
基于遥相关的三峡水库中长期径流预测
2016-03-15 05:58董前进张旭
华北水利水电大学学报(自然科学版) 2016年6期
董前进, 张旭
(1.武汉大学 水资源与水电工程科学国家重点实验室,湖北 武汉 430072; 2.江西师范大学 鄱阳湖湿地与流域研究教育部重点实验室,江西 南昌 330022; 3.武汉大学 湖北省水资源安全协同创新中心,湖北 武汉 430072)
基于遥相关的三峡水库中长期径流预测
董前进1,2,3, 张旭1
(1.武汉大学 水资源与水电工程科学国家重点实验室,湖北 武汉 430072; 2.江西师范大学 鄱阳湖湿地与流域研究教育部重点实验室,江西 南昌 330022; 3.武汉大学 湖北省水资源安全协同创新中心,湖北 武汉 430072)
径流中长期预测是水利水电工程设计、施工和运行管理的重要依据,而预报因子的选取和预报模型的构建一直是径流中长期预测的两大难点。本文以宜昌站1951—2013年汛期流量资料为例,根据国家气候中心74项环流特征量,分别构建了基于相关系数法和随机森林算法的径流预测遥相关模型,并且对比了依据不同的相关系数和因子选择数目对预测精度的影响。结果表明,相较于传统的相关系数法,基于随机森林算法的预测模型的稳健性与预测精度均可大大提高。研究内容可为三峡水库中长期径流预报及中长期调度计划制定提供技术支撑。
中长期径流预测;遥相关;随机森林算法;多元线性模型;宜昌站
随着当前社会经济的高速发展,人们对水文预报的要求越来越高,不仅要求有准确的短期预报以防御突发的暴雨洪水事件,同时要求有较长预见期的中长期水文预报以拟定相关规划与计划[1]。中长期水文预报主要利用大气因子或者海温因子进行径流预测,分为因子筛选和模型建立两部分。待选因子通常包含74项大气环流指数和海温因子等。因子筛选主要有相关系数法、逐步回归法和全子集回归法等[2],但这些方法只考虑到了单个因子同预测目标间的相关关系,以此构建的模型往往不是最佳模型,且根据相关系数选择多少预测因子较为合适尚存在疑问,较易因为因子选择过多而造成过拟合[3]。模型的建立是近些年研究的重点内容,常见的模型主要包含神经网络模型[4]、时间序列模型[5]、支持向量机模型[6]、基于小波分析的预测模型[7]等。总体而言,在因子的筛选方法上一直研究较少。随机森林(Random Forest,RF)算法作为近些年来兴起的新型智能算法,具有较好的预测能力和相对简易的编码,在特征因子的选择方面具有独特的优势。该算法不仅能考虑单个因子的重要性,而且可考虑因子之间的复杂联系。文献[8]将随机森林算法作为因子选择的工具,把筛选过的因子作为神经网络模型的输入层,取得了较好的效果;文献[9]则利用随机森林算法进行因子的筛选和洪水风险分析,并且将结果与随机向量机模型进行对比;同时,随机森林模型也成功地运用于长江中上游枯水期径流预测中[10]。因此,本文将尝试基于随机森林算法进行三峡水库宜昌站汛期径流的中长期预测。
三峡水库是当今世界最大的水利枢纽工程,具有防洪、发电、航运、生态等综合功能。每年6—9月为汛期,10月至次年5月为非汛期。目前三峡水库短期预报已经取得了令人满意的成果,而中长期预报还处于发展阶段[11]。三峡水库的中长期径流预报不仅有利于制定更科学合理的调度计划,更有利于三峡水库水资源的综合调度,协调各部门对水资源的需求,充分发挥三峡水库的综合效益等。当前三峡水库中长期径流预测的方法中,有利用混沌神经网络模型进行预测的[12],还有在多元线性回归模型、自回归模型、最近邻抽样回归模型以及支持向量机模型上引入小波分析,实现了较为精确的中长期径流预报的[12],但都缺少对预测因子选择的研究和针对汛期径流的中长期预测。
许多观测事实表明,全球各个区域环流的变化与异常是有相关性的。一个区域环流的变化与异常可以引起另一些区域环流的变化与异常,这种区域性环流变化与异常的相关性称为大气环流遥相关[13]。当前已有研究表明,三峡水库径流同大气因子具有较强的相关关系[14-15],即遥相关。本文正是基于遥相关考虑三峡水库径流的中长期预测。根据国家气候中心提供的74项环流特征指数,针对三峡水库1951—2013年的汛期洪峰、洪量分别构建了基于相关系数法和随机森林算法的径流预测模型,比较了不同的预测因子选择方法和选择数目的影响,找出了最佳的预测因子初筛方法和最合适的因子筛选数目。
1 基于相关系数法的径流预测
首先构建了基于相关系数法的宜昌站汛期径流预测模型。通常选用过去两年1—12月份和当年1—5月份的74项大气环流指数、一阶平均和二阶平均后过去两年1—12月份和当年1—5月份的74项大气环流指数作为待选预测因子(共3×(12×2+5)×74=6 438个)。将宜昌站6—9月的洪峰、洪量作为预测目标。把研究时段(1951—2013年)分成两个部分:1951—1992年作为参数率定期;1993—2013年作为模型验证期。利用相关系数(Spearman相关系数、Kendall相关系数和Pearson相关系数)法对因子筛选,对于筛选过后的因子,再次通过逐步回归的方法建立多元线性模型。本文对比了3种相关系数和不同的因子数目的影响,组成了4种方案。具体方案见表1。

表1 各方案的因子筛选和模型建立过程
已有的中长期径流预测中,文献[2]依据相关系数筛选出20个备选因子,通过向前逐步回归最终选择5个因子建立模型。文献[16]则筛选出17个影响径流预测的因子,通过主成分分析对17个因子化简。为更大程度地避免因子选择的冗余性,本文不仅仅采用逐步回归方法,还将进行全子集回归,因此,不妨将通过相关系数选择的备选因子数目拓展为25个,同时,列出方案4选择Pearson相关系数的前50个因子作为对比。
2 基于随机森林的中长期径流预测
随机森林算法是由加州大学伯克利分校统计系教授Leo于2001年提出来的一种统计学习理论[18]。随机森林算法第一步采用Bagging[18]方法来组成多个样本;后对每个样本进行决策树建模;最终组合多棵决策树的预测,通过投票得出最终预测结果。决策树,又称为分类回归树。决策树的基本思想是一种二分递归分割方法,在计算过程中充分利用二叉树,在一定的分割规则下将当前样本集分割为两个子样本集,使得生成的决策树的每个非叶节点都有两个分枝,这个过程又在子样本集上重复进行,直至不可再分成为叶节点为止[17]。由于单棵决策树模型往往精度不高,且容易出现过拟合问题,因此随机森林模型组合了多个样本建立了多个决策树,详细结构如图1所示。

图1 随机森林模型的结构示意图
随机森林模型包含两个重要参数,样本子集数量M(图1)和回归树节点划分待选变量数N。M越大,随机森林模型的过拟合效应越小;N越大,子预报模型间的差异性越小。一般M取值应较大,N取值应接近总解释变量数的1/3。
本文在方案5中使用随机森林算法进行因子的初选,并与传统的相关系数法进行对比。由于随机森林模型可以考虑到较大容量的因子数目,因此本文将所有的6 483项待选因子均作为随机森林模型的输入因子,其中的预测目标、率定期、验证期的选择与相关系数法径流预测模型相同。因子的选择依据Incnodepurity指数[20],即通过计算所有树变量分割节点不纯性的减少值来比较变量的重要性。本文为了与相关系数选择法进行对比,选择随机森林模型Incnodepurity指数的前25个因子作为线性模型的输入因子,选择过的因子作为后续模型建立的输入因子,同样进行逐步回归、全子集回归和物理成因筛选,使最终预测因子数目减少到10个左右。文中M取值为20 000,N取值为2 146。
3 结果与讨论
受篇幅所限,表2中仅列出预测效果较好的方案1、方案3和方案5所选用的预测因子。由表2可以看出,所选择的预测因子与文献[14]、文献[15]和文献[21]所选择的预测因子类似,但在时间上有差别,主要包含了物理成因较为明确的西藏高原、南方涛动指数、印度洋副高北界、冷空气和欧亚环流指数等因子[21],因此可以认为筛选的因子具有较好的物理成因。最终预测因子数为7个左右,可认为基于逐步回归、全子集回归的因子筛选方法有一定的优势且避免了因子筛选的冗余性。

表2 方案1、3、5的预报因子
模型精度的评价方法:①《水文情报预报规范》(GB/T 22482—2008)规定,预报误差小于多年变幅的20%为合格[22]。可依此计算预测结果的合格率。②采用Nash系数(即预测结果与实测值的接近程度)进行评价。Nash系数为1,则表示二者最为接近。
最终方案1—5的预测结果见表3。从Nash系数和合格率来看,基于随机森林算法的方案5的率定期和验证期评价参数的差距较小,且合格率达到了90%左右,Nash系数在0.65左右,效果最好。而基于传统的相关系数法的预测模型的稳健性较差,且单独通过加大相关系数法选择的因子数目并不能取得较好的优势,反而可能因为因子选择过多而造成过拟合。采用相关系数法时,方案1基于Pearson相关系数取得的效果最好,方案4由于使用的待选因子数目过多,达到了50个,虽然后来通过逐步回归、全子集回归进行筛选,但其验证期的结果仍较差。图2与图3给出了不同模型的预测结果,由图可知,使用随机森林算法的模型5具有较大的优势,其预测结果与实测洪峰、洪量最为接近。而单独利用相关系数的模型1—3的预测效果较差,预测结果偏离实际值较多。
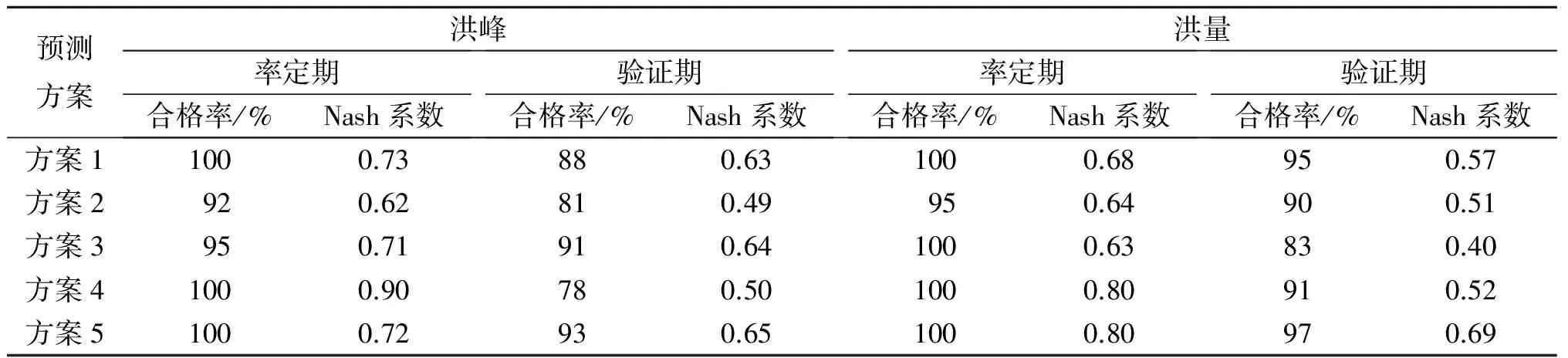
表3 汛期洪峰、洪量精度评价参数

图2 验证期洪量的实测值和各方案的预测值
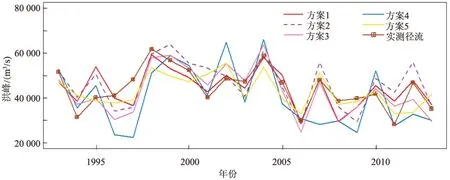
图3 验证期洪峰的实测值和各方案的预测值
4 结语
基于随机森林算法的预测模型,无论是模型的稳定性还是预测精度,相较于传统的相关系数法均有大幅提高。究其原因,相较于相关系数法,随机森林算法由于算法的先进性,可以进行大容量下的重要性选取,且考虑到了因子之间的复杂联系。但若依靠相关系数法加大因子筛选的数目,则易因因子选择过多,而造成过拟合,降低预测的效果。
本文采用了随机森林算法、Spearman相关系数法、Kendall相关系数法和Pearson相关系数法作为因子选择的方法,考虑了预测因子和预测目标间复杂的相关关系及预测因子内部的联系,但是仅仅构建了预测因子和预测目标间的多元线性相关关系,未能表达预测因子和预测目标间复杂的非线性关系,故构建有力的非线性预测模型将是下一步的研究工作。
[1]范钟秀.中长期水文预报[M].南京:河海大学出版社,1999.
[2]冯小冲,王银堂,刘勇,等.基于物理统计方法的丹江口水库月入库径流预报[J].河海大学学报:自然科学版,2011,39(3):242-247.
[3]卡巴科弗.R语言实战[M].北京:人民邮电出版社,2013.
[4]刘荻,周振民.RBF神经网络在径流预报中的应用[J].华北水利水电学院学报,2007,28(2):12-14.
[5]张丽霞,雷晓云.时间序列分解模型在乌拉斯台河年径流量预测中的应用研究[J].水资源与水工程学报, 2006,17(2):22-24.
[6]林剑艺,程春田.支持向量机在中长期径流预报中的应用[J].水利学报,2006,37(6):681-686.
[7]邓娟.三峡水库入库径流中长期预报模型研究及系统开发与应用[D].武汉:华中科技大学,2011.
[8]赵文秀,张晓丽,李国会.基于随机森林和RBF神经网络的长期径流预报[J].人民黄河,2015,37(2):10-12.
[9]WANG Z,LAI C,CHEN X,et al.Flood hazard risk assessment model based on random forest[J].Journal of Hydrology,2015,527:1130-1141.
[10]赵铜铁钢,杨大文,蔡喜明,等.基于随机森林模型的长江上游枯水期径流预报研究[J].水力发电学报,2012,31(3):18-24.
[11]沈浒英,杨文发,李筱琳.三峡工程大江截流水文气象预报[J].人民长江,1999,30(9):3-5.
[12]王雪.长江三峡中长期径流预报研究及其系统设计与开发[D].武汉:华中科技大学,2011.
[13]李维京.现代气候业务[M].北京:气象出版社,2012.
[14]XU K,BROWN C,KWON H H,et al.Climate teleconnection to Yangtze River seasonal streamflow at Three Gorges Dam,China[J].International Journal of Climatology,2007,27(6):771-780.
[15]LIU D,GUO S,LIAN Y,et al.Climate-informed low-flow frequency analysis using nonstationary modeling[J].Hydrological Processes,2014,29:2112-2124.[16]刘勇,王银堂,陈元芳,等.丹江口水库秋汛期长期径流预报[J].水科学进展,2010,21(6):771-778.
[17]HAYES T,USAMI S,JACOBUCCI R,et al.Using classification and regression trees (CART) and random forests to analyze attrition:results from two simulations[J].Psychology & Aging,2015,30(4):911-929.
[18]PUIMANNOV S.Sorption of arsenic onto Vindhyan shales:role of pyrite and organic carbon[J].Chemical Biology & Drug Design,2014,83(2):198-206.
[19]BREIMAN L.Bagging predictors[J].Machine Learning,1996,24(2):123-140.
[20]AKGÜNGÖR A P,YILDIZ O.Sensitivity analysis of an accident prediction model by the fractional factorial method[J].Accident Analysis & Prevention,2007,39(1):63-68.[21]宋春远,罗剑琴,饶传新,等.宜昌市典型伏秋连旱大气环流特征分析[C]∥中国气象学会.中国气象学会2005年年会论文集.北京:气象出版社,2005.
[22]水利部水文局.水文情报预报规范:GB/T 22482—2008[S].北京:中国标准出版社,2008.
(责任编辑:陈海涛)
Medium and Long-term Runoff Prediction of Three Gorges Reservoir Based on Teleconnection
DONG Qianjin1,2,3, ZHANG Xu1
(1.State Key Laboratory of Water Resources and Hydropower Engineering Science, Wuhan University, Wuhan 430072, China; 2.Key Laboratory of Poyang Lake Wetland and Watershed Research, Ministry of Education, Jiangxi Normal University, Nanchang 330022, China; 3.Hubei Provincial Collaborative Innovation Center for Water Resources Security, Wuhan University, Wuhan 430072, China)
The medium and long-term runoff forecast is an important basis for water conservancy and hydropower engineering design, construction and operation management. Predictors-selection and model construction are two key issues in the mid-long term runoff forecasting. In this paper, taking the flow data of Yichang station during the flood season from 1951 to 2013 for an example, based on the 74 circulation characteristics of the National Climate Center, the runoff prediction models based on the correlation coefficient method and the stochastic forest algorithm are constructed respectively. And the influence of different correlation coefficient and factor selection number on prediction accuracy is compared. The results show that the robustness and prediction accuracy of the prediction model based on stochastic forest algorithm can be greatly improved compared with the traditional correlation coefficient method. The study can provide technical support for the long-term runoff forecast and the long-term scheduling plan of the Three Gorges Reservoir.
mid-long term runoff prediction; hydro-climate teleconnection; random forest algorithm; multi-liner regression; Yichang station
2016-10-17
国家自然科学基金资助项目(51439007,51190094);江西省重大生态安全问题监控协同创新中心资助项目(JXS-EW-00)。
董前进(1979—),男,湖北安陆人,副教授,博士,从事水资源系统工程方面的研究。E-mail:dqjin@whu.edu.cn。
10.3969/j.issn.1002-5634.2016.06.007
TV121;P338
A
1002-5634(2016)06-0038-05
猜你喜欢
水利水电快报(2022年8期)2022-11-23
粮食问题研究(2022年2期)2022-04-25
黑龙江大学自然科学学报(2022年1期)2022-03-29
品牌研究(2020年32期)2020-08-09
中国水利(2020年14期)2020-08-02
人民珠江(2019年4期)2019-04-20
中国水利(2018年21期)2018-11-23
通信电源技术(2018年5期)2018-08-23
儿童故事画报·智力大王(2016年6期)2016-09-14
中国海洋大学学报(自然科学版)(2014年6期)2014-02-28
