
面向采油工程领域的数据服务系统
2015-12-23 01:08胡长军贾丽娜
计算机工程与设计 2015年8期
刘 歆,胡长军,李 扬,贾丽娜
(北京科技大学 计算机与通信工程学院,北京100083)
0 引 言
本文提出了一套采油工程领域基于本体的数据服务系统 (an oil production engineering ontology-based data service system,OPODSS),OPODSS提供了一个语义丰富的全局语义数据模型和高级查询功能。OPODSS屏蔽了底层数据源的差异,用户和上层应用程序不必知道数据的来源和复杂性,可以利用OPODSS 以无处不在、即需即用[1,2]的方式,直接访问实时更新的底层数据资源。OPODSS还有语义推理功能,可以推理出复杂语义关联关系的数据中隐含的知识。
OPODSS首先使用本体学习的方法,抽取油田分布的各专业数据库的数据模式,建立局部本体,通过本体演化、本体合并、约束推理,建立一个语义丰富的全局本体,虽然各个油田公司的数据具有异构特性,但是每个油田公司都有基础数据、生产数据、设备数据、地质数据等这些数据类型,因此该全局本体适用于各个油田公司;然后建立直接访问底层数据源的数据接口,屏蔽底层数据源的分布、异构、语义关联复杂等特性,提供统一、透明的语义数据查询与数据共享服务,实现语义数据集成。
实践结果表明,数据服务系统可以为油气井生产决策提供全面、实时的数据支持,为优化设计与诊断提供可靠数据服务,进而提高产量和采收率、延长检泵周期,产生巨大经济效益。
1 相关工作
Michael J.Carey等[3]调研了3种比较流行的数据服务,分别是采用服务的数据存储、集成的数据服务和云数据服务,但是这3种数据服务都没有考虑语义之间的关联。
Andreas Bender等[4]提出了科学工作流中面向服务的领域数据集成框架,该框架建立了领域数据模型,让分布、异构的数据源与应用程序桥接起来,但是文章中的领域数据模型不是根据数据源分布、异构的特性,从数据源学习而来,而是领域专家通过图形化的界面手工构建的,带有一定的主观性,而且数据元素之间缺乏语义关联。
Raji Ghawi等[5,6]提出了关系型数据库到本体的映射的语义互操作,利用DB2OWL工具自动从关系数据库模式产生本体,但是它没有考虑多个分布、异构的数据源映射为一个本体的情况。
Anish Das Sarma等[7]在分析了在大量、异构的表中找关联表的问题,提出了使用计算模式相似度的方法查找相关联的表的方案。Li Qian等[8]提出了样本驱动的模式映射系统,但这种方法带有一定的不准确性,而且是针对字符串样本的模式映射。
2 体系结构
OPSDS (Oil production engineering semantic-based data integration system)提供给用户和上层应用程序语义丰富的全局本体和用户查询、接收底层数据源数据的API,有基于函数的和基于查询的两种类型的API。用户和上层应用程序只需要根据全局本体或数据接口进行数据查询即可。OPSDS的实现架构如图1所示。
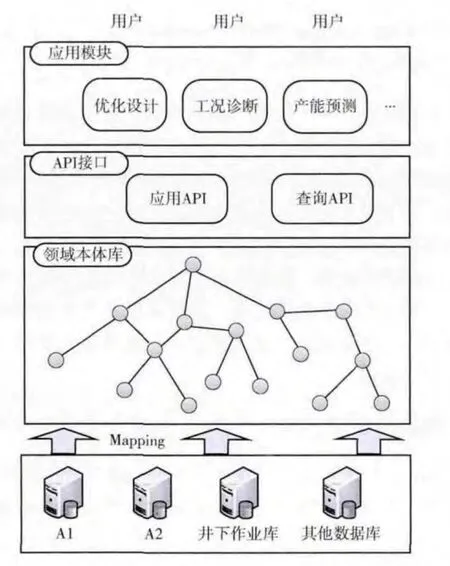
图1 OPODSS的实现架构
2.1 全局本体的构建
采油工程领域的数据库遍布全国,存储模式和数据结构各不相同,数据之间存在复杂的关联关系,不利于石油领域专家和上层应用程序的使用。因此,迫切需要一个能针对异构数据源和领域术语的数据集成系统,屏蔽底层数据的差异,通过领域的全局本体即可访问底层数据。
全局本体构建时,首先,根据需求进行数据筛选,对需要的数据初步分类、整理、归纳,得到系统所需要的数据类型,数据实体等。然后,采用自底而上的策略,抽取数据库的模式信息,建立初始局部本体,再根据油气井工程领域的概念集中概念的关系,将初始局部本体修正为语义更为丰富的局部本体;再通过各局部本体的演化、合并形成全局本体,然后通过增加语义约束、细化和完善,形成一个完整的、语义丰富的全局本体。
2.2 语义映射
用户和上层应用程序,根据全局本体或函数接口,提交查询请求Request。OPODSS首先解析查询请求Request,将查询请求转化为可对本体进行查询的SPARQL 语句。然后将SPARQL查询语句重写,转换为SQL 语句对底层数据源访问,数据库的查询结果根据规则库的数据处理规则进行清洗、转换,Result以统一的格式返回。
SPARQL查询语句重写转换,是把用户基于全局本体的语义查询请求,转换为可以对底层数据源访问的SQL 语句,全局本体到数据源的映射,有一对一和一对多两种形式,包括3种方式:
(1)需要的数据来自一个数据源的一张表;
(2)需要的数据来自一个数据源的多张表;
(3)查询需求需要多个数据库的多张表协同完成。
语义查询过程如图2所示。
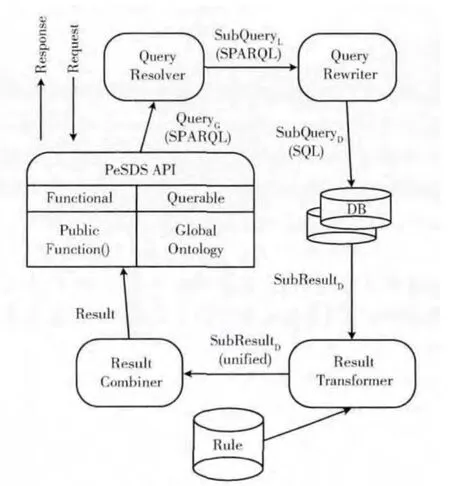
图2 语义查询过程
语义查询的具体实现步骤如下:
(1)获取用户的查询请求Request,生成全局查询语句QueryG(QG),QG采用SPARQL描述。
(2)利用逻辑推理机进行推理,将查询语句QG中的全局本体中的类/属性名称转换为相应局部本体中的类/属性名称。
(3)查询分解器将查询QG分解为针对每个局部本体的子查询SubQueryL,SubQueryL= {SQL1,SQL2,…… ,SQLn},其中,n是局部本体的个数。
(4)查询重写器将SubQueryL重写为针对每个数据源的本地子查询SubQueryD,SubQueryD= {SQD1,SQD2,…… ,SQDn},SQD采用SQL描述。
(5)执行本地子查询,返回查询结果SubResultD,Sub-ResultD= {SRD1,SRD2,…… ,SRDn}。
(6)结果转换器将查询结果SubResultD根据规则库的规则,进行清洗和转换后,得到规范化的子查询结果。
(7)结果合并器将规范化的SubResultD合并,形成最终的查询结果Result并返回。
3 OPODSS系统实现及应用
3.1 应用背景
从采油工程领域对数据的需求出发,开发了OPODSS系统,对油田生产数据库、勘探数据库、设备数据库、井下作业数据库、测井数据库、工艺措施数据库等多个专业数据库进行语义数据集成。OPODSS屏蔽了底层数据库的分布、异构、语义关联复杂等特点,可以为用户和上层应用提供更好的数据的交互和共享服务。
目前,OPODSS已经可以为多个上层应用提供数据服务,其中,比较典型的是采油优化设计与决策支持系统。采油方案的优化设计是该系统的重要功能之一。方案优化设计的作用是,通过对抽油机、抽油杆、抽油泵以及扶正器等抽油设备的调整,以产量,泵效,系统效率等为目标进行综合评判,产生不同条件下的采油方案,用户可以根据需求选择最佳方案。
油田进行采油时,有多种类型的井。下面以抽油机井的优化设计为例,说明OPODSS的系统实现。一口抽油机井进行优化设计时,根据井的基础数据、生产数据、地质(勘探)数据等,搭配不同的采油设备,产生不同条件下的抽油机井优化设计方案[9]。采油设备涉及到抽油机型号选择、杆柱的组合、扶正器设计、抽油泵型号选择等多个方面。图3是进行优化设计时,涉及到的数据及其物理分布。
抽油机优化设计涉及到多方面的数据,这些数据种类繁多,格式多样,数据信息海量,并高速增长,并存储于不同的物理数据库。一方面,一种数据可能来自一个数据库,也可能来自多个数据库;可能来自一个数据库的一张表,也可能来自一个数据库中的多张表。另一方面,这些数据库的环境、硬件平台各不相同,数据库对数据的存储模式也不同,这就造成了结构异构、语义异构、数据关联关系复杂、难以实时交互信息等问题。比如,抽油杆结构数据体现了典型的异构问题,分为结构异构和语义异构。语义异构表现为,JH 井号这一字段,在不同的数据库中,存储的名称不同。在D1数据库中是JH,在D2数据库中,存为well_name,在D3数据库中,存为well。一口井需要一组抽油杆数据,每根抽油杆包含杆级数、杆长、杆径等信息,不同的杆级数对应不同的杆长。对于一个三级抽油杆,D1把三级杆长组合起来,存成一个字段;D2 根据不同的杆级数,将杆长分为3行记录存储;D3是用一行记录中的3个字段来表示,这种抽油杆结构数据的存储方式,体现了典型的结构异构。如图4所示。
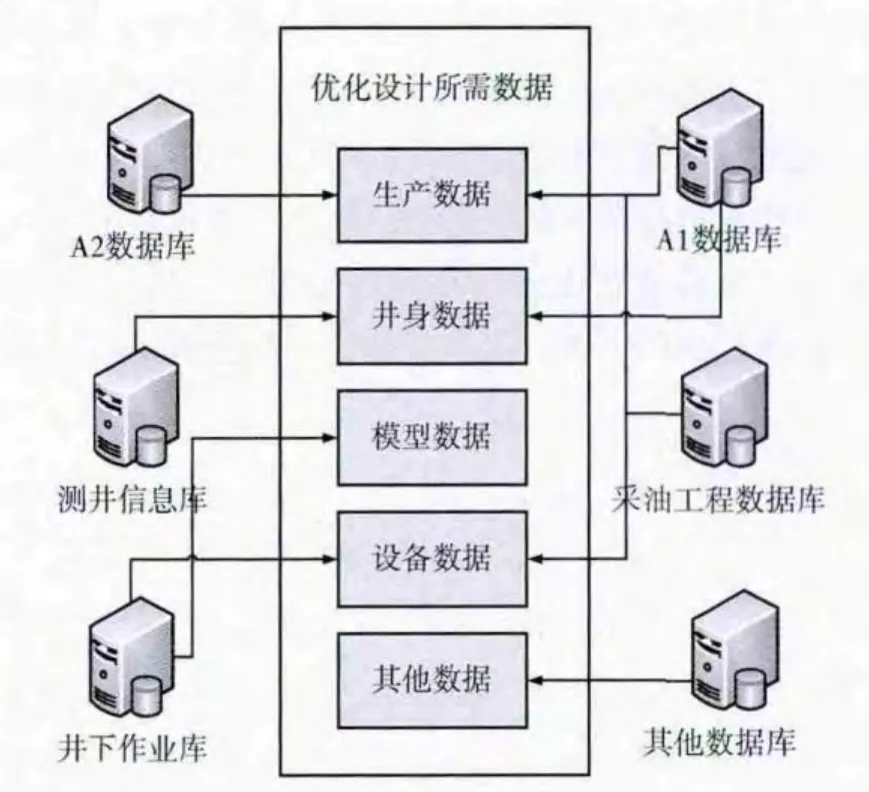
图3 抽油机井优化设计
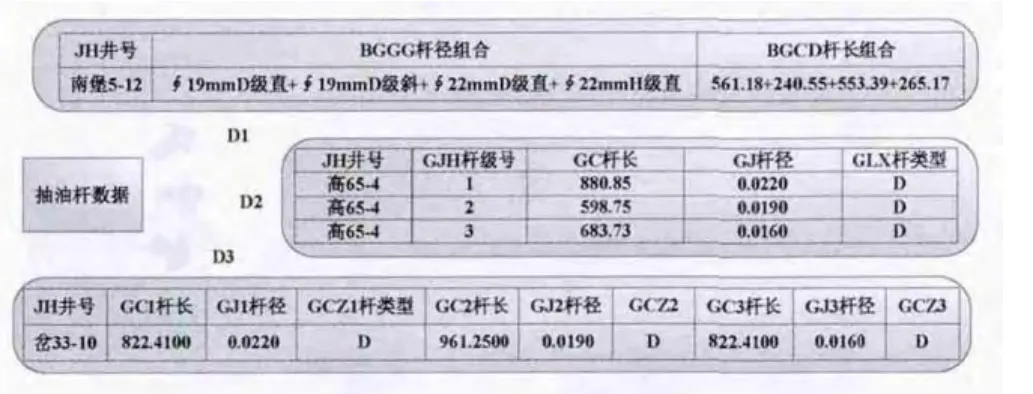
图4 异构的抽油杆数据
再比如,井型数据,体现了数据间的关联关系,因为井型是根据井斜角数据计算而来。我们把井斜角小于5°的井,当作直井;把井斜角大于75°的角当作水平井;把井斜角在5°和75°之间的井,看作是斜井[10]。
优化设计涉及到基础数据、生产数据、地质数据、抽油机数据等多种类型的数据,这些数据存储在不同的物理位置,存储在不同的数据库中,存储模式也各不相同。语义异构、结构异构、复杂的关联关系等问题,使得采油工程领域的数据服务越来越迫切和重要。
3.2 OPODSS系统实现
3.2.1 基于函数接口的服务
采油方案的优化设计,是典型的利用OPODSS提供的函数接口,实现访问数据的数据服务方式。上层应用程序根据OPODSS提供的优化设计函数接口,即可访问所需的数据资源,不必关心数据实际存储的物理位置,存储于哪种类型的数据库,及数据的存储模式。图5 (a)是抽油机优化设计功能的界面,界面上有方案优化设计所涉及到的数据,这些数据可以通过OPODSS提供的优化设计的函数接口,函数查询全局本体,然后再映射到数据源取得。图5(b)展示了方案优化设计所需的部分数据,通过函数查询的方式,映射到的本体,及全局本体与数据源的映射关系。
“我也这么认为过。”英格曼站下脚,回过头对闭着的大门说,“后来发现,对你们来说,激怒不激怒,结果都一样。”
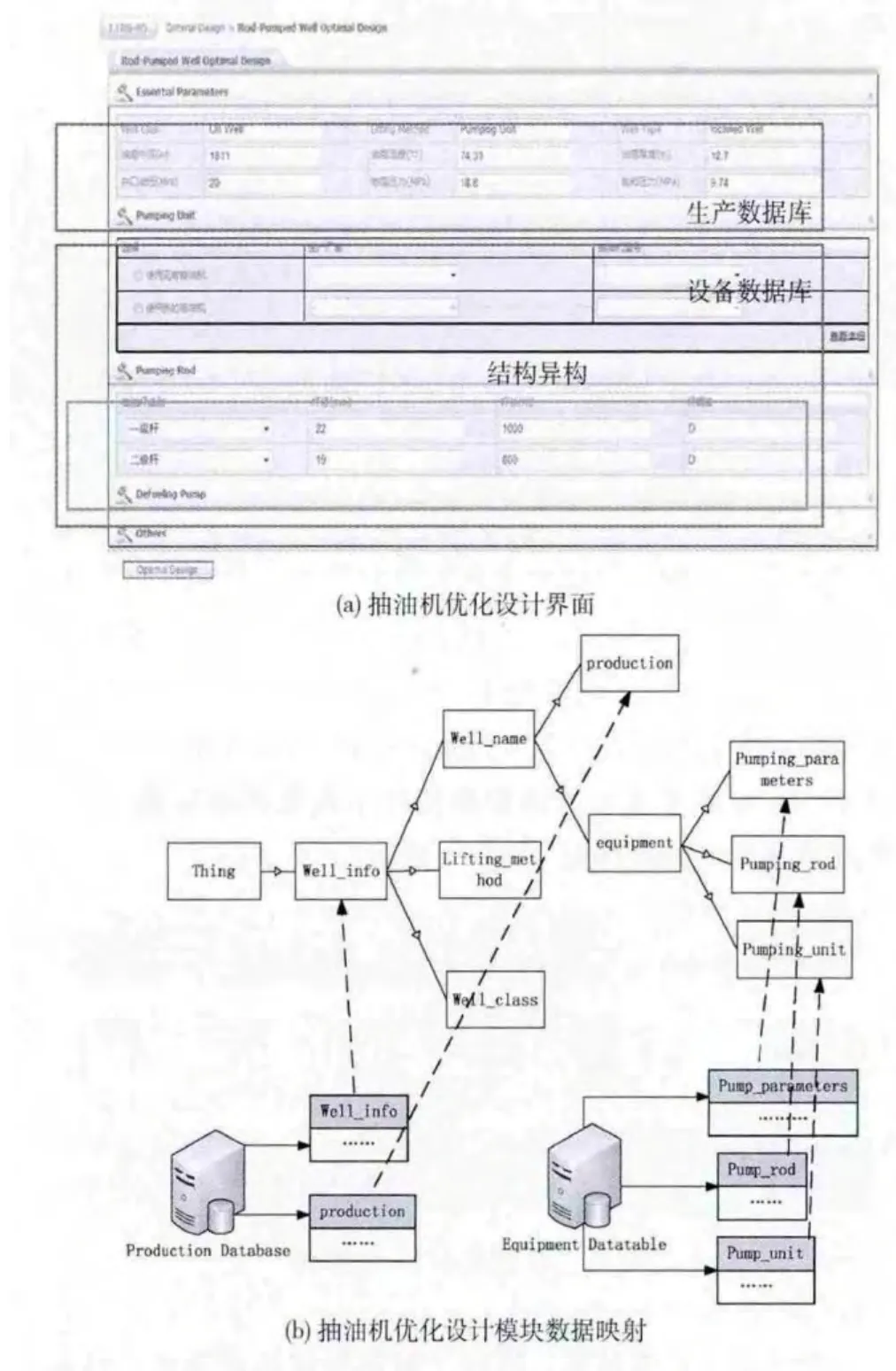
图5 油机优化设计模块实现
图5 (a)中,Essential Parameters部分需要的数据,通过图5 (b)所示的本体的类well_name、well_class等,映射到生产数据库取得的,而图5 (a)中Pumping Unit、Pumping Rod和Defueling Pump部分需要的数据,是通过本体类映射到设备数据库取得,实现了分布数据的集成,并为上层应用程序所用。
图5 (b)中,生产数据库中井的名称为well_name,设备数据库中名称为well,这是典型的异名同义的异构现象,我们使用PeDSOnto:hasSynonymy把这两个类的语义进行关联。这个例子中,类well和类well_name映射的实例都是9L106-05。而Pumping Rod部分,体现了结构异构的问题,OPODSS可以将图5 (b)中组合存储的抽油杆结构数据,处理为图5 (a)抽油杆结构数据的格式,以呈现给用户和应用程序。
图6是点击图11 的 “优化设计”按钮,利用这些数据,进行计算后的结果,OPODSS对底层数据源的数据进行重用和共享,为工程所用,实现了数据的 “增值”。
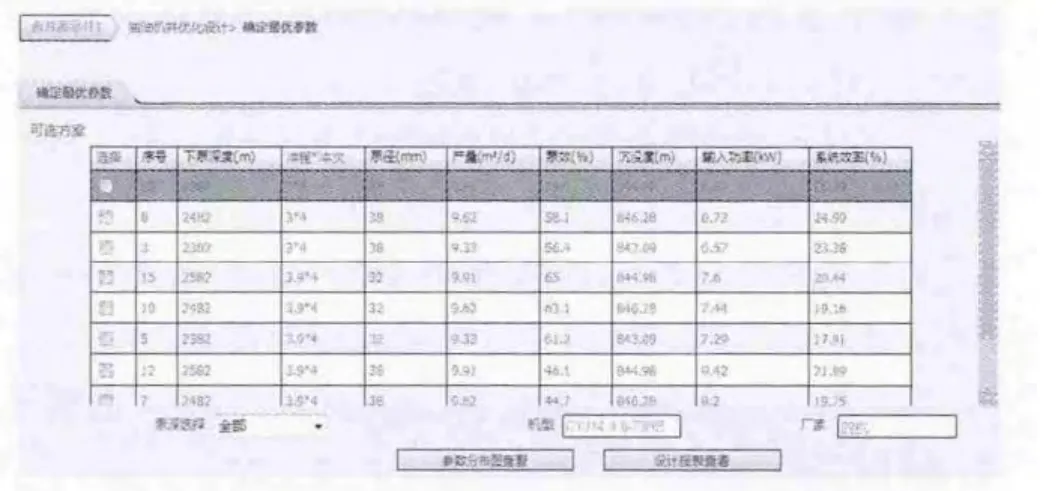
图6 抽油机优化设计的结果
3.2.2 基于查询的服务
OPODSS提供了基于查询的数据服务,可实现数据的语义查询。
图7中,勾选左边的数据源,其下方可以看到数据源的数据物理分布。既可以查询整个油田的数据,也可以通过勾选的方式,选择油田中采油厂、区块等部分数据。右边的现实字段,可以选择想要查询的字段名称,通过条件选择,限制所需查询的字段的条件,点击 “增加条件”按钮,即可把要查询的字段及其限制条件,添加到右边的已选条件中。依次,可以添加多个查询字段及其查询条件。点击 “查询数据”按钮,即可显示查询结果,及其对应的数据源。

图7 OPODSS的数据查询服务
图8是查询结果和相应的数据源的模式。产油量和含水率,分别来自冀东和大庆的生产数据库;抽油机型号字段,冀东油田、大庆油田和总公司的数据库中都有,但是冀东和大庆油田的该字段,对应的实际的井号,总公司的设备数据库中,该字段对应的是抽油机型号的具体参数,而用户查询时,这些字段的数据都需要,所以,OPODSS就实现了不同的物理数据库,同一数据库中,不同表之间的联合查询。
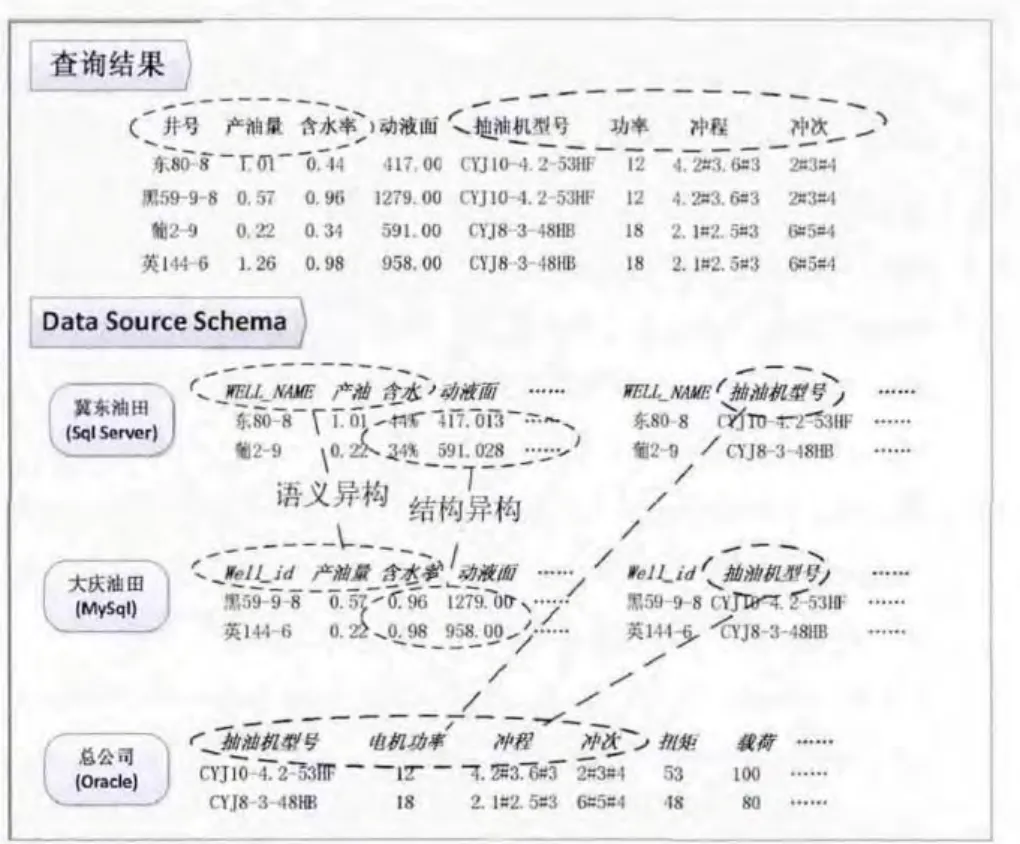
图8 查询结果和数据源
冀东、大庆和总公司存储数据所用的数据库各不相同,这就造成了系统异构。字段井号、产油量、含水率在冀东油田和大庆油田的存储形式不同,这就造成了语义异构。而含水率,冀东存储的是百分比,而大庆存储的是小于1的小数,动液面的数据两个油田存储的精度不同,这就造成了数据存储结构的异构。由于油田公司物理数据库中的数据,每天都是实时更新的,通过全局本体到底层数据库的逐级映射,用户和上层应用程序,可以获得最新的数据。OPODSS可以屏蔽底层数据库纷繁复杂的异构性和物理的分布性,通过全局本体,逐步映射到底层的数据库,经过数据的查询转换、数据清洗,将查询结果以统一的格式返回给用户。
OPODSS屏蔽底层数据源分布、异构、语义关联复杂的差异,建立采油工程领域的全局语义数据模型,并提供数据的查询和共享服务,使分布的数据无缝链接,使上层应用程序在OPODSS上平滑移动。
3.3 OPODSS的生产应用
以OPODSS为核心的采油优化设计与决策分析系统已经在CNPC多个油田得到应用,已经为3万余口油气井的生产监控和措施效果评价提供全面和实时的数据服务。使用OPODSS后,与传统的数据使用方法相比,取得了良好的工程应用效果,其中,最突出的效果一个是延长检泵周期,另一个是提高采收率。
在采油工程领域,检泵周期是指从上次各种措施后下泵正常抽油开始,到这次抽油装置失效而停止抽油的间隔天数。OPODSS可以使已有的数据资源得到充分利用,提高检泵周期。井岔74-124的检泵周期低于100 天,在950 m 和1800m 处频繁杆断,系统通过查询这口井的历史数据,对已有数据进行计算,发现两处侧向力达到6KN,所以优化扶正器配置和加重杆长度后,检泵周期从100天延长到122天。再者,系统对井东3-10使用的抽油机参数进行调整,降低电流平衡度、等值扭矩、电流变化后,发现系统效率从9.8%提高到18.6%,提高了8.8%。调整前后的对比见表1。
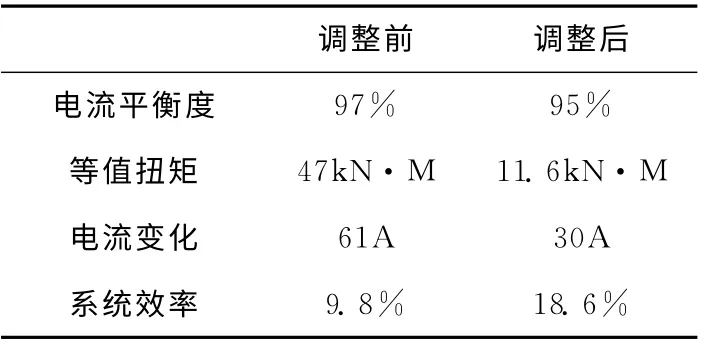
表1 井东3-10参数调整前和调整后的对比
使用OPODSS 的采油优化设计与决策支持系统(PetroPE)已经在大庆、吉林、冀东、大港、华北油田推广应用,在华北和冀东油田现场试用软件,对356 口井进行优化和诊断,其中,对95口井进行有杆泵优化,系统效率从21.3%提高到26.9%,平均提高5.6%;对50口井进行螺杆泵优化,系统效率从30.2%提高到36.7%,平均提高6.5%,前后对比的柱状图如图9所示。
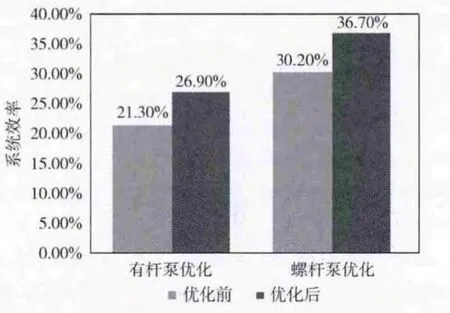
图9 系统效率对比
据统计,系统效率平均提高1%,不但产油量有明显的增加,而且年节电4 亿度。所以,OPODSS充分利用数据资源,成为了提高产量、减低成本的有效手段。
4 结束语
对错综复杂的领域数据进行语义数据集成,是目前研究与应用的热点。本研究利用本体技术,对分布、异构、语义关联复杂的数据源建立全局语义数据模型,提供全面、实时的数据服务,是一种可行、有效的方法。
对于数据密集型的工业领域,建立基于领域本体的全局语义数据模型,实现基于语义的数据集成,并为上层生产应用服务,可以得到很好的应用效果。
石油领域是典型的数据密集型领域,OPODSS在生产实践中起到了关键的作用。OPODSS实现了数据的共享和重用,上层应用程序直接通过OPODSS就可以即需即用地访问分布、异构、关联复杂的数据资源,并得到规范化的数据,为工业生产所用。在应用需求的驱动下,OPODSS将生产、学习和科研紧密结合,这是推动科技进步,实现科学技术是第一生产力的有效途径。
在下一步的工作中,OPODSS 会在更多的油田使用,并且到推广勘探、地震等石油方面的其它领域。
[1]Mahmoud H A,Aboulnaga A.Schema clustering and retrieval for multi-domain pay-as-you-go data integration systems[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data,2010:411-422.
[2]GE J,HU C,LI Y,et al.An intermediate view for data integration,management in cloud computing [J].Journal of Computational Information Systems,2013,9 (9):3611-3618.
[3]Carey M J,Onose N,Petropoulos M.Data services [J].Communications of the Acm,2012,55 (6):86-97.
[4]Bender A,Poschlad A,Bozic S,et al.A service-oriented framework for integration of domain-specific data models in scientific workflows[J].Procedia Computer Science,2013,18:1087-1096.
[5]Zhang L,Li J.Automatic generation of ontology based on database[J].Journal of Computational Information Systems,2011,7 (4):1148-1154.
[6]Ghawi R,Cullot N.Building ontologies from XML data sources[C]//DEXA Workshops,2009:480-484.
[7]Sarma A D,Fang L,Gupta N.Finding related tables[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data,2012:817-828.
[8]Qian L,Cafarella M J,Jagadish H V.Sample-driven schema mapping [C]//Proceedings of the ACM SIGMOD International Conference on Management of Data,2012:73-84.
[9]Liu X,Hu C,Li Y,et al.The advanced data service architecture for modern enterprise information system [C]//International Conference on Information Science and Applications.IEEE,2014:1-4.
[10]Jia L,Hu C,Li Y,et al.A semantic-based data service for oil and gas engineering [C]//Proceedings of the 10th Interna-tional Conference on Web Information Systems and Technologies,2014:131-136.
猜你喜欢
石油石化节能(2022年12期)2022-12-30
房地产导刊(2022年10期)2022-10-18
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
中国商论(2016年34期)2017-01-15
电子科技大学学报(2016年2期)2016-08-31
浙江大学学报(工学版)(2015年2期)2015-05-30
中国煤层气(2014年6期)2014-08-07
电信科学(2014年2期)2014-02-28
河南科技(2014年16期)2014-02-27
