
一种基于启发式思维的约束性谱聚类算法
2015-11-02 09:19吴希
中国科技信息 2015年15期
吴 希
一种基于启发式思维的约束性谱聚类算法
吴 希
本文在谱聚类算法的基础上提出了一种基于启发式思想的相似约束矩阵的构建方法,并利用正约束和负约束,结合半监督思想,利用先验信息引导聚类过程,同时结合优化中的KKT条件进行聚类,数据实验证明这种方法的误差率较低,聚类效果较好。
随着科学技术的发展,人类每天都在主动或被动的囤积着大量的数据,这些数据一方面演绎了我们生活中的一些变化,同时,在其背后,也蕴藏了很多有用的信息,因此,对于大量甚至海量数据的处理就成为了人们所面临的一项主要任务。数据挖掘是指从大量数据中提取内在隐含的信息和知识的过程,当然这些数据的形态并不理想,甚至是不完全的,有噪声的,随机的,模糊的 。
数据挖掘中包括很多方法,其中重要的手段之一是聚类分析,目前将聚类分析应用于生物信息、金融交易、医学影像的例子比比皆是,很多传统的聚类算法都有了相应的发展与推广,本文中,我们基于启发式的思维,建立一种新的构造约束矩阵的方法,并利用优化问题中的KKT条件,对正则化谱聚类算法进行改进,提出一种新的聚类算法。
谱聚类算法概述
传统聚类方法是在数据的基础上所提出的,容易陷入局部最优,即若数据满足假设条件,则会有较准确的聚类结果,反之,效果则不理想。为了能在任意的样本空间上进行聚类,并使其收敛于全局最优解,提出了谱聚类算法。谱聚类算法是基于图论理论的基础上提出的,算法的核心是确定图G=(V, E)的相似矩阵,矩阵中的元素一般定义为:
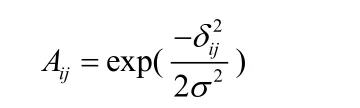
其中δij是点xi和xj之间的欧氏距离,σ是一常数,习惯上定义Aii=0。
构造矩阵时,参数σ的选择是十分重要的,不同于以往直接估计的方法,下面我们引入一个新的参数m,基于启发式的思维,提出一种确定σ的方法。
构造相似约束矩阵
算法的构造思想是首先计算数据间的距离,然后对距离进行排序,计算相邻两距离之差,若最大,则参数m确定,这样能够保证相邻的数据点有较大的隶属度。算法步骤如下:
算法1
输入:数据x1, x2,…,xn;
输出:相似约束矩阵A ;
1.计算每一对数据点之间的距离δij;
2.将距离升序排列,计算相邻数据点间的距离之差;
3.由max{δ′j+1-δ′j}确定参数m ;
启发式的约束性谱聚类一般形式
半监督学习是近年来数据挖掘中提出的一种新的学习方法,它将数据中存在的有限的先验信息加入到算法中,算法能借助这些信息得到更准确的结果。这里,对已知的先验信息进行如下的限制:
定义一个限制矩阵Qn×n,Qn×n中包含已知的先验信息:
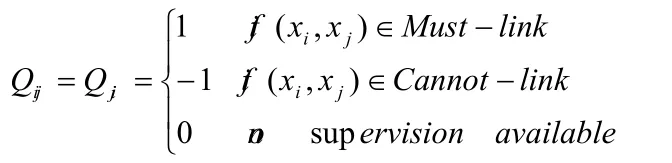
同时定义分类指示向量f∈{-1,+1}n,则聚类时若体现先验信息的价值,应满足
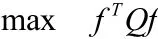
事实上,为了更好的解决问题,只要限制fTQf≥α即可。
将此式引入到正则化谱聚类算法中,在优化问题的KKT条件基础上,建立如下算法。
输入:矩阵A 、Q 以及参数α(其中A 、Q的定义如上所示,α由用户指定);
算法2
输出:向量f*(f*中的分量代表对应数据的分类结果);
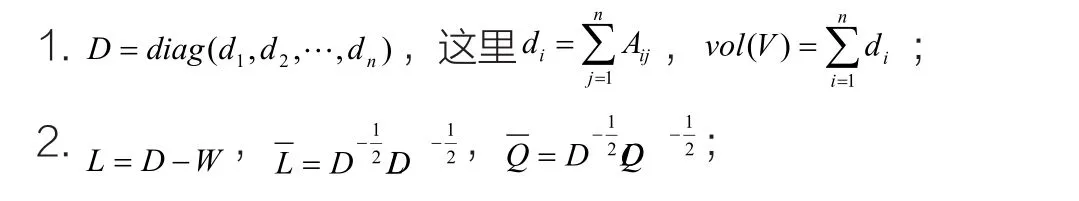
3.计算Lv=µv 的特征值和特征向量;
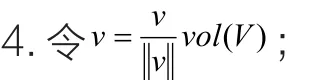
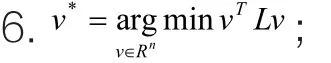
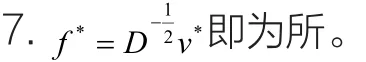
实验分析与结论
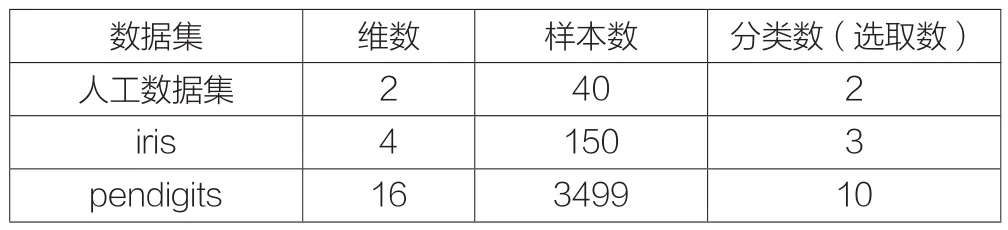
表1 数据集描述
在人工数据集上,新算法的误差率ER=0,在真实数据集上,图1和图2给出了本文算法与传统KKM算法的对比。
综合以上两组实验可以看到,本文算法具有良好的聚类效果。
总结
聚类算法是数据挖掘中的重要算法之一,近年来,在医学、商业等很多方面都得到了广泛的应用,其中谱聚类算法由于其良好的收敛性及聚类效果,使其成为了聚类算法中的使用较频繁的一种算法。本文从启发式思想入手,提出了一种新的构造相似约束矩阵的方法,同时结合KKT条件和半监督方法,对正则化谱聚类进行了改进,并取得了较好的实验结果。
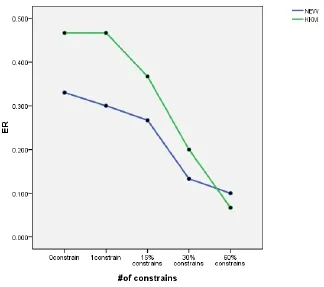
图1 数据集Iris上误差率的比较
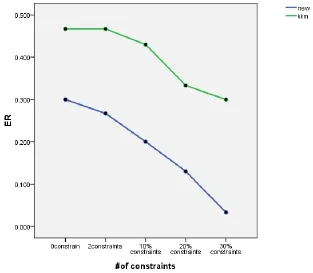
图2 数据集pendigits上误差率的比较
10.3969/j.issn.1001-8972.2015.15.023
猜你喜欢
中国卫生统计(2022年2期)2022-05-28
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
健康大视野(2020年1期)2020-03-02
科技创新与应用(2019年26期)2019-10-24
自动化学报(2017年5期)2017-05-14
电脑知识与技术(2017年2期)2017-04-25
电子技术与软件工程(2016年24期)2017-02-23
岁月(2016年5期)2016-08-13
中小企业管理与科技·中旬刊(2016年6期)2016-06-20
