
在线图表更新技术的改进与应用
2016-02-09 08:27王雪梅张少波
实验科学与技术 2016年6期
王雪梅,张少波
(南京邮电大学 计算机学院,江苏 南京 210003)
在线图表更新技术的改进与应用
王雪梅,张少波
(南京邮电大学 计算机学院,江苏 南京 210003)
针对MySQL数据库在进行数据定义语言(DDL)操作时因锁表动作引起长时间业务阻塞的问题,实现了一种不阻塞读写事务的在线图表更新(OSC)方法。考虑到电商数据库对读写事务的可用性要求,OSC系统将具有原子性的DDL语句拆分成若干步骤,创建临时表分片拷贝全量数据,并利用触发器保证增量数据的一致性,在实现无锁更改表结构的同时,解决了业务长时间阻塞的问题。另外,针对OSC技术在应用场景中遇到的系列问题,提出了相应的改进方法,如预检测、防并发执行等,并结合淘宝实际数据库架构,提供了复杂场景下OSC技术的应用分析。
数据一致性;影子表;在线图表更新;触发器
互联网电商平台一般以“n个9”作为指标,对其业务提出高可用性要求;如“5个9”指一年内系统不能正常工作的时间少于5′15″。但早期的MySQL数据库在执行更改表结构的DDL操作时因对整张表引入锁表动作,导致较长时间的业务阻塞[1-3]。2010年,为了解决这个问题,Facebook的数据库技术团队首次提出在线图表更新(online schema change,OSC)[4]解决方案。2011年,阿里巴巴的数据库团队研发出了类似OSC技术的产品MyDDL。同时,MySQL在5.1版本中提供了Fast Index Creation的功能,以InnoDB插件的形式在Optimized Create Index和Drop Index上避免表拷贝行为[5-7]。MySQL的5.6版本引入DDL Online Operate[8],虽然在大部分表更新操作中避免了表拷贝,一定程度上缓解了表锁定的问题,但由于不能支持全部的DDL操作[9],例如,更改字段类型等,仍然不能彻底消除因日常运维的频繁表结构更改对业务可用性的影响。
本文基于Facebook提出的OSC基本思想,实现了一个在InnoDB引擎层之上的server层工具,通过将具有原子性的DDL语句拆分成若干原子性操作,创建临时表分片拷贝全量数据,并利用触发器保证增量数据一致性,因只有极少部分操作会进行锁表从而极大减少了对原表的锁表时间。另外,结合淘宝实际数据库架构,针对“读写分离架构”“单元化架构”等复杂场景下基于OSC的数据库运维过程中出现的系列问题,提出了相应的优化方法,分析了不同场景下OSC技术的可行性。
1 OSC系统的基本设计
为尽量减少锁表时间,OSC将原生DDL操作分成15个原子性步骤,如图1所示。除了步骤13)

图1 OSC系统主要流程图
为了满足表结构变更需求,OSC系统构造影子表(ghost)拷贝原表中的全量数据,并创建3个触发器(INSERT、UPDATE、DELETE),保证在全量数据拷贝过程中对原表新加入数据的拷贝,或者在原表上执行更改、删除操作后,实现影子表与原表数据的一致。由于对原表进行插入、更新、删除的操作发生在全量数据拷贝过程中的任意时刻,因此需要引入辅助表dk(DELETE KEY)用来在整个全量数据拷贝过程结束后修正原表与影子表不一致数据。
图2为INSERT触发器设计图。INSERT触发器设计如下:

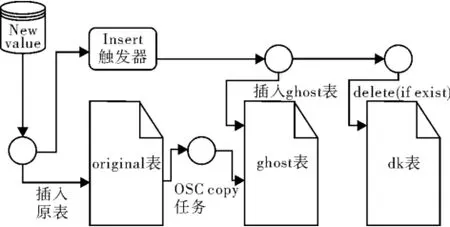
图2 INSERT触发器设计图
在original表全量数据拷贝到ghost表中时,当有数据插入original表时,会通过INSERT触发器将数据同时插入到ghost表中,并判断dk表中是否有该条记录(DELETE触发器可能会将数据插入到dk表),若有则从dk表中删除该记录。INSERT触发器保证了拷贝过程中对增量数据的拷贝,每一条在拷贝过程中插入到original表中的数据都会通过INSERT触发器插入到ghost表。
UPDATE触发器将对original表修改的数据以“REPLACE INTO”的方式插入ghost表。DELETE触发器在删除ghost表中相应数据的同时需要在dk表中插入删除数据主键以做标记。如果需要删除的数据正在拷贝到ghost表中,并且在delete触发器准备将ghost表中该数据删除的时刻ghost尚未包含该数据,但删除完后数据又拷贝到ghost表,此时会发现原表中数据已被删除,但ghost表中仍然包含该数据,从而出现原表与ghost表数据不一致的问题。为此,引入辅助表(dk)记录了DELETE触发器的删除操作,在完成全量拷贝过程后对ghost表进行修正。这样可以有效防止删除的数据仍滞留在ghost表中,从而保证原表数据与ghost表数据的一致性。
上述问题还存在于全量拷贝过程中。全量数据拷贝有可能再次把INSERT触发器插入的增量数据当作全量数据进行二次拷贝,会出现“ERROR 1062(23000):Duplicate entry”的错误。因此,全量拷贝需要进行“INSERT IGNORE INTO”。INSERT IGNORE INTO与INSERT INTO的区别就是INSERT IGNORE INTO会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果数据库中有数据就跳过这条数据。这样就可以保留数据库中已经存在的数据,达到在间隙中插入数据的目的。
2 OSC系统改进
虽然OSC系统一定程度上解决了原生DDL的锁表问题,但由于OSC本身独立于MySQL,在不同场景下运行时,如不加限制或优化仍然会带来无法忽视的逻辑错误,可能会引发数据丢失、数据不一致等系列问题。下文着重介绍主备复用、并发执行等实际场景中可能出现的问题,并给出相应的解决方案。
2.1 主备复制问题
为了提高容灾能力,减少系统压力,电商数据库往往设计成主从架构。正常情况下,主服务器端执行所有的写入操作,并将所有写操作记录到二进制日志文件(binlog)中。为了保证主从服务器数据的一致,从服务器会定时从binlog中拷贝日志信息到自身的中继日志(Relay log)中,并重演Relay log中的所有新发生的操作或事件。
现在考虑OSC系统在数据库主从架构下的应用。若在主库中使用OSC技术,OSC执行过程中的每一条语句都将记录在主库的binlog文件中,通过上文所述的主从复制模式,相应语句会复制到从库中的Relay log中,从库通过执行Relay log操作,实现主从数据库的数据一致性。但是,如果在从库执行OSC系统,当全量数据全部拷贝到影子表中后,交换原表与影子表表名,会出现主库中表结构与从库中表结构不一致的情形。当有数据写入主表时,再通过主从拷贝机制往从表插入数据就会出现错误!因此,OSC系统应当严禁在从库中执行。
为防止因OSC系统在从库执行带来的数据丢失的问题,可以通过将从库的READ_ONLY变量设置为ON,禁止SUPER权限之外的从服务器线程或用户执行更新操作。非SUPER权限用户对READ_ONLY为ON的从库进行数据插入、删除或更改操作时,会出现如下报错:
ERROR 1290(HY000):The MySQL server is running with the--read-only option so it cannot execute this statement.
所以,在OSC系统执行之前,需要通过对执行库的READ_ONLY进行检查,以避免OSC系统在从库上执行,从而防止数据丢失。
2.2 并发执行
OSC系统不支持同一张表上的并发执行。事实上在同一张表上并发执行OSC,可能会给整个数据库带来灾难性影响。OSC在执行过程中可能会因为各种原因中途被迫退出,来不及清理残留的触发器(INSERT、UPDATE、DELETE)、影子表和dk表。为了每次执行OSC系统不受这些残留触发器和临时表的影响,在OSC系统正式执行之前需要对这些触发器和临时表进行清理。但是,当在同一张表上并发执行OSC时,如果后执行的OSC对先执行的OSC的触发器和影子表进行删除重建的话,已拷贝进影子表的全量数据以及增量数据会丢失,造成数据不一致性问题。
为了防止并发执行OSC系统带来的不良影响,可以在每次执行OSC系统前加上一个“表名锁”:
"SELECT GET_LOCK(′{$key}′,{$timeout})AS get_lock";
执行OSC的线程会占用“表名锁”直到整个OSC系统执行完毕。在OSC执行过程中,若有其他的OSC系统对该表进行操作会因得不到“表名锁”而出错退出。注意,这里的锁仅对字符串加锁,并不影响业务读写。
2.3 与原生DDL行为不一致问题
如上所述,设计OSC系统旨在替代原生DDL,防止因在大表上执行DDL操作长时间阻塞读写业务。然而,对于某些数据表结构的更改操作,往往会出现OSC与原生DDL执行结果不一致的情形。例如,原数据表“t1”中包含两个字段{ID,name},其中ID设置为主键。“name”列中有若干条数据且有部分数据一致。假设现在对“t1”表进行如下原生DDL操作:
Mysql>ALTER TABLE T1 ADD UNIQUE KEY UK(name)
由于该操作试图对拥有重复性的列加唯一索引,系统会报告“1062”错误:
ERROR 1062(23000):Duplicate entry′0′for key′UK′
如果应用OSC执行该功能,OSC首先会根据原表表结构更改需求创建影子表,将原表数据通过insert ignore into拷贝到影子表中。如果原表的“name”列中出现重复项,向影子表进行拷贝时会因为唯一索引的约束造成数据丢失。
事实上,OSC系统与原生DDL的行为不一致问题很难通过程序的逻辑判断来检测出来,这时有必要引入前置检查,即在原表中取少部分样本数据,分别进行原生DDL操作与OSC操作,检查两种行为的一致性,若两种行为一致则通过,否则放弃OSC操作。
统计学中对样本有如下要求:1)总体内所有观察单位必须是同质的;2)在抽取样本的过程中,必须遵守随机化原则,并且达到足够的数量。事实上,若在大表中执行select count(*)操作需要对全表进行扫描,造成长时间阻塞,脱离了OSC系统的初衷。另外,前置检查的主要目的是检测OSC与原生DDL的一致性,需要抽取原表中可能会造成OSC与原生DDL不一致行为的数据样本,无须通过随机抽样覆盖原表中的不同数据种类。经验表明,大部分造成OSC与原生DDL行为不一致性的数据出现于表的开头与结尾即边缘数据。考虑到数据多样性,在数据表中间部分也应抽取少量样本。样本提取的具体做法是:在数据表中的前、中、后各取3 000条数据表项作为样本,根据主键排序limit 3 000来获得头与尾的数据(通过主键索引并不会影响效率)。中间部分的数据由于无法获得数据总量,只能对数据量进行估算;若是数据型主键(多主键情况下只考虑最左主键),则对最小值和最大值取平均数作为中间数据起始点;对于非数据项数据,如日期型、字符串型,可以忽略中间样本。获得中间数据起始点后,通过主键排序以及limit n,m语句可获得中间部分数据。但这样会对整个表通过索引进行半表扫描,通过where限定可以有效提高效率。
获得最小主键:select key_name from original_ table order by key_name limit1;
获得最大主键:select key_name from original_ table order by key_name desc limit 1;
获得估算中间值:middle_num=(min_ num+max_num)/2;
获得中间数据:
insert into test_table
select*from original_table
order by key_name
limit middle_num,3000
where key_name>middle_name;
一般情况下,通过引入前置检查确实可以避免OSC与原生DDL行为在执行表结构更新操作上的不一致性,但在某些极端情况下仍然存在不一致情形,比如,如果在进行预检查时表中无数据,而检查后对表中插入若干数据(加唯一索引列存在重复项),此时执行OSC仍会出现上述问题,并且该问题难以通过编程解决。
2.4 多版本行为的一致性
MySQL不同版本之间存在差异,如果不对这些差异进行处理,OSC系统在不同版本的MySQL执行下会有行为不一致问题。
以MySQL 5.1.50为例,#Bug 56226导致My-ISAM引擎在alter table后binlog文件出错。官方描述”After ALTER TABLE without column size change,binlog gets corrupted since the tablemap is unexpectedly set to 0 in subsequent updates.The problem can be avoided by flushing table after ALTER TABLE command.The problem happens on MyISAM table only.”例如在test库的t1表中进行alter table操作,binlog日志记录如下:
|binlog.000001|1329|Table_map|1|1371|table_id:0(test.t1)
|binlog.000001|1371|Update_rows|1|1419|table_id:0 flags:STMT_END_F
此时,table_id被意外地设置为0,这对数据恢复、主从备份都有较大的影响。
为了在不同版本下的MySQL都能良好地运行OSC系统,需要针对不同的版本做出相应的调整。主要有以下两个方面:
对于MySQL 5.1.50之前的版本,在ALTER TABLE之后对表进行FLUSH操作;在MySQL 5.6版本以后,由于内置DDL Online operate,一些DDL操作运用原生DDL较之OSC系统更具可靠性;所以,可以对DDL语句进行智能判断,若DDL Online operate操作能够在不锁表的情况下完成DDL操作,则选择原生DDL进行,否则继续选择OSC系统。
3 OSC在复杂场景下的应用
OSC通过将一条DDL语句分解为若干原子性步骤,有效缓解了原生DDL操作锁表带来的业务阻塞问题,可以应用在具有容灾需求的一些复杂应用场景中。下面将分析OSC在读写分离的主从架构[11-12]和单元化架构[13-14]下的应用。
3.1 读写分离的主从架构
简单的读写分离主从架构由一个中心服务器(主库)和若干个单元服务器(从库)组成,中心服务器主要负责写操作,单元服务器负责读操作,主从服务器都保存全部数据量。由于主从数据库中的数据都是相同的,而从库端无写入操作。因此,触发器的创建无须复制到从库端,除了触发器之外,所有其他DDL操作均需复制到从库端,ghost表和dk表的数据也复制到从库端。具体来说,在从库端,无须执行图1中的第8)~第10)步骤。执行主库对ghost表、dk表的DDL语句就能保证从库端ghost表、dk表与主库端一致,在完成图1的步骤14)后即可保证主从端数据一致性。所以,在配置复制任务时,只需通过在从库端执行临时表的创建,并且过滤掉从库端触发器相关的DDL操作即可。
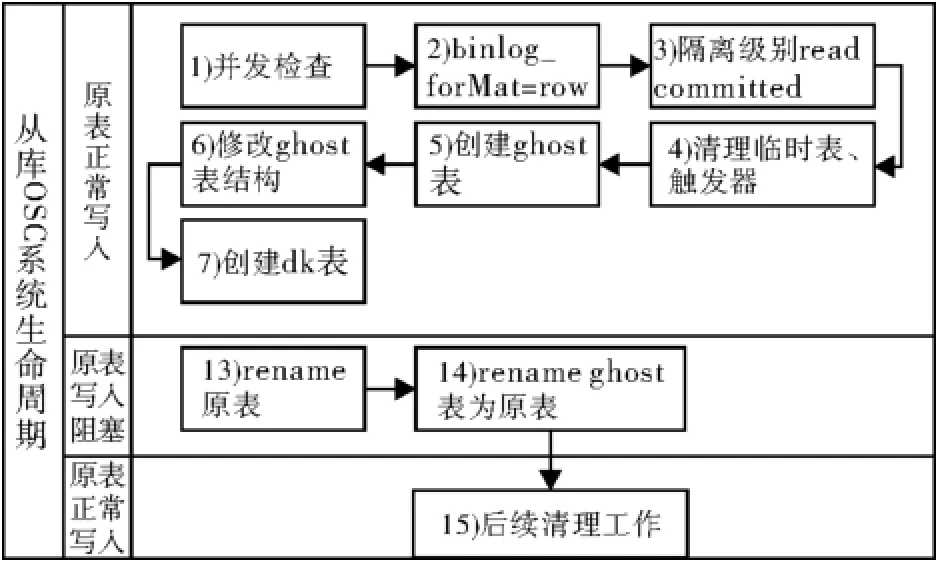
图3 读写分离的简单主从架构下从库OSC系统
3.2 单元化架构
单元化架构是从并行计算领域发展而来。在分布式服务设计领域,一个单元(cell)就是满足某个分区所有业务操作的自包含的安装。而一个分区(shard),则是整体数据集的一个子集,如果你用尾号来划分用户,那同样尾号的那部分用户就可以认为是一个分区。单元化就是将一个服务设计改造让其符合单元特征的过程。
为了解决单机瓶颈问题,淘宝数据库从最初的单机MySQL升级形成IOE架构。近几年,不断扩展的业务规模和用户规模对数据库的并发性、可用性和扩展性等方面提出了更高的要求,阿里引入sharding的思想,将数据库分布到多个物理节点,让多节点并发处理不同的写请求。并且考虑到容灾需要,阿里内部基于MySQL已建设完成了单元化架构。
单元化式架构由一个中心和若干单元组成,与简单的读写分离架构不同,单元化式架构的中心、单元均能承担读写业务,中心保存100数据量,单元保存部分数据量。在单元化式架构中,DDL操作可以在中心,也可以在某个单元;每个单元保存部分数据,并且它们保存的数据不完全一样。
由于单元化式架构下各个单元保存数据的差异性,导致系列问题:1)图1步骤11)中全量迁移的数据,可能包括目的端不需要的数据;2)步骤8)~步骤10)中由触发器产生的增量数据,可能并不是目的端需要的数据;3)步骤8)~步骤12)中目的端也许有源端没有的数据,没有正确地被迁移到ghost表中,删除的primary key也没有正确地被记录到dk表;4)在步骤13)中,由于目的端的数据和源端数据不一样,则不一样的那一部分随着rename操作而丢失。
总之,如果按照上面的OSC复制方案,目的端的表数据最终会变得和源端一模一样。导致数据不一样的主要是步骤8)~步骤12),因此这些步骤需要重构。
步骤8)~步骤12)主要完成全量数据、增量数据的拷贝工作,ghost表和dk表数据不能像读写分离结构下直接从源端复制过来,要直接从目的端生成,需要在配置复制任务时加入数据同步黑名单中,即在源端的ghost表与dk表的DDL操作不复制到目的端。由于增量数据部分主要由步骤8)~步骤10)这3步所建的3个trigger产生的,所以只需要在目的端同步这3个trigger的创建操作,目的端就可以直接产生自己的增量数据到ghost表和dk表。
步骤11)主要是搬迁原表的全量数据到ghost表,我们需要将这个搬迁逻辑在目的端按照源端一样的逻辑规则搬迁,但不是直接复制源端的数据,因此需要复制源端全量迁移的算法在目的端执行。这个算法是OSC实现的,因此有如下两种方法可以实现算法的搬迁:
1)将OSC的全量迁移算法代码集成到复制数据的中间件中,这样在目的端就可以按照这个逻辑来实现数据全量迁移;
2)将OSC的全量迁移算法代码从源端往目的端复制,一个可行的方法是,将算法以MySQL的存储过程来实现,然后OSC以创建存储过程的形式将算法复制到目的端。
4 结束语
OSC技术是解决企业数据库日常运维过程中锁表之痛的实用工具,在OSC技术之前,企业在运维数据库过程中如果要对表结构有变更需求,一般只能选择在业务低峰期去变更或在主备架构下分次变更,这对运维工作带来了极大的不便。虽然MySQL官方也一直致力于解决此类问题,相继推出Fast Index Creation和DDL Online Operate功能,但仍然不能彻底解决全部的DDL锁表问题。OSC系统依旧是未来一段时间内解决DDL操作锁表问题的不可或缺的手段。
虽然OSC技术思想简单,但在实际运用过程中由于业务场景的复杂性,以及表变更需求的多样化,往往会出现一系列问题,如OSC变更与原生DDL变更行为不一致。本文针对OSC在实际应用过程中遇到的系列问题,提出了相应的改进方法,并对两种典型的复杂应用场景下OSC系统的应用进行分析。
[1]AXMARK D,LARSSON A,WIDENIUSM,et al.MySQL 5.0 reference manual[M].first edition.Sweden:MySQLAB,2006,56-200.
[2]AXMARK D,LARSSON A,WIDENIUS M,et al. MySQL internals manual[M].Sweden:MySQLAB,2006.32-135.
[3]Paul DuBois.MySQL技术内幕[M].杨晓云,王建桥,杨涛,译.4版.北京:人民邮电出版社,2011.
[4]NOACH Shlomi.Online schema change[Z/OL].America:Facebook,2010.https://code.google.com/p/openarkkit/.
[5]MySQL 5.5 Reference Manual.InnoDB Fast Index Creation[EB/OL].[2016-02-12].http://dev.mysql.com/doc/refman/5.5/en/innodb-create-index.htm l,2015.
[6]姜承尧.MySQL技术内幕:InnoDB存储引擎[M].北京:机械工业出版社,2011.
[7]陈小辉,文佳,邓杰英.MySQL的体系结构及InnoDB表引擎的配置[J].福建电脑,2009,25(7):162-162.
[8]MySQL 5.6 Reference Manual.DDLOnline Operate[EB/OL].[2016-02-12].http://dev.mysql.com/doc/refman/5.6/en/innodb-online-ddl.htm l,2015.
[9]MySQL 5.6 Reference Manual.Limitations of online DDL[EB/OL].[2016-02-12].http://dev.mysql.com/doc/refman/5.6/en/innodb-create-indexlimitations.htm l,2015.
[10]MySQL 5.6 Overview of Online DDL[EB/OL].[2016-02-12].http://dev.mysql.com/doc/refman/5.6/en/innodb-create-index-overview.htm l,2015.
[11]沙光华,陈泳,张长江.读写分离技术在运营支撑系统中的应用[J].计算机工程与应用,2015,51(12):107-110.
[12]刘小俊,徐正全,潘少明.一种读写分离的分布式元数据管理方法——以“数字城市”应用为例[J].武汉大学学报(信息科学版),2013,38(10):1248-1252.
[13]华竹轩,王桂荣,徐楠,等.支持海量数据的分布式数据库架构设计与验证[J].河南科学,2014(9):1719-1725.
[14]梁宇鹏.单元化架构,为什么要用以及我们如何做到[EB/OL].[2016-02-12].http://www.infoq.com/cn/articles/how-weibo-do-unit-architecture,2014.
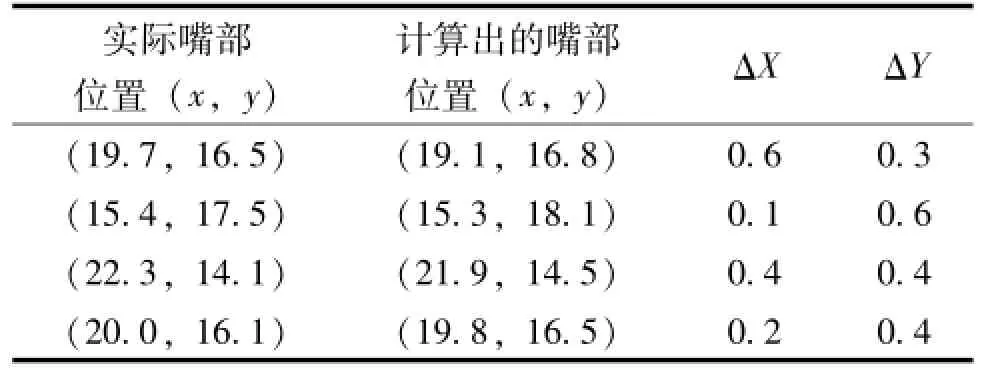
表1 实际与计算对比

图6 实际效果图
7 结束语
本文开发的智能辅助饮食系统可以帮助无臂残疾人进行自主饮食。本系统对二值化图像进行数字图像处理,由算法可进行嘴部定位,精度较高,全程通过语音进行交互,减少了系统的使用难度。该系统具有自动添水和温度异常警告功能。另外本系统还具有良好的可拓展性,可以在未来进行功能的添加和结构的改进。
参考文献
[1]潘松.黄继业.陈龙.EDA技术与Verilog HDL[M].北京:清华大学出版社,2010.
[2]李朝青.单片机原理及接口技术[M].北京:北京航空航天大学出版社,2005.
[3]王晓明.电动机的单片机控制[M].北京:北京航空航天大学出版社,2011.
[4]朱文佳.戚飞虎.快速人脸检测与特征定位[J].中国图像图形学报,2005,10(11):1454-1457.
[5]王军南.丛爽.基于视觉定位的二自由度机械臂控制系统[J].机械与电子,2008(2):49-52.
[6]张培仁.杨兴明.机器人系统设计与算法[M].安徽;中国科学技术大学出版社,2008.
[7]薛丹丹.基于眼和嘴定位的人脸归一化算法研究[J].电子测试,2012(9);53-57.
[8]徐光辉.程东旭.黄如.基于FPGA的嵌入式开发与应用[M].北京:电子工业出版社,2006.
[9]江国强.SOPC技术与应用[M].北京:机械工业出版社,2006.
[10]彭澄廉.挑战SoC——基于Nios的SOPC设计与实[M].北京:清华大学出版社,2004.
The Improvement and Application of Online Schema Change
WANG Xuemei,ZHANG Shaobo
(College of Computer Science,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
To solve the business blocking problem caused by DDL operation in MySQL database,an online schema change(OSC)method is implemented with non-blocking operation in reading and writing transactions.Considering the availability requirement of the electronic commerce database on the read and write transaction,OSC system divides atomic DDL statements into several successive steps,creates a temporary ghost table to make a copy of all data from the original table fragment by fragment,and adopts triggers to ensure data consistency incrementally,so as to realize schema change with non-lock and solve the problem of business long time blocking.In addition,aiming at solving the problems of the OSC system encountered in practical applications,a series of solutions are presented,such as pre-detection,concurrency execution prevention etc.Moreover,combined with the Taobao's database architecture,the analysis on the OSC's application in complex business scenarios is provided.
data consistency;ghost table;online schema change;trigger
TP311.1
A
10.3969/j.issn.1672-4550.2016.06.019
2016-03-03;修改时间:2016-03-16
江苏省研究生创新计划(CXZZ13_0476);南京邮电大学校级科研基金(NY215169)。
王雪梅(1978-),女,硕士,讲师,主要从事现代通信网络、信息处理技术的研究工作。和步骤14)对原表进行了可忽略的轻量级锁表操作,其余操作规避了对原表的锁表行为,从而达到避免阻塞业务读写的目的。与MySQL5.6的新特性DDL Online Operate相比,OSC不依赖于某个具体的存储引擎,具有更为广泛的适用性;例如,DDL Online Operate无法完成对表进行存储引擎的更改以及列类型的变化,但OSC系统却可以做到。详细的Summary of Online Status for DDL Operations,见MySQL5.6官方文档14.10.1 Overview of Online DDL[10],该表记录了DDL Online Operate的适用范围。
猜你喜欢
四川劳动保障(2021年7期)2021-12-02
中国生殖健康(2018年1期)2018-11-06
今日中国·中文版(2017年8期)2017-09-03
网络安全和信息化(2017年4期)2017-03-08
环境科学导刊(2016年4期)2016-06-30
上海农业学报(2016年5期)2016-02-10
遥感信息(2015年3期)2015-12-13
科技传播(2012年12期)2012-07-05
长春大学学报(2012年6期)2012-02-26
通化师范学院学报(2012年2期)2012-01-11
