
社会化标签语义相似度的协同过滤算法
2016-01-22 09:07:45谌颃
华侨大学学报(自然科学版) 2016年1期
谌颃
(广东技术师范学院天河学院 信息与传媒学院, 广东 广州 510540)
社会化标签语义相似度的协同过滤算法
谌颃
(广东技术师范学院天河学院 信息与传媒学院, 广东 广州 510540)
摘要:为解决传统的协同过滤算法不能准确理解用户的喜好,影响推荐准确率和推荐效果,提出基于社会化标签语义相似度的协同过滤算法.算法以标签语义相似度为基础,将项目资源和相关标签的语义信息纳入,显著提高了推荐系统的预测性能.研究结果表明:与以具体评分数据为基础的算法相比,该算法较好地解决了词相似度和句子相似度计算问题,推荐准确度和性能较以往的协同过滤算法有明显提高,改善了推荐效果.
关键词:协同过滤; 推荐系统; 社会化标签; 语义相似度; 预测性能
网络信息迅猛增长带来了日益严重的信息过载问题[1],个性化推荐系统可帮助用户在海量信息中有效搜索关心的资源.这些系统一般采用了基于内容、协同过滤或两种方法混合的技术[1-2].虽然这些传统的推荐技术应用广泛,但是它们在理解用户喜好方面存在不足,因此推荐精确度和效果有较大的影响.标签系统为用户提供了另一种实现资源推荐的新方法,它是一种提供基于Web的服务,用户能使用简短的语言描述对网页信息资源进行分类的标签技术[2].此外,标签还为内容相似性的比较提供了方法.考虑标签和项目资源的语义差别,本文提出了一种基于社会化标签语义相似度的协同过滤算法.
1标签的概念模型
标签(tag)是用户为项目资源自由、随意添加的一组标记或注解,用户的这种自主行为具有重要的社会意义,它可以更好地帮助用户组织资源、浏览资源和推荐资源[3].为了便于基于经验数据和模型的标签系统实现推荐行为,首先要建立一个通用可行的概念模型.考虑到通用性和有效性,研究选择采用三元组模型,包含用户集合(users)、标签集合(tags)和项目资源集合(items)等3个实体集合.
标签系统建立起了用户、标签和资源三者间的动态关系,如图1所示.用户集合区域是用户空间,包含了该系统中所有用户集合,每个元素代表一个用户;标签集合区域是标签空间,包含了该系统中全部标签集合,每个标签对应一个词(如“Avatar”)或一个短语(如“Forrest Gump”);项目资源集合区域则为项目资源空间,包括所有的项目集合,每个项目通常由一个唯一的编号标记.

图1 标签系统的动态关系Fig.1 Dynamic relationship of tag system
2标签喜好预测
2.1 项目交互的预测方法
一种基于用户与具有相关标签的项目交互的预测方法,如图2所示.用户在访问资源时往往有两类行为:一是新增、查找、关注标签的行为;二是用户浏览项目资源时的交互行为,如点击、浏览、评分、收藏等[4].通过对两类行为的分析可知用户感兴趣的内容.研究发现,如果将项目与标签之间的相关性作为预测算法的一个权重值,则该算法能够获得更好的用户喜好预测结果.

图2 标签的喜好推导Fig.2 Inferring a user′s preference for a tag
2.2 标签与项目的相关权重计算
通过Sigmoid函数计算出标签质量,相关权重值可用标签质量计算.设标签t与项目i的相关权重为w(i,t),则有

式(1)中:m为标签质量,m=TF×IDF,其中,设某项目所有的标签相关权重之和为1.0,TF表示词频,指词条t在文档d中出现的频率,IDF表示逆文档频率指数,指词条t出现的文档频率(DF)的反比[5].
2.3 标签喜好推导算法
根据用户-系统的交互行为,有多种方法可预测推导出用户的标签喜好.用户对项目的评分能更准确地表达用户的喜好.因此,文中选择用户对项目的数字评分方法,即用项目评级(item-ratings,IR)算法推导用户的标签喜好.此算法考虑了标签的相关权重,即有
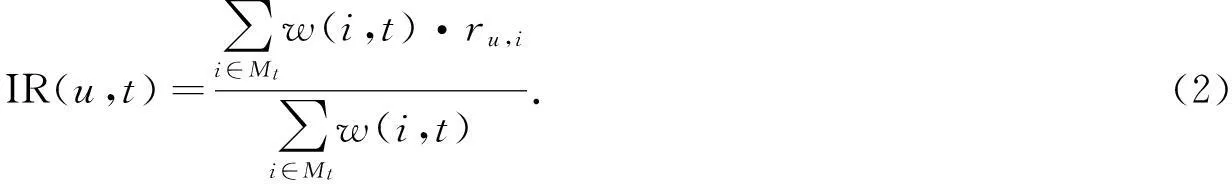
式(2)中:u表示用户;w(i,t)表示项目i和标签t之间的相关权重;ru,i表示用户u对项目i的评分;Mt是所有包含了标签t的项目的集合.然而,该算法的分子和分母的总和都没有考虑用户未评价的项目.在一些网站(如Del.icio.us)可能无法得到精确推导值,但是如果用户将一个项目添加为其最喜爱,那么就可以认为这个用户是喜欢这些项目的.
2.4 基于标签的推荐算法
预测出用户感兴趣的标签后,下一步将通过隐式标签(implicit-tag,IT)算法预测用户对项目资源的评分.具体方法:预测项目i的用户评分,先要计算出该用户对项目i之标签的兴趣程度,以及标签-项目的相关权重w(i,t).用户对标签的兴趣程度用NTP(u,t)表示,Ti表示项目i的所有标签的集合,则预测用户u对项目i的评分计算式为
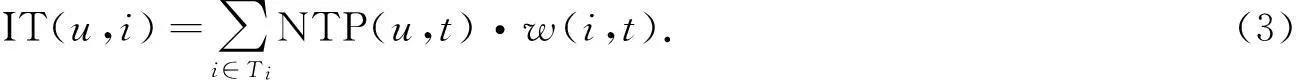
3基于WordNet的语义相似度算法
通过对MovieLens数据分析发现,标签是一个单词的情况约占39%,说明大多数标签是由多个单词构成的短语或句子.因此,计算标签之间的语义相似度需要分别计算词的相似度和句子的相似度.
3.1 词的相似度算法
词的相似度是取两个词所有概念相似度的最大值[6].计算两个同义词集的语义相似度的方法很多,如Wu & Palmer,Leacock & Chodorow和R. Resnik算法等.两个词的相似度(sim-words,SW)的表达式为
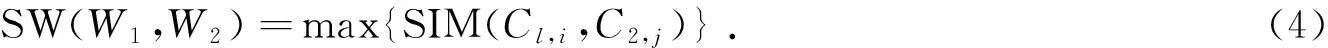
式(4)中:Cl,C2分别表示第一个词W1和第二个词W2的所有概念;SIM(Cl,i,C2,j)表示第一个词的第i个概念和第二个词的第j个概念的语义相似度.
3.2 句子的相似度算法
假定两个句子X和Y,其中X的长度为m,Y的长度为n.算法的主要步骤:1) 分词;2) 提取词干;3) 词性标注;4) 词义消歧;5) 将分词结果组成词语义相似度矩阵S[m,n],若是缩写词,如SCI(science citation index),先查缩写词典,再计算相似度值;6) 采用Hungarian方法将句子语义相似度计算问题转化成两个图的最大匹配权重计算问题,取句子X和Y中的词分别为两个图中的定点[7];7) 把前面的计算步骤合并计算,得到句子的相似度.
选用Dice相关系数计算句子的相似度(sim-sentences,SS),即

首先,设一个参照值;然后,依次对所有数据对进行匹配,若匹配分值超过参照值,说明这两个词的语义相似,予以保留[7];最终,通过式(5)可得匹配关系值即句子相似度值.例如,给定两个句子S和T,其长度分别为5和3.根据图的匹配算法得到S[1]与T[1]进行匹配,其匹配分值是0.8,S[2]与T[2]的匹配分值为0.7,S[3]与T[3]的匹配分值为0.75.使用Dice相关系数,设参照值为0.5,可以看出,3个分值都大于参照值,因此,选择这3个匹配对.由式(5)计算可得比值,即句子的相似度为2×(1+1+1)/(5+3) =0.75.
4用户评分预测和资源推荐列表的计算
预测用户u对他未曾购买过的项目资源i的评分.一方面,从式(3)可推导出用户u对标签的喜好NTP(u,t),从而得到其感兴趣的upre标签集合.即设参照值θ,用户u添加标签t,如存在NTP(u,t)>θ,则说明用户对它感兴趣,就将它加入到upre标签集合中.另一方面,还要得到与项目相关度最高的irel标签集合.即设参照值ω,如果有w(i,t)>ω,则说明此标签与项目相关度高,就将它加入到irel标签集合中.然后,计算出upre,irel两个标签集合的相似度值(SR),即SR(u,i)=SS(upre,irel).此值就是用户u对未购买项目i的预测评分.
需要说明一下,如果把两个集合中的所有标签(单词、短语或句子)分别串起来就可以看成是两个“句子”[8],那么,采用以上句子相似度算法计算两组标签集合的相似度是合理的[9-10].
重复对用户u所有未购买过的项目进行SR(u,i)的计算,并将全部预测评分结果从大到小排序,取前N个项目资源,即是N推荐列表.
5实验与分析
实验选择MovieLens(http:∥www.grouplens.org)第三组数据集作为实验数据集,该数据集含有71 567名用户对10 681部电影的10 000 054条评分数据及95 580个标签.
通过Ntop方法计算出项目预测准确度.首先,将推荐产生的N个资源置于训练集中;然后,检测N个资源有多少存在于测试集中,量越多算法的准确度就越高,反之,就越低.
用户集中全部用户重复以上实验后,计算得出全体用户兴趣度的平均值.平均Ntop准确度计算式为

式(6)中:Iu为设用户Ui已标注过标签的电影集;U为用户集合;Rui是训练集中用户Ui的推荐列表;Iui是用户Ui测试集中的电影集.如果Npre的值越高,则说明对应推荐算法的推荐准确度越高.

表1 不同算法的预测准确度比较
基于CFBTSS算法做了5和10两组实验,其中,推荐列表长度分别取5和10,并且分别用Cosine-tag和Implicit-item算法做了同样的实验,然后对三者进行比较,结果如表1所示.从表1可以看出:无论推荐列表长度是5还是10,CFBTSS算法结果皆优于另两种,其推荐准确度更高.
比较推荐列表的平均评分评价算法的有效性,分数越高,用户对推荐结果就越满意,算法也越有效.同样做了推荐列表长度分别为5和10的两组实验.当推荐列表长度为5时,CFBTSS算法的平均分和准确度为4.3,0.72;当推荐列表长度为10时,其平均分和准确度分别为3.6,0.68.由此可知,推荐列表5的用户评分平均达到了4.3颗星,表明用户比较喜欢这些电影.从实验结果看,提出的CFBTSS算法能够推荐更符合用户喜好的电影,表示这样的推荐更有意义.
以上两个实验结果表明:CFBTSS算法的推荐精确度和性能与传统个性化推荐算法相比有了较大地改善.
6结束语
文中算法以标签语义相似度为基础,与以具体评分数据为基础的算法相比,具有更好的理解意义和准确度,对改进个性化推荐系统具有重要意义.下一步工作是研究改进语义差别计算的方法及如何更加科学地描述项目资源的属性.
参考文献:
[1]王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-74.
[2]BEGELMAN G,KELLER P,SMADJA F.Automated tag clustering: Improving search and exploration in the tag space[C]∥Proceedings of the 15th International Conference on World Wide Web.Edinburgh:ACM Press,2006:1-5.
[3]谌颃.使用分类改进标签推荐系统准确度的研究[J].微电子学与计算机,2011,28(5):96-93.
[4]陈叶旺,李海波,余金山.一种基于农业领域本体的语义检索模型[J].华侨大学学报(自然科学版),2012,33(1):27-32.
[5]杨现民,余胜泉.学习资源语义特征自动提取研究[J].中国电化教育,2013(11):74-80.
[6]符征.语义引擎的形成及其应用[J].自然辩证法研究,2013(11):21-25.
[7]邓双义.基于语义的标签推荐系统关键问题研究[D].上海:华东师范大学,2009:37-41.
[8]许棣华,王志坚,林巧民,等.一种基于偏好的个性化标签推荐系统[J].计算机应用研究,2011(7):2573-2579
[9]崔林,宋瀚涛,陆玉昌.基于语义相似性的资源协同过滤技术研究[J].北京理工大学学报,2005,25(5):402-405.
[10]荀恩东,颜伟.基于语义网计算英语词语相似度[J].情报学报,2006,25(1):43-48.
(责任编辑: 黄晓楠英文审校: 吴逢铁)

Collaborative Filtering Algorithm Based on
Social Tags Semantic Similarity
CHEN Hang
(Information and Communication College, Tianhe College of
Guangdong Polytechnic Normal University, Guangzhou 510540, China)
Abstract:In order to solve the traditional collaborative filtering algorithm can not accurately understand the user′s preferences, affect the recommendation accuracy and recommendation effect, a collaborative filtering algorithm based on social tags semantic similarity is proposed. Based on the semantic similarity of tags, the semantic information of project resources and related tags is included, and the prediction performance of the recommendation system is significantly improved. Research results show that: compared with the algorithm based on the user rating, the proposed algorithm can solve the problem of word similarity and sentence similarity computation, and the recommendation accuracy and recommendation effect, as well as the performance of the proposed algorithm is significantly improved compared with the previous collaborative filtering algorithm.
Keywords:collaborative filtering; recommendation system; social tags; semantic similarity; prediction performance
基金项目:广东省高等学校学科与专业建设专项(2013LYM0110); 广东省教育科学规划专项(14JXN060)
通信作者:谌颃(1980-),男,高级工程师,主要从事网络信息系统、数据挖掘和个性化推荐技术的研究.E-mail:toboby@126.com.
收稿日期:2015-11-13
中图分类号:TP 301.6
文献标志码:A
doi:10.11830/ISSN.1000-5013.2016.01.0084
文章编号:1000-5013(2016)01-0084-04
猜你喜欢
软件(2016年4期)2017-01-20 10:09:33
计算机时代(2016年12期)2017-01-14 21:05:05
计算机应用(2016年12期)2017-01-13 20:37:46
中国新通信(2016年22期)2017-01-13 08:22:08
软件导刊(2016年11期)2016-12-22 21:40:40
现代情报(2016年11期)2016-12-21 23:35:01
电脑知识与技术(2016年28期)2016-12-21 11:09:59
电脑知识与技术(2016年27期)2016-12-15 19:46:14
电脑知识与技术(2016年27期)2016-12-15 19:41:16
电脑知识与技术(2016年26期)2016-11-24 18:12:54
