
HDFS中高效存储小文件的方法
2015-12-23 01:06林涵阳
计算机工程与设计 2015年2期
尹 颖,林 庆,2,林涵阳
(1.江苏大学 计算机科学与通信工程学院,江苏 镇江212013;2.南京理工大学 计算机系,江苏 南京210094;3.江苏实达迪美数据处理有限公司,江苏 昆山215332)
0 引 言
目前,HDFS (Hadoop distributed file system)作 为Hadoop 分布式文件系统已经广泛用于各种大数据应用中[1,2],提供了高吞吐量的数据访问,适合存储海量的大文件。然而,在Web 2.0应用场景中,小文件数量呈几何级增长,HDFS在处理大量小文件时由于所有文件请求都需要单NameNode进行处理,性能十分低下[3],因此,优化HDFS存取大量小文件的效率是必要的。
在基于HDFS 存储海量小文件问题上,Bo Dong 等2012年通过实验验证了文件小于4.35 MB时,存取效率明显降低,因此将4.35 MB 作为大小文件的分界点更为合理[4]。在HDFS中文件系统的元数据挂载在Namenode内存中,文件系统所能容纳的文件数目由Namenode的内存大小决定。在HDFS使用小文件时需要大量的寻址和数据节点的跳跃来检索小文件的位置,若系统中存在1 000 000个文件,则需消耗300MB内存,当系统中文件上升到十亿级别或更多时就超出了名字节点的负载能力。从客户机的角度来看,HDFS是一个分为两级的分布式文件系统,所有文件和块映射的元数据查询事务都要经过NameNode,这样在面对高并发访问时是非常低效的;同时大量小文件的存在使得集群内部数据节点和名字节点之间心跳信号交换的信息量增加。
1 相关研究
目前针对小文件问题的解决方法主要有两种:一是HDFS系统 自带的Hadoop Archiver[5]和Sequence file[6]解决方法;二是在读取数据之前判断是否为小文件,若是则增加小文件处理模块[7]。
1.1 Hadoop Archiver和Sequence file
Hadoop Archiver是构建在HDFS之上的文件系统,将小文件存入HDFS块中打包成HAR 文件,从而有效的减少NameNode内存使用率,对客户端提供透明的访问,但由于读取过程为两层的索引文件和数据文件的读取,所以Hadoop Archiver在处理海量小文件读操作时并不高效。
Hadoop Sequence file为二进制键值对提供一个持久化的数据结构,可以作为小文件的容器,将大量小文件打包到Sequence file类中,有助于存储和处理小文件。使用Sequence file合并小文件可以有支持基于Record或Block 压缩,并且在MapReduce中支持本地任务获得较高效率,但文件合并过程一般需要消耗很长时间。
1.2 小文件处理模块
小文件处理模块通常是先判断文件是否为小文件,如果判断文件为小文件则将一定数量的小文件合并为大文件,同时为文件合并前后的对应关系建立索引,来提供对文件的访问。地理信息系统中结合WebGIS 数据的相关特征,将相邻地理位置小于16 MB的小文件合并成一个64 MB文件,并为其构建索引[8]。BlueSky 中国电子教学共享系统中,把属于同一课件的小文件合并成一个大文件,存放教学所用的PPT 文件和视频文件[9]。目前此方案仅仅成功应用在某种特殊文件存储上,并无不限应用的统一方案。
通过对已存在的海量小文件存储方案的研究,本文针对大量的小文件元数据信息给名字节点内存带来的压力,采用把由名字节点维护的文件系统的命名空间和块管理从名字节点中分离出来,利用NFS服务器同步系统中的元数据,以适应当前大数据时代数量不断增长的海量小文件的存储。针对Hadoop小文件处理低效的问题,修改文件和数据块之间的对应关系,允许在同一数据块中存储多个小文件,以此增加文件处理是的吞吐量,提高MR 效率。
2 基于HDFS处理小文件的优化方案
2.1 系统架构
在原HDFS中Namenode作为系统唯一的管理者,不仅负责文件和目录的相关事务还要处理文件的读写请求。小文件由于其文件数据较小,使得元数据在整个文件存储所占比例较大,因此给NameNode节点管理整个文件系统造成较大压力。所以在本系统中将文件和目录的管理同文件的读请求事务分开来处理,增加了负责响应客户端读文件请求的Read NameNode节点,以及NFS服务器。系统架构如图1所示。

图1 系统架构
对各节点进行说明:
PrimaryNameNode:继承自NameNode,作为主要的NameNode节点负责更新、创建、删除等逻辑操作,还负责DataNode之间的通信监控各个节点的状态。
ReadNameNode:继承自NameNode,它定期读取PrimaryNameNode存储在NFS上的日志来更新自己内存中的文件系统目录树元数据,和PrimaryNameNode联合完成原生的NameNode服务。
DataNode:此节点存储数据块,并向PrimaryNameNode和ReadNameNode同时发送心跳信息和BlockReport,其中包括Block的位置信息。
NFS 服 务 器:存 储PrimaryNameNode 和ReadName-Node的映像和日志。PrimaryNameNode提供一个基于HTTP的流式接口,NFS服务器利用NameNode内建的HTTP服务器,使用GET 操作,周期性的读取Primary NameNode命名空间镜像和镜像编辑记录,每次读取的结果都更新到系统中的元数据中。ReadNameNode读取此文件,更新内存中的元数据,并定时做CheckPoint,将映像和日志回写到NFS服务器。
客户端:此节点向ReadNameNode查询元数据信息。
文件系统的元数据存储在Read NameNode和Primary NameNode中,这些元数据主要为两种:目录树和块位置。作为文件系统的管理层,他们之间的元数据信息应该保持同步。其中数据块和DataNode的映射关系是通过同时向两个NameNode汇报来维持一致,而目录树的一致性则需通过使用NFS 服务器来完成。Primary NameNode将日志实时同步到NFS上,Read NameNode可以实时读取NFS 上的日志,通过日志回放,可以解决目录树信息一致的问题。
2.2 文件和数据块的对应方式
采用两种服务器Read NameNode和Primary NameNode分别完成客户端对文件的不同请求,这种方式可以提高HDFS中小文件的存取效率;修改文件和块的对应方式,允许一个块内存放多个小文件,可以增加小文件的管理能力和MapReduce计算小文件的能力。
HDFS中小文件小于数据块的大小,不会占用比存储原始文件占用磁盘空间更大的空间。对于小文件而言,存储在块中最多需要一次切割,因此索引节点中是数据块索引无需二次间接块、三次间接块等,保留i-node内索引,在NameSpace中增加块内偏移索引offset,用于查找文件在Block中的起始位置,文件和数据块的对应关系如下。
不在不同数据块内的大文件:文件名 {块ID+块内偏移索引offset}+ {间接块ID…}+{块ID+块内偏移+块内长度}
文件在一个数据块内:文件名 {块ID+块内偏移+块内长度}
其中,小文件的以字节为单位的长度作为块内长度。
在文件写入系统的时候根据文件长度判断文件是否为小文件,若是,则为小文件优先查找剩余空间大于文件的长度的数据块,若存在这样的数据块怎将该数据块剩余空间的起始位置作为文件在块中的偏移位置。若未写满的块中不存在剩余空间大于小文件大小的数据块,怎为该小文件分配新的未使用的数据块。
如此一来,Namespace中文件与数据块对应列表增加偏移量属性,但对于存储在同一数据块上的小文件来说,它们使用相同的块管理元数据,因此从总体上说元数据信息量减少了。
系统中文件和数据块的对应方式改变后,相应的小文件的索引方式也要修改。获取文件和数据块的位置信息是读写数据的前提条件。但对于小文件的开始位置不一定在数据块的起始处,所以针对修改小文件和块的对应方式后的读取,需要增加文件的块中偏移量参量。相应的读请求字段如图2所示。

图2 读请求字段
请求的前两个字段包括版本号和操作码,数据块ID 和数据块版本号,通过这两个参数数据节点可以确定操作的目标数据块。以上4个参数还不足以确定存储开始位置不在数据块起始位置的小文件,因而需要使用startOffset来定位小文件的开始位置和length获取要读取的文件的长度信息。
3 实验性能测试
系统构架图如图1所示,从逻辑上来看整个系统的节点包含NameNode、NFS Server、DataNode和Client这4种类型,Client和DataNode部署在同一节点上,共需6个虚拟节点,具体见表1。

表1 系统节点配置
Primary NameNode先启动,启动时首先判断本节点的角色,接着产生一个Read NameNode实例,对父类Name-Node初始化,同时启动Web服务器、RPC 远程过程调用服务器和相关服务线程;接下来启动Read NameNode;最后Primary NameNode和Read NameNode启动接收Client请求服务。
实验主要测试海量小文件同时上传和读取所需时间,以及各Deamon的内存占用情况。
(1)向HDFS上传文件和从系统中读取文件所需时间测试:测试所用文件数量250 000,文件大小在4K 和60 M 之间,平均大小31.2K,总大小7.42G。分别测试将这些小文件上传至原始文件系统和针对大量小文件优化后的文件系统的时间消耗,以及从原始文件系统中读取和从优化后的文件系统中读取文件的时间消耗。见表2。
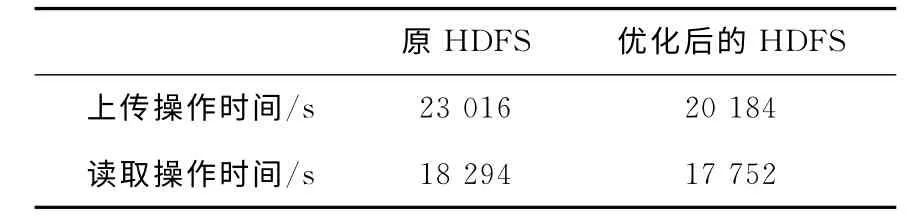
表2 用户操作原系统和优化后系统时间消耗
(2)平均内存占用情况:分别测试用户操作原始系统时NameNode内存占用率和优化后文件上传中Primary NameNode内存占用率、客户端请求读写文件时Read Name-Node内存占用率以及无读写操作时两种NameNode内存占用率。结果如图3所示。

图3 用户操作和无操作时原系统和优化后系统中名称节点内存占用率
4 结束语
本文针对HDFS云存储不适合大量小文件存储的问题,采用将读请求从NameNode任务中分离出来,使用NFS服务器同步文件元数据的策略,以提高整个系统中文件数量的容量,并且减轻Primary NameNode的作业量。这种机制解决了HDFS对小文件存储和计算能力低效的问题,但是由于相关的研究资料太少,只能通过分析源码来获取信息,而且其机制相对复杂,该方案存在一些不足之处。如Name-Node 的 FailOver[10]恢 复 没 有 改 善, 不 支 持 HDFS HA[11,12];同时,系统中存储元数据的NFS是单一故障点。但软件成熟可靠,坏的几率很小,该机制稳定性和性能有待进一步的检验。
[1]CHEN Xuwen,HUANG Yingming.Cloud computing technology and modeling of mass VOD system [J].Modern Electronics Technique,2013 (14):10-12 (in Chinese). [陈旭文,黄英铭.海量视频点播系统的云计算技术与建模实现 [J].现代电子技术,2013 (14):10-12.]
[2]SUN Yuancheng.Hadoop key support video surveillance technology research and application-based data center[D].Beijing:Beijing University of Posts and Telecommunications,2012 (in Chinese).[孙元成.基于Hadoop的视频监控数据中心关键支 撑技术研究与应用 [D].北京:北京邮电大学,2012.]
[3]WANG Linghui,LI Xiaoyong,ZHANG Yibin,et al.Mass small-file storage file system research overview [J].Computer Applications and Software,2012,29 (8):106-109 (in Chinese).[王铃惠,李小勇,张轶彬,等.海量小文件存储文件系统研究综述[J].计算机应用与软件,2012,29(8):106-109.]
[4]Dong Bo,Qiu Jie,Zheng Qinghua,et al.A novel approach to improving the efficiency of storing and accessing small fileson Hadoop:A case study by PowerPoint files[C]//IEEE International Conference on Services Computing,2010:65-72.
[5]Rajeev Gupta,Himanshu Gupta,Ullas Nambiar,et al.Efficiently querying archived data using Hadoop [C]//19th ACM Conference on Information and Knowledge Management,2010:1301-1304.
[6]Zhao Xiaoyong,Yang Yang,Sun Lili,et al.Metadata-aware small files storage architecture on Hadoop [C]//Web Information Systems and Mining,2012:136-143.
[7]YU Si,GUI Xiaolin,HUANG Ruwei,et al.Improving the storage efficiency of small files in cloud storage[J].Journal of Xi’an Jiaotong University,2011,45 (6):59-63 (in Chinese).[余思,桂小林,黄汝维,等.一种提高云存储中小文件存储效率的方案[J].西安交通大学学报,2011,45 (6):59-63.]
[8]Liu Xuhui,Han Jizhong,Zhong Yunqin,et al.Implementing WebGIS on Hadoop:A case study of improving small file I/O performance on HDFS [C]//IEEE International Conference on Cluster Computing and Workshops,2009:429-436.
[9]Bluesky’s integrated LiDAR imaging system [J].Highways,2012,81 (7):76.
[10]DENG Peng,LI Meiyi,HE Cheng,et al.Research on Name-Node single point of fault solution [J].Computer Engineering,2012,38 (21):40-44(in Chinese).[邓鹏,李枚毅,何诚,等.Namenode单点故障解决方案研究[J].计算机工程,2012,38(21):40-44.]
[11]Doug Henschen.NetApp teams with cloudera to back Hadoop[EB/OL].http://www.informationweek.com,2013.
[12]Oriani Andre,Garcia Islene C.From backup to hot standby:High availability for HDFS [C]//IEEE 31st Symposium on Reliable Distributed Systems,2012:131-140.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
高技术通讯(2021年5期)2021-07-16
当代陕西(2019年14期)2019-08-26
当代陕西(2019年13期)2019-08-20
魅力中国(2019年6期)2019-07-21
网络安全和信息化(2016年3期)2016-11-26
中学数学杂志(初中版)(2016年5期)2016-11-01
武汉理工大学学报(交通科学与工程版)(2015年5期)2015-12-05
测绘科学与工程(2014年5期)2014-02-27
测绘科学与工程(2014年2期)2014-02-27
