
基于Hadoop的高校日志分析应用架构的研究
2015-09-10 07:22孙彦超李忠刚
中国教育信息化·基础教育 2015年8期
孙彦超 李忠刚

摘 要:随着信息化的建设,高校管理系统越来越多,通过查看分析系统日志可以监测系统状态,调查系统故障,更好地保证系统的正常运行。但由于日志数据量巨大,不易被读懂,无法通过人工分析挖掘出有价值的信息。分布式计算的出现,为解决这一难题提供了思路。Hadoop用于构建分布式存储开源框架,通过部署在上面的MapReduce程序,广泛地应用于处理海量的数据。结合具体问题,文章设计了基于Hadoop的高校日志分析系统,并深入分析了该系统的业务处理流程和系统功能框架。通过对实验结果的分析,证明了系统是有效的和有价值的。
关键词:日志分析;Hadoop;集群;分布式计算
中图分类号:TP393 文献标志码:B 文章编号:1673-8454(2015)16-0082-03
一、引言
计算技术的不断发展带动着高校信息化建设的深入,为了实现信息化教学管理,各大高校采用越来越多的系统。与此同时,系统需求复杂程度也越来越高,为了使这些系统能够正常运行,以及保证其安全性和可扩展性,查看日志已经成为一项重要的途径。通过分析日志数据,可以获取许多有价值的信息,如设备故障、网络运行历史背景、网络异常行为等方面的信息。[1]
但由于这些日志数据量大,且不易被读懂,利用传统的技术进行分析,在存储和计算量上都会遇到很大的困难,难以挖掘出对改进用户体验和提升管理水平都非常具有价值的信息,分布式计算技术恰好可以很好的解决这个问题。[2]
Hadoop作为当前流行的处理大数据的平台,近年来备受业内关注,因此得到了快速的发展,在网页搜索、日志分析、广告计算和科学实验等领域中出现了许多相关应用[3-5]。著名电商网站淘宝网拥有3000个节点的Hadoop集群,如此大规模的集群为它的日常运营做出了关键支撑。除此之外,Facebook、百度、Yahoo等众多互联网巨头也都在使用Hadoop。[2]
基于Hadoop 技术的特点,可以用它来存储高校的日志数据,并开发相应的算法对这些数据进行挖掘分析,提高高校对这些日志数据的利用价值。本文以高校日志分析系统为例,介绍了Hadoop在海量日志分析中的应用架构。
二、Hadoop介绍
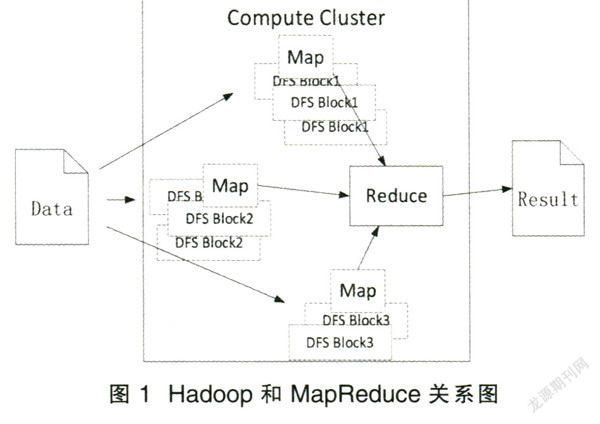
Hadoop是Apache开发的开源的MapReduce集群实现。Hadoop的核心包含两部分,分别是Hadoop分布式文件系统(HDFS)和在此之上的MapReduce编程模型实现。Hadoop分布式文件系统(HDFS)是一个适合运行在通用硬件和大规模数据集上的分布式文件系统。而MapReduce是一种分布式编程模型,用于大规模数据集的并行计算,编程人员不用考虑分布式并行编程的具体实现,就能开发出分布式计算程序。HDFS和MapReduce的关系如图1。
每个HDFS采用Master/Slave架构,主要有四个组成部分:客户端(Client)、元数据节点(NameNode)、副元数据节点(Secondary NameNode)和数据节点(DataNode)。一个HDFS集群只包含一个元数据节点,元数据节点存储整个分布式文件系统的元数据信息,此外,还负责监控数据节点是否正常,如果出现异常情况,就将其从整个文件系统中删除。副元数据节点负责定期整理元数据节点中的文件,为其分担一部分工作,提高对内存资源的利用率。数据块的实际存储由数据节点负责,包括数据的读写,并定时向元数据节点汇报存储块的信息。[6]
MapReduce是一个把数据集的大规模操作分发给每个节点,从而实现并行计算的编程模型。MapReduce提供了简洁的编程接口,对于某个计算任务来说,其输入的是键值对,输出也以键值对的方式表示。MapReduce中的Map函数将用户的输入数据以键值对形式通过用户自定义的映射过程转变为同样以键值对形式表达的中间数据。而Reduce过程则会对中间生成的临时中间数据作为输入进行处理,并输出最终结果。[6]
三、系统架构
基于Hadoop的高校日志分析系统的日志处理流程主要由存储、分析和显示三个部分构成[1],如图2所示。在存储阶段,日志服务器负责接收日志源提供的日志,并将这些数据按照顺序存放在数据库或者文件中,之后再转储到Hadoop集群中,进行必要的数据归并和清洗,以便后续的分析处理;在分析阶段,MapReduce程序需在Hadoop集群中运行,按指定条件查询或挖掘日志数据,获得期望的信息;为了把这些信息进行归并和转换,日志分析结果仍然以文件形式存储在Hadoop集群中,经过专门的处理后,最后的结果以可视化的形式显示给用户。
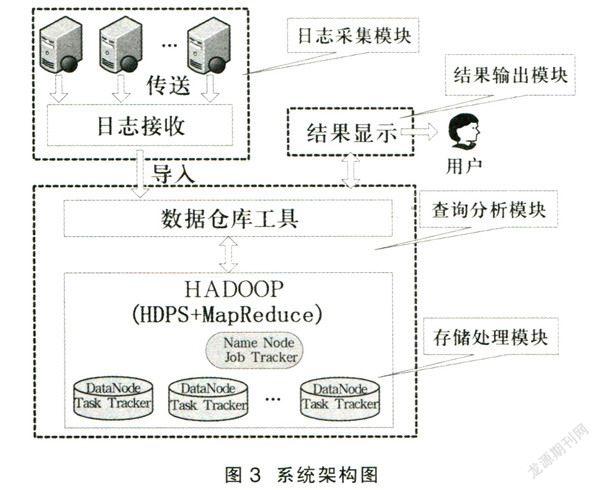
根据上述的日志分析流程,为了实现功能需求,可将基于Hadoop的高校日志分析系统的逻辑架构方案设计如图3所示。
1.日志采集模块
采集并传送日志源产生的日志数据。日志的采集采用定时传送的方式,即日志接收节点每天定时收集每一个前端Web服务器中产生的日志数据。通过后台脚本,日志收集节点将从各个Web服务器采集到的日志数据导入到数据仓库工具中。
2.查询分析模块
在此模块中,需要一个非常重要的工具,即专门用于为用户提供查询接口的数据仓库工具(HBase,Hive等),它部署在元数据节点(NameNode)上。
查询模块的功能如下:首先,日志采集模块采集到的都是一条一条的日志记录,为了方便后续的查询和处理,需要将每个系统的日志数据映射成数据库表,结构化到数据库的概念之中;其次,由于系统是分布式的,查询模块需要提供大规模的查询分析功能来满足大量用户的查询请求,再将查询结果返回给结果输出模块。
在实际处理用户的自定义查询时,数据仓库工具执行的步骤如下:①客户端(Client)组件接收并向驱动器提交自定义的查询语句。②驱动器负责接收并转发客户端传来的查询语句给编译器,编译器收到后,将查询语句进行解析、优化。HDFS任务和MapReduce任务组成一个类似有向无环图的优化策略,最后,这些任务被执行引擎利用Hadoop来完成。
3.存储处理模块
存储处理模块同上述的查询分析模块部署在同一Hadoop集群中,它是由HDFS负责具体的执行,包括实际数据存储和数据仓库工具提交的MapReduce任务。首先,JobTracker创建一个包含Map任务和Reduce任务的作业对象,其中Map任务根据己划分的输入信息来创建,Reduce任务则根据一定的属性来设置。在初始化工作完成之后,每个TaskTracker会收到来自JobTracker根据特定调度算法分配的任务。TaskTracker接收到任务后,从共享文件系统中将任务文件和程序运行所需的文件复制到本地文件系统。然后,创建任务工作目录并为运行该任务新建一个实例。当完成作业的所有任务后,该作业的状态被JobTracker标记为成功,并被发送给数据仓库工具。
4.结果输出模块
结果输出模块负责将查询结果以某种形式表现给用户查看。后台将客户端传来的查询请求传递到查询分析模块,数据仓库工具将其编译、解析和优化后生成MapReduce任务,存储处理模块就负责处理这些查询任务,并将结果通过查询分析模块返回到结果输出模块,最后以可视化的形式呈现给用户。
四、测试
为了验证基于Hadoop的高校日志分析系统的有效性,我们构建了一个特定的实验平台并采用了特定测试方法。
1.实验环境
硬件平台包含6台服务器,其中的一台用来作为HDFS的元数据节点,4台作为数据节点,这5台机器充当Hadoop集群,另外一台用作与之进行对比的单机。具体配置如下:处理器类型:Intel(R) Core(TM)2Duo E6600 @2.40GHz;内存大小:2GB。集群服务器操作系统:ubuntu-12.04,Hadoop版本:Hadoop-0.23.1。
2.实验数据及内容
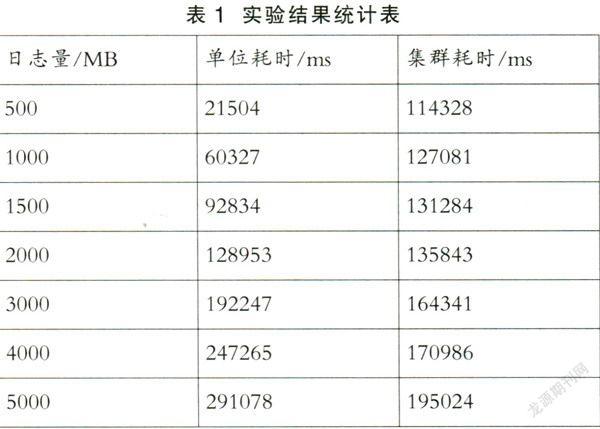
在实验中,输入内容为实际的系统产生的几组日志数据,这几组的数据量大小不同,在Hadoop集群和传统单机模式下分别处理这些数据,最后统计出两者消耗时间的长短,进行结果的对比。统计结果如表1所示。
3.实验结果分析
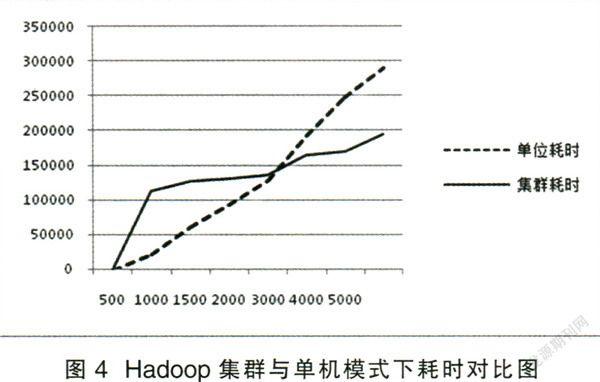
分析实验结果发现,在日志数据量小于2G的情况下,Hadoop集群的时间消耗大于单机处理,其处理海量数据的优势并未发挥出来。但当需要处理的日志数据大小超过2.5G时,Hadoop集群的优势就会慢慢显现出来,且随着数据量的逐渐增大,其优势也会越来越明显,具体如图4所示。
四、结论
高校系统日志分析是高校日常管理的重要保障之一,本文提出基于Hadoop的高校日志分析系统,利用Hadoop集群在海量数据处理方面的优势,高效地进行海量日志数据的分析和挖掘,具有很高的实用价值。实际上Hadoop还有很大的应用空间,这些还有待进一步的研究。
参考文献:
[1]杨锋英,刘会超.基于Hadoop的在线网络日志分析系统研究[J].计算机应用与软件,2014(8):311-316.
[2]胡光民,周亮,柯立新.基于Hadoop的网络日志分析系统研究[J].电脑知识与技术,2010(22):6163-6164,6185.
[3]程苗,陈华平.基于Hadoop的Web日志挖掘[J].计算机工程,2011(11):37-39.
[4]Yang F Y,Liu H Ch. Research in HDFS based on Campus Network Environment[C]//Processing of 2011 International Conference on Image Analysis and Signal Processing. WuHan,China,2011:648-652.
[5]Lou J G, Fu Q,Wang Y, et al.Mining dependency in distribute system through unstructured logs analysis[J].Operating Systems Review (ACM),2010,44(1):91-96.
[6]刘永增,张晓景,李先毅.基于Hadoop/Hive的Web日志分析系统的设计[J].广西大学学报(自然科学版),2011(S1):314-317.
(编辑:鲁利瑞)
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
系统工程与电子技术(2016年2期)2016-04-16
