
网络大数据基准测试程序拟定与探讨
2015-11-29 12:35:40高加琼
四川职业技术学院学报 2015年3期
高加琼
(四川职业技术学院计算机科学系,四川遂宁629000)
网络大数据基准测试程序拟定与探讨
高加琼
(四川职业技术学院计算机科学系,四川遂宁629000)
利用基准测验流程来检验计算机装置处理数据的性能表现是目前采用的主要方式,但是,至今还没有一个成熟完善且被业界普遍遵循的基准检验方案问世,特别是悄然而至的大数据涌潮给当今社会带来了更为艰巨的问题,为求得较理想的测验方案,本文依托具体的大数据平台拟定了一套Hadoop系统的交通事务大数据基准捡验流程.经挑捡若干个属性等级的项目,把流程内容特点进行数量化处理,并选取以同类相聚的计算方法,评估每一个流程的输进参数集合的近似程度,参照类别聚集情况,给基准测验确定了典型的流程及输进参数集合.最终,经过实践检验证明,该基准测验在符合流程内容广泛性的前提下,彻底去掉了基准测验集合中的多余成分.
大数据基准测验流程;输进参数集;流程近似性;交通信息
由于网络技术的不断发展和持续地扩大应用领域,人类的生存已进入了大数据时代,据有关资料公布显示,二零一一年度,全世界I P终端客户占人口总数的32.77%.此数据标志着地球上生存的二十三亿人随时都在不断地创造新的参数.二零一二年三月,相关公司通报全球一日创造的参数量可跃及2.5E B(每E B等于一亿G B)[1].
大数据具备不同于其他数据的特点,其具有四个“V”的特性,即Volume(数据量大)、Velocity(速率高)、Varity(种类多)和Value(价值高).数量大,说的是一个参数集合规模突破了P B等级或更多;速率高,说的是其参数量的速率提高的相当迅速;数据样式复杂,其包括各类随机显现、没有确定性趋势的、不宜记录于常规记录表中的参数等等,其中相当量的参数是来自于各行业的视觉、语音及日复一日的常规记录.然而,绝大部分数据不具备足够的应用价值,在应用前必须经过筛选、提质和交融等过程[4],且需要运用几率话题模型来描述和解决,几率话题模型是一系列旨在发现隐藏在大规模文档中的主题结构的算法.几率话题模型见图1,其中,α和β表示语料级别的参数,θ是文档级别的变量,每个文档对应一个θ,X和Y都是单词级别变量,X由θ生成,Y由X和β共同生成.

图1 几率话题模型
针对这些严峻的实际现状,优质的大数据处理程序的问世显得尤为迫切,以攻克社会、团体和个人用户在生存过程中面临的诸多新难题,为他们的工作、学习和生活带来实实在在的方便,为人类社会大数据课题的解决提供技术支撑.出于更优质高效地调控和精确地评估此类庞大繁杂的参数集合体系的目的,业界不断推出各类型的处理大数据程序流程,但不如人愿的是,至今仍无一套既可用来调理和评判如此相异的大数据体系、且能客观地显现相关体系的性质区别的普遍基准测验方法集合.正是这些大数据的特性给其基准测验集合的编制造成了相当高的难度[2].
1 大数据基准检验流程集合编制的关键内容
编制大数据基准测验流程集合基本要应对五个方面难题:(1)该体系的繁杂程度严重制约着拟制一套标准的基准检验样板模型的进程;(2)该体系内运用范畴的复杂性给选择有代表性的运用流程增加了很大难度;(3)该体系内的参数量规模也给基准检验流程的再现过程造成了相当程度的难题;(4)该体系的迅捷演变也期待着基准检验包变更能够配合上参数体系的演变[3];(5)不具备可以当做基准检验流程输进的实际参数.上述难点的存在致使至今尚未获得一套被普遍赞同的大数据基准检验流程集合.
2 现实已存在的大数据基准检验流程集合
大数据基准检测流程具有相当的重要性,许多业内专家早就涉入有关内容,部分知名I T运营商及学术单位也相继推出各自体系的大数据基准检测流程集合,但是,这部分检测流程集合均带有不同种类和程度的缺陷或弊病.
H i B ench属于一类配合于H adoop体系的基准检测流程集合,所推出的基准检测流程既涵盖组合的基准检测,又囊括实际的运用流程,它把流程运作持续耗费时间及体系进出比率当作基准检验的估判标准[3];某一直属于云服务的流程集合,推出了一整套重点基准检测流程及负荷产出手段,此类负荷能够恰当比较4类云服务系统的性质特点,给基准检测客户挑捡最佳处理措施创造了基础,我国科研单位也随之推出了针对特殊应用范畴的大数据基准检验流程集合.上面所述是3个各具特色的成功例证.现时所推出的三种相异的基准检验流程集合都很理想的完成了本系统的基准检验所需内容,然而它们的有关表述里却未说明怎样挑拣基准检验流程及给个别的基准检验流程选取输进参数集合,并且能给予其客观实际的输进参数集合[3].
3 大数据基准检验流程集合的条件需求
与常规基准检验流程集合相同,大数据基准检验流程集合亦必须符合下述6个项目的标准:
(1)大数据基准检验流程需要应用到各个事业范畴,或相同范畴的诸个侧面.现实社会,基本的大数据普及范畴包括学术研讨、保健医护、交易场所、金融保险、信息传输、社会交往传媒机构以及零散销售等领域,此类各异的应用范畴给大数据体系赋予了各式各样的需求内容[1].
(2)大数据基准检验需要包括各种参数类型,如是否具有结构性的参数,实际来说需要涵盖取自于社会交往系统的图参数、流态式参数、地理情况参数及遗传基因参数等.基准检测集合的编制需要由运用流程等级起步,于此部分相异参数类别内选择共存的重点参数运作流程,比如编排顺序等内容[2].
(3)大数据基准检验流程需选取组合参数.当做大数据的基准检验过程时,由I T网络上下载具体的大批量参数集合成本相当高,况且凭借现实的I T宽带进行传送大数据集合也比较脱离客观实际,所以,大数据基准检验集合需要编制出组合参数的计算方法及手段[4].然而,针对如此要求,行业内具有相当多的不同意见,其中许多专家提出,组合参数不便于模拟实际参数集合所呈现出来的过程和内容,笔者也认可这一论断.
(4)大数据基准检验必须顾及参数的隐私及安全要求。部分大数据集合里涵盖了应当保密的资料,比如病人的诊断医治资料、保险单位的业务资料及有关军队国防材料等,所以,大数据基准检验应用人员时,供给单位应实行保障隐私不被泄露的大数据处理过程.
(5)该基准检验过程必须顾及流程的稳妥性。部分大数据体系时常进行较大规模运算过程以及应对相当量的数据流资料运算,这种情况下,必须要有确定的稳妥性能,此番的运用过程相对于大数据运作流程都显示了对其稳妥性的需求.
(6)大数据基准检验要求需要吸取以往的成熟操作经验,当在编制大数据基准检验时,需要吸取在过去电脑条件时就早已成为普遍遵循的基准检验原则,这样的原则内容已有若干种.要借鉴它们的编制模型过程及性质估判要求等,有时还可以在它的现有条件下利用单独增加效能、增加大数据基准性能等手段进行编制大数据基准检测集合.
4 大数据基准检验流程集合的编制过程
大数据基准检验流程集合的编制过程基本有两项内容组成:(1)挑拣典型的基准检验流程;(2)给各个基准检验流程挑拣匹配的输进参数集合.另外,其捡验集合尚需符合前面几项原则.
要具备此两种性质,还要处理好下面几种事项:
(1)挑选典型的基准检验流程;
(2)评估若干种基准检验之间的流程运作属性之相近内容,在维持流程运作方式比较多的前提下,消除多余的成分;
(3)给预设的基准检验流程挑拣匹配的输进参数集合;
(4)给基准检验流程确定评判标准.
此小节对SI A T-B ench的编制措施及前期结果做以初步阐述.
4.1 确定有代表性的运用流程
由图1可见,某个有代表性的大数据体系就像一条流水作业线,它凭借若干个各自相异的参数调理环节构建,实际的大数据运作流水线也许互不一样,然而主要部分大多涵盖图2所显现的5个环节.
基准检验流程集合通常同时包含系统等级及组件等级的基准检验流程[2].每一套体系等级的基准检验流程可以凭借总体大数据装置流水作业线而构建.此类的基准检验流程亦可另外称为端至端的基准检验.部分基准检验专业人士希望每套基准检验流程都可以检验总体大数据体系,其实是不符合客观情况的.一套优质高效体系等级的基准检验流程可以给客户指出相当便捷的方式来对比相异的大数据体系,实行基准检验的全部大数据体系都可运用一样的检验流程,而且使用一样的指标做于比较.体系等级的基准检验流程的特点,是可以给装置性能建立一份方便明晰的可视图表,而不必划分构件等级的基准检验流程与各自时期环节中的实际运行效果.
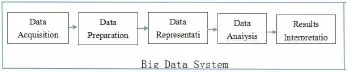
图2 一套有代表性的大数据体系Pipeline样板模型
组合部件等级的基准检验流程较体系等级的该类流程有深一步的机动性能,而且它还比较方便确定内容,并且,另外的区别是仅检验体系的个别项目,是很方便安排且仅服务于体系的对象构成部件.
4.2 选准基准检验流程及输进参数集合
于此文里面,笔者凭借对流程运作特性做近似性评判以便设置基准检验流程及与它相匹配的输进参数集合,流程运作的近似性能评估由两个环节组成.第一,用单元小组所属性能去给流程运作特点确定数量;第二,凭借核算有关工艺将流程运作近似性质做一评估.
本着编制相关系统的目标,在此依托相异层面的特点把流程运作做予评估:
(1)运用类型的特点.指体系的IO进出比率、相关进出参数规模的所占比例、两个过程的运作时间比例;
(2)运作体系等级的特点.指磁盘软件储存读写的参数总量、网络传播的参数总量;
(3)微观范畴组合等级的特点;
(4)排布方式体系等级的特点,指每个运算阶段间的较大差异性质.
由上述的各个层面里,本文挑拣二十一个特定性能去表达流程运作特点.
当进行实证检验时,本文选用流程与输进参数集合的构架作为主要表达样本,用某个携带二十一项自身特性设定的向量去表达某个针对目标的处理过程.所以,此类相异向量能够被用来定量评估各自流程彼此的近似水平,保持基准检验流程集合的运作形式之丰富性,而且能消除基准检测集合里的多余部分内容.还能够依托评估各类输进参数集合对流程运作的影响来给基准检验流程挑出有代表性的引进参数集合.
参数评估的基本步骤包括:
(1)将基础参数做熵权核算,把所有自身特性做权重序列排布,熵权代表评估目标的差异水平.遵循统一的原则,在基础特性类别内依照权重比例大小挑拣出一套子集合;
(2)对上一步骤的引出参数做规范化运作,去掉各特性之间衡量规则的不同内容;
(3)把上面的引出参数做主要组成评估,并核准基本组成数目情况;
(4)利用每个主要组成的新定方位参数来表达流程和它的引入参数集的构成;
(5)核算表达流程和引入参数集构成向量的欧型相隔长度,做各层面类别聚集.
运用流程彼此间的区别和引入参数集合对流程运作带来的影响,能够相当便捷的依据散落节点图(图3)和层次聚类图(图4)做一描述.两类相异流程和引进参数集构架的流程运作愈接近,和其配合的两种向量在流程运作范围内愈靠近;相反时即得负面结果,足以证明其配套的流程运行差别很明显.
所以针对类别聚集效果,能够相当便捷地撤掉基准检验流程集合里的多余部分.针对一样的基准检验流程亦能便捷地依托类别聚集效果挑拣典型的引入参数集合.
5 基准检验的评定标准
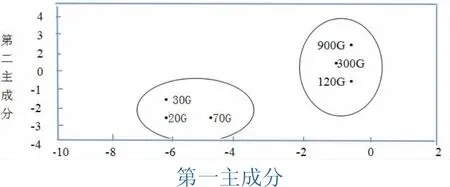
图3 主成分散点图
性质评估是基准检验及比较各种相异体系的首要环节,通常条件下,除体系的进出比率以外,性质评定标准还涵盖其付出的投入和收获的产出,基准检测的客户可依托性质评定标准做平衡对待,参照本身需要情况挑拣性价比领先的大数据处理过程.再者,基准检验的精准度及结论显露出的可推断性都是性质评定标准的关键内容.图3为第一、第二主成份的散点图,图中的两个点簇即表示一种尺寸的输入数据,其高于内存数据的程序行为为一组,低于则成为另一组.同时,由图4的层次聚类图看出,数据集越接近,程序行为越相似,如150G和160G、200G和250G.
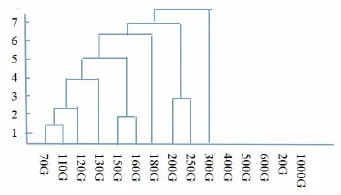
图4 层次聚类图示
6 结束语
由本文的阐述评判过程可以得出,当编制大数据基准检验流程方案时,对大数据有代表性流程运作的方式进行定量评估,而且把流程运作的相近性亦给与评估,均能充分地配合基准检测流程方案的两个条件,在维持流程运作丰富性的前提下去掉多余程分.
经过实验证明,针对某些大数据检验流程,再引进参数集为200G到1000G的序列范围时,流程运作极其相近,故Terasor t仅可选定200G来当作典型的引入参数集合,不但能够精确分析其在引进参数1000G条件下的运作特性,还可精确估计流程的工作时间,从而降低了80%的流程分析时间.相信以后定能编制更精准的基准检验流程.
[1]M eng X F,C i X.B ig data management:concepts,tech ni q ues and chal lenges[J].J ournal of C omputer R e searchand D evelopment,2013,50(1):146-169.
[2]孟小峰,慈祥。大数据管理:概念、技术与挑战[J].计算机研究与发展,2013.50(1):1741-1752.
[3]李建中,刘显敏。大数据的一个重要方面:数据可用性[J].计算机研究与发展,2013,50(6):1147-1162.
[4]赵彦荣,王伟平,孟丹,等。基于H adoop的高效连接查询处理算法C HM J[J].软件学报,2012,23(8):2032-2041.
TheResearchand Discussionon theProgram of LargeDataBenchmarkofNetwork
G A O J ia q iong
(S ichuan Vocational and Technical C ol lege,S uining S ichuan 629000)
Using the reference test procedures to test the per formance of a computer device for processing data is themain formused cur rent ly.H owever,there is no sophisticated and beingwidely followed benchmar k test program.To obtain the ideal test program,relying on a plat formof large data,the paper develops a t raf f ic af fairs B ig D ata reference pic k ing inspection process with H adoop system.A f ter pic k ing several proper ties of pro j ect,ma k ing number process of process content features,evaluating theappro x imate degreeof the input parameters of each process,thena typical f lowand input parameter set aremade.I t is proved that in conformitywith the breadth of the content process,it completely removedunwanted ingredients in the reference test col lection.
B ig D ata R eference Test P rocedures;I nput P arameter S et;F low A ppro x imation;Traf fic I nformation
TP311.13
A
1672-2094(2015)03-0147-04
责任编辑:张隆辉
2015-01-17
本文系四川省教育厅自然科学重点项目《网络大数据测试基准研究》(编号:15Z A0349)研究成果之一.
高加琼(1973-),女,四川天全人,四川职业技术学院副教授.
猜你喜欢
今日农业(2021年10期)2021-07-28 06:28:12
劳动保护(2018年5期)2018-06-05 02:12:10
中国公路(2017年9期)2017-07-25 13:26:38
传媒评论(2017年4期)2017-07-10 09:22:56
国际医学放射学杂志(2016年4期)2016-08-22 10:56:54
办公自动化(2016年18期)2016-08-20 12:50:24
公民与法治(2016年19期)2016-05-17 04:18:15
读者·校园版(2015年7期)2015-05-14 13:11:40
中国工程咨询(2015年8期)2015-02-16 06:38:50
中国卫生(2014年11期)2014-11-12 13:11:34
