
数据中心网络TCP Incast仿真分析
2015-12-20 06:57郭丽娜
计算机工程与设计 2015年1期
郭丽娜
(中国航天科工集团第二研究院706所,北京100854)
0 引 言
由于数据中心网络需要可靠传输,所以在广域网成功应用多年的TCP可靠传输协议目前也普遍应用于数据中心网络中,但是本身针对于广域网环境设计的TCP协议并不适合高带宽、低延迟的数据中心网络环境,比如在网络中普遍使用的Linux 操作系统中,TCP 的重传超时计时器RTO 默认值为200ms,该值远远大于数据中心网络的平均RTT 值 (一般为10μs至100μs)[1]。
TCP Incast问题指[2]:在数据中心网络中,当多个发送者同时向一个接收者发送数据块时,随着发送者个数的增多,接收者的瓶颈链路吞吐率会急剧下降,产生吞吐率崩溃现象。由于这种多对一的网络模型在数据中心网络中普遍存在,所以TCP Incast成为数据中心网络传输性能的突出问题。
本文对TCP Incast问题进行了详细的介绍,并通过NS2仿真实验对该问题进行了深入的分析。
1 TCP Incast问题
1.1 问题背景
数据中心网络的环境特点和通信模型是导致TCP In-cast问题的主要因素。
数据中心网络链路为高带宽、低延迟链路;同一个机架上的服务器由一个架顶交换机[3](top of rack switch)链接,目前数据中心由于成本限制,采用的架顶交换机一般为商品交换机[4],具有浅缓冲区的特点;同时数据中心网络中大部分流量为短数据流[5],如搜索引擎的查询请求产生的数据流。
数据中心网络具有典型的划分聚合通信模型[4](Partition/Aggregate)。如图1 所示,当一个任务请求到来,由一个Aggregator将任务分配给下层的多个Aggregator,逐层下发后最终分配给实际执行任务的 Worker 节点。Worker执行完任务后将结果返回给上层Aggregator,Aggregator逐层向上汇聚,最后得到结果。数据中心网络中像搜索引擎这样对时效性要求严格的应用,在此过程中会限制延迟的时间,如果一个查询请求延迟限制 (deadline)为250ms,每一层划分都会缩小延迟限制值,超过deadline的任务就会被舍弃,影响最终结果的质量。
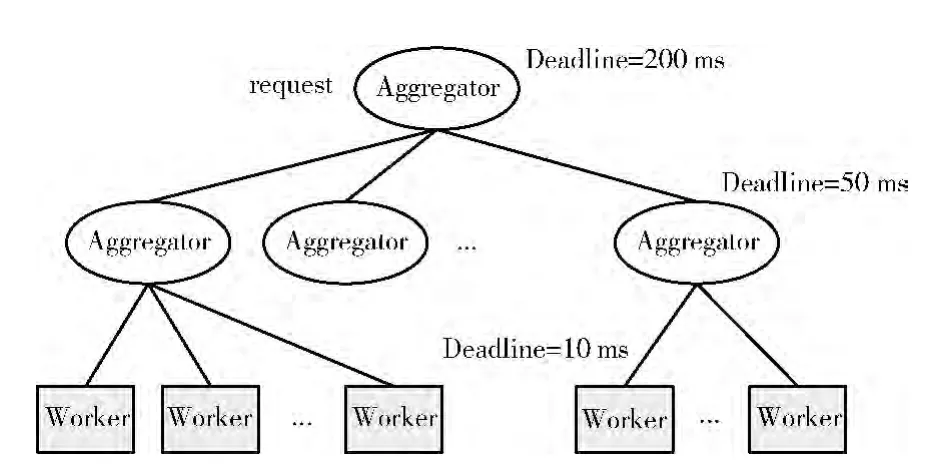
图1 划分聚合通信模型
划分聚合通信模型普遍存在于数据中心网络的应用程序中。例如搜索引擎:一个关键字的查询请求分发给多个Worker进行计算,然后将多个结果同时返回,最终汇聚给终端用户;MapReduce计算模型[6]:大量的key-value键值对中间结果从多个mapper同时发送汇聚给reducer;分布式存储集群[2]:多个存储节点向请求数据的节点同时发送应答。
1.2 问题描述
由以上背景可知,数据中心网络中普遍存在多对一的通信模型,如图2所示,当一个任务被分发给多个服务器处理后,多个服务器将执行结果同时发送给请求者接收端,同一批发送的执行结果称为数据块 (data block),其中每一个服务器发送一个服务请求单元 (SRU)。随着同时发送的服务器数量的增多,接收端与交换机之间的链路吞吐率会急剧下降,这种多对一发送模式下接收者吞吐率崩溃的现象称为TCP Incast问题。

图2 TCP Incast多对一场景
1.3 问题原因
产生该问题的主要原因是:①数据突发性同时传输,交换机浅缓冲区容量有限,导致缓冲区溢出,造成后到数据包的丢失;②大量丢包导致TCP拥塞控制,发送窗口减半,降低发送速率;③TCP 对丢包进行超时重传,根据RTO 默认值,超时一般会持续200ms,而数据中心网络中RTT (10μs至100μs)远远小于RTO,导致链路有90%以上空闲[2]。
2 NS2仿真实验设计
本文基于广泛使用的开源网络仿真平台软件NS2[7](版本为NS2.35),在Linux系统 (Fedora 13)下开发仿真实验程序并运行仿真实验。
如图3所示,采用多对一的网络拓扑结构,实线表示链路,所有链路带宽为1000 Mbps,链路延迟为25μs,交换机R0和接收者R1之间为瓶颈链路。虚线表示节点绑定的代理,每个发送节点绑定TCP 协议和FTP 应用,FTP发送SRU 大小256KB,接收者R1为每一个链接绑定接收代理TCPSink。仿真程序在所有发送者同一批SRU 都被接收到以后再发送下一批。
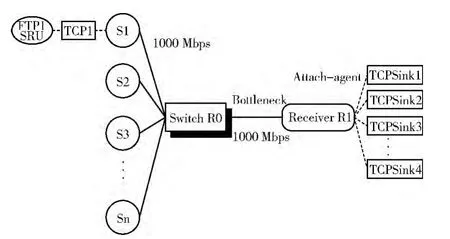
图3 NS2仿真网络拓扑
详细实验参数设置如表1所示。下一节将通过改变交换机缓冲区大小、SRU 大小和RTO 最小值来分析实验结果。当某一个参数变化时,其它参数保持不变。

表1 NS2仿真参数
实验结果主要考察瓶颈链路性能,即接收者R1的吞吐率随着发送端Server数量不同的变化情况。
3 实验及分析
3.1 TCP Incast现象
如图4所示,当同时发送的Server数量较小时,吞吐率在900Mbps左右,当Server数量增加到8时,吞吐率崩溃到100 Mbps 以下,产生TCP Incast现象,之后随着Server数量的增多,吞吐率一直徘徊在100 Mbps到200 Mbps之间。
实验结果与文献 [8]的结果一致,而文献 [2]中的复现结果在Server数量为4时吞吐率降低到300 Mbps到400 Mbps之间,之后再降低到100 Mbps。
3.2 不同TCP改进协议的性能

图4 TCP Incast现象
由于TCP拥塞控制算法和差错控制算法是影响TCP协议传输性能的主要因素,因此,我们实验比较了采用不同算法的几种典型的TCP改进协议在云数据中心网络环境下TCP Incast场景中的性能。主要实验测量了快速恢复算法的NewReno、选择性应答的Sack、二分搜索寻找目标窗口的Bic和通过上次拥塞事件消逝事件检测网络拥塞程度的HTCP。
如图5所示,以上4种TCP改进协议都产生了相同的吞吐率曲线趋势,没有改进TCP Incast问题。细微的差别只是产生吞吐率崩溃的Server数量略有不同。

图5 TCP改进协议比较
3.3 不同缓冲区大小条件的性能
由1.3节的问题原因分析可知,产生TCP Incast问题的关键在于交换机缓冲区过小导致的溢出和丢包。因此,我们通过调整缓冲区大小,实验比较了不同缓冲区大小条件下的传输性能。图6 显示了实验结果,当缓冲区由32 KB不断增大到1024KB 时,吞吐率崩溃发生的Server数量随之增大。
实验结果表明,通过增大瓶颈交换机缓冲区大小可以解决TCP Incast问题。但是该方法有两个缺点:一是大缓冲区的交换机价格很高,如Force10E1200价格约为5万美元[2],架顶交换机都增大缓冲区会提高数据中心建设成本,违背数据中心通过规模化经济原理降低成本的初衷;二是即使增大了交换机的缓冲区也会带来问题,如前面所述,数据中心网络多为延迟敏感的短数据流,大缓冲区会增大后到的短数据流排队等待的时间[4]。
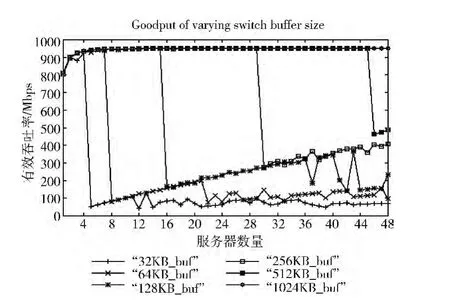
图6 不同缓冲区大小比较
3.4 不同服务请求单元条件的性能
如图7所示,实验结果显示,增大服务请求单元SRU的大小有助于减轻TCP Incast问题。当SRU 增大至8192 KB时,带宽利用率可以保持在80%以上。更大的SRU 使得发送端Server在等待超时事件发生的同时更有效利用链路空余带宽,减小等待超时对带宽利用率的损耗。

图7 不同SRU 比较
但是,该方法也存在以下两个缺点:
(1)大的SRU 在数据中心网络的大部分应用中是不可行的。数据中心分布式计算的宗旨就是将一个任务分散到大量的计算节点,每个计算节点快速地计算完成一个小数据块,最终汇聚返回结果。假设一个任务的总量为8 MB,若SRU 大至8 MB,则该任务只分配给一个计算节点,计算时间取决于单个节点处理8 MB 任务的时间;如果SRU为256KB,则该任务会分配给32 个计算节点,单个计算节点的计算时间明显较小。
(2)在快速的分布式存储系统中,更大的SRU 会增加请求端内核的内存压力,可能造成请求的失败[2]。
3.5 不同RTO 最小值条件的性能
如1.3节所述,造成TCP Incast问题的主要原因之一是TCP对丢包进行超时重传,而默认的RTO 远远大于数据中心网络的RTT值,重传等待造成链路空闲。如图8所示,减小RTO最小值有助于减轻Incast现象,提高吞吐率。

图8 不同RTO 最小值比较
TCP协议存在延迟ACK 概念,即不立即发送ACK,而是等待一段延迟时间将ACK 与该方向发送的数据包一起发送。Linux 系统默认的延迟ACK 等待时间为40 ms[9],当RTO 最小值减小至低于40ms时,将产生ACK 还未到达就超时重传的冗余现象。所以我们通过关闭延迟ACK 观察TCP Incast情况,如图9所示,在RTO 最小值默认200 ms时,关闭延迟ACK 对吞吐率没有影响;在RTO 最小值减小到40 ms和1 ms时,关闭延迟ACK 有助于提高吞吐率。
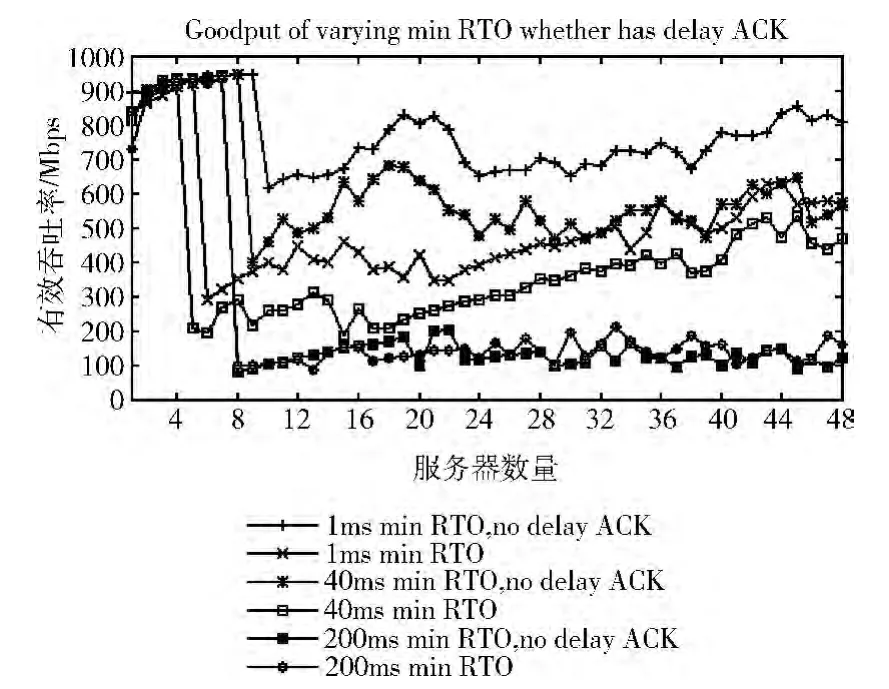
图9 不同RTO 及关闭延迟ACK 比较
但是该方法存在实现可行性和安全性两个缺点。首先,小的RTO 最小值需要操作系统很小的时钟粒度支持,现有的Linux 操作系统时钟粒度无法实现1ms 的RTO 最小值[2]。其次,过小的RTO 最小值可能导致大量不必要的重传,即使时钟粒度支持小RTO 的实现,对于其取值的权衡也需要进一步研究。
3.6 调整TCP拥塞窗口限值
通过对TCP Incast现象的深入分析,我们发现,造成吞吐率急剧下降的一个主要原因是各个服务器在传输时对发送速率缺乏约束,没有根据网络状况进行适应性调整。因此,我们根据网络状况,通过动态调整拥塞窗口限值来控制各个服务器的发送速率,使其不超过其公平分享带宽,以此避免拥塞发生,从而提高TCP Incast传输模式的传输性能。该算法主要原理如下:
首先,计算链路的容量

式中:BW——瓶颈带宽,RTT——往返时延,Queue——链路上的队列长度,其值主要由交换机的缓存大小决定。
然后,计算每个服务器流的公平分享容量

式中:N——同时传输的服务器流数目。然后,设置每个流拥塞窗口的限值为Cs。
在每次传输初始,系统计算好Cs,动态调整拥塞窗口限值,而不是采用固定的默认值。图10显示了在第2节介绍的实验配置下,采用动态拥塞窗口限值算法与默认情况的实验结果对比,从图中可以看出,采用动态拥塞窗口限值算法显著地提高了TCP Incast传输模式的性能。

图10 动态拥塞窗口限值效果 (1G 链路)
图11显示了在10G 瓶颈链路带宽环境下,采用动态拥塞窗口限值优化算法与默认窗口的实验结果对比,在10G高速网络环境下,在服务器数目较大时,该算法相对于1G链路带宽环境优势更明显。

图11 动态拥塞窗口限值效果 (10G 链路)
但是,调整拥塞窗口限值的方法具有依赖于计算和手动配置的局限性,难以适用于变化的环境。
4 结束语
本文通过NS2仿真实验对数据中心网络中的TCP Incast问题进行了研究。通过改变交换机缓冲区、服务请求单元SRU、RTO 最小值等影响因素进行实验和比较分析,发现增大缓冲区、增大SRU、减小RTO 最小值以及在小RTO 情况下关闭延迟ACK 等方法可以减轻TCP Incast问题,但是这些方法在数据中心网络中都存在缺点和局限性。由于TCP拥塞控制算法是影响TCP 协议性能的一个主要原因,而标准TCP协议拥塞控制算法是针对低带宽低时延的网络环境设计的,现有主流的各种TCP改进协议的拥塞控制算法主要是针对高带宽高时延网络进行改进的,在低带宽低时延的云数据中心网络环境中性能同标准TCP一样性能不佳,因此,要从根本上解决云数据中心网络中TCP Incast性能问题,需要研究针对云数据中心网络特点的TCP拥塞 控制算法和 传输协议[3-4,10-12]。
[1]Chen Y,Griffith R,Liu J,et al.Understanding TCP Incast throughput collapse in datacenter networks [C]//In Proc 1stACM Workshop on Research on Enterprise Networking,2009.
[2]Phanishayee A,Krevat E,Vasudevan V,et al.Measurement and analysis of TCP throughput collapse in cluster-based storage systems[C]//Proceedings of the 6th USENIX Conference on File and Storage Technologies,2008:1-14.
[3]Wu H,Feng Z,Guo C,et al.ICTCP:Incast congestion con-trol for TCP in data center networks[C]//In ACM CoNEXT,2010.
[4]Alizadeh M,Greenberg A,Maltz D,et al.Data center TCP(DCTCP)[C]//In Proc ACM SIGCOMM,2010.
[5]Kandula S,Sengupta S,Greenberg A,et al.The nature of datacenter traffic:Measurements and analysis [C]//In Proc of Internet Measurement Conference,2009.
[6]Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[C]//6th Symposium on Operating Systems Design and Implementation,2008:137-149.
[7]The network simulator-ns-2[EB/OL].[2013-09-01].http://www.isi.edu/nsnam/ns/.
[8]Zhang J,Ren FY,Lin C.Modelling and understanding TCP Incast in data center networks[C]//Proceedings of the 30th IEEE International Conference on Computer Communications,2011.
[9]Vasudevan V,Phanishayee A,Shah H,et al.Safe and effective fine-grained TCP retransmissions for datacenter communication [C]//In Proceedings of the ACM SIGCOMM,2009:303-314.
[10]Adrian S-W Tam,Kang Xi,Yang Xu,et al.Preventing TCP Incast throughput collapse at the initiation,continuation,and termination [C]//In Proc IEEE 20th International Workshop on Quality of Service,2012.
[11]Jaehyun Hwang,Joon Yoo,Nakjung Choi.IA-TCP:A rate based Incast-avoidance algorithm for TCP in data center networks[C]//In Proc IEEE International Conference on Communications,2012:1292-1296.
[12]Jun Zhang,Jiangtao Wen,Jingyuan Wang,et al.TCP-FITDC:An adaptive approach to TCP Incast avoidance for data center applications[C]//In Proc ICNC,2013.
猜你喜欢
网络安全和信息化(2018年6期)2018-11-07
沈阳工业大学学报(2018年1期)2018-01-08
水利规划与设计(2017年11期)2017-12-23
网络安全和信息化(2017年8期)2017-11-07
环境保护与循环经济(2017年8期)2017-03-22
工程建设与设计(2016年1期)2016-02-27
项目管理技术(2015年3期)2015-04-23
电测与仪表(2015年22期)2015-04-09
电子设计工程(2015年6期)2015-02-27
自动化博览(2014年9期)2014-02-28
