
Apriori改进算法在哮喘病案数据挖掘中的应用
2015-12-28 07:35朱习军陈亚楠董国华
徐州工程学院学报(自然科学版) 2015年3期
朱习军,陈亚楠,董国华
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
Apriori改进算法在哮喘病案数据挖掘中的应用
朱习军,陈亚楠,董国华
(青岛科技大学 信息科学技术学院,山东 青岛266061)
摘要:中医哮喘病案含有大量医家临床诊断获得的经验数据,利用数据关联分析方法可以挖掘医药方剂配伍规律及症状与用药之间的关联关系.文章主要研究了Apriori算法在挖掘医案数据时的性能与不足,并基于计算机对位串逻辑运算的快速反应,提出Apriori算法的改进算法——Apriori-BSO算法,并对比了两种算法的运行时效,结合经典Apriori算法,挖掘出频繁项集及强关联规则.实验证明,将Apriori改进算法应用于哮喘用药数据及症状-用药联合数据进行关联分析,挖掘出的医药方剂配伍规律及症状与用药之间的关联关系,在哮喘病案数据分析中效果良好,应用价值显著.
关键词:关联分析;Apriori算法;哮喘;串逻辑运算
现实世界中事物之间通常存在相互依赖或相互关联的关系,在已经知道某事物的情况下,与其有关联或依赖关系的事物就可以推断出来,表述事物之间这种关联关系或依赖关系的规则被称为关联规则[1].目前关联规则在不同的领域都有着重要的应用,通过多维关联规则的研究,分析不同月份、不同地区、不同部门及其他因素对债务与收益的影响,是关联规则在金融领域的重要应用;在零售业中,利用关联分析对顾客需求、产品销售、以及产品的趋势与时尚,挖掘规则进而合理搭配、摆放商品,实现利润最大化;对电信业进行关联分析,可以帮助掌握商业动向,识别出是哪种电信模式,捕捉一些盗用行为,从而能更有效地使用现有资源,使服务的质量得以提升.中医哮喘病案[2]含有大量医家临床诊断获得的经验数据,采用关联分析的方法能将这些数据以知识的形式表述出来,这对中医数据客观化、医家经验传承及医疗研究都有重要的作用[3].本文通过流程图及实例分析了经典Apriori算法,并提出一种基于位逻辑运算的Apriori算法的改进算法,即Apriori-BSO算法,将改进算法用于哮喘病案数据的关联分析中,挖掘出了哮喘诊治中的有价值的数据规则.
1关联规则基本概念
定义A为一个由项组成的集合,称之为项集.若项集A中含有k个项,那么就称其为k项集.统计项集A在事务数据库D中出现的次数和事务数据库D中总事务的个数,用出现次数除以总事务数,即为项集的支持度.如果项集的支持度大于事先设定的阈值,就称该项集为频繁项集.
关联规则表示事物间的关联关系,可用类似X⟹Y的式子来表示,该式中X⊂I,Y⊂I并且X∩Y=φ,I为D中所有项的集合.若X∪Y在事务数据库D中所占的百分比为s%,那么就称关联规则X⟹Y的支持度是s%,事实上,支持度就是概率值.如果项集X的支持度表示为support(X),规则的置信度就用support(X∪Y)/support(X)来表示,实际上置信度就是一个条件概率P(Y/X),支持度与置信度按公式(1)、(2) 计算.
support(X⟹Y)=P(X∪Y),
(1)
confidence(X⟹Y)=P(Y|X),
(2)
也就是说,事物之间的关系如果满足了事先设定的置信度以及支持度,就称之为关联规则.
2Apriori及其改进算法
2.1 Apriori算法基本思想及性能分析
Apriori算法主要是发现频繁项集的过程,事务中所含频繁项集仅占一小部分,为避免计算所有项集的支持度而产生大量的计算,在Apriori算法中,用已知频繁项集生成长度更长的项集,并将其称为候选频繁项集,通过筛选候选频繁项集得到频繁项集.生成频繁项集的过程可依据以下性质:频繁项集的子集必为频繁项集.Apriori算法的步骤如下[5].
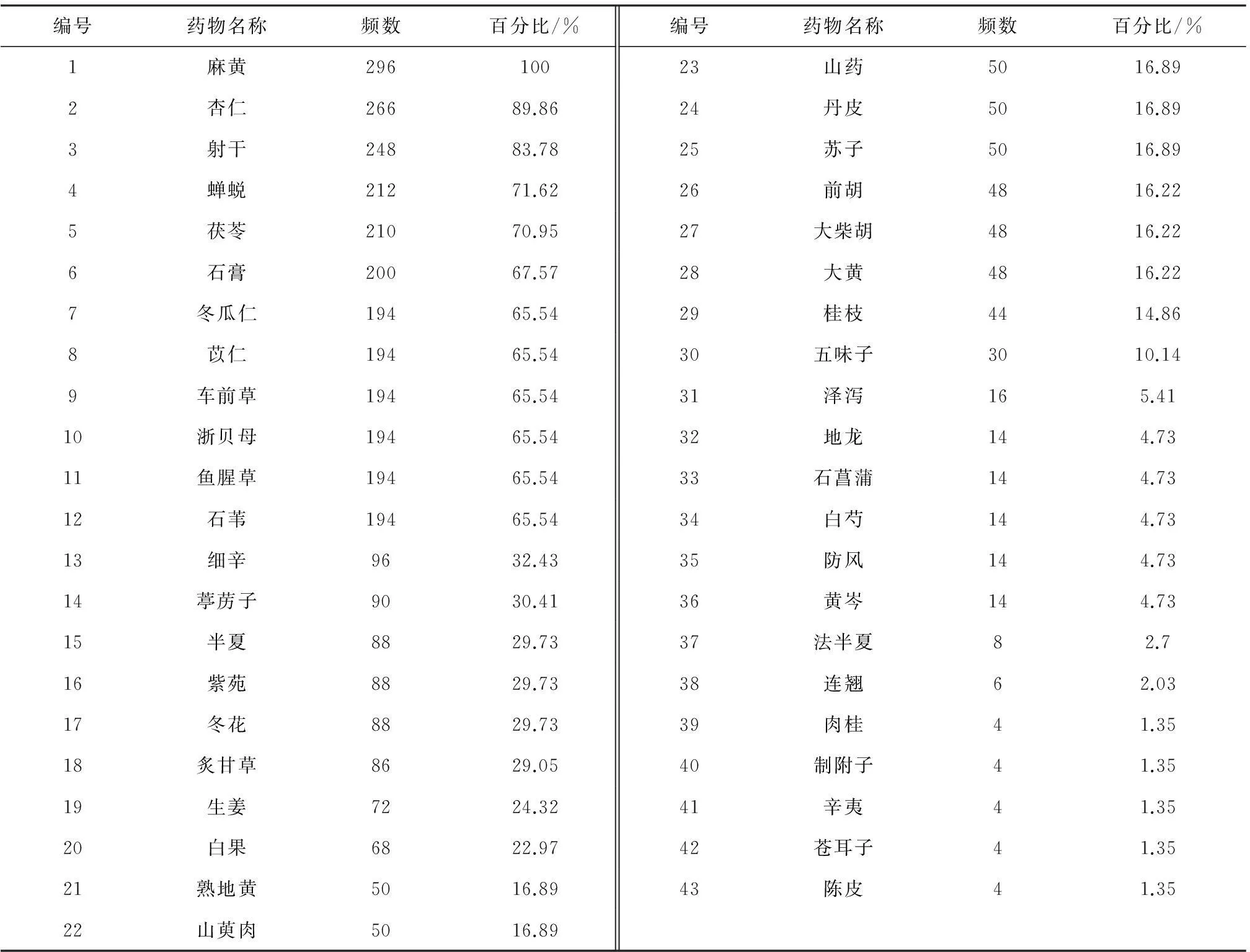
1)扫描一次数据库D,统计每个一项集的支持度计数(一个项集的支持度计数是指该项集在数据库中出现的次数),将满足最小支持度阈值的一项集加入频繁一项集L1.
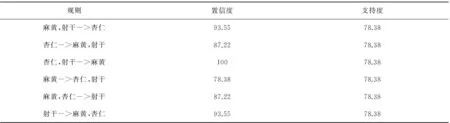
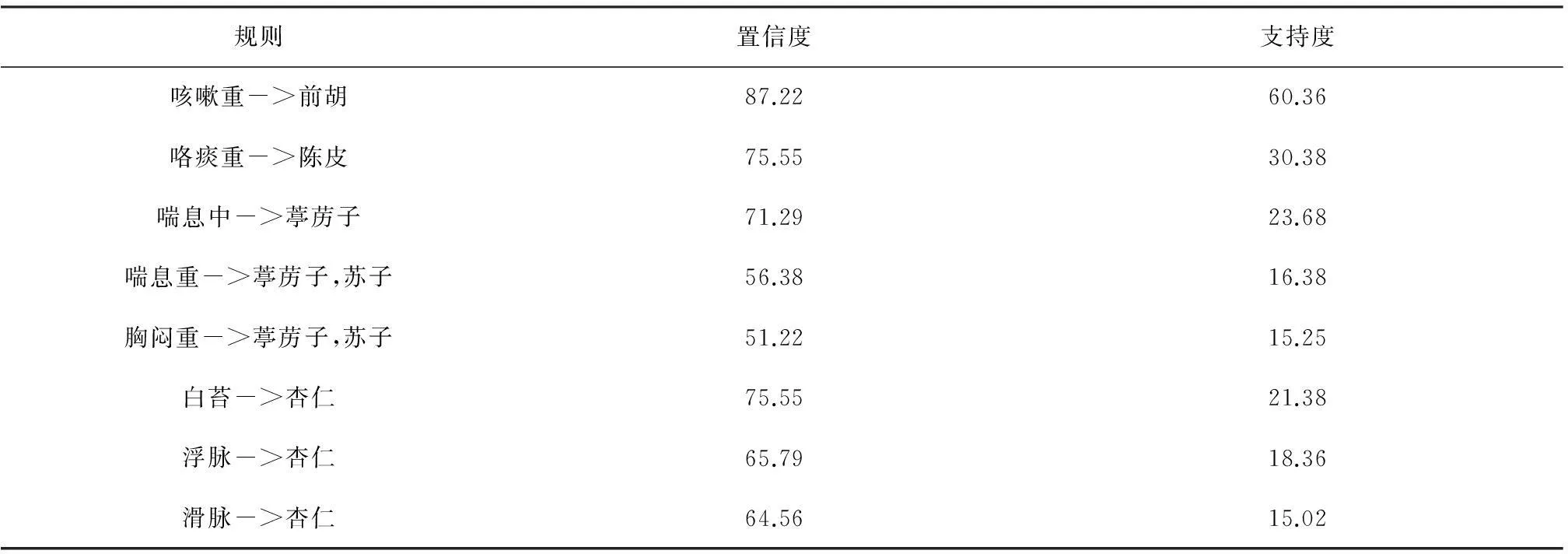
2)连接步.由频繁(k-1)项集Lk-1中的项进行连接操作生成候选k项集,这就是连接步,即JOIN运算,具体运算情况如下:若p,q∈Lk-1,p={p1,p2,…,pk-2,pk-1},q={q1,q2,…,qk-2,qk-1},并且当1≤i 3)剪枝步.Ck中的项集并不都是是频繁的,而候选频繁项集太大会给算法运行带来很大的计算开销,因此有必要对其进行删减,此时应遵循以下原则:若(k-1)项集不频繁,那么包含它的k项集必定不是频繁k项集,所以,当候选k项集有不在Lk-1中的(k-1)项集,那么这个候选k项集不是频繁的,应该把它从Ck中移去. 4)扫描一次数据库D,计算Ck中各个项集的支持度. 5)通过对比支持度阈值,删除候选k项集Ck中小于支持度阈值的项集,其余项集组成频繁k项集的集合Lk. 循环运行步骤2)~5),一直到不能再生成新的频繁项集集合为止.由以上步骤可以看出,Apriori算法能够生成所有满足最小支持度阈值的频繁项集. 图1 Apriori算法流程图 根据前述Apriori算法的步骤,设计算法运行流程,见图1. 由以上算法的运行过程可以看出,Apriori算法存在时间消耗方面的局限性,一是由候选项集产生频繁项集过程对海量数据库的多趟扫描;二是用JOIN步产生候选项集时k-1频繁项集与k-1频繁项集的连接需要保证其k-2项是相同的且k-1项不同,这也增加了算法的计算量,而且连接步产生的候选项集也会很多,并随着频繁1项集的增多而不断增多,比如说如果频繁1项集有5个,那么候选2项集就有10个,如果频繁1项集有1000个,那么候选2项集就有个,如果频繁1项集有10 000个,得到的候选2项集就会有个,多达107个,这个计算量是非常大的. 针对Apriori算法可能会多趟扫描数据库与产生大量候选项集方面的问题,基于位串的逻辑运算对其进行改进,将该改进算法记为Apriori-BSO算法. 基于位串逻辑操作的改进Apriori算法主要是针对计算机对位串的快速反应,利用数学中“位”的概念[7],把事物数据库D中的每个事物I用一个位串来表示.根据“位”的逻辑运算找出项集的支持度计数,结合经典Apriori算法,挖掘出频繁项集及强关联规则.整个算法步骤如下. 1)设定支持度与置信度阈值. 2)扫描数据库,依次对事务库中的每个项在事务中出现与否用“1”,“0”表示,若出现则记为“1”,未出现记为“0”,从而将事务库中的每个项在各个事务中的出现表示为一组位串.统计每个项对应的位串中“1”的个数,即为该项的支持度计数.选取支持度计数大于阈值的候选项作为频繁1项集L1中的项. 图2 Apriori-BSO算法流程图 3)根据L1生成项序列S,S={L1中项位串的集合}.对每个项编码,生成编码位串:编码长度为事物库所含单项的个数,如果某个单项在生成的项集的项中出现,相应项序列位置记为“1”,否则为“0”. 4)对Lk-1进行连接操作.对Lk-1中的项编码位串依次进行逻辑“或”操作,并统计结果位串中所含“1”的个数,若为k,将加入候选k项集Ck. 5)对生成Ck中的项对应的Lk-1的项位串进行逻辑“与”操作,最终得到的结果为Ck中对应项的项位串,项位串中“1”的个数,即为该候选项的支持度计数,将支持度计数大于阈值的候选项作为频繁k项集Lk中的项.重复以上步骤,直到对Lk所含单项个数小于(k+1),停止算法. 算法运行流程如图2所示. 该算法用到的性质如下. 性质1:频繁k项集的子集也必定是频繁的. 性质2: 频繁k项集中单项的个数少于(k+1)则生不成频繁(k+1)项集. 在相同条件下,使用java语言,采用UCI上提供的大型数据集进行测试,Apriori-BSO算法对比经典Apriori算法,其运行处理数据的时间对比结果如图3所示. 图3 Apriori-BSO算法与经典Apriori算法运行时间比较 结果证明,随着处理数据记录条数的增加,改进算法比经典算法的运行时间大幅减少. 3Apriori-BSO算法在医药数据挖掘中的应用 本文中所用到的哮喘医案数据,主要来自青岛海慈医疗集团中医呼吸科临床数据,如图4所示.其中共有哮喘医案296例. 图4 青岛海慈医院中医呼吸科临床数据 中医医案数据因其特殊性,存在不少问题和困惑,如病、证、症、证名等概念模糊,证型诊断标准不规范,对某证特异性指标的刻意追求,辨证分型不统一等.目前中医学界证名纷杂、各证之间界限不清,出现一证多名、同证异名、以病为证、以证为病的现象.因此,在研究中医医案数据之前,应首先规范医案数据. 文中利用的数据挖掘方法主要是通过关联规则方法寻找中医哮喘诊治过程中中药方剂的配伍规律及症状-用药规律,因此,涉及到的数据有中药数据、症状数据,本文首先将中药名字统一化,如中药“浙贝母”,有的中医师习惯书写简称“浙贝”,统一为“浙贝母”.将中药名称规范后,把中医呼吸科中出现的中药从1开始编号.通过数据库中条件语句查询,对出现在296例哮喘病案数据中的中药编号并统计,结果如表1所示. 表1 哮喘病案中的中药编号及统计数据 根据海慈医院的哮喘症状分级量化方案,将哮喘的普通症状分级量化,并对其编号,如表2所示. 表2 哮喘普通症状编号表 四诊方面的症状主要涉及到舌象与脉象及大鱼际掌纹阴阳性.对哮喘病案中出现的舌象信息进行分类编号,如表3所示. 表3 舌象编号表 根据哮喘病案中出现的脉象信息对其分类编号,如表4所示. 表4 脉象编号表 大鱼际掌纹阴阳性用p表示,p0表示“阴”,p2表示“阳”. 将改进算法用于中医哮喘医药数据挖掘,把支持度阈值设为35%,置信度阈值设为75%.用Apriori-BSO算法对规范后的中药数据进行处理,发现的频繁项集及关联规则如图4所示. 图4 频繁项集及关联规则结果图 根据图1中对应的中药编号结合图4中的处理结果,得到从中医哮喘医药数据中挖掘到的关联规则及其对应的置信度与支持度,见表5. 表5 中医哮喘医药数据关联关系 % 从表5中可以得到如下结论:麻黄、杏仁、射干具有强相关性,而且通过咨询专家发现这个组合药对也是中医临床上常用来治哮喘的组合之一,该结论是有价值的. 设定支持度为15%,置信度为50%,用Apriori-BSO算法对哮喘用药与症状的关联关系进行挖掘,发现的关联规则如表6所示. 表6 中医哮喘用药与症状关联关系 % 从表6中可以得到以下结论:陈皮对咯痰症状有缓解作用,前胡对咳嗽症状有缓解作用,葶苈子、白果配对组合对喘息有缓解作用,葶苈子、苏子配对组合对喘息和胸闷都有缓解作用,葶苈子对喘息有缓解作用,杏仁对舌象呈白苔,脉象为浮脉或滑脉都有改善作用,通过与专家沟通也发现,上述发现是有价值的. 4结语 本文通过分析经典Apriori算法的性能与不足,基于计算机对位串逻辑运算的快速反应,提出Apriori算法的改进算法,并在相同条件下对比了两种算法的运行时效;将采集到的哮喘医案数据规范化并采用改进Apriori算法对哮喘用药数据及症状-用药联合数据进行关联分析,挖掘出了哮喘医药方剂配伍规律及症状与用药之间的关联关系,经与专家沟通,证实了挖掘出的规则是有价值的. 参考文献: [1] 黄穗,刘剑.一个牙科电子病历系统的设计与实现[J].计算机工程,2004,30(4):167-169. [2] 赵霞,汪受传,韩新民,等.小儿哮喘中医诊疗指南[J].中医儿科杂志,2008,4(3):4-6. [3] 朱文峰.中医诊断学[M].北京:人民卫生出版社,1999. [4] 郑舞,刘国萍.常见数据挖掘方法在中医诊断领域的应用概况[J].中国中医药信息杂志,2013,20(4):103-107. [5] 李雄飞,李军.数据挖掘与知识发现[M].北京:高等敎育出版社,2003. [6] Brauckhoff D,Dimitropoulos X,Wagner A,et al.Anomalyextraction in backbone networks using association rules[J].IEEE/ACM Transactions on Networking(TON),2012,20(6):1788-1799. [7] 王伟.关联规则中的Apriori 算法的研究与改进[D].青岛:中国海洋大学,2012. [8] 李成.智能数据挖掘与知识发现[M].西安:西安电子科技大学出版社,2006. [9] 董国华,朱习军.中医肺病科电子病历系统设计与实现[J].软件,2014,35(3):17-19. [10] Qian Y,Liang J,Song P,et al.Evaluation of the decision performance of the decision rule set from an ordered decision table[J].Knowledge-based Systems,2012,36:39-50. (编辑武峰) 中图分类号:TP311;R203 文献标志码:A 文章编号:1674-358X(2015)03-0008-07 收稿日期:2015-07-10 基金项目:国家自然科学基金项目(51375427);江苏省自然科学基金项目(BK20131232);江苏省产学研联合创新资金项目(BY2014117-08) 作者简介:曾励(1957-),男,四川威远人,教授,博士,硕士生导师,主要从事磁悬浮及控制、无轴承电动机、抽油机螺杆泵技术等研究. The Application of Improved Apriori Algorithm in Axthma Cases Data Mining ZHU Xijun,CHEN Yanan,DONG Guohua (College of Information Science and Technology, Qingdao University of Science and Technology, Qingdao 266061,China) Abstract:TCM asthma case contains a lot of empirical data obtained by physicians in clinical diagnosis,using data correlation analysis methods to mine the rule of medicine prescription compatibility and the incidence relation between symptoms and medication.The article analyzes and studies the performance and disadvantages of Apriori algorithm by examples, and proposes an improved Apriori algorithm called Apriori-BSO algorithm based on the fast response of computer's logic operations in bit strings. Combined with the classic Apriori algorithm,it then compares the running aging of the two algorithms to mine the frequent item sets and strong association rules.The experiments showed that the improved Apriori algorithm is valuable in the data analysis of asthma cases when it is applied to the correlation analysis of asthma medication data and the symptoms-medication data in mining the rule of medicine prescription compatibility and the incidence relation between symptoms and medication. Key words:correlation analysis; Apriori algorithms; asthma; bit strings operation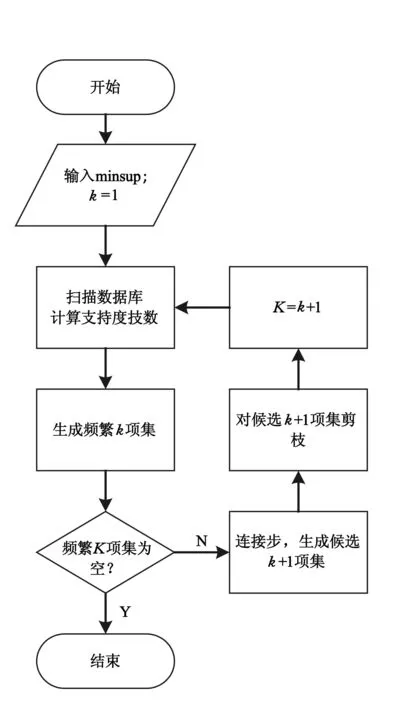
2.2 改进Apriori算法


3.1 中医数据采集与规范




3.2 哮喘医案数据挖掘

猜你喜欢
保健医苑(2022年1期)2022-08-30
中老年保健(2021年6期)2021-08-24
计算机应用(2016年12期)2017-01-13
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
中国市场(2016年36期)2016-10-19
科技视界(2016年15期)2016-06-30
电脑知识与技术(2016年4期)2016-04-11
