
多级评分聚类诊断法的影响因素*
2016-01-10 00:48:04康春花曾平飞
心理学报 2016年7期
康春花 任 平 曾平飞
(浙江师范大学教师教育学院,金华 321004)
1 引言
自认知诊断评估(Cognitive Diagnostic Assessment,CDA)问世以来,研究者进行了多方面多角度的探索,其中发展最迅猛的是诊断分类模型(Diagnostic Classification Model,DCM)。在DCM方面,研究者根据不同的实践需求从不同的前提和假设提出了各类模型,如按测评的评分方式,有 0-1评分的模型(如 RSM、AHM、DINA、NIDA、FM、GDM等)、多级评分或连续评分的模型(Bolt &Fu,2004;祝玉芳,丁树良,2009;涂冬波,蔡艳,戴海琦,丁树良,2010;张淑梅,包钰,郭文海,2013;李娟,丁树良,罗芬,2012;田伟,辛涛,2012;Sun,Xin,Zhang,&de la Torre,2013;罗欢,丁树良,汪文义,喻晓锋,曹慧媛,2010)。然而,这些多为参数模型,参数模型除了参数估计过程比较复杂外,往往需要大样本数据,且属性个数又不能太多 (Chiu &Douglas,2013;涂冬波等,2010)。为此,研究者开始探索更为简洁的非参数方法,如Vapnik (2000)依据风险最小化原则提出了基于统计学习理论的机器学习方法——支持向量机(Support Vector Machines,SVM),SVM不仅结构简单,还可运用小样本数据,既省时又高效(何学文,赵海鸣,2005;邝铮,2010)。Chiu等人(Chiu,Douglas,&Li,2009)在属性合分思路(Henson,Templin,&Douglas,2007)的基础上提出0-1评分的聚类分析方法。为吻合测评实践需要,研究者(康春花,任平,曾平飞,2015)将 0-1评分的聚类分析法拓展到多级评分(Grade Response Cluster Diagnostic Method,GRCDM),并探讨了样本容量、失误率及属性层级对其判准率的影响,所得结果表明:GRCDM在模拟和实践情境中均有很高的判准率,且对样本容量及属性层级紧密度依赖较小,可适用于小型测评等特征,这在一定程度上体现出非参数方法的优势。然而,目前关于非参数方法的研究还尚粗浅,能否借助参数方法的已有成果,探索GRCDM的影响因素,深入考察GRCDM的优势和性能,丰富非参数方法研究,是值得进一步关注的问题。
纵观参数方法的相关研究,可将影响模型判准率的因素概括为三个方面:一是与诊断测验相关的因素,如属性层级关系、Q矩阵、属性个数、题目数量(测验长度)等;二是与被试相关的因素,如被试能力分布、样本容量、失误率等;三是模型的选择,如模型与数据是否拟合,或模型与题目特征是否吻合(问题解决时属性之间的补偿性)。 其中,已有研究在测验因素方面关注较多。首先,在属性层级方面,研究表明属性层级结构的类型对判准率有一定的影响,属性层级结构越紧密判准率越高(颜远海,丁树良,汪文义,2011;蔡艳,涂冬波,丁树良,2013;田伟,辛涛,2012),而当层级关系误设时,则刚好相反,属性间关系越密切判准率则越低(涂冬波,蔡艳,戴海琦,2013a)。其次,Q矩阵在CDA中的作用至关重要,Q矩阵中包含的R矩阵个数越多,其判准率越高(丁树良,杨淑群,汪文义,2010;丁树良,汪文义,杨淑群,2011)。Q矩阵中的元素缺失或冗余会影响模型的判准率(Im &Corter,2011),属性缺失将高估掌握者的作答概率或失误参数,属性冗余将高估未掌握者作答概率或猜测参数(Kunina-Habenicht,Rupp,&Wilhelm,2012;Rupp&Templin,2008)。再次,在属性数目和测验长度方面,属性数目太多会造成判准率的急速下降,认知属性的个数最好不要超过7个(涂冬波,蔡艳,戴海琦,2013b;涂冬波,蔡艳,戴海琦,丁树良,2011),而在发散型、收敛型、无结构型中,测验长度宜越长越好,但在线型结构中,测验长度并非越长越好(颜远海等,2011)。在被试因素方面,失误率越大判准率越低已是不争事实。参数模型要求的样本容量一般在1000甚至2000以上(Chiu &Douglas,2013;涂冬波等,2010),可对于非参数方法,500人已是较佳样本,200人也很适宜(康春花等,2015)。此外,当被试的知识状态为负偏态时,判准率普遍高于其他分布形态(涂冬波等,2013a)。
研究者在参数模型的影响因素方面已做了较多的探索,并得到了较为一致的结论。参照参数方法的研究范式,本研究拟从测验因素和被试因素两方面分3个实验较为完整地探索属性数目、被试知识分布、属性层级关系、属性层级误设和Q矩阵误设对GRCDM的影响,以进一步考察非参数方法的特征与适用性,丰富非参数方法研究。
2 多级评分聚类诊断法的思路
多级评分聚类诊断法(GRCDM) (康春花等,2015)是在0-1计分聚类诊断法(Chiu et al.;Chiu &Douglas,2013)的基础上拓展而成,其整体思想是基于属性合分及其标准化的思路,计算出理想反应模式(Ideal Response Patterns,IRP)和观察反应模式(Observed Response Patterns,ORP)所对应的属性能力向量,通过ORP的属性能力向量到IRP的属性能力向量的距离,实现对被试知识状态的归类。
2.1 GRCDM的属性总分及能力向量的计算

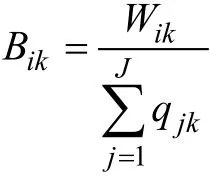
2.2 GRCDM的具体思路
GRCDM 是直接基于属性得分的诊断分类法,无需任何参数估计,因而其具体算法和思路简单明了(如图1所示),图1展示了对具有某个ORP的被试知识状态的归类过程。假如测验有k个属性,则其过程为:首先,需要基于Q矩阵或R矩阵,得到m 种理想掌握模式(Ideal Master Patterns,IMP)和IRP;其次,根据属性合分及能力向量的计算方法(2.1所示)得到m种IRP在k个属性上的能力向量,如“(B,……,B)…… (B,……,B)”;再次,计算某个ORP如ORP在k个属性上的能力向量“(B,……,B)”;最后,以IRP所对应的m种属性能力向量为初始聚类中心,计算 ORP所对应的属性能力向量与m个IRP所对应的m种属性能力向量的距离,把 ORP归类到距离最近的 IRP,从而把具有这种ORP的被试归类到其所属IRP对应的IMP中。

图1 GRCDM的具体思路
3 研究 1:属性数目、被试分布、属性层级关系对GRCDM的影响
3.1 研究目的
康春花等人(2015)研究表明GRCDM对样本容量无依赖,本研究拟在样本容量为 500的情况下,探讨属性数目、被试能力分布、属性层级关系对GRCDM判准率的影响,以考察GRCDM的适宜性与稳健性。
3.2 研究方法
3.2.1 研究设计
在被试人数n
=500和被试作答失误 10%时,研究包含 3个因素:3种属性个数(4个、7个、9个)、4种属性层级结构(线型、收敛型、发散型、无结构型,3种属性个数下的4种层级结构(见附录图1~图3)、2种被试能力分布(均匀分布、正态分布),为3×4×2的交叉设计,共24个实验,每个实验均重复20次以减少误差。属性个数为4个时,各层级结构下的简化Q阵包含4、5、5、8题;属性个数为7个时;各层级结构下的简化Q阵包含7、8、25、64题,其中64题缩减为22题,只包含测量1至3个属性的题目;属性个数为9个时,各层级结构下的简化Q阵包含9、26、27、256题,其中256题缩减为37题,只包含测量1至3个属性的题目。
3.2.2 模拟观察反应
在固定失误率为10%和样本容量为500的前提下,模拟不同属性数目、层级结构和被试能力分布共24种条件下的ORP,其思路为:
首先,根据 3.2.1各属性个数和层级结构下的Q矩阵,得到IMP及其对应的IRP;
其次,计算每种 IRP的总分,将其从小到大排序,使具有这些知识状态的被试人数满足标准正态分布(或平均分布),总分相同的IMP平均分配人数,产生500名被试进行分配;
最后,发生10%的失误,先产生一个服从U (0,1)的随机数r,ORP按如下规则获得:如果r>0.95且IRP的项目得分不是满分,则该项目得分增加1分;当IRP的项目得分是满分时,则该项目得分减1分;如果r<0.05且IRP的项目得分不为0分,则该项目得分减1分;如果IRP的项目得分为0分时,该项目得分增加 1分;如果0.05≦ r≦0.95时,则IRP的项目得分不变。由此,通过改变IRP的原有分数,在随机 10%的项目上发生失误,从而得到具有随机失误的 ORP (田伟,辛涛,2012;罗欢等,2010)。
在获得所有模拟数据后,采用2.1和2.2的思路对数据进行分析,数据模拟和分析过程均通过matlab 7.0编程实现。
3.2.3 评价指标

3.3 研究结果
3.3.1 GRCDM在各实验条件下的PMR和MMR均值
表1为属性数目、层级关系、被试分布各实验条件下,GRCDM的分类准确率PMR和MMR均值。由表1可以看出,GRCDM具有较高的PMR和MMR,各实验条件下的整体 PMR和MMR均值分别为96.26%和99.09%,且PMR和MMR最高可达99.88%和99.98% (9个属性、发散型、正态分布时),最低也能达 90.11% (4个属性、发散型、正态分布时)和96.81% (4个属性、收敛型、均匀分布时),PMR和MMR均值随属性个数的增加呈递增趋势(其他因素对 PMR值的影响需进一步分析)。由于 PMR是掌握模式匹配率而MMR只需单个属性的判准率,因此MMR>PMR,且MMR最低值和平均值都已经很高了,其变化规律又与 PMR一致,故接下来的所有分析中重点关注PMR的变化情况。

表1 三因素24种条件下的PMR和MMR均值(20次)
3.3.2 属性数目、层级关系及其交互效应对 PMR的显著影响
为进一步揭示属性数目、被试能力分布和属性层级关系对GRCDM的影响机制,对PMR进行三因素方差分析,发现:属性数目和属性层级关系均存在主效应(F
(2,456)=2064.83,p
<0.001,η=0.90;F
(3,456)=180.55,p
<0.001,η=0.54),且属性数目与层级关系的交互效应显著(F
(6,456)=
180.94,p
<0.001,η=0.70);而被试分布的主效应(F
(1,456)=44.21,p
<0.001,η=0.08)、被试分布与层级关系的交互效应(F
(3,456)=
13.15,p
<0.001,η=0.08)、属性数目与被试分布的交互效应(F
(2,456)=5.82,p
<0.01,η=0.03)等尽管达到了显著水平,但因效果量 η太小(在方差分析中,η>0.16是大效果量(舒华,张亚旭,2008)),认为它们实际效应并不存在;属性数目、被试分布和属性层级关系的三次交互效应不显著,F
(6,456)=
2.09,p
>0.05。由此,在3个影响因素中,属性数目、层级结构及其交互关系对GRCDM的影响强烈,而被试分布及与其它因素的相互关系对 GRCDM 的影响甚微(如,均匀和正态分布时,各层级关系下的 PMR均值分别为:99.10、98.53、99.14、99.40;99.31、98.67、99.14、99.40)。属性数目和层级关系的交互效应见图2。经简单效应分析发现,属性数目在各层级关系上均存在简单效应(线型:F
(2,117)=143.7,p
<0.001,η=0.711;收敛型:F
(2,117)=612.05,p
<0.001,η=0.91;发散型:F
(2,117)=1037.27,p
<0.001,η=0.95;无结构型:F
(2,117)=234.19,p
<0.001,η=0.80),并且在线型、收敛型和无结构型上均为9个>7个>4个属性,而在发散型上,为9个和7个属性均高于4个属性,但9个和7个之间无差异。另一方面,层级关系在各属性数目上也存在简单效应(4 个:F
(3,156)=153.60,p
<0.001,η=0.75;7 个:F
(3,156)=216.32,p
<0.001,η=0.806;9 个:F
(3,156)=54.63,p
<0.001,η=0.51),并且在 4 个属性时无结构型>线型>收敛型和发散型,在7个属性时发散型>无结构型>线型>收敛型,而在 9个属性时发散型>无结构型和收敛型>线型。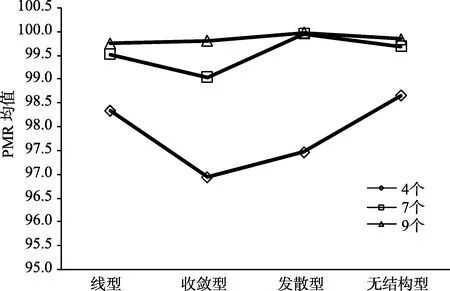
图2 属性数目与层级关系的交互效应
4 研究2:属性层级关系误设对GRCDM的影响
4.1 研究目的
在 CDA中,属性层级关系的正确设定非常重要,然而在实践研究中,并不能保证属性层级关系是百分百正确的。那么,如果层级关系误设了,哪种情况对GRCDM判准率的影响较大,哪种情况对GRCDM影响甚小呢?本研究将具体分析属性层级关系误设对GRCDM判准率的影响。
4.2 研究方法
4.2.1 研究设计
研究1表明GRCDM随着属性数目增多判准率反而增高,且对被试分布无依赖性,因而,为简化问题,本研究在控制属性个数为4个、被试能力正态分布、被试人数为100人及作答失误率为10%的情况下,探讨不同类型的层级关系误设对 GRCDM判准率的影响。实验包括 4种层级结构(线型、收敛型、发散型、无结构型)下的 6种正确层级关系和11种错误层级关系(概括为4种错误类型,见附录图4)。错误层级关系的模拟均不改变层级关系类型,即正确层级关系为线型的,错误层级关系还为线型(涂冬波等,2013a)。
附录图4中,错误1、错误2、错误3、错误7的类型为属性层级关系颠倒(如:错误 1中将属性A3为属性A4的先决属性,变为属性A4为属性A3的先决属性);错误4、错误8的类型为有层级关系变为无层级关系(如:错误4中属性A2是A3的先决属性,变为两属性逻辑关系为独立的);错误 6、错误10的类型为无层级关系变为有层级关系(如:错误6中,属性A2和A3是无逻辑关系的,变为属性 A2是 A3的先决属性);错误 5、错误 9、错误11的类型为属性层级关系错乱(如:错误 5中,属性A1和A2是无逻辑关系的,变为A1是A2的先决属性,与此同时,A1和A2是A3的先决属性变为A1和A2分别独立于A3)。
本研究为单因素实验设计,自变量为层级关系错误类型,有5个水平,共17个条件下的实验:层级关系正确(6种情况)、层级关系颠倒(4种情况)、有层级关系变为无层级关系(2种情况)、无层级关系变为有层级关系(2种情况)、层级关系错乱(3种情况)。为减少实验误差,每个条件均重复20次。因变量为MMR均值及降幅。
4.2.2 数据模拟及分析
首先,在正确层级关系的前提下,得到被试真实的IMP,在此基础上模拟被试的ORP,方法同研究 1;其次,得到正确层级关系下的简化 Q矩阵、属性能力向量,以此能力向量为初始聚类中心,采用 GRCDM 得到每个被试在每个属性上的 MMR(本实验主要关注错误类型而非层级关系对GRCDM的影响,在同一种错误类型下会有不同的层级关系,从而无法比较PMR而只能比较MMR的变化),作为层级关系误设时的对照值;再次,得到各种错误类型下的简化Q阵、IMP及能力向量,以错误时的能力向量为初始聚类中心,对被试的 ORP进行GRCDM分析,得到被试此时的MMR;最后,对正确和错误时的MMR进行比较,得到层级关系误设时的MMR降幅,并对其进行描述统计及方差分析,推导研究结论。
4.3 研究结果
4.3.1 不同错误类型下的MMR降幅
表2为不同类型的 11种层级关系误设下的MMR均值和相较正确层级关系的MMR均值降幅。由表2可以看出层级关系颠倒(错误1、2、3、7)的MMR均值的平均降幅为0.117、有层级关系变为无层级关系(错误 4、8)的 MMR 均值的平均降幅为0.006(降幅最小)、无层级关系变为有层级关系(错误6、10)的MMR均值的平均降幅为0.105、层级关系错乱(错误 5、9、11)的 MMR 均值的平均降幅为0.245。其中,无结构型时的层级关系错乱(错误11)的 MMR均值降幅最大(40.40%),此外较大的还有错误9、6、7、2等:发散型时属性层级错乱(24.60%)>收敛型时无层级关系变为有层级关系(11.90%)>发散型时层级关系颠倒(11.70%)>线型时层级关系颠倒(11.30%),其它类型的降幅则相对较小。

表2 11种层级关系误设下的MMR均值降幅
4.3.2 错误类型对MMR降幅的影响
对4种层级关系误设类型的方差分析结果表明,错误类型对 MMR降幅存在显著影响,F
(3,216)=97.12,p
<0.001,η=0.51,其降幅由大到小依次为:属性层级关系错乱>无层级关系变为有层级关系、属性层级关系颠倒>有层级关系变为无层级关系(见表3)。
表3 Scheffe事后多重比较结果
5 研究3:Q矩阵误设对GRCDM的影响
5.1 研究目的
属性层级关系误设,必然导致Q矩阵中存在属性冗余或缺失,为进一步考察GRCDM的稳定性或敏感性,本研究在研究 2的同等控制条件下,探讨不同属性层级结构(线型、收敛型、发散型、无结构型)下的不同Q矩阵误设(属性多余、属性缺失、属性既冗余又缺失)对GRCDM判准率的影响。
5.2 研究设计
实验为4×3 (4种层级关系、3种误设类型)的交叉设计,共12个试验,每个试验均重复20次以减少误差。各实验条件下的题目为各层级结构(见附录图1)下的简化Q阵。4种层级结构下的简化Q阵都包含(1 1 0 0)考核模式,因此可通过对该题目的错误设置来考察不同 Q矩阵误设类型对 GRCDM判准率的影响。实验中包括3种Q矩阵误设类型:属性缺失是指将(1 1 0 0)误设为(1 0 0 0);属性冗余是指将(1 1 0 0)误设为(1 1 1 0);属性缺失&冗余是指将(1 1 0 0)误设为诸如(1 0 1 0)等模式。
表4呈现了不同层级结构下的Q矩阵误设的模拟。改变类型中“1→0”表示Q矩阵误设类型为属性缺失,“0→1”表示属性冗余,括号中的数字指缺失或多余了哪个属性(4个属性分别为A1、A2、A3、A4),如“1→0(1)”表示属性 A1 缺失、“0→1(3)”表示属性A3多余。被试ORP的模拟方法、数据分析思路同研究2。评价指标为PMR和MMR。
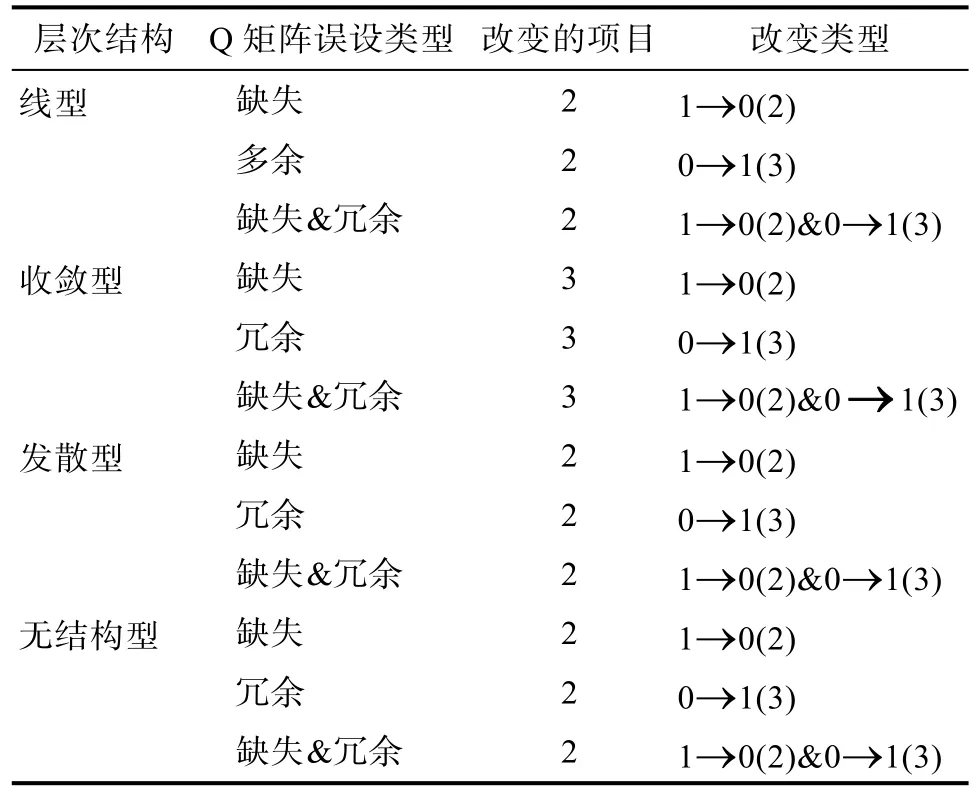
表4 不同层级结构下Q矩阵误设的模拟
5.3 研究结果
5.3.1 Q矩阵误设对PMR和MMR的整体影响
表5为4种层级结构下的3种Q矩阵误设对GRCDM判准率的影响,即相较正确Q矩阵的PMR和MMR降幅。从表5可以看出,MMR的降幅最高才0.06,最低为0,可见Q矩阵误设对MMR的影响并不大。而PMR的降幅相对MMR稍高,平均降幅为4.3%,尤其在线型和无结构型时较大,其中线型属性缺失&冗余时,PMR降幅达 23.7%,可见 Q矩阵在线型时的误设对GRCDM影响较大。属性层级结构、Q矩阵误设类型对PMR和MMR影响的交互效应可见图3。由图3可知,PMR的降幅趋势与MMR类似,因此只分析PMR降幅结果。
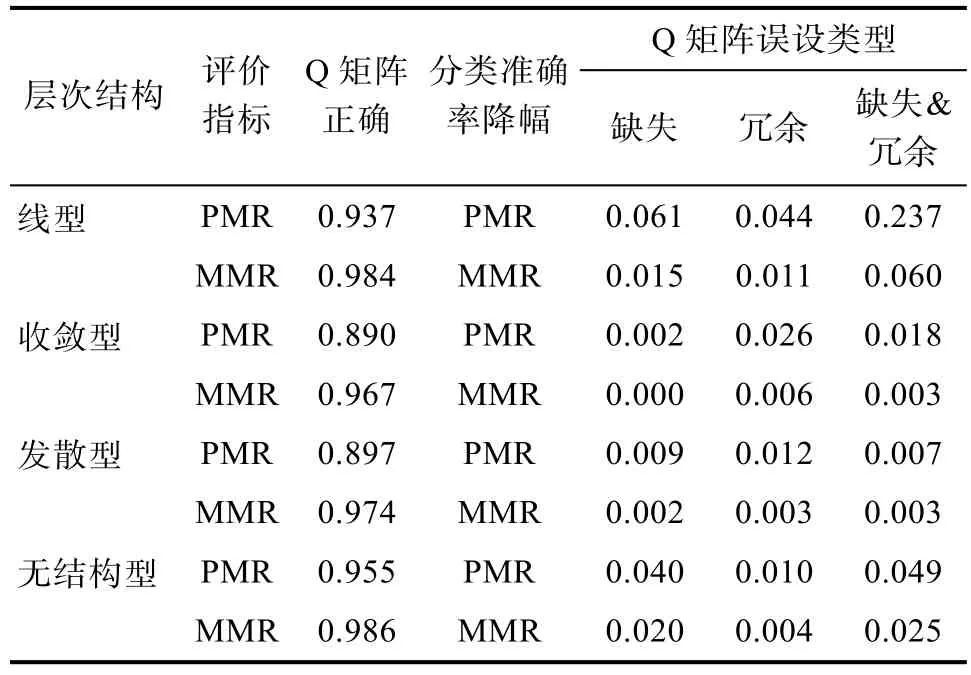
表5 属性层级结构、Q矩阵误设对判准率的影响
5.3.2 属性层级结构和误设类型对GRCDM判准率的影响

图3 属性层级结构、Q矩阵误设对PMR和MMR影响的交互效应图
对 PMR进行两因素方差分析发现:属性层级结构和Q矩阵误设类型主效应均显著(F
(3,228)=91.57,p
<0.001,η=0.55;F
(2,228)=66.40,p
<0.001,η=0.37);属性层级结构与Q矩阵误设类型的交互效应显著,F
(6,228)=49.83,p
<0.001,η=0.57。进一步简单效应分析表明:误设类型在线型和无结构型时简单效应显著(F
(2,57)=232.30,p
<0.001,η=0.89;F
(2,57)=8.15,p
<0.001,η=0.22),且在线型时表现为属性冗余、属性缺失>属性冗余&缺失,在无结构型时表现为属性冗余>属性缺失、属性冗余&缺失;而在收敛型和发散型时简单效应并不显著(F
(2,57)=2.39,p
>0.05;F
(2,57)=0.075,p
>0.05)。结合表4、表5和图3可得出,线型和无结构型在Q矩阵正确时的判准率相对较高,但也容易受Q矩阵误设的影响而导致判准率下降,收敛性和发散型在 Q矩阵正确时的判准率相对上两种稍低,却不易受Q矩阵误设影响,降幅在各种误设条件下接近于0,且误设类型之间无显著差异。6 讨论
6.1 GRCDM 对属性数目无依赖,随属性数目增加判准率反而升高
在参数模型中,模型判准率随属性数目增多会呈现下降的趋势,一般而言不宜超过 7个,否则会造成判准率的急速下降(Chiu &Douglas,2013;涂冬波等,2010,2013b)。为比较不同模型在属性数目变化时判准率的变化趋势,搜索已有研究相似条件下的9种多级评分模型的模拟结果进行描述(见表6)。由表6可以看出,与参数方法不同的是,GRCDM不仅不受限于属性数目,随着属性数目的增多其判准率反而呈递增趋势。并且,在属性个数相当甚至较多的情况下,其判准率要高于P-DINA、GRM-GDD、GRM-AHM-A、GRM-AHM-B、GRM-RSM和多级Fusion等方法(涂冬波等,2010;李娟等,2013;祝玉芳,丁树良,2009;Bolt &Fu,2004;田伟,辛涛,2012),但略微低于 GDD-P和GP-DINA两种方法(张淑梅等,2013;Sun et al.,2013)。可见,在属性数目较多样本容量又较少的情况下,较适于选用GRCDM 作为分类方法,但如果样本容量较大,则GDD-P和GP-DINA也是不错的选择。由此,可以认为GRCDM对属性个数无依赖,在一定程度上弥补了参数模型受限于属性个数不易过多的现状,更能吻合实践教学中属性个数较多及更微观细致的评估需求。
6.2 GRCDM 不受被试知识分布影响,较适合松散型结构
关于被试知识状态分布与判准率之间的关系,参数模型由于所需样本量较大,一般在模拟设计时都设定被试知识状态是正态分布(少数设为均匀分布),但对分布状态本身研究较少,仅有的研究为:当被试的知识状态为负偏态时,参数模型的判准率普遍高于其他分布形态(涂冬波等,2013a)。本研究同时考察了被试分布形态、属性层级关系和属性数目对GRCDM的影响,结果表明被试分布形态的主效应及与其它两变量之间的二次和三次交互效应均未达到明显效果。这个结果说明GRCDM这种非参数方法对被试知识状态分布无依赖,这不仅可以与其对样本容量无依赖的结果相印证(康春花等,2015),也进一步体现了非参数方法的特征与优势。究其原因,可能与非参数方法本身对总体分布形态无要求有关,所以改变被试知识状态的分布就犹如改变加权平均数的权重一样,对非参数方法的结果并无影响,这正是非参数方法的优势所在。
以往研究表明层级关系对参数模型判准率影响较大,属性间逻辑关系越紧密,判准率越高;属性间逻辑关系越松散,判准率偏低(涂冬波等,2013a;蔡艳等,2013;颜远海等,2011;田伟,辛涛,2012)。本研究显示GRCDM在各属性层级的PMR均值由小到大依次为:收敛型(94.86%)<线型(96.01%)<发散型(96.60)<无结构型(97.58),层级结构存在主效应,与属性数目也存在交互效应,随着属性个数的增加,GRCDM 更适合发散型和无结构型(见3.3.2)。这为松散型知识结构下的分类诊断找到了一种简单有效的替补方法。
6.3 GRCDM对层级关系误设的反应因属性层级而异
虽然DINA模型族可以不考虑属性层级,然而属性层级却是认知模型的一种表达形式(毋庸置疑),它在认知诊断测验编制中(如试题的开发与组卷)乃至对被试的分类诊断与补救中都起着至关重要的作用(丁树良,罗芬,汪文义,2012;DiBello &Stout,2007;Leighton,Gierl,&Hunka,2004)。然而,已有多级评分模型对属性层级误设并未做相关研究。仅有的研究见于涂冬波等人(2013a)关于几种非补偿性参数模型(0-1评分模型)在属性层级误设时的比较,以反映各种模型在属性误设时的敏感性或稳定性。图4(图中纵坐标单位为%)列出了属性层级误设时,GRCDM 与涂冬波等人(2013a)结果的比较。从图4可以看出,GRCDM无论在各种属性层级误时的降幅还是总体平均降幅都比 RSM、AHM-A、GDD要小很多,但比DINA-HC稍高。由此,我们可以认为GRCDM在层级误设时的判准率还是比较稳定的,之所以比 DINA-HC模型要稍高点,是因为DINA模型族本身就是不考虑层级关系的模型。

表6 GRCDM与其它多级评分诊断模型在不同属性个数的判准率(%)

图4 属性层级误设时GRCDM与其它模型的判准率降幅比较
此外,涂冬波等人(2013a)的结果表明:属性间逻辑关系越紧密,其层级关系误设导致的降幅越大,然而具体哪一种层级误设类型的影响最大,却未提及。本研究实验2结果表明,除了“有层次关系变为无层次关系”的MMR均值的平均降幅为0.006,其它条件下降幅均较大。说明GRCDM对层次关系误设的反应比较敏感。纵观4种误设类型,发现其降幅从大到小依次为:属性层级关系错乱(24.5%)>无层级关系变为有层级关系(10.4%)、属性层级关系颠倒(8.8%)>有层级变为无层级(0.6%)。具体到各种层级关系类型时,其降幅较大的还有:无结构型时的层级关系错乱(40.4%)>发散型时属性层级错乱(24.6%)>收敛型时无层级关系变为有层级关系(11.9%)>发散型时层级关系颠倒(11.7%)>线型时层级关系颠倒(11.3%)。由此,GRCDM对“有层级变为无层级”容忍度较高,而对“层级关系错乱”容忍度较低,尤其是无结构型和发散型时的基础属性一定不能误设,紧密型的属性逻辑确定也需谨慎,在不能保证两属性间是否存在先决关系的前提下,尽量视其为独立。
6.4 Q矩阵误设对GRCDM的影响因层级关系而异
属性层级误设必然导致 Q矩阵中的元素缺失或冗余,而Q矩阵的界定是否正确直接关系到测验项目的质量、测验是否具有结构效度以及基于测验结果的诊断信息是否准确。然而,无论是基于数学的方法、模型的方法还是专家多次讨论的结果,Q矩阵都未必完美无缺,因而研究者陆续对Q矩阵误设时诊断方法的判准率进行研究,以探讨诊断模型或方法的敏感性或稳定性。那么Q矩阵误设对项目质量及判准率有哪些具体影响呢?Rupp和Templin研究发现,当Q矩阵中的某个项目所测属性缺失时,该题失误参数将被高估,并且,由于Q矩阵中缺少了特定的属性考核模式,将无法区别某些知识状态的被试,进而导致被试分类的正确率降低(Rupp &Templin,2008;Kunina-Habenicht et al.,2012),而属性冗余时,该题猜测参数将被高估(Rupp &Templin,2008)。本研究实验 3表明,在线型和无结构型时,其判准率的高低依次为属性冗余、属性缺失、属性冗余&缺失,而在收敛型和发散型时GRCDM对属性误设的容忍度较高,降幅基本在 1%以下。就GRCDM而言,Q矩阵误设也会导致判准率的下降(与参数模型一样),所不同的是,相比收敛型和发散型,无结构型和线型的判准率在属性既冗余又缺失及属性缺失时更易受影响,但对属性冗余容忍度较高,而收敛性和发散型相对具有较大的稳定性,不易受Q矩阵误设的影响。
7 结论
GRCDM 无需参数估计,是一种较为简便且适宜小型评估的非参数方法(康春花等,2015),为进一步深入探讨其特性,本研究通过3个模拟研究考察其影响因素,所得结果表明:(1) GRCDM不会受限于属性数目和被试能力分布状态,在各种条件下其判准率均较高,且随属性数目的增多判准率反而增高;(2) GRCDM的判准率依属性层级误设类型不同而不同,其中影响最小的是“有层级变为无层级”、最大的是“属性层级关系错乱”,尤其是针对无结构型和发散型时;(3) Q矩阵误设对GRCDM的影响因属性层级关系的不同而不同,其中收敛型和发散型受影响较小,结构型和线型的判准率在属性既冗余又缺失时降幅较大。
然而,尽管本研究进一步探测了GRCDM的主要特性,为非参数认知诊断方法的研究提供了新信息,但有些方面还需继续改进和完善:(1)丰富模拟研究中关于失误分数的设计方式(加 1分减 1分的范式略显单一),后续研究可以采用张淑梅等(2013)滑动矩阵这种与现实情境较吻合的多元化的失误分数设计方式;(2)进一步完善Q矩阵误设方式,未来研究可以考虑采用喻晓锋,罗照盛等人(2015)关于 Q矩阵误设和联合估计的方法,进一步考察 GRCDM的稳定性与灵敏性;(3)关注GRCDM与其它参数或非参数方法(如SVM)的直接比较,进一步考证其在诊断分类中的优越性,以获得更多直接信息。
Bolt,D.,&Fu,J.B.(2004).A polytomous extension of the fusion model and its Bayesian parameter estimation.Paper presented at NCM E,San Diego,USA.
Cai,Y.,Tu,D.B.,&Ding,S.L.(2013).A simulation study to compare five cognitive diagnostic models.Acta Psychologica Sinica,45
(11),1295−1304.[蔡艳,涂冬波,丁树良.(2013).五大认知诊断模型的诊断正确率比较及其影响因素:基于分布形态,属性数及样本容量的比较.心理学报,45
(11),1295−1304.]Chiu,C.-Y.,&Douglas,J.(2013).A nonparametric approach to cognitive diagnosis by proximity to ideal response patterns.Journal of Classification,30
(2),225−250.Chiu,C.-Y.,Douglas,J.A.,&Li,X.D.(2009).Cluster analysis for cognitive diagnosis:Theory and applications.Psychometrika,74
(4),633−665.DiBello,L.V.,&Stout,W.(2007).Guest editors' introduction and overview:IRT-Based cognitive diagnostic models and related methods.Journal of Educational Measurement,44
(4),285−291.Ding,S.L.,Luo,F.,&Wang,W.Y.(2012).Extension to Tatsuoka’s Q matrix theory.Psychological Exploration,32
(5),417−422.[丁树良,罗芬,汪文义.(2012).Q矩阵理论的扩展.心理学探新,32
(5),417−422.]Ding,S.L.,Wang,W.Y.,&Yang,S.Q.(2011).The design of cognitive diagnostic test blueprints.Journal of Psychological Science,34
(2),258−265.[丁树良,汪文义,杨淑群.(2011).认知诊断测验蓝图的设计.心理科学,34
(2),258−265.]Ding,S.L.,Yang,S.Q.,&Wang,W.Y.(2010).The importance of reachability matrix in constructing cognitively diagnostic testing.Journal of Jiangxi Normal University (Natural Science),34
(5),490−494.[丁树良,杨淑群,汪文义.(2010).可达矩阵在认知诊断测验编制中的重要作用.江西师范大学学报(自然科学版),34
(5),490−494.]He,X.W.,&Zhao,H.M.(2005).Support vector machine and its application to machinery fault diagnosis.Journal of Central South University (Science and Technology),36
(1),97−101.[何学文,赵海鸣.(2005).支持向量机及其在机械故障诊断中的应用.中南大学学报(自然科学版),36
(1),97−101.]Henson,R.,Templin,J.,&Douglas,J.(2007).Using efficient model based sum-scores for conducting skills diagnoses.Journal of Educational Measurement,44
(4),361−376.Im,S.,&Corter,J.E.(2011).Statistical consequences of attribute misspecification in the rule space method.Educational and Psychological Measurement,71
(4),712−731.Kang,C.H.,Ren,P.,&Zeng,P.F.(2015).Nonparametric cognitive diagnosis:A cluster diagnostic method based on grade response items.Acta Psychologica Sinica,47
(8),1077−1088.[康春花,任平,曾平飞.(2015).非参数认知诊断方法:多级评分的聚类分析.心理学报,47
(8),1077−1088.]Kuang,Z.(2010).Application of support vector machine to cognitive diagnosis
(Unpublished master thesis).Jiangxi Normal University.[邝铮.(2010).支持向量机在认知诊断中的应用研究
(硕士学位论文).江西师范大学.]Kunina-Habenicht,O.,Rupp,A.A.,&Wilhelm,O.(2012).The impact of model misspecification on parameter estimation and item-fit assessment in log-linear diagnostic classification models.Journal of Educational Measurement,49
(1),59−81.Leighton,J.P.,Gierl,M.J.,&Hunka,S.M.(2004).The attribute hierarchy method for cognitive assessment:A variation on Tatsuoka's rule-space approach.Journal of Educational Measurement,41
(3),205−237.Li,J.,Ding,S.L.&Luo,F.(2013).The generalized distance discrimination based on graded response model.Journal of Jiangxi Normal University (Natural Science),36
(6),636−639.[李娟,丁树良,罗芬.(2013).基于等级反应模型的广义距离判别法.江西师范大学学报(自然科学版),36
(6),636−639.]Luo,H.,Ding,S.L.,Wang,W.Y.,Yu,X.F.,&Cao,H.Y.(2010).Attribute hierarchy method based on graded response model with different scoring-weight for attributes.Acta Psychologica Sinica,42
(4),528−538.[罗欢,丁树良,汪文义,喻晓锋,曹慧媛.(2010).属性不等权重的多级评分属性层级方法.心理学报,42
(4),528−538.]Rupp,A.A.,&Templin,J.(2008).The effects of Q-matrix misspecification on parameter estimates and classification accuracy in the DINA model.Educational and Psychological Measurement,68
(1),78−96.Shu,H.,&Zhang,Y.X.(2008).Research methods in psychology:Experimental design and data analysis.
Beijing,China:People’s Education Press.[舒华,张亚旭.(2008).心理学研究方法:实验设计和数据分析
.北京:人民教育出版社.]Sun,J.,Xin,T.,Zhang,S.M.,&de la Torre,J.(2013).A polytomous extension of the generalized distance discriminating method.Applied Psychological Measurement,37
(7),503−521.Tian,W.,&Xin,T.(2012).A polytomous extension of rule space method based on graded response model.Acta Psychologica Sinica,44
(2),249−262.[田伟,辛涛.(2012).基于等级反应模型的规则空间方法.心理学报,44
(2),249−262.]Tu,D.B.,Cai,Y.,Dai,H.Q.&Ding,S.L.(2010).A polytomous cognitive diagnosis model:P-DINA model.Acta Psychologica Sinica,42
(10),1011−1020.[涂冬波,蔡艳,戴海琦,丁树良.(2010).一种多级评分的认知诊断模型:P-DINA 模型的开发.心理学报,42
(10),1011−1020.]Tu,D.B.,Cai,Y.,&Dai,H.Q.(2013a).Comparison and selection of five noncompensatory cognitive diagnosis models based on attribute hierarchy structure.Acta Psychologica Sinica,45
(2),243−252.[涂冬波,蔡艳,戴海琦.(2013a).几种常用非补偿型认知诊断模型的比较与选用:基于属性层级关系的考量.心理学报,45
(2),243−252.]Tu,D.B.,Cai,Y.,&Dai,H.Q.(2013b).A polytomous extension of higher-order DINA model.Journal of Psychological Science,36
(4),984−988.[涂冬波,蔡艳,戴海琦.(2013b).基于HO-DINA模型的多级评分认知诊断模型的开发.心理科学,36
(4),984−988.]Tu,D.B.,Cai,Y.,Dai,H.Q.,&Ding,S.L.(2011).A research on MCMC parameter estimation and the properties of the high order DINA model.Joumal of Psychological Science,34
(6),1476−1481.[涂冬波,蔡艳,戴海琦,丁树良.(2011).HO-DINA模型的MCMC参数估计及模型性能研究.心理科学,34
(6),1476−1481.]Vapnik,V.(2000).The nature of statistical learning theory
.New York:Springer Science &Business Media.Yan,Y.H.,Ding,S.L.,&Wang,W.Y.(2011).The research on factors influencing diagnostic accuracy in AHM and DINA.Journal of Jiangxi Normal University (Natural Science),35
(6),640−645.[颜远海,丁树良,汪文义.(2011).影响AHM与DINA诊断准确率的因素研究.江西师范大学学报(自然科学版),35
(6),640−645.]Yu,X.F.,Luo,Z.S.,Qin,C.Y.,Gao,C.L.,&Li,Y.J.(2015).Joint estimation of model parameters and Q-matrix based on response data.Psychologica Sinica,47
(2),273-282.[喻晓锋,罗照盛,秦春影,高椿雷,李喻骏.(2015).基于作答数据的模型参数和Q 矩阵联合估计.心理学报,47
(2),273-282.]Zhang,S.M.,Bao,Y.,&Guo,W.H.(2013).A generalized cognitive diagnosis model under a particuliar polytomous situation.Psychological Exploration,33
(5),444−450.[张淑梅,包钰,郭文海.(2013).一种多级评分的广义认知诊断模型.心理学探新,33
(5),444−450.]Zhu,Y.F.,&Ding,S.L.(2009).A polytomous extension of attribute hierarchy method based on graded response model.Acta Psychologica Sinica,41
(3),267–275.[祝玉芳,丁树良.(2009).基于等级反应模型的属性层级方法.心理学报,41
(3),267−275.]猜你喜欢
航天工业管理(2020年9期)2020-12-28 00:38:02
军事运筹与系统工程(2020年1期)2020-09-11 06:41:00
山东体育学院学报(2018年2期)2018-10-29 11:09:58
江苏理工学院学报(2017年3期)2017-05-30 14:46:05
电子技术与软件工程(2017年4期)2017-03-27 19:51:09
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
系统工程与电子技术(2016年2期)2016-04-16 05:17:09
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
