
一种基于Heat Map的地理标签数据可视化表达的研究
2016-04-11 01:00:34华一新
测绘工程 2016年6期
赵 婷,华一新,李 响,李 翔,杨 飞
(信息工程大学 地理空间信息学院,河南 郑州 450052)
一种基于Heat Map的地理标签数据可视化表达的研究
赵婷,华一新,李响,李翔,杨飞
(信息工程大学 地理空间信息学院,河南 郑州 450052)
摘要:地理标签数据是指蕴含在网页、照片、微博等信息媒介中的地理空间信息,其表现形式通常是经纬度坐标。通过分析地理标签数据的研究现状,对地理标签数据进行分类,并归纳地理标签数据具有属性数据非结构化、海量信息分布不均、强调位置相对关系等特点。针对其中一个特点,通过对K-means算法进行改进,结合计算机图形学相关知识,利用热力图表达地理标签数据的分布特征。最后,通过与ArcGIS核密度图、散点图进行比较,得出该热力图算法具有表达效果明显、用户体验好等优点。
关键词:地理标签数据;可视化;热力图;K-means聚类
随着移动互联网技术的进步,对地理信息应用研究的深入,制图者与地图使用者的界限变的模糊,传统的制图方式发生变革;新地图学委员会的成立,也同样预示着新的地理时代已经悄然来临。伴随着智能移动终端的普及,人们越来越习惯于通过智能移动终端上的应用及时获取或分享信息。在使用此类应用的过程中,产生了海量的含有地理位置信息的社交数据,我们称这类爆发性增长的新型数据为地理标签数据(Geotagged data),由于该数据的产生与人类活动息息相关,为可视化研究领域带来了新的挑战。
地理标签数据[1]指在HTML网页、照片、微博等信息媒介显式或隐式植入的地理空间信息,其表现形式是地理经纬度坐标,也包含高程、范围、形状等其它地理空间信息,采用的是与传统空间数据组织结构(即用“数据分层”以及“几何+属性”)不同的形式。
根据地理标签数据的数据结构,一般常用k-means算法生成地理标签聚类。其核心思想是基于聚类对象的属性将数据分为k组,最终实现类内方差最小化。然而该算法虽然方法简单且保证了计算速度,但是牺牲算法精度;其结果的准确性很大程度上取决于最初的簇集;k值需提前给定。有很多采用该算法生成任意聚类的例子,在这些例子中,没有依据初始的种子点位置,且在随机选取中心点的概率甚至无限高。
对此,本文采用一种根据非常具体的概率来选择初始种子点的方法来对k-means方法进行初始化,利用启发式算法来确定k值,以此提高聚类算法的精度;此外,在研究地理标签数据的基础上,分析归纳该数据特点,选择合适的可视化方法进行表达。针对其中一种可视化方法——热力图,结合该聚类算法进行实现,并对此做出评价。
1地理标签数据分类
地理标签数据的存在形式通常有:照片、视频或音频文件、SMS消息、地理位置微博、网页、维基百科的文章应用等。其三种数据类型可归纳为:地理标签文档、地理标签照片、地理位置微博。
地理标签文档:现在对地理标签文档的研究大都以维基百科为主,维基百科有大量的数据,可将其作为数据源对其内容进行知识挖掘,从而提取相关关联。如通过研究地理标签文档和作者所在地理位置进而判断两者之间是否存在一定的空间规律[2]。
地理标签照片:从地理标签照片中获取的信息主要有三类:照片本身;除地理标签外其他标签信息,可称为注释信息;拍摄者信息(包含设备信息)。Flickr[3]网站常常用于获取照片、视频等含地理坐标的多媒体产品,该平台给人们的生活带来便利,对地理标签照片的研究也大都基于Flickr。如Eric Fischer[4]建立了一系列“本地人和旅游者”的城市分布地图,从中清晰地分辨本地人和旅游者对同一个城市不同地方的喜好,即从地理标签照片上挖掘事件和用户行为。
地理标签微博:也称位置微博,因含有地理空间位置信息的标签信息,常用于挖掘地名和兴趣点或是地理舆情的预测。国内对位置微博[5,6]的研究较为火热,对其他两种标签数据研究较少。
2地理标签数据特点分析
从空间数据可视化方法的角度对地理标签数据特点进行分析,可视化方法可以表达数据的探索发现特征、位置分布特征、表达空间统计特征,并且由于地理标签数据具有强调位置相对关系、海量信息分布不均、属性数据非结构化这三个特点,故而可基于以上特点进行可视化方法分类。
属性信息非结构化:与传统的矢量数据不同,地理标签数据的属性信息可能是非结构化的,需要对这种非结构化的文本信息进行可视化研究;而标签云是一种从大文本中提取有效知识的可视化方法,适用于文本信息的表达,是文本分析处理的简单而高效的可视化表达方法,所以利用标签云与表达地理位置的地图相结合而得到的标签云地图能更好地表示含有文本信息的可视化。
海量信息分布不均:随着地理标签数据以百万级涌现,其密集程度很高,此时单个点的显示没有意义,只有把多个点聚合起来可视化研究才有意义,据此可采用热力图来研究地理标签数据的分布统计特征,以一种非常直观的形式来呈现密度信息,带来效果明显的用户体验。
强调位置的相对关系:随着互联网发展不断涌现出的海量的地理标签数据,研究其个人绝对位置(即精准位置)已经没有意义,更多是表达地理标签数据的相对位置关系,可采用拓扑图来表达地理标签数据的相对位置关系。
从新地理信息时代的[7]角度,通过与传统统计数据的对比,研究地理标签数据进的特点,如表1所示:

表1 地理标签数据与传统统计数据的比较
3基于Heat Map的标签数据可视化表达
本文以地理标签数据的海量数据分布不均的特点为出发点,利用热力图研究地理标签数据的分布特征。热力图(Heat Map)最初作为一个研究模型于2006年在微软公司内部发布,随着地理位置相关的空间信息大量涌现,热力图的应用范围得到更大拓展。它是数据可视化(Information Visualization) 中常用的一种方法,直观地反映地理对象某一特征的空间分布态势。
3.1热力图生成步骤
热力图是一个理想的表达密度空间数据的解决方法,它清晰地揭示了高发地区的分布情况,其生成过程如下:
1)建立一个含有256个RGBA值的数组,这个数组用来当作热力图的配色矩阵(调色板),其中A代表Alpha通道,用来记录图像中的透明度信息。地图上的热区赋予数组靠右的颜色,而冷区赋予靠左的颜色如调色板图1所示。

图1 调色板
2)坐标系转换。将经纬度坐标转换为屏幕坐标,可利用百度地图Web服务API为开发者提供的http接口,即用java发起http请求,然后解析json或xml数据等,也可使用Chunk Taylor的“地缘/UTM转换算法[9]”进行坐标转换。
3)标签聚类。由于地理标签数据中包括坐标信息以及注释信息,可首先利用坐标信息来创建地理聚类。为提高聚类精度,可选择k-means ++算法[8]来确定初始种子点,随后可采用启发式算法来确定k值,通过该方法,最终得到这个k值、初始种子点的位置。完成数据集的聚类时,每一个聚类标签具有三个属性:标签名称、中心点坐标、聚类半径,其中聚类半径由中心点到其成员距离的平均值通过欧氏距离计算得到。
4)计算中心点透明度。反映热点颜色深浅的变量值,即透明度(Intensity),透明度也可称为对象的影响因子,该值作为每个对象的影响范围的中心点的透明度,热点的颜色深浅直接表达出数据的变化特征[10]。常见的计算对象透明度公式如下:

(1)
其中,Z代表中心点待表示特征值,Z0代表数据集中待表示特征值的最小值,Zmax代表待表示特征值的最大值。
5)绘制灰度图。以每个点的坐标值作为中心点,并以第4节标签聚类半径为半径绘制一个颜色渐变的圆。中心点颜色最深,从圆的边缘到中心点颜色逐渐变浅,直至所有点的渐变圆绘制完成。
6)灰度图色彩化。利用调色板中的值对图中每一个像素进行色彩化,选择RGBA模型中任意通道(R、G、B任选其一)值(0~255)作为配色矩阵的索引,并提取通道值来代替旧颜色,完成灰度带到调色板的映射。
3.2热力图实验
本文以近40年全球地震分布带以及地震等级对周边的影响为例,利用主题爬虫技术从互联网上获取1973年至今全球各地发生地震的时间、位置、震级等地理信息,采用C#语言,并结合计算机图形学相关知识,在VS2013平台上进行图形图像编程,实现全球地震分布的热力图,并结合地震带地图集对所得结果进行验证,以确保该方法的有效性,其过程如图2所示。

图2 热力图生成流程
3.2.1数据获取
通过分析地理标签数据特点,可通过网络爬虫技术获取这类数据。网络爬虫工作原理是一种按照规则自动抓取万维网信息的程序或脚本。它首先获得初始网页上的URL,在抓取网页的过程中不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。本文实验数据通过爬取地震相关网站,经过正则表达式等方法进行匹配,得到含有经度、纬度、地震发生时间、震级等信息。其字段存储结构如表2所示:

表2 字段存储结构
3.2.2数据分年
为研究近40年全球地震带的变迁,需对获取的数据进行分年,每十年为一个节点。通过建立读写文件的指针读取文件,然后以动态链表的形式开辟存储空间,依次将文件中的各个字段读到内存中,通过对字段进行处理得到分年后的文件。也可将数据存储在服务器中,利用ArcGIS Server发布地图服务调用所需数据。
3.2.3热力图算法实现
从数据库读取全球地震数据后,利用k-means算法和k-means++算法,对标签数据进行聚类分析,随后通过灰度圆叠加得到灰度图,再根据灰度图与调色板的映射关系进行色彩化,最终得到热力图图层。可以采用百度、谷歌等地图作为底图,然后将生成的新图层与底图叠加,从而得到完整的热力图。
3.3结果分析
图3为通过改进的热力图算法生成的1973—1982年地震分布热力图,可看出地震高发带大都集中在各大板块的交界处,分布情况与三大地震带相符合,即环太平洋地震带、欧亚地震带和海岭地震带,可见该种热力图分析方法是合理的。此外,采用地理标签数据作为实验数据,可实时获取最新的信息,获取速度快,成本低,且信息量丰富,为研究分布特征提供分析支持,尤其是为政府部门对某些突发事件提供决策支持。
图4分别为利用1973—1982年地震数据得到
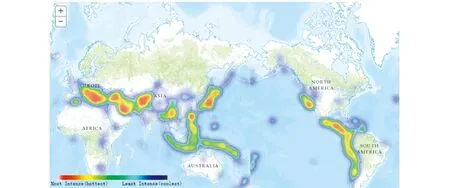
图3 1973—1982年地震分布热力图

图4 ArcGIS核密度图、散点图
ArcGIS生成的核密度图、散点图,图3、图4中这三种方法都可以表达数据的分布特征,对上述三种方法从用户体验、表达效果2个方面进行比较。
1)点密度法采用的颜色过于单一,且无法反映数据分布的差异性,由于数据量的增加,不能通过多张点密度图来观察事件的发展变化趋势,用户体验差。图5是利用热力图得到每十年地震带分布的变化图,可看出欧亚板块与印度洋板块活动较频繁,地震发生频率逐年增加,需要当地政府对这一带地区加强防震意识,减少地震对当地的损失。
2)热力图和ArcGIS核密度图都可以通过设置颜色梯度很好地反映数据分布的差异性,效果好,数据越密集越热,颜色越亮。
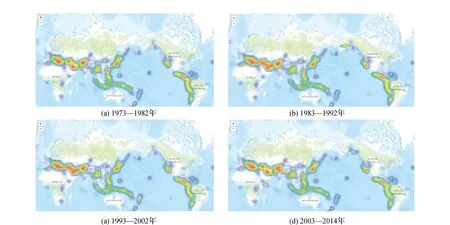
图5 1973—2014年每10 a全球地震分布热力图
4结束语
地理标签数据是大数据时代和科技发展的产物,其对人们生活的影响越来越大。本文分析了地理标签数据的数据类型与特点,研究了标签数据的可视化技术,并通过改进k-means算法实现了地震带热力图,验证本实验中热力图的可用性和优越性。由于地理标签数据的内涵是不断发展的,今后还需要研究更多技术以完善标签数据的可视化技术。
参考文献:
[1]Geotagging[EB/OL].(2015-01-09)[2015-04-03].https://en.wikipedia.org/wiki/Geotagging.
[2]HARDY D.Volunteered geographic information in Wikipedia[M].University of California,Santa Barbara,2010.
[3]HAUFF C.A study on the accuracy of Flickr’s geotag data.Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval[C].ACM Press,2013:1037-1040.
[4]FISCHER E.Locals and Tourists[J].Av Proyectos,2015:70-71.
[5]袁晓如,张昕,肖何,等.可视化研究前沿及展望[J].科研信息化技术与应用,2011,2(4):3-13.
[6]张恒才,陆锋,陈洁.微博客蕴含交通信息的提取[J].中国图象图形学报,2013,18(1):123-129.
[7]李德仁,邵振峰.论新地理信息时代[J].中国科学(F辑:信息科学),2009,39(6):579-587.
[8]ARTHUR D,VASSILVITSKII S.k-means++:The advantages of careful seeding.Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms[C].Society for Industrial and Applied Mathematics,2007:1027-1035.
[9]TAYLOR C.Geographic/utm coordinate converter[Z/OL].(2003-06-20)[2015-01-09].http://home.hiwaay.net/~taylorc/toolbox/geography/geoutm.html.
[10] 曾毅,高斌,李明铭,等.一种HeatMap技术可视化GIS三维数据方法[J].电脑编程技巧与维护,2012 (22):120-122.
[责任编辑:路晓鸽]
Research on heat map visualization of geotagged dataZHAO Ting,HUA Yixin,LI Xiang,LI Xiang,YANG Fei
(School of Geospatial Information,Information Engineering University,Zhengzhou 450052,China)
Abstract:Geotagged data means being embedded in web pages,photos,microblogging and other information media geospatial information,on which the manifestations are usually latitude and longitude coordinates.This paper,through the analysis of the research status of geotagged data,classifies the geographic label data and summarizes non-structured attribute data,mass distribution of information,and the relative position relationship.And for one of the features,K-means algorithm is proposed to use Heuristic algorithm to determine the k value.Combined with knowledge of computer graphics,the heat distribution graph is used to represent the geotagged data.Compared with scatter diagram and ArcGIS nuclear density map,this algorithm has high efficiency of being expressive and user-friendly.
Key words:geotagged data;visualization;heat map;K-means cluster
中图分类号:P208
文献标识码:A
文章编号:1006-7949(2016)06-0028-05
作者简介:赵婷(1987-),女,研究生.
基金项目:国家自然科学基金青年科学基金项目(41401467);国家自然科学基金面上项目(41471336);国家自然科学基金(41271450);国家科技支撑计划(2012BAK12B02)
收稿日期:2015-05-18
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
英语文摘(2021年4期)2021-07-22 02:36:30
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
现代临床医学(2019年4期)2019-09-10 07:44:02
传媒评论(2019年4期)2019-07-13 05:49:14
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
中学历史教学(2017年12期)2018-01-19 03:00:23
公民与法治(2016年10期)2016-05-17 04:12:58
