
基于词序统计组合的中文文本关键词提取技术
2015-12-23 01:02:56苏祥坤吾守尔斯拉木买买提依明哈斯木
计算机工程与设计 2015年6期
苏祥坤,吾守尔·斯拉木,买买提依明·哈斯木,2
(1.新疆大学 信息科学与工程学院 新疆多语种信息技术实验室,新疆 乌鲁木齐830046;2.和田师范专科学校 计算机科学系,新疆 和田848000)
0 引 言
文本挖掘是数据挖掘领域的一个重要表现,关键词提取则是文本挖掘的重要手段和文本主题的体现,帮助用户从繁重的文本信息选取工作中解脱出来。单文本关键词提取是指针对单一的文本进行主要信息的提取工作,关键词是为了文献标引工作而从报告、论文中选取出来以表示全文主题内容信息款目的单词和术语。然而当前人们每天使用的大多数互联网网页中并没有提供其关键词的标引。这使得人们在浏览网页时,凭借网页标题和检索结果很容易忽略一些对自己需求有价值的信息。本文针对此问题提出了一种基于词序统计组合关键词提取方法。本文通过统计词序,组合生成组合词,以此选取包括词性特征、词序特征、位置特征、词频特征、词长特征、词跨度特征、TFIDF等在内的多种特征进行综合评定候选关键词的权重大小。该方法能够高效提取表征文本主要信息的关键词,其准确率可达到70%以上,方便普通用户和各领域、专业人员的使用。另外,由于日益增加的新词、分词系统的错误划分,可能将这些新词进行拆分并偏离原意。对一些高频的未登录的新词,本文提出的方法在一定程度上具有很大的反馈作用。
1 相关工作
目前,国内外各学者已经对关键词提取进行了大量的研究和实验。较常用的关键词提取方法大致可以分为基于语义的方法、基于统计的方法和基于机器学习的方法三大类。
常用的基于语义的方法多是建立在分析词语词义,继而构造语义有向图等。如:方俊等[1]提出的基于语义的关键词提取算法,通过消歧算法得到候选词,继而提取出关键词。谢凤宏等[2]提出的基于加权复杂网络的文本关键词提取,通过构建复杂的语义网络拓扑图来进行关键词的权重计算,并继而提取出关键词。胡学钢等[3]提出的基于词汇链的关键词提取方法。此外还有张颖颖等[4]提出的基于同义词的方法等等。
常用的统计方法多以TFIDF算法为基础进行关键词权重计算并进行关键词提取实验的。如张建娥[5]提出的基于TFIDF 和词语关联度的中文关键词提取方法2、李静月[6]提出的对TFIDF 公式进行改进的网页关键词提取方法等等。
而常用的机器学习方法则是建立在大量的语料库基础上,并进行大量的参数训练,多用SVM 模型和贝叶斯模型等进行关键词的计算和提取。如:罗准辰[7]设计的基于分离模型的中文关键词提取算法,对单独的关键词提取和串提取有不错的效果;王锦波[8]等提出的基于朴素贝叶斯模型的中文关键词提取方法等。
2 本文方法
本文采用的是已有的中科院分词系统进行分词和词性标注。在分词的过程中,人工调整程序,每一个分词和词性标注后的词语进行词语在文章中的词序的统计。本文实验是以网页单文本为语料实验对象进行实验的,所以本文初步对文本进行预处理之后,再进行分词切词、词性标注、词序统计、停用词过滤、组合词生成、词频统计、二次过滤、权重计算、子串过滤和提取关键词等步骤。其系统框架流程如图1所示。

图1 系统框架流程
2.1 文本预处理
通过阅读及研究发现,文本的标题和首句往往对文本主旨有很大的标引作用,所以预处理阶段主要是提取文本的标题和首句。其文本标题和正文的规律,具体可参见文献 [9]。
对于文本首句的提取,在研究断句的时候,发现从标点符号的用法上可以进行首句的提取。中文文本中,标志句子的标点有句号、问号、叹号、省略号等。所以只要在句末找到这类符号,就可以裁定、提取出相应句子。
2.2 组合词生成
研究发现,现有分词系统并不能全面的、完整的考虑到文本中的词的关系,所以有些可以作为关键词的词组往往被拆分成单个的词,而有时候词组比单个词更具有作为文章关键词的作用来反映文章主旨。如计算机领域里的“数据挖掘”这个词组,分词之后会拆分成 “数据”和 “挖掘”,而单独的 “数据”和 “挖掘”并没有 “数据挖掘”一词更能表达文章意思、主旨。
类似的词语有很多,它们大多在文中被拆分的时候词频较大且左右相邻,拆分后其词与其它词语搭配很少或不搭配。所以本文利用其在文中的词序位置和词性关系对其进行了组合。在很大程度上避免了类似过滤缺点的发生。其中词性的组合规则本文参照了张红鹰[9]提出的词性组合规则。有的研究人员采用构建有向图[10]的方法进行组合词的生成,但这样无疑是增加了计算量和实现难度。还有先计算权重后进行组合的方法[9],但这样容易在过滤和计算权重阶段造成权重的计算偏差,继而造成组合的偏差。还有罗准辰[7]基于分离模型的提取词串的方法,具有很高的准确率,但需运用大型统计词典,这在处理大型批量数据计算量方面稍显局限。
综合分析后,根据主客观需要,本文设计了如下算法,描述如下:
输入:待提取关键词的文本T,需提取的关键词个数m
输出:提取的m 个文本关键词或词组
步骤1 对原始文本进行预处理,包括分词切词、词性标注、词序统计及停用词过滤;
步骤2 对步骤2得到的结果进行词语和词组的词频统计,过滤掉词频大小=1的词语;
步骤3 逐个词语扫描,对步骤2得到的结果进行词语组合:前者词语A 和后者词语B 词序之差=1且符合合并规则的进行相邻合并,设置新组合词的词序为后者词语B的词序值,并记录被覆盖的词语;组合词作为正常词语进行新的组合并标记出新的词性,直到所有词语扫描完毕;
步骤4 过滤组合词词长<2或组合词词长>6的词语,剩下的词语作为候选词语;
步骤5 对候选词语计算权重并降序排列候选词,进行子串过滤,输出排列前m 个权值较大的词语作为最终关键词。
2.3 二次过滤
通过研究发现,可作为一篇文章的关键词的词语在文章中出现的频率往往在1词以上,所以那些只出现一次的词语就可以排除作为关键词的可能而进行过滤。
另外,可作为关键词的词长一般最多包含6 个汉字,所以词长大于6个词的就同样可以排除作为关键词的可能而进行过滤。另外,作为关键词的词语多是名词、动词、名词类词组或动词类词组,所以其它词性的词语或词组如:虚词、介词、助词等,同样也可以排除作为关键词的可能而进行过滤。
经过两次过滤之后,剩下的词语作为候选词进行权重计算,其准确率大大提高,时间和空间都会得到大大的改善。
2.4 权重计算
如果处理的是同一领域的文本,那么TFIDF会把那些在各个文本中都出现的高频词或关键词给过滤掉。如:处理属于科技类的一系列文本,由于 “信息检索”可能出现在所有文本中,所以当计算log(n/DF(x))时,结果会为0,因此可能会过滤掉这样的重要关键词。而单独的只考虑其它特征又会容易忽略某一词在不同文本的区分性和单文本的代表性。
所以本文同时采取TFIDF 和其它特征进行综合加权,计算候选关键词的权重,并以此来提取关键词。
2.4.1 词频加权
词频是一个词语在文章中出现的总次数。研究发现,如果一个词语在文章中出现的频率越高,说明这个词语对文章主旨反映的贡献也就越大,所以本文对词语词频的加权计算公式是
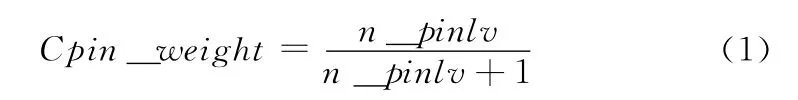
式中:Cpin_weight——词频的权重,n_pinlv——该词在文章中出现的总次数。Cpin_weight随着词频的增加而逐渐上升,且逐渐向1收敛。也就是说词语出现的频率越高,该词作为关键词的可能性也就越大。但增长又非线性的,即便词频过高,也会基本趋于稳定,更符合实际权重计算的需要。
2.4.2 词性加权
研究发现,对于一篇文章而言,反映文本主旨的,可以作为关键词的多是名词类和动词类的词语等等。所以词语Ci词性的权重公式如下所示

2.4.3 标题、首句和首末段加权
研究发现,一篇文章的标题的命名好坏、准确与否直接影响了文章的主旨反映和读者的兴趣。更有甚者,一篇文章的标题往往是一篇文章主旨的浓缩,甚至是核心内容,所以出现在文章标题里的词语也往往对与关键词提取具有重要的贡献。
文章首句则常是文章话题、主题或是文章所要议论的引发、提示,所以首句中的词语对关键词的提取贡献也同样不容忽视。
另外,一篇文章的第一段往往是全文的初步概括,承载着全文的主旨,所以对出现在第一段中的词也需要增设权重。末段往往是对全文的概括和总结,所以也纳入了考虑范围。
出现在其它段的词不再额外增设权重值。其各权重设置见表1。

表1 权重设置
2.4.4 词长加权
研究发现,一个词语的长度越长,则包含的信息量也就越丰富,更加能起到表达文章主旨的作用,成为关键词的可能性也就越大。其计算公式如下所示
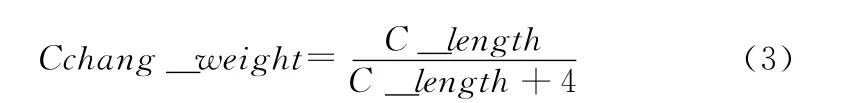
式中:Cchang_weight——词长的权重,C_length 是词的长度。
2.4.5 词跨度加权
研究发现,词语在正文中首次出现和末次出现的跨度越大,则词在贯穿全文和表达文章主旨的作用上也就越重要,可以在一定程度上做为关键词提取的考虑因素。计算公式如下所示
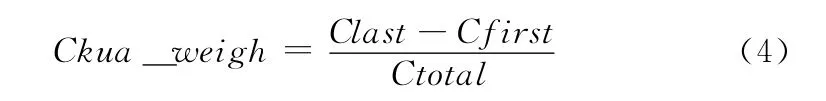
式中:Ckua_weight——词跨度的权重,Clast——词最后出现在文章中的词序,Cfirst——词首次出现在文章中的词序,Ctotal——文章中的最后一个词的词序。
2.4.6 TFIDF权重计算
TFIDF是一种常用的经典的统计方法,词语X 在文本P中出现的频率越高,同时在其它文本中出现的频率越低,则X 对P的贡献也就越大,其公式为TFIDF=TF*IDF,其中,TF表示词频 (term frequency),IDF 表示逆向文件频率 (inverse document frequency)TF 表示词条在文本中出现的频率。
但如果关键词在所有文本中都出现,log(n/DF(x))=0。那么只用TFIDF 方法是提取不出来该词的。如果采用依据词库的方法进行提取,其词库的建立完善与否直接关系到提取的准确性,而且需要大量的比较和计算,这在进行大数据操作时具有很大的局限性,所以本文只把TFIDF作为一个重要加权特征进行考虑。
2.4.7 最终权重计算
综合以上分析,最终权重计算公式为
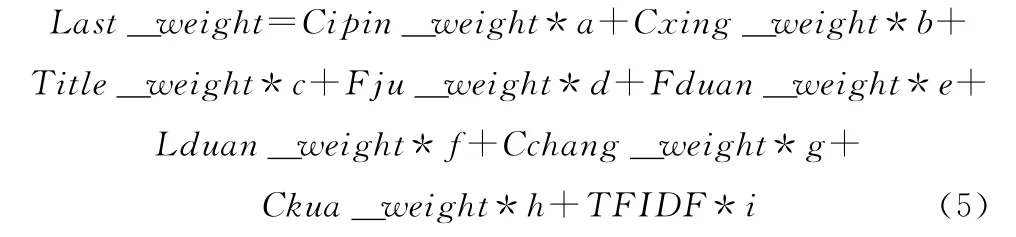
式中:Last_weight——候选词的最终权重,a,b,c,d,e,f,g,h,i均为各个特征权重的比例因子,可以用来调整不同特征权重在最终权重的贡献度大小。将最终权重值按大小降序排列,得到前N 个词作为候选关键词。各种属性的系数影响因子赋值参考文献 [9]如下所示:a=1.5,b=1.1,c=1.0,d=1.0,e=1.0,f=1.0,g=1.0,h=1.0,i=1.0。
2.5 子串过滤
对最终候选词排序的时候,有的词可能会是另一个词的子串,而子串往往没有父串的语义信息丰富,作为关键词的可能性小,如果子串、父串都进行提取可能会造成信息的重复提取,进而影响结果的准确度。如: “信息检索”一词是“信息”和 “检索”的父串,所以遇见类似的情况的时候,只提取父串“信息检索”即可。但如果只单纯的考虑包含关系的过滤和利用分词的最小词频进行过滤[9]可能会造成重要语义的过滤。如一篇关于计算机的文章,文章中多次出现“计算机应用”,“计算机发展”,“计算机科学”等词语,但对于这篇文章来说,文章主旨和语义指向应该是 “计算机”,即计算机比计算机应用更加具有关键词代表性。
那么,如果只单纯的考虑包含关系的过滤,就会过滤掉 “计算机”这个词,那么就会造成提取词语语义的局限性,只提取了局部语义。而如果只考虑子串权重大于父串权重就全部提取,又会造成上述类似 “信息检索”和 “信息”“检索”的重复提取,容易造成具体指向不明,影响最终提取结果的准确率。
研究发现,经本文方法计算的最终权重,有意义的子串父串最大差值不超过0.25,所以本文曾采用了子串值<父串值+0.25的方法进行过滤子串实验。但后来实验发现如果采用此方法过滤,不能针对所有文本过滤掉子串,当子串权重实际较大的时候,便过滤不掉这种子串。如军事类别中一篇关于辽宁舰的文章,在此文章中,“辽宁舰”一词被分词成 “辽宁”和 “舰”两个词,实际词频值分别为10 和13,计算的权重分别为2.709090909090909 和2.7285714285714286,而实际的组合词 “辽宁舰”的权重是1.9090909090909092,那么再用该方法过滤的时候就过滤不掉子串。所以,本文采用组合词频的比值方法来过滤子串。其计算公式如下所示
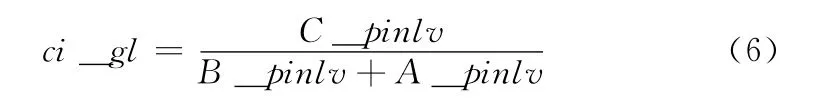
式中:ci_gl——计算结果,C_pinlv——组合词C的词频值,A_pinlv 和B _pinlv——子串A 和B 的词频值。当ci_glv的值大于0.3[9]的时候就过滤掉子串,否则不过滤。通过实验结果表明,该方法较前几种过滤方法能够更好的过滤掉子串。
3 实验结果
本文实验环境为Window XP 操作系统,2.8 GHz的CPU,2G 内存,编程工具为Myeclipse10。我们从人民网站上采集了涉及教育、经济、博客、军事,科技,汽车,娱乐7个领域的2100篇文本。随机抽取20篇,30篇,40篇文本,文本平均大小为7KB左右,对每一篇文本提取5个关键词,分别对使用词序和没有使用词序两类提取关键词的方法进行测试,其提取结果与4个语言学专业的研究生人工提取的关键词准确率进行比较。准确率计算公式为

式中:P——准确率,A——计算机抽取的关键词集合,H——人工标注的关键词集合,|A∩H|——两个集合完全匹配的关键词数目,|A|——A 集合所包含关键词数目。最终计算结果与无词序组合的TFIDF方法、有词序组合的TFIDF方法、无词序组合的本文方法进行结果比较。实验计算结果如图2所示。
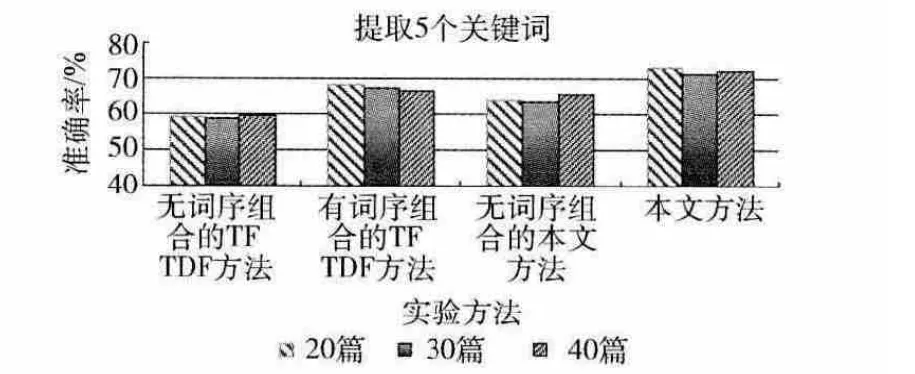
图2 实验结果
从图2中我们可以看出,本文采用的基于词序统计组合的关键词提取方法较无词序的提取方法,准确率至少提高了7.55个百分点。本文方法较其它3种方法提取的结果准确率都有不同程度的提高,具体结果见表2。

表2 各方法提取结果对比
实验结果表明,本文提出的词序统计组合的方法较其它方法更加高效、准确,该方法提取的关键词能较好的反映和体现文本主题。另外,影响结果准确率的原因有:首先,分词的准确率高低是对结果准确率产生重要的影响因素之一;由于本文没有考虑命名实体的识别,所以对于人名、地名,尤其是外译名词等识别度不高,这也影响了结果的准确度;网页文章不似科技学术文献写作那么规范,用词那么准确,表征性那么高;组合词只考虑了部分主要词类的组合,没有完整的语义组合规则,这也有一定的局限性;此外,人工提取关键词的时候,由于各人认识不同,所以关键词提取的时候,不可避免的出现人工误差,这也会影响结果的准确度。以上原因都将是我们以后工作将要改进和努力的地方。
4 结束语
本文进行了三次候选词的过滤,第一次是对停用词的过滤,第二次是对组合后的词组和低频词进行过滤。第三次是对候选词子串的过滤。实验发现,经过三次过滤,实验结果的准确性较一次、两次过滤得到大大的改善和提高。由于我们的实验尚在在起步阶段,准确率会受同义词、近义词等词义方面的影响,此外还会受外译词语和新生词等方面的影响。另外,本文对未登录的新词也起到了一定的识别作用,但对其识别的精确度还优待改善、提高。以后的工作,我们会重点针对这些方面进行提高和改善。
[1]FANG Jun,GUO Lei,WANG Xiaodong.Semantically improved automatic keyphrase extraction [J].Computer Science,2008,35 (6):148-151 (in Chinese). [方俊,郭雷,王晓东.基于语义的关键词提取算法 [J].计算机科学,2008,35(6):148-151.]
[2]XIE Fenghong,ZHANG Dawei,HUANG Dan,et al.Text keywords extraction based on weighted complex network [J].Journal of Systems Science and Mathematical Sciences,2010(11):1592-1596 (in Chinese). [谢凤宏,张大为,黄丹,等.基于加权复杂网络的文本关键词提取 [J].系统科学与数学,2010 (11):1592-1596.]
[3]HU Xuegang,LI Xinghua,XIE Fei,et al.Keyword extraction based on lexical chains for Chinese news web pages [J].Pattern Recognition and Artificial Intelligence,2010,23 (1):45-51 (in Chinese).[胡学钢,李星华,谢飞,等.基于词汇链的中文新闻网页关键词提取方法 [J].模式识别与人工智能,2010,23 (1):45-51.]
[4]ZHANG Yingying,XIE Qiang,DING Qiulin.Chinese keyword extraction algorithm based on synonym chains[J].Computer Engineering,2010,36 (19):93-95 (in Chinese).[张颖颖,谢强,丁秋林.基于同义词链的中文关键词提取算法[J].计算机工程,2010,36 (19):93-95.]
[5]ZHANG Jian’e.A Chinese keywords extraction approach based on TFIDF and word correlation [J].Information Science,2012,30 (10):1542-1544 (in Chinese). [张建娥.基于TFIDF和词语关联度的中文关键词提取方法 [J].情报科学,2012,30 (10):1542-1544.]
[6]LI Jingyue,LI Peifeng,ZHU Qiaoming.An improved TFIDF based approach to extract key words from web pages [J].Computer Applications and Software,2011,28 (5):25-27(in Chinese).[李静月,李培峰,朱巧明.一种改进的TFIDF网页关键词提取方法 [J].计算机应用与软件,2011,28(5):25-27.]
[7]LUO Zhunchen,WANG Ting.Research on the Chinese keyword extraction algorithm based on separate models[J].Journal of Chinese Information Processing,2009,23 (1):63-70(in Chinese).[罗准辰,王挺.基于分离模型的中文关键词提取算法研究 [J].中文信息学报,2009,23 (1):63-70.]
[8]WANG Jinbo,WANG Lianzhi,GAO Wanlin,et al.On an improved nave Bayesian keyword extraction algorithm [J].Computer Applications and Software,2014,31 (2):174-181(in Chinese).[王锦波,王莲芝,高万林,等.一种改进的朴素贝叶斯关键词提取算法研究 [J].计算机应用与软件,2014,31 (2):174-181.]
[9]ZHANG Hongying.Chinese key words extraction algorithm[J].Computer Systems&Applications,2009,26 (8):73-76(in Chinese).[张红鹰.中文文本关键词提取算法 [J].计算机系统应用,2009,26 (8):73-76.]
[10]JIANG Changxing,PENG Hong,CHEN Jianchao,et al.Keywords extraction algorithm based on combined word and synset[J].Application Research of Computers,2010,27(8):2853-2856 (in Chinese). [蒋昌星,彭宏,陈建超,等.基于组合词和同义词集的关键词提取算法 [J].计算机应用研究,2010,27 (8):2853-2856.]
[11]YUAN Jinsheng,MAO Xinwu.Keyword extraction from Chinese news web pages based on multi-features[J].Computer Engineering and Applications,2014,50 (19):222-226 (in Chinese).[袁津生,毛新武.基于组合特征的中文新闻网页关键词提取方法 [J].计算机工程与应用,2014,50 (19):222-226.]
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
当代陕西(2020年17期)2020-10-28 08:18:18
孩子(2019年12期)2019-12-27 06:08:44
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
心理与行为研究(2016年4期)2016-12-16 10:36:46
北方文学·中旬(2016年6期)2016-08-01 12:04:30
江西教育C(2015年4期)2015-05-25 21:11:27
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
