
面向商品评价的情感要素抽取
2016-02-08 11:33:54冯仓龙蔡东风
沈阳航空航天大学学报 2016年6期
冯仓龙,白 宇,蔡东风
(沈阳航空航天大学 人机智能研究中心,沈阳 110136)
面向商品评价的情感要素抽取
冯仓龙,白 宇,蔡东风
(沈阳航空航天大学 人机智能研究中心,沈阳 110136)
商品评价的细粒度倾向性分析的目标是对评价信息中所涉及评价对象的各个侧面进行情感极性判别,进而准确反映用户的商品评价意图。情感要素抽取是商品评价的细粒度倾向性分析的关键步骤。提出了一种面向商品评价细粒度分析的情感要素抽取方法,该方法将情感要素词典及聚类代码引入CRF模型中,实现情感对象和情感词同步抽取。在3类不同领域的商品评价数据集上进行实验,准确率平均达到了96.06%,召回率平均达到了91.39%,F值平均达到了93.66%,在混合商品评价数据集上的实验结果显示,准确率、召回率、F值分别达到了96.84%、93.34%和95.06%。
倾向性分析;商品评价;情感要素抽取
在线商品评价是消费者对购买商品的主观评论信息(包括对商品的整体评价和对性能、规格、材质、外观等商品属性)的细粒度评价。通常,商品评价信息具有情感倾向性,能够被用于消费决策或产品监测的评价信息主要是对商品的积极评价和消极评价,对商品评价进行情感倾向性分析的目的就是从大量主观评价信息中判别评价信息的情感倾向。
如表1所示,从情感倾向性表达方面看,评论内容可分为无倾向性(中立)、单一倾向性评价(积极、消极)和复合倾向性评价。

表1 评价内容举例
单一倾向性评价指在评价内容中仅对评价对象的某一侧面进行评价或对评价对象的多个侧面给出相同极性的评价结果(如积极、消极等)。目前,商品评论倾向性分析的相关研究主要针对这类单一倾向性评价内容开展[1-3]。复合倾向性评价指在评价内容中对评价对象的多个侧面给出不同极性的评价结果。细粒度倾向性分析的目标即是分别对复合倾向性评价中所涉及评价对象的各个侧面进行情感极性判别,进而准确反映用户的商品评价意图。总体流程如图1所示。
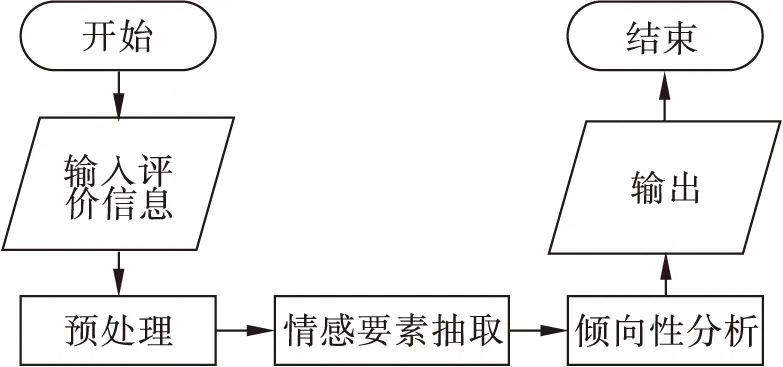
图1 细粒度评价倾向性分析总体流程
其中,情感要素(情感对象或情感词)抽取是商品细粒度倾向性分析的关键步骤,包括情感对象、情感词的识别与对齐。如评论d =“设计的很合理,机身拿起来手感超好,屏幕比较出色,显示细腻,有正规发票,客服不错。”中,情感对象A={“设计”,“机身”,“手感”,“屏幕”,“显示”,“发票”,“客服” },情感词E = {“很合理”,“超好”,“出色”,“细腻”,“正规”,“不错”},经过情感要素抽取后得到的情感对象、情感词词对Ω= {<设计,很合理>,<手感,超好>,<屏幕,出色>,<显示,细腻>,<发票,正规>,<客服,不错>}。
本文提出的情感要素抽取方法将情感对象和情感词作为词对来进行抽取,实验结果表明,该方法有效地解决了情感词与被修饰的情感对象不匹配的问题。同时,在词对的抽取方面获得了较高的综合指标。
1 相关工作
Kushmerick[4]提出一种基于规则的信息抽取,需要预先构造抽取规则集,相对于基于词典的信息抽取有一定的扩展性。Liu 等[5]采用关联规则方式抽取产品属性,并将产品属性附近的情感词作为评价词,实现一套产品评论分析系统。王鑫等[6]采用依存句法树为基础的论元识别手段,通过制约论元与特定词性的词在依存句法树中的距离来过滤优秀的候选论元集合。Yue等人[7]给出一系列转换规则,并提供了抽取活动图的方法,实现数据抽取。陈炯等人[8]借助同义词词林构建产品属性模板,使用属性模板识别产品属性。上述基于规则的方法在文本信息抽取中虽然可以取得较好的成绩,但在商品评价中经常出现不规则的语法结构,在文字表达上多为口语,再加上网络新词的不断涌现,导致商品评价情感要素的抽取存在障碍。
W.Jin等[9]利用隐马尔科夫模型(HMM)对词序列进行序列标注,可以有效地抽取未登录词。徐冰等人[10]使用CRF识别情感对象,系统在模型的训练过程中引入浅层句法信息和启发式位置信息,同时在不增加领域词典的情况下,有效提高了系统的精确率。孙晓等[11]提出将情感对象及情感词视为CRFs中不同标记的词,因此能使用CRFs同步抽取。Kim 等[12]将语义角色加入特征集合,在观点及主题抽取中取得较好效果。W.Wei等[13]针对产品属性层次关系没被充分利用的限制,提出了一种基于分层学习情感本体树的抽取算法。张旭成等[14]介绍了基于文本统计类别信息熵的关键词抽取技术。Qiu等[15]通过观察名词与形容词的依存句法关系,制定了一种双向传播的规则扩展种子词,最终可抽取出名词性评价特征和形容词性情感词典,实验取得了不错的效果,并提出一种可抽取观点表达式并判断极性的组合模型。吴苑斌等[16]等利用树核函数抽取产品特征和观点表达式。在商品评价信息抽取中,情感要素是以词对的形式出现的,上述方法在解决这一问题上还需要对情感对象和情感词做词对齐处理,本文提出的将二者作为词对抽取的方法可以有效地解决这一问题。
2 情感要素的抽取
2.1 特征说明
在情感要素抽取任务中,基于CRF模型的方法通常使用的特征包括词、词性及浅层句法特征等,如表2所示。

表2 基本特征表
文献[11]在上述特征的基础上还使用了语法成分特征(Gram)及句法父节点语法成分特征(PGram)。其中,句法父节点是依存句法分析树中当前词的父节点,而语法成分包括主语、谓语、宾语等。本文考虑到词类信息对词对抽取结果的影响,引入情感要素特征和聚类代码特征。
2.2 情感要素特征
在商品评价数据集合中,每句带有倾向性的评论均应包括情感词和情感对象词,因此,可将词的语义角色分为情感词、情感对象词和其他词3类,且各语义角色类别在数据集中的分布均匀。本文将情感对象词和情感词的语义角色作为情感要素特征,并通过情感对象和情感词词典进行特征标记。
情感对象特征(Emo)函数
情感词特征(Obj)函数
其中,A={情感对象};E={情感词};wi=词。
情感对象和情感词词典可以从训练语料的标注信息中直接获得。
2.3 聚类代码特征
聚类代码特征(Clu)通过聚类操作可以将具有相同词义的情感对象或情感词聚集到一起,在情感要素的抽取方面可以间接帮助识别同类情感要素;同时可以把每个小类看成是一个词典,这样相当于得到多个细粒度的词典,起到辅助情感要素词典识别情感对象和情感词的作用。
词聚类需要将词进行向量化处理,向量化是用N维行向量(N1,N2,N3,…,Nn)来表示一个词,通过词向量可以计算词与词之间的相似度。本文采用word2Vec模型对文本建模,为充分体现词与词的语义关系,理论上训练词向量的语料规模越大越好。实验采用搜狗新闻语料2.19G及混合商品评论语料231288条作为训练数据,训练word2Vec词向量模型,并得到情感对象和情感词的向量化表示,进而进行聚类操作,并为每个类赋予一个编号作为聚类代码特征,聚类模型选用K-means[17-18],对于测试集中的词利用KNN模型进行分类操作从而得到聚类代码。
3 实验数据及其结果分析
3.1 数据说明
实验数据全部来自天猫和京东商城的商品评价信息。为体现领域差距,分别选取手机、电饭煲和马桶3个领域差距较大的数据集,其中手机电商评价数据共2 064条,1264条用作训练,800条用作测试;电饭煲电商评价数据共2123条,1323条用作训练,800条用作测试;马桶电商评价数据共2118条,1318条用作训练,800条用作测试,以及3个领域的混合商品评价数据4705条用作训练,2400条用作测试。
3.2 训练集构建
本实验采用有监督模型进行情感要素的抽取,因此需要人工标注语料,标注规则的复杂性导致标注需要耗费大量时间。本实验使用已开发好的标注应用程序进行操作,其好处是避免标注人员直接接触文本数据而造成数据篡改,同时可以为以后的标注任务提供方便。由80名学生组成的标注团队,每组20人分别标注所有语料,第一轮将全部语料标注4遍,之后打乱数据重新分配,进行第二轮标注,取同一条数据中标注一致性最强的标签作为待选标签可以减少误标注率,最后进行人工校对以增强结果的准确性。本文采用与文献[11]相同的标注集进行标注,标注集合如表3所示。
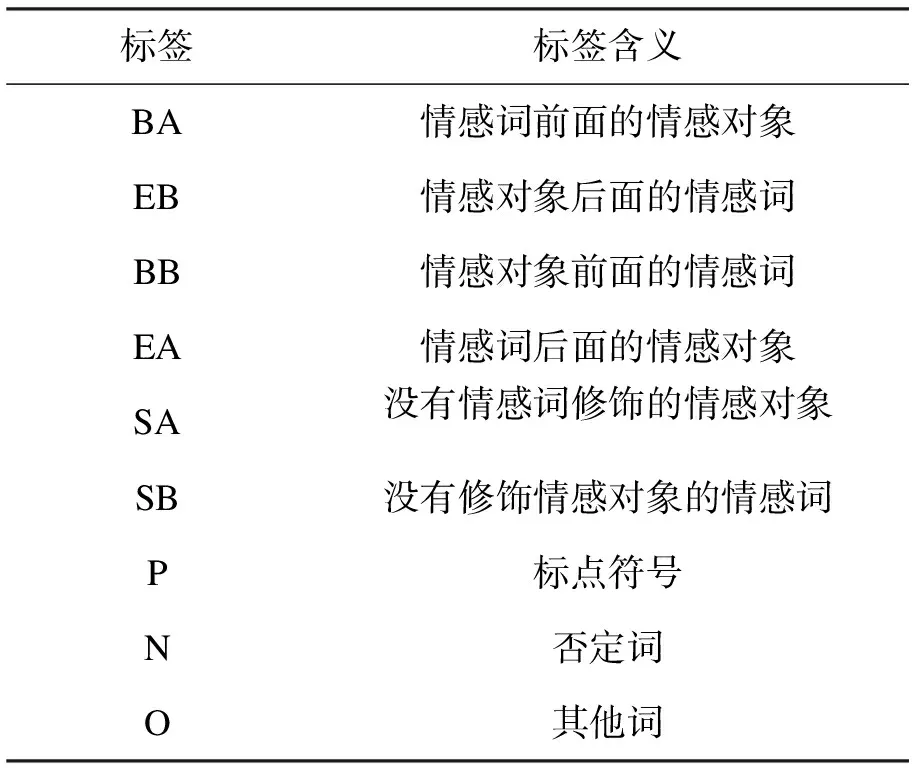
表3 标注集说明
3.3 实验结果分析
采用条件随机场模型(CRF)在电饭煲、马桶、手机及混合数据上做了4组特征的对比试验,特征组合选取见表4所示。
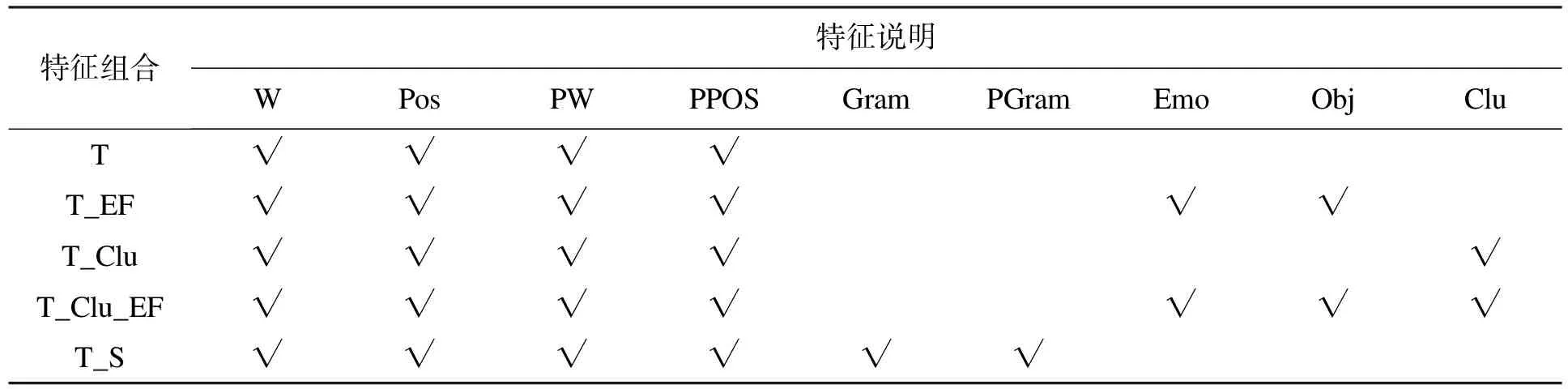
表4 特征组合说明
表5至表7分别列出了不同特征组合在测试集上的准确率、召回率及F值的实验结果。
通过对比特征组合T和T_EF发现,将情感要素词典特征引入CRF模型,无论准确率还是召回率都会有很明显的提升,这说明在词对抽取方面将规则模块融入CRF模型可以起到很好的效果,词典不但可以带来语义信息,更重要的是还能将规则抽取方法的优势融入统计模型。
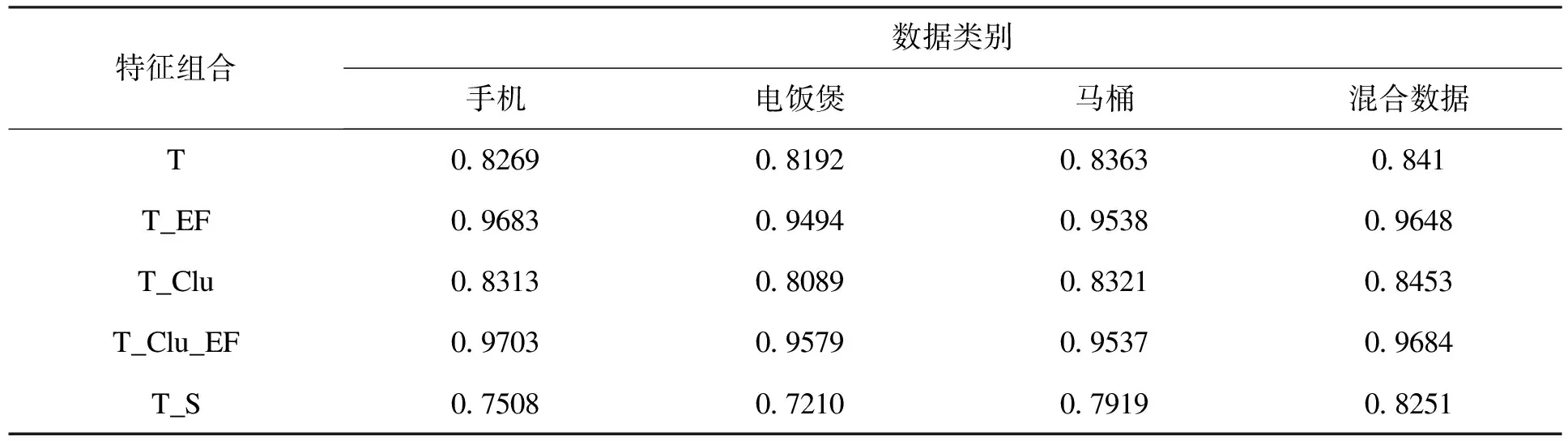
表5 准确率

表6 召回率
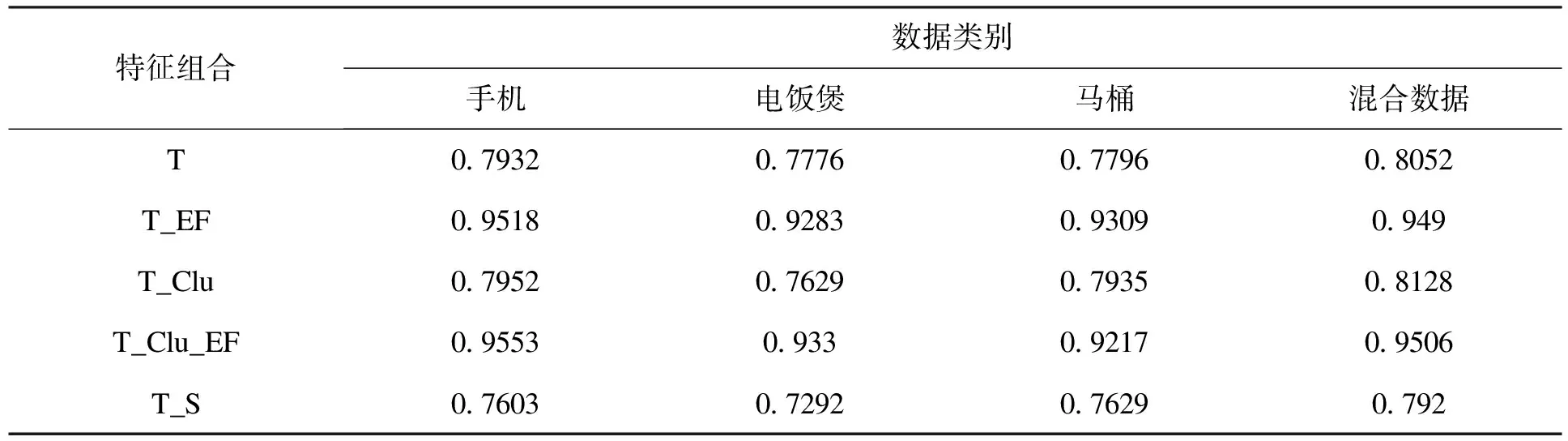
表7 F值
同时,比较T和T_Clu特征组合发现,引入聚类代码特征使词对抽取的各项指标得到了提升,一方面聚类代码可以起到多个细粒度词典的作用,判断信息是否为情感要素;另一方面,将词义信息引入模型中可以间接帮助识别同类情感要素。然而通过聚类得到的词类准确率没有词典高,在情感要素识别方面的效果较词典略差,因此不能全面取代词典特征。从实验结果来看,商品电饭煲和马桶抽取的准确率与召回率略微下降。分析推测,这是由于电饭煲和马桶的商品属性数量与手机等电子产品相比较少,且关于产品的属性描述略微单一化,因此聚类效果不佳,然而从手机评价数据以及混合数据的实验效果来看,结果有很大的提升,说明聚类代码对于词对抽取是有积极影响作用的。
特征组合T_S是在T的基础上加入语法成分特征,实验结果表明,该特征受句法分析准确率的影响较大,因此在词对抽取过程中没能达到很好的效果。
综上,本文尝试将情感要素词典和聚类代码同时引入CRF模型,发现二者的融合在词对抽取方面可以达到更好的效果,且避免了句法分析准确率对词对抽取的影响。对比3个领域的商品评价数据集上的实验发现,只有在马桶评价数据集上的实验结果没有得到提升。通过分析商品的评价语料发现,由于产品本身属性描述的不规范性,导致聚类的准确率下降,因此对于词典特征的补充效果不是很好,但是从其他类的语料以及混合语料上的实验效果来看,将词典特征与聚类代码特征结合是可以得到较为理想的抽取效果的。综合来看,通过5折交叉验证的方式,在3类不同数据的实验中,F值平均达到93.66%,在混合数据集上的实验中,F值达到了95.06%,充分表明了本实验方法在<情感对象,情感词>词对抽取方面的有效性。
4 结论
本文将情感要素词典及聚类代码引入条件随机场模型(CRF)中,实现情感对象和情感词的同步抽取,采用此方法将规则信息抽取的优势融入统计模型,从而提高了统计方法的效率,并通过在不同领域评价信息上的实验证明了方法的可靠性。
从实验可以看出词典在词对抽取的效率方面提供了明显的支持,当测试集与训练集来自不同领域商品评价信息时,通过训练集构建情感要素的词典在测试集中可能出现未登录词,对于这种情况可以采用动态构建情感要素词典的方法。在构建情感对象词典方面,可以设计词性序列模板获得候选商品属性词集,并采用统计方法筛选候选商品属性词[19],如表8所示,从而得到较全面的情感对象集合。
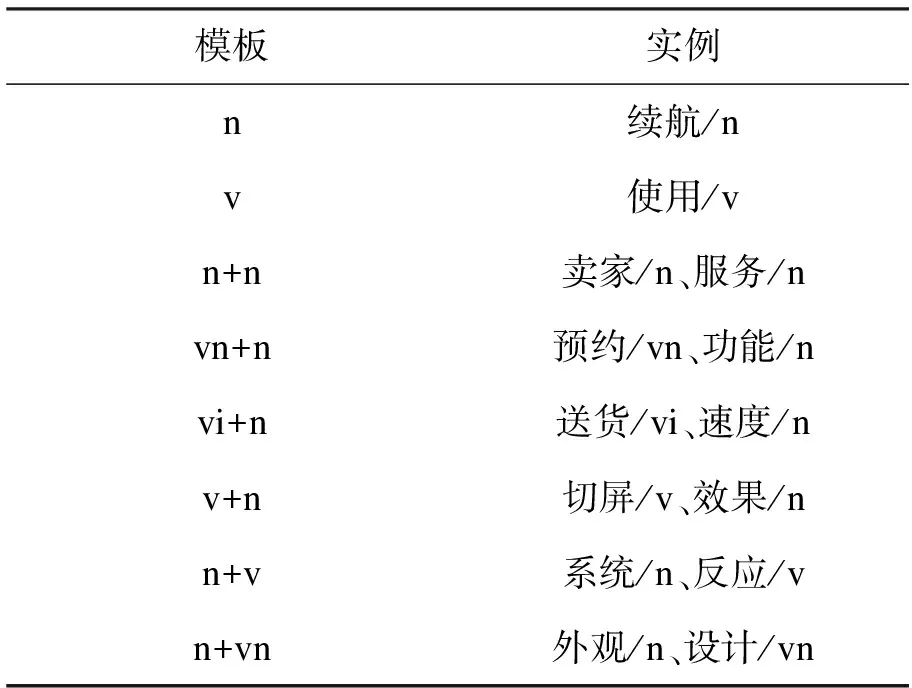
表8 词性序列模板
在情感词典的扩建方面,可以在基础情感词典的基础上采用计算互信息的方式构建扩展情感词典。目前,现有的基础情感词典主要有知网的“情感分析用词语集”和大连理工大学的“情感词汇本体”,前者将情感词分成正、负2个方面并提供了包含6个级别的程度词语集,后者则给出更为详细的情感词说明,包括情感强度、极性、及词义数等信息。通过此类方法可以得到较全面的情感词集。商品评价信息中的大量错别字及口语化现象导致词典的构建存在障碍,进而影响词典特征的准确率,下一步考虑通过引入拼音等中间媒介还原词义的方法来解决错别字及口语化现象。
[1]TURNEY P D.Thumbs Up or Thumbs Down?Semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of ACL-02,40th Annual Meeting of the Association for Computational Linguistics,2002:417-424.
[2]PANG B,LEE L,Vaithyana than S.Thumbs up?Sentiment classification using machine learning techniques[C]//Proceedings of EMNLP-02,the Conference on Empirical Methods in Natural Language Processing.Philadelphia,2002:79-86.
[3]YI J,NASUKAWA T,BUNESCU R,et al.Sentiment analyzer:extracting sentiments about a given topic using natural language processing techniques[C]//Proceedings of the 3rd IEEE International Conference on Data Mining(ICDM-2003).Melbourne,2003:427-434.
[4]KUSHMERICK N.Wrapper induction:efficiency and expressiveness [J].Artificial Intelligence,2000,118(01):15-68.
[5]LIU B,HU M Q,CHENG J S.Opinion observer:analyzing and comparing opinions on the web[C]//Proc of the 14th International Conference on World Wide Web.Chiba,2005:342-351.
[6]王鑫,穗志方.基于依存树距离识别论元的语义角色标注系统[J].中文信息学报,2012,26(2):40-45.
[7]YUE T,BRIAND L.An automated approach to trans form use cases into activity diagrams[C]//Proceedings of the 6th European Conference on Modeling Foundations and Applications.Paris,2010:337-353.
[8]陈炯,张虎,曹付元,等.面向中文客户评论的产品属性抽取方法研究[J].计算机工程与设计,2012,33(3):1245-1250.
[9]JIN W,HO H.A novel lexicalized HMM-based learning framework for web opinion mining[C]//Proceedings of the 26th Annual International Conference on Machine Learning,Ouebec,2009:465-472.
[10]徐冰,赵铁军,王山雨,等.基于浅层句法特征的评价对象抽取研究[J].自动化学报,2011,37(10):1241-1247.
[11]孙晓,唐陈意.基于层叠模型细粒度情感要素抽取及倾向分析[J].模式识别与人工智能,2015,28(6):513-520.
[12]KIM S M,HOVY E.Determining the sentiment of opinions[C]//Proc of the 20th International Conference on Computational Linguistics.Geneva,2004:1367-1373.
[13]WEI W,GGULLA J A.Sentiment learning on product reviews via sentiment ontology Tree[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics,Morristown:ACL,Uppsala,2010:404-413.
[14]张旭成,宋传宝.基于文本类别信息熵的中文文档关键词提取[C].武汉:中文信息处理国际会议,2007.
[15]QIU G,LIU B,BU J J,et al.Expanding domain sentiment lexicon through double propagation[C]//Proceedings of the 21st international joint conference on Artificial intelligence,California,2009:1199-1204.
[16]WU Y B,ZHANG Q,HUANG X J,et al.Phrase dependency parsing for opinion mining[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing,Morristown:ACL,Stroudsburg,2009:1533-1541.
[17]冯超.K-means聚类算法的研究[D].大连:大连理工大学,2007.
[18]周爱武,于亚飞.K-means聚类算法的研究[J].计算机技术与发展,2011,21(2):62-65.
[19]LI CHUNLIANG,ZHU YANHUI,XU YEQIANG.Research of attribute word extraction method in chinese product comment[J].Computer Engineering,2011,37(12):26-28.
(责任编辑:刘划 英文审校:赵亮)
Emotional factors extraction for commodity reviews
FENG Cang-long,BAI Yu,CAI Dong-feng
(Research Center for Human-computer Intelligence,Shenyang Aerospace University,Shenyang 110136,China)
The objective of the fine-grained orientation analysis on commodity reviews is to recognize the emotional polarity of the various sides of a commented object and reflect the intention of user’s reviews accurately.An emotional factor extraction is the key step in the analysis of the fine grain orientation of commodity reviews.This paper presented an approach for the extracting these factors.We introduced the dictionary of emotional factors and the clustering code into the CRF model,and then extracted emotional objects and corresponding emotional words simultaneously.Through experiment on the commodity reviews data sets in 3 different fields,we got 96.06% in precision,91.39% in recall and 93.66% in F-measure averagely.Finally,the experimental results showed that it has 96.84% in precision,93.34% in recall and 95.06% in F-measure on the mixed data set.
propensity analysis;commodity reviews;emotional factors extraction
2016-10-28
国家科技支撑计划(项目编号:2015BAH20F)
冯仓龙(1987-),男,黑龙江佳木斯人,硕士研究生,主要研究方向:人工智能与自然语言处理,E-mail:fd0724@163.com;蔡东风(1958-),男,辽宁沈阳人,教授,主要研究方向:人工智能与自然语言处理,E-mail:caidf@vip.163.com。
2095-1248(2016)06-0071-06
TP391.1
A
10.3969/j.issn.2095-1248.2016.06.012
猜你喜欢
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
文苑(2019年24期)2020-01-06 12:06:50
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
电子测试(2017年15期)2017-12-18 07:19:27
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
智能系统学报(2015年4期)2015-12-27 09:38:39
新闻研究导刊(2015年17期)2015-12-25 12:36:42
语言与翻译(2015年4期)2015-07-18 11:07:43
电子设计工程(2015年6期)2015-02-27 12:04:53
中央民族大学学报(自然科学版)(2014年3期)2014-06-09 08:54:32
