
再探分析师盈利预测之相对准确性
2015-09-17 05:43:04上海海洋大学上海201306
商业会计 2015年14期
(上海海洋大学 上海 201306)
一、引言
一般而言,企业盈利预测研究主要运用于三个重要领域:证券估价与投资决策;获得“更准确”的市场预期盈利;解释管理当局的会计政策选择(Watts and Zimmerman,1986)。 因此,盈利预测研究具有极为重要的意义。通常情况下广大投资者可以获得两种类型的企业盈利预测,即利用时间序列模型估计的盈利预测和证券分析师发布的盈利预测。那么这两者之中,哪一个更加准确?本文试图回答这一问题。本文的研究将有助于研究人员和投资者深入理解证券分析师盈利预测的性质,并为他们提供更为准确的盈利预测。
二、研究背景
从理论上讲,证券分析师的盈利预测应该更加准确,因为证券分析师具有特定的信息优势。例如,如果我们在“提前一个季度”的预测区间内预测某上市公司2005年的年度盈利,时间序列模型可以利用截至2005年第三季度的盈利信息予以预测。但是,证券分析师不但可以利用盈利信息,他们还可以运用截至2005年第三季度的所有其他财务信息、非财务信息以及行业信息和宏观经济信息。证券分析师的这种信息优势被称之为“同期优势”(a contemporaneous advantage)(Brownet al.,1987;Fried and Givoly,1982)。 不仅如此,许多证券分析师的预测值通常是在2005年第三季度结束之后才陆续发布。这就意味着证券分析师可以取得2005年第三季度之后的许多新信息,并利用这些信息更为准确的预测盈利,即证券分析师同时还具有“及时性优势”(a timing advantage) (Brown et al.,1987;Fried and Givoly,1982)。
此外,Brown and Rozeff (1978)指出,证券分析师盈利预测长期存在的这一事实本身就足以表明证券分析师的盈利预测优于时间序列模型的盈利预测。在一个参与者寻求自身利益最大化的市场中,我们假定盈利预测的提供方和需求方都以预测准确性为基础来确定盈利预测的供求。并且,毋庸置疑的是,证券分析师盈利预测的代价高于时间序列模型的盈利预测。在此情况下,以寻求自身利益最大化为目标的公司长期雇佣证券分析师进行盈利预测就意味着证券分析师的盈利预测比时间序列模型的盈利预测更为准确。
大量实证研究结果已证实了证券分析师盈利预测的优越性(Brown and Rozeff,1978;Brown et al.,1987;Crichfieldet al.,1978;Collins and Hopwood,1980;Fried and Givoly,1982;O’Brien,1988)。很多研究者还发现越接近财务报告日,证券分析师的盈利预测就会越 准 确 (Crichfieldet al.,1978;Collins and Hopwood,1980)。 不过,分析师的盈利预测也在一定程度上存在系统性偏误,即证券分析师的预测过于乐观,倾向于高估盈利 (Fried and Givoly,1982;O’Brien,1988)。
值得强调的是,O’Brien(1988)在其实证研究中将证券分析师的盈利预测细化为三种指标:分析师预测的均值、中位数和最新值。除了证实分析师预测优于时间序列模型预测之外,她还发现最新值优于均值和中位数。但是,当剔除比较旧的分析师预测之后,在较远的预测区间内最新值与均值和中位数并无显著差异,而在较近的预测区间内,均值、中位数则优于最新值。这一结果表明相比于消除个别分析师的预测偏误而言,预测日期的新旧对于盈利预测准确性更为关键。
近年来,国内的一些研究也发现我国证券分析师的盈利预测优于时间序列模型的预测(岳衡、林小驰,2008;吴东辉、薛祖云,2005)。但是,国内的研究仍然较为不足,尤其是忽视了分析师预测的均值、中位数和最新值之间的准确性;此外,还局限于利用历史年度盈利数据的时间序列模型,忽视了更为有效的季度盈利预测模型。有鉴于此,本文试图弥补上述空白,进一步深入研究我国证券分析师的盈利预测相比于时间序列模型预测的准确性。
三、实证研究设计
(一)时间序列模型
目前,国内很多研究均采用随机游走模型,并根据历史年度盈利数据来预测企业未来的年度盈利(岳衡、林小驰,2008;吴东辉、薛祖云,2005)。然而,要预测年度盈利,最有效的办法是运用季度盈利预测模型来预测未来年度中各个季度的盈利,然后将其加总(Watts and Zimmerman,1986; Kothari,2001)。 因此,除了随机游走模型,本文还运用两个基于季度盈利的时间序列模型:Seasonal Martingale Model和Seasonal Sub-martingale Model(之所以没有采用其他更为复杂的时间序列模型,主要是因为目前我国上市公司无论是年度盈利还是季节盈利的数据在时间序列上都太少,不足以支持较为复杂的模型),并以季度盈利预测为基础,按照相应的预测区间分别形成年度盈利预测 (年度盈利预测是已经公布的实际季度盈利与未来季度预测盈利之和)。预测区间分别为“提前四个季度”,即2004年年报公布后,2005年第一季度季报公布前;“提前三个季度”,即2005年第一季度季报公布后,2005年中报公布前;“提前二个季度”,即2005年中报公布后,2005年第三季度季报公布前;“提前一个季度”,即2005年第三季度季报公布后,2005年年报公布前。
1.季度鞅模型(Seasonal Martingale Model)。 F(Xt)=Xt-4;下标 t表示时间(季度),Xt表示实际盈利,F(Xt)表示预测盈利。
2.季度下鞅模型(SeasonalSub-martingale Model)。 F(Xt)=Xt-4+(Xt-1-Xt-5);下标t表示时间 (季度),Xt表示实际盈利,F(Xt)表示预测盈利。
3.随机游走模型 (Random Walk Model)。 F (Xt)=Xt-1; 下标 t表示时间(年),Xt表示实际盈利,F(Xt)表示预测盈利;对于同一家公司而言,这一模型在不同预测区间的年度盈利预测是一样的。
(二)预测误差指标
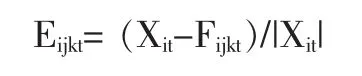
其中i代表公司,j代表预测模型或方法,k代表预测区间,t代表年度。Xit代表i公司t年度实际盈利,|Xit|代表i公司t年度实际盈利的绝对值。Fijkt代表用j模型对i公司t年度盈利提前K个季度的预测,Eijkt代表用j模型对i公司t年度盈利提前K个季度预测值的预测误差。为了检验预测误差是否存在系统性偏误,本文采用Wilcoxon Signed Ranks test,因为它较不容易受到预测误差定义和极端值的影响(Brown and Rozeff,1978)。预测误差取绝对值之后的指标|Eijkt|代表了预测准确性。为了检验不同模型的预测准确性差异,本文采用了Friedman检验 (针对两个以上预测模型之间的比较)和Wilcoxon符号秩检验(针对两个预测模型之间的比较),因为它们较不容易受到预测误差定义和极端值的影响(Brown and Rozeff,1978)。
(三)数据收集与整理
Wind数据库收集了35家证券研究机构提供的A股上市公司2005年每股收益预测数据。截至2006年4月30日,有1 340家A股上市公司公布了2005年年报,其中有1 090家公司有2005年每股收益的预测值。由于这些证券公司对同一家上市公司在不同时间陆续发布了预测值并不断进行修正,所以任何一家上市公司都存在多家证券机构的预测值。这些预测值的预测日期最早的是2004年年末,最晚的是公司2005年年报公布日前一日。另外,上市公司2003—2005年的年度每股收益和季节每股收益也来自Wind数据库(每股收益的预测数据和实际数据均为全面摊薄的每股收益)。
根据Wind提供的预测数据的特点,笔者取得分析师预测的三种指标,即均值、中位数和最新值。具体而言,首先,根据四个不同的预测区间确定四个日期,分别是2005年年报公布日之前十个交易日(选择截至于财务报告日之前“十个交易日”,是为了避免盈利信息提前泄露造成的影响),对应于“提前一个季度”;2005年第三季度季报公布日之前十个交易日,对应于“提前二个季度”;2005年中报公布日之前十个交易日,对应于“提前三个季度”;2005年第一季度季报公布日之前十个交易日,对应于 “提前四个季度”。基于这四个日期,再分别取得各个日期前各预测机构(或分析师)作出的最新的预测值和相应的预测日期。然后,计算出均值和中位数。最后,在这些预测值中选取预测日期最新的预测值作为盈利预测最新值,若该数值不止一个,则取它们的均值作为盈利预测最新值。
本文采用以下规则形成研究样本:在同一预测区间内,每一家上市公司必须同时存在6种预测方法形成的预测值;未发生送股、转股和红股等变动总股本的事项 (如果上市公司发生送股、转股和红股等变动总股本的事项,这会导致总股本变动前后分析师对每股收益的预测和历年实际的年度及季度每股收益数据不可比。因此,笔者根据研究惯例,剔除了发生这些事项的公司)。运用这一规则后,从“提前四个季度”至“提前一个季度”的四个预测区间内,分别有352家、639家、642家和696家公司,本文称其为全样本。
为了避免过时的预测值影响分析师预测的准确性 (O’Brien,1988),本文根据四个不同的预测区间确定四个期间,分别是2005年第三季度季报公布日与2005年年报公布日之前十个交易日之间;2005年中报公布日与2005年第三季度季报公布日之前十个交易日之间;2005年第一季度季报公布日与2005年中报公布日之前十个交易日之间;2004年年报公布日与2005年第一季度季报公布日之前十个交易日之间。在上述四个期间内,分别取得各预测机构(或分析师)作出的最新的预测值和相应的预测日期,然后计算出均值和中位数,最后在这些预测值中选取预测日期最新的预测值作为盈利预测最新值 (若该数值不止一个,则取均值作为盈利预测最新值)。
根据上述方法形成分析师的盈利预测后,笔者运用与“全样本”同样的规则,形成了一个“子样本”:从“提前四个季度”至“提前一个季度”的四个预测区间内,分别有106家、588家、236家和347家公司。
四、实证结果及分析
(一)描述性统计分析(见表1)
表1反映了分析师的预测频率,即每家公司平均约有2至4个预测值。 另外,“及时”比例(Y/X)最低仅为21.00%。因此,剔除过时预测值之后,分析师盈利预测的准确性应该有显著提高。
(二)预测偏误分析(见表2)
表2分析了6种预测方法是否存在系统性偏误。在所有预测区间内,均值、中位数和最新值都显著小于0。这意味着分析师的预测存在系统性偏误,倾向于乐观。分析师的乐观偏误可能是受利益驱使而故意发布乐观预测,但也可能是2005年这一特定时期的影响。此外,在所有预测区间,RW和SM都显著小于0,即时间序列模型预测也存在乐观偏误。由于时间序列模型预测很难受到人为操纵,所以这一结果似乎表明分析师的乐观偏误源于特定时期的影响。
(三)预测准确性分析
表3分析了6种预测方法的预测准确性。就时间序列模型而言,在所有预测区间内,SM显著优于RW和SSM,RW和SSM之间没有一致的结果。这证实了由一个合适的季度盈利模型(SM)所获取的年度盈利预测优于由年度盈利模型(RW)获取的年度盈利预测。
就分析师而言,最新值优于均值和中位数,或至少与其同样准确。一般来说,预测日期越新,分析师可以利用的信息也就越多,相应的盈利预测就会越准确,所以过时的预测值其准确性要低于及时的预测值。有鉴于此,相当比例过时预测值的存在(见表1)使得全样本中均值和中位数的准确性大打折扣。尽管它们仍然可以抵消个别分析师的预测偏误,但总体上无法与最新值相比拟。这一结果表明相比于消除个别分析师的预测偏误而言,预测日期的新旧对于盈利预测准确性更为关键(O’Brien,1988)。
将分析师预测与时间序列模型预测相比较,SM在所有区间内都比均值、中位数和最新值更准确,RW和SSM与均值、中位数和最新值互有优劣。总体而言,这一结果并不支持分析师预测的优越性。其原因如下:一般来说,证券分析师相比于时间序列模型具有信息优势;但是,全样本未剔除分析师过时的预测值,而过时的预测值与时间序列模型预测相比非但没有信息优势,反而存在一定的信息劣势,从而可能最终干扰了分析师相比于时间序列模型的准确性。基于这一原因,本文接下来采用子样本来探讨分析师预测相比于时间序列模型预测的准确性,相关实证结果如下页表4所示。
表4分析了子样本中6种预测方法的预测准确性。就分析师而言,由于剔除了过时的预测值,均值和中位数的准确性得到了显著提高——它们略优于最新值。一般来说,单个分析师的预测会产生乐观或者悲观的偏误。如果取得众多分析师预测的均值或者中位数,这些偏误就会相互抵消。同时,因为剔除了过时的预测值,所以均值和中位数的准确性不会受损于那些较旧的预测值。因此,均值或者中位数会比包括最新值在内的任何单个分析师的盈利预测更加准确。

表1 分析师预测的数量分析

表2 预测偏误
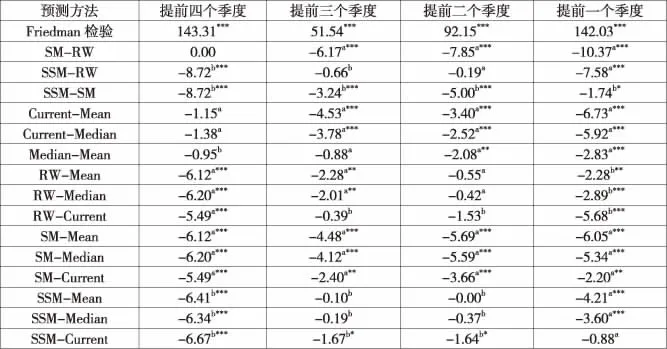
表3 预测准确性(全样本)
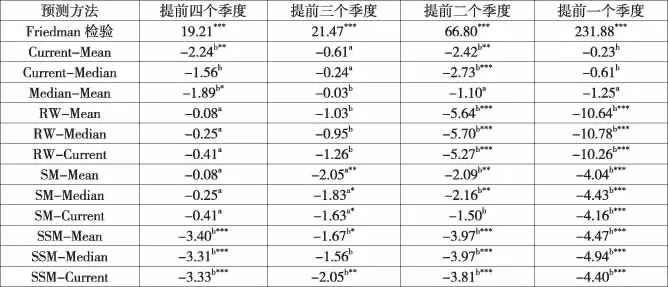
表4 预测准确性(子样本)
就分析师与时间序列模型的比较而言,关于SM,在较早的预测区间内(提前三个季度),SM倾向于比均值、中位数和最新值准确,但在较晚的预测区间内 (即提前二个季度和提前一个季度),均值、中位数和最新值倾向于比SM准确。关于RW和SSM,均值、中位数和最新值都倾向于比RW和SSM准确。这一结果表明,在剔除过时的分析师预测值之后并且在比较接近2005年年报公布日的期间内,分析师的预测优于时间序列模型预测,或至少与其同样准确。这一结论在一定程度上证实了证券分析师盈利预测相比于时间序列模型预测的优越性。
五、结论与启示
本文的研究不仅有助于投资者和研究人员深入理解证券分析师盈利预测的性质及其相比于时间序列模型预测的准确性,而且有助于他们在相关的投资决策和学术研究中合理地运用分析师的盈利预测。本文的主要结论及相应的启示如下:
首先,证券分析师的盈利预测存在系统性偏误,倾向于过度乐观、高估盈利。不过,这一偏误可能源于特定时期的影响,而非受利益驱使所致。
其次,就时间序列模型而言,以合适的季度盈利模型(Seasonal Martingale Model)为基础形成的年度盈利预测比以年度盈利模型(随机游走模型)为基础形成的年度盈利预测更加准确。
再次,就证券分析师盈利预测而言,如果不剔除过时的分析师预测值,那么最新值优于均值和中位数。这表明相比于消除个别分析师的预测偏误而言,预测日期的新旧对于盈利预测准确性更为关键。若剔除过时的分析师预测值,均值和中位数则略优于最新值。此时,因为消除了单个分析师预测可能存在的偏误,均值或中位数比包括最新值在内的任何单个分析师的盈利预测更加准确。一言以蔽之,最新值、均值和中位数之间在剔除过时的分析师预测值前后的准确性差异提醒投资者和研究人员需要谨慎分析和合理运用证券分析师的盈利预测。
最后,就分析师与时间序列模型的比较而言,在未剔除过时的分析师预测值的条件下,由于其降低了分析师的信息优势 (甚至转化为信息劣势),从而使得时间序列模型预测优于分析师的预测。剔除过时的分析师预测值之后,分析师盈利预测的准确性得以显著改善,从而使得在接近2005年年报公布日的期间内,证券分析师的预测优于时间序列模型的预测。这一结论在一定程度上证实了证券分析师盈利预测相比于时间序列模型预测的优越性。
猜你喜欢
今日农业(2021年12期)2021-10-14 07:31:02
汽车观察(2018年10期)2018-11-06 07:05:10
现代企业文化(2018年13期)2018-06-09 08:22:26
统计与决策(2018年9期)2018-05-22 13:17:41
海外华文教育(2017年8期)2017-11-07 04:42:02
商周刊(2017年6期)2017-08-22 03:42:50
海外华文教育(2016年4期)2017-01-20 08:22:28
试题与研究·中考数学(2015年2期)2015-06-05 10:19:34
试题与研究·中考数学(2015年2期)2015-06-05 10:13:02
中学数学杂志(2014年6期)2014-03-01 03:48:18
