
基于KNN和Bayes算法的组合分类器的垃圾评论识别研究
2016-04-08 10:11梁曌陈思宇梁小林康欣
经济数学 2016年1期
关键词:互信息
梁曌 陈思宇 梁小林 康欣


摘 要 产品垃圾评论在一定程度上影响了评论信息的参考价值,本文旨在建立识别模型将垃圾评论从评论文本中剔除,保留真实的产品评论。首先,分析了产品评论的特点,从数据搜集、文本预处理、互信息检验、文本表示4个模块提取了14个特征。然后,利用高互补性建立了基于KNN和Bayes算法的组合分类器模型。最后,利用交叉验证对iPhone 6 Plus的产品评论进行检验,得到评价指标分别为:正确识别率75.3%、召回率82.1%以及F1值77.5%.
关键词 KNN算法;Bayes算法;组合分类器;互信息;交叉验证
中图分类号 O213;TP18 文献标识码 A
1 引 言
电子商务的异军突起促使网购走进人们的日常生活,网购的同时,多数网民会在不受约束的情况下对相关产品发表评论,而这种随意性往往使得这些产品评论中充斥了大量无用的、不真实的信息,这些信息就是垃圾评论.垃圾评论在一定程度上影响了评论信息的参考价值,从而误导潜在消费者并干扰销售商对销售业绩的评价.产品垃圾评论的识别旨在解决这一问题,将垃圾评论从评论文本中剔除,保留真实的产品评论,为用户提供可靠的参考依据.
结合近几年垃圾评论识别的文献可知,垃圾评论识别的关键问题是文本特征的提取与分类算法的选择.N Nitin Jamal和Bing Liu等[1]首次对垃圾评论进行了分类,很好地识别了英文领域中存在的无用评论,但由于中英文之间存在差异,往往英文领域的垃圾识别方法不能直接有效地应用到中文领域当中.游贵荣等[2]提出了中文垃圾评论的特征提取方法,邱云飞等[3]、吴敏等[4]、李霄等[5]分别从用户行为、产品特征的显著性检验以及信息的有用性角度对垃圾评论的识别进行了研究,但在分类器的选取上,上述学者均采用单一算法的分类模型,如单一的Logistic回归算法等.大量的理论与实验结果表明,多分类器系统不但可以提高分类的正确率,而且可以提高识别系统的泛化能力和鲁棒性.与此同时所有分类器都参与集成的效果并非最好,从众多分类器中选择部分互补性强的分类器进行集成可以提高集成的效率并改善其效果[6].因此本文在建立文本特征表示模型的基础上,提出了用高互补性组合分类器对评论进行识别和过滤.
2 文本特征的提取
2.1 产品评论的特点与垃圾评论的分类
为了更准确地识别垃圾评论,首先探讨产品评论的特征.
通过对中文产品评论中的评论文本进行分析,总结出中文产品评论领域的特点主要体现在以下几个方面:
1)评论文本格式自由多样;
2)评价对象的多样化;
3)评论内容具有近似重复性;
可分为①由不同评论者针对同一产品发表的近似重复评论;②由同一评论者针对不同产品发表的近似重复评论;③由不同评论者针对不同产品发表的近似重复评论;
4)不真实评论;
5)广告;
6)不带有感情色彩的随机文本.
基于以上分析,将垃圾评论定义为以下5种类型:-
1)非指定产品的评论:该类评论的特点为它虽然是评论,但只对品牌和制造商,甚至是站点评论,而没有针对当前产品本身进行评论,或者确实是对产品进行了评论,但是评错了产品.如在苹果手机的评论中,“买SONYZ3也不错啊,很漂亮,旗舰机...”等
2)虚假评论:如“我这有全新的iPhone6 Plus,只要99元”等.
3)广告评论:如“苹果超爱大屏幕3 500元拿现货QQ热购122929079”
4)无意义文本:
①个人的消费经历,如“再烂都永远有人疯抢,飘扬过海甚至成为一部手机,实在不懂.”②人身攻击,如“用苹果的都是脑残”等,③其他无关文本,如“信号不好等”“转给我呗?”
5)咨询性评论:只是询问关于产品的情况,而不是评论.如“多少钱呢?”.
2.2 特征提取与量化
为了建立产品垃圾评论识别模型,根据2.1节的分析结果,分4个模块对产品评论文本进行特征提取与量化.
模块一 数据的搜集
本文采用WebHarvest网络爬虫对京东商城和天猫商城内多个商家的iPhone 6 Plus的产品评论进行爬取,得到由两万条产品评论组成的数据集A0,同时对苹果官网上关于iPhone 6 Plus的产品参数进行爬取,得到产品属性数据集B0.
模块二 对爬取的数据集进行预处理
1)构造用户词典.用户词典包括停用词词典、极性词词典,其中极性词词典主要是由HowNet极性词加上一些评论作者常用的、和表达情感有关的网络流行词,及一些口语化的词语与缩写组成,用以表达用户褒贬倾向和感情色彩.停用词词典由网络上现有的停用词词表加上针对垃圾评论特性的停用词组成[7-9].
2)文本分词.中文单词是评论信息处理的基础,分词工具采用中科院提供的分词工具ICTCLAS 2015分词系统[10],其主要功能包括中文分词、词性标注,同时允许用户向系统中导入自定义词典以提高特定领域的分词效果,因此,将上述用户词典与产品属性数据集B0作为自定义词典导入ICTCLAS分词系统后,对数据集进行逐条分词、词性标注以及情感词标注,得到预处理后的数据集A.
模块三 特征的互信息检验
为了选取最能表达文本信息内容的特征,本文从被评论的商品、评论者、文本结构、情感倾向、主题词五个属性提取特征,在提取特征之前,先利用互信息说明这5个属性对识别垃圾评论具有显著相关性.-
互信息是2个事件集合之间的相关性,通常用来衡量某个属性和类别之间的统计独立关系,互信息量越大,代表特征项与类别之间的贡献概率也越大.现对所选特征进行互信息检验,旨在说明所选属性能在一定程度上反应该条评论的信息,即所选属性项是互信息量较大的词条,互信息(MI)定义如下endprint
2)高互补性分类器
高互补性分类器组合的构建流程大致为:首先构造一定数量的候选分类器如Bayes分类器、KNN分类器、SVM分类器和logistics回归分类器等,计算分类器之间的相关程度,然后根据相关系数对候选分类器进行排序,并依据可信度,选择出对目标有较高识别率的分类器组合.
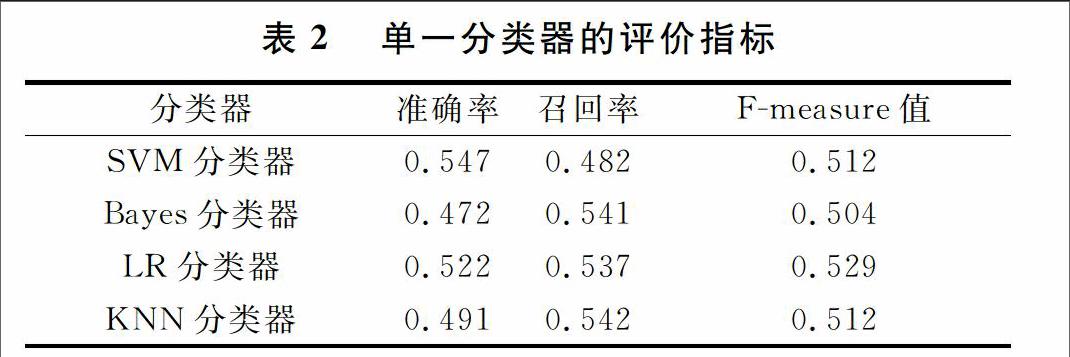
首先,验证单一算法分类器的局限性.利用数学软件MATLAB,对其进行基于多层BP网络的识别模式的标记,对上述四种分类器用SPSS比较其准确率,召回率以及Fmeasure值.得表2.由表2,垃圾评论识别的准确率相对偏低,不少数量的正常评论被识别为垃圾评论;其召回率也不高,直观来看是有些垃圾评论被判别为正常评论.可见单一分类算法的过滤效果并不理想,本质原因是分词的不准确性使得评论文本特征有限的缺点充分暴露,以致于对结果的准确性产生很大影响,而且Bayes分类器要求各个特征项之间相互独立,这显然于现实不符.同时也从侧面说明单一算法的分类器对数据量要求很大,需要对较为完备的训练集特征进行学习[6].
为了更准确地进行垃圾评论识别,本文对各分类器进行组合,得到高互补性分类器.根据高互补性分类器组合理论,利用相关系数对上述4种分类器的互补性进行分析,即相关系数大的分类器组合互补性弱,相关系数小的分类器组合互补性强.
利用SPSS软件对其进行相关分析,见表3.
由表3,相关系数的大小排序为:
SVM+Bayes>SVM+KNN>Bayes+LR> LR+KNN>LR + SVM>Bayes+KNN.
其对偶命题互补性排序为:
SVM+Bayes LR+KNN 可见Bayes分类器和KNN分类器的相关性最低且显著性均大于0.01,即可认为他们之间的互补性最强,存在统计学意义.而SVM分类器和Bayes分类器的相似度较高,且显著性大于0.01,认为存在统计学意义.为了进一步验证这4种分类器的互补性,对这6个组合进行聚类检验. 用SPSS软件对其进行聚类分析,结果见表4 由上可知,互补性最强的组合分类器为Bayes+KNN分类器. 3.4 模型的交叉验证 本文利用WebHarvest爬虫从天猫和京东商城爬取了20 000条评论作为原始数据集A0,将构建好的用户词典与产品属性数据集B0导入ICTCLAS 2015分词系统后,得到预处理数据集A,对A中的每个数据类型进行人工标记,再随机地将其等分成4份得到A1、A2、A3、A4. 先以数据集A1为检验集,A2,A3,A4为训练集,计算模型的性能指标.首先将数据集A2,A3,A4的特征向量导入Bayes+KNN组合分类器对其进行训练,然后将检验集A1的特征向量导入到已训练好的分类器中,得出检验集中相应评论是非垃圾评论还是垃圾评论,最后根据分类器对每条评论判定的结果以及人工标记,计算该训练集和检验集组合下,分类器的性能指标.用同样的方法得到依次以A2、A3、A4为检验集的分类器的性能指标,相关结果见表5.-将上述3个评价值平均得,基于KNN算法和Bayes算法的垃圾评论识别模型的最终准确率达到75.3%,召回率为82.1%,F1值为77.5%,结果较为理想,有应用价值. 4 结束语 垃圾评论识别的关键问题是文本特征的提取与分类算法的选择.本文根据中文评论的特点提取了14个特征,并利用组合分类器算法对垃圾评论进行了识别,得到了较理想的结果.通过搭建基于Hadoop的大数据平台集群,本模型可推广到一个基于通过海量数据集进行训练的垃圾评论问题,从而实现此模型适用于更一般产品的垃圾评论的检测目标.- 参考文献 [1] N JINDAL, B LIU.Opinion spam and analysis[C]//Proceedings of the first ACM international conference on Web search and data mining,2008:219-229. [2] 游贵荣,吴为,钱沄涛.电子商务中垃圾评论检测的特征提取方法[J].情报分析与研究.2014,251(10):93-100. [3] 邱云飞,王建坤,邵良彬等.基于用户行为的产品垃圾评论者监测研究[J].计算机工程.2012,38(11):254-257,261. [4] 吴敏,何珑.融合多特征的产品评论识别[J].微型机与应用.2012,31(22):85-87. [5] 李霄,丁晟春.垃圾商品评论信息的识别研究[J].现代图书情报技术.2013,29(1):63-68. [6] H J KANG,D DOERMANN.Selection of classifiers for the construction of multiple classifier systems[C]//Proceedings of the 8th- international conference on Document Analysis and Recognition. Seoul, Korea, 2005,1194-1198. [7] 知网[DB/OL].HowNet Knowledge Database[DB/OL].[2013-11-05]. http://www.keenage.com/ . [8] 赵文婧.产品描述词及情感词抽取模式的研究[D].北京:北京邮电大学计算机学院,2010. [9] 顾益军,樊孝忠,王建华.中文停用词表的自动选择[J].北京理工大学学报.2005,25(4):337-340. [10]ICTCLAS 汉语分词系统 (ICTCLAS Chinese Lexical Analysis System [CP/OL].[2015-10-05].http://www.ictclas.org/. [11]C C CHEN, Y D TSENG. Quality evaluation of product reviews using an imformation quality framework[J].Decision Support Systems. 2011, 50(4):755-768. [12]陈昀,基于数据挖掘技术的产品垃圾评论识别研究[D].保定:河北大学计算机科学与技术学院,2014.
猜你喜欢
计算机应用(2016年10期)2017-05-12
光学精密工程(2016年2期)2016-11-07
科学(2016年3期)2016-05-30
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
遥感信息(2015年3期)2015-12-13
黑龙江工程学院学报(2015年5期)2015-12-04
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
电测与仪表(2014年11期)2014-04-04
