大数据癌症风险预测系统
2015-10-20 06:09:56马立伟曾强吕秋平范成烨程鹏
世界复合医学 2015年1期
马立伟,曾强,吕秋平,范成烨,程鹏
1.美国英立数据研究中心,西雅图 98015 2.中国人民解放军总医院,北京 100853 3.北京一网数据研究中心,北京 100084 4.安徽中医药大学第一附属学院,合肥 230031
*论著——生物信息技术*
大数据癌症风险预测系统
马立伟1,3,曾强2134,吕秋平,范成烨,程鹏
1.美国英立数据研究中心,西雅图 98015 2.中国人民解放军总医院,北京 100853 3.北京一网数据研究中心,北京 100084 4.安徽中医药大学第一附属学院,合肥 230031
中国抗癌协会指出:90%的早期癌症没有明显症状,以至于80%的癌症患者确诊时已属于中晚期。如果我们能够早期发现癌症,至少可以挽救上百万人的生命。本研究的主要目的就是借助于大数据价值提取技术,建立一套能够早期预测癌症风险的系统。本研究对486394人,包括40217名癌症患者和446177名健康体检者进行了血常规,血生化和尿常规数据的分析预测, 预测分析数据共计48项。显著性分析和预测模型的统计方法为逻辑分析法和判别分析法 ,显著性检验标准为p < 0.05 。预测分析使用的统计软件为SAS,预测分析所用数据均来自MS SQL 数据库。研究结果显示血常规,血生化和尿常规数据可以用来区分癌症患者和健康者,基于血常规,血生化和尿常规数据的癌症风险预测模型可以精准锁定高风险癌症人群,准确率达95.5%。癌症风险预测模型建成后,经过2014年1—7月9931名癌症患者和110077名健康体检者数据的验证,准确率超过95%。本研究证明血常规,血生化和尿常规数据可以用来早期预测癌症的风险。
大数据;早期预测癌症;血常规;血生化;尿常规
癌症,一个令人闻之色变的名词,已经成为当今医学界的一大挑战。纵观历史,人类以往与疾病和细菌的斗争都是以人类的最终胜利而告终。但在癌症面前,人类似乎第一次感到束手无策了。德国科学家Thomas Bosch教授2014年8月宣布,人类永远无法战胜癌症[1]。
面对癌症的挑战,人类真的就没有希望了吗?
2012年5月,美国6家联邦机构为大数据和癌症特性的研究项目提供了2亿美元的资助,研究机构希望通过这项以大数据研究和开发的课题带动其他医疗领域的大数据研究,尤其是干细胞和其他重大疾病领域[2]。2013年5月李嘉诚捐资2000万英镑资助英国牛津大学开展 “大数据”医学研究[3]。2014年6月12日,中国政协召开座谈会,医疗、金融、食品安全等重点领域被选为中国“大数据”重大应用示范工程,中国首次拉开了大数据在医疗领域应用研究的序幕。
国际抗癌联盟指出,癌症如能及早发现和充分治疗,三分之一的癌症可以预防,三分之一的癌症患者可以完全治愈,但不幸的是80%的癌症患者错过了最佳诊断和治疗时机。所以早期预测和预防,是人类战胜癌症的最佳方法。
2014年9月26日,北京一网数据软件有限公司,美国英立数据分析公司和国内数家医院合作共同搭建完成了全球首个“大数据癌症风险预测系统”,为人类战胜癌症带来了希望。
大数据癌症风险预测系统是借助国际领先的大数据价值提取技术,对4万多名癌症患者和40多万名健康者的血常规,血生化和尿常规指标进行统计分析对比后,采用具有显著性,能够区分癌症患者和健康者的血尿指标建立的一套癌症预测系统。该预测系统可以随时提取体检者或就诊者的血尿化验数据进行分析预测,为每一个受试者预测出一个数值在1-100之间的癌症风险分值,然后将体检者或就诊者的预测结果与癌症患者的已有指标进行对比,采用大数据预测效果提升的标准评估技术,动态评估体检者或就诊者的癌症风险。
1 研究方法
1.1背景
血液检查是早期查出癌症的重要手段,国内的研究证明恶性肿瘤患者血液流变学指标和健康人比较有非常显著性的差异,特别是红细胞压积普遍降低[4]。英国的研究发现癌症患者尿液中的蛋白质含量和健康人具有明显差异[5],尿液也成为诊断癌症的一种方法。
目前研究机构和大学研究室里的早期预测癌症和诊断方法基本上都是与基因和生物标记物有关的[6,7],奥地利遗传学家、维也纳大学医学遗传学系主任亨斯特施莱格教授2012年在欧盟临床肿瘤协会的年会上指出“基因测试并不能为预测患癌风险提供准确依据”[8]。 爱尔兰MERCY AND CORK 大学医院的教授帕沃也指出“90-95%的癌症是由生活方式和吸烟造成的,只有5-8%的癌症是和遗传基因有关”[9]。生物标志物的测定方法复杂,费用高昂,关键是许多标志物的本质尚不完全明了。肿瘤标志物通常只是作为一种检测肿瘤的辅助手段,它的更大价值在于肿瘤病人手术后可以依据肿瘤标志物的数值变化,来判断手术或化疗是否有效,肿瘤标志物对检测早期癌症效果不好,误差率较高。
尽管实践已经证明癌症患者和健康人的血尿化验数据具有明显差异,而且获取常规健康体检的血尿化验数据也并非难事,但利用常规健康体检的血尿化验数据来早期预测癌症的风险目前在全球还是一项空白。
1.2研究对象
本研究对486394人,包括40217名名癌症患者和446177名健康体检者进行了血常规,血生化和尿常规数据的分析预测。癌症患者中,男性平均占68%,女性为32%,男性平均年龄为61岁,女性为64岁;健康体检者中,男性平均占63%,女性为37%,男性平均年龄为42岁,女性为40岁,详情见表1。

表1 研究对象基本情况Table 1 Subject Basic Information
1.3预测数据
本研究采用的是常规健康体检中涵盖的基本数据,包括年龄,性别,身高,体重,血常规,血生化和尿常规,共计48项,部分指标见表2。

表2 预测癌症风险的部分指标Table 2 Partial Parameters Used for Predicting Cancer Risk
1.4统计学分析
本研究采用的预测技术为逻辑回归分析(Logistic Regression Analysis),逻辑回归分析在医学研究中应用广泛。目前主要是用于流行病学研究中危险因素的筛选,但它同时具有良好的判别和预测功能,尤其是在资料类型不能满足Fisher判别和Bayes判别的条件时,更显示出Logistic回归判别的优势和效能。
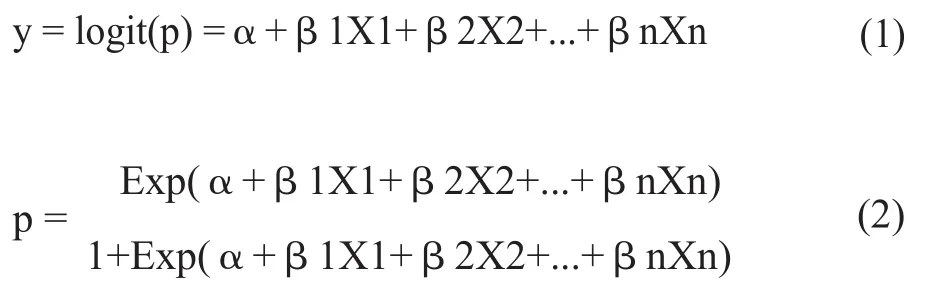
其中y 为因变量,X 为自变量,p 为概率,α 为截距(常数),β 为回归系数,Exp为指数函数。
本研究采用的风险评估技术为,净提升效益算式(Net Lift Algorithm)。

其中 Pt 为测试组癌症患者的百分率,Pc 为对照组癌症患者的百分率。
本研究中统计分析和预测的显著性检验标准为p < 0.05 。统计分析预测使用的统计软件为SAS。
1.5独立的结果验证
本研究的预测模型是基于2010年到2013年共4年的数据上搭建完成的,建成的预测系统中的7个预测模型将逐一经过2014年1到7月,9931名癌症患者和110077名健康体检者的独立的数据验证。
2 结果与分析
本研究经过对2010-2013年30286名癌症患者和336100健康体检者48项指标的相关分析和显著性检验后,采用具有显著性,能够区分癌症患者和健康者的常规血尿指标建立了7种单一的癌症风险预测模型(肺癌,肝癌,胃癌,直肠癌,食管癌,乳腺癌和宫颈癌, 见图1),7种癌症预测模型的准确率都超过了95%,平均为95.8%。预测模型可为用户预测出7个数值在1-100之间的标准分值,通过与癌症患者的已有血尿指标进行对比,动态分析预测结果,评估用户的癌症风险。
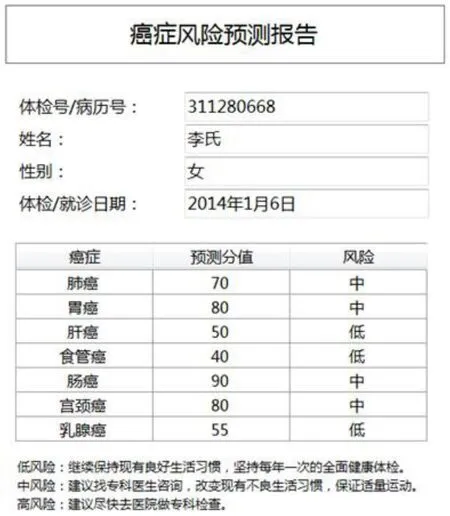
图1 基于体检者血常规,血生化和尿常规数据的癌症风险预测报告
由于各种癌症自身的特点,不同癌症在常规血尿指标中的体现也不同,所以不同的常规血尿指标在预测不同癌症中的作用也不同。平均每种癌症预测模型选用的常规血尿指标为32-35项,表3列出了早期胃癌风险预测模型所选用的部分指标和这些指标从低风险,中风险,高风险到中晚期癌症的变化趋势和过程。表4列出了部分指标在预测早期胃癌风险中的作用。
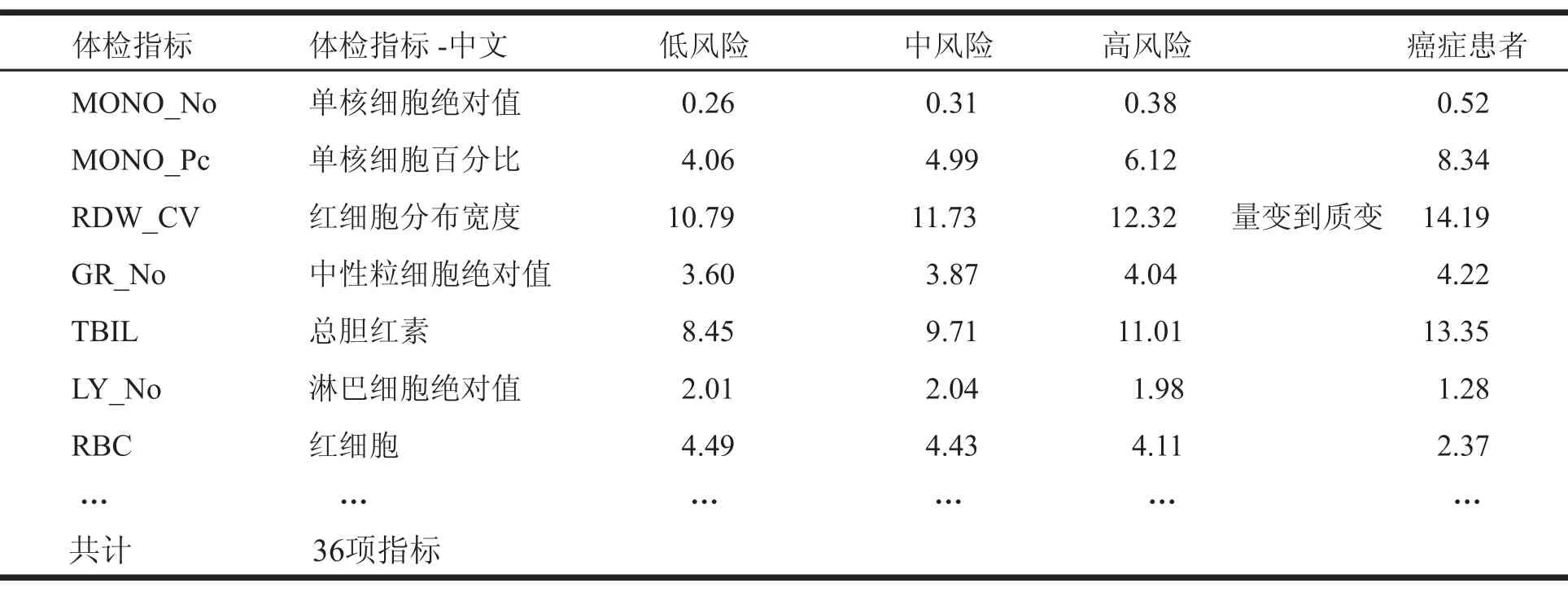
表3 胃癌风险 预测模型选用的部分指标Table 3 Partial Parameters Selected by the Early Stomach Cancer Risk Prediction Model
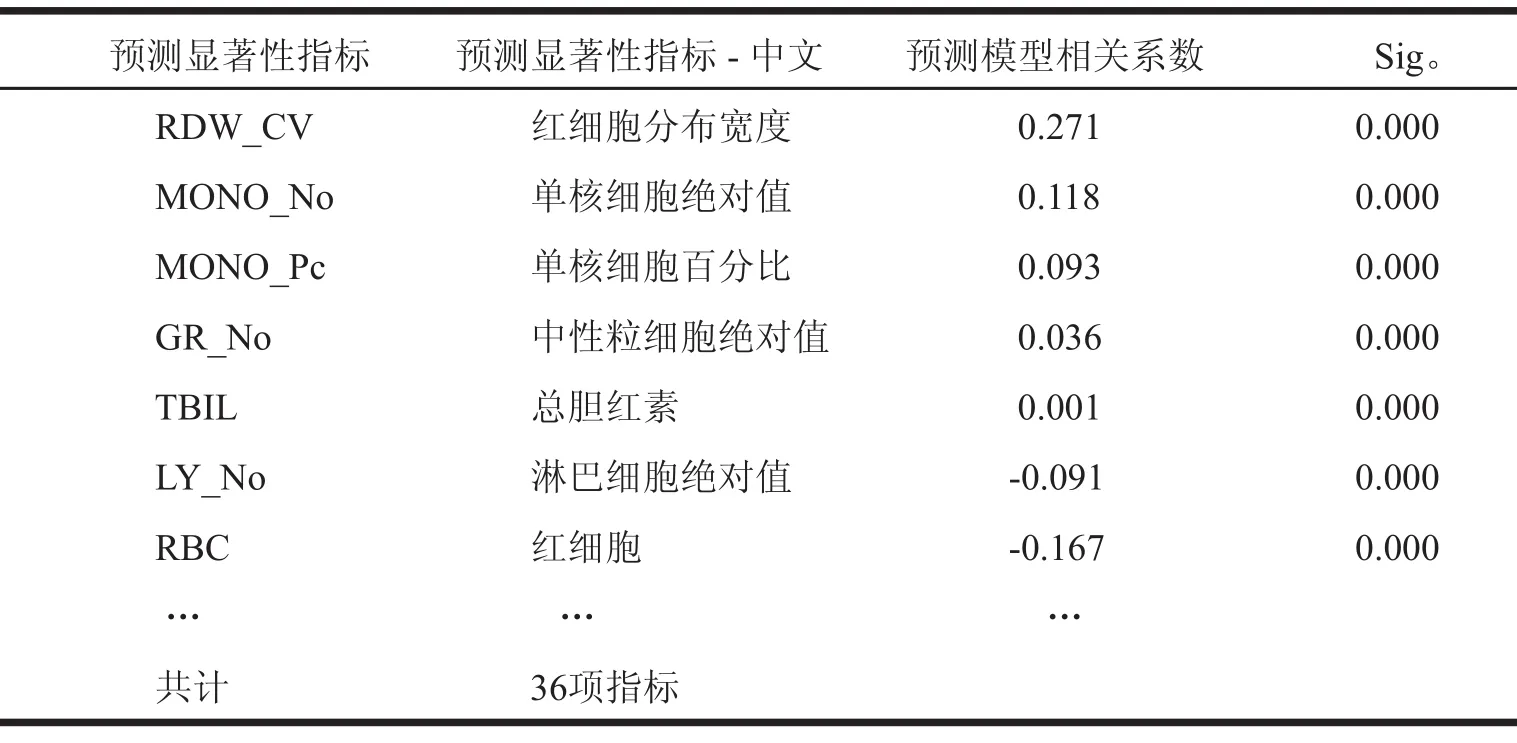
表4 预测胃癌风险 部分指标的相关系数Table 4 Coeffi cients of Stomach Cancer Risk Prediction Model
3 讨论
目前使用常规血尿数据预测癌症风险在全球还没有先例,下面简单介绍一下独立验证结果和几个实例。
本研究的7种癌症预测模型都是基于2010年到2013年的数据,这7种预测模型在搭建完成后,经过2014年1到7月,9931名癌症患者和110077名健康体检者血尿数据的验证,每一种癌症风险预测模型的验证准确率均超过了95%,平均为96.5%,与预期结果的95.8%,基本保持一致。
本研究在中国安徽的一家3甲医院的实际验证中从正常体检的健康人群中预测出4名高风险人员,这4名常规体检者经过医院的进一步专科检查,已有3人临床检查为早期肺癌,肝癌和胃癌,另外一人没有确诊,但身体相关部位明显感到不适。
不同的血尿指标在预测癌症风险中的作用是不同的,有些指标和癌症风险是正比关系,如表4中的红细胞分布宽度,单核细胞百分比,和中性粒细胞绝对值等,如果体检者其他指标保持不变,这些指标的升高,就预示该体检者患胃癌的风险高;有些指标和癌症风险是负比关系,如表4中的淋巴细胞绝对值和红细胞,如果体检者其他指标保持不变,这些指标的降低,就预示该体检者患胃癌的风险高。预测胃癌最重要的前5项指标为血小板分布宽度,白蛋白,红细胞分布宽度,血红蛋白和红细胞压积。
癌症的发生和发展是一个从量变到质变的过程 (如图2所示), 癌细胞的变化其实都会在人体的血尿指标上反映出来,见表3。由于90%的早期癌症是没有明显症状的,癌症患者在早期不会出现明显症状或根本无任何症状,只有当癌细胞发展到一定程度,人体才会出现一系列症状,所以80%的人一旦发现癌症时已经是中期或晚期。

图2 癌细胞的生长过程
本研究的结果,癌症风险预测系统具有3大特点,第一,可以精准锁定高风险人群,预测准确率超过95%;第二,预测方法简便,基于已有血尿数据,无需进一步取样;第三,预测费用低,不到市场价格的10%。
“上工治未病,不治已病”。 预防是我们建立癌症风险预测系统的最终目的,爱尔兰MERCY AND CORK大学医院的教授帕沃已经告诉我们,“90-95%的癌症是由生活方式和吸烟造成的”,我们的愿望是:通过早期预测癌症风险,对健康和亚健康人群发出“癌症”的预警,促使人们改变不良生活方式和戒烟,最后远离癌症。
4 结论
通过大数据分析建立的癌症风险评估模型可以有效的利用正常健康体检中的血常规,血生化和尿常规的数据,用于多种癌症的风险预测,而且预测和验证的准确率均超过95%,这将为癌症的防治提供一种便捷的、经济的、有效的新手段,将在癌症的早防早治方面发挥积极的作用。
(References)
[1] Study: We’ll Never Cure Cancer. 2014-06-26 [2015-02-04]. http://www.newser.com/story/189053/study-wellnever-cure-cancer.html.
[2] Erwin Gianchandani . “Five Reasons ‘Big Data’ is a Big Deal”. 2012-06-29 [2015-02-04]. http://www.cccblog. org/2012/05/29/five-reasons-big-data-is-a-big-deal/
[3] Oxford University. Prime Minister joins Sir Ka-shing Li for launch of £90m initiative in big data and drug discovery at Oxford. 2013-05-03 [2015-02-04]. http:// www.ox.ac.uk/news/2013-05-03-prime-minister-joins-sirka-shing-li-launch-%C2%A390m-initiative-big-data-anddrug/
[4] 王玉莲, 王秀珍, 杜迎雪, 等. 恶性肿瘤患者血液流变学观察[J]. 现代中西医结合杂志, 1996, 10(2): 133-134.
[5] Husi H, Stephens N, Cronshaw, A, et al. Proteomic analysis of urinary upper gastrointestinal cancer markers[J]. PROTEOMICS - Clinical Applications, Vol. 5, 2011, (5-6): 289-299.
[6] Wang H D, Yuh C H, Tu H C, et al. Method for Early Diagnosis of Liver Cancer : USA, US20140099647 [P]. 2014-04-10.
[7] Lothe R A, Sveen A, Agesen TH, et al. Method and Biomarkers for Analysis of Colorectal Cancer: USA, US20140342361 [P]. 2014-11-20.
[8] Senn H J. Myths and misunderstandings hamper efforts to prevent cancer[C]//Proceedings of ESMO 2012 Congress. Vienna, Austria, 2012: ESMO 2012 Press Release..
[9] Power D. Myths and misunderstandings hamper efforts to prevent cancer[C]//Proceedings of ESMO 2012 Congress. Vienna, Austria, 2012: ESMO 2012 Press Release.
Big Data Cancer Risk Prediction System
MA Liwei1,3, ZENG Qiang2, LU Qiuping1, FAN Chenye3, CHEN Peng4
1. Yingli Data Technology, Seattle 98015, USA 2. Chinese PLA General Hospital, Beijing 100853, China 3. Beijing Yiwang Data Technology, Beijing 100084, China 4. Anhui Chinese Medicine University Hospital, Hefei 230031, China
Chinese Anti-Cancer Association indicates that about 90% of early cancers have no obvious symptoms, so that 80% of the diagnosed cancer patients are in the later stage. More than one million lives could be saved if we can predict early cancer risk. The purpose of this research is to provide a system to early predict cancer risk with the help of big data technology. A total of 486,394 people including 40,217 cancer patients and 446,177 normal people were involved in the study. The data were used in the research including demographic, CBC (Complete Blood Count), CMP (Complete Metabolic Panel), Lipids and Urinalysis data, total of 48 data points. Both Logistic analysis and discriminant analysis were used to identify the signifi cant factors and to build seven cancer risk prediction models and the signifi cant level was set at p < 0.05. SAS was used as the primary statistical analysis tool. All the data were pulled out from the MS SQL database. The analysis results showed that CBC, CMP, Lipids and Urinalysis data can signifi cantly distinguish normal people from cancer patients and those data can be used to build cancer risk prediction models, the average accuracy of the prediction models was 95.5%. Those seven prediction models were verifi ed by a total of 120,008 people (from January 2014 to July 2014) including 9,931 cancer patients and 110,077 normal people. The accuracy of the verifi cation was over 95%. This research shows that the routine blood and urine test results can be used to predict cancer risk in the early stage.
big data; early cancer prediction; complete blood count (CBC); blood chemistry; urinalysis
R73
A doi 10.11966/j.issn.2095-994X.2015.01.01.11
2015-02-06;
2015-02-17
马立伟,博士,研究方向为大数据健康医疗,电子信箱:liweima@yahoo.com;曾强,教授,研究方向为亚健康和癌症预测,电子信箱:zq301t@126.com; 吕秋平,研究员,研究方向为大数据智能应用,电子信箱:qiupinglu@gmail.com
引用格式:马立伟,曾强,吕秋平,等.大数据癌症风险预测系统[J].世界复合医学, 2015 , 1(1): 63-67.
猜你喜欢
健康体检与管理(2022年2期)2022-04-15 01:33:37
中老年保健(2021年8期)2021-08-24 06:22:38
世界最新医学信息文摘(2021年12期)2021-06-09 08:37:12
中国自行车(2018年8期)2018-09-26 06:53:34
临床医药文献杂志(电子版)(2017年71期)2017-03-10 15:35:28
人人健康(2016年21期)2016-11-05 11:05:31
中国卫生标准管理(2015年10期)2015-01-27 09:31:56
中国卫生标准管理(2015年1期)2015-01-26 21:17:41
中国卫生标准管理(2015年8期)2015-01-26 18:08:35
河南医学研究(2014年4期)2014-02-27 14:52:23