
基于改进HFT模型的显著性检测
2015-12-23 01:11刘尚旺毛文涛刘国奇
计算机工程与设计 2015年8期
刘尚旺,李 铭,毛文涛,刘国奇
(河南师范大学 计算机与信息工程学院,河南 新乡453007)
0 引 言
人类视觉系统 (human visual system,HVS)在面对复杂场景时,能迅速将注意力集中在显著区域而忽视无关信息,这就是视觉注意[1-5]。显著性检测方法分为两类:自下而上和自上而下的视觉注意模型。前者是根据输入图像的低层视觉特征的显著性大小来构建视觉注意的过程[6-8];而后者依赖于具体的任务,受人的意志支配,需要先验知识的支持和指导[9,10];还有一些模型同时利用了这两种视觉注意模型机制[11]。
目前,大多数可计算视觉注意模型都属于自下而上型,它们又可以分为:空间域和频域视觉注意模型。其中,频域视觉注意模型具有计算速度快、简单、可调参数很少或没有、显著性检测结果更加符合人类视觉等优点,成为了近年来的研究热点。Hou等提出幅度谱残差 (spectral residual,SR)[12]显著性检测方法,开创了在频域内构建视觉注意模型的先河[13-16]。经文献分析与实验验证,其中HFT模型[16]在模仿人类视觉系统 (HVS)方面,效果显著,但HFT 模型同其它频域视觉注意模型一样,普遍缺乏生物视觉理论依据。针对此问题,本文从颜色空间的选择、四元数虚部系数的选择以及最终显著图的产生方法上对HFT 模型加以改进,提高其生物可信性,进而更好地进行显著性检测。
1 HFT模型及其性能比较分析
验证实验中,测试模型的数据集合采用领域内较为广泛使用的Bruce数据集[19]和Judd数据集[20]。其中Bruce数据集是最早和最广泛使用的数据集,包含120 幅图像,图像分辨率为681×511;Judd数据集是目前为止能够得到的图像规模和类别最大的数据集,包含1003幅图像,图像具有不同的分辨率和宽高比。性能分析时,文中从视觉注意模型的输出结果——显著图和人类视觉的吻合程度以及最常用的受试者工作特征曲线 (receiver operating characteristics,ROC)下的面积 (area under curve,AUC)这两方面来进行定性和定量的分析。其中,定量分析时,AUC的值等于0.5时,表示是随机水平;小于0.5表示负相关;大于0.5表示正相关;AUC的值越接近于1,表明模型的性能越好。
空间域的视觉注意模型不仅结构复杂、计算量大,而且需要设置的参数也较多,如:Itti模型[21]、基于图论的视觉显著性模型(graph-based visual saliency model,GBVS)[22]、信息最大化模型 (visual attention model based on information maximization,AIM)[23]等。相比之下,频域视觉注意模型结构简单、计算量小,并且需要设置的参数少或根本不需要设定参数,如相位谱傅里叶变换模型 (phase spectrum of Fourier transform,PFT)、相位谱四元数傅里叶变换模型 (phase spectrum of quaternion Fourier transform,PQFT)[15]、基于离散余弦变换的图像签名模型(discrete cosine transform,DCT)[17]以及四元数离散余弦变换的显著性检测模型 (quaternion discrete cosine transform,QDCT)[18]。经典的空间域视觉注意模型:Itti、GBVS 和AIM 模型的显著性检测结果,如图1所示。前述的几个频域视觉注意模型在相同的输入图像下,得到的实验结果,如图2所示。通过图1和图2比较,可以明显看到空间域视觉注意模型取得的显著图分辨率较低 (参见图1 和图2的图 (b)、图 (e)和图 (f)图像的显著图),并且检测到的显著目标也不如频域视觉注意模型的视觉效果好 (参见图1和图2的图 (a)、图 (c)、图 (d)、图 (e)和图 (f)图像的显著图)。

图1 经典的空间域视觉注意模型输出的显著
另外,还可从AUC值指标的角度来评价空间域和频域视觉注意模型。两类视觉注意模型在上述两个数据集上的平均AUC 值,分别见表1 和表2。通过对比表1 和表2,在Bruce数据集上,频域视觉注意模型的综合平均AUC 值为0.6900,空间域视觉注意模型的综合平均AUC 值为0.6556,频域视觉注意模型的AUC 值提高了5%;而在Judd数据集上,频域视觉注意模型的综合平均AUC 值为0.6939,空间域视觉注意模型的综合平均AUC 值为0.6748,频域视觉注意模型的AUC值提高了2.8%。
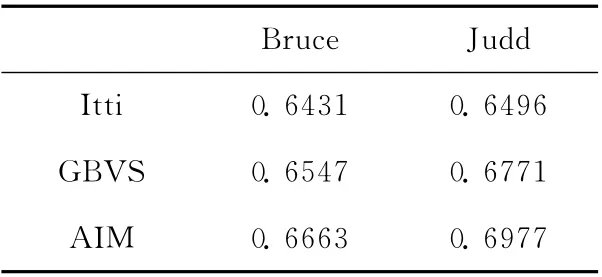
表1 空间域视觉注意模型的平均AUC值
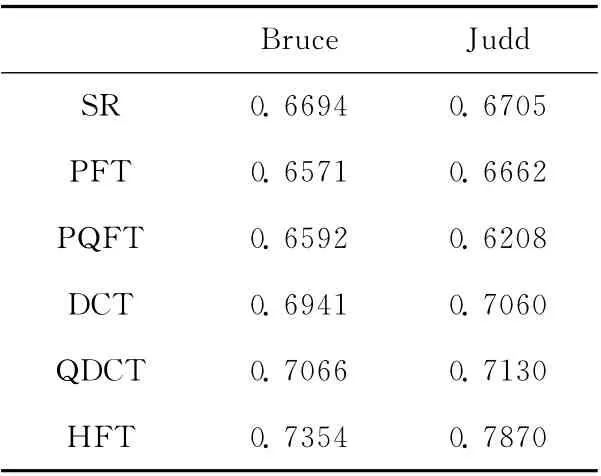
表2 频域视觉注意模型的平均AUC值
综上所述,不难看出频域视觉注意模型的性能要优于空间域视觉注意模型。尽管频域视觉注意模型得到显著图的视觉效果比空间域视觉注意模型要好,但其本身仍然存在不完善的地方。对于自然图像,从图2可以看出,SR 和PFT 得到的显著图几乎一样,虽然SR 和PFT 方法的计算速度快,没有参数的设定,但是它们只利用了图像的灰度信息而忽视了图像的颜色特征,故它们不能运用于彩色图像的显著性检测。除此之外,SR 和PFT 方法只能检测到目标物体的边缘信息和图像中的纹理特征 (见图2第二行和第三行的图 (e)、图 (g)和图 (h));换句话说,当且仅当显著目标较小时,它们才能很好地将显著目标检测出来 (见图2第二和第三行的图 (d)图像)。于是,PQFT模型同时考虑了颜色,方向以及光强等静态图像的信息,可以用于彩色图像的显著性分析;而且该模型将3种特征通道通过四元数的方式进行并行处理,提高了计算速度。但是,从图2第四行来看,PQFT 模型只能检测到显著目标的大致边缘位置,而不能均匀光滑地突出整个显著目标区域。简言之,SR、PFT 以及PQFT 模型在一定程度上,相当于结合高斯后处理的一个梯度运算,对于自然图像的幅度谱来说,其低频部分包含重要的显著信息,并且显著信息量比高频部分要多得多。因此,如果幅度谱被PFT、PQFT 中这样的水平面替代,则所有的频率都被同等对待。也就是说,高频部分被抑制,低频部分被提高,亦即所谓的梯度增强运算。总而言之,SR、PFT 以及PQFT 检测的显著目标之所以还不够理想,其主要原因在于它们舍弃幅度谱的方式不合理。

图2 自然图像的显著
SR、PFT 和PQFT 模型均基于傅里叶变换,而DCT图像签名和QDCT 模型基于离散余弦变换。从图2的第五和第六行来看,DCT 和QDCT 模型检测的显著目标明显要比SR、PFT 以及PQFT 要好,但是这两个方法同样存在检测的显著目标只突出边缘信息的缺点 (如图2第五和第六行的图 (g)、图 (h)所示)。从实验的视觉效果图上来看,相比DCT 和QDCT 模型,HFT 模型的显著性检测优势好像有限;但是,从表2中AUC 指标值上来看,HFT 模型取得了最大的AUC值,这表明HFT 模型在性能上要优于DCT 和QDCT 方法。究其原因,HFT 模型采取了傅里叶变换后对幅度谱进行高斯平滑滤波这种合理的舍弃幅度谱冗余信息的方法。另外,相比离散余弦变换,傅里叶变换的物理意义更加明确,便于揭示频域视觉注意模型的生物可信性。
通过上述实验验证与分析,HFT 视觉注意模型在显著性检测方面,不管是效果上还是效率上均取得了很好的效果。但是,同其它频域视觉注意模型一样,HFT 模型缺少生物视觉理论基础,从而难以令人信服与认可。故,在综合分析现有主要视觉注意模型的基础上,本文从颜色空间的选择、四元数图像虚部系数的确定以及最终显著图的产生方法这3个方面对HFT 模型进行改进,以进一步增加其生物可信性和有效性,期望取得更好的显著性检测效果。
2 改进HFT模型
2.1 颜色空间的选择
图像表示中最常用的颜色空间是RGB 颜色空间,但RGB颜色空间设计的初衷是使输出设备更好地显示输出图像,没有充分考虑人类视觉感知,正是由于这个固有限制,导致RGB 特征在显著性计算中的作用受到限制。另外,RGB各个颜色通道的数值与其所表示的刺激强度并不成线性关系,在分析和计算时,难以准确计算颜色的差异。
相反,CIE Lab 颜色空间的色域较宽阔,不但包含RGB颜色空间的所有色域,而且能表现更多的色彩。或者说,人类眼睛能感知到的色彩,CIE Lab 都能表现出来。不同于RGB颜色空间,CIE Lab颜色空间的设计致力于感知的均匀性,更接近人类视觉系统 (HVS),能够弥补RGB颜色空间色彩分布不均匀的缺陷。L 分量和人类对亮度的感知十分匹配,还可以通过修改a和b分量的输出来对颜色进行精确的平衡,或者用L 分量调整亮度对比度,所以CIE Lab颜色空间更加符合人类视觉感知。因此,本文首先使用Lab颜色空间来改进HFT 模型。
2.2 图像的超复数或四元数表示
2.2.1 超复数傅里叶变换
超复数傅里叶变换已广泛地应用在彩色图像处理中[24]。在实际应用时,超复数矩阵被具体化为一个四元数。一个超复数矩阵可以定义为
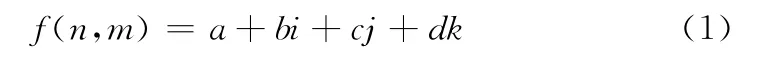
式 (1)的离散傅里叶变换形式,如式 (2)所示
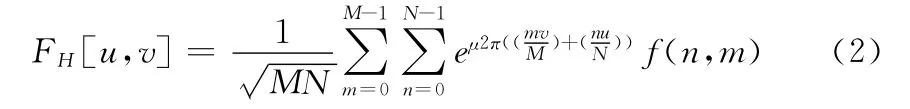
式中:μ是一个单位纯四元数,并且μ2=-1。
超复数傅里叶变换的逆变换为
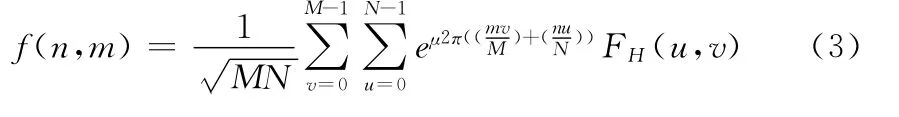
2.2.2 图像的超复数或四元数表示
超复数或四元数可以用于联合图像的不同特征,将一个图像表示成四元数形式。图像的超复数或四元数矩阵表示,如式 (4)所示
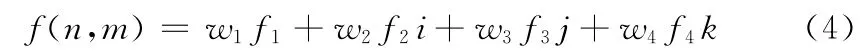
式中:w1-w2是权重,f1-f4是特征图,f1是运动特征,f2是亮度特征,f3和f4是颜色特征。对于静态输入图像,f1=1,f2-f4的计算公式如式 (5)~式 (7)所示
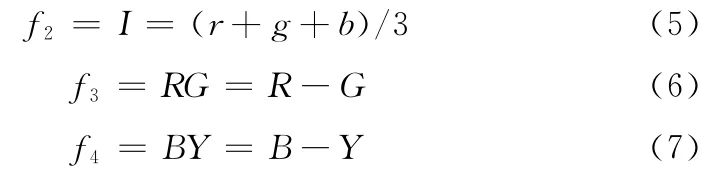
式中:r,g,b表示输入彩色图像的红、绿和蓝通道,R=r-(g+b)/2,G=g- (r+b)/2,B=b- (r+g)/2,Y=(r+g)/2-|r-g|/2-b。权重设为w1=0,w2=0.5,w3=w4=0.25。
2.2.3 四元数图像虚部系数的确定
四元数图像傅里叶变换的频域处理框架很值得推荐和研究,然而该框架的显著性检测性能,很大程度上取决于四元数图像虚部系数的确定[15,16,18]。因此,在四元数图像的3个虚部特征系数的合理确定上,有必要对HFT 继续进行改进。研究结果表明,人类视觉接受域中的神经节细胞的感受野是同心圆结构,具有独特的中央-周围拮抗性质。因此,本文选择CIE Lab颜色间中去掉冗余低频信息的L,a,b这3个通道来代替HFT 模型中四元数图像的3个虚部特征系数,来进一步改进HFT 模型。即,改进HFT 模型中四元数图像3个虚部特征系数分别为
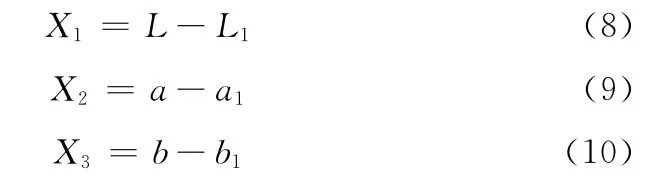
式中:X1、X2和X3分别用来代替HFT 中I、RG 和BY,L、a和b 为Lab颜色空间3 个通道的值;L1、a1和b1为对应通道相应像素点八邻域的均值。
式 (8)~式 (10)中四元数图像3个虚部特征系数的计算方法类似于IG 或MSSS模型[25]中简化的C-S运算,即可以简单地模仿生物视觉神经元的中央兴奋-周边抑制机制。也就是说,该运算作为四元数图像的虚部系数具有明确的生物学意义。
2.3 四元数图像傅里叶变换的极坐标形式
四元数图像傅里叶变换的极坐标形式为
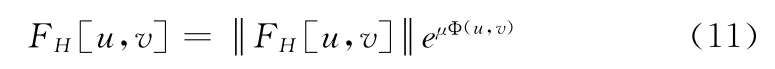
从而,幅度谱A(u,v),相位谱P(u,v)和纯四元数矩阵χ(u,v)的计算方法如式 (12)~式 (14)所示
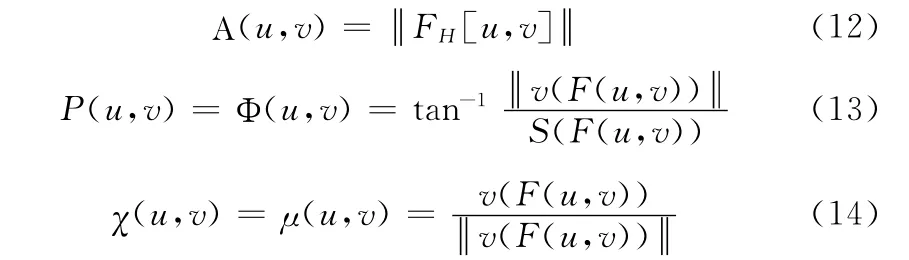
2.4 幅度谱平滑滤波
HFT 模型的研究结果表明,幅度谱既包含显著信息,也包含不显著的信息。因此,HFT 模型采用不同的高斯核函数对幅度谱进行平滑滤波,以达到抑制高频信息的同时增强低频信息的目的;不同的幅度谱平滑滤波后构成了一个谱尺度空间。高斯核函数以及谱尺度空间的定义,如式(15)和式 (16)所示
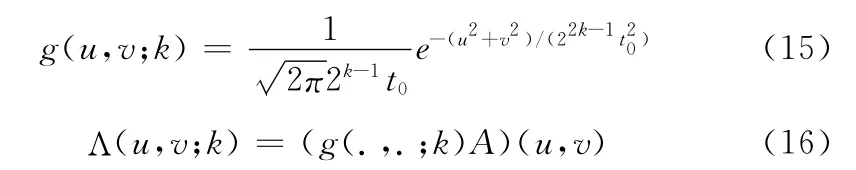
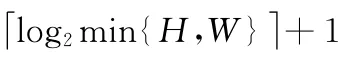
2.5 不同尺度上显著图的计算
根据已经计算出的幅度谱和相位谱,就可以计算出不同尺度上的显著图,如式 (17)所示
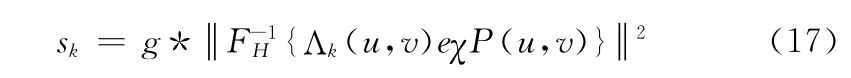
式中:g——一个固定尺度的高斯核函数。
这样,就得到一系列的显著图{sk}。接下来,需要根据一定的原则从该显著图序列{sk}中选出最终的显著图S。
2.6 最终显著图的确定
首先,依据设定的熵准则选择出最合适的尺度kp,如式所示
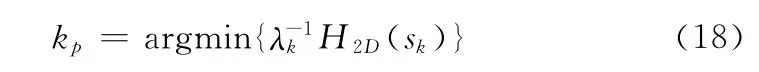
式中:λk=∑∑k(n,m)N(sk(n,m)),k是一个和S 同尺寸的2 D 中心高斯掩膜,∑∑k(n,m)=1;H2D(x)是一个经过低通高斯核函数gn与二维信号x 卷积后计算出的熵,H2D(x)=H{gn*x}。
HFT 模型中,根据kp从 {sk}序列中选择出最终显著图,其它尺度上的显著图则被彻底舍弃;然而,这些被彻底舍弃的显著图中事实上也包含有一些重要的显著信息,这些显著信息的不合理舍弃造成HFT 模型的显著性检测效果有时不太准确。因此,有必要在熵最小尺度上显著信息的基础上,将所有尺度上的显著信息合理融合起来。为此,本文以熵最小尺度上的显著信息为基础,以其它尺度上的对应熵为贡献率来融合其它尺度上的显著信息,从而提出一种多尺度最终显著图的确定方法。该方法步骤如下:
(1)按照HFT 模型中计算熵的方法,计算出每个尺度上显著图的熵H2D(sk);
(2)计算出熵的最小值Hmin和平均值Haveg;
(3)在 {sk}中找到熵最小尺度上的显著图smin;
(4)最终显著图的确定方法,如式 (19)所示
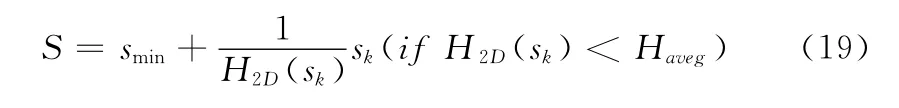
简言之,改进HFT 模型中,选择了比较符合人类视觉感知的CIE Lab颜色空间,并且确定的四元数图像虚部系数有一定的生物视觉理论基础,最终的显著图也融合了不同尺度的显著信息,从而有利于显著性检测。
3 实验结果与分析
为了全面评价相关模型,下面从自然图像显著性检测、心理图像显著性检测、ROC 曲线以及AUC 值等几方面来进行对比实验与分析。
3.1 自然图像显著性检测
相关模型典型自然图像的显著性检测视觉结果对比图,如图2所示。
从图2的第七和第八行图 (a)的检测结果来看,改进HFT 模型能够准确地检测出两个人,而HFT 模型只检测出了一个人;对于图 (b),改进HFT 均匀地检测出了小孩整个显著目标对象,而HFT 模型漏检了小孩的右腿;图(c),只有改进HFT 模型检测到了兔子的位置并将其显示出来;图 (d),显著目标应该是改进HFT 模型检测到的长颈鹿,而不是其它模型检测出的树木;对于第五个图像,SR 和PFT 只突出了显著目标的边缘,PQFT 只检测到显著目标的大概位置,HFT 只突出了中心部分,而DCT、QDCT 以及改进HFT 模型均匀平滑地突出了整个显著区域;最后两个图像,只有改进HFT 模型检测的结果能较均匀平滑地突出整个显著目标对象。
3.2 心理图像的显著性检测
心理图像是不同于自然图像的另一类型图像数据,也是评价视觉注意模型性能的重要标准之一。相关模型的部分心理图像的显著性检测视觉结果对比图,如图3所示。
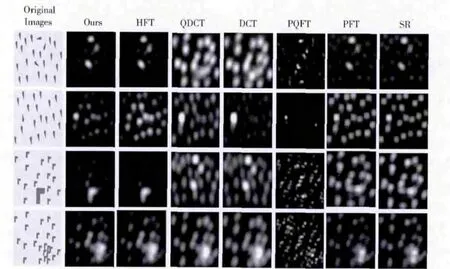
图3 心理图像的显著
从图3可以看出,SR 和PFT 模型只检测到了第一幅心理图像的显著目标;PQFT 模型给出了显著目标的大致位置;DCT 和QDCT 模型很好地突出了第二个心理图像的显著目标,对于其余3个图像均没有正确地检测到显著目标;HFT 模型和改进HFT 模型的检测的结果相当,但是对于第二幅图像,HFT 检测的结果并不令人满意,而改进HFT 模型准确地突出了与其它对象方向相反的显著目标。从显著性检测视觉结果图来看,改进HFT 模型能够很好地检测到心理图像的显著目标。可见,改进HFT 模型的显著性检测视觉结果与人类视觉系统 (HVS)相当接近。
无论是自然图像显著性检测结果还是心理图像显著性检测结果,改进HFT 模型都要优于其它方法。究其原因,改进HFT模型之所以能检测到其它模型所不能检测到的显著目标,最主要的原因在于其生物可信性的提高,即所选择的四元数图像的虚部系数属于简化的C-S运算,具有一定的生物视觉理论基础;该C-S运算还充分利用了CIE Lab颜色空间的3个特征通道的差异,和人类视觉感知的特点非常吻合。
3.3 ROC曲线和AUC值分析
为了对模型进行公平比较,其ROC 曲线和AUC 值均在相同测试平台上由同一测试程序计算得到。相关模型在Judd数据集上的ROC曲线,如图4所示。
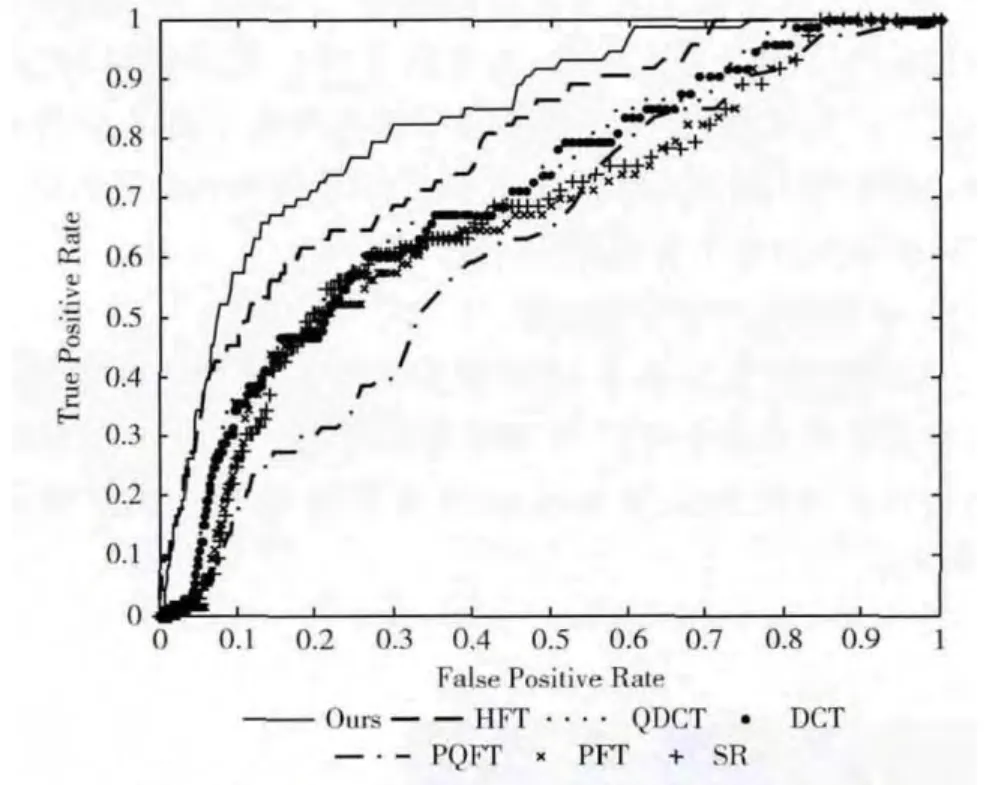
图4 相关模型在Judd数据集上的ROC曲线
从图4中可以看出,改进HFT 模型的ROC 曲线在其它模型的上方,其曲线下面积 (AUC 值)无疑最大,这意味着改进HFT 模型的性能最优。
两个数据集上的平均AUC值,见表3。
从表3的实验数据可见,改进HFT 模型在Bruce和Judd 两个数据集上的平均AUC 值均取得了最大值,较HFT 模型分别增长了0.97%和6.33%,再一次表明改进HFT 模型显著性检测的有效性。
为什么改进HFT 模型能够准确地检测到自然图像和心理图像的显著目标,并且在两个数据集上都取得较高的AUC值呢?一个重要的原因是选择的CIE Lab颜色空间更接近于人类视觉感知;另外一个原因是确定的四元数图像的虚部系数属于简化的C-S运算,该运算是生物可信的,它有明确的生物视觉理论基础,类似于人类视觉接收域的神经元的中央-周围拮抗性质;最后一个至关重要的因素是最终显著图的计算中充分融合了不同尺度上的显著信息。
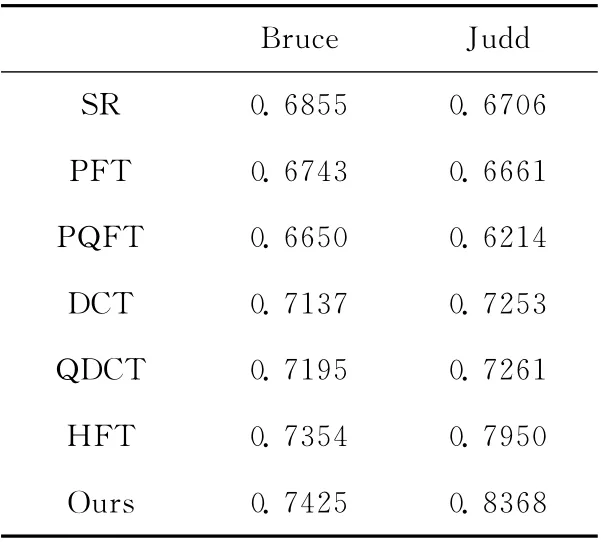
表3 CIE Lab颜色空间下AUC值的比较
4 结束语
本文通过对HFT 视觉注意模型进行的三方面改进:①选择了和人类视觉感知更接近的CIE Lab颜色空间;②确定的四元数图像虚部系数属于简化C-S运算,一定程度上模拟了生物视觉神经元的中央兴奋-周边抑制机制;③融合不同尺度上的显著信息来生成最终的显著图,大大提高了HFT 模型的生物可信性和有效性。实验结果表明,改进HFT 模型的自然图像、心理图像的显著性检测结果,不管是视觉结果图还是AUC 值都优于其它相关模型。其中,AUC值比HFT 模型在Bruce和Judd数据集上分别提高了0.97%和6.33%。当然,本文的改进模型只利用了自下而上的低层信息,没有考虑自上而下的先验信息,下一步将重点研究将自下而上和自上而下的信息综合起来进行图像显著性的检测。
[1]Zhang L B,Yang K N.Region-of-interest extraction based on frequency domain analysis and salient region detection for remote sensing image[J].IEEE Geoscience and Remote Sensing Letters,2014,11 (5):916-920.
[2]Tsotsos J K,Rothenstein A.Computational models of visual attention [J].Scholarpedia,2011,6 (1):6201-6201.
[3]HAO Wenxin,GAO Lining.Object detection based visual attention and local descriptor[J].Computer Engineering and Design,2012,33 (5):1918-1922 (in Chinese). [郝文欣,高立宁.基于视觉注意机制与局部描述子的物体检测 [J].计算机工程与设计,2012,33 (5):1918-1922.]
[4]Wu Y T,Shih F Y,Shi J,et al.A top-down region dividing approach for image segmentation [J].Pattern Recognition,2008,41 (6):1948-1960.
[5]Meger D,Forssen P E,LaiK,et al.Curious george:An attention semantic robot[J].Robotics and Autonomous System,2008,56 (6):503-511.
[6]Fang Y,Lin E,Lee B S,et al.Bottom-up saliency detection model based on human visual sensitivity and amplitude spectrum[J].IEEE Transaction on Multimedia,2012,14 (1):187-198.
[7]Cheng M M,Zhang G X,Mitra N J,et al.Global contrast based salient region detection [C]//IEEE Conference on Computer Vision and Pattern Recognition,2011:409-416.
[8]Perazz F,Krahenbuhl P,Pritch Y,et al.Saliency filters:Contrast based filtering for salient region detection [C]//IEEE Conference on Computer Vision and Pattern Recognition,2012:733-740.
[9]Yang J,Yang M H.Top-down visual saliency via joint CRF and dictionary learning [C]//IEEE Conference on Computer Vision and Pattern Recognition,2012:2296-2303.
[10]Zhu J,Qiu Y,Zhang R,et al.Top-down saliency detection via contextual pooling [J].Springer Link Signal Processing System,2014,74 (1):33-46.
[11]ZHU Chenyang,HUO Hong,FANG Tao.Visual attention model based on Bayesian inference using multiple cues [J].Computer Engineering and Design,2013,34 (7):2470-2475(in Chinese).[朱辰阳,霍宏,方涛.基于贝叶斯推理的多线索视觉注意模型 [J].计算机工程与设计,2013,34 (7):2470-2475.]
[12]Hou X,Zhang L.Saliency detection:A spectral residual approach [C]//IEEE Conference on Computer Vision and Pattern Recognition,2007:1-8.
[13]Peters R,Itti L.The role of Fourier phase information in predicting saliency [J].Journal of Vision,2008,8 (6):879.
[14]Bian P,Zhang L.Biological plausibility of spectral domain approach for spatiotemporal visual saliency [M].Advances in Neuro-Information Processing,Springer Berlin Heidelberg,2009:251-258.
[15]Guo C,Zhang L.A novel multi-resolution spatiotemporal saliency detection model and its applications in image and video compression [J].IEEE Image Process,2010,19 (1):185-198.
[16]Li J,Levine M D,An X,et al.Visual saliency based on scale space analysis in the frequency domain [J].IEEE Transactions Pattern Analysis and Machine Intelligence,2013,35(4):996-1010.
[17]Hou X,Harel J,Koch C.Image signature:Highlight sparse salient regions [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34 (1):194-201.
[18]Schauerte B,Stiefelhagen R.Predicting human gaze using quaternion DCT image signature saliency and face detection[C]//IEEE Workshop on Applications of Computer Vision,2012:137-144.
[19]Bruce N D B,Tsotsos J K.Saliency,attention,and visual search:An information theoretic approach [J].Journal of Vision,2009,9 (3):1-24.
[20]Judd T,Ehinger K,Durand F,et al.Learning to predict where humans look [C]//IEEE 12th International Conference on Computer Vision,2009:2106-2113.
[21]Borji A,Itti L.State-of-the-art in visual attention modeling[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35 (1):185-207.
[22]Borji A,Sihite D N,Itti L.Quantitative analysis of humanmodel agreement in visual saliency modeling:A comparative study [J].IEEE Transaction on Image Processing,2013,22(1):55-69.
[23]Bruce N,Tsotsos J K.Saliency,attention,and visual search:An information theoretic approach [J].Journal of Vision,2009,9 (3):1-24.
[24]Zhou Y,Kamata S.Hypercomplex polar Fourier analysis for color image [C]//IEEE International Conference on Image Processing,2011:2117-2120.
[25]Achanta R,Ssstrunk S.Saliency detection using maximum symmetric surround [C]//IEEE International Conference on Image Processing,2010:2653-2656.
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
中学生数理化·高一版(2022年3期)2022-04-15
中等数学(2021年6期)2021-08-14
数学学习与研究(2020年23期)2020-01-11
电子制作(2019年24期)2019-02-23
西南交通大学学报(2018年5期)2018-11-08
雷达学报(2018年3期)2018-07-18
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20
知识产权(2016年8期)2016-12-01
卷宗(2016年8期)2016-11-15
