
科学视频综合语义标注框架构建研究
2016-03-26 06:58祝忠明中国科学院兰州文献情报中心中国科学院大学
图书馆理论与实践 2016年1期
关键词:本体
王 敬,祝忠明(.中国科学院兰州文献情报中心;2.中国科学院大学)
科学视频综合语义标注框架构建研究
王敬1,2,祝忠明1(1.中国科学院兰州文献情报中心;2.中国科学院大学)
摘要:本研究意在构建一个适用于科学视频的语义标注框架,为科学视频的语义标注提供策略参考。在对科学视频进行内容语义和视频结构分析的基础上,把标注结果与关联数据连接,并借助领域本体、媒体片段标识符以及媒体资源本体等工具来完成标注框架的构建。科学视频综合语义标注框架可以实现科学视频的结构化、语义化浏览与导航以及科学视频及其片段的语义检索,并可为用户提供与科学视频内容相关的丰富背景信息。
关键词:科学视频;语义标注;关联数据;本体
1 引言
随着多媒体技术和数字图书馆技术的迅速发展以及web 2.0的广泛普及,科学视频已经成为科研过程中一种非常重要的非文本(Non-Textual)学术资源。科学视频一般指那些用于教育,或能向大众传播科学的新发现或见解的视频,[1]通常包含以下几种类型:科学实验演示视频﹑教学与讲座视频﹑会议与研讨会展示视频等。对科学视频进行保存﹑组织与开发利用已经逐渐得到数字图书馆和科研机构的重视。如:《JoVE》[2](Journal of Visualized Experiments,可视化实验期刊),是第一本致力于以视频方式展现医学和生命科学等领域研究过程和成果的期刊。与传统以文本格式呈现的期刊相比,JoVE综合多种媒体的优势,专注于通过视频来完整地传递科学实验的过程,使知识传递更加生动﹑直观,并在一定程度上解决了复杂实验难以还原和重复进行的问题。
面对不断增长的科学视频数量,通过快进﹑快退等简单操作浏览视频的传统方式已经不适应用户快速摄取专业知识的需求。因此,如何实现对科学视频的结构化﹑语义化浏览与导航是当前视频检索领域重点研究的问题。作为视频检索的必要基础,视频索引问题的解决将为基于视频数据库和互联网的搜索应用提供基本的技术支持。基于视频内容分析的语义标注,就是建立高性能视频索引的十分有效的方法。[3]视频的语义标注就是为某个视频的关键帧﹑镜头以及场景等分配相对应的高层语义概念,以反映视频的真实内容。
本文综合考虑科学视频的音频特征与结构特征,在语音分析与视频分割的基础上,引入关联开放数据﹑媒体片段标识符以及媒体资源本体等机制,提出一种针对科学视频的综合语义标注框架,并讨论框架各个组件的具体实现方法。
2 视频综合语义标注相关方法
仅使用某一种视频特征进行语义标注的方法往往不能够获得良好的标注效果,因此有学者尝试综合利用视频的多种特征(语音﹑视觉与文本等)来对视频进行更加全面﹑准确的标注。如:文献[4]从视频创作者的角度提出了一种基于多模态(视觉﹑音频﹑文本)的视频数据标注框架;文献[5]从视频的视觉﹑音频以及文本信息的分析入手,构建了一个音乐视频标注系统;德国国家科学图书馆的音视频搜索引擎AV-Portal利用场景﹑语音﹑文本以及图片的识别技术实现了对科学视频资源的自动语义标注。[6]以上视频的语义标注方法几乎都是在一个封闭的环境中实现的,并且还只停留在概念级别,对视频的背景信息,如视频中的人物﹑事件﹑地点等信息的表达有限。
也有一些研究为了能够给视频提供丰富的背景信息,尝试把视频的标注内容与关联开放数据连接在一起。如:BBC(英国广播公司)将节目以及音乐数据与关联开放数据源DBpedia和MusicBrainz进行连接。[7]Balthasar等[8]为了实现TV与网络内容的连接,使用自然语义处理工具抽取TV内容中的命名实体并将其与关联数据源进行映射。这些研究虽然把视频的标注与关联数据连接到了一起,但是它们所标注的是整个视频资源而不是视频片段,而且标注的视频对象也不包含本文所讨论的科学视频。
本文构建的科学视频综合语义标注框架所要实现的应用场景主要有以下几个方面。
(1)实现科学视频的结构化﹑语义化浏览与导航。用户在浏览科学视频时,可以根据视频摘要(以关键帧为单位的视频结构目录)直接定位至所要查看的关键帧,或者根据识别出的语义概念定位至与该概念相对应的关键帧,使用户彻底从传统的视频拖拽方式中解放出来。
(2)实现科学视频及其片段的语义化检索。用户使用语义概念检索科学视频时,检索结果不但包含与检索主题相关的整段科学视频,而且还包含与主题相关的科学视频片段。用户可以根据科学视频或视频片段的URI直接定位到所要查看的内容。
(3)为用户提供与科学视频内容相关的丰富背景信息。通过引入关联数据,用户在浏览科学视频内容时,根据浏览内容的不同,系统将展示与当前浏览内容相关的所有信息,从而丰富用户获取信息的体验。
3 科学视频综合语义标注框架的构建
科学视频可以重现科学研究过程﹑缩短科研周期﹑减少资源浪费,从而提高科学研究以及知识获取的效率。如:JoVE可以还原科学实验的完整过程,知识传递也更加生动;另外还可以利用教学视频学习专业知识,利用会议视频了解研究领域前沿动态等。这些典型的科学视频是科学研究以及学习过程中的宝贵资源,它可以以一种生动﹑直观﹑高效的方式传播科学知识,为用户提供一种身临其境的学习以及研究体验。随着这些科学视频资源数量的快速增长,对其进行存储﹑组织﹑检索与利用显得愈发重要。而对科学视频进行语义标注是实现科学视频有效组织与利用的重要过程。科学视频有其独有的特征,在进行语义标注时需要根据视频的特征并结合传统视频语义标注方法进行。标注通过对不同类型科学视频的分析,可以发现它们具有几个共同特征。
(1)科学视频一般都包含语音,语音所表达的重要信息通常聚焦于某个特定的领域。如:讲述物理实验过程的视频会涉及“physics”﹑“mechanics”等词汇;多媒体会议中会使用“CBIR”﹑“index”等词汇。这也是科学视频不同于其他视频的显著特征之一。其他视频所包含的语音信息表达的内容广泛,不涉及特定的学科领域,如:新闻视频﹑音乐视频﹑电影等。
(2)科学视频内容的逻辑单元一般比较明确,视频镜头或场景的变化往往伴随着视频主要内容的变化。如:教学视频中某一章节的开始或结束;研讨会视频中某个参会者演讲的开始与完成。
(3)从用户角度看,科学视频所涉及的大多是专业领域的知识,一般用户对相关知识的理解较难。因此,用户希望在观看视频时能方便﹑快捷地获取与视频内容相关的领域概念的扩展解释﹑视频中所包含的人物﹑机构以及地点等信息,以更好地理解视频所表达的内容。
为了实现第2节所述的应用场景,针对科学视频的特征,本文所构建的科学视频综合语义标注模型如图1所示。①语义分析,提取出语义概念;②结构分析,形成具有标识符与语义关系的视频片段;③语义标注,并将语义标注的结果与关联数据连接在一起。
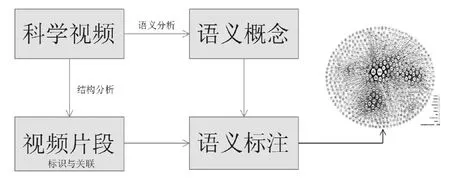
图1 科学视频综合语义标注模型
3.1科学视频内容语义分析
科学视频内容语义分析就是在对视频语音进行识别的基础上,从中抽取出视频所包含的可被人类理解的高层语义概念。这些语义概念是实现语义化浏览与检索的基础。科学视频一般都包含高质量的语音信息,而且语音所表达的内容一般涉及某个特定的领域。因此,可以利用相对应的领域本体对科学视频中的语音信息进行概念识别(如图2)。
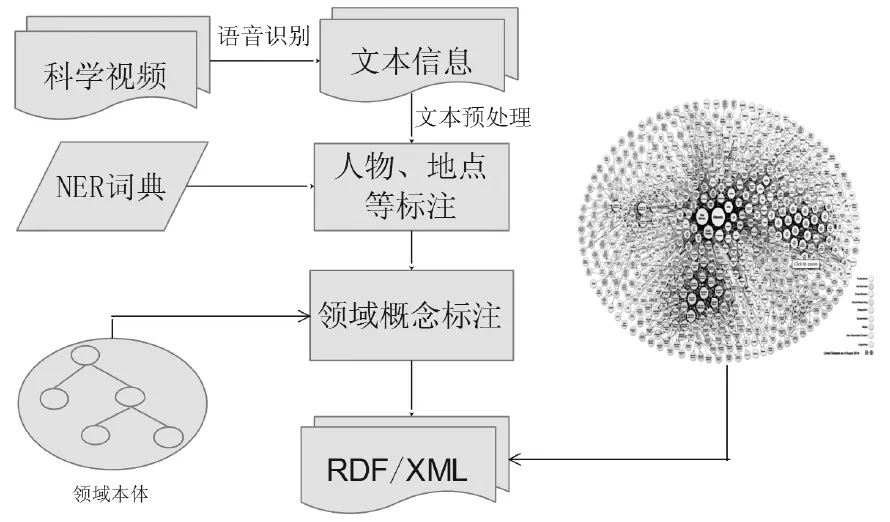
图2 科学视频内容语义分析框架
3.1.1语音识别与文本信息处理
语音识别就是借助成熟的语音识别技术(Automatic Speech Recognition)自动将视频的语音信息转化为文本信息。虽然语音识别会受到噪音等因素的影响,但是语音信息依旧是表达视频内容语义的最佳选择,如文献[9]利用语音信息实现了对新闻视频的语义标注。
语音识别以后,需要对形成的语音文本信息进行分句﹑分词等预处理。为了实现对视频内容中所涉及的人物﹑地点以及机构等的标注,就需要对预处理后的文本进行命名实体识别(NER),根据MUC的评测结果,英文命名实体识别的召回率与准确率都已达到90%以上。如:文献[10]利用NER工具ANNIE实现了对文本中人物﹑地点等实体的识别。
在识别命名实体后,需进行标记,以备后续处理。选择与科学视频内容相对应的领域本体,并将其作为词典,识别出已标记文本信息中包含的领域概念。通常采用关键词匹配或计算词语间语义距离的方法识别相关概念。如:文献[11]使用地学领域的SWEET本体实现了对地学领域专业文档的自动语义标注。在概念识别的过程中,为了提高标注的准确性,还需要对文档中的概念进行语义消歧与扩展。[12]
为了使标注结果能够被计算机广泛的处理,需要采用RDF资源描述框架把领域本体识别后的结果映射为RDF三元组,然后以RDF/XML的形式表示映射结果。为了实现标注的结果与视频片段的同步,还需要在RDF/XML文档中加入时间戳。
3.1.2标注结果与关联开放数据云连接
如第2节所述,当前一些研究已经尝试把视频的标注与关联数据连接,但是这些研究标注的是整个视频资源而不是视频片段。本文所探讨的是如何提供视频片段级别的语义标注,并把这些标注与关联数据进行连接,进而为用户提供与科学视频内容相关的所有背景信息。如:视频内容中的人物﹑地点﹑领域概念的详细信息等。
自2007年W3C启动了关联开放数据(LOD)[13]项目以来,LOD关联数据网络的规模增长十分迅速。截至2014年4月,LOD云已包含超过300亿个“RDF三元组”以及295个数据集。[14]其包含的领域与内容也逐步扩展,从早期的地理信息﹑生命科学数据﹑百科词条等,发展到目前涉及媒体﹑出版﹑政府信息﹑用户信息等内容,几乎涵盖了所有的领域。以关联开放数据中的核心数据源DBpedia为例,它从网络百科全书Wikipedia中抽取结构化信息,内容包含了物理﹑化学﹑生物学等几乎所有科学领域。
因此,关联数据源可以为科学视频的内容提供丰富﹑详细的背景信息。把标注结果与关联开放数据进行云链接后,用户在浏览科学视频或视频片段时,系统就可以根据视频内容的不同,展示与当前浏览内容相关的所有信息。从LOD云中获取的数据本身已是RDF格式,可直接与语音识别与处理后形成的RDF/XML文档进行连接与融合。
3.2科学视频结构分析
对科学视频进行结构分析是实现科学视频结构化﹑语义化浏览与导航的关键。结构分析就是利用相关原理与技术把科学视频分割为逻辑单元明确的视频片段,如关键帧﹑镜头以及场景等。把视频结构化,就如同给一本书配上简介与目录,用户不必浏览整本书就可以知道这本书的主要内容,并能快速找到感兴趣的内容。传统的视频结构化只是在视频分割的基础上构建视频结构本体,如:文献[15,16]。由于缺乏对视频片段的标识与关联,视频片段并没有成为独立的语义对象被用户检索与浏览。另外,由于缺乏一种对视频资源的内容﹑元数据以及视频资源片段之间关系进行正式﹑通用描述的方案,以上研究所构建的视频结构本体也不具有通用性。本文使用W3C媒体片段工作组所发布的媒体片段标识符(Media Fragments URI 1.0)[17]来标识科学视频片段,并使用W3C媒体标注工作组发布的媒体资源本体(Ontology for Media Resources 1.0)[18]来描述科学视频资源的内容﹑元数据以及视频片段之间的关系(如图3)。
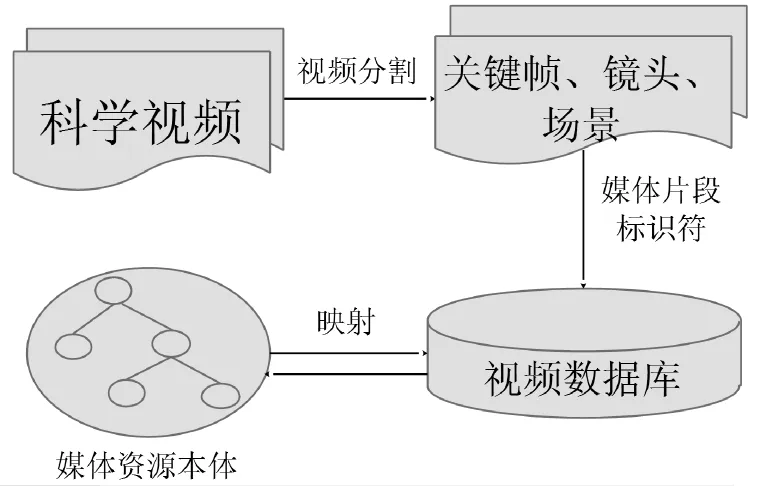
图3 科学视频结构分析
3.2.1科学视频分割
科学视频内容的逻辑单元一般比较明确,视频镜头或场景的变化往往伴随着视频主要内容的变化,如科学实验视频某个步骤的开始与完成等。因此,可以根据这些明确的逻辑单元把视频分割为关键帧﹑镜头﹑场景三个层次。关键帧用于描述一个镜头的关键图像帧,通常最能反映一个镜头的主要内容,是视频的最小逻辑单位;镜头是指一台拍摄设备从打开至关闭期间所拍摄的一连串帧序列,是彼此独立的逻辑片段;场景由语义上相关和时间上相邻的若干镜头组成,它反映了视频较高层次的语义内容。
在视频分割过程中,首先经过镜头边界探测,把视频分割成一个一个的镜头,实现对每个镜头的关键帧提取。在镜头单元的基础上,通过聚类,得到视频场景。在进行镜头边界探测时,颜色直方图比较法是当前一种应用较多﹑简单有效的方法。场景边界的探测可以结合视频的内容以及镜头边界探测的方法完成。提取关键帧时,可以在每一个分割好的镜头中通过比较帧图片与关键帧集合中的关键帧之间的直方图交集,选择多个关键帧代表每个镜头。[19]
3.2.2科学视频及其片段标识
标识科学视频资源及其片段,是实现科学视频及其片段语义检索的关键。用户在检索科学视频时,系统展示的是与检索主题相关的整个视频资源以及视频片段,并且这些视频资源以及视频片段具有独立的URI,用户可以直接点击相应的URI来浏览相关的视频片段(关键帧﹑镜头与场景)。这样科学视频片段就成为一个独立的语义对象而被用户处理与检索,从而促进当前以及未来网络基础设施中对这些视频片段的再利用。2012年9月,W3C媒体片段工作组发布了Media Fragments URI 1.0(basic),分别从时间﹑空间等维度实现了对媒体片段的标识。媒体片段(Media Fragments)是指根据不同维度把媒体资源划分为不同的片段。如:根据时间维度可把一个完整的视频划分为一个个视频片段,或者根据空间维度把视频分割为一张张图片等。
时间维度(Temporal axis):指源媒体的一个特定的时间范围,如“从10秒开始,至20秒结束”。时间片段由标识符“t”表示,如:http://example.com/video. mp4#t=20,90,表示20秒至90秒的视频片段。因此,使用时间维度可以实现对科学视频场景以及视频镜头的标识。
空间维度(Spatial axis):表示源媒体资源中一个特殊的空间矩形,该矩形可被指定为像素坐标或者百分比。使用标识符x﹑y﹑w﹑h来表示,(x,y)表示矩形左上角的一个坐标点,w,h分别表示矩形的宽度与高度,如:http://example.com/video.mp4#xywh=pixel:160,120, 320,240(像素)。空间维度一般用于标识静态的视频画面或普通的图片,所以,可以用空间维度来标识科学视频的关键帧。
在对科学视频的关键帧﹑镜头以及场景成功标识以后,科学视频片段就成为一个个独立﹑可检索的语义对象。用户在不用找到源视频的情况下就可以实现对科学视频片段的浏览﹑检索﹑分享以及重用。
3.2.3媒体资源本体
为了解决搜索与标注相关媒体资源时所出现的不同元数据格式之间的交互性问题,并能以一种通用的框架对多媒体内容的语法以及语义特征进行描述与表示,W3C媒体标注工作组(Media Annotation Working Group)在2012年2月开发完成了“媒体资源本体1.0”(OntologyforMediaResources1.0)。媒体资源本体定义了一组用于描述多媒体内容的最小标注属性集,以及一组这些属性与当前主要元数据格式之间的映射集(如图4)。
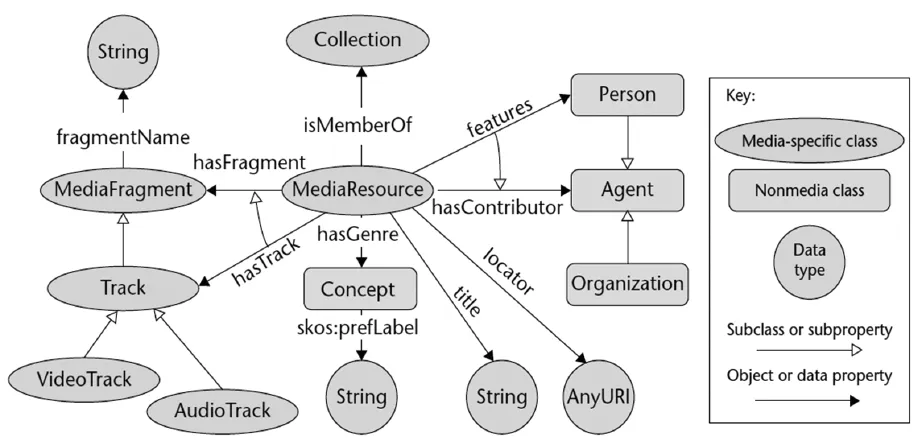
图4 媒体资源本体1.0类模型[20]
媒体资源本体分别定义了专门描述媒体特征的媒体类集(Media-specific class):MediaResource﹑MediaFragment﹑Collection等;非媒体类集(Nonmedia class):A-gent﹑Rating﹑Location等。为了表征类之间的特征与关系,本体还定义了描述类之间关系(如:hasFragment)的对象属性(ObjectProperties)与描述每个类固有特征(如:视频资源的Identifier与Title等)的数据属性(DataProperties)。
媒体资源本体不但可以以一种正式﹑通用的方式对不同类型的视频资源的内容与元数据进行描述,而且还可以清晰﹑明确地表征视频资源对象之间的关系。如:视频资源与其片段的关系,视频资源对象与其固有属性之间的关系等。因此,在完成科学视频的分割与视频片段的标识后,就可以把已分割﹑具有标识符的视频片段与媒体资源本体进行映射(如图5)。

图5 映射模型
在完成映射以后,一方面,科学视频资源及其片段之间就具有了语义关联,系统为用户呈现的检索结果是具有语义关系﹑互相连接在一起的科学视频资源对象;另一方面,科学视频资源对象本身也具有了通用的元数据描述方案,解决了不同格式元数据的交互性问题。
3.3科学视频综合语义标注框架
科学视频内容的语义分析主要是识别出语音中所包含的领域概念以及命名实体,并把这些识别出的语义概念与关联开放数据进行连接,从而为科学视频内容提供更多的背景信息,丰富用户获取视频信息的体验。科学视频的结构分析主要是在视频分割的基础上,使用媒体片段标识符对科学视频片段进行标识,并利用媒体资源本体表征科学视频对象之间以及视频对象与其属性之间的关系。这样不但可以使视频片段作为独立的语义对象而被用户检索到,而且还可以使用户结构化﹑语义化地浏览科学视频。在科学视频的内容语义分析与结构分析完成以后,就需要把语义分析后的形成的RDF/XML文件与结构分析后形成的映射模型进行映射,也就是最后阶段的语义标注。由于RDF/XML文件与映射模型中都包含视频的时间信息,因此可以根据科学视频的时间轴,完成RDF/XML与映射模型的最后映射,最终完成科学视频的语义标注(如图6)所示。
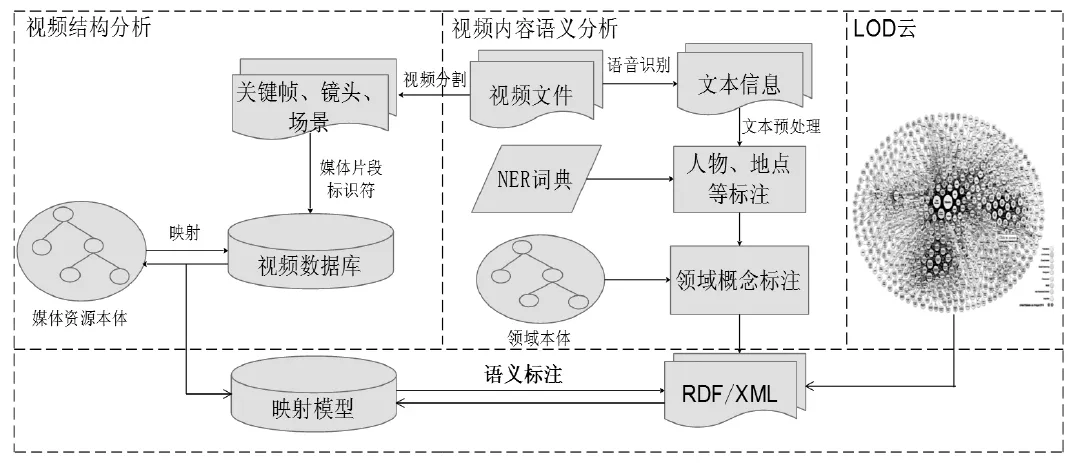
图6 科学视频综合语义标注框架
4 总结
在分析科学视频特征的基础上,着重从视频片段级别实现对科学视频的综合语义标注。在语音识别与视频分割的基础上,引入关联开放数据,为科学视频提供丰富的背景信息;使用媒体片段标识符标识视频片段,使其成为独立的语义对象,从而提高视频片段在网络上的可见性与可检索性;使用媒体资源本体描述视频资源的内容﹑元数据以及视频片段之间的关系。模型中每个过程的具体实现将是后续研究的重点内容之一。
[参考文献]
[1]LeeD,et al.LeeDeo:Web-Crawled Academic Video Search Engine[C]//Proceedings of the 10th IEEE International Symposium on Multimedia,Berkeley,CA. IEEE,2008:497-502.
[2]JoVE[EB/OL].[2014-10-08].http://www.jove. com/.
[3]宋彦.视频语义标注方法和理论的研究[D].合肥:中国科学技术大学, 2006.
[4]Snoek C G M,Worring M.Multimodal Video Indexing:A Review of the State-of-the-art[J].Multimedia Tools and Applications,2005,25(1):5-35.
[5]XuC,etal.AutomaticMusicVideoSummarizationBased on Audio-Visual-Text Analysis and Alignment[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval,Salvador,Brazil. New York:ACM,2005:361-368.
[6]Neumann J,Plank M.TIB’s Portal for audiovisual media:New ways of indexing and retrieval[J].IFLA Jour-nal,2014(40):17-23.
[7]Kobilarov G,et al.Media Meets Semantic Web How the BBC Uses DBpedia and Linked Data to Make Connections [C]//Proceedingsofthe 6th European Semantic Web Conference,Crete,Greece.BerlinHeidelberg:Springer,2009:723-737.
[8]Schopman B,etal.NoTube:makingtheWebpartofpersonalised TV[C]//Proceedings of the Web Science Conference 2010,NC,USA.Raleigh:Web,2010:1-8.
[9]Küük D, Yazc A.Exploiting information extraction techniques for automatic semantic video indexing with an application to Turkish news videos[J].Knowledge-Based Systems,2011,24(6):844-857.
[10]Damljanovic D,Bontcheva K.Named Entity Disambiguation using Linked Data[C]//Proceedings of the 4th International Workshop on Semantic Web Information Management, Arizona, USA. NY, USA: ACM, 2012:1-7.
[11]姚晓娜,祝忠明.面向地学领域的自动语义标注研究[J].现代图书情报技术, 2013(4):48-53.
[12]老松杨,等.基于领域本体的新闻视频检索[J].小型微型计算机系统, 2007, 28(8):1470-1476.
[13]LOD[EB/OL].[2015-03-31].http://www.w3. org/wiki/SweoIG/TaskForces/CommunityProjects/Linking OpenData.
[14]State of the LOD Cloud[EB/OL].[2015-04-22]. http://lod-cloud.net/state/.
[15]陆琳睿.一种基于本体的视频检索方法[J].西南大学学报(自然科学版),2008,30(11):119-124.
[16]Bagdanov A D,et al.Semantic annotation and retrieval of video events using multimedia ontologies[C]//Proceedingsofthe2007 International Conferenceon Semantic Computing,California,USA.Washington:IEEE ComputerSociety,2007:713-720.
[17]Media Fragments URI 1.0(basic)[EB/OL].[2015 -04-01].http://www.w3.org/TR/media-frags/.
[18]Ontology for Media Resources 1.0[EB/OL]http://www. w3.org/TR/mediaont-10/.
[19]刘娟.视频分割与目录生成研究与实现[D].成都:电子科技大学, 2012.
[20]Stegmaier F,et al.Unified Access to Media Metadata onthe Web[J].IEEE MultiMedia,2013,20(2):22-29.
动态·资料
首届“书香银川·悦读精彩”新年读书节开幕
(本刊讯)2015年12月30日,由宁夏银川市文化新闻出版广电局主办、银川市图书馆承办的首届“书香银川·悦读精彩”新年读书节在银川市美术馆启动。本届读书节历时5天。
开幕式上,银川市图书馆馆长强朝辉宣布了银川市公共图书馆全面启动二代身份证免押金借阅图书。同时,银川市公共文化数字服务平台正式上线运行。银川市图书馆和银川市书报刊协会向银川监狱、兴庆区月湖乡李学虎爱心书屋及红寺堡新庄集小学捐赠了2000余册图书。
本届读书节精彩纷呈,在5天的时间里,共有18项主题活动,包括精品图书优惠展销、作家签名售书、“书香银川·悦读精彩”读书专题报告会、首届“宁蒙陕甘青图书馆数字化发展论坛”、“银川公共文化数字平台”演示、“书香银川·悦读精彩”主题朗诵欣赏会、“共享阳光爱心助盲”新年联谊会、“笔下中华”汉字听写大会、“悦读书·悦动手”亲子趣味做手工活动、“悦读精彩·开卷有益”读书沙龙活动、“我行我塑”黏土DIY大赛、读书节寻宝活动“大家来找字”等,内容丰富、形式多样、启迪智慧、寓教于乐,引导广大市民好读书,读好书,在全市形成新一轮的阅读热潮。
读书节上,为了让更多的市民了解数字图书馆,更好地利用数字资源,银川市图书馆还邀请了北京超星集团、同方知网、北京新东方、武汉博看期刊数据库及北京爱迪科森教育科技股份有限公司等数字资源商家,现场介绍和演示各类数字资源的利用。
(戴茜张婕)
Study on Framework Construction of Comprehensive Semantic Annotation for Scientific Video
Wang Jing,Zhu Zhong-ming
Abstract:This paper aims to design a framework of comprehensive semantic annotation for scientific video and provides proposals for semantic annotation of scientific videos.By analyzing the semantics and structure of scientific video, we associate the annotation with Linked data and use the Domain Ontology, Media Fragments URI and Ontology for Media Resources to constructe the framework. With this framework,users can browse the scientific video by its semantics and structure. The framework can implement the semantic retrieval ofscientific video and its fragments andprovide abundant relatedinformation about the scientific video for the users.
Keywords:Scientific Video;Semantic Annotation;Linked Data;Ontology
[收稿日期]2015-08-27[责任编辑]刘丹
[作者简介]祝忠明(1968-),男,中国科学院兰州文献情报中心研究员,博士生导师,研究方向:数字图书馆系统;王敬(1988-),男,中国科学院大学2013级硕士研究生,研究方向:数字图书馆技术。
[基金项目]本文系中国科学院规划与决策科技支持系统建设基金项目“机构知识库NTM支持工具集”(项目编号:y4ZG071001)的研究成果之一。
中图分类号:G254;G254.927
文献标志码:B
文章编号:1005-8214(2016)01-0050-06
猜你喜欢
智能系统学报(2022年3期)2022-06-19
吉林大学学报(信息科学版)(2021年5期)2021-10-26
哈哈画报(2021年10期)2021-02-28
中小企业管理与科技(2019年12期)2019-06-12
小型微型计算机系统(2019年6期)2019-06-06
江苏科技大学学报(自然科学版)(2018年6期)2018-02-15
中国塑料(2017年2期)2017-05-17
制造业自动化(2017年2期)2017-03-20
创新科技(2015年9期)2015-12-15
中国音乐教育(2014年3期)2014-05-16
