
数据挖掘技术在高血压病种上的应用研究
2015-10-24 11:06甘昕艳等
电脑知识与技术 2015年5期
甘昕艳等

摘要:近十年来我国卫生信息化建设已取得了飞速的进展,信息系统应用水平不断提升,大量的医学信息被科学的记录下来,如何从这些医学数据资源挖掘出深层次的、隐含的、有价值的知识,就变得越来越重要。该文在对各种数据挖掘算法进行分析研究的基础上,选择IBM SPSS Modeler作为数据挖掘平台,以某社区医院电子病历作为数据源,利用不同的挖掘算法对电子病历系统中的数据进行研究。通过数据的采集、数据清理和数据筛选方法,结合常见的高血压病案,用不同的挖掘模型进行比较分析,总结出各种算法的特点及适用范围,得出适合这种常见病的挖掘模型,并给医务人员提供简单而有效的数据挖掘模型。
关键词:电子病历;数据挖掘;关联规则
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2015)05-0001-04
1 绪论
1.1研究背景
随着计算机技术和数据库技术的飞速发展,各种卫生信息系统在医学领域的广泛应用,由此积累下来的海量医学数据,在此海量的医学数据背后隐藏着许多重要的有用信息,怎样才能把深层次的、隐含的、有价值的知识从数据资源中把挖掘出来,这在当今日趋重要。在国内,数据挖掘技术在医疗服务领域的研究有所报道,但到目前为止,针对于不同的医学目标实现医学数据挖掘应用,怎样科学地选择合适的数据挖掘算法,此类方法学研究在国内尚还较少。
临床信息系统(CIS)中的电子病历系统是以病人为主导,包含所有横向的、纵向的医院信息和临床信息数据的系统。如何从这些数据集中使用不同数据挖掘技术挖掘出各种疾病的成因以及它们之间的相互关系、和各种疾病的发展规律,并总结各种治疗方案的诊疗效果,这对疾病的预防、诊断、治疗和医学研究意义非常重大。本文是基于SPSS Modeler软件平台的基础上对医学数据进行规则的挖掘和知识探索。
1.2 国内外数据挖掘的应用及研究现状
在国外,目前在金融领域、生物工程领域、企业分析以及网络信息搜索等许多领域数据挖掘技术都有了很好的应用[1]。国际知名调查机构通过技术调查,认为未来五年内数据挖掘和并行处理体系将挤在十大新兴技术投资焦点的前列,“数据挖掘和人工智能”将列在首位的。在我国,数据挖掘技术最早在如中国海关集团、人民银行、上海通用汽车等少数实力雄厚的国企或外资企业中得以充分应用。也有少数应用在经济上,如使用一般数量化模型如人工神经网络方法、回归分析法和时间序列方法在经济上对于股价指数进行预测。目前在国内,数据挖掘技术在医疗服务领域的研究已有一些成果,但至今为止,怎样科学地选择适当的数据挖掘算法,针对不同目标的实际应用挖掘,这方面的方法学在国内研究还较尚少。
1.3 研究意义
本研究以某社区医院电子病历作为数据源,对数据挖掘算法在电子病历系统中的应用进行了研究。结合常见高血压病案,通过使用不同的挖掘模型进行比较分析,总结出各种算法的特点及适用范围,得出适合这常见病的挖掘模型,并给医务人员提供简单而有效的数据挖掘模型。同时通过研究探索性电子病历数据挖掘技术的实现,也将进一步做更复杂的数据查询提供参考模式,这也给将来医务人员、科研工作者使用更高层次的数据分析方法解决诊疗水平提供有效的科学的途径,具有极其重要的现实意义。
2 数据挖掘综述
2.1 数据挖掘定义
从技术角度来解释,数据挖掘就是通过自动分化分析数据仓库的大量的、有噪声的、模糊的、不完全的实际应用数据,进行提取人们不知道的隐性的知识和规律,依托于数据库、数据统计和人工智能技术的发展,最大可能地利用已有信息和数据,归纳性推理,挖掘潜在规律[2]。数据挖掘技术主要由三个部分,即数据、算法和技术、建模能力组成。
2.2 常用的数据挖掘算法
2.2.1 神经网络
神经网络是由大量的简单的处理单元组成的,自适应非线性的大规模动力系统,是神经科学、统计学、计算机科学和物理学的交叉学科[3]。神经网络能够有良好的自适应、自学习和高容错能力,并具有分布式存储、并行处理以及联想等特点。目前在常用的多种训练算法和网络模型中,多层前馈型神经网络是应用最广泛的。
BP网络是一种由输入层、输出层和隐含层组成的单向传播的多层前馈网络,如图①所示,是目前在各行各业应用最多的一种模型。
2.2.2 决策树
决策树算法是属于的分类、回归和关联型算法,它主要用于对离散型和连续型的数据进行预测性的建模。
决策树的常用算法有:
1) CART算法
CART算法是一种二分递归分割技术,是结构简单的二叉树,它将总样本集分成两个子样本集,使每个非子结点都有两个分支[4]。
2 )CHAID算法
CHAID提供了一种在多个自变量中自动搜索能产生最大差异的变量方案。
CHAID过程:建立细分模型,根据卡方值最显著的细分变量将群体分出两个或多个群体,对于这些群体再根据其他的卡方值相对最显著的细分变量继续分出子群体,直到没有统计意义上显著的细分变量可以将这些子群体再继续分开为止。
3 电子病历分析数据集的建立
高血压是社区医疗中最为普遍和严重的疾病,其中高血压并发症多,病生理复杂,病症不明显,近年来发病率上升迅猛.社会经济危害性严重.从发展趋势上看尤其值得重视。下面以高血压形成病因作为研究对象,构建一套简单易行的计算机辅助医学数据挖掘系统解决方案。
数据集的预处理步骤主要由:数据集成(dataintergration)、数据清洗(dataClenanig)、数据消减(datareduetion)、和数据转换(datatransformation)几个步骤构成。数据处理是数据挖掘是否能正确得到结果的最重要的一步。本章主要从电子病历中提取原始数据,使用SQL SERVER软件和EXECL软件进行清理数据,筛选,根据数据挖掘所需的字段属性值来分离出不同的分析数据表,再使用SPSS Modeler 14.2软件对数据筛选,不断训练数据集,达到数据挖掘模型的要求。
3.1 数据来源
本数据来源于某社区医院慢性病档案管理系统采集的数据,其中储存的数据库文件为“社区医疗病历.mdf ”文件。本数据库包含有,有”病人”、“病史”、“医生”、“体格检查”、“医院名称”、“用户”“用户权限”、“权限类别”、“用户权限组”等13个数据表表格。本案例主要使用”病人”、“病史”、“体格检查”、“医生”这几个数据表来获取数据源。
3.2 数据预处理
通过SQL SERVER数据库管理系统把存放在Delphi数据环境中的原数据,生成社区医疗病历.mdf 数据库,为了在更好地清洗数据,本文把数据库再转换成EXECL表格。把需要的”病人”、“病史”、“体格检查”、“医生”表格分别转化“高血压分析表”表。
3.3 数据清洗
数据源是数据挖掘的关键,对采集的原始数据进行清洗,这样才能保证信息源的数据质量。首先把其中原数据库中的12个信息表处理成需要使用的两个电子表格“预测数据源”,“高血压预测”,删除不需要的字段,修改录入错,合并相同数据等,考虑到一些没必要的因素,对各个表中删除不必要的字段, 最终变成“预测数据源”表和“高血压预测”表;鉴于线性分析的要求,把高血压中的“初步诊断”字段修改为逻辑型或数据值。
3.4 数据集成和变换
使用SQL SERVER 2000,把这些表格转换成EXECL文件表格形式。
1) 转换数据源:把社区医疗病历数据库.mdf 文件换成EXECL表格研究所需要的数据表格进行研究。转换数据名为:医疗数据库,使用其中的“病人”,“病史”和“体格检查”数据中的数据源作为主要研究对象。
2) 数据分析:使用SPSS Modeler软件对数据表进行分析。经分析,发现原数据的几个表格数据不够连接,没有可比性,再返回EXECL表格进行数据处理,把体格检查表和病人表、病史表的数据源部分数据按“病人编号”排序复制成一个表格,删除“用药”这一列,如图2示:
3) 数据处理:把现“病史”这一列分解成几列,作为以后各个单项研究的基础,数据挖掘的需要,分别生成“预测数据源”表和“高血压相关分析”表。
3.5 数据获取
在EXECL表中对已处理的表应用于SPSS Modeler中作为数据源,其中使用FIND()函数,把原字段“初步诊断”中的结论转换成“布尔”型数据,过程如图3:
数据处理是数据挖掘是否成功或能否挖掘到有用数据结论的一个关键,本章利用数据库软件及表格处理软件对原数据进行采集、清理、排除的研究,得到挖掘SPSS Modeler所需要的数据源,为下一章进行挖掘模型做好准备。
4 几种常用挖掘算法在电子病历数据中的分析研究
4.1 人工神经网络法
4.1.1 建立临界值模型
4.1.1.1采用RBFP神经网络模型对高血压进行预测分析
此模型是用相关的数据来说明其他指标对高血压的成因影响。挖掘过程包括探索、数据准备、训练。
1)探索
表示神经元的数据字段包括:
[病人编号\&年龄\&T(体温)\&P\&R\&身高\&体重\&就诊时间\&主诉\&现病史\&既往史\&是否有遗传\&初步诊断\&]
由于初步诊断对数据进行预测排除,选择“年龄,体重,高压,低压”作为线性数据,测试这些数据与结论是否成线性相关,结果如图4。
3) 训练
将数据导入IBM SPSS Modeler,根据需要建立工程,引入经过处理的数据源,显示数据源视图,定义挖掘模型,最后部署项目并处理挖掘模型。经过字段筛选,再制定训练规则,其训练规则使用如图5所示的规则,规则可以使用的最大时间为15分钟,准确性要达到90%以上。
4) 模型分析
通过执行上面规则的数据流,得到本模型的结果为图6神经网络预测:
从模型分析上显示,身高,体重及年龄对高血压的影响是最大的三个因素,并且结果直观,易懂,从此分析结果看使用神经网络来预测高血压病因是可行的,下面会进一步分析验证其指标。
4.2 高血压病因的决策树-CHAID模型分析
1)系统模型设计
本文要研究高血压的病因与哪些因素相关,因此下面使用决策树中的CHAID算法进行挖掘病案成因。决策树中的CHAID算法提供了一种在多个自变量中自动搜索能产生最大差异的变量方案,其模型需要一个单一的目标和一个或多个输入字,它以因变量为根结点,对每个自变量(只能是分类或有序变量,也就是离散性的,如果是连续变量,如年龄,收入要定义成分类或有序变量)进行分类。
2)模型的训练
高血压的病因CHAID模型挖掘测试,按上面的模型要求,处理好数据源,通过运行,结果显示如图7所示:
图形分析:使用CHAID模型测试的结果发现只有“身高”属性对高血压的病因形成是最主要的, 也就是说由根结点出发,生成的组只有一个,根据属性变量预处理的具体策略,如果仅有一个或两个分组,则不做合并处理至于原因有可能是因为本文的数据源输入及选取有一定的不准确性,故此结果对此病例作用不大,不能为医生提供预防病因的成因研究,所以此法对本病例不适合。
通过上面的挖掘分析结果显示,使用决策树中的CHAID算法对高血压的病因形成在本文的病案中结果都作为不合理处理。
4.3 高血压病因的线性模型分析
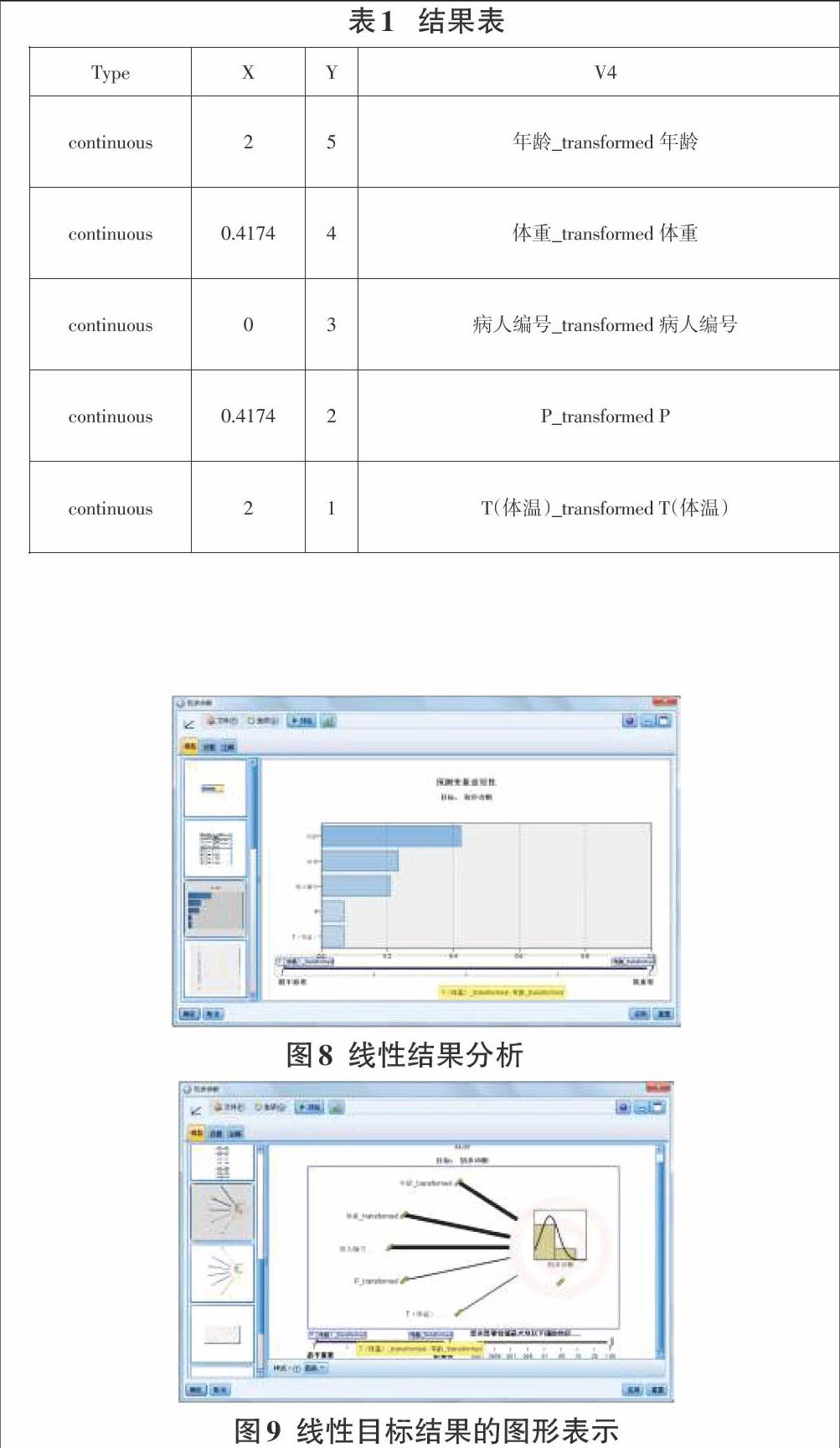
若采用线性建模,使用以下字段作为输入和目标, 作为关键输入和输出量,同时把初步诊断字段进行处理,因输出目标只能是逻辑型或数据值,因此把初步诊断为高血压者改为数字1,其他改为数字0,进行预测,结果发现“年龄”字段对高血压是影响最大的,结果如表1:
最终的结果分析图如图8线性结果分析所示,其目标结果的图形表示如图9线性目标结果的图形所示。由此可得知高血压病成因与“年龄”和“体重”是相关性最大的。
4.4模型验证分析
4.4.1 神经网络预测高血压模型分析验证
经过上面的使用神经网络预测高血压模型预测分析,我们得到了以下的预测结果如图10所示:
从图11结果得知,该预测的准确度达到92%,此准确度是可以作为我们评定这个模型是否成功的指标之一,我们在训练模型中规定了大于90%以上的准确度是可行的,同时我们在分析模型时其使用的模型规则,其置信度是基于预测的概率基础上的:从结果中我们可以看到高血压的形成与“身高”、“体重”、“年龄”这三个因素是最密切相关的,这说明结果是有一定的预测意义的。
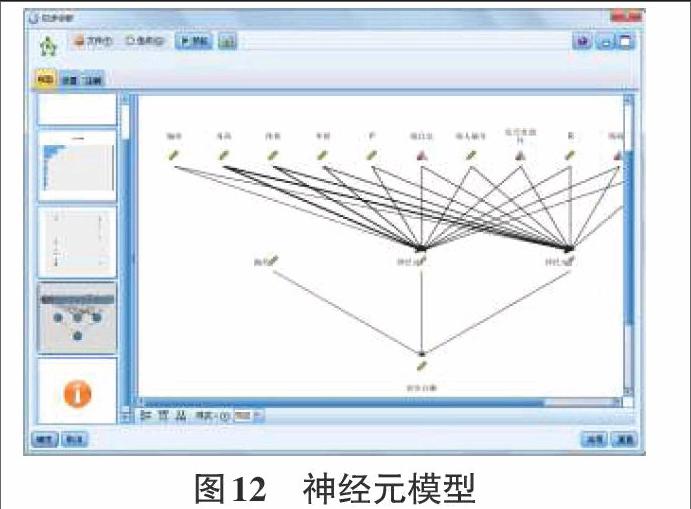
我们还可以转换其神经元模型显示模式,选择网络图形显示,结果如图12神经元模型所示,根据此图的样式也可看出经过一层隐藏层最后得到跟高血压病症成因相关的比较重要的元素是年龄、体重与身高这几个指标,并且此指标也与线性模型研究结果一致,这些图形的显示直观易懂,因此神经网络模型分析高血压成因的使用是成功的,并且简单可行的。
结果分析: 所以我们可以得到结果该关联规则是“强关联规则”,此其结果直观易懂,操作简单。
5 结束语
通过神经网络模型预测高血压病发病成因,得到了影响高 (下转第6页)
(上接第4页)
血压成病的主要因素。本文通过采用线性回归法、人工神经网络法和决策树算法中的CHAID模型来诊断知识,得出线性回归法与人工神经网络这些模型在本病案中均易被医务人员使用者解读;并总结得出神经网络模型是预测影响高血压的主要因素病因的最合适预测算法,并且所获知识的可靠程度以及准确率明显优于其他算法,决策树中的CHAID算法对高血压的病因形成在本文的病案中结果都作为不合理处理,这是从使用者易理解性、判别分类准确率和可靠性角度综合之结果。
参考文献:
[1] 易静.医院信息数据挖掘及实现技术的探索[D].重庆医科大学博士论文,2007.
[2] 周怡,王世伟.医学数据挖掘--SQL SERVER2005案例分析[M].中国铁道出版社,2008.
[3] 丁小丽,杨涛,周金海. 利用人工神经网络分析疾病的影响因素一一以高血压为例[J]. 医学信息,2009(1):4-5.
[4] 王友仁,张砦,崔江,等.储剑波智能组卷系统的建模与算法研究[J].系统工程与实践,2004(9):85-89.
[5] 魏平,张元.一种求解组卷问题的遗传算法[J].宁波大学学报(理工版),2002,15(2):47-50.
[6] Kayawa M Sugita Y Morooka Sensor Diagnosis System Combining Immune Network and Leaning Vector ,1996,117(5):44-55.
[7] 苏新宁等.数据仓库和数据挖掘[M].清华大学出版社,2006.
[8] 韩力群.人工神经网络教程[M].北京邮电大学出版社,2007.
[9] Warren Thomthwaite擞据仓库工具箱[M].清华大学出版社,2007.
[10] 百度搜索网 (http://www.biosou.com/index_newshow.php?newsid=70848)
猜你喜欢
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
