
分存技术在代码混淆中的研究
2015-12-20 06:57杨秋翔陈够喜牛文瑞
计算机工程与设计 2015年1期
杨秋翔,王 蕊,陈够喜,牛文瑞
(中北大学 计算机与控制工程学院,山西 太原030051)
0 引 言
近年来,软件破解者不断运用逆向工程技术对软件代码进行静态分析、动态跟踪等攻击。代码混淆技术[1-2]通过代码变换来降低程序的可理解性,使代码更难于被静态分析,增加了软件被篡改或非法复用的难度。其中,代码控制流混淆是当前代码混淆技术中的研究热点。目前,存在着许多种代码控制流混淆变换[3-4],但都由于变换形式过于单一,很容易被逆向工程所过滤。针对这种情况,文献[5]提出不透明谓词变换和降级高级控制结构变换,加大了反编译及逆向工程的难度;文献 [6]提出插入垃圾代码的改进的控制变换,增加了防止破解者静态分析的能力;文献 [7]提出混沌不透明谓词变换,尽可能地防止破解者对代码进行静态攻击。但是这些变换最终无法确定代码的混淆强度是否足够抵抗攻击,并且无法动态地检验破解者的非法操作。
针对混淆强度和动态检验非法操作的问题,本文在现有的代码控制流混淆变换的基础上,提出了一种基于分存技术的代码控制流混淆方法。该方法将分存技术与常规控制变换相结合,并应用于软件的注册验证机制,改变了代码的控制流结构,增加了破解者攻击软件的难度,具有足够的混淆强度,能够随时检验破解者的非法操作,成本较低且易于实现,在一定程度上实现了对代码的安全保护。
1 相关定义
定义1 Bernstein多项式。设f(x)∈C [0,1],n∈Z+,则Bernstein多项式函数Bn(x)定义为
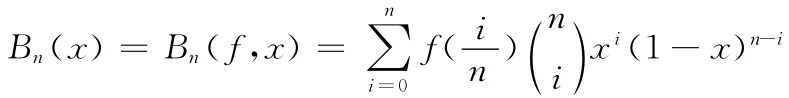
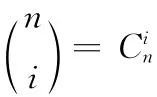
定义2 不透明谓词。设i∈ {1,2,…,n},-Pi,当程序中点p 上的输出在混淆程序之前就已确定时,称谓词Pi在点p 上是不透明谓词。如果Pi的输出一直为真,就记作 (Pi)T;如果Pi的输出一直为假,就记作 (Pi)F;如果Pi的输出时为真时为假,就记作 (Pi)?。
定义3 偏好关系。设非空集合M= {mi,i=1,2,…,n}是定义于RN+上的抵抗破解者逆向工程的所有可选方法的集合,如果对于M 中的任意两种方法存在关系:m1m2,就可认为用户对方法m1的评估偏好于方法m2。
假设软件破解者对程序实施攻击,用户分别用方法m1和m2进行代码保护。在理想条件下,任何代码都可以被逆向工程所攻击,因此可将获得逆向工程所需的难度系数记为s(m1)与s(m2)。若s(m1)>s(m2),则说明使用方法m1保护代码更难被逆向分析,即s(mi)可表示为当用户使用方法mi保护代码时破解者的攻击复杂度。由于偏好的方法能够造成破解者的攻击复杂度加倍,所以s(·)就能够反映出偏好关系,于是用户更偏好的方法总能被s(·)赋一个更高的值,即m1m2s(m1)≥s(m2)。
2 基于分存技术的代码控制流混淆方法
2.1 分存技术
分存技术是将一个单载体分解为若干个多载体再进行传输或存储的过程,用来增强载体信息的安全性。已有的实现分存技术的方法包括基于Lagrange插值、基于Bernstein多项式和基于中国剩余定理。由于利用基于Bernstein多项式的分存技术对载体进行分存可以实现从离散到连续的推广,所以本文采取Bernstein多项式把软件密钥分解为若干个加密算法不同的密钥段,进而在软件程序中实现分存,以便增加代码的安全性。
由定义1可推导为
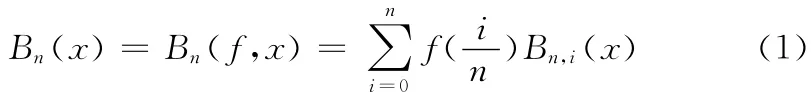
设∑:f=f(u,r)为一参数曲面,f(u,r)= {fi,j︱i=0,…,n1,j=0,…,n2}, (u,r)D∈R2,对式(1)Bn(x)进行扩展,可得二维乘积型Bernstein多项式函数为
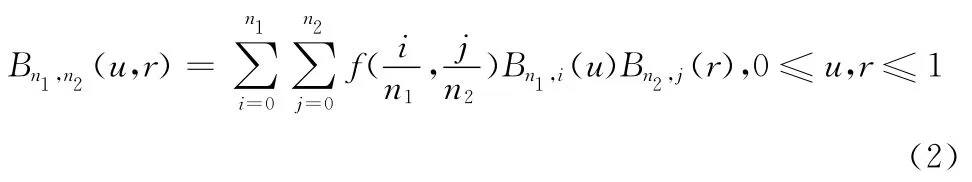
根据式 (2)可知二维乘积型Bernstein多项式函数可构成Bézier曲面,即两组Bernstein多项式函数在D= [0,1]× [0,1]上可构成n1×n2次Bernstein-Bézier曲面为
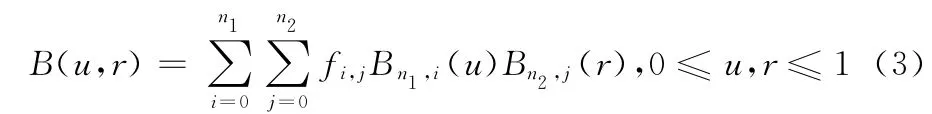
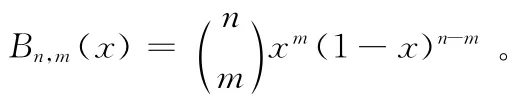
利用基于Bernstein多项式的方法对载体进行分存,把软件的密钥按照定义1分解为不同加密算法的若干密钥段,进而推导出式 (1)、式 (2),再根据用户与若干密钥段间的映射关系函数,运用式 (3)构造出多个不同的Bernstein-Bézier曲面参数方程,进而把这些曲面参数方程看作验证函数,最终将它们隐藏在程序代码中实现分存技术。
由于构造出了多个互不相同且个数未知的验证函数,所以通过任意一个验证函数的验证都只是判断用户是否合法的必要条件,不是充分条件,真正合法的密钥需要通过所有验证函数的验证。即使破解者攻击了验证函数中的任意几个,也无法确定其总共的个数,也无法求得密钥中任何一段的内容。即使破解者攻击了所有的验证函数,也必须具有一定深度的数学功底才能求得密钥。同时为了保护验证函数,可对其使用不同的加密算法来增强加密强度,尽可能地防止破解者通过验证函数破解密钥。
2.2 改进的代码控制流混淆方法
代码控制流混淆是在软件发布前对程序代码的控制流程进行变换的过程,该变换在不改变程序执行结果的前提下,尽可能地使得控制流复杂化,降低程序的可读性,模糊程序的逻辑关系,提高程序的抗攻击能力。现有常用的代码控制流混淆方法有插入垃圾代码、使用不透明谓词、扩展分支跳转和循环条件等[8]。
本文改进的代码控制流混淆方法的思想是:将分存技术应用于代码控制流混淆,使构造出的多个互不相同的验证函数分别与不透明谓词和分支函数相结合,共同插入到程序代码中。由于程序的跳转表恢复机制是根据分支函数的判断条件来控制跳转的目的地址的,所以本文将在顺序执行语句块中构造出多个分支控制流,利用跳转地址的重定向来混淆跳转表恢复机制,使得原有的顺序流程变为选择分支,更好地改变程序代码的控制流结构且不影响其执行过程,能够加大混淆的强度,阻碍软件破解者获得准确程序代码的信息,还可以动态地验证非法性操作。
(1)验证函数与不透明谓词的结合
由于验证函数和不透明谓词都可以通过布尔值确定程序代码的控制流方向,于是可以将其共同作为判断条件插入顺序执行语句块,构造出伪分支控制流。根据定义2在程序中点p 上分别插入永真不透明谓词 (Pi)T和永假不透明谓词 (Pi)F,设j∈ {1,2,…,n},验证函数的表达式为Fj,具体的插入情况如图1、图2所示。
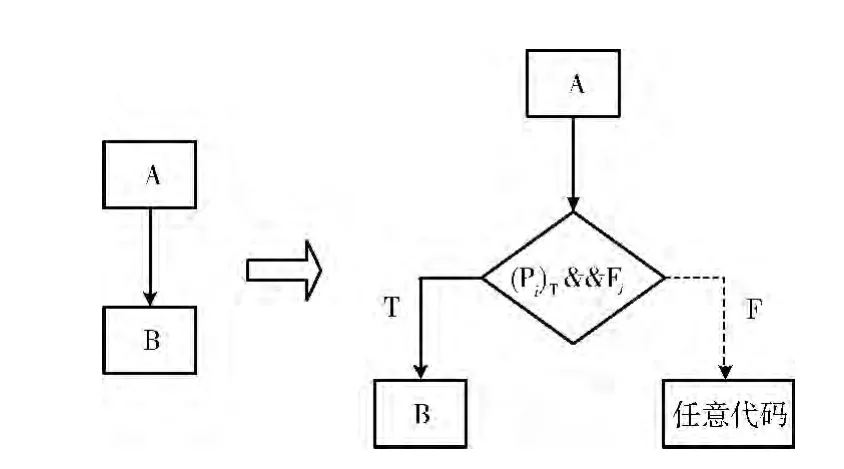
图1 顺序执行块中插入验证函数与永真不透明谓词
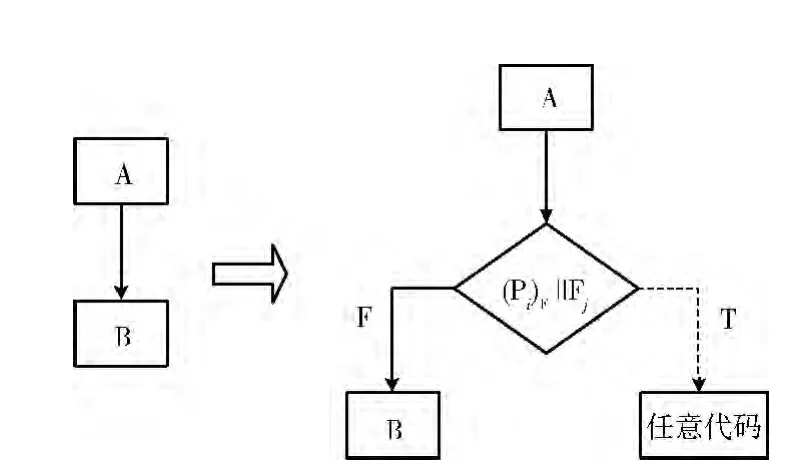
图2 顺序执行块中插入验证函数与永假不透明谓词
图1表示在顺序语句A 和B中间插入的判断条件是永真不透明谓词和验证函数表达式相与的运算,即插入之后的表达式为 (Pi)T&&Fj,并且构造出了两个分支控制流。假定A 通过了Fj的验证,则和 (Pi)T相与后的结果依旧为真,而反之若未能通过验证,则和 (Pi)T相与后的结果依旧为假。将B放在分支结构为真的部分,为假的部分放入不会被真正执行的任意代码,使得插入判断条件后不改变程序真正的执行过程。
图2表示在A 和B中间插入的判断条件是永假不透明谓词和验证函数表达式相或的运算,即插入之后的表达式为,同样构造出了两个分支控制流。假定A 通过了Fj的验证,则和 (Pi)F相或后的结果依旧为真,而反之若未能通过验证,则和 (Pi)F相或后的结果依旧为假。将B放在分支结构为假的部分,为真的部分放入不会被真正执行的任意代码,同样使得插入判断条件后不改变程序真正的执行过程。
(2)验证函数与分支函数的结合
基于分支函数的代码控制流混淆思想是将程序代码中的直接跳转语句构造为对分支函数的调用,使用分支函数替代直接跳转,并且返回条件跳转语句的目的地址[9]。将验证函数与分支函数相结合,进一步扩展成用验证分支函数替代直接跳转语句,实现程序代码的控制流混淆,具体的插入情况如图3所示。
图3表示在顺序结构的分支跳转中插入验证分支函数,利用验证分支函数来验证并修改分支调用函数的目的地址,最终返回程序真正的目的地址,不改变程序的执行过程。
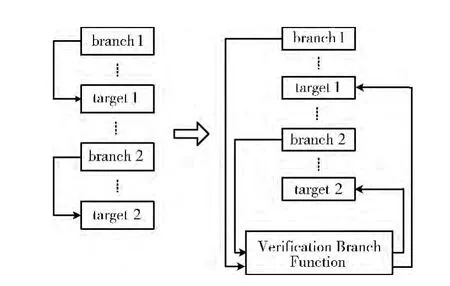
图3 直接跳转结构中插入验证分支函数
验证分支函数采用多重重定向结构,如图4 所示,构造出n个分支函数,其中含有1个正确的调用分支和n-1个设置了虚假函数返回地址的伪调用分支,于是跳转表恢复机制将产生一个包含大量虚假目的地址的跳转表,使得软件破解者无法正确定位程序代码真正的目的地址。由于在调用验证分支函数后,系统会根据跳转表恢复机制中的跳转目的地址执行被调函数,并立即把被调函数的返回地址压栈,再返回调用函数处继续顺序执行下一条语句,所以在调用函数后加入若干垃圾代码以及多个验证函数,一方面能够使得破解者进入大量的混淆代码中,返回到调用函数处的下一条语句中的虚假目的地址,造成对程序的理解错误;另一方面能够在返回真正正确的目的地址之前,检测程序是否被攻击,一旦被攻击,验证分支函数将返回错误的目的地址,响应程序运行异常。
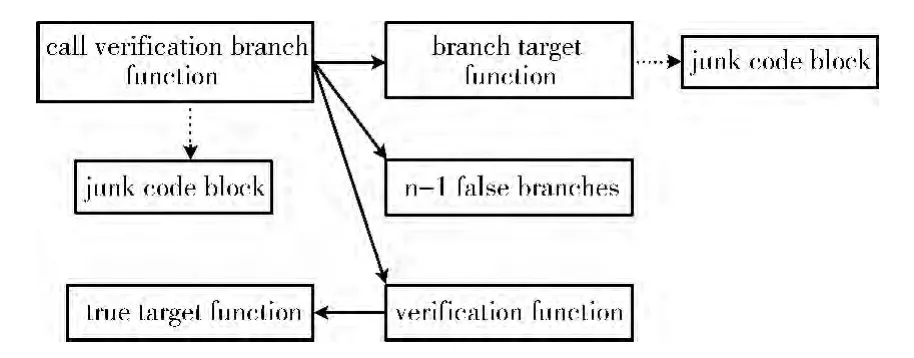
图4 验证分支函数多重重定向结构
综上所述,程序代码的控制流依赖于分支函数内部对判断条件的控制变量的修改,扩展分支函数是利用间接控制分支跳转来加大条件结构的复杂度,达到混淆代码的效果。为了隐藏跳转的实际目的地址,使分支函数的真出口为条件跳转的目的地址,假出口为使其跳转到原程序接下来的下一条语句,并保证原程序模块间的相对执行顺序和功能不变。通过重构控制结构,能够有效地提高软件抵抗攻击的能力,达到更深一层次的代码保护。
3 实验分析与验证
代码混淆的目的是保证软件代码的安全性,使代码更难于被静态分析或逆向工程。在实际应用中,许可注册验证模块属于软件代码的敏感环节,为了防止攻击者破解注册机,进而对关键代码进行篡改或非法复用,应对注册码验证过程实施有效的防范措施,于是选用基于分存技术的代码控制流混淆方法。设用户码为u,注册码为rj,注册机为fj,验证函数为Fj,j∈ {1,2,…,n},具体操作的一般步骤如下:
(1)将软件密钥r分存成若干段rj;
(2)构造不同的f映射关系,使得:rj=fj(u);
(3)构造曲面参数方程Fj(u,rj),使得:Fj=fj-1;
(4)将Fj结合常规控制流混淆方法插入软件代码,使代码达到足够的混淆强度。
本文提出的基于分存技术的代码控制流混淆方法能够混淆软件代码的控制流程,增加破解者攻击代码的难度,动态地保证注册码验证的安全性,有效地保护代码的安全。具体可从如下几方面验证:
首先,结合上文提到的两种控制变换方法,对一段小程序进行控制流混淆变换,用反汇编工具Ollydbg2.01b对其进行反汇编分析,结果如图5、图6所示。

图5 原始程序的反汇编指令

图6 控制变换后程序的反汇编指令
由图5和图6中可以看出:将举例小程序中的直接跳转和循环函数的结构改造成了调用复杂的多分支函数的结构,利用不透明谓词,在代码中加入了不会被程序执行的混淆跳转,导致变换后的代码出现了与原始代码结合的难以分析的垃圾代码,造成了反汇编结果的错误,扰乱了代码的控制流结构。由于最终提升了破解者恢复出原有程序控制流结构的难度,所以能够证明这个方法起到了混淆代码的作用。
其次,由于对于软件代码没有绝对安全的保护措施,只要破解软件的难度大于获得合法软件的代价时,就可认为该措施是合理安全的,于是从攻击者破解软件的复杂程度的角度出发,采用将加入分存技术后的控制变换与原始的控制变换的攻击复杂度作对比的方法,判断本文改进方法的混淆强度是否足够抵抗攻击,进而验证改进方法的正确性和有效性。
以Matlab 8.0为实验平台,选取10个程序代码段,比较攻击者欲想成功破解经过两种方法处理的软件所需的攻击复杂度,实验结果如图7所示,K 表示千行。
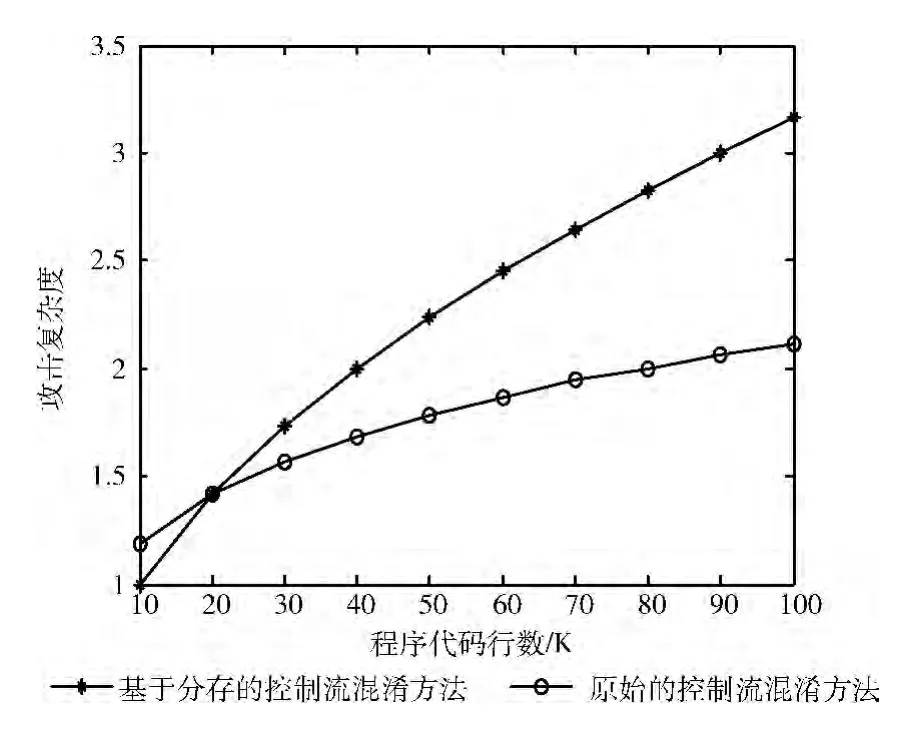
图7 两种方法处理的抗攻击性比较
从图7中的曲线趋势可以看出:随着程序代码的行数增加,会隐藏更多个不确定的Fj,经过它们在程序内部不断地验证安全性和混淆控制流,会导致破解者攻击Fj的攻击范围逐渐扩大,以至于攻击程序代码的难度相应增大,即开发者使用基于分存技术的代码控制流混淆方法导致的攻击者所需攻击复杂度的倍数大于使用原始的代码控制流混淆方法。同时,把改进方法看作方法m1,原始方法看作方法m2,从实验结果可以得出:s(m1)>s(m2),根据定义3足以说明m1与m2满足关系:m1m2,即改进方法是偏好于原始方法的。经过计算得出,当程序代码为106行时,使用改进的方法进行代码保护效果更优,破解者的攻击将高达10倍于软件代码的保护能力才能够破解成功[10]。改进方法在一定程度上抵抗攻击性强,更适用于大型软件代码的保护。
最后,由于构造的验证函数Fj的个数未知,并且可以存在于代码中的任何位置,所以不易被攻击者发现,隐蔽性较强,使得攻击者根本无法完全了解注册机f的映射关系。将密钥r以密文的形式写入一个自定义格式的数据文件,注册登录时使用F1进行验证,如果验证通过就显示注册成功。将其它的Fj-1隐藏在程序中或与不透明谓词和分支函数相结合,每当程序顺序执行到该处或者用户后续执行特定的操作的时候才会被调用。但是一旦任意一个F 验证到r非法,程序就会清除r并将软件初始化,恢复为未注册状态,实现动态地判断非法操作,时刻验证安全性,以便保护代码的安全。综上所述,基于分存技术的代码控制流混淆方法是一种可行有效的代码保护方法。
4 结束语
因为代码混淆技术只要能够有效地延缓被静态分析及逆向工程就达到了保护代码的目的,所以随着研究的深入,会被更加广泛地应用。本文用基于分存技术的代码控制流混淆方法对软件代码的薄弱环节注册码验证进行保护,与采用原始方法相比,具有更好的混淆效果,增大了破解者的攻击复杂度,增加了软件的抗攻击能力,在一定条件下保证了程序抵抗逆向工程的能力。不过本方法更适合于大型软件代码的保护,需要在日后进一步研究更全面性的保护并考虑开销问题。
[1]ZHAO Yujie,TANG Zhanyong,WANG Ni,et al.Evaluation of code obfuscating transformation [J].Journal of Software,2012,23 (3):700-711 (in Chinese). [赵玉洁,汤战勇,王妮,等.代码混淆算法有效性评估 [J].软件学报,2012,23 (3):700-711.]
[2]XU Changzheng,DU Yujie,CHEN Yan,et al.Research of code obfuscation and its efficiency [J].Application Research of Computers,2009,26 (9):3502-3505 (in Chinese).[徐长征,杜玉杰,陈岩,等.代码迷惑及其有效性研究 [J].计算机应用研究,2009,26 (9):3502-3505.]
[3]Hang JC.Research and implementation of a code obfuscation algorithm based on control flow flattening [D].Xi’an:Northwest University,2010.
[4]YANG Le,ZENG Fanxing,HE Huojiao,et al.Research of obfuscating algorithms based on the garbage code [J].Microelectronics & Computer,2011,28 (4):127-130 (in Chinese).[杨乐,曾凡兴,何火娇,等.一种基于垃圾代码的混淆算 法 研 究 [J].微 电 子 学 与 计 算 机,2011,28 (4):127-130.]
[5]FU Jianjing.Application of transformation techniques for code obstructing to software protection [J].Computer Applications and Software,2008,25 (4):103-105 (in Chinese). [付 剑晶.代码干扰变换在软件保护中的使用 [J].计算机应用与软件,2008,25 (4):103-105.]
[6]JIANG Hua,LIU Yong,WANG Xin.Code confusion technology research based on control flow [J].Application Research of Computers,2013,30 (3):897-899 (in Chinese).[蒋华,刘勇,王鑫.基于控制流的代码混淆技术研究 [J].计算机应用研究,2013,30 (3):897-899.]
[7]SU Qing,WU Weimin,LI Zhongliang,et al.Research and application of chaos opaque predicate in code obfuscation [J].Computer Science,2013,40 (6):155-159 (in Chinese).[苏庆,吴伟民,李忠良,等.混沌不透明谓词在代码混淆中的研究与应用 [J].计算机科学,2013,40 (6):155-159.]
[8]WANG Chaokun,FU Junning,WANG Jianmin,et al.Survey of software tamper proofing technique [J].Journal of Computer Research and Development,2011,48 (6):923-933(in Chinese).[王朝坤,付军宁,王建民,等.软件防篡改技术综述 [J].计算机研究与发展,2011,48 (6):923-933.]
[9]SHANG Tao,GU Dawu.Research on resistance to disassembly of software [J].Application Research of Computers,2009,26 (12):4553-4557 (in Chinese).[尚涛,谷大武.软件防反汇编技术研究 [J].计算机应用研究,2009,26 (12):4553-4557.]
[10]WANG Rui,YANG Qiuxiang,CHEN Gouxi,et al.Software protection game model based on divided-storage strategy[J].Journal of Computer Applications,2013,33 (9):2525-2528 (in Chinese). [王蕊,杨秋翔,陈够喜,等.基于分存策略的软件保护博弈模型 [J].计算机应用,2013,33 (9):2525-2528.]
猜你喜欢
数字技术与应用(2021年5期)2021-06-29
电子科技(2021年2期)2021-01-08
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
计算机工程与设计(2020年11期)2020-11-17
西夏研究(2020年2期)2020-06-01
电子技术与软件工程(2017年24期)2018-01-17
软件工程(2016年11期)2017-01-17
外语学刊(2016年4期)2016-01-23
电子设计工程(2015年6期)2015-02-27
新媒体研究(2009年4期)2009-03-14
