
基于领域本体的数据挖掘技术在贿赂犯罪侦查中的应用
2016-03-10 07:30:44郑廷张云涛
中国检察官·司法务实 2016年2期
郑廷 张云涛



内容摘要:针对目前职务犯罪中日益增长的贿赂犯罪涉案人员关系复杂的特点,在传统侦查方法的基础上,可以尝试利用领域本体概念建立贿赂犯罪案件的专业知识模型,并根据该模型分析计算贿赂犯罪案件的资料和电子信息,利用数据挖掘技术关联关系算法从犯罪嫌疑人的社会关系人群中筛选出案件相关人,从而为获取新的案件线索与突破案件提供辅助性帮助。
关键词:领域本体 数据挖掘 贿赂犯罪 侦查
一、基于领域本体的数据挖掘技术概述
数据挖掘,又称为资料探勘、数据采矿。它是数据库知识发现中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中的信息的过程。通俗的说,数据挖掘技术就像采矿,从大量的矿石中提炼出有用的资源。数据挖掘技术目前主要应用于以下几个方面:(1)分类:将数据映射到几个已经确定好的类别中去;(2)聚类:又称无指导的学习,即在没有预先定义类别的前提下,将属性相似的数据聚集于一起;(3)关联规则:揭示数据之间的隐藏的关系;(4)时序模式:用当前所有的数据预测未来的趋势;(5)偏差模式:发现与正常情况不同的异变,以提前预警。在公安机关刑事犯罪侦查中,数据挖掘也已经发挥着重要作用,利用对类似犯罪记录数据的分析获取相似类型刑事犯罪的特征规律,已成为确定侦查工作方向的重要借鉴与依据。
领域本体则指某一概念系统所蕴涵的语义结构,是对某一事实结构的一组非正式的约束规则。它可以理解和/或表达为一组概念(如实体、属性、过程)及其定义和相互关系。总的来说,构造本体的目的是为了实现某种程度的知识共享和重用,主要有以下两方面:(1)本体的分析澄清了领域知识的结构,从而为知识表示打好基础。本体可以重用,从而避免重复的领域知识分析。(2)统一的术语和概念使知识共享成为可能。目前常见的领域本体构造由五个基本建模元语:类、关系、函数、公理和实例。
基于领域本体的数据挖掘技术对于贿赂案件侦查具有重要价值。贿赂犯罪案件的侦查重点往往集中在对以犯罪嫌疑人为中心的有直接或间接关系的人物群体的侦查讯问。那么如何从犯罪嫌疑人庞大的人际关系网络中,筛选甄别出与案件有关联的人群呢?这就需要分析犯罪嫌疑人的社交人群获取个人信息,再判断其是否与案件有关联关系。而随着社会与科技的进步以及信息化产品在日常生活中的广泛应用,犯罪嫌疑人为了隐藏罪证、逃避法律制裁,通过手机、网络等工具,采用网络匿名、间接接触等联系方式,使其犯罪手法亦愈发隐蔽,犯罪过程更加复杂。各类通讯工具以及互联网的广泛应用,使得人们的社会行为轨迹可以通过留存在手机、计算机、移动存储,互联网络、转账记录、消费记录、出行记录等的数据记录进行分析而得以还原,从而有助于侦查人员获取与犯罪嫌疑人有贿赂关系的人员群体信息。
二、贿赂犯罪侦查中运用数据挖掘技术的实施方案
数据挖掘技术通常需要有信息收集、数据集成、数据清理、数据变换、数据挖掘实施过程和知识表示等步骤,是一个反复循环的过程,每一个步骤如果没有达到预期目标,都需要回到前面的步骤,重新调整并执行。根据数据挖掘的步骤,贿赂案件犯罪嫌疑人关系人群的筛选过程可分为以下流程:
(一)贿赂犯罪专业知识库的建立
此过程可以分为两个阶段同时进行。第一阶段,利用以往的贿赂案件卷宗资料进行数据挖掘的关联规则计算,发现潜在的隐藏关联规则,作为训练该类案件知识库的素材。比如,通过分析以往贿赂案件资料可以发现,在100件贿赂犯罪案件中,70件案件中犯罪嫌疑人为职能部门领导,而这70件案件中又有30件案件中犯罪嫌疑人的直系亲属参与贿赂犯罪过程,即部门领导的直系亲属有案件关联的支持度为30/100=0.3,可信度为0.3/0.7=0.43。因此,一方面可以贿赂犯罪罪犯与其他案件相关人资料卷中出现词频较高的具有实际意义的词汇作为关键字,设为领域本体建设的参考元素节点;另一方面,分析案件统计数据,发掘其中的潜在关联关系,并选取其中支持度与可信度均较高的部分作为建立领域本体中元素节点间的关联关系的参考,并可以将这些关联关系元素出现的频率作为该元素的一个属性值,用于之后的关联度计算。
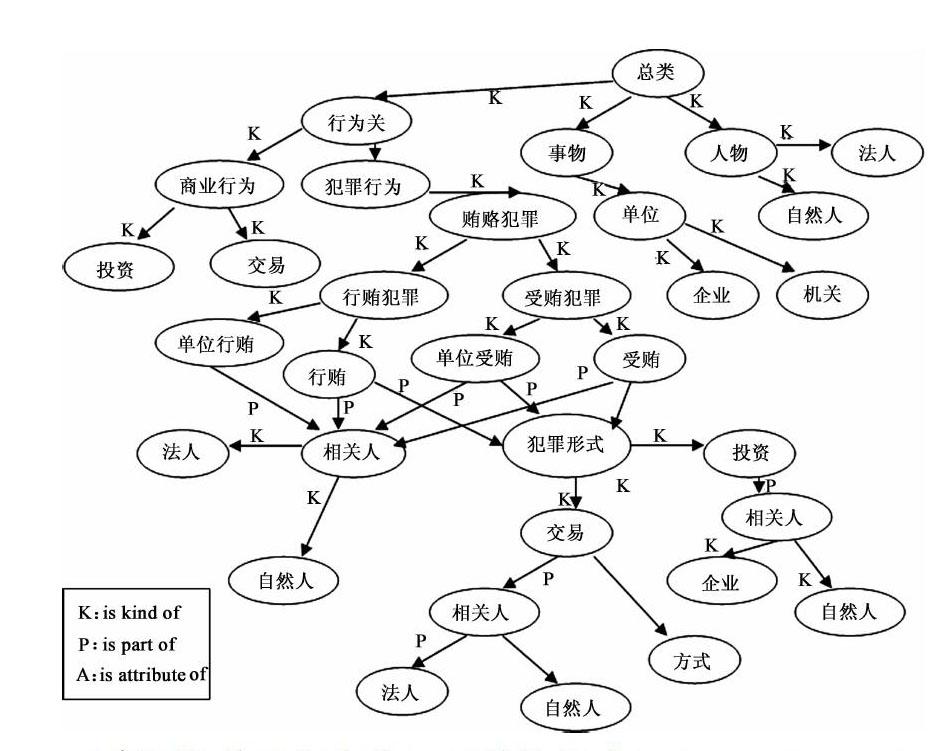
第二阶段,基于领域本体的概念,利用第一阶段获取的关键字库以及关联规则集合,建立专业知识模型。所谓专业知识模型,也可以看作是对案件相关人的特征模型画像,即根据已有相同类型案件资料,如讯问口供、案情内容等,通过中文语义分词、关联度与权值的计算以及从词库中选取的作为特征模型节点元素的关键词,将这些元素通过一定关联关系联系在一起,从而形成的特征知识库模型。之所采用领域本体作为知识库的存在形式,主要是利用领域本体中元素之间的语义关系,通过建立元素节点间的语义关联,一方面可以最大限度地避免因为同义词或近义词而导致遗漏关键词,另一方面还可以在两个没有直接关联的关键词之间寻找到间接关联关系,从而最大程度地挖掘文本资料的案件相关信息。这种领域本体模型的建立可以利用本体编辑工具,如斯坦福大学的protege程序。它提供了本体概念类关系、属性和实例的构建,并可以转化XML、RDF(S)、OWL等多种格式文件。下文以建立简单的领域本体模型作为示例。
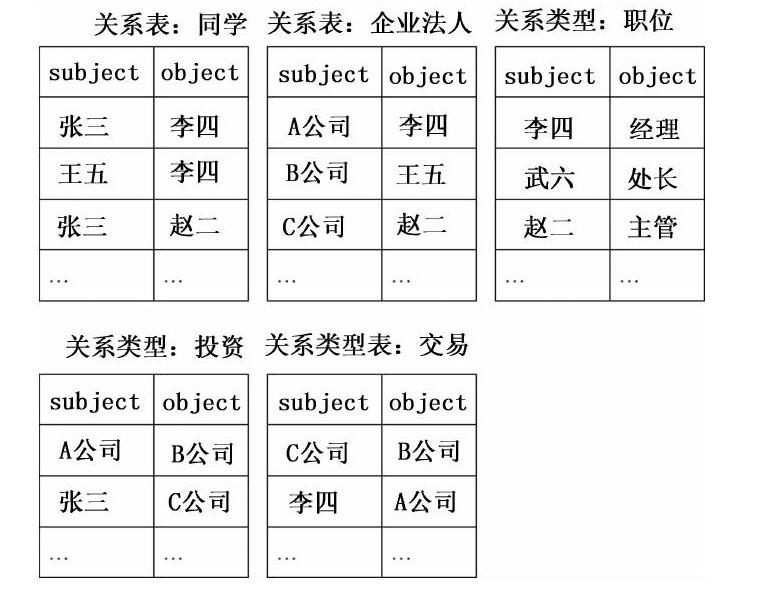
从上图可以看出,本体的元素节点间主要存在三种关联形式,即is kind of、is part of、is attribute of。其中,is kind of对照以protege创建的知识本体中的父子类关系;is attribute of对应属性关系类,即可以将本体元素间的关系对应为三元组的格式(subject,relation,object),比如“企业,子类,国企”、“企业,子类,私企”、“单位,子类,机关”、“投资方,投资,融资方”、“行贿人,行贿,受贿人”、“社会关系,子类,朋友”等。因此该领域本体的存储方式可以通过JENA对本体的RDF三元组读取,并以关系数据库的形式进行存储,分别以RDF三元组的关系属性作为表名新建数据表,由此获得的一系列数据表就是能够记录领域本体各元素节点间关系特征的数据表。其存储结构示例如下:
(二)侦查案件相关人关联度的计算
第一,信息收集。此阶段主要为关系人Ri的个人信息数据以及与犯罪嫌疑人关联关系信息的收集工作,即可以采用技术手段,对犯罪嫌疑人乃至其联系人的通信与网络终端进行电子证据取证,获取信息、通话录音记录(利用文字记录)、聊天记录、邮件等相关数据,也可以收集包括受贿人、行贿人以及证人的初步讯问笔录等传统的案件资料。将这些文本资料分类分别存储于不同的文件目录中,用作下一步分析检索使用。
第二,信息数据的结构化处理。此过程即将在上一阶段获得的信息数据进行清理筛选,从中获取与案件相关的信息,是将非结构化的文字资料转化为结构化的数据信息的过程。该过程可以通过多种方式进行,如可以采取用户界面的形式,人工判读相关资料信息,通过填写表单而将文本中的信息转换为结构化存储,也可以利用中文语义分词工具,首先将与每个关系人对应的资料信息分别处理为关键词条,将邮件、短信、聊天记录、通话记录(文字抄录)等文本信息通过中文分词工具,摒除副词、介词、符号、数字等不具备主要含义的词汇,根据上下文的语义关系,利用语义分析工具Chinese Semantic Parse,进行语义标注与语义的元数据抽取,将文本中的语句转化为RDF三元组格式。例如,对于语句“张三是李四的同学”、“A公司的企业法人是李四”、“A公司投资B公司”等,该工具可以依次解析为<张三,同学,李四>、
第三,相关人案件关联度权值的计算。当犯罪嫌疑人关系人的相关资料被语义分析检索完成后,关系数据表也同时被导入完成。此时可以发现,关系数据库已经形成一个网状的关系图,关系人王X与犯罪嫌疑人李X两个节点之间存在1至N条连通路径。如下图:
这些连通路径即是王X与李X的关联关系。比如,对于第i条路径(李X-领导-A工程-C公司-B公司-法人-王X),可以根据建立本体时所赋予的这些实例所述的类的出现频率属性,作为计算这一关联关系规则路径的支持度与可信度的参数,分别记作SUBri与CONri;将通过犯罪嫌疑人与其关系人的所有关联路径的支持度与可信度,即可以计算出两者的关联度。关联度的值越高,可以认为两者关系更加紧密,与该案件的相关度越高。
第四,关联度阈值的确定与案件相关联系人的筛选。阈值的确定可以通过本文介绍的方法对案件相关人进行计算分析获得的结果与实际办案过程的结果相对比,也可以通过侦办人员根据侦查过程中办案力量以及案件侦破环节等实际情况,自行设定调节,从而获得不同关联程度范围的相关人名单。
(三)案件侦结后对侦查辅助系统作用程度的评估
在数据挖掘中,专业知识库的建立往往是一个循环往复的过程,因此在整个案件侦结后,需要将实际确定的案件相关联系人与通过数据挖掘筛选获得的案件相关联系人进行对比分析,并将在挖掘过程中因为领域本体元素的不完善而导致的最终结果的遗漏加以记录,作为领域本体更改补充的依据。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
电力与能源(2017年6期)2017-05-14 06:19:37
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
法制与社会(2016年30期)2016-11-24 19:02:46
法制与社会(2016年30期)2016-11-24 19:02:01
法制与社会(2016年30期)2016-11-24 18:20:59
法制博览(2016年11期)2016-11-14 10:24:37
法制博览(2016年11期)2016-11-14 10:04:19
法制博览(2016年11期)2016-11-14 09:42:53
信息通信技术(2015年6期)2015-12-26 01:16:46
