
一种基于图的流形排序的显著性目标检测改进方法
2015-10-14 08:49吕建勇唐振民
电子与信息学报 2015年11期
吕建勇 唐振民
一种基于图的流形排序的显著性目标检测改进方法
吕建勇*唐振民
(南京理工大学计算机科学与工程学院 南京 210094)
该文针对现有的基于图的流形排序的显著性目标检测方法中仅使用-正则图刻画各个节点的空间连接性的不足以及先验背景假设过于理想化的缺陷,提出一种改进的方法,旨在保持高查全率的同时,提高准确率。在构造图模型时,先采用仿射传播聚类将各超像素(节点)自适应地划分为不同的颜色类,在传统的-正则图的基础上,将属于同一颜色类且空间上位于同一连通区域的各个节点也连接在一起;而在选取背景种子点时,根据边界连接性赋予位于图像边界的超像素不同的背景权重,采用图割方法筛选出真正的背景种子点;最后,采用经典的流形排序算法计算显著性。在常用的MSRA-1000和复杂的SOD数据库上同7种流行算法的4种量化评价指标的实验对比证明了所提改进算法的有效性和优越性。
显著性目标检测;改进的图模型;流形排序;边界连接性;连通区域
1 引言
人眼具备的独特的视觉注意机制能够有效地指导人们发现场景中最具吸引力的重要区域。而如何模拟这种视觉注意机制,使计算机视觉也具备类似的能力,正是显著性的研究目标。由于显著性结果可很好地服务于各种应用,如目标检测与识别[1]、基于视频缩放[2]、场景文字自动定位[3]等,从上世纪80年代起,认知心理学、神经生理学以及计算机视觉等领域的专家对显著性展开了广泛、深入的研究[4]。
Itti等人[5]将视觉注意机制划分为两个阶段:快速的、下意识的、自底向上的、数据驱动的显著性提取,以及慢速的、任务依赖的、自顶向下的、目标驱动的显著性搜索。相应地,研究者们将显著性方法划分为自底向上和自顶向下两大类[6]。而从显著性的发展过程以及最终的应用方向上考虑,又可将其分为视觉关注点预测[7]和显著性目标检测两类[8],前者倾向于捕获图像中最具吸引力的关键点;而后者追求完整、均匀地突出整个目标,这正是本文研究的内容。
多数显著性目标检测方法简单地利用某图像区域的颜色、梯度、边缘、纹理等低层特征在局部或者全局的独特性进行计算。文献[9]构建多尺度局部双层窗口,并在全局范围内滑动,将内外窗口中所含像素点的颜色差异作为显著性度量。文献[10]提出了频域调谐(Frequency-Tuned, FT)算法,在对图像进行高斯平滑后,通过计算某像素点的颜色与原图像的平均颜色之间的距离获取显著性。与上述直接利用颜色特征不同,文献[11]提出使用稀疏直方图简化颜色表述,利用基于图的分割方法将图像划分为多个区域后,计算区域间的颜色对比度,并进行颜色平滑和空间距离加权,实现了经典的区域对比度(regional contrast)显著性算法。仅利用颜色特征,在面对较复杂场景时,效果不佳。于是一些方法综合考虑颜色与空间信息,比如文献[12]提出的上下文感知(Context-Aware, CA)方法,但其容易在物体边界处产生高显著值;而文献[13]结合了局部区域间的颜色与空间距离以及形状特征,通过能量最小化模型,提取显著性目标;文献[14]则在RC的基础上,利用软分割方式对图像颜色聚类,并充分考虑各颜色类的空间分布,改进了RC方法的显著性结果,但其处理纹理图像时,存在不足。
一些利用先验前景或者背景假设的方法取得了明显的进步。文献[15]提取图像中的关键点构造凸包(convex hull),将其围成的区域作为粗略的前景目标范围,通过贝叶斯框架计算显著性。而文献[16]认为大部分位于图像边界的区域属于背景,并利用测地线距离度量各图像块与先验背景之间的差异,作为显著性。但实际上有时部分目标也会接触到图像边界。针对此问题,文献[17]利用各区域的周长与面积的比值,设计了一种更为鲁棒的背景估计方式,称为边界连接性;而文献[18]利用选择性背景优先的显著性方法对背景的真实性进行较为精确的判断;文献[19]则提出了一种层次先验估计策略,综合考虑了先验背景与前景的分布情况,并提出了基于连通区域的交互优化改善估计结果。
近年来,基于图模型的显著性方法有着很高的检测准确率。文献[20]将位于图像边界的超像素作为吸收节点,利用吸收马尔可夫链(absorbing Markov chain)检测显著性。而基于图的流形排序(Manifold Ranking, MR)的显著性方法[21]则将超像素作为图模型中的节点,构造k-正则图;选取背景种子点后,将显著性检测转化为其余节点与这些种子点之间的相似度流形排序;然后将得到的初始显著图阈值分割,选取前景种子点,再利用流形排序的思想进行加强,得到最终的显著图。但该方法的背景假设过于理想化,与文献[20]相同,仅不加区分地将图像边界处的超像素作为背景种子点,当较大面积的真正显著性目标接触到图像边界时,算法容易失效。此外,该方法采用k-正则图刻画各节点间的空间连接性,有时并不能很好地描述属于同一个显著性目标内部多个节点之间的空间相关性。
针对上述两种缺陷,本文提出了改进的策略:在构建图模型时,在k-正则图的基础上,将属于同一颜色类且空间位置上位于同一连通区域的各个节点也进行连接,以便于更加一致、均匀地突出整个目标;而在选取背景种子点时,利用文献[17]所提的边界连接性度量位于图像边界的超像素属于背景的概率,进而筛选出真正的背景种子点。本文的内容组织如下:第2节主要介绍了经典的基于图的流形排序显著性目标检测方法模型;第3节详细阐述了本文方法的改进之处;第4节为实验结果分析;第5节是结论。
2 经典的基于图的流形排序显著性方法
经典的基于图的流行排序显著性方法流程如图1所示,其基础是构建图模型。

图1 文献[21]所提MR方法的流程图
定义一个图模型=(,),其中为所有节点的集合,表示节点之间的边。基于图的流形排序问题可简单描述如下[21,22]:定义图中某些节点为查询对象(query),而图中剩余节点根据其与查询对象之间的相关性进行排序。具体而言,给定一组数据集,为这些数据的个数,为特征维数,其中某些数据被标记为查询对象。定义排序函数:R,其作用是相对于查询对象给每个数据x分配相应的排序得分,这里可以将看成是一个向量。同时,定义指示向量,其中当x是查询对象时,y=1,否则y=0。这组数据对应图模型=(,),其边权重由关联矩阵表示。而对应的度矩阵为=diag{11,12,,d},那么对于给定的查询对象的排序评分可通过求解式(1)所示的最优化问题获得[21]:
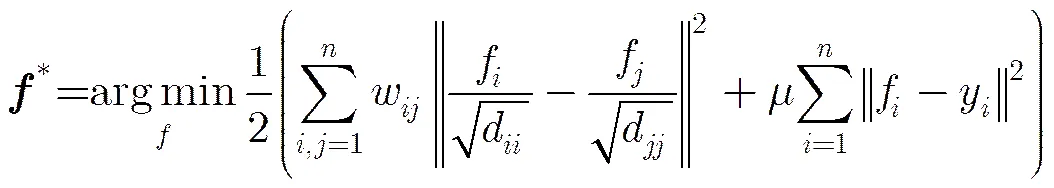
其中第个元素的d=,参数用于平衡第1项的平滑约束和第2项的拟合约束条件。
将式(1)对求导并令其等于0,得到最优解。排序函数的最终优化结果用矩阵的形式可表达为
(2)
(3)
将流形排序用于显著性检测时,首先需要对图像建立图模型,然后选取显著性种子点,而图中每个节点的显著程度通过其相对于种子点的排序得分来度量。其中图模型的建立至关重要。文献[21]采用SLIC(Simple Linear Iterative Clustering)方法[23]将图像分解为超像素表示(SLIC综合考虑像素间的颜色和距离的相似性,将彼此相邻且颜色接近的像素聚集为局部小区域),然后将超像素作为图中的节点(如图2(a)中被分割成的局部小区域所示),构造-正则图,即图中每个节点的度均相同。具体而言,,如图2(a)所示,每个节点不仅和其空间上邻接的节点(蓝色)相连,那些与该节点的邻接节点共享同一个超像素边界的节点(黄色)也相连。此外,文献[21]还将图像4个边界处的所有节点两两之间进行连接(见图2(a))。而两个节点之间的边权重定义为
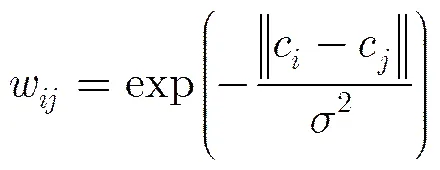
c和c表示超像素和在CIELab颜色空间的平均颜色之间的欧式距离;控制边权重的变化程度,实验时取值为10。
接着文献[21]将显著性检测分为两个阶段。第1阶段选取图像4个边界处的超像素为背景种子点,即查询对象,以图像上边界处的查询对象Q为例,按式(3)计算图中节点相对于Q的排序得分,那么节点相对于Q的显著性为
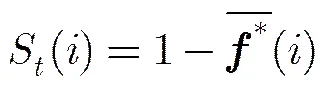
节点相对于下、左、右边界处的查询对象的显著性S(),S(),S()也可通过类似式(5)的公式计算。而节点最终第1阶段的显著性为

计算所有节点的显著性后得到第1阶段的显著图S(见图2(b))。接着采用自适应阈值分割方法分割S,得到前景种子点,即第2阶段的查询对象,按式(3)计算图中节点相对于这些查询对象的排序得分,得到节点的第2阶段,即最终的显著性:

将所有节点的显著性标准化为[0,1],最终的显著图见图2(c)。观察可知,其显著性效果并不理想,接触到图像下边界的真正目标显著性缺失,反而突出了背景。
3 本文的改进方法
本文改进方法的流程图如图3所示,主要改进了图模型的构建以及背景种子点的筛选过程。

图2 文献[21]所提MR方法的图模型和显著图结果

图3 本文方法的流程图
3.1改进的图模型
文献[21]所提MR方法虽然使用-正则图(类似于局部平滑操作)很好地刻画每个节点与其周边节点的空间关系,但实际上如果将同类的(homogenous)且空间上又属于同一个连通区域的节点在图模型中也连接在一起,能更加合理、准确地描述节点之间的相关性;并且在给定查询对象进行流形排序时,这些同类的节点也能取得更加一致的排序得分,对于目标能更加均匀地突出,对于背景能更加有效地抑制。
于是,本文在利用SLIC方法[23]将图像分解为超像素表示的基础上,采用仿射传播聚类(Affinity Propagation Clustering, APC)[24]将超像素按颜色聚集为不同的区域。APC不同于传统的k-means方法,其无需预设分类数目,将所有超像素作为潜在聚类中心,根据各超像素间的相似性,采用贪心策略不断迭代更新每一个超像素的吸引度和归属度,自适应产生若干聚类中心,相比而言,更加适用于复杂多变的各种场景下的分类任务。与文献[18]相似,APC方法中超像素和之间的相似度定义为
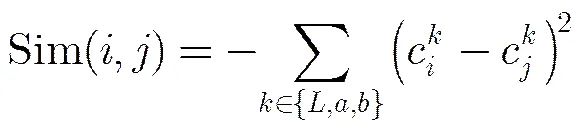
在APC过程中很有可能将空间上相距较远且彼此之间没有连通性的区域也划分在同一个颜色类之中,而本文的图模型需要刻画的是邻近的同类区域中各节点(超像素)之间的相关性,因此,这里引入连通区域的概念。所谓连通区域,是指同属于一个颜色类且空间上聚集在某一个区域的超像素的集合,而其中的超像素之间可通过邻接超像素到达彼此。以图2(a)中的图像为例,采用APC方法的分类结果如图4(a)所示,共分为9个颜色类。前景雕像所在的类中各超像素比较集中,在空间上同属一个连通区域,见图4(b);而某个背景云朵所在类中,各超像素较分散,共包含6个连通区域,有的连通区域仅含1个超像素,见图4(c)。
这些位于某一连通区域的超像素有较大概率共同属于前景目标或者背景。因此,本文在保留MR方法构造的-正则图基础上,将同属一个连通区域的超像素之间也进行连接。接着将式(4)定义的两个节点之间的边权重调整为
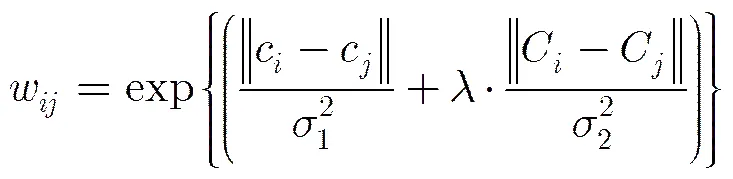
其中C和C是节点和所属连通区域在CIELab颜色空间的取值,即为其中包含的所有超像素的平均颜色;是平衡系数,取值为0.5;实验时,。
按式(9)调整边权重会使属于同一连通区域的节点之间的关联性更强,边权重更大;而分属不同颜色类下不同连通区域的节点间的边权重被削弱;比式(4)的边权重设定更有区分性,也更符合人类视觉上的直观感知。
3.2改进的背景种子点筛选
MR方法的另一个缺点是在计算第1阶段的显著性时,仅简单地将图像边界处的超像素作为背景种子点,如图5(a)所示。虽然文献[16]经过对大量图像的分析给出了统计性证明,文献[20]也采用了相同的假设,但当前景目标有较大部分接触到图像边界时,MR方法效果不佳,如图2(b)和图2(c)所示。

图4 APC方法结果及连通区域示例

图5 MR方法和本文方法的背景种子点对比
受文献[17]所提边界连接性概念的启发,本文在对其进行改进的基础上,筛选出有较大概率属于真正背景的超像素作为背景种子点。
假设图像被划分为若干个较大的区域,那么区域的边界连接性定义为[17]
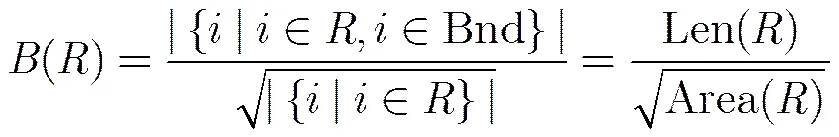
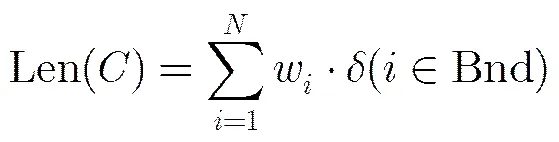
其中w为超像素中所含像素点数目;与文献[16]相同,当超像素中像素点与图像边界的最短距离小于10个像素,就认为接触到图像边界,即;为指示函数,当满足时,=1,否则为0。相应地,类的面积为
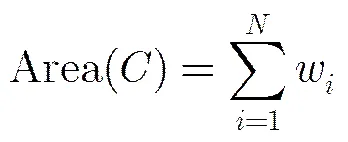
实际上,正如文献[18]所述,属于前景目标的类中超像素分布较为集中,而背景类中的超像素比较分散和杂乱,因此,本文并不直接将式(11)和式(12)代入式(10)中计算,而是将类间相对空间离散程度加入到边界连接性的度量中。假设图像共划分为个颜色类,类中含有个超像素,类相对于其余所有类的空间离散程度为
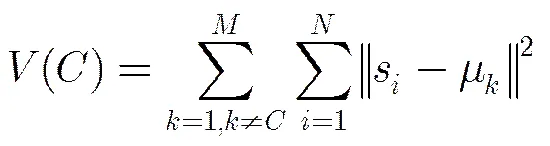
s为超像素的空间位置,为第个类空间聚类中心,有

融合式(11)~式(13)的结果,得到改进的边界连接性:
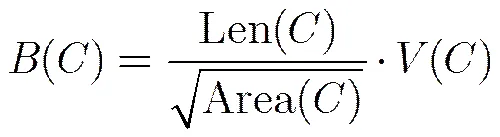
某类的边界连接性越大,其属于背景的概率越高。和文献[17]类似,将边界连接性转化为背景概率,超像素的背景概率为
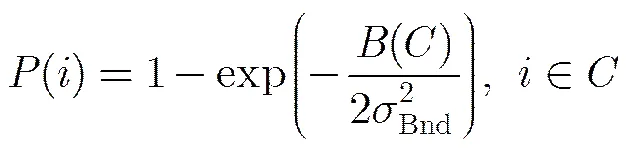
图5(b)为本文方法产生的背景概率图,接触到图像下边界的雕像部分的背景概率较低。采用图割方法[25]对其分割后的结果见图5(c),成功地将这部分超像素排除在背景之外。最后,本文选取位于图像边界处且背景概率值较低的超像素作为真正的背景种子点,见图5(d)。需要注意的是,在确保目标部分的超像素不被错选为背景种子点时,本文也会将个别真正属于背景的超像素漏选,但这并不影响后续的显著性计算,因为这些漏选的背景超像素与背景种子点更加相似,在流形排序时会赋予其与背景种子点更加一致的排序得分。
3.3生成显著图
在构造改进的图模型和筛选出真正的背景种子点后,按式(3)、式(5)、式(6)计算每个超像素在第1阶段的显著性,标准化为[0,1],得到第1阶段的显著图,见图6(a)。与图2(b)中MR方法第1阶段的显著图相比,本文方法的效果有明显改进,赋予了真正的目标更高的显著值,各种背景的显著值明显降低。
接着,在计算第2阶段的显著性时,本文先采用图割(graph cuts)方法[25]分割第1阶段的显著图,获取前景种子点。图割将图像分割问题与图的最小割问题相关联,即图像分割转化为像素标记问题,而这个过程通过最小化能量函数得到:
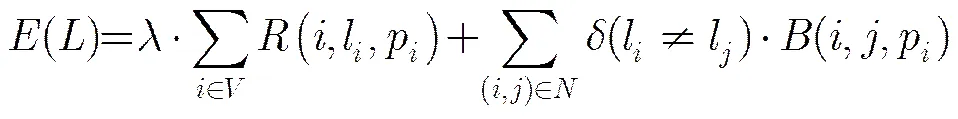
表示标记的集合,对于超像素,即图中的节点,有。表示图中所有的节点集合,为超像素的空间邻接节点集合。p为在第1阶段的显著图中取值,区域项定义为
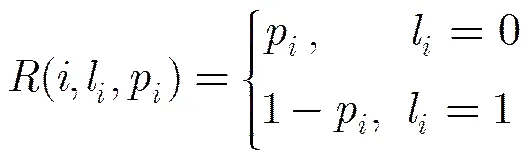
而对应的边界项定义为

图割后,选取前景种子点,按式(7)计算,第2阶段,即最终的显著图见图6(b)。其中真正的目标被准确、完整、均匀地凸显;MR方法中错误凸显的云朵背景(见图2(c))在图6(b)中的显著值极低;本文结果与真实值(Ground Truth, GT)更加接近,见图6(c)。
4 实验结果与分析
本文在两个经典的显著性目标检测数据集MSRA-1000和SOD上进行对比实验。MSRA- 1000[10]被广泛使用,共包含1000幅大小为300×400左右的图像,虽然其中目标的种类变化多样,但大多数仅含单个目标,且目标与背景差异较为明显。SOD数据集虽然仅含300幅大小为480×320左右的图像,但其较为复杂,有些图像含有较多目标,且目标之间差异性强,有时目标混杂于背景,被公认为十分具有挑战性[20]。这两个数据集都给出了人工标注的真实值,以便于主观和客观的性能评价。经典的显著性方法较多[8],限于篇幅,本文选取了近年来极具代表性的以及和本文方法有相关性的共7种方法进行比较,包括:FT[10], RC[11], CB[13], GC[14], BS[15], GS-SP[16]和MR[21]。
P-R曲线(Precision-Recall curve)[10,11]是最常用的评价显著性目标检测算法优劣的指标。准确率(Precision)表示算法给出的属于真正目标的部分占算法给出的所有显著性目标的比例;而查全率(Recall)则是指算法给出的属于真正目标的部分占人工标注的真正目标的比例。各种方法的P-R曲线见图7,本文方法在该指标上的表现明显优于其余方法。在MSRA-1000数据库上,当查全率位于区域[0,0.96]时,本文方法的准确率一直是所比较的算法中最高的,当查全率小于0.85时,本文算法的准确率保持在0.97左右。虽然当查全率大于0.96时,本文算法的准确率略低于GS-SP,但在其余的查全率取值处,本文算法的准确率远高于GS-SP。与MR 方法相比,本文算法的准确率也有明显提升,证明了本文算法所做改进的有效性。在SOD数据库上,也有类似的表现。虽然由于SOD的复杂性导致各算法在P-R曲线上的结果远小于MSRA-1000数据库,但本文算法依然保持最高的准确率。
F-measure是另一个重要的量化性能评价指标,其计算公式为


图6 本文改进方法产生的显著图
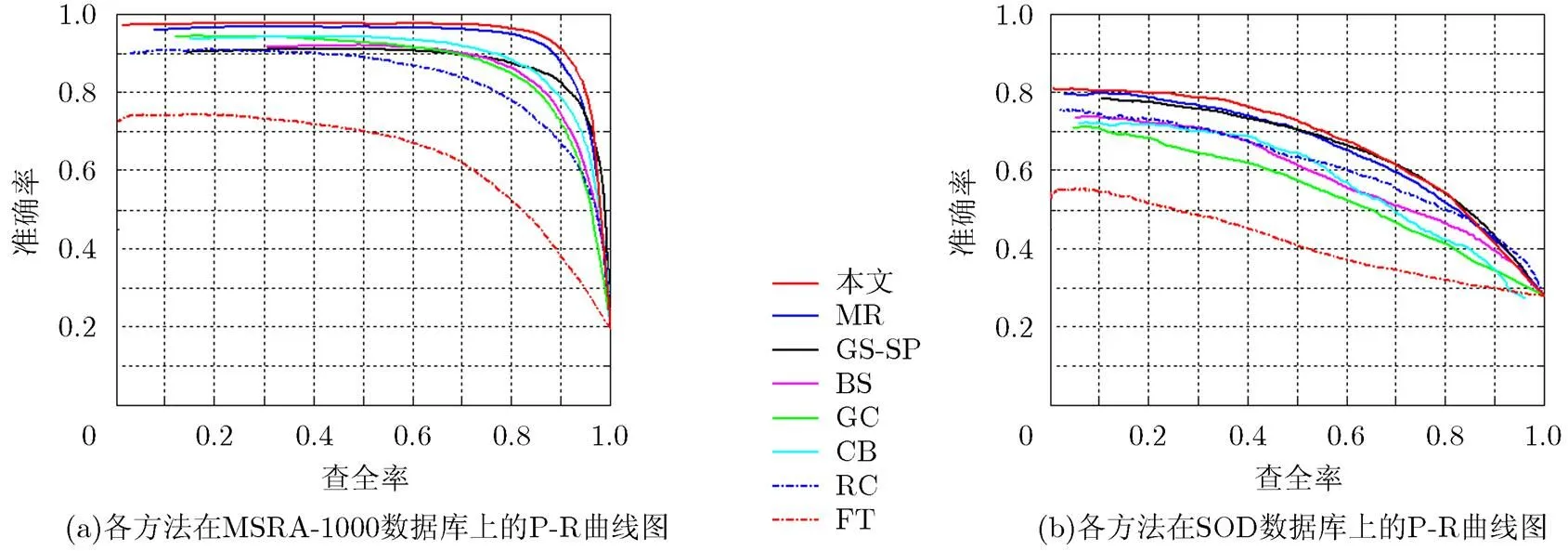
图7 本文方法和7种经典显著性方法的P-R曲线图的对比结果
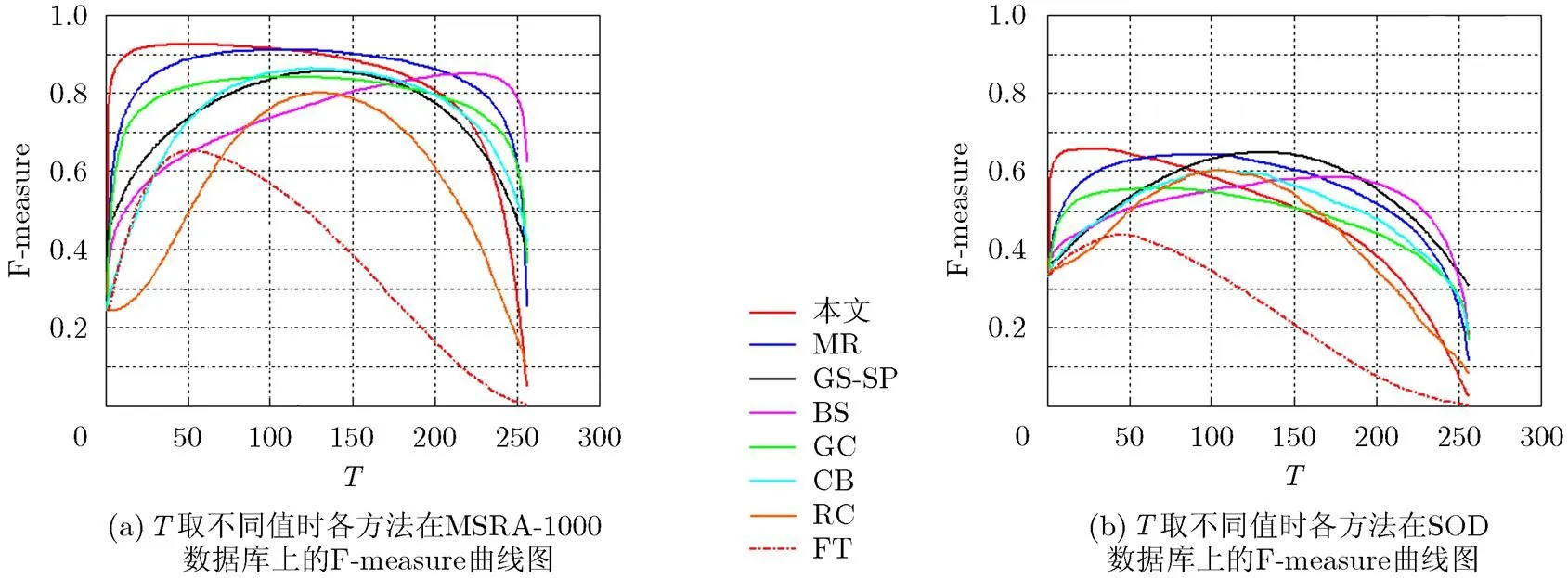
图8 本文方法和7种经典显著性方法的F-measure vs T曲线图的对比结果

表1 各方法的最高F-measure和对应的阈值T
接着,本文使用自适应阈值分割策略[10,11](阈值自动设置为图像平均显著值的2倍)比较分割后的平均准确率、查全率和F-measure,结果见图9。自适应阈值分割后,本文的F-measure在MSRA-1000数据集上高达0.925,在SOD数据集上高达0.646,均是所有算法中最高的。图9(a), 9(b)中,本文方法的准确率高于MR方法,但查全率却略低。这是因为本文所提改进的图模型和背景种子点筛选,会尽量准确地凸显真正的显著性目标,但如果目标包含多个差异较大的颜色类,本文方法在选择第2阶段的前景种子点时,很有可能会遗漏部分目标区域,导致这部分显著值略低,造成查全率下降。
上述3种评价指标将目光集中在被正确标记为真正目标的图像区域,而没有考虑那些被正确标记为背景的区域,因此,文献[14]使用平均绝对误差(Mean Absolute Error, MAE)指标来度量显著图和人工标注的真实值(GT)之间更加全面的相似性:
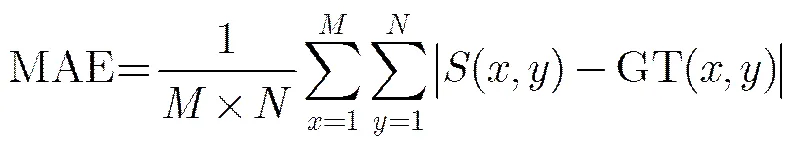
,分别为图像长和宽。各方法的MAE柱状图见图10。本文方法在MSRA-1000和SOD数据集上的MAE值都是最小的,分别仅为0.073和0.238。说明了本文方法的显著图在整体上(包括目标和背景)与真实值最为一致。值得注意的是,在SOD数据集上,本文算法的MAE值明显小于MR,而在MSRA-1000数据集上,两者较为接近,这说明在较复杂场景下,本文算法能够取得更加接近真实值的检测效果。
各算法产生的具有代表性的显著图见图11(前3幅图像来自MSRA-1000数据集,后两幅图像来自SOD数据集)。本文方法的显著图能够更加准确、均匀地凸显目标,与人工标注的真实值中的前景目标(白色)更加接近。MR方法中过多突出了接近图像中间部分的非目标成分,如第1, 2, 4幅图像,而本文方法却成功避免了这一缺陷;MR方法有时会赋予真正目标内部差异较大的显著值,如第3, 5幅图像,而本文方法有效地改进了这一现象。综合而言,本文方法的显著性目标检测结果更好,误检区域和漏检区域少。
本文比较了各算法的平均运行时间,见表2。实验在配置为Intel(R) Core(TM)i5-2410M CPU, 4 G内存的台式机上完成。本文3.1节改进的图模型计算复杂度为(),为图中超像素(节点)的数目,为图中每个节点对应的边的数目的平均值;3.2节改进的背景种子点筛选计算复杂度为(),为仿射传播聚类得到的颜色数目;而3.3节生成显著图的计算复杂度与原始的MR方法相同,仅为()。由于本文所提改进方法包含较多步骤,因此耗费的时间略长,高于MR以及运行时间较短的GC, RC和FT方法,而显著低于GS-SP和BS方法。但结合上述4种量化性能评价指标上的表现,本文方法仍然具有优势。
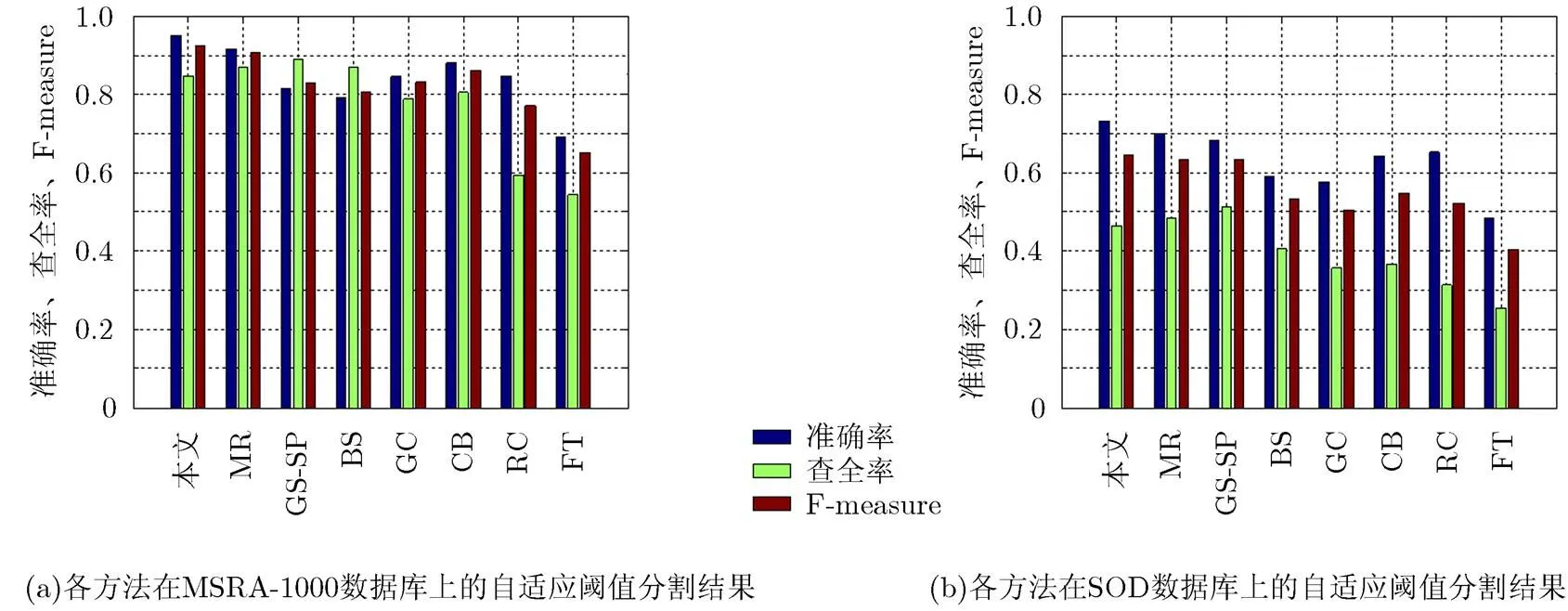
图9 本文方法和7种经典显著性方法在自适应阈值分割后的准确率、查全率和F-measure

图10 本文方法和7种经典显著性方法的MAE柱状图

图11 本文方法和7种经典显著性方法产生的显著图的视觉效果对比
表2各算法在MSRA-1000和SOD数据库上的平均运行时间

方法名称本文方法MRGS-SPBSGCCBRCFT 时间(s)2.550.687.49159.370.102.890.140.19
5 结论
本文针对经典的MR方法中仅使用k-正则图刻画各个节点的空间连接性的不足以及先验背景假设过于理想化的缺陷,设计了有效的改进策略。将同属于某颜色类且空间上位于同一连通区域的超像素相连,能够能更加合理、准确地描述图模型中各节点之间的相关性;而基于边界连接性的背景种子点筛选,能够避免MR方法中误将部分前景目标划分为背景造成的偏差。在常用的MSRA-1000和复杂的SOD数据集上同7种经典的显著性方法的4种量化性能评价指标上的实验比较,证明了本文所提改进方法的有效性和优越性。接下来的工作将考虑结合更高层的显著性线索,如对称性、目标轮廓以及心理学的一些指导策略,去提取那些目标多样、场景复杂的图像中显著性目标检测的准确性与完整性。
[1] Li W T, Chang H S, Lien K C,.. Exploring visual and motion saliency for automatic video object extraction[J]., 2013, 22(7): 2600-2610.
[2] Chen D Y and Luo Y S. Preserving motion-tolerant contextual visual saliency for video resizing[J]., 2013, 15(7): 1616-1627.
[3] 姜维, 卢朝阳, 李静, 等. 基于视觉显著性和提升框架的场景文字背景抑制方法[J]. 电子与信息学报, 2014, 36(3): 617-623.
Jiang Wei, Lu Chao-yang, Li Jing,. Visual saliency and boosting based background suppression for scene text[J].&, 2014, 36(3): 617-623.
[4] Borji A and Itti L. State-of-the-art in visual attention modeling[J]., 2013, 35(1): 185-207.
[5] Itti L, Koch C, and Niebur E. A model of saliency-based visual attention for rapid scene analysis[J]., 1998, 20(11): 1254-1259.
[6] 钱生, 陈宗海, 林名强, 等. 基于条件随机场和图像分割的显著性检测[J]. 自动化学报, 2015, 41(4): 711-724.
Qian Sheng, Chen Zong-hai, Lin Ming-qiang,.. Saliency detection based on conditional random field and image segmentation[J]., 2015, 41(4): 711-724.
[7] Borji A, Sihite D N, and Itti L. Quantitative analysis of human-model agreement in visual saliency modeling: a comparative study[J]., 2013, 22(1): 55-69.
[8] Borji A, Sihite D N, and Itti L. Salient object detection: a benchmark[C]. Proceedings of the European Conference on Computer Vision, Florence, 2012: 414-429.
[9] Achanta R, Estrada F, Wils P,. Salient region detection and segmentation[C]. Proceedings of the International Conference on Computer Vision Systems, Heraklion, 2008: 66-75.
[10] Achanta R, Hemami S, Estrada F,.. Frequency-tuned salient region detection[C]. Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Miami, 2009: 1597-1604.
[11] Cheng M M, Zhang G X, Mitra N J,.. Global contrast based salient region detection[C]. Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Providence, 2011: 409-416.
[12] Goferman S, Zelnik-Manor L, and Tal A. Context-aware saliency detection[J]., 2012, 34(10): 1915-1926.
[13] Jiang H, Wang J, Yuan Z,.. Automatic salient object segmentation based on context and shape prior[C]. Proceedings of the British Machine Vision Conference, Dundee, 2011: 110.1-110.12.
[14] Cheng M M, Jonathan W, Lin W Y,.. Efficient salient region detection with soft image abstraction[C]. Proceedings of the IEEE International Conference on Computer Vision, Sydney, 2013: 1529-1536.
[15] Xie Y L, Lu H C, and Yang M H. Bayesian saliency via low and mid level cues[J]., 2013, 22(5): 1689-1698.
[16] Wei Y C, Wen F, Zhu W J,.. Geodesic saliency using background priors[C]. Proceedings of the European Conference on Computer Vision, Florence, 2012: 29-42.
[17] Zhu W J, Liang S, Wei Y C,. Saliency optimization from robust background detection[C]. Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Columbus, 2014: 2814-2821.
[18] 蒋寓文, 谭乐怡, 王守觉. 选择性背景优先的显著性检测模型[J]. 电子与信息学报, 2015, 37(1): 130-136.
Jiang Yu-wen, Tan Le-yi, and Wang Shou-jue. Saliency detected model based on selective edges prior[J].&, 2015, 37(1): 130-136.
[19] 徐威, 唐振民. 利用层次先验估计的显著性目标检测[J]. 自动化学报, 2015, 41(4): 799-812.
Xu Wei and Tang Zhen-min. Exploiting hierarchical prior estimation for salient object detection[J]., 2015, 41(4): 799-812.
[20] Jiang B W, Zhang L H, Lu H C,. Saliency detection via absorbing markov chain[C]. Proceedings of the IEEE International Conference on Computer Vision, Sydney, 2013: 1665-1672.
[21] Yang C, Zhang L H, Lu H C,. Saliency detection via graph-based manifold ranking[C]. Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Portland, 2013: 3166-3173.
[22] Cheng X, Du P, Guo J,.. Ranking on data manifold with sink points[J]., 2013, 25(1): 177-191.
[23] Achanta R, Shaji A, Smith K,.. SLIC superpixles compared to state-of-the-art superpixel methods[J]., 2012, 34(11): 2274-2282.
[24] Frey B J and Dueck D. Clustering by passing message between data points[J]., 2007, 315(5814): 972-976.
[25] Boykov Y and Jolly M P. Interactive graph cuts for optimal boundary & region segmentation of objects in N-D images[C]. Proceedings of the IEEE International Conference on Computer Vision, Vancouver, 2001: 105-112.
An Improved Graph-based Manifold Ranking for Salient Object Detection
Lü Jian-yong Tang Zhen-min
(,,210094,)
To overcome the shortage that the spatial connectivity of every node is modeled only via the-regular graph and the idealistic prior background assumption is used in existing salient object detection method based on graph-based manifold ranking, an improved method is proposed to increase the precision while preserving the high recall. When constructing the graph model, the affinity propagation clustering is utilized to aggregate the superpixels (nodes) to different color clusters adaptively. Then, based on the traditional-regular graph, the nodes belonging to the same cluster and located in the same spatial connected region are connected with edges. According to the boundary connectivity, the superpixels along the image boundaries are assigned with different background weights. Then, the real background seeds are selected by graph cuts method. Finally, the classical manifold ranking method is employed to compute saliency. The experimental comparison results of 4 quantitative evaluation indicators between the proposed and 7 state-of-the-art methods on MSRA-1000 and complex SOD datasets demonstrate the effectiveness and superiority of the proposed improved method.
Salient object detection; Improved graph model; Manifold ranking; Boundary connectivity; Connected region
TP391.41
A
1009-5896(2015)11-2555-09
10.11999/JEIT150619
2015-05-25;改回日期:2015-08-13;
2015-08-28
吕建勇 lv_jy@126.com
国家自然科学基金(61473154)资助课题
The National Natural Science Foundation of China (61473154)
吕建勇: 男,1979年生,讲师,主要研究方向为图像处理技术.
唐振民: 男,1961年生,教授,博士生导师,主要研究方向为图像处理技术、智能机器人与智能检测.
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
儿童时代·幸福宝宝(2021年11期)2021-12-21
现代装饰(2020年4期)2020-05-20
科普童话·学霸日记(2020年1期)2020-05-08
红领巾·萌芽(2019年8期)2019-08-27
小天使·一年级语数英综合(2019年2期)2019-01-10
证券法律评论(2018年0期)2018-08-31
中国与非洲(法文版)(2017年10期)2017-11-23
CHIP新电脑(2016年3期)2016-03-10
