
网络论坛类媒体舆情热点主动发现的方法
2015-12-25 01:11马国富
重庆科技学院学报(社会科学版) 2015年3期
马国富
随着互联网的普及应用,以BBS、博客(Blog)和微博客(MicroBlog)为代表的互联网论坛类媒体,已经成为社会民众公开发表、交流观点最为主要的信息平台。2011年10月13日,国家互联网信息办公室组织召开 “积极运用微博客服务社会经验交流会”,一批政府机构、大型企业的代表和有关专家学者在会上介绍了使用微博客的经验。会议肯定了境内50余家微博客网站的积极作用,希望党政机关和党政领导干部“以更加开放自信的态度”开设微博客、用好微博客。2012年,微博继续升温,成为社会舆论的发动机。据2013年1月15日中国互联网络信息中心(CNNIC)发布的第31次《中国互联网络发展状况统计报告》,截至2012年12月底,我国的网民规模已达5.64亿,其中微博用户规模为3.09亿,占网民总数的54.7%;手机微博用户规模为2.02亿,占所有微博用户的65.6%。我国互联网普及率42.1%,低于英美日韩等国家(均在70%以上),但我国的网络舆论场却绝对是世界上规模最大的,舆论强度也是在全世界无以匹敌的[1]。
目前,我国的网络反腐呈现专业化、常态化的趋势,同时也有娱乐化的特点。政府公信力面临“塔西佗陷阱”的挑战。“网络问政”正在从应急管理向制度建设延伸。因此,对互联网论坛类媒体舆情热点实行主动发现策略,为政府相关部门的决策提供支持,已显得非常重要而紧迫。
一、关于网络舆情
网络舆情,是由于各种事件的刺激而产生的通过互联网传播的人们对于该事件的所有认知、态度、情感和行为倾向的集合[2]。网络作为第四媒体已成为社会舆情的主要载体之一,网络舆情也必然会成为政府管理的一部分。从政府管理角度而言,总是希望能够充分了解非常规事件所涉及的各个因素之间的牵制、互动关系,从而在分析预判某一决策可能产生的综合效果的基础上,及时、果断、有效地作出新的正确的决策。
美国社会心理学家奥尔波特和波斯特曼提出了一个关于谣言的公式,即:R=I×A。其中,R(Rumor)即“谣传”;I(Important)为“重要性”;A(Ambiguous)为“含糊性”。一件事之所以引起谣言,说明它有一定的重要性和含糊性。事件本身的重要性加上初期信息的不确定性,极易让谣言得到传播。克服谣言,最有效的办法是通过权威的、即时的信息发布渠道及时公布真相,也就是排除“含糊性”,让“A”值为“0”。要做到这一点,首先必须及时发现舆情热点,然后综合分析,揭示真相;或者据此作出正确的决策,引导舆情。
二、舆情热点的主动发现模型
主动发现论坛类媒体舆情热点的过程,包含媒体信息采集、信息热点发现与热点表达呈现三个环节。信息采集环节采集的舆情信息为结构化的存储信息,包含信息采集时间、网络地址、主体发表内容。媒体舆情热点主动发现模型如图1所示。

图1 论坛类媒体舆情热点主动发现模型
论坛类媒体数量庞大,根据访问方式,可分为可匿名身份浏览和身份认证访问两类;根据发布形态,可分为静态发布与动态发布两类。静态发布页面的主体内容及其内部所含超链接网络地址,分别以文本信息和统一资源标识符(URL)的方式直接嵌入页面源文件的HTML标记(Tag)中。通过使用HTML标记识别的方法[3],可以实现静态页面主体内容与其所含超链接网络地址的提取,完成对其发布内容的递归采集工作。动态发布页面中除了少量静态URL,还含有大量须通过浏览器执行脚本才能解析得到的超链接网络地址和网页主体内容,因此,无法使用HTML标记识别的方法对动态发布信息实现递归获取。针对不同类型的论坛媒体信息,需要采取不同的信息获取方法,以实现对媒体发布内容的采集(如表1所示)。

表1 不同类型论坛媒体的信息获取方法
(一)信息采集
1.身份认证过程模拟
目前,大部分静态网页可通过匿名身份访问,而大部分论坛类媒体需要身份认证才能访问。为此,建立网络身份认证交互过程模拟实现方案,以实现对身份认证论坛发布信息的获取。
论坛类媒体主要是通过网页上的认证表单来实现客户端身份认证。因此,可以通过JSSh客户端向内嵌JSSh服务器的Firefox浏览器发送JavaScript指令[4],让浏览器自动填写网页上的身份认证表单,然后进行提交请求。整个身份认证过程完全模拟用户与论坛的要求进行。身份认证之后,JSSh客户端利用JSSh服务器加载身份认证与论坛发布信息,通过JavaScript指令操作,提取论坛URL信息和主体内容。
2.动态网页解析
通过身份认证后,便可进行网页识别了。静态网页,使用HTML语言和URL标识识别。动态网页,需要浏览器执行脚本才能解析超链接地址和网页主体内容。目前,动态网页主要是利用VBScript、JavaScript、PHP等脚本语言和动态网页技术(ASP.NET)来实现。文献[5-7]对论坛、博客等媒体信息的获取进行了研究,但没有涉及脚本解析问题。采用浏览器模拟技术实现对动态网页内容获取,主要由客户端通过脚本指令指示内嵌脚本服务器的网络浏览器加载动态网页主体内容,通过脚本解析引擎进行动态脚本解析。然后,浏览器通过网页整合引擎生成静态网页的HTML DOM树,最后导出静态网页及其发布内容。在此基础上,递归获取脚本片段所含超链接指向的网络资源、提取动态页面主体内容(见图2)。
(二)信息热点的主动发现
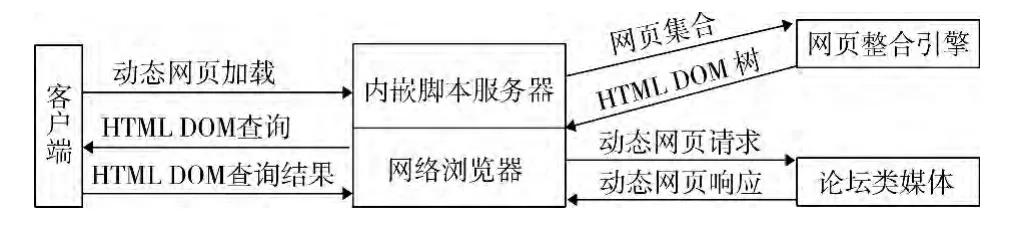
图2 动态网页信息的获取过程
互联网论坛类媒体发布信息具有离散特性,形态多样,分布不平衡,跨类别交叉,主题信息不全,甚至没有主题信息。因此,在信息热点发现环节,要使用适合于高离散性信息理解与融合的词法/句法分析方法、离散语义特征表达方法以及离散信息主题聚类方法。论坛类媒体发布信息类似于自然语言处理领域的对话(Dialog),不同的是后者的内容集中于同一篇文档中,而前者的内容是分散的,时间、地点都有所不同;共同的难题是远程指代与主题矛盾。由于论坛类媒体信息的离散性,在对其进行信息分析前,还需要实现离散语义复原。鉴于此,提出基于离散信息主题聚类的论坛类媒体舆情热点主动发现方法,主要包含论坛类媒体发布信息跟踪与语义复原,面向离散信息的自动分词、句法分析、特征表达和主题聚类等(见图3)。每个舆情热点强度,由聚合所得各个类别的信息总量予以体现。

图3 舆情热点主动发现方法
信息热点发现环节接收信息采集环节对不同论坛媒体发布信息的存储结果,主要对其中发布信息主体内容进行自动分词、句法分析、离散语义特征表达以及离散信息主题聚类。
(三)信息热点的表达呈现
在信息热点表达呈现环节,针对异构的互联网媒体发布内容,采取异构信息归一化存储,同时对主题信息及内容进行快照。归一化存储的信息主要包括:发帖时间、发帖作者、URL、发帖标题、发帖内容、跟帖时间、跟帖作者、跟帖内容等关键信息。通过对信息进行元数据统一定义,实现单一与组合选型“与、或”等逻辑操作,从而为深入获取全面的热点内容服务。
[1]祝华新.未来十年的网络舆论场[J].网络传播,2014(5).
[2]曾润喜.网络舆情信息资源共享研究[J].情报杂志,2009(8).
[3]常红要,朱征宇,陈烨,等.基于HTML标记用途分析的网页正文提取技术[J].计算机工程与设计,2010(24).
[4]李翔,李生红,刘功申,等.信息内容安全管理及应用[M].北京:机械工业出版社,2010:7.
[5]潘冰,徐亮亮.中文博客搜索引擎研究[J].计算机工程与设计,2010(8).
[6]彭冬,蔡皖东.面向Web论坛的网络信息获取技术及系统实现[J].计算机工程与科学,2011(1).
[7]刘佐达,张久岭,陈茂科,等.一种面向BBS信息检索的主题网络爬虫算法[J].郑州大学学报(理学版),2010(2).
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
成都信息工程大学学报(2021年6期)2021-02-12
车迷(2019年10期)2019-06-24
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
快乐语文(2018年7期)2018-05-25
电子制作(2017年2期)2017-05-17
消费电子(2016年12期)2017-01-19
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
