Classification using Distant Supervision[M]. Technical report, Stanford Digital Library Technologies Project, 2009.
[6] 谢丽星,周明,孙茂松.基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报.2012,26(1): 73-83.
[7] Dmitry Davidov, Oren Tsurm, Ari Rappoport.Enhanced Sentiment Learning Using Twitter Hashtags andSmileys[C]//Proceedings of the FourteenthConference on Computational Natural LanguageLearning, CoNLL 10, Uppsala,Sweden.2010:107-116.
[8] Cambria E, Song Y, Wang H, et al. Semantic Multidimensional Scaling for Open-Domain SentimentAnalysis[J]. Intelligent Systems, IEEE, 2014, 29(2):44-51.
[10] B C M Fung, K Wang, Ester. Hierarchical Document Clustering Using Frequent Itemsets[C]//Proceedings of the SIAM International Conference on Data Mining, 2003.
[11] 《知网》中文版.[EB/OL]http://www.keenage.com/html/c_index.html.
[12] 朱嫣岚,闵锦,周雅倩等.基于Hownet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[13] http://tcci.ccf.org.cn/conference/2013/dldoc/ev02.pdf.
[14] http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
Chinesemicro-blog Sentiment Analysis using Both Explicit and Implicit Text Features
CHEN Tieming, MIAO Ruyi, WANG Xiaohao
(College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou, Zhejiang 310023,China)
Micro-blog sentiment analysis is a key technique of public opinion research for social networks. Micro-blog emoticons and sentiment words are both of intuitive called as explicit emotion features, while the content semantics are called implicit features which sometimes are very important for micro-blog emotion discrimination. Therefore, in this paper, a new systematic methodology for sentiment analysis is proposed using both explicit and implicit emotion features. At first, the sentiment analysis dictionary, the glossary of social networking terms, as well as the emoticon library, are all initialized. Then, the text micro-blog frequent word sets are defined. According to the feature set of words, the initial micro-blog clusters can be directly generated depending on the maximum frequent item sets. Furthermore, as to solve the micro-blog overlap problem between multiple initial clusters, an efficient elimination method is proposed employing the extended membership degree of the short-message semantic. Finally, the semantic similarity matrix for each separated cluster is defined, based on which a hierarchical sentiment clustering for micro-blogs is conducted. Taking the well-known contest NLPCC2013 in China as instance, the efficiency of our proposed method is proved by the comparing experiments. At last, a real-world case is also done to exactly show the emotion change from Chinese micro-blogs for the Malaysia Airlines Disappear Incident during March 8 to Spril 8, 2014
emoticons; emotion dictionary; semantic; frequent item set; clustering

陈铁明(1978-),博士,教授,主要研究领域为网络与信息安全。E-mail:tmchen@zjut.edu.cn缪茹一(1983-),硕士研究生,主要研究领域为文本挖掘和舆情分析。E-mail:mryzjut@gmail.com王小号(1981-),实验师,主要研究领域为网络与信息安全。E-mail:wxh@zjut.edu.cn
1003-0077(2016)04-0184-09
2014-09-15 定稿日期: 2015-03-20
国家自然科学基金重点支持项目-NSFC-浙江两化融合联合基金(U1509214)
TP391
A
猜你喜欢
消费电子(2022年6期)2022-08-25
疯狂英语·新阅版(2020年11期)2020-12-21
开放教育研究(2020年2期)2020-03-31
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
计算机技术与发展(2017年8期)2017-09-01
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
大作文(2016年7期)2016-05-14
长江学术(2016年4期)2016-03-11
