
汽车车内噪声与振动等级评估*
2015-09-04 06:25刘兴恕张伯俊张鹏飞
汽车工程师 2015年8期
刘兴恕张伯俊张鹏飞
(1.天津职业技术师范大学汽车与交通学院;2.邢台职业技术学院)
噪声与振动是汽车界最活跃的研发领域之一,在汽车研究与产品开发过程中的作用越来越突出。汽车制造公司为了提高汽车车内舒适度,积极开展研究。研究人员认为在汽车车内,暴露的噪声与振动直接与发动机转速的增加或者减少一致,一般来说,与发动机转速的传播成正比。在前人研究的基础上,本研究基于试验考虑了声品质指标和振动,通过聚类和分类算法建立评估模型,使用“遗传算法-神经网络”(GANN)分类聚类的数据,应用线性判别分析(LDA)验证分类结果[1]。研究表明:采用聚类和分类算法评估汽车车内噪声与振动等级是可行的,并为今后车内噪声与振动分析和控制提供借鉴。
1 研究方法
1.1 振动评估
测量振动等级最理想的方法是参考振动剂量值,故在本研究中,依据文献[2]并参考加权加速度评估振动等级。振动剂量值的计算公式为:
式中:μVDV——振动剂量值,ms-1.75;
a(t)——加权加速度,m/s2;
t——时间,s;
T——发生振动的总时间,s。
1.2 声学等级评估
文章使用声品质软件,选择响度、尖锐度、粗糙度和抖动度4个声品质指标[3],来定量并且定性地评估声学等级。
1.3 蒙特·卡罗模拟
蒙特·卡罗模拟是一种概率性技术,通常是基于目前数据中存在的趋势用来产生大量的随机样本[4]。由于多元正态分布(MVN)是蒙特·卡罗模拟的一种应用,且文中数据涉及多个变量,因此,使用MVN法是最合适的方法[5]。
1.4 聚类和分类
1.4.1 聚类
本方法对聚类所应用的工具是层次聚类。聚类过程的初始步骤在于将数据集中的每个项目分配到其本身的群中。在这种情况下,如果项目数为n,即意味着现在具有的群数为n。这是因为每个群仅包含一个项目。在这里,就项目之间的距离而言令相似性等于群之间的距离;然后,通过观察最相似的一对,或者可以组合为单个群的最接近的群,继续该过程,如图1所示。
1.4.2 分类
分类包括“遗传算法-神经网络”(GANN)和线性判别分析(LDA)。在本研究中,出于分类的目的而采用GANN模型。该模型包括遗传算法和人工神经网络2个要素。LDA作为另一种选择,通过“类别和其他范围内的分散矩阵”及“类别之间的分散矩阵”2种分类方法,旨在最大化类别之间的可分性。
2 试验
根据声音频率和振幅测量噪声,使用B&K头&躯干(HAT)2100型传感器获得特定的声品质指标。评估振动等级的测量位置包括前车门(副驾驶员侧)、变速箱、转向装置、前车门(驾驶员侧)、仪表盒和后侧车门(驾驶员侧)[6]。需要在3种状态下进行数据测量:
1)静止:无任何路面激励的影响;
2)高速路上的运动:路面粗糙度的影响适中;
3)人行道上的运动:路面粗糙度的影响强烈[7]。
测试车采用自动质子位V6发动机。测量车内声品质所使用的设备为布鲁尔&卡亚尔便携式及多通道脉冲3560D型仪器。为了记录噪声,B&K头&躯干(HAT)2100型传感器位于前排副驾驶右侧车门,在仪表板前底部安装了振动探测器B&K同位素分离器751-100模型,如图2所示。
首先使用B&K脉冲Lapshop软件测量噪声;然后使用布鲁尔&卡亚尔声品质7698型软件分析噪声,获得声品质指标值。在本例中,所有测点处读取的数据必须记录汽车底部、仪表盒、转向、车门和变速箱的振动测量值。
测量中每个试验的记录时间为10 s,由驾驶员和笔记本电脑处理器进行测试。驾驶员的任务是驱动汽车,专注于汽车行驶方向并维持特定的转速。与此同时,笔记本电脑处理器的任务是操作B&K脉冲Lapshop软件,记录测试过程中在每个试验中发生的噪声和振动。发动机在特定转速下,每个测量必须重复3次[8]。
3 结果
基于声品质指标的测量结果,发现在驻车或者驱动状态下,响度指标值随着发动机转速的增加而增加。与响度指标相反的是尖锐度指标值随着发动机转速的增加而减少。然而,关于粗糙度指标和抖动度指标对发动机转速的变化并没有观察到特别的趋势。应用方差分析(ANOVA)来研究存在于不同位置之间结果中的变化,如图3所示。
从图3可以看出,产生振动等级较高的主要位置是汽车仪表盒、转向、车门和变速箱。比起其他零部件,汽车底部是具有较低振动暴露的唯一位置。
通过调查声品质参数与振动剂量值之间存在的相关性,可以建立线性回归模型确定这2个因素之间存在相关性的明显程度。根据线性回归分析的结果,发现在特定零部件上声品质指标的某些参数与暴露的振动的某些等级是一致的,如图4所示。选择的因素是响度指标和在汽车底部、转向和变速箱处的暴露振动。为了评估驾驶室内经历的声品质等级,将这4个因素作为聚类模型中的输入,以便能够将其分成5种舒适度,如表1所示。
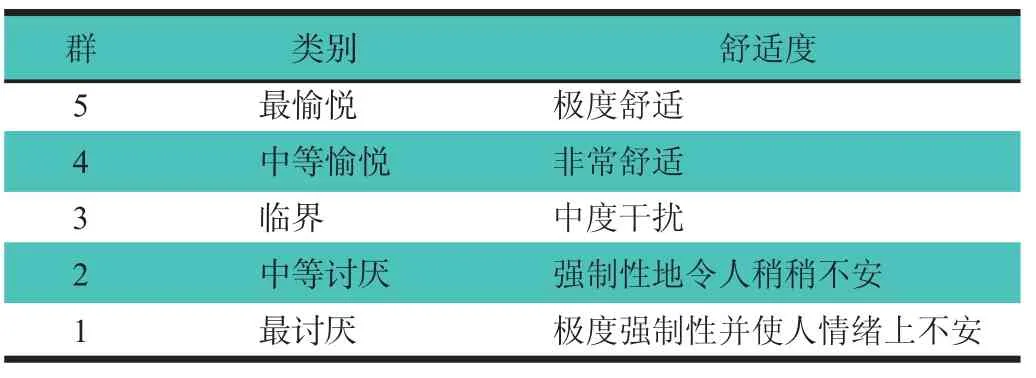
表1 汽车车内舒适度特性
尽管在驾驶室内测量了不同零部件处的振动等级,但是注意到只有一些区域是明显的振动暴露点,其中仅选择与参数响度、底部、转向及变速箱因素相关联的数据应用在聚类和分类过程中。明显的暴露振动点可以通过线性回归分析结果观察到。聚类结果根据发动机转速在1 200~3 500 r/min范围内,分别在静止、高速路及人行道状态下,获得的响度及振动剂量值(底部、转向和变速箱)的数值不同,对应的群类也不同。基于所观察到的结果,发现通过考虑输入的噪声与振动,使用基于舒适度的层次聚类,可以对噪声与振动的暴露成功进行聚类。这是一个新颖的方法,而不是暂时的评估,因为这些暴露的噪声与振动通常是主观的,并且很难评估。
根据评估结果,还知道层次聚类能够找到在调查的特定零部件上响度参数与暴露的振动之间存在的相关性。为生成更多的数据,模拟了层次聚类,在这之后,执行的分类过程产生的结果准确性更高。在分类过程中使用了GANN和LDA 2类分类,对每个GANN模型,分类算法都进行了20个试验。在相应的模型中通过衍生的5 000个数据库和测试的2 500个数据库,来评估提出的GANN。同时对于每个LDA模型,衍生的数据库为5 000个。根据聚类所得到的结果,通过随机模拟可以获得分类所需的数据库。基于这些结果,发现2种模型对于数据的分类是足够有效的,因为获得每个试验的精度都超过70%。但是,对比这2种模型,LDA的性能要比GANN的性能更好,如图5所示。
4 结论
基于提供的数据,提出的层次聚类的算法和混合GANN与LDA 2种算法能够有效地聚类和分类噪声振动的等级。通过参考经历噪声与振动的趋势,提出的模型就噪声振动而言能够将这些组之间的舒适度区分为最愉悦、中等愉悦、临界、中等讨厌和最讨厌5个群。除此之外,LDA算法通过使用噪声振动的输入数据库,成功简化了经历的噪声振动产生的舒适度。通过观察图5中的结果,得出相比于GANN,LDA算法更有效,因为后者表现的准确率更高。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
无线互联科技(2022年2期)2022-04-20
计算机应用与软件(2021年7期)2021-07-16
舰船科学技术(2021年12期)2021-03-29
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
劳动保护(2019年3期)2019-05-16
科技传播(2018年5期)2018-04-07
演艺科技(2017年8期)2017-09-25
中学生数理化·八年级物理人教版(2016年8期)2016-12-24
饮食科学(2016年7期)2016-07-27
