
一种改进的网络突发话题检测算法
2016-01-11 02:40:38哈艳,杜瑞忠,钟莲等
河北大学学报(自然科学版) 2015年5期
关键词:网络舆情
一种改进的网络突发话题检测算法
哈艳1,2,杜瑞忠2,钟莲3,张东琦2,李森4
(1. 河北大学 建筑工程学院,河北 保定071002;2. 河北大学 计算机科学与技术学院,河北 保定071002;
3. 河北软件职业技术学院 软件工程系,河北 保定071000;4. 河北大学 数学与信息科学学院,河北 保定071002)
摘要:引进文本相关度这一影响因子,提出了一种基于蚁群聚类算法的突发话题检测算法,该算法结合蚁群聚类算法的优势,综合考虑文本聚类和文本相关度的影响,得到对网络突发话题检测的最优聚类效果,并对近年来网络突发话题进行实验,达到了很好的聚类速度和聚类效果,验证了算法对突发话题检测的准确性和即时性.
关键词:网络舆情; 突发话题检测; 文本相关度; 蚁群聚类算法
An improved algorithm of bursty topic detection
HA Yan1,2,DU Ruizhong2,ZHONG Lian3,ZHANG Dongqi2,LI Sen4
(1.College of Civil Engineering and Architecture, Hebei University, Baoding 071002, China;
2.School of Computer Science and Technology, Hebei University, Baoding 071002, China;
3. Software Engineering Department ,Hebei Software Institute,Baoding 071000,China;
4. College of Mathematics and Information Science, Hebei University, Baoding 071002, China)
Abstract:A burst topic detection algorithm based on the ant colony clustering algorithm by introducing the text-related factor has been proposed. Combined with the advantages of ant colony clustering algorithm, this algorithm can get an optimal clustering effect on detection network of burst topic by considering the effect of text clustering and text-related degrees. Based on the experiments of network unexpected topic in recent years, it has been proved that this algorithm can achieve good effect of speed clustering and cluster, as well as the accuracy and immediacy of the algorithm topic burst detection.
Key words:online public opinion; bursty topic detection; text-related; ant colony clustering algorithm
第一作者:哈艳(1974-),女,回族,河北肃宁人,河北大学副教授,河北大学在读博士,主要从事计算机技术方向研究.
E-mail:hayan1997@sina.com
随着Web 2.0技术的快速发展,以互联网为载体的各种社交网络平台成为Web 2.0时代最具代表性的应用,其中,微博已经成为互联网舆情形成的主要网络媒体之一[1],同时,对突发话题的检测、溯源以及传播预测是网络舆情管理的重要目标之一.目前已有学者提出诸多话题检测算法,比如Michail Vlachos[2]将突发事件定义为由一组高相关的突发特征组成的事件.应用OMRBD(在线多分辨率突发发现算法)发现不同突发持续时间的突发特征.为了用突发特征表示突发事件,本文把突发特征之间的关联关系以及突发特征的优先级作为输入,使用近邻传播算法[3]发现突发事件.程学旗等[4]提出了一种基于噪声过滤的突发话题发现模型,从内容和用户参与度2个角度发现网络论坛中的突发话题并且能够找到与这些突发话题相关联的一些核心用户以及由这些用户所构成的网络社区.Michael Mathioudakis等人[5]实现了一个Twitter数据流事件发现系统,其首先基于排队论识别突发词,然后根据突发词的共现关系形成事件,利用PCA,SVD和命名实体识别技术获得描述事件的文本信息.
现有的微博突发话题相关的舆情研究中未考虑突发话题的形成机理,导致应用到实际微博舆情监管效果不佳.比如,Qiming Diao等人[6]基于微博消息流中同一时间的消息倾向于属于同一话题和同一个用户发布的消息,提出了基于LDA模型[7]的突发话题检测模型,该方法虽然同时考虑了时态信息和个人兴趣,但是其在计算所有话题的基础上再进行突发话题检测,整体检测时间慢,且只能针对离线数据进行突发话题检测;Mario Cataldi等人[8]通过衰老理论对字的生命周期进行建模,进而提出基于字的突发话题检测模型.文中采用固定时间窗口大小的滑动窗口机制,但是微博消息流变化迅速,在短时间内没有固定规律,但在长时间内表现出周期性,因此无法处理短时间内的突发情况,此方法虽然考虑了用户的属性信息,但是采用pagerank的迭代算法计算用户的影响力,大大增加了算法的计算复杂度.因此,本文从话题聚类效果和速度的最优角度出发,运用蚁群聚类算法(RTACC算法)的基本原理,结合文本相关度进行聚类优化,达到了很好的聚类效果.
1几个相关向量的定义
定义1文本集合D={D1,D2,…,Dk,…,Dn},1≤k≤n.其中,Dk表示D中第k个文本,n表示D中所包含文本的总数.已知舆情文本集合{D}有n个话题问题和K个分类{Sj=j=1,2,…,K},各个舆情文本有d个特征值,见矩阵D:
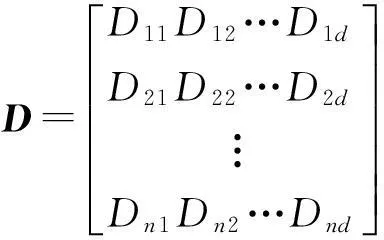
矩阵D中,每行为一个特殊向量,Di1,Di2,…,Did为第i个特殊向量的d个特征值,要求达到各向量到聚类中心的距离之和达最小,它的目标函数如下:
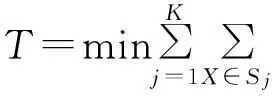
(1)
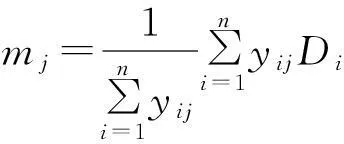
(2)
定义2初始话题集合IT={IT1,IT2,…,ITk,…,ITm},其中,ITi(i=1,2,…,n)表示对文本集合D中所有集合经过去除冗杂数据和符号后的文本构成的数据集.
定义3话题集合T={T1,T2,…,Tk,…,Tm},其中Ti(i=1,2,…,n)表示初始数据集中话题次数比指定阈值大的集合并利用字典处理中同近义词原则将话题中同、近义词语处理后得到的数据集.有,Ti⟹Tj的可信度和支持度S.C,S分别如式(3),(4)所示.

(3)

(4)
其中,|{T:Ti∪Tj⊆D}|表示在D中同时出现话题Ti和Tj的文本数目,|D|表示文本的总数目.
定义4相关度矩阵A,表示话题Ti(i=1,2,…,n)和Tj(i=1,2,…,n)之间可信度的矩阵.由定义中关联规则Ti⟹Tj的可信度计算公式,遍历T中所有话题,确定2个话题间的相关可信度,与话题间可信度有关.建立nn的话题相关矩阵A:
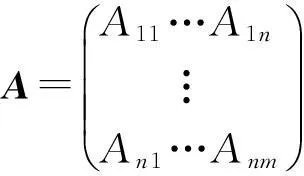
矩阵中各元素按式(5)进行计算
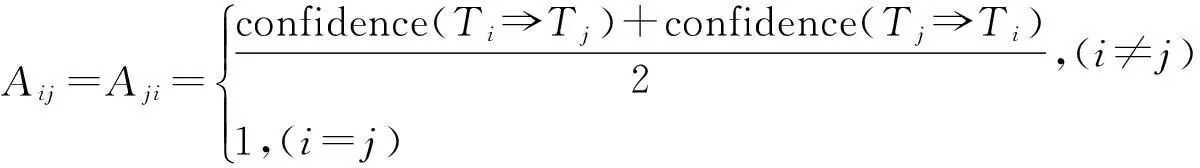
(5)
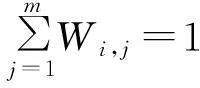
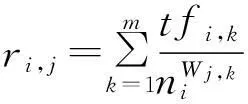
(6)
式中tfi,k的表示Di对TCj中Tk的贡献度,即Tk在Di中出现的频率,ni表示Di中包含的话题总数.
2基于蚁群算法的网络突发话题检测流程
考虑网络突发话题检测算法一个组合优化问题(S,f,Ω)[9],问题中,S是候选话题的集合,f是目标函数,对于任意s∈S有目标函数值f(s);Ω是约束条件的集合,由可行解集合,突发话题检测问题(S,f,Ω)可以描述为以下问题:
1)话题集合ξ=(c,c2,…,cNC)为优化问题的组成.
2)由可能话题序列x=〈ci,cj,…,ck,…〉来定义问题的有限状态话题集合χ,其中ci,cj,…,ck是ξ的话题元素.话题数目表示为|x|,表示话题中元素的个数,最大值l<∞.
3)突发话题集合S是有限状态话题集合χ的子集,即S⊆χ.
4)可行状态话题集合χ⊆χ,由满足约束条件的话题集合Ω的序列构成x∈χ.
5)S*是非空话题集合的最优解,如果满足S*⊆χ且S*⊆S.
关键词由上可知,突发话题检测问题可以用一种有向图G=(ξ,L)的思路进行解决,问题中,ξ为话题的集合,L为所有话题的链接弧集合,本文算法在检测算法的应用步骤如下:
Step 1初始化
关键词随机产生初始可行解s′,并设置=s′,∀(i,j),τij=τ0,对每一个蚂蚁选择初始c1,k=1,xk=〈c1〉;
Step 2解的构造
While(xk∈χ且xk∉S)do.
在每一步k,构建序列xk=〈c1,c2,…,ck〉后,根据如下的概率选择下一个结点l:
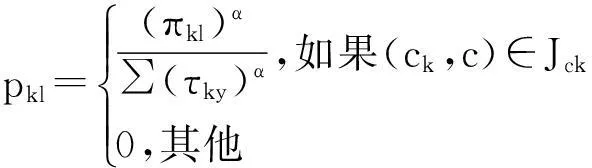
其中Jck表示可行域,α∈(0,+∞)为参数.当Jck为空,蚂蚁停止搜索,解的构造完成;
Step 3信息激素更新
∀(i,j):τij←(1-ρn)∘τij,
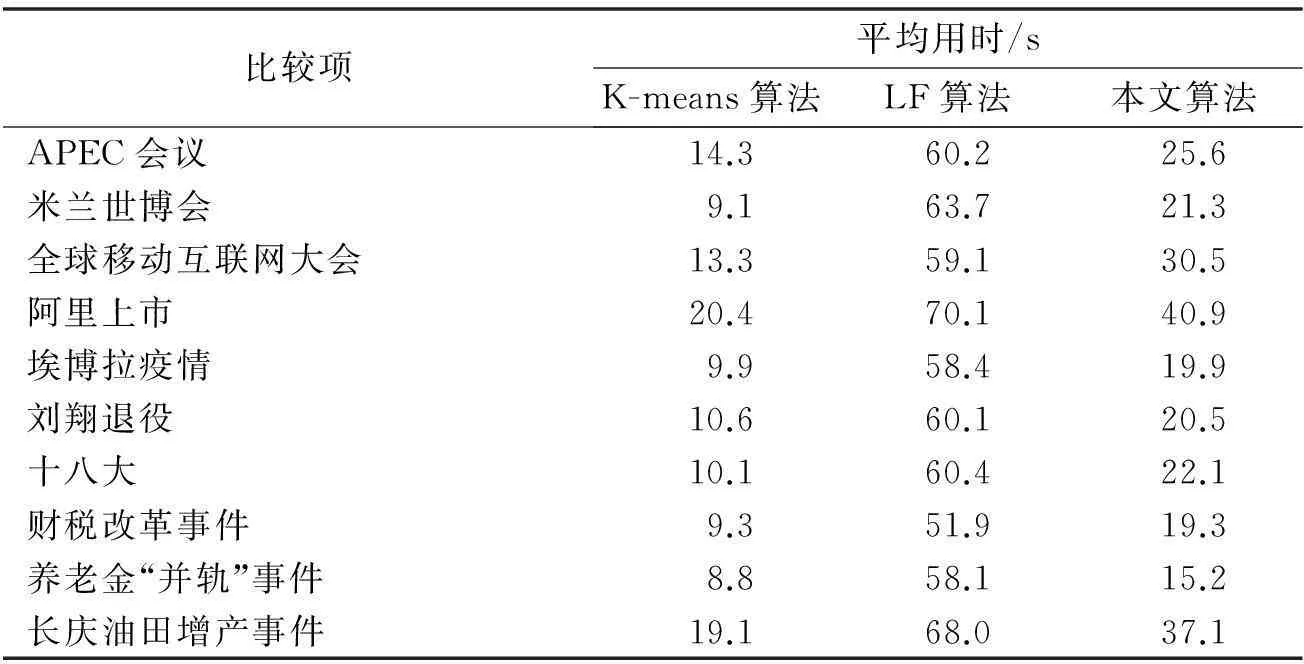
Iff(st) ∀(i,j)∈:τij←τij+ρn∘g(), 其中,0<ρn<1为信息激素发挥系数;g(s)是路径s的函数,且满足:f(s) 3引进文本相关度的蚁群聚类算法 关键词第1步,关联规则算法的建立.从大量的文本中挖掘出有价值的描述文本集合之间相互联系的话题.在关联规则中,设D=(D1,D2,…,Dk,…,Dn)是所有文本的集合,其中的元素称为文本项,T为话题项的集合. 假设X,Y是文本项集,关联规则是一个形如X⟸Y的蕴含式,这里X⊂T,Y⊂T,并且X∩Y=Φ.其中X是数据集的前文本,Y是数据集的后文本,⟹是相关度计算.文本集D的2个约束条件是支持度S和可信度C约束,分别代表频度和强度.话题文本集D中包含项目集X和Y,Y的话题数与所有话题数之比,成为关联规则X⟹Y的支持度S,即 S:support(X⟹Y)=|{T:X∪Y⊆T}|/|D|. 可信度C是包含文本集合X和Y的项目数与X总项目数之比 C:confidence(X⟹Y)=|{T:X∪Y⊆T}|/{T:X⊆T}|. 第2步,文本相关度的计算.文本相关度计算式如式(7)所示: (7) 第3步,文本相似度和相关度的结合.利用余弦相似度计算出2个话题文本Di和Dj的相似度Si,j=sim(Di,Dj),然后利用文本相关度来修正文本相似密度,结合算法如式(8): (8) 关键词当i=j时,Vi,j=1.当|Si,j-Ri,j|≤ε时,说明相似度与相关度并没有对话题带来大幅度的修正,于此0≤ε≤,γ为一种度量相关度与相似度二者之于文本相关度产生如何影响的因子.当Si,j<ε且Ri,j>λ时,说明文本相似度微小,而相关度则是给予了文本集合之间较大的影响,在此0≤λ≤1.除此之外,各种测试均能说明相似度和相关度都会令文本联系带来一定的变动,而在此之中,α为相关度之于相似度的调整. DOI:10.3969/j.issn.1000-1565.2015.05.014 中图分类号:TP391文献标志码:A 收稿日期:2015-01-15 基金项目:河北省社会科学基金资助项目(HB14XW014); 保定市社科基金资助项目(20140434);河北省大学生创新训练计划项目(2014047) 4数值实验 本算法在windows7操作系统中,利用C#语言,采用Microsoft Visual Studio 2012和Microsoft SQL Server 2008软件进行实现,对实验数据进行处理,得出4.3中的实验结果. 本文从实际问题入手,编写网络爬虫数据采集系统,对国内各大主流媒体网站进行数据采集,并对数据进行预处理,最后在其中选出10个话题,分别是APEC会议、米兰世博会、全球移动互联网大会、阿里上市、埃博拉疫情、刘翔退役、十八大、财税改革事件、养老金“并轨”事件、长庆油田增产事件.为保证数目,本文对每个话题选择 100 篇新闻报道,共计1 000篇. 本文先采用F-measure评价指标[10]对传统K-means算法[11]、LF算法[12]和基于文本相关度的蚁群聚类算法的性能进行比较分析.K-means算法参数为K=10.LF算法和本文提出的算法参数为α=0.25,k1=0.1,k2=0.15,s=2.下表为3种算法评价指标比较结果: 表1 3种算法的评价指标比较 为了明显地观察比较结果,利用MATLAB软件将表1数据绘制成3种算法的 F-measure 性能折线图,如图1. 图1 F-measure性能折线 然后分别比较不同算法对于相关话题聚类需要的平均运行时间,表2为比较结果. 表2 平均执行时间的比较 为了便于比较结果,利用MATLAB软件将表1数据绘制为平均运行时间折线图,如图2. 实验结果表明,本文所用的蚁群聚类算法与K-means聚类算法以及LF算法相比,其聚类查准率与聚类查全率均高于二者.本文算法执行时间明显低于LF算法, K-means算法虽然执行速度较快,但其处理效果低. 由此说明本文算法中引进文本相关度这一度量提高了对网络突发话题的查准率和查全率,表现出了更好的聚类效果和聚类速度. 图2 平均运行时间折线 5结论 本文通过引用话题文本相关度这一影响因子,结合蚁群聚类算法的优势,提出的基于文本相关度的蚁群聚类分析算法达到了网络突发话题检测的最优聚类效果,并对近年来网络突发话题进行实验,验证了算法对突发话题检测的准确性和即时性,表明基于文本相关度的网络突发话题检测算法对网络突发话题的检测是有效的. 参考文献: [1]夏火松,甄化春.大数据环境下舆情分析与决策支持研究文献综述[J].情报杂志,2015,34(2):1-6. XIA Huosong, ZHEN Huachun. Public opinion analysis and decision support study under big data surroundings[J].Journal of Information,2015,34(2):1-6. [2]VLACHOS M, MEEK C,VAGENA Z. Identifying similarities, periodicities and bursts for online search queries[Z]. Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data, Paris, France, 2004. [3]FREY BJ ,DUECK D. Clustering by passing messages between data points[J].Science,2007, 315(2):972-976. [4]陈友,程学旗,杨森.面向网络论坛的突发话题发现[J].中文信息报,2010,24(3):29-36. CHEN You, CHENG Xueqi, YANG Sen. Outburst topic detection for Web forums[J].Journal of Chinese Information Processing,2010,24(3):29-36. [5]MATHIOUDAKIS M , KOUDAS N .TwitterMonitor: trend detection over the twitter stream[Z]. Proceeding of the 2010 International Conference on Management of Data, New York, USA, 2010. [6]DIAO Q, JIANG J, ZHU F, et al. Finding bursty topics from microblogs [Z]. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island , Korea, 2012. [7]欧卫,谢赞福,谢彬彬,等.基于LDA模型的社交网络主题社区挖掘[J].计算机与现代化, 2014(8): 21-29. OU Wei, XIE Zanfu, XIE Binbin, et al. Mining of topic communities in social networks based on LDA model[J]. Computer and Modernization, 2014(8):21-29. [8]MARIO C, LUIGI DI C, CLAUDIO S. Emerging topic detection on twitter based on temporal and social terms valuation[Z]. Proceedings of the Tenth International Workshop on Multimedia Data Mining, New York, USA, 2010. [9]易云飞,陈国鸿.基于 k-means 的改进粒子群算法求解TSP问题[J].微计算机信息,2012,28(9):475-477. YI Yunfei,CHEN Guohong. An improved PSO algorithm based on k-means to solve TSP[J].Microcomputer Information,2012,28(9):475-477. [10]桑基韬,查正军,徐常胜.以用户为中心的社会多媒体计算[J].中兴通讯技术,2014,20(1):29-31. SANG Jitao, CHA Zhengjun, XU Changsheng. User-Centric social multimedia computing[J].ZTE Technology Journal,2014,20(1):29-31. [11]李红岩,胡林林,王江波,等.基于K-means的最佳聚类数确定方法研究[J].电脑知识与 技术,2014,10(1):110-114. LI Hongyan, HU Linlin, WANG Jiangbo, et al. A method for determining vintage number of clusters based on K-means algorithm[J]. Computer Knowledge and Technology, 2014,10(1):110-114. [12]陈应显.蚁群聚类算法中确定相邻对象方法的改进[J].计算机工程与应用,2009,45(18):144-146. CHEN Yingxian. Improvement of identified adjacent object on ant colony clustering algorithm [J].Computer Engineering and Application,2009,45(18):144-146. (责任编辑:孟素兰)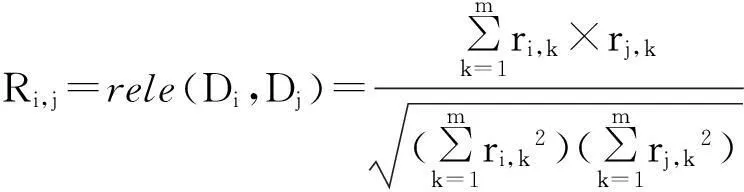

4.1 算法编程环境
4.2 实验数据采集
4.3 实验运行结果及数据分析


 猜你喜欢
新媒体研究(2016年21期)2016-12-19 06:03:11现代经济信息(2016年27期)2016-12-16 21:01:23法制与社会(2016年33期)2016-12-15 12:45:20山东青年(2016年9期)2016-12-08 16:45:59山东青年(2016年9期)2016-12-08 16:38:43今传媒(2016年10期)2016-11-22 13:04:37新媒体研究(2016年19期)2016-11-18 19:34:10大学教育(2016年11期)2016-11-16 20:34:04中国市场(2016年38期)2016-11-15 23:42:46经营者(2016年12期)2016-10-21 07:51:37
猜你喜欢
新媒体研究(2016年21期)2016-12-19 06:03:11现代经济信息(2016年27期)2016-12-16 21:01:23法制与社会(2016年33期)2016-12-15 12:45:20山东青年(2016年9期)2016-12-08 16:45:59山东青年(2016年9期)2016-12-08 16:38:43今传媒(2016年10期)2016-11-22 13:04:37新媒体研究(2016年19期)2016-11-18 19:34:10大学教育(2016年11期)2016-11-16 20:34:04中国市场(2016年38期)2016-11-15 23:42:46经营者(2016年12期)2016-10-21 07:51:37
