
RDA内容、媒介和载体类别分类的可用性研究*本文系2013年四川省文化厅图书情报学与文献学规划“《资源描述和检索》(RDA)的内容、媒体与载体类别的分类可比性实证研究”(项目编号:WHTTSXM[2013]3)研究成果。
2016-01-04 02:13
新世纪图书馆 2015年3期
关键词:编目
RDA内容、媒介和载体类别分类的可用性研究*本文系2013年四川省文化厅图书情报学与文献学规划“《资源描述和检索》(RDA)的内容、媒体与载体类别的分类可比性实证研究”(项目编号:WHTTSXM[2013]3)研究成果。
凡迪周茜
摘要《资源描述和检索》用一组内容、媒介和载体类别的资源分类替代了第二版《英美编目规则》里的一般资料标识。研究采用了和封闭式卡片分类法相似的设计,通过发放问卷,调查了中国被试对这一分类的接纳程度,以及语言上的差异是否构成将R DA英文版在英语国家外用作编目标准的障碍。研究结果表明,国内被试对这一R DA的分类接纳良好,但语言差异确实影响了英文版R DA在国内的可用性。
关键词编目《资源描述和检索》资源分类可用性
分类号G254.31
Usability Research of RDA’s Resource Categorization Tested in China
Fan Di,Zhou Qian
Abstract Resource Description and Access (RDA) includes a new taxonomy of media, carrier and content types that replaced AACR2’s general material designations (GMDs). With a research design similar to the closed card sorting, the authors distributed the questionnaires and investigated Chinese users’acceptance of the RDA taxonomy and whether the linguistic difference could be problematic for the use of RDA’s English version as a cataloging standard outside the Anglo-American world. The results suggested that Chinese participants’acceptance of the RDA taxonomy was rather good, but the linguistic difference did hinder the usability of this taxonomy.
Keywords Cataloging. Resource Description & Access(RDA). Resource categorization. Usability.
0 引言
作为新的国际编目和元数据标准,《资源描述和检索》(RDA)以《书目记录的功能需求》(FRBR)和《规范数据的功能需求》(FRAD)中的概念模型为基础编制。RDA期待能让元数据使用者更为方便地查找、识别、选择和获取不同种类的资源[1]。新标准的名字中没有出现“英美”的字样,是标准国际化的标志之一,同时体现出了标准消除英美文化偏颇的意愿[2]。
为了给元数据用户提供更好的体验,RDA的新尝试之一,就是停用了第二版《英美编目规则》中的一般资料标识,而以一组三要素的资源分类取而代之,即内容类别(对应FRBR中的“内容表达”层次)以及媒介类别和载体类别(均对应FRBR的“载体表现”和“单件”层次)[3]。RDA对资源类型的分类,是以FRBR中的概念模型为基础的。然而,这一概念模型,是“对书目记录中主要反映的数据进行逻辑分析后获得的”[4]。RDA的这一分类实际上是以理论为基础的,用户对这一分类的接纳程度如何还不明确。
1 背景和文献回顾
就西文资源而言,国内无论是公共图书馆还是高校图书馆通常都采用英文作为描述性编目和主题编目的语言。包括中国国家图书馆和CALIS这两个最有影响力的机构都是如此,在描述性编目上参照AACR2,主题编目上采用国会图书馆主题标目(LCSH)。试想,如果RDA被引入国内用作西文文献的编目标准,即便RDA提供了采用非英语的脚本、数字和日期来著录资源的选项[2],国内西文文献的编目语言也不大可能突然由英语调整成汉语。否则,图书馆目录中的新RDA记录和先前的记录之间就会因语言差异而显得非常不一致。而要采用英文版的RDA作为国内西文编目的标准,就有必要测试国内读者对这一RDA分类及其采用的受控词汇的接纳程度,以了解这一分类在采用英文原文的受控词汇时,对国内读者而言是否如宣传所说的那样便于查找、识别、选择和获取资源。
Hider的两项研究[5-6]同本研究最为相关。Hider采用卡片分类法和自由列表法,比较了RDA分类和来自澳大利亚高校的最终用户的分类。在自由列表法测试中,Hider计算了各个词语出现的频率,作为衡量词语重要性的指标。由于研究设计的局限,没有采用另一项也能衡量重要性的指标,即词语出现的先后位置。同样,也没有对相似性矩阵的分析。Hider的结论是,图书馆资源是多面化的。同载体和内容这两个分面相比,其它分面(比如资源的受众及其目的)也具有相当的重要性。在他的卡片分类研究中,Hider的被试对两组卡片进行了分类。一组是之前自由列表法中获得的词汇,另一组是RDA分类中的受控词汇。Hider总结到,目录用户区分载体和内容类别这两个分面确有一定的困难。
但是,作为集体主义文化的东方国家,中国图书馆读者同澳大利亚的相应群体相比,在文化和语言上有很大的差异,他们对相同测试的反映也就可能会不一致。因此,考虑到RDA的国际化定位,在其它文化下测试这一RDA分类很有意义。
在Library, Information Science & Technology Abstracts(LISTA)中没有找到其它类似的研究(仅包括英文文献)。国内研究中,在CNKI和维普数据库里也未能找到类似的研究。RDA相关文献中,仅刘丽静和陈瑞金[7]的研究是以RDA的内容、媒介、载体分类为主,他们对三种类别进行了概述性和实务性介绍。国内RDA相关的文献通常是从编目员的角度对RDA进行研究的。很少有研究人员的文献(比如高红和靖翠峥[8],林明[9])从元数据用户(读者和参考咨询馆员)的角度进行研究,而且均未采用定量的方法。
2 研究设计和研究问题
卡片分类法的目标是生成“以用户为中心的分类”[10]。自由列表法被用以发现特定知识领域的内容,范围和边界[11],但是在双语环境下采用自由列表法显得复杂、操作性不强。因此,本研究只采用卡片分类法。卡片分类法有开放式和封闭式两种。我们最初打算采用只有英文受控词汇的开放式卡片分类法,因为开放式卡片分类法能获取到更多的信息,并且是信息架构研究中更常用的设计[12],在RDA还没有官方中文译文的情况下,贸然引入受控词汇的中文翻译可能因译文措辞的随意性而引起结果的偏颇。我们进行了一次小规模的预先测试(开放式卡片分类,受控词汇以英语原文给出,在线进行)。有两位被试者参加了测试,且均具有英语口译的硕士学历。她们反馈说分类测试难度过大,且均未完成分类测试。因此我们对研究设计进行了较大的调整,以便测试能顺利完成。
调整后的研究采用问卷的形式。受控词语排列成一排,每个词语后面共四个选项,包括内容、媒介和载体这三个类别,以及一个词语难以理解、分类的选择。问卷要求被试者在每个词语后只勾选一个选项,这样调查问卷就和封闭式卡片分类非常类似了。
为了让被试者在分类前对内容、媒介和载体类别有一定的预备知识,问卷前面给出了内容、媒介和载体类别的示例。示例包括了书籍、网络视频流和音乐激光唱片这三种资源的内容、媒介和载体类别,以帮助其顺利完成问卷。示例中的受控词汇既给出了英语原文,同时也给出了非官方的中文译文。
问卷中共出现26个受控词汇,包括4个媒介类别词汇、12个载体类别词汇和10个内容类别词汇。选取受控词汇的方法是:媒介类别全选,内容类别只选奇数行,载体类别只选行数能被三整除的词汇。这是为了确保选取的词汇能较为全面地反映出RDA的这一分类设计,最终获得一份共26个受控词汇的列表。
根据受教育状况和回答问卷的版本,被试者分为三组。第1组为复旦大学的本科学生(非英语或图情专业);第2组为天津财经大学和西南政法大学的英语教师,或四川大学的英语系的硕士研究生;第3组为四川大学的本科学生(非英语或图情专业)。第1、2组回答版本A的问卷,其中待分类的受控词汇仅给出英语原文(但问卷前的示例包括中文译文)。问卷鼓励被试者使用工具书来尝试解决难以理解的词语,同时要求被试者对经过努力尝试后仍然难以理解或分类的词语不要勉强,而是在问卷上向我们反馈难以理解、分类这一情况(即勾选第4个选项)。第3组回答版本B的问卷,受控词汇同时给出英语原文和中文译文。问卷要求被试者依靠中文译文的帮助对原文的英语词汇进行分类。中文解释消除了被试因为欠缺语言技巧而在回答问卷时感到困难的情况。参照Tullis[13]的研究,每一组的样本数都大于15(第1组21人,第二组20人,第三组16人),这样既确保了研究结果可靠准确,又使得研究易于操作。
给出受控词汇中文译文的原则是尽量简洁,同英语原文结构尽量相似。中国国家图书馆出版社在准备RDA印刷版的中译本[14]。但是,除了该中译本即将出版的消息外[15],研究期间未能找到更进一步的相关信息。不过,在我国台湾的一家公共图书馆网站上,我们找到了一份RDA常用术语的翻译列表,这一术语列表旨在为台湾图书馆交流RDA时提供方便[16-17]。本研究的问卷中采用的受控词汇译文就是以此为基础的。考虑到中国大陆同中国台湾在语言习惯上的差异,我们的译文在台湾译文的基础上有所变动,以方便被试者理解。(比如”video”的译文从“录影”变更成了大陆地区更常用的“视频”)。同时,台湾译文中的繁体汉字均被调整成简化汉字。
研究的主要目标是测试RDA的这一分类能否被中国读者接纳。这是研究的第一个问题,即:RDA的内容、媒介和载体类别分类能否被中国读者接纳?
这一问题将通过分析问卷的分类结果进行解答。另一方面,如果RDA的分类能被中国元数据用户接纳,那么用户群体的分类结果与RDA中的分类越一致,就说明这一读者群体对RDA的分类理解得愈好。后面分析的数据证实了这一设想的可行性,于是我们使用计分方式(“一致性得分”)来衡量每份问卷中读者分类和RDA分类的一致性。
以英语原文形式呈现给被试者的受控词汇,在分类时可能因为其复杂的措辞而增大分错的机会。为了了解相对复杂的英文措辞是否影响英文版RDA在国内的可用性,同时考虑到第2组被试者的英语水准较高,第3组被试者在回答时有中文译文辅助,我们拟检验下列两个研究假设:
研究假设(Ha1):第2组的一致性得分平均数比第1组高。
研究假设(Ha2):第3组的一致性得分平均数比第1组高。
接受或拒接这两项研究假设,能帮助解释第二个研究问题:即RDA受控词汇复杂的英语措辞是否影响其对中国用户的可用性?
3 数据分析
问卷中的数据被编码并录入到Excel表格中,经转换,再使用SPSS来进行分析。
首先,剔除包含极端结果的问卷。如我们发现一份问卷中只有4个词语被归类,其余的词语全部被标识为难以理解、分类,与其他问卷的结果截然不同。该问卷的结果被剔除,后面的数据分析中均不包含该份问卷结果。
根据被试者使用的问卷版本,我们将其重新分组。A组使用版本A的问卷(无中文译文);B组使用版本B的问卷(含中文译文)。即A组相当于先前的第1、2组,B组相当于第3组。考虑到问卷形式和封闭式卡片分类的相似性,我们采用Tullis[18]提出的方法来处理和研究与问题1相关的统计。对每一个词汇,我们都分别计算出被试者归入内容、媒介和载体类别的比率。比率最高的那个类别,就是被试者最倾向于将该词汇归入的类别。然后,我们将这一用户分类结果同RDA的实际分类进行了比对。问卷上无受控词汇中文译文的A组,共4个词语的分类结果与RDA不一致(下文简称之为“误分类”),如表1所示。
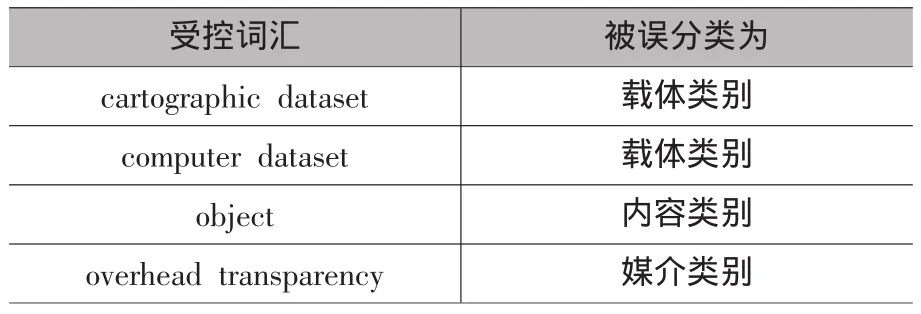
表1 A组中被误分类的受控词汇
通过计算被反映难以理解和分类词汇的比率,我们发现“microopaque”被反映难以理解和分类的比率比其被归入载体类别的比例还要高。尽管这一词语在内容、媒介和载体类别这三项中归入载体类别的比率最高,同RDA的实际分类一致,但是其被反映难以理解、分类的高比率,提示这一术语的措辞对中国用户相当生僻。“overhead transparency”被反映难以理解、分类的比率同其被错误归入媒介类别的比率刚好一样。B组也有4个词汇被误分类(如表2所示)。其中“microscopic”被误分类成内容类别的比率同其被反映难以理解、分类的比率刚好也一样。结果表明,A组和B组中,被试分类结果同RDA的实际分类不一致的词汇数量均为4个,一致的词汇数量为22个。
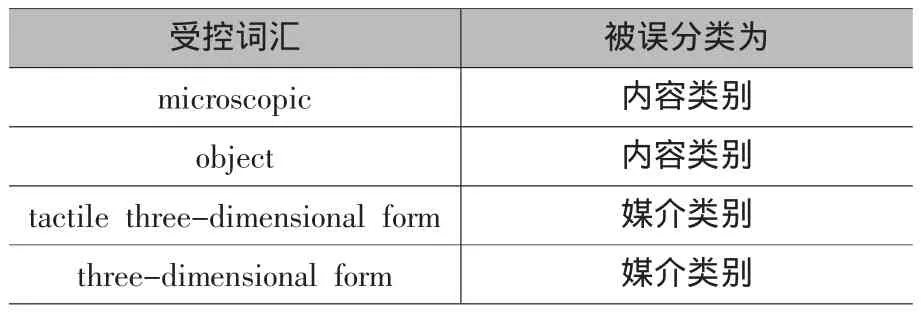
表2 B组中被误分类的受控词汇
现在,问卷分组又回到先前的第1组、第2组和第3组。对每个问卷而言,被试者每正确分类一个词汇,就记1分。也就是说,如果一份问卷上的词语分类同RDA完全一致,该问卷就记26分;反之,如果一份问卷得分越低,其同RDA分类的一致性,也就是相似程度就越低。使用SPSS计算每一组的平均得分,结果如表3所示;同时采用了K-S检验来测试每组的样本是否为正态分布,结果如表4所示。
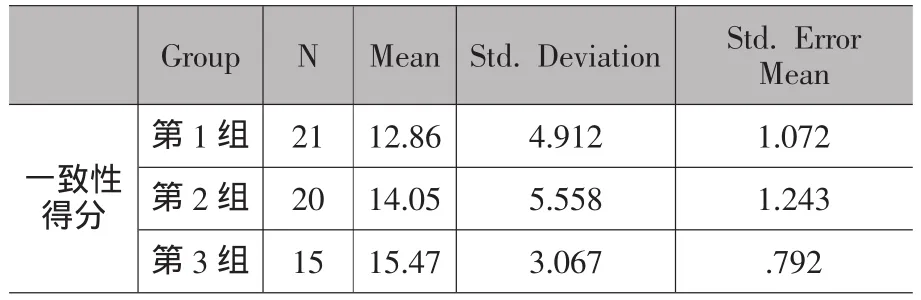
表3 每组一致性得分的统计信息
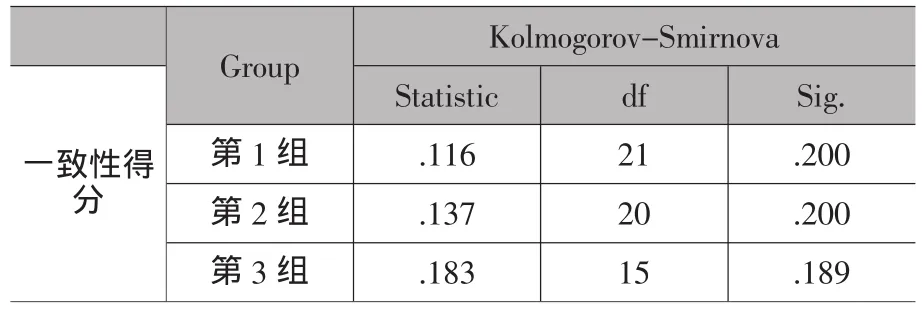
表4 正态分布检验
结果提示,第2组和第3组的算术平均数均高于第1组,同预期一致。第1组中的一致性得分,D (21)=0.12,p>0.05,第2组的一致性得分,D(20)=0. 14,p>0.05和第3组的一致性得分,D(15)=0.18,p>0. 05,均为正态分布。于是,我们执行了两次独立样本的t-检验,来比较第1组和第2组,以及第1组和第3组的得分。结果如表5和表6所示。
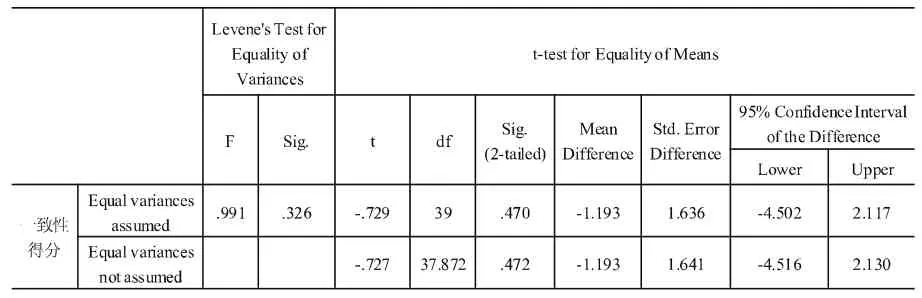
表5 独立样本t-检验(第1组和第2组)
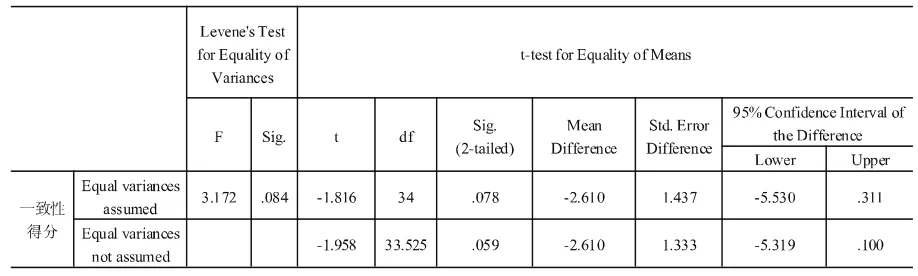
表6 独立样本t-检验(第1组和第3组)
结果表明,第2组的平均得分(M= 14.05,SE=1. 24)高于第1组(M=12.86,SE=1.07),但是该差异并不显著,t(39)=-0.73,p>0.05(1-tailed),r =0.12。第3组的平均得分(M=15.47,SE=0.79)高于第1组,此差异具有显著的统计意义,t(34)=-1.82,p<0.05(1-tailed),并且具有中等的效应量,r=0.30。
4 讨论和结论
数据分析显示,在A组和B组中,26个受控词汇分别仅有4个被误归类,表明在有设计合理的示例提示帮助下,参与研究的中国被试者的分类结果与RDA所预先规定的分类非常相似。这一结果证实了RDA分类设计的合理性,至少从本研究的结果来讲是如此。在A组中,被试者反映对“overhead transparency”和“microopaque”的理解、分类较为困难;以“dataset”结尾的两个词语均被误归类为载体类别,而不是RDA所规定的内容类别。但在B组中,“dataset”结尾的词语均被正确分类,相反,以“three-dimensional form”结尾的词语均被误分类,同时还有“microscopic”和“object”。在这一组中,“microscopic”还被反映难于理解、分类。
含“dataset”的词语在A组中的错误分类,以及其在B组中的相反结果可能是被试者错误理解英语单词“dataset”的结果,表示被试者缺乏对英文“dataset”的相关图式。这一猜测可能也适用于A组中的其他被误分类或被反映难以理解、分类的词语。B组中,所给出的“three-dimensional form”和“tactile three-dimensional form”这两个词汇的中文译文分别为“立体形式”和“触感立体形式”,“microscopic”所对应的译文为“显微”,它们被误分类或反映为难以分类、理解,可能是其中文译文的问题。这些译文从中国台湾的翻译中直接引用过来,未作调整,虽然较为准确地传递出了英语受控词汇原文的含义,但确实较为拗口。不过考虑到目前尚无更为贴切合适的中文译文,加之即便如此B组的分类结果同RDA的分类也相当一致,对RDA分类可用性的结果还是相当积极的。
两个独立样本的t-检验表明,应当拒绝研究假设Ha1,并接受研究假设Ha2。据此我们得出结论,更高的英语教育水平并未能带来更高的一致性得分,但提供中文译文对提高得分确有效果。
这些证据表明,RDA复杂的英语措辞确实给参加研究的中国被试者带来了困难。即便部分被试者接受过更好的英语教育,有些甚至就在从事英语教学工作,但这一优势并未对其理解RDA分类有明显的帮助。另一方面,只需简单地向被试者提供中文译文,而且译文中的一少部分还有些拗口,被试者回答问卷的结果就会有显著的区别。如果今后RDA要被应用到中文语言的编目中,这些受控词汇的中文译文就必不可少了。否则,以RDA英文受控词汇构成的目录,对于英语水平较低的用户将会有非常糟糕的体验。RDA如果要应用到国内的西文编目中,也应当考虑通过在联机目录中同时提供图标和英文受控词汇,或者将英文受控词汇进行调整等方式,以用户友好型的式样来呈现这一分类体系,方能满足用户的需求。
虽然我们目前从中国台湾的这份翻译和我们在研究中所采用的译文来看,要将RDA的这些受控词汇“完美”地用中文表达出来还不太可能。(“完美”是指既自然顺口,又容易理解的中文。)从翻译研究中Reiss的文本分类来看,这一翻译的原文本质上是“信息型”(informative),而非“表情型”(expressive)或“操作型”(operative)文本。因此,翻译这些受控词汇,应当主要寻求语义上的对等,而不是其美学上的或者是超语言的(extralinguistic,比如劝说性质的)效果[19],以达到让RDA的这些受控词汇真正为中国用户查找、识别、选择和获取资源服务,而不是得到形式优美但使用效果差的中文译文。
本研究的局限在于参加的被试者都是从高校中选取的教师和学生。这一设计为研究带来了很多便利,让研究过程更加易于操作和实施,但是我们的样本选择也由此有了偏颇。独立样本的t-检验这一部分,由于被试者的外语水平无法人为操纵,故采取了准实验(quasi-experiment)的手段,在研究中对被试者的外语水平这一变量实际上采用的是伪操纵(pseudo-manipulation)的方法。这一因素,使得我们得出“更高的英语教育水平并未能带来更高的一致性得分”这一结论的证据还不够确实。这些因素成为本研究的局限所在。故可以考虑采取具有更高信度和效度的方法,并在其他RDA可能成为未来元数据标准的地区进行进一步研究。
参考文献:
[1]Joint Steering Committee for Development of RDA. RDA:Resource Description & Access[S]. Chicago:American Library Association,2013.
[2]Paradis,Daniel. RDA:A Cataloguing Code for the Digital Age[EB/OL].[2014-01-07].http://spectrum.library. concordia.ca/7672/1/RDA% 2C_a_cataloguing_code_for _digital_age.pdf.
[3]Hart,Amy. The RDA Primer:A Guide for the Occasional Cataloger[M]. Santa Barbara,Calif.:Linworth,2010:45-48.
[4]国际图联书目记录的功能需求研究组.书目记录的功能需求:最终报告[EB/OL].王绍平,等,译.[2014-01-15].http://www.ifla.org/files/assets/cataloguing/frbr/frbr -zh.pdf.
[5]Hider,Philip. A comparison between the RDA taxonomies and end -user categorizations of content and carrier[J]. Cataloging & Classification Quarterly,2009,47:544-560.
[6]Hider,Philip. Library resource categories and their possible groupings[J].Australian Academic & Research Libraries,2009,40(2):105-115.
[7]刘丽静,陈瑞金.基于MARC21格式的RDA描述:以“内容、媒介、载体类型”为例[J].图书馆杂志,2014 (1):36-39.
[8]高红,靖翠峥.图书馆OPAC的FRBR实践及相关思考:来自RDA标准的启示[J].国家图书馆学刊,2011(2):21-27.
[9]林明.目录的语言/文字和规范检索点:试读《国际编目原则声明》和RDA的语言/文字原则[J].大学图书馆学报,2012(3):74-79.
[10]Sauro,Jeff. 10 Things to Know about Card Sorting [EB/OL].[2014-01-15].http://www.measuringusability. com/blog/card-sorting.php.
[11]Sinha,Rashmi. Beyond card sorting:Free-listing Methods to Explore User Categorizations[EB/OL].[2014-01-16].http://boxesandarrows.com/beyond -cardsorting -free-listing-methods-to-explore-user-categorizations/.
[12]Spencer,Donna. Card Sorting:Designing Usable Categories[M]. New York:Rosenfeld Media,2009:82.
[13]Tullis,Tom,Larry Wood. How many users are enough for a card-sorting study?[Z]. Proceedings of the Usability Professionals Association Conference,Jun. 7-11(2004).
[14]“RDA in Translation-Chinese”[EB/OL].[2014-04-12]. http://www.rdatoolkit.org/translation/Chinese.
[15]RDA中文版即将出版[J].中国图书馆学报,2014,40 (1):109.
[16]RDA重要中文词条用语[EB/OL].[2014-04-12].http://catweb.ncl.edu.tw/portal_d7_cnt.php?button_num=d7 &folder_id=28.
[17]RDA媒体类型(Media type)、载体类型(Carrier type)、内容类型(Content type)词条中译[EB/OL].[2014-04-12].http://catweb.ncl.edu.tw/userfiles/1392859825. pdf.
[18]Tullis,Thomas S. Using Closed Card -Sorting to Evaluate Information Architectures[EB/OL].[2014-04-14].http://www.eastonmass.net/tullis/presentations/ClosedCardSorting.pdf.
[19]Hatim,Basil,Jeremy Munday. Translation:An Advanced Resource Book [M]. London:Routledge,2004:281-286.
凡迪四川省图书馆助理馆员。四川成都,610016。
周茜四川省图书馆副研究馆员。四川成都,610016。
收稿日期:(2014-05-23编校:方玮)
猜你喜欢
大众投资指南(2021年14期)2021-12-01
现代交际(2021年15期)2021-11-25
卷宗(2018年14期)2018-06-29
读与写·下旬刊(2018年3期)2018-06-04
现代职业教育·职业培训(2018年1期)2018-05-14
科学中国人(2017年21期)2017-07-14
科技视界(2016年25期)2016-03-10
黑龙江史志(2015年13期)2015-12-07
办公室业务(2015年1期)2015-12-03
办公室业务(2015年23期)2015-11-26
