
基于联合HOG 特征的车牌识别算法
2015-12-23 01:08高婷婷
计算机工程与设计 2015年2期
殷 羽,郑 宏,高婷婷,刘 操
(武汉大学 电子信息学院,湖北 武汉430072)
0 引 言
每个国家的车牌具有各自不同的特点,国外现有的车牌识别系统对我国车牌进行识别时存在很大问题,不能简单的直接利用国外现有的研究成果。目前,国内研究人员针对汉字字符识别已经提出了符合汉字结构特征的特征提取方法。其中包括四边码、方向线素特征[1]、汉字笔画抽取特征[2]、笔画分布特征和弹性网格特征等。在文献 [3]中,提出了基于欧拉数改进的模板匹配方法,此方法减少了大量匹配过程,提高了相似字符的识别率。文献 [4]中,提出了将双神经网络分类器引入脱机手写汉字识别。对于数字字母的识别,文献 [5]提出利用隐马尔科夫特征和分形维数进行数字字母的识别,识别率较高,但也仅停留在理论阶段,不适用于复杂环境中的识别。目前广泛应用于字符识别的方法主要有3 种:模板匹配字符识别[6],神经网络字符识别[7],统计学习字符识别[8]。基于模板匹配的字符识别方法是依据处理后的车牌字符与预设模板的相似程度来进行判断。神经网络方法凭借其良好的适应能力、较好的学习能力以及容错能力受到较为普遍的欢迎。基于统计学习的字符识别方法目前在车牌识别的各个场景中有较多应用。其中,采用支持向量机的车牌识别算法在近年来十分流行,它有效避免了从归纳到演绎的过程,同时方法简单,鲁棒性强。
虽然车牌识别技术已经取得了一定的成果和突破,但是离成熟应用于复杂多变的实际场景要求差距还较大,目前一些新的理论方法还只能应用于几种特殊场景,有待进一步实验论证和改进。
本文提出了联合方向梯度直方图和核主成分分析法特征,它综合了二值图、灰度图、16值图的方向梯度直方图特征的优点,能够较好提取汉字结构特征。方向梯度直方图特征进行联合后,HOG 特征维数增加,此时为了缩短特征提取时间,本文用核主成分分析法方法进行降维。字符识别方法采用的是对小样本问题有较好分类效果的支持向量机。
1 基于联合HOG 特征的车牌识别算法
常见车牌有7个字符,文中是将分割下来的7个字符进行识别。车牌字符由英文字母、汉字和数字组成,中文和英文数字的特点不一样:中文汉字笔画稠密、轮廓复杂;数字和英文则轮廓清晰,结构简单。因此文中对汉字和英文数字采用不同的分类器,对它们分别提取特征。本文车牌识别过程是:首先确定字符的分类器。然后分别提取汉字、数字字母的灰度方向梯度直方图 (histogram of oriented gradients,HOG)[9]特征、二值HOG 特征、16值HOG特征,将它们组合成联合HOG 特征,将得到的联合HOG特征用核主成分分析法进行降维。最后将汉字和数字字母的联合HOG 特征送入支持向量机进行训练和预测,将汉字和数字字母的识别结果进行组合,得到最终的车牌字符识别结果。基于联合HOG 的车牌识别流程如图1所示。

图1 基于联合HOG 的车牌识别流程
1.1 方向梯度直方图
方向梯度直方图的核心思想是计算图像中被检测目标的局部梯度的统计信息。由于梯度是针对边缘轮廓,因此目标的外形轮廓可以由梯度分布所描述。因此,HOG 特征就是通过将分割下来的单个字符分割成小的连通区域 (细胞,cell),成为细胞单元,每个细胞单元中的每个像素生成一个梯度直方图,这些直方图的串联就可表示出所检测目标的特征。为了提高光照变化的适应性,将这些直方图在分割下来的单个字符中的一个较大区域 (块,block)内进行对比度归一化,具体来说就是计算每个局部直方图在块中的密度,根据密度来对这个块中的每个细胞单元进行归一化。经过归一化后,HOG 特征对光照变化和阴影可以获得更好的适应能力。
HOG 具体实现过程如下:
(1)计算图像梯度:先用模板 [-1,0,1]对分割下来的单个字符做卷积运算,得到水平方向梯度分量Gh(x,y),如式 (1)所示;再用模板 [1,0,-1]对分割下来的单个字符做卷积运算,得到竖值方向梯度分量Gv(x,y),如式 (2)所示;最后,计算该像素点的梯度幅值M(x,y)和θ(x,y)梯度方向,如式 (3)、式 (4)所示,f(x,y)表示该点的像素值,计算公式为[10]
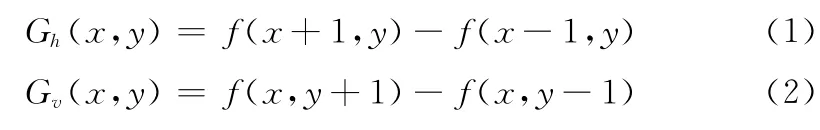
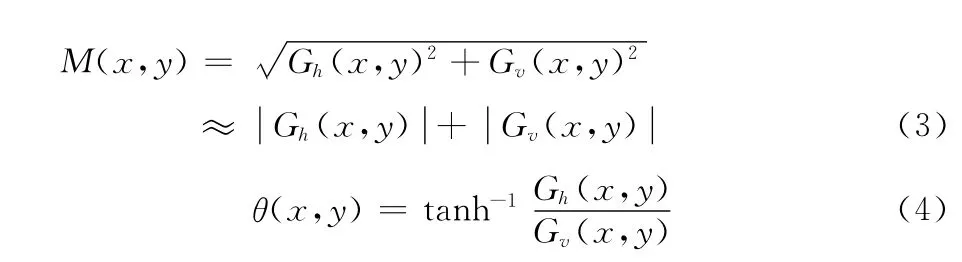
(2)构建梯度方向直方图:在细胞单元中的每个像素点都要为基于某个梯度方向的直方柱投票,梯度方向可取0~180°或者0~360°,在以往的实验证明0~180°效果较好。单个字符图像被分为若干个细胞单元,每个细胞单元包括8*8个像素,将梯度范围分为9个方向角度,因此利用9个方向角度对8*8个像素的梯度信息进行投票。特别指出,直方图投票采取加权投票,即每个像素的梯度幅值作为投票权重。
(3)将细胞单元组合成块:块的结构有两种:矩形块(R-HOG)和环形块 (C-HOG)如图2 所示。本文采用矩形块来进行目标检测,矩形块一般包含3个参数:每个块中细胞单元的数目,每个细胞单元中像素点的数目以及每个细胞单元的方向角数目。文中参数为:2*2 细胞/块,8*8像素/细胞单元,9个方向角度/细胞单元。
(4)块内归一化
计算公式如下所示[10]
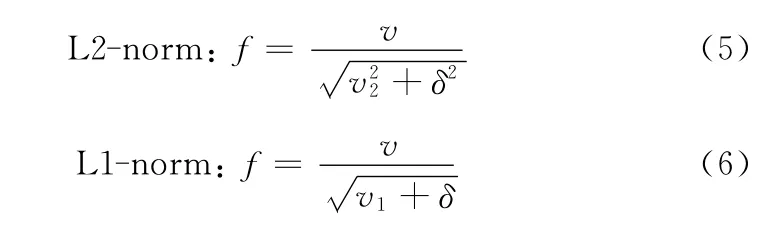
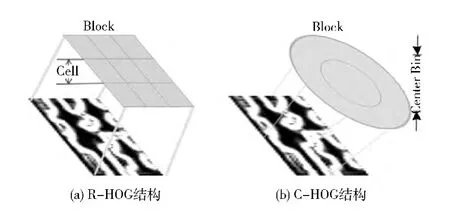
图2 块的结构

L2-hys:先计算L2-norm,然后将v 的最大值限定为0.2,再进行归一化。
其中,v表示包含给定块统计直方图信息的未归一化向量;δ 是一个很小的常数,作用是为了避免分母为0;是v 的k 阶范数。在Dalal的实验中发现L2-hys,L2-norm,L1-sqrt效果差不多,L1-norm 字符识别效果要差一些,但这4个归一化方法在识别性能上对比未归一化都有明显提高。本文中采用的是L2-norm 进行归一化。
如图3所示:假设将车牌字符归一化到64*128,每8*8个像素组成一个细胞单元,每2*2个细胞单元组成一个块,当块的滑动步长为8时,扫描垂直方向可以滑动15次,水平方向可以滑动7 次,因此可以得到36*7*15=3780位的特征算子。单个车牌字符处理效果如图4 所示,车牌字符灰度图的梯度幅值图和梯度角度图包含的细节信息多,但缺点在于角度图中的字符轮廓不明显,影响了车牌字符识别率。为了克服上述缺点,提出了联合HOG 特征,将灰度图的HOG 特征、二值图的HOG 特征和16 值图的HOG 特征联合起来。

图3 车牌字符与块和细胞单元的关系

图4 车牌字符HOG 特征
1.2 联合方向梯度直方图
HOG一般是基于灰度图像进行处理的,灰度图像保存了图像的细节信息,但是字符图像的轮廓不鲜明;而二值图像虽然保存了轮廓信息,但是丢失了图像细节,如图5所示。灰度图的梯度幅值图和梯度角度图包含大量的细节信息,其中角度图像中的字符轮廓不明显。二值图的梯度幅值图和梯度角度图的字符轮廓均比较清晰,但是没有细节信息。

图5 灰度图HOG 特征和二值图HOG 特征对比
基于这种情况,本文提出了联合HOG 的方法,即将灰度图和二值图分别计算HOG 并组合成联合特征,如式 (8)所示:H 代表是得到的联合特征,hi表示灰度图和二值图的HOG 特征,wi代表的是灰度图和二值图HOG 的权重值,权重之和为1。权重分布的不同对后来的识别结果有很大影响。经实验证明,权重值都为0.5 时,识别效果是最好的,并且对比单独的灰度图或二值图的识别效果好

同时本文进一步提出将16值图的HOG 特征加入联合HOG 特征,即分别进行车牌字符的灰度图、二值图和16值图的HOG 计算,将结果以某种关系线性组合起来得到的联合HOG 特征,组合如式 (9)所示:H 代表最终的联合HOG 特征,hgrary,h2,h16分别代表车牌字符灰度图、二值图和16值图的HOG 特征,wi代表权重。本文经过实验结果表明,在权重为0.3,0.3,0.4时识别效果最好
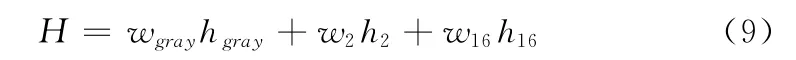
联合HOG 将灰度图、二值图和16值图的特点结合起来,能够一定程度的弥补单独进行灰度图或者二值图的HOG 预案算造成的不足,对识别率有也有一定程度的提高。具体不同权值对识别率的影响将在实验结果与分析中详细说明。由于HOG 生成过程冗长,得到的特征向量维数较大,而联合HOG 特征由多个HOG 串联得到,维数更大。因此,本文用核主成分分析法对联合HOG 进行降维,这样不仅可以缩短训练时间,同时不影响识别率。
1.3 核主成分分析法
核主成分分析法 (kernel principal component analysis,KPCA)定义参见文献 [11]。设xi∈Zp(i=1,2,3,…,n),将输入空间Zp通过非线性变换ε 映射到F,F 中的样本点记为ε(xi),F空间样本的协方差矩阵为C,如式 (10)所示。根据Mercer定理,用核函数K(xi,xj)替代空间F中的内积,如式 (12)所示。αjr表示标准化后的特征向量,gr(xj)为对应ε 的第r 个非线性主元分量,其中r=1,2,…,m,如式 (12)所示。将所有的投影值形成一个矢量g(xj)作为样本的特征值,如式 (13)所示。KPCA 虽然能解决非线性问题,但是样本点的数目比较大,造成核矩阵的维数比较大,所以计算复杂度也增加了。本文用稀疏的 贪 婪 矩 阵 逼 近 (sparse greedy matrix approximation,SGA)[12]方法减小样本点的个数,从而降低了核矩阵的维数。计算公式如下所示[13]

1.4 车牌字符特征分类
车牌字符分类主要是指将待识别的字符特征与经过学习的训练字符特征通过某一算法进行对比来进行识别。常用的分类器主要包括最小距离分类器、k-最近邻分类器、贝叶斯分类器、决策树、Adaboost级联分类器、人工神经网络和支持向量机[14](support vector machine,SVM)。根据需要训练分类的车牌字符特性及不同分类器的特点,本文主要采用支持向量机进行分类。支持向量机的核心思想在于利用一个分类超平面当作决策的曲面,来最大化正类和负类两者的边缘距离。考虑到本文中车牌字符识别中训练样本的数量有限,而且生成的HOG 维数较多,因此本文采用的对小样本问题有较好分类效果的支持向量机。针对多分类的问题,本文采用的 “一对一”的方式进行划分。
SVM 在处理样本并进行训练预测识别的过程大致为以下几步:在车牌字符样本中选择训练样本集和测试样本集,分别对训练集和测试集进行预处理,并提取HOG 等特征,然后利用交叉验证法选择最优参数c和g,最后利用最佳参数训练SVM,获得训练模型,利用训练模型对测试集进行预测,得到预测分类准确率。
SVM 中常用的核函数包括线性核函数,径向基核函数,多项式核函数,sigmoid核函数。对于不同的核函数测试集的分类准确率也会不同,见表1,通过对数字字母的89张图片进行测试得到的分类准确率。由表1可知,车牌字符识别中采用径向基核函数的分类准确率最高。因此,本文SVM 的核函数采用的是RBF核函数。

表1 不同核函数的识别率对比
综上所述,在提取特征以后,利用SVM 进行训练分类。在训练过程中的参数需要进行寻优,本文在进行HOG参数对比的实验中,为了尽快得到结论节省训练时间,所采用的SVM 参数统一为:惩罚变量c的变换范围是2-5~25,核函数参数g 是2-5~25,将测试集分为3个部分,参数c和g搜索的步长为2。
2 实验结果及分析
本文中的实验部分所采用的车牌图片均来自治安卡口或电子警察中采集到的真实图片。在此实验中所有车牌字符图片均为32*64大小。软件平台为:Matlab2010 (算法验证),Microsoft Visual 2005 (MFC 对 话 框 界 面 设 计),libsvm (SVM 工具箱)。分类识别率计算方法如式 (14)所示,Accuracy 为测试集的分类准确率,N 为总测试样本数,Nc为识别正确的测试样本数。分类准确率值越大,字符的识别效果越好
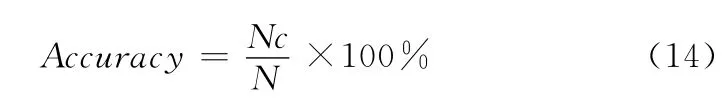
2.1 不同特征识别率对比
文中对比了数字字母、汉字在不同特征的情况下,对识别率和识别时间的影响。其中数字字母的训练集图片为569张,测试集图片为1479张;汉字的训练图片为468张,测试图片为1096张。训练集和测试集图片均为已切分好的单张灰度图片,分类器为支持向量机,实验结果如图6和图7所示。LBP[15]、方向线素特征[7]、水平垂直投影、13点特征法[16]虽然识别时间短,但是识别率比较低。LBP对图像噪声非常敏感,车牌字符灰度图像含有较多的噪声,对LBP特征识别结果有一定程度影响;方向线素特征是针对汉字字符结构提出来的,适用于手写汉字识别;水平垂直投影法和13点特征法都是基于二值图像的字符识别,二值化的效果对识别结果有很大影响;HOG 特征识别基本达到了较好的结果;联合HOG 降维后特征识别率最高,它是基于灰度图、二值图、16值图的HOG 特征,将灰度图和二值图的优势结合起来,在识别时间增加不多的情况下,识别率得到一定程度的提升。
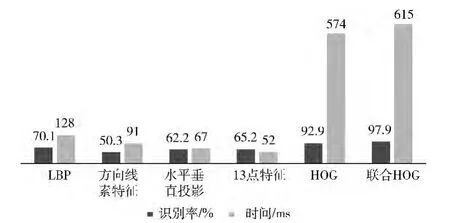
图6 数字字母不同特征识别率对比
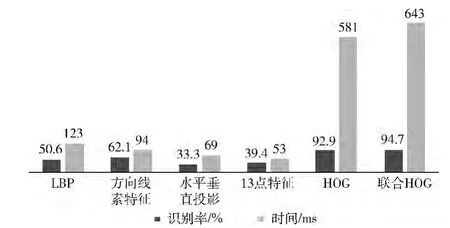
图7 汉字不同特征识别率对比
2.2 联合HOG 特征权值分布实验
文中用汉字字符作为实验图片,汉字训练集图片为242张,测试集图片为592张,实验结果如图8和图9所示。联合HOG比基于单独灰度图,二值图或16值图的HOG 分类准确率有一定程度地提高。对于灰度图和二值图,在权值分别为0.5和0.5时分类准确率达到最高。对于灰度图,二值图和16值图,在权值分别为0.3,0.3和0.4时识别效果最好。这代表着在权值分布越接近的时候,识别效果越好。
2.3 不同车牌识别方法对比
将本文的车牌识别方法跟Tesseract[17]和BP神经网络进行比较,见表2。本文在进行字符识别的研究之前曾尝试过利用开源软件Tesseract对预处理好的车牌进行识别,Tesseract对预处理效果的依赖程度很大,通常都是将车牌的字符感兴趣区域划分出来后进行二值化,再利用Tesseract进行识别。如果二值图片不是很理想,就会大大的影响识别效果。这对预处理提出了非常高的要求,但一般预处理是无法达到如此严格的标准。另外,Tesseract用简体中文库识别的车牌图片,由于车牌汉字二值化的效果参差不齐,低质量的车牌汉字二值化后会造成笔画断裂等不必要的损失,导致汉字的识别效果不能令人满意。多个综合特征结合BP神经网络车牌识别方法中[18],多个综合特征指基元数,平均宽度,区域分布,水平垂直投影等字符的多个特征,它是针对字符的二值图像提取的。由于汉字的结构紧凑,笔画稠密的特点使得汉字图像在二值时易产生笔画断裂,这对综合特征中的基元数,平均宽度和区域分布在统计结果上都有一定程度的影响;特征向量的数量庞大导致BP神经网络在训练时收敛较慢,对识别速度有一定的影响。该方法对车牌中的数字字母识别效果较好,但是由于汉字识别错误的关系,影响了整体的车牌识别率。如果二值图片不是很理想的话就会大大的影响识别效果。联合HOG+SVM 特征在未进行KPCA 降维前识别率虽然有一定程度的提升,但识别时间是HOG+SVM 所需时间的3倍,本文所用联合HOG+KPCA+SVM 方法在汉字和数字、字母识别中均能达到较好的识别效果,识别时间跟HOG+SVM 识别时间差异不大。

图8 灰度图和二值图不同权值分布的识别率

图9 灰度图、二值图和16值图不同权值的识别率

表2 完整车牌识别率对比
3 结束语
文中在HOG 特征的基础上提出了联合HOG 特征。对灰度图、二值图、16值图进行特征联合以后,识别时间是灰度图HOG 特征的3倍,为了减少识别时间,本文用KPCA 对HOG 特征进行降维,降维后识别时间跟灰度图HOG 特征差异不大。通过实验证明了联合HOG 特征跟LBP、方向线素特征等相比在车牌识别率上有一定程度的提升。同时得出了联合HOG 特征在权值分布均匀时,识别率比较高。用联合HOG+KPCA+SVM 对车牌字符进行识别,能够较好的识别车牌,但是HOG 的生成过程较长,针对如何进行速度的提升和性能优化将是以后工作中重点解决问题,同时考虑扩展该方法在其它模式识别领域的应用。
[1]LIN Ying,LV Yue.Handwritten bangle numerals recognition based on directional element feature [J].Computer Engineering,2009,35 (15):185-186 (in Chinese). [林颖,吕岳.基于方向线素特征的孟加拉手写数字识别 [J].计算机工程,2009,35 (15):185-186.]
[2]ZHAO Jiyin,ZHENG Ruirui,WU Baochun,et al.A review of off-line handwritten Chinese character recognition [J].Acta Electronica Sinica,2010,38 (2):405-415 (in Chinese).[赵继印,郑蕊蕊,吴宝春,等.脱机手写体汉字识别综述 [J].电子学报,2010,38 (2):405-415.]
[3]CHEN Wei,CAO Zhiguang,LI Jianping.Application of improved templates matching method on plate recognition [J].Computer Engineering and Design,2013,34 (5):1808-1811(in Chinese).[陈玮,曹志广,李剑平.改进的模板匹配方法在车牌识别中的应用 [J].计算机工程与设计,2013,34(5):1808-1811.]
[4]WANG Ge,XIE Songyun,DANG Zheng.Exploring recognition of off-line handwritten Chinese characters using double ANN classifier [J].Journal of Northwestern Polytechnical University,2010,28 (4):574-578 (in Chinese). [王 歌,谢松云,党正.基于双神经网络分类器的脱机手写体汉字识别[J].西北工业大学学报,2010,28 (4):574-578.]
[5]GENG Qingtian,ZHAO Hongwei.License plate recognition based on fractal and hidden Markov feature [J].Optics and Precision Engineering,2013,21 (12):3198-3204 (in Chinese).[耿庆田,赵宏伟.基于分形维数和隐马尔科夫特征的车牌识别 [J].光学精密工程,2013,21 (12):3198-3204.]
[6]XIE Zhijiang,LU Bo,LIU Qin,et al.Rotation invariant and fast image template matching algorithm [J].Journal of Jilin University:Engineering and Technology Edition,2013,43(3):711-717 (in Chinese).[谢志江,吕波,刘琴,等.旋转不变性图像模板匹配快速算法 [J].吉林大学学报:工学版,2013,43 (3):711-717.]
[7]Gheorghita S,Munteanu R,Graur A.An effect of noise in printed character recognition system using neural network[J].Advances in Electrical and Computer Engineering,2013,13 (1):65-68.
[8]ZHANG Qi,WANG Yuanyuan,MA Jianying,et al.Automatic identification of vulnerable plaques based on intravascular ultrasound images [J].Optics and Precision Engineering,2011,19 (10):2507-2519 (in Chinese).[张麒,汪源源,马剑英,等.基于血管内超声图像自动识别易损斑块 [J].光学精密工程,2011,19 (10):2507-2519.]
[9]Arróspide J,Salgado L,Camplani M.Image-based on-road vehicle detection using cost-effective histograms of oriented gradients[J].Journal of Visual Communication and Image Representation,2013,24 (7):1182-1190.
[10]XIANG Zheng,TAN Hengliang,MA Zhengming.Performance comparision of improved HOG,Gabor and LBP [J].Journal of Computer-Aided Design and Computer Graphics,2012,24 (6):787-792 (in Chinese). [向征,谭恒良,马争鸣.改进的HOG 和Gabor,LBP 性能比较 [J].计算机辅助设计与图形学学报,2012,24 (6):787-792.]
[11]Meng Y,Zou J,Gan X,et al.Adaptive WNN aerodynamic modeling based on subset KPCA feature extraction [J].Journal of Central South University,2013,20 (4):931-941.
[12]Rakotomamonjy A.Surveying and comparing simultaneous sparse approximation(or group-lasso)algorithms[J].Signal Processing,2011,91 (7):1505-1526.
[13]ZHANG Zhaoyang,TIAN Zheng.Adaptive kernel feature subspace method for efficient feature extraction [J].Pattern Recognition and Artificial Intelligence,2013,26 (4):392-401 (in Chinese).[张朝阳,田铮.特征有效提取的自适应核特征子空间方法 [J].模式识别与人工智能,2013,26(4):392-401.]
[14]Choi J H,Lee H Y,Lee H K.Color laser printer forensic based on noisy feature and support vector machine classifier[J].Multimedia Tools and Applications,2011:1-20.
[15]Zhao Y,Jia W,Hu R X,et al.Completed robust local binary pattern for texture classification [J].Neurocomputing,2012,106:68-76.
[16]ZHANG Jian.Research on character recognition of license plate recognition [J].Information Technology,2011,35(9):109-110 (in Chinese).[张剑.车牌识别中字符识别的研究 [J].信息技术,2011,35 (9):109-110.]
[17]Patel C,Patel A,Patel D.Optical character recognition by open source OCR Tool Tesseract:A case study [J].International Journal of Computer Applications,2012,55 (10):50-56.
[18]Erdinc Kocer H,Kursat Cevik K.Artificial neural networks based vehicle license plate recognition [J].Procedia Computer Science,2011,3:1033-1037.
猜你喜欢
高技术通讯(2021年2期)2021-04-13
电子制作(2019年12期)2019-07-16
测控技术(2018年10期)2018-11-25
计算机技术与发展(2017年12期)2017-12-20
成都信息工程大学学报(2017年3期)2017-11-09
小猕猴智力画刊(2017年5期)2017-05-25
计算机应用(2016年10期)2017-05-12
电子制作(2017年22期)2017-02-02
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
