
基于多特性融合的代词消解方法研究
2016-02-06 05:44刘利
电脑与电信 2016年11期
刘利
(泸州职业技术学院信息工程系,四川 泸州 646005)
基于多特性融合的代词消解方法研究
刘利
(泸州职业技术学院信息工程系,四川 泸州 646005)
互联网已成为一个海量的开放式知识库,其中包含着许多有价值的信息,而网页是互联网信息承载的载体,将信息结构化成为知识库构建的基础。网页信息不仅包含许多指代词,还含有自身的标题。指代词消解是信息结构化的前提,综合网页信息具有的一般性和特殊性的特点,本文提出基于多特性融合的代词消解方法研究,能更好地适应网页信息代词的消解,提高网页信息代词消解的准确率。
多特性;标题;代词消解;信息结构化
1 引言
互联网信息具有规模庞大、样式多样、信息散乱等特点。而网页是互联网信息承载的载体,利用互联网构建知识库,成了对海量网页信息的抽取及结构化的过程。网页信息结构化的前提是代词消解,代词消解的结构直接影响到信息结构化的准确率。当前,绝大多数的网页信息都具有标题,对标题的描述包含在信息正文中,网页文本信息抽取模块将充分考虑网页信息的特征,建立适合它的文本信息抽取方法。
目前常见的代词指代消解方法有王智强等[1]人提出了基于决策树的汉语共指消解方法;庞宁等[2]人提出的利用最大熵来训练模型的方法;李国臣等人[3]结合庞宁等人的方法后提出了基于语料库的决策树机器学习算法;董国志等人[4]总结了基于规则和基于统计方法的缺点,提出基于规则预处理与最大熵模型相互结合的方法,在准确率和召回率上有所提高。
上述常用的指代消解方法不能很好地适应网页正文信息,比如:百度百科中有关李彦宏的介绍,标题为“李彦宏_百度百科”,有一段话为:“他要参战!在美国一批搜索引擎公司已崛起,而他选择了回国创业。他回忆这段人生抉择时说,‘我小时候有很强的不服输心理,越是大家不看好的事,我越是要做成。’”,其中并没有出现过他的名字。如果用董国志等人的方法,则在这段话的代词消解上不能实现。本文结合董国志等人的指代消解方法和网页的特性提出基于多特性融合的代词消解方法研究,能很好地适应上述情况。
2 标题统计分析
网页信息抽取模块产生的大量文本信息有其特殊性,比如抽取信息涉及主题范围广、绝大数网页都有标题或者子标题等。经统计发现标题中通常包含有该文本信息描述的命名实体,这个特征来源于网页正文信息和标题的关系。因此在命名实体识别方面,本文利用西南交大中文分词系统[5]对网页的标题以及网页内容进行分词,然后利用统计的方法,统计出标题的实体词频数最高的两个词(下面简称FWord和SWord),实验表明这两个词最有可能是文章的主旨词。
采用的评价标准是正确率(P1),具体公式如下:

本文选取体育类、财经类、人物类等领域各200个网页和大规模网页集中的200个网页,用公式(1)计算主旨词提取的正确率,其结果如表1所示。

表1 标题词频统计实验
在医药招商类信息的正确率较低,究其原因在于标题里面含有的噪声信息太多,导致统计词频确定主旨词时定位在噪声信息上。从财经类和体育类的词频统计结果来看,它们的标题有些采用比喻的手法,导致在确定标题主旨词时定位出错。不过在整体上的正确率还是较高的,说明通过标题的词频统计能反映出文章的主旨。
3 算法描述
本文对网页信息代词消解具体流程,如图1所示。
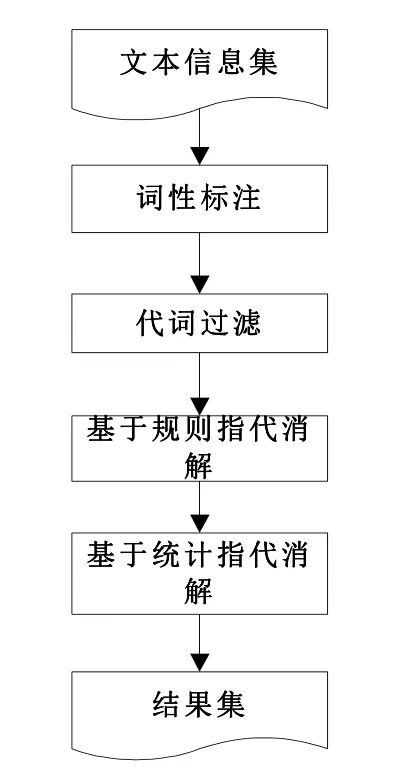
图1 指代消解流程
先用西南交大分词[5]对网页文本信息进行分词,提取信息里面所有的代词,再用算法消解代词。
在算法消解代词过程中,采取以下规则:
规则1:如果人称代词是单数,则找到表示人并且是单数概念的名词。如果人称代词是复数,则找到连词(比如“和”、“同”等)连接的并列结构或有复数概念的词。
规则2:如果指代词是指男性概念的,比如他、他的等,则在候选消解词中找到语义类相同并且性别相同的词进行消解。同理,如果代词为“她”或者“她的”,则需要找相应性别的人进行消解。
规则3:指代词和候选消解词之间的语义类要相同,比如对于表人的代词,候选消解词语义也要表“人”。同理,对于表物的代词,候选消解词也要表“物”,比如公司、地点、组织等都表示为物的。在判断实体词的语义方面,本文用的是“知网”中文语义库识别的[6,7]。
规则4:在选取候选消解词时限制在指代词所在位置的前两句以内,在计算时设定一个句子的距离值为1,也就是限制距离为3的范围以内。并且距离指代词越近则该候选消解词的权重越大。
规则5:如果指代词是第一人称代词,那么在该句子内搜索语义为“人”并且后面紧跟动词的词,若满足条件则,用该词进行消解。否则,不予消解。比如:“小明说:‘我想...’。”的形式出现就符合规则5。
再采取基于统计的指代消解方法,主要是从语义一致性、同位语一致性和距离属性三个特征属性着手。
(1)语义一致性
比较候选消解词同待消解指代词的语义是否属于同类,如果是则设置公式(2)中的特征函数为1,否则为0。

其中,x表示文本信息中命名实体或名词,y表示文本信息中的代词。
(2)同位语一致性
比较候选消解词和待消解指代词是否为同位语,如果是则设置公式(3)的值为1,否则设置为0。

其中,x和y同上述函数一致。比如“小明/nr、/w小红/ nr还有/v我/rr,/w我们/rr一起/s打球/vi”,其中“小明、小红、我”和“我们”是同位语。
(3)距离属性
比较消候选消解词和待消解指代词是否在同一句,如果是则设置公式(4)的值为3;如果相差一句则设置公式值为2;如果相差两句,则特征函数值为1;其他情况为0。公式如下:

其中,x和y同上述函数一致。

通过上面公式计算后,再用下面的权重公式进行计算,如公式(6):
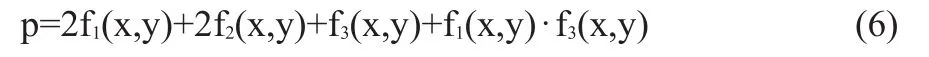
若p的值大于或等于5时,则进行消解,否则不进行消解。
4 实验过程和结果分析
自然语言处理的三个评测指标,即准确率、召回率。各个指标定义如下公式所示:


其中,P为准确率,R为召回率。
同其他消解方法的对比试验结果如表2所示:
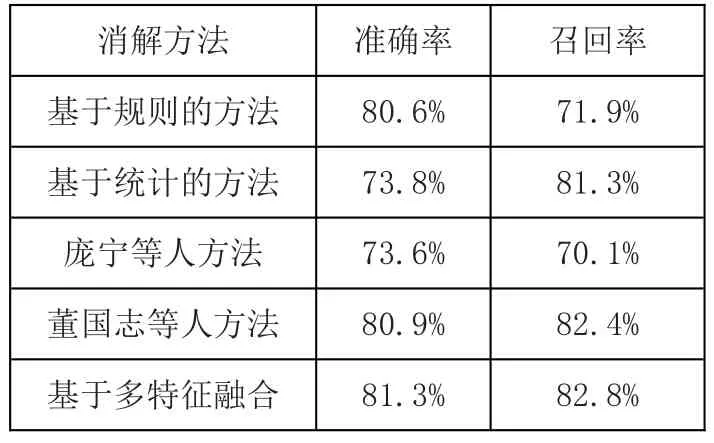
表2 代词消解结果对比
上述结果表明,较其他方法,本文方法能更好地适应网页信息代词消解。
5 结语
本文结合代词消解的常用方法,找到一种适应网页代词消解的方法,为网页信息结构化提供基础,但网页信息结构化还需要更高的准确率,后期可结合句法分析方法提高代词消解的准确率。
[1]王智强,李蕾,王枞.基于决策树的汉语代词共指消解[J].北京邮电大学学报,2 0 0 6,2 9(4):1-5.
[2]庞宁,杨尔弘.基于统计模型与规则的指代消解研究[J].太原科技,2 0 0 7,16 0(5):6 1-6 2.
[3]李国臣,罗云飞.采用优先选择策略的中文人称代词的指代消解[J].中文信息学报,2 0 0 5,19(4):2 4-3 0.
[4]董国志,朱玉全,程显毅.中文人称代词指代消解的研究[J].计算机应用研究,2 0 11,2 8(5):17 74-17 79.
[5]西南交大中文分词与智能问答系统[EB/O L].h t t p://i c s.s w j t u. e d u.c n/i n d e x.j s p
[6]知网库和讲解地址[EB/O L].h t t p://w w w.k e e n a g e.c o m/h t m l/ c_i n d e x.h t m l
[7]董振东,董强,郝长伶.知网的理论发现[J].中文信息学报,2 0 0 7,2 1(4):3-9.
Research on the Method of PronounsAnaphora Resolution Based on Heterogeneous Features Fusion
Liu Li
(Luzhou Vocational and Technical College,Luzhou 646005,Sichuan)
The Internet has become a mass of open knowledge base,which contains much valuable information.Web pages are the carriers of information,and the foundation of knowledge base construction.Web information contains many pronouns and titles. The pronouns anaphora resolution is the premise of information structure.The integrated web page information has general and special characteristics.This paper proposes a method of pronouns anaphora resolution based on heterogeneous features fusion,which can better adapt to the web information pronouns anaphora resolution and improve the accuracy.
heterogeneous features;title;pronouns anaphora resolution;information structure
TP391.1
A
1008-6609(2016)11-0042-03
刘利(19 8 8-),男,四川泸州人,硕士研究生,研究方向为人工智能、数据挖掘。
猜你喜欢
科学咨询(2022年19期)2022-11-24
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
疯狂英语·初中天地(2021年11期)2021-02-16
疯狂英语·初中天地(2021年12期)2021-02-12
考试与评价·八年级版(2020年1期)2020-10-26
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
高中生·天天向上(2018年1期)2018-04-14
自动化学报(2017年11期)2017-04-04
