
嵌入技术的动态异构信息网络的演化聚类
2015-08-23 09:37:02陈丽敏杨静张健沛
哈尔滨工程大学学报 2015年5期
陈丽敏,杨静,张健沛
(1.哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨150001;2.牡丹江师范学院计算机科学与技术系,黑龙江牡丹江157011)
信息网络普遍存在,如社会信息网络、DBLP书目网络,这些网络由多种类型数据构成,不同类型数据之间彼此关联,称之为异构信息网络。对异构信息网络聚类分析能更好地理解网络的隐藏结构以及每个类的数据所代表的角色[1],而基于概率模型的异构信息网络聚类算法[2-3]只针对具体的应用领域设计函数,不具有普遍性,且收敛性也不稳定。异构网络的链接推理[4]时,往往需要最初的聚类划分更精确一些,而传统的高阶异构聚类算法[5-6]复杂度太高不适合异构信息网络。异构信息网络经常是动态的而非静态的,动态同构数据的演化聚类[7]的研究已经做了很多,而动态的异构信息网络的演化聚类分析,目前只有ENetClus[8]算法,该算法没有关注聚类质量,更侧重跟踪类的变化及分析类的推进、形成与消失。Khoa[9]使用近似 commute time嵌入聚类同构数据集,取得了很好的效果。受该思想启发,本文从相容二部图的角度提出一种基于嵌入技术的动态异构信息网络的演化聚类算法,具有较高的聚类质量,且计算速度也比较快。
1 时间平滑二部图
定义 1:给定G=<V,E,W>,V=X0∪X1,其中X0与X1为2个不同类型的数据集。若∀〈xi,xj〉∈E,则xi∈X0且xj∈X1,称G为二部图。
r(xi,xj)表示二部图G的结点xi与xj的关系,若结点xi与xj有关系,则结点xi与xj之间有边存在,否则无边存在。
给定t时刻的二部图Gt,∀xi,xj∈Gt。使用代价函数时间平滑Gt两结点的关系:

式中:rt(xi,xj)表示t时刻结点xi与xj的时间平滑的关系,rO(xi,xj)表示t时刻二部图两结点的原始关系,即没有时间平滑的关系。rt-1(xi,xj)表示先前时间结点xi与xj之间的关系。SC(·)为快照代价函数,表示t时刻rt(xi,xj)与rO(xi,xj)的相似度。TC()为时间代价函数,表示t时刻rt(xi,xj)与rt-1(xi,xj)的相似度。
函数SC()和TC()可选择多种衡量指标。取SC()=,使cost最小的rt(xi,xj)就是最佳关系,则两结点最佳的关系为

例如,t时刻DBLP书目网络的papers与authors构成一个二部图G,G中只有不同类型的结点之间存在关系。t时刻的G中,先前时间的papers已经全部更换,但先前时间的authors会保留在t时刻的二部图中,因此t时刻的二部图G,仅使用异构数据的关系无法体现先前时间authors之间的联系。而先前时间authors之间的联系影响着t时刻papers的划分。所以需要表达先前时间所有结点间的关系。cij表示二部图结点i,j的commute time距离,cij能够表达二部图的所有结点间的关系。cij是2个结点间所有路径的平均值,故cij能够表达一段时间两结点的关系。令ct(xi,xj)表示t时刻及先前时间结点xi与xj的 commute time 距离。令rt-1(xi,xj)=ct-1(xi,xj),rO(xi,xj)是t时刻二部图Gt中两结点的原始关系。由式(1)获得t时刻时间平滑二部图,若rt'(xi,xj)≠0,则两结点之间存在边,否则无边。rt'(xi,xj)≠0的数目就是的边的数目,中2个相同类型的结点之间也可能存在边。充分体现了t时刻及先前时间所有结点间的关系。
式(1)只计算t时刻属于的结点间的关系。先前时间结点的关系会导致不够稀疏,通过计算Gt中也属于的结点的k近邻,可构造稀疏的时间平滑二部图。由2.2节可快速计算的近似commute time嵌入,而由嵌入可计算任意两结点的ct(xi,xj),因此每次只要存储t时刻近似commute time嵌入即可。
2 时间平滑二部图的近似commute time嵌入
2.1 时间平滑二部图的commute time嵌入
设G'是加权无向图,L是G'的Laplacian矩阵,L+是L的伪逆矩阵,则
性质 1[10]:cij=Gvol'(ei-ej)TL+(ei-ej)
其中Gvol'是G'的权重总和,即Gvol'=∑wij;wij为G'的结点i、j构成的边的权重;ei是第i个元素为1的单位列向量,即
设Λ与Φ分别是时间平滑二部图的Laplacian矩阵L的特征值构成的对角矩阵及特征值对应的特征向量矩阵,特征值λ1≤λ2≤…≤λn。L+是的矩阵L的伪逆矩阵,则由性质1,的任意两结点i,j的cij为

则cij是空间第i列向量与第j列向量的欧式距离的平方,称为时间平滑二部图的commute time嵌入[11]。
直接计算ψ需花费O(n3)时间分解特征矩阵。设有n个结点s条边,定向的边,令

则 Bs×n是一个有向边-点入射矩阵。令是由边的权值构成的对角矩阵,则的Laplacian矩阵 L=BTB[11]。
2.2 时间平滑二部图的近似commute time嵌入
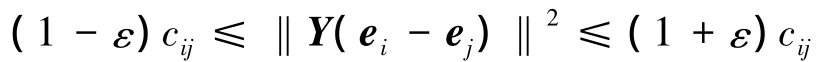
其中,Qkr×s是行向量独立同分布的随机矩阵,
但计算Y,涉及L+,直接计算 L+复杂度过高。根据文献[12]方法,可分解计算Y。令(),则 Y=θL+,等价于计算 YL=θ。通过矩阵θ的每个行向量θi计算方程组yiL=θi,其中yi是矩阵Y的行向量。使用STSolve求解程序[13]能够线性时间计算出yiL=θi每个近似的,由于,则
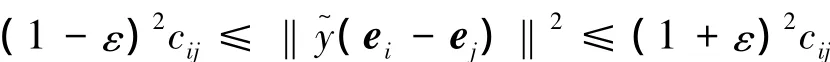
设Gt对应的邻接矩阵为 Wn0×n1,t时刻的近似commute time嵌入的算法如下:
算法1 ApCte(approximate commute time embedding)
输入:t时刻二部图Gt的Wn0×n1;
输出:的近似commute time嵌入;
步骤:
1)查找Gt中属于的结点,由指示数据计算这些结点的k近邻,由式(1)计算的邻接矩阵;
4)采用 STSolve 方法[13]计算 YL=θ 的每个;
5)输出的嵌入。
数据集X0与X1的样本映射到了一个共同的子空间。的前n0个列向量指示数据集X0,后n1个列向量指示数据集X0。设Gt中属于的结点数为nt,nt<n,算法 1 的 1)步采用kd树构造Gt中属于的结点的k近邻需要O(ntlnnt)时间。是稀疏图,邻接矩阵有s个非零元素,则2)步计算B与及L的时间为O(2s)+O(s)+O(n)。因为稀疏矩阵B有2s个非零元素,对角矩阵有s个非零元素,故3)步计算 θ的时间为O(2skr+s)。4)步用STSolve 方法[13]计算的时间为(skr)。则算法 1的时间复杂度仅为(ntlnnt+4s+n+3skr)。
3 基于近似commute time嵌入的异构信息网络的演化聚类
3.1 模型的组成
定义2 给定一个由M+1种类型的数据集χ=构成的信息网络G=<V,E,W>,如果∀e=〈xi,xj〉∈E,那么xi∈X0且xj∈Xmm≠0,则G称为星型模式的异构信息网络,X0称为目标类型,Xm(m≠0)称为属性类型。
给定一个由M+1种类型的数据集构成的星型模式的异构信息网络,其中是Xm的对象数目,X0为目标数据集为属性数据集。W(0m)∈Rn0×nm表示X0与Xm之间的关系,其中,元素表示X0的样本与Xm的样本的关系。如果与存在关系,则与有边存在,边的权重为,否则无边该信息网络包含M个关系矩阵
t时刻目标数据集X0与属性数据集Xm构成一个二部图,由式(1)可计算t时刻时间平滑二部图,设的邻接矩阵为。由 2.2节,可计算的近似commute time嵌入Y(0m)=,其中前n0个列向量指示目标数据集X0,表示为,称之为指示子集,后nm个列向量指示属性数据集Xm,表示为Y(m)。称指示X0第i个对象的数据为指示数据,1≤i≤n0.的指示数据与X0的对象存在一一对应的关系。M个二部图对应M个近似commute time嵌入,则目标数据集X0被M个指示子集所指示,X0的每个对象被M个指示数据所指示。

设X0划分为H个类,β(m)是矩阵的权重,其中数据属于M个类,这M个类分别位于不同的指示子集,这M个类设置相同的类标号。令
从相容的角度,式(2)的目标函数F取得最小值,则目标数据集X0聚类达到最佳。显然,式(2)的全局最优解是NP难问题。
3.2 快速算法的推理
3.2.1 类标号设置
在目标数据集X0中随机选择H个对象,指示这H个对象的指示数据在各自的指示子集中作为H个类的初始中心点,指示同一个对象的中心点,令其所在类的标号一致,则其他指示同一个对象的指示数据或者都属于第j个类,或者都不属于第j个类,1≤j≤H。
3.2.2 加权距离总和
X0的一个对象被M个指示数据所指示,这M个指示数据到各自指示子集的类的中心点的距离都影响着这个对象所属类的分配。设qi∈X0,指示qi,则权重距离总和决定了qi所属的类。即
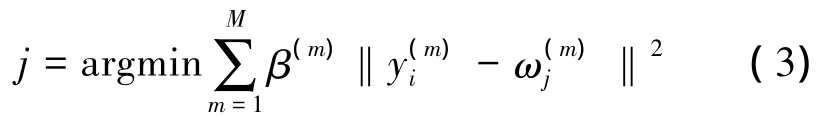
式中:j是qi所属类的标号,也是所属类的标号。
3.2.3F的极小值
式(2)的F也可以表示为指示同一个对象的指示

给定M个指示子集的类的初始中心点,首先由式(3)划分指示子集的类,此时令F=F0;的类的中心点不变,然后计算的每个类的新中心点,新中心点取值所在类的所有指示数据的平均值,令
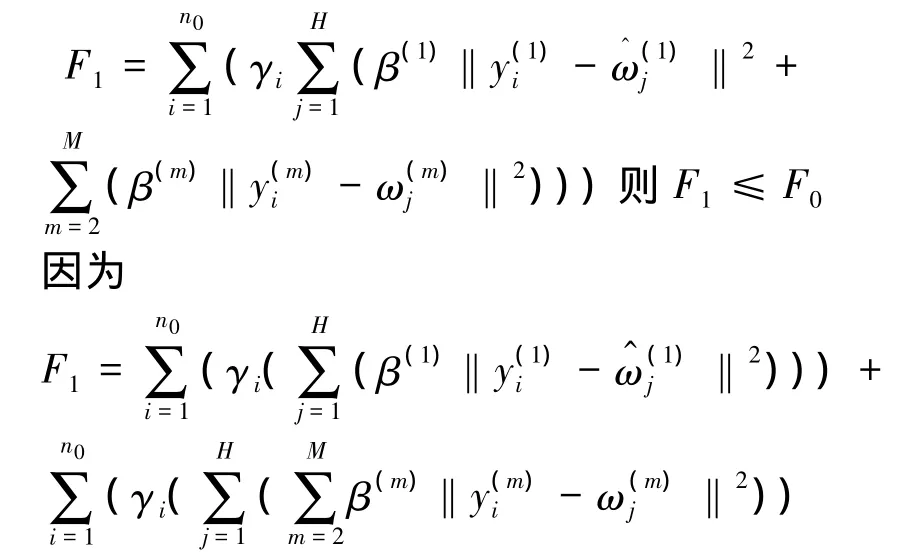

故F1≤F0。
而当的类替换了新的中心点的中心点不变,由式(3)重新划分类,此时令F=F2,则有F2≤F1。
算法2 EClu-pACte(evolutionary clustering algorithm based on approximate commute time embedding for heterogeneous information network)
输 入:t时 刻的,聚类数H;
输出:t时刻目标数据集X0的类;
步骤:
1)form=1∶Mdo
{①由算法1计算的嵌入Y(0m);
②确定指示X0的指示子集;}
3)do
{form=1∶Mdo
{①计算式(3)划分的H个类;
②重新确定每个类的新的中心点,并建立类标号;
}while式(4)收敛;
4)输出目标数据集X0的类。
4 实验
4.1 实验数据
从DBLP信息网络选取真实数据建立实验数据集,取 venues、authors、papers和 terms建立书目网络。选取4个学术区域建立小数据集Ssmall,这4个区域包括 database、data mining、information retrieval和machine learning。每个区域取5个有代表性的conference,共20个会议,20个会议的所有authors、papers及出现在论文题目中的所有terms。papers为目标数据集,venues、authors和terms为属性数据集,建立一个星型模式的异构信息网络。本文使用Ssmall分析kr对聚类准确率的影响。
对1993-2008年上述4个学术区域的20个会议的所有authors、papers及出现在论文题目中的所有terms,分析目标数据集papers的演化情况。
本文算法EClu-pACte的所有实验均采用文献[13]的一种近乎线性时间的求解程序计算的嵌入数据集,该方法用于对角占优矩阵。所有算法均在MATLAB环境中实现。
4.2 关系矩阵的确定
X0表示目标数据集 papers,X1、X2与X3分别表示属性数据集 authors,venues与 terms。则X0与的原始关系为的元素为

4.3 参数kr取值分析
选取小数据集Ssmall,对于给定的kr,取u=50,α=1,参数kr的变化对papers聚类质量的影响,如图1所示。实验说明当kr>50时准确率曲线已经趋于平滑,取kr=60很适合,则其他实验也取kr=60。
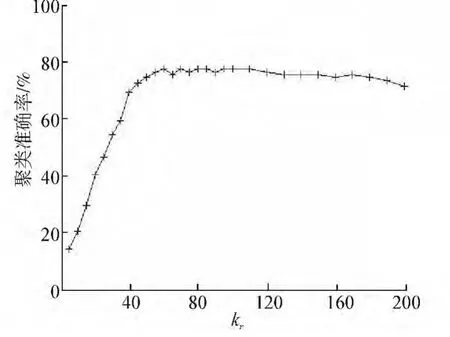
图1 kr对聚类准确率的影响Fig.1 The influence of kron clustering accuracy
4.4 参数α取值分析
参数α是用来平衡快照质量与历史质量的。本实验的目标数据集papers在不同的时间点(年份)是不同的,没有重复的,papers不存在连续性,但属性数据集存在连续性。属性数据集的连续性影响t时刻目标数据集papers的划分,使得t时刻的papers与先前时间的papers存在着关联。本次实验取k=7,α的取值对聚类准确率的影响如图2所示,其中图2的聚类准确率取每个时刻(1994-2008)共计15个聚类准确率的平均值。说明α=0.8聚类质量最好。

图2 α对聚类准确率的影响Fig.2 The influence of α on clustering accuracy
4.5 计算速度分析
划分1994年的papers,比较α取不同值时不同算法的计算速度。如表1所示,当α=1时,t时刻的二部图没有时间平滑,异构信息网络是稀疏的,故计算速度很快,与ENetClus算法计算速度几乎一致。当0<α<1时,计算速度略有下降,原因是需要计算中属于的结点的k近邻,以构造稀疏的时间平滑的二部图。但采用kd树构造Gt中属于的结点的k近邻仅需要O(ntlnnt)时间。实验的目标数据集是papers,中的papers肯定不会出现在t时刻的中,故每次只需存储指示属性数据集authors、venues和terms指示子集即可,因此计算速度相对还是比较快的。

表1 计算速度比较Table 1 Comparison of computing speed s
4.6 准确率分析
ENetClus算法取文献[8]的最佳参数,本文算法取α=0.8,其他参数同上述实验。准确率比较如图3所示,本文算法的聚类质量要明显好于ENet-Clus算法。与ENetClus算法相比,本文算法能够比较真实地反映在t时刻及先前时间数据对象的关系。若t时刻的数据对象与先前的数据对象不存在任何关系,本文算法能够真实地反映出来。而ENetClus算法是从类的角度时间平滑,而不管前后两个时刻数据是否确实存在关系,因此比较粗糙。若前后时刻数据存在关系,ENetClus能大致反映其关系,否则ENetClus反映的是错误的关系。而且基于概率模型的ENetClus算法受应用领域限制,通用性不强。
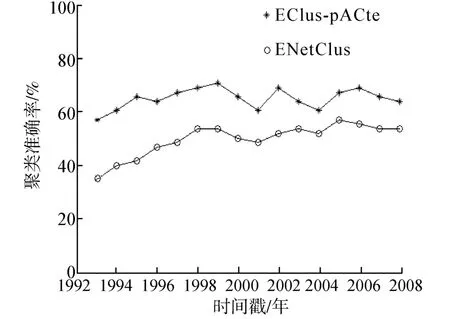
图3 演化聚类准确率比较Fig.3 Comparison of evolutionary clustering accuracy
5 结论
通过理论分析及实验验证说明:
1)本文采用时间平滑二部图充分反映了某时刻及先前时间结点间的关系,聚类质量高于以往的算法;
2)实验的运行时间说明利用稀疏性,采用线性时间求解程序加快了计算速度;
3)本文算法通用性强,适合于任何的星型模式的异构信息网络,不受异构信息网络的应用领域所限制。但本文算法参数较多,每个时间平滑二部图的关系的权重都需要人为确定,如何自动选取最佳的关系权重,还需进一步研究。
[1]SUN Yizhou,HAN Jiawei.Mining heterogeneous information networks:principles and methodologies[J].Synthesis Lectures on Data Mining and Knowledge Discovery,2012,3(2):1-159.
[2]SUN Yizhou,YU Yintao,HAN Jiawei.Rankclus:rankingbased clustering of heterogeneous information networks with star network schema[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2009:797-806.
[3]WANG R,Shi C ,PHILIP S Y,WU B.Integrating clustering and ranking on hybrid heterogeneous information network[M].Berlin Advances in Knowledge Discovery and Data Mining.2013:583-594.
[4]AGGARWAL C,XIE Y,PHILIP S Y,On dynamic link inference in heterogeneous networks[C]//SDM.2013:415-426.
[5]GAO Bin,LIU Tieyan,MA Weiying.Star-structured highorder heterogeous data co-clustering based on cosistent information theory[C]//ICDM'06.Hong Kong,China,2006:880-884.
[6]LONG Bo,ZHANG Zhongfei,WU Xiaoyun,et al.Spectral clustering for multi-type relational data[C]//Proceedings of the 23rd International Conference on Machine Learning,ACM.2006:585-592.
[7]AGGARWAL C,SUBBIAN K.Evolutionary network analysis:a survey[J].ACM Computing Surveys(CSUR),2014,47(1):10.
[8]GUPTA M,AGGARWAL C,HAN J,et al.Evolutionary clustering and analysis of bibliographic networks[C]//Advances in Social Networks Analysis and Mining(ASONAM).Kaohsiung,Taiwan,2011:63-70.
[9]KHOA N L D,CHAWLA S.Large scale spectral clustering using resistance distance and Spielman-Teng solvers[J].Discovery Science,2012:7-21.
[10]QIU H,HANCOCK E R.Clustering and embedding using commute times[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(11):1873-1890.
[11]SPIELMAN D A,SRIVASTAVA N,Graph sparsi fi cation by effective resistances[J].SIAM Journal on Computing,2011,40(6):1913-1926.
[12]SPIELMAN D A,TENG Shanghua.Nearly-linear time algorithms for preconditioning and solving symmetric,diagonally dominant linear systems[J].SIAM Journal on Matrix Analysis and Applications,2014,35(3):835-885.
[13]KOUTIS I,MILLER G L,TOLLIVER D.Combinatorial preconditioners and multilevel solvers for problems in computer vision and image processing[J].Computer Vision and Image Understanding,2011,115(12):1638-1646.
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
刑法论丛(2018年2期)2018-10-10 03:32:22
法律方法(2018年3期)2018-10-10 03:21:34
数学物理学报(2018年1期)2018-03-26 08:16:42
电信科学(2016年11期)2016-11-23 05:07:56
学习月刊(2016年4期)2016-07-11 02:54:12
湘江法律评论(2016年0期)2016-06-15 20:29:29
通信电源技术(2016年6期)2016-04-20 06:21:36
汽车零部件(2014年10期)2014-11-11 12:25:04
电子设计工程(2014年12期)2014-02-27 11:58:23
