
图书馆科研热点发掘服务模型研究与设计
——以应用经济学为例
2015-12-26 05:04罗琰钦
图书馆论坛 2015年12期
罗琰钦
图书馆科研热点发掘服务模型研究与设计
——以应用经济学为例
罗琰钦
科研热点发掘是图书馆工作内容之一。在经济学研究过程中发现,学术文献发表周期长、外部资源零散等问题长期阻碍着科研工作的开展。为此,文章以应用经济学为研究范例,提出基于图书馆内外网信息融合的科研热点发掘服务模型,给出该模型的问题解决方案、体系结构以及运作流程。该模型结合馆藏信息资源与学术网站信息进行热点发掘。测试证明,在应用经济学领域,该模型能较为准确、及时和全面地提供热点发掘服务。
图书馆服务 热点发掘 网络信息 应用经济学
0 引言
科研热点通常由某一学科中最能代表学科发展趋势,并能影响当前学科发展的关键性科学难点、重点及相应的学说构成[1-2]。图书馆信息服务模式正在从面向馆藏资源的普惠信息服务向面向读者的个性化信息服务转变[3]。从应用经济学研究看,鉴于其研究范围广、资料多、信息需求大等特点,针对应用经济学的图书馆科研热点发掘工作主要从三方面为读者提供服务:(1)查新求证,避免重复研究,即判断科研主题(通常是读者正在研究或感兴趣的内容)是否属于本学科前沿,是否具有研究价值和研究可行性;(2)查漏补缺,扩展读者的研究思路,即为读者提供其关注科研主题关联度高的热点资源,如关键词、学者、文献;(3)启迪引路,指导领航,即为科研新手提供学科梳理和指导,使其对要进行的研究工作有全面清晰的认识,能尽快切入研究热点[4-5]。尽管相关服务流程与工具(如Cite Space)已得到了较广泛的应用,但在应用经济学研究和教学过程中,上述方法与工具暴露出一系列问题:(1)Cite Space等工具操作较复杂,知识图谱的应用也需要较多的前期经验与较深厚的学科背景,并不适合科研新手和非计算机专业人员。(2)上述服务流程需要较多人工干预,自动化程度不高,生成结果受主观因素影响大。以四川大学应用经济学《学科前沿》课程为例,该学科涵盖内容广,6组博士研究生独立发掘出的科研热点的评分(百分制)标准差高达28.3。(3)上述服务对各学科的相关资源应用率低,时效性差。针对这些问题,本文分析其成因,提出解决方案,以应用经济学为例,构建基于内外网信息融合的图书馆科研热点发掘服务模型(Scientific Research Focus Mining,SRFM)。
1 体系结构与运作流程
1.1 模型结构
SRFM模型的体系结构与模块见图1。
(1)外部科研热点跟踪模块。该模块的设计依据是“八二原理”,即网络中80%的信息源自20%的网站。基于该原理,该模块能采用网页发掘方法(网络机器人)对应用经济学所属的认可度较高的教科研网站进行数据采集,从中发现与科研热点相关的学者、专业词汇、链接等信息。在实际应用中,结合应用经济学实际情况,SRFM模型对47个学术网站进行全文抓取,处理后仅占用352M存储空间,体现了较好的模型可用性。对部分难以直接通过网络机器人抓取的网站,采用反向检索技术,通过向全文搜索引擎提交指定站点搜索项的请求,获取搜索引擎中的缓存数据(如Baidu Cache和Google网页快照),从中采集这些科研网站中的突发词、膨胀词等信息。此外,一方面通过频繁更新,提高科研热点发现的及时性,另一方面通过相关链接的扩展搜索,提高热点发现的全面性。由于系统的存储容量有限,同时为避免重复搜索,该模块设定的发掘深度为3层:从初始网站开始,至多进行2层相关链接的发掘。
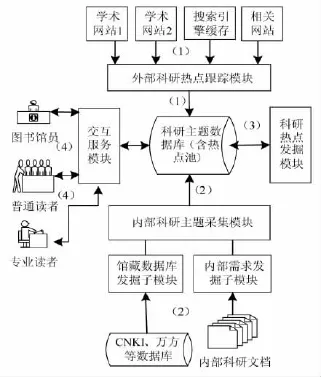
图1 模型体系结构与处理流程
(2)内部科研主题采集模块。该模块分为两个子模块,第一个子模块基于图书馆购买的文献数据库构建,它结合外部发掘模块提供的基础信息,依据数据库提供的树型学科分类结构开展内部科研主题的全面提取,主要发掘算法参见下文;第二个子模块基于校内对应的学术群体构建,以提高服务的针对性和实用性,它能够在网络空闲时间自动调用网络机器人程序对校内学术群体进行深度发掘,对学术群体发布的相关文档和网页进行数据采集与分析,并通过Poi文档解析工具(支持doc/pdf/ppt等常用科研文献格式)和共词分析技术,发现其中的科研主题需求等信息,为内外挖掘提供更为精准的依据。
(3)科研热点发掘模块。基于内外科研信息采集模块收集到的相关信息,构建对应的科研主题数据库,并基于该数据库开展三类发掘:①以时间为驱动,定期(周/月)发掘主题数据库,并更新应用经济学的“热点池”。针对应用经济学的实际情况,SRFM模型为每个二级学科设定一定容量的热点池。②以读者特定的精确需求为依据,对某下属学科进行及时发掘。由于新算法和热点池的构建,SRFM模型针对应用经济学下属二级学科的发掘时间能够在15分钟内完成。③以交叉学科热点为目标,以热点池为初始发掘点,以外部学术搜索引擎(百度学术和Google Scholar)为搜索工具,以近似关键词和链接为搜索对象开展搜索。
(4)交互服务模块。针对应用经济学研究人员的计算机操作水平参差不齐,平均水平低于图书馆员的现状,该模块分为两个子模块:第一个为专业管理服务子模块,由图书馆员操控,通过对读者进行热点发掘操作辅导,明细化发掘目标,再提交给发掘模型进行处理;第二个为普通查询服务子模块,该子模块根据科研主题数据库中高排名的热点信息,绘制树状(森林)图谱,每一个节点代表一个科研主题,节点间连线代表从属或学科交叉关系。有关交互服务模块的设计将在2.3节中阐述。
1.2 发掘与处理流程
基于上述结构与处理模块,SRFM模型的热点发掘与处理流程见图1。
(1)图书馆内外的科研热点数据采集,主要包括科研信息的内部主题和外部热点两部分。其中,外部科研热点跟踪主要采取定时遍历的方式,以网络机器人程序为采集工具,将指定网站的最新网页下载到本地服务器,并从中抽取突发词(最新出现词)和膨胀词(最近高频词);内部科研主题采集模块的两个子模块则分别对CNKI等学术数据库和馆内读者需求进行主题抽取与分析,一方面从馆内信息源中发掘近期的读者关注热点,从而提高热点发掘的针对性,另一方面对馆外发掘出的科研热点予以验证,从而判断其是否新颖,关注度是否较高,从实践来看,这一判断过程减少了外部模块的信息处理量。
(2)对采集的科研主题/热点进行清洗处理。在此过程中,科研热点发掘模块将结合内外部科研主题/热点数据,对内部发掘到的科研主题实施清洗,初步抽取近期的相关学科突发词和膨胀词,将这些含有关键词、学者、从属关系等内容的信息保存在科研主题数据库中,以节省后续处理所需的系统资源。
(3)科研热点发掘。内外部发掘得到的科研主题数据存储在科研主题数据库中,由于各网站及文献数据中的热点数据极多(以技术经济学为例,近3年科研热点数量超过55个,涉及关键词1457个),如果要进行完整的突发词关联检测,将会非常困难。因此SRFM模型构建高速发掘算法,通过树状结构的热点发掘窗口进行数据扫描,将发掘到的热点存储在热点池中。
(4)科研热点综合服务。图书馆员根据读者的不同需求与实际信息技术水平提供两类服务:当读者初涉相关领域,对学科发展缺乏足够了解时,图书馆员细化其需求,从分析中得到读者需求的所属学科、近似关键词与所需热点的内容、时限、关联主题等信息,并以上述分析内容为依据,在科研主题数据库的热点池中检索匹配程度最高的热点;当读者对某领域较为熟悉时,可通过科研主题数据库支持的树状图谱,直接进入所需发掘的子学科进行内容浏览,如果其中缺少相关内容,读者可提供缺失内容对应的关键词,通过科研热点发掘模块,驱动内外热点采集模块进行更深入的发掘[6]。
2 关键算法与模块
2.1 热点存储结构
为节约系统开销,SRFM模型采用较为精炼的树状存储结构来进行科研热点相关信息的存储,即根据二级学科划分将采集到的科研信息分类成主题树。以学科作为分类标准的科研主题树具有以下特征:第一,其根节点是某个科研主题的核心,可以是学者名或者专业关键词;第二,下属的每个叶子节点将存储与核心词相关的内容,包括主题ID、专业关键词、权重、相关学者名、词性、内容摘要、检索词频、上下关系指针,其定义构造过程如下:首先进行参量配置,主题的核心词权重为常量1;其次非根节点的权重由它在整个数据库中出现的总次数计算得到(具体计算方法见下文);再次通过构建停止条件集合,构建终端的叶子节点,由于实验采用的是CNKI等以中文为主的数据库,因此条件集中包括以下词汇:“完成”“结束”“综述”“截止”“为止”等,当叶子节点关联的文献中出现停止词时,相关主题词的权重将减少(陈旧或终结的主题词)。上述所构建的科研主题树存储了从数据库和外网挖掘到的所有科研主题,且遍历发掘所有的主题树(即从主题根节点开始,计算相关分支上的权重和,并进行分支权重排序)。这个过程可以用下列迭代算法进行表述,最终通过较为完整的树形结构展示相关的科研主题。
2.2 科研热点发掘算法
SRFM模型的遍历发掘核心算法步骤如下:假设科研话题集合是一个包含n个主题树的森林图谱X,算法总体目标是将n棵树型主题xi(i=1,2,…,n)划分为c个类,进行科研热度排序,构建每个类的聚类中心(热点池)。SRFM模型依据模糊数学理论,对每一个已发掘的科研主题,通过设定/计算其在[0,1]区间的隶属度来判断它在各个类的归属程度。此外,为保证交叉学科研究热点的公平性和可计算性,硬性设定一个归一化要求,即任意一个主题的所有隶属度之和必须等于1,由此有下式:

其中,本模型使用的权重函数如式2:
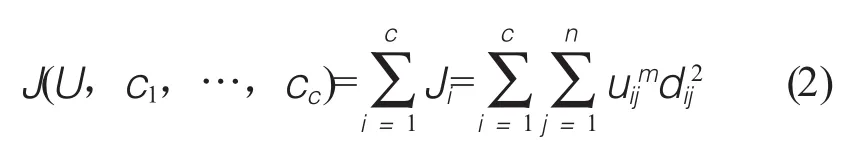
上式中的uij在[0,1]区间中取值,而ci为模糊分类i的热点池;其中dij=||ci-xi||是第i个热点池与第j个主题之间的欧几里得空间距离,而m∈1,∞)则是加权参量。
基于上述数据结构,本模型依托FCM(Fuzzy Clustering Means)方法确定实际的计算步骤,其中使用的内存变量为热点池ci和隶属度矩阵U:
第一步,确定热点池的数量c(2≤c<N),本模型的实验针对应用经济学展开,因此热点池设定为74个(即二级学科数量)。
第二步,设定初始化的模糊分类矩阵。模糊分类矩阵以U(s)表示,设定s=0,即U(0),开始计算。
第三步,处理U(S)时的基础数据Vi(s),其中有:
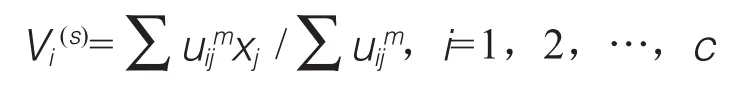
第四步,通过2个子步骤将U(S)处理成U(S+1)(j=1~N).
首先,处理Ij和:
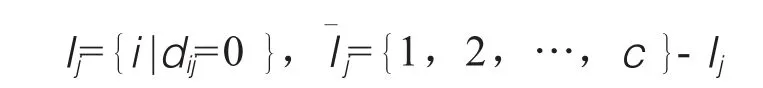
其次,处理主题xj的新隶属度uij,表示如下:
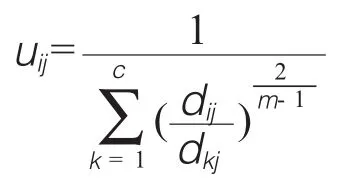
uij=0,,同时设定
第五步,通过阈值控制U(S)和U(S+1)之间的距离,当||U(S)-U(S+1)||<ε分类停止;反之,则有s=s+1,算法将返回第三步继续循环[7-10]。
2.3 交互服务模块设计
交互服务模块是SRFM模型中的重点,包括专业管理服务和普通查询服务两个子模块,实现难点是专业管理服务子模块的设计。为满足科研查新求证、查漏补缺以及启迪引路三类需求,同时为学科专家(专业读者)和科研新手(普通读者)提供个性化服务,该模块采用图2所示结构和服务流程。
第一步,当读者需要进行科学热点发掘时,图书馆员为其提供指导,协助读者确定发掘需求与依据(可以是若干科研主题词、学者姓名,甚至可以是一段摘要或一个文档)。例如,读者需要对互联网金融进行发掘时,图书馆员可将其发掘依据扩展为<互联网金融,大数据,移动支付,谢平>。
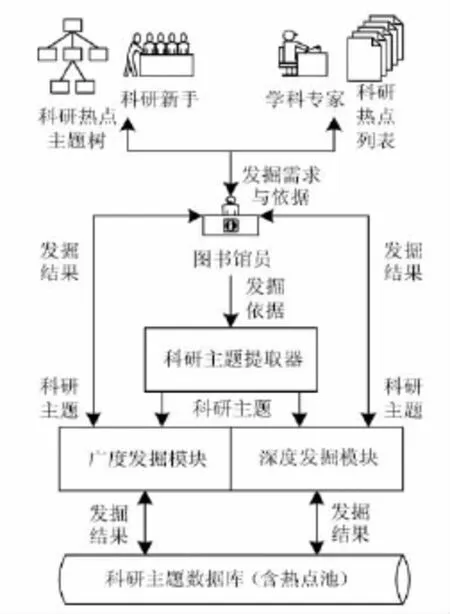
图2 交互服务结构与流程
第二步,图书馆员将指导读者从发掘依据中提取科研主题(主要是关键词),并为其发掘进行学科粗划分,再交由模块中的科研主题提取器(基于自动分词工具)进行自动提取。
第三步,图书馆员依据读者的不同类型(学科专家或科研新手)选择不同的发掘器,对科研主题树进行匹配发掘。其中学科专家提供的发掘依据通常描述较为精准,分类较为清晰,因此采用深度发掘器,最终发掘到的结果也较为深入,主题匹配度很高;而科研新手提供的发掘依据通常较宽泛,分类较模糊,因此采用广度发掘器,最终发掘到的结果较全面完整。
第四步,图书馆员在发掘器完成工作后,将结果以不同形式展示给读者:对学科专家,主要以科研热点列表形式提供文字信息和链接;而对科研新手,主要以科研热点主题树的形式,提供可视化信息[11]。
3 实验结果与分析
3.1 实验对象
为全面测试SRFM模型的性能,基础数据设定为应用经济学相关的174925篇CSSCI核心期刊论文,分别对表1所示6类应用经济学下属二级学科进行测试。为保证测试的公平和可信,测试中调用两台相同配置的联想万全服务器进行并行测试。详细测试项见表1。与之对应,外网信息源包括经济学院学术委员会指定的47个网站和150个其他相关网站,如中国世界经济学会、中国技术经济学会。由于科研热点发掘结果的最终认定存在较多主观因素,测试中对读者群体进行主观问卷调查,被调查的群体包括教师103名,其中副高职以上为75名;经济学相关专业研究生353名,其中博士研究生95名。
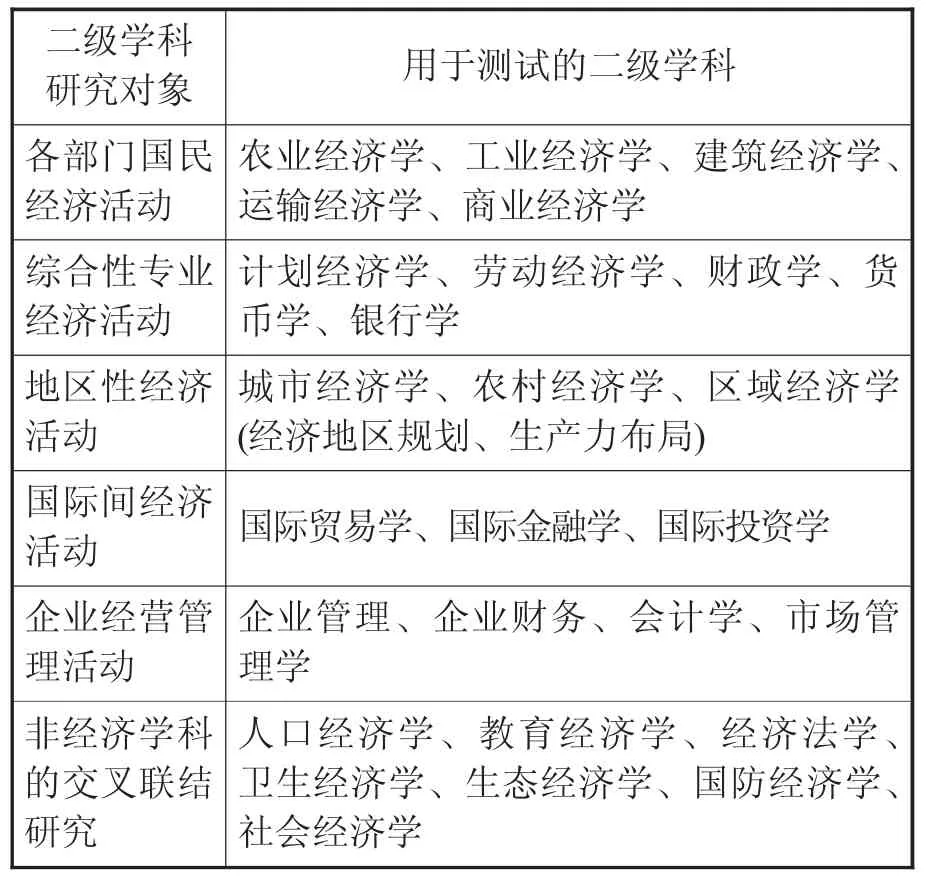
表1 应用经济学发掘对象
3.2 科研热点发掘实验结果
最终调查结果见表2。图3为两类模型对应用经济学热点的动态发掘覆盖度。该覆盖度的定义为:在一定时间段内,模型发掘出的并被读者群体认可的科研热点,在所有读者群体实际关注热点中的数量比例变化情况。由图3可知,由于充分利用内外网的信息资源,SRFM模型在静态和动态情境中均表现出较高的热点发掘准确率和查全率。
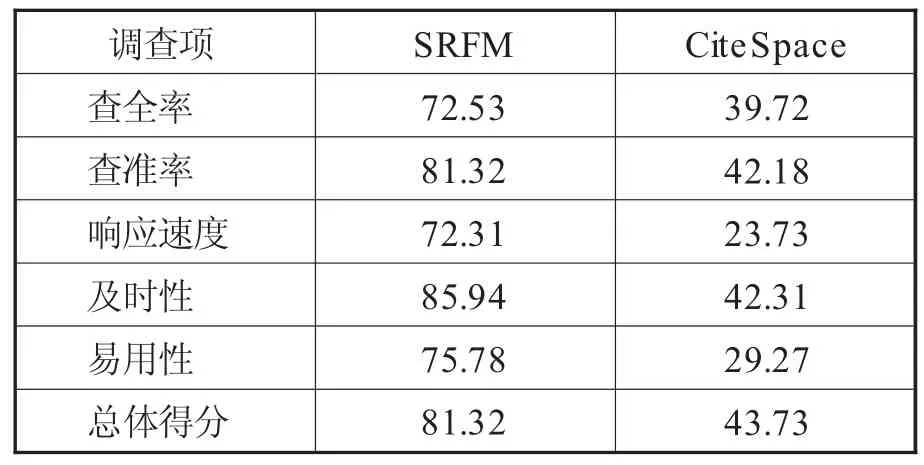
表2 模型发掘性能的主观满意度对比
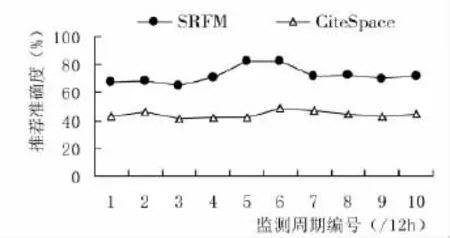
图3 动态发掘精确度对比
3.3 服务效能实验
为测试本模型的服务效能,以《应用经济学专题》课程为背景,以其中的4个专题(从16个专题中随机抽取)为实验对象,将46名硕士研究生分为两组,对两种模型进行平行实验,2名任课教师与2名图书馆员同时对实验进行跟踪指导和结果评判。最终的实验结果见表3。由表3可知,SRFM模型的服务效能较高,能在检索词较少、平均检索次数较少、教师/馆员指导次数较少的情况下,取得质量较高、较全面的科研热点发掘结果。从读者角度看,该模型方便易用,无需读者掌握特殊的工具和技巧;从图书馆员角度看,该模型能将图书馆服务与科研工作无缝衔接,提供高质量的科研热点服务,降低馆员的工作强度。
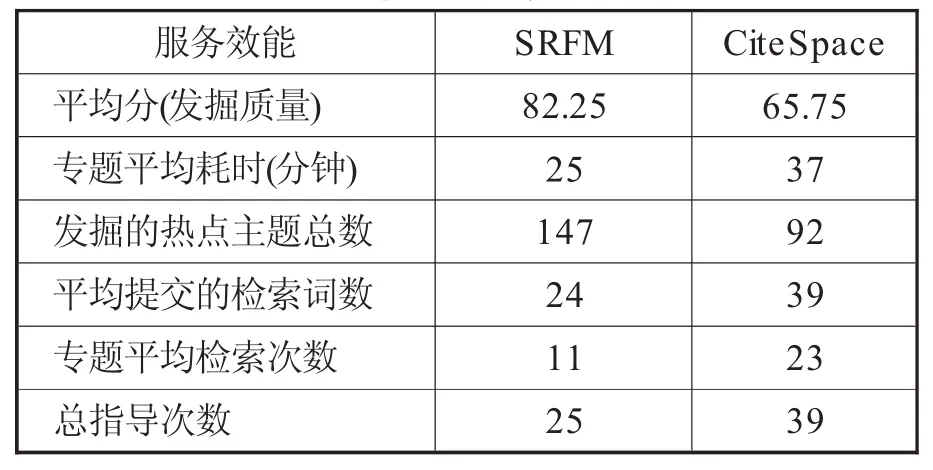
表3 模型服务效能对比
4 结语
本文以应用经济学为研究对象,提出图书馆科研热点发掘服务的SRFM模型和实现框架。较之操作专业化的基于Cite Space工具的模型,SRFM模型地自动化程度较高、更新速度快,能较全面的发掘应用经济学中的科研热点,为应用经济学研究提供信息支持。未来工作中,将进一步推广SRFM模型的应用至其他领域,并引入更为高效快捷的算法来实现海量数据发掘。此外,该模型在实际应用中对目前界定较为含混的交叉学科(如应用经济学的部分二级学科)的发掘性能还有待提高,将在后续工作中进一步研究。
[1]程燕锋.广东高校科技查新工作的现状分析与对策研究[J].图书馆论坛,2013(3):90-96.
[2]洪凌子,黄国彬,于洋.基于CiteSpace的国内外数字图书馆研究论文的比较分析[J].图书馆论坛,2011(6):91-100.
[3]盛宇.基于微博的学科热点发现、追踪与分析——以数据挖掘领域为例[J].图书情报工作,2012,56(8):32-37.
[4]徐灿,陈晨.基于CiteSpace的学科领域研究热点与前沿可视化分析——以无线传感器网络领域为例[J].信息资源管理学报,2012(4):69-75,87.
[5]汪东伟,李梅,殷沈琴,等.基于动态数据的经济学领域研究热点分析[J].图书馆杂志,2014(12):24-31.
[6]刘丽.基于信息可视化的国际图书馆服务领域前沿演进分析[J].图书馆论坛,2012(3):6-12.
[7]张伟聪.教育部科技查新工作站调查与分析[J].图书馆论坛,2014(5):36-40.
[8]覃丽金,吉家凡,唐朝胜,等.主题式学科化服务模式研究——结合海南大学图书馆的案例分析[J].图书馆论坛,2014(4):23-29.
[9]卫军朝,蔚海燕.基于CiteSpaceII的数字图书馆研究热点分析[J].图书馆杂志,2011(4):70-78.
[10]张云,曾莉,李文林,等.基于聚类分析的图书馆联盟热点分析[J].图书馆学研究,2013(6):2-7,20.
[11]张艺蔓,李秀霞,韩牧哲.基于共词分析的图书馆学科服务研究热点分析[J].情报探索,2015(4):126-130.
Research and Design of Scientific Research Focus Mining Service Model in Libraries——A Case of Applied Economics
LUO Yan-qin
Scientific research focus mining is an important point of library researches.The long publication cycle of sci-tech periodicals and the disparity of exterior network scientific information make the related works difficult. With a case of applied economics,a scientific research focus mining model was presented based on library interior/exterior information fusion.Then the solutions,architectures and working flows of the model are proposed as following.And the model fused the scientific sites and the library information resources to deal the problems above.Test results prove that the model can provide correspondingly exact,real-time and comprehensive scientific research focus mining services in applied economics fields.
library service;focus mining;information fusion;applied economics
格式 罗琰钦.图书馆科研热点发掘服务模型研究与设计——以应用经济学为例[J].图书馆论坛,2015(12):56-61.
罗琰钦(1983-),四川大学经济学院博士研究生。
2015-06-02
猜你喜欢
社会科学战线(2022年8期)2022-10-25
加油站服务指南(2022年6期)2022-07-28
宁波大学学报(理工版)(2022年4期)2022-07-08
华北理工大学学报(自然科学版)(2021年3期)2021-07-03
小猕猴智力画刊(2020年12期)2021-01-07
车迷(2019年10期)2019-06-24
英语文摘(2019年11期)2019-05-21
快乐语文(2018年7期)2018-05-25
军事文摘·科学少年(2017年4期)2017-06-20
中央社会主义学院学报(2016年2期)2016-05-04
