
基于全变量信息的子空间监控方法
2015-08-20 07:31吕小条宋冰谭帅侍洪波
化工学报 2015年4期
吕小条,宋冰,谭帅,侍洪波
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
引 言
随着现代工业及科学技术的迅猛发展,系统的规模和复杂性不断增加,过程监控变得越来越重要。有效的过程监控可以保障生产安全、保证产品质 量[1]。然而,实际化工过程的监控系统得到的数据往往维度较高,变量间关系复杂,直接基于原始数据建立检测模型较为复杂。为了得到包含原始数据主要特征的低维数据,出现了多种降维方法[2]。
多元统计过程监控(multivariate statistical process monitoring,MSPM)方法通过降维,得到了包含原始数据主要特征的低维数据,然后基于低维数据建立故障检测模型,目前已在化工过程中得到了广泛的应用[3-6]。PCA 是目前研究较多的多元统计过程监控方法之一,然而,传统的PCA 过程监控方法通常会造成信息缺失。一方面,由于PCA 将原始数据投影到PCS 和RS 两个空间,主元空间仅保留了方差较大的主元,丢弃了方差较小的主元,破坏了信息的完整性;另一方面,尽管T2和SPE作为互补的监控指标,但是它们监测过程的不同方面,在过程监控中的地位是不对称的。这样,在线检测时,这种差异会进一步加剧,造成信息缺失[7-8]。信息缺失会影响过程监控性能。
为了更好地实现化工过程故障监控,近几年,许多学者从子空间角度提出了多种故障监控方法。Ge 等[9]提出了非线性过程监控的线性子空间方法(BSPCA),该方法基于PCA 分解构造线性子空间,将原始过程变量划分为k+1 个子块。文献[10]首先通过k均值聚类算法划分不同的操作模态,然后在单一模态下,用多个线性子空间近似过程变量的非线性特性,解决了具有非线性特性的多模态问题。文献[11]针对Plant-Wide 过程,利用PCA 分解将原始数据划分成k+1 个子块,然后在每个子块中建立PCA 模型进行监控,这种划分子块的方法不需要任何过程知识。文献[12]将ICA 与子空间有机结合,提出了基于独立元贡献度的子空间故障检测方法,用于处理非高斯过程。上述子空间方法的共同特点:在构造每个子空间时,均挑选了对该子空间贡献度较大的变量,因此同一变量可能出现在多个子空间中,存在变量的重叠,会导致过程信息的冗余。Zhang 等[13]利用子空间方法处理多模态及动态问题,使得模态划分更加准确,算法复杂度大大降低。该方法提取了不同模态的共同信息,构成共同子空间及每个模态下的特定子空间,在子空间中采用、SPE 作为监控指标,由于、SPE 在过程监控中地位不对称,导致信息缺失问题。Jiang 等[14]提出了基于SPCA 的故障检测和诊断方法,根据T2的变化率来挑选主元,将对故障敏感的主元划分在同一子空间中。但敏感主元只在故障发生时被挑选,还有一些主元不能被挑选,造成过程信息的缺失[15]。
为了在降维的同时更好地保存变量信息,本文提出一种基于全变量信息的子空间监控方法(FVI),用于线性过程监控。首先,PCA 分解得到两个正交且互补的空间PCS 和RS,考虑到每个变量与PCS 和RS 关联程度不同,可将关联关系相似的变量划分在同一子空间中,这样可确保不同子空间之间的差异性,以及同一子空间内部的有效性。本文采用夹角来衡量每个变量与PCS 或者RS 的关联关系。该变量与PCS(或RS)夹角越小,说明它在PCS(或RS)上的投影越大,即与 PCS(或RS)的相似性越高,反之亦然。故可依据夹角的大小,将全部变量划分为3 个子空间:①子空间Ⅰ,变量与PCS 夹角小,与PCS 相似性高;②子空间Ⅱ,变量与RS 夹角小,与RS 相似性高;③子空间Ⅲ,变量与PCS 和RS 的夹角均大,与二者相似性均低。这样,原始数据空间被划分成3 个低维的子空间,然后,在每个子空间中建立监控模型,采用马氏距离作为监控指标,并利用贝叶斯推断整合各个子空间的监控结果。FVI 方法构造的3 个子空间包含了全部过程变量,可以更充分地利用过程信息。最后,通过数值仿真及TE 过程仿真研究验证了FVI方法的有效性。
1 PCA 简介
考虑数据矩阵:X=[x1,x2,…,xn]T∈Rn×m,其中m表示变量,n表示采样数。在进行PCA 建模之前,先对数据进行标准化,将X的各列处理成单位方差且零均值的变量。定义标准化后的协方差矩 阵为

对C进行特征值分解,并按照特征值大小降序排列。则PCA 对X进行如下分解

其中,P∈Rm×k、∈Rm×(m-k)分别为PCS 和RS 的负载矩阵,T∈Rn×k、∈Rn×(m-k)分别为PCS 和RS的得分矩阵。
2 子空间的构造方法
2.1 理论依据
传统PCA 过程监控方法在降维时会造成信息缺失,严重影响过程监控性能。受分块建模策略和关键变量选择方法的启发,可以将全部过程变量划分成截然不同的多个子块,即将原始数据空间用多个子空间近似[16]。要建立合理的子空间监控模型,关键要确保子空间的差异性和有效性。差异性要求各个子空间之间的差别要大,能够更好地反映不同方面的信息,减少冗余;有效性要求单个子空间要包含足够信息,这样才能反映各个内在成分的特征和变化。
考虑到每个变量与PCS 和RS 关联程度不同,将关联关系相似的变量划分在同一子空间,这样可确保构造出的子空间具备差异性和有效性。本文采用夹角来衡量每个变量与PCS 或者RS 的关联关系。该变量与PCS(或RS)夹角越小,说明它在PCS(或RS)上的投影越大,即与 PCS(或RS)的相似性越高,反之亦然。故可依据所得的夹角来划分子空间,下节将详细介绍子空间的划分方法。
2.2 子空间的划分方法
首先,对标准化后的数据X∈Rn×m进行PCA 分解,得到PCS 和RS,然后计算变量i(i=1,2,…,m)与PCS 的夹角θiPCS

其中,Xi代表X的第i列,即第i个变量。变量i与RS 的夹角θiRS

由于Xi是一个向量,而T和均为一个矩阵,求上述夹角,即求一个向量与一个矩阵所张成的子空间之间的夹角[17-18]。
设T张成的子空间为F1,即

分别对T和Xi作QR 分解,求得标准正交基

然后对作SVD 分解

则向量Xi与矩阵T所张成的子空间F1 之间的夹 角为

其中0°≤θiPCS≤90°,由于PCS 和RS 正交互补,所以有下面等式成立

式(9)表明:同一变量与PCS 的夹角同与RS 的夹角之和为定值90°。说明某变量与PCS 夹角越小,则与RS 夹角越大,夹角的大小表征相似程度的高低,故可依据每个变量与PCS 和RS 相似性的高低来划分子空间。由于=90° -,因此统一采用θiPCS来构造子空间。定义θcut1和θcut2作为分界值,构造的3 个子空间如图1所示:①子空间Ⅰ,变量与PCS相似性高,0°≤θiPCS≤θcut1;②子空间Ⅱ,变量与RS 相似性高,θcut2≤θiPCS≤90°;③子空间Ⅲ,变量与PCS 和RS 相似性均低:θcut1≤θiPCS≤θcut2。
选取分界值θcut1和θcut2时,要确保每个子空间内部的有效性,有效性体现在同一子空间中的θiPCS相对集中,因此可采用K均值聚类算法对(i=1,2,…,m)进行聚类,得到子空间Ⅰ、Ⅱ、Ⅲ中的变量。聚类完成后,子空间Ⅰ中最大角度记为θI,max,子空间Ⅲ中最小角度记为θIII,min,最大角度记为θIII,max,子空间Ⅱ中最小角度记为θII,min,则分界值θcut1∈[θI,max,θIII,min),θcut2∈(θIII,max,θII,min]。

图1 3 个子空间构造示意Fig.1 Schematic diagram of three subspaces construction
2.3 监控结果整合
子空间构造完成后,全部过程变量被划分成3块。在每个子空间中,计算马氏距离作为监控指标

其中,s表示子空间,取1,2,3(对应子空间Ⅰ、Ⅱ、Ⅲ),Xs表示子空间s中的变量构成的矩阵,Ss表示子空间s的协方差矩阵,ms表示子空间s所包含的变量数目,满足:表示自由度为ms的控制限。
通常情况下,不同子空间的监控模型具有不同的控制限,因为子空间的自由度ms不一定相同。因此,对于新的监控样本xnew,不能从3 个子空间的监控结果直接得到最终的监控结果。本文采用贝叶斯推断策略,将3 个子空间的监控结果以概率的形式整合[19]。首先,xnew在每个子空间中发生故障的概率计算如下

式中,N和F分别代表正常和故障,P(N)和P(F)分别代表正常和故障的先验概率,P(N)和P(F)分别定义为α和1-α,其中α表示置信水平。为了得到Ps(F|xnew),还需要知道Ps(xnew|N)和Ps(xnew|F),对这两个概率定义如下

这样便得到xnew在每个子空间中发生故障的概率Ps(F|xnew)。定义最终的监控结果为 BIC(xnew),为了更好地整合结果,采用添加权重的方法将得到的3 个概率作如下整合,求得最终的监控结果

整合后的控制限: BIClim=1-α,当 BIC(xnew)超过控制限时,说明有故障发生,否则,视为正常过程。
对于变量间关联强的化工过程,θiPCS(i=1,2,…,m)的分布会相对集中一些,可能会出现某个子空间为空的情况。
3 基于FVI 方法的过程监控
基于FVI 方法的过程监控包括离线建模和在线检测两个阶段。
3.1 离线建模
(1)采集正常训练样本数据X,并对数据进行标准化;
(2)对X进行PCA 分解,得到主元空间PCS和残差空间RS;
(3)根据式(8),计算Xi与PCS 的夹角θiPCS;
(4)对θiPCS进行聚类,Xi被分成3 块,对应子空间Ⅰ、Ⅱ、Ⅲ;
(5)在每个子空间中,计算协方差矩阵Ss,根据式(10)确定子空间的控制限Ds,lim;
(6)取整合后的控制限 BIClim。
3.2 在线检测
(1)对于新的测试数据xnew,进行标准化;
(2)根据离线建模步骤(4),xnew的全部变量相应地被分成3 块,构成子空间Ⅰ、Ⅱ、Ⅲ;
(3)在每个子空间中,利用离线建模阶段得到的Ss,计算马氏距离Ds;
(4)利用贝叶斯推断策略整合3 个子空间的监控结果,得到 BIC(xnew);
(5)判断 BIC(xnew)是否超过控制限 BIClim,若超过,说明有故障发生,否则视为正常。
图2为离线建模和在线检测的流程图。
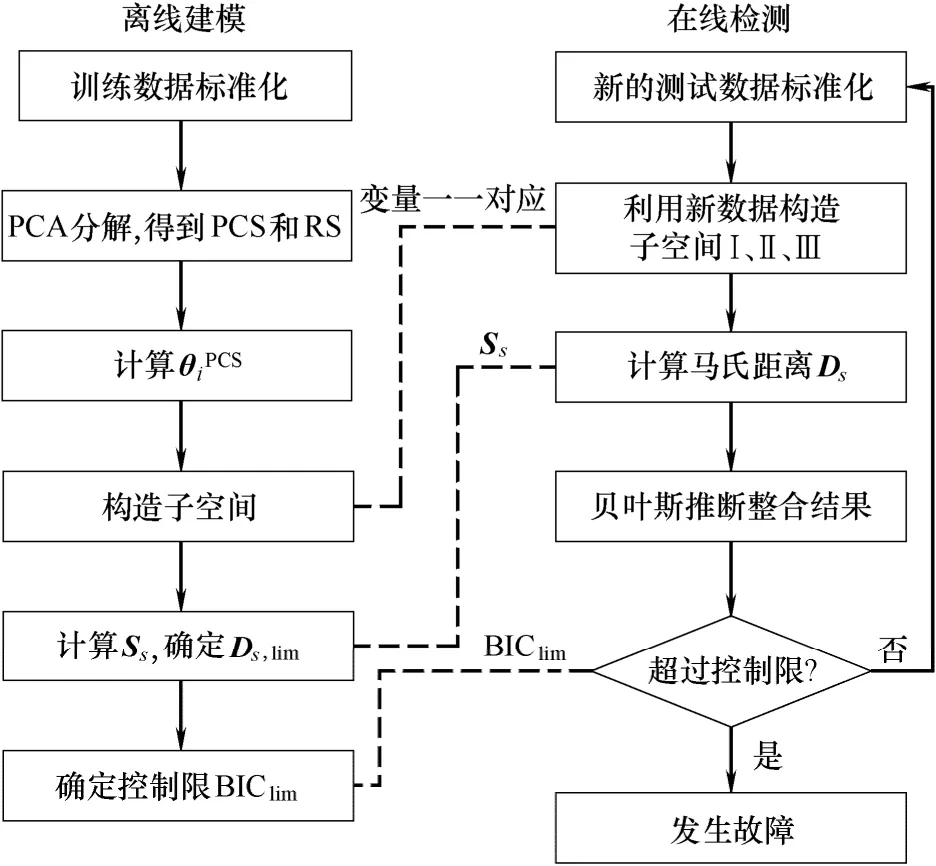
图2 FVI 方法的流程Fig.2 Flowchart of FVI method
4 仿真实例
本节对两个例子进行仿真研究,第1 个是数值例子,第2 个是Tennessee Eastman(TE)过程。将FVI(BIC)方法与PCA(T2,SPE)方法的仿真结果进行比较,证明本文方法的有效性。
4.1 数值仿真
本节参照文献[8]中的数值例子,构造出的数值模型结构如下

其中,t=[t1,t2,t3,t4,t5]T是零均值高斯分布的数据源,其标准差分别为1,0.8,0.6,0.9 和0.3。噪声noise 服从零均值,标准差为0.01 的高斯分布。首先,在正常工况下,产生800 个样本作为训练数据。然后设定两个故障:故障1,201T=时刻起给x3加一个幅值为1 的阶跃信号;故障2,T=201 时刻起给t5加一个幅值为3 的阶跃信号。两种故障工况下,分别产生800 个样本作为测试数据。在测试数据中,前200 个样本是正常样本,后600 个样本是故障样本。

表1 两种方法的误报率和漏报率Table 1 Fault alarm rate and miss alarm rate of two methods/%
PCA 方法采用方差贡献度选取主元个数,设定方差贡献度为0.85。FVI 方法的参数设置如下:PCS的维度为2。计算每个变量与PCS 的夹角,对夹角值进行K均值聚类,构造的3 个子空间变量组成如下:子空间Ⅰ:x4,x5;子空间Ⅱ:x2;子空间Ⅲ:x1,x3。统计量的置信限均为0.99。
表1给出了PCA 方法和FVI 方法对两个故障检测得到的误报率和漏报率,表中粗体表示检测结果的最优值。从表1可看出,与PCA(T2,SPE)方法相比,FVI(BIC)方法的检测效果更好。当误报率在允许范围内,对于故障1,PCA(T2,SPE)方法中T2统计量和SPE 统计量的漏报率均在90%以上,基本检测不出故障;而FVI(BIC)方法中BIC 统计量的漏报率为0,可以准确地检测出故障1。对于故障2,PCA(T2,SPE)方法中T2统计量的漏报率为13%,SPE 统计量的漏报率为85%,检测效果较差;而FVI(BIC)方法仍然可以准确地检测出故障。
为了更好地说明FVI 方法的有效性,图3给出了两种方法的统计量对数值例子中故障1 的茎叶图,图中纵坐标分别表示T2值、SPE 值和BIC 值。由图3可知,对于数值例子中故障1,故障数据与正常数据的T2和SPE 值没有明显差别,说明T2和SPE 不能有效地区别正常数据与故障数据;而故障数据的BIC值明显大于正常数据的BIC值,说明BIC能很好地识别故障。
4.2 TE 过程仿真

图3 数值例子故障1 的 T 2、SPE 和BIC 茎叶图Fig.3 T2,SPE and BIC stem plots of fault 1 in numerical example
TE 过程是基于实际工业过程的仿真实例,已经 被广泛作为连续过程的策略、监视、诊断、优化的研究平台。整个过程包含5 个主要操作单元,即反应器、冷凝器、气液分离塔、循环压缩机和汽提塔。TE 模型具有6 种操作模式,12 个操作变量和41 个测量变量,并且可以人工设定21 种故障工况[20-22]。
本文采用单模态数据作为过程数据,选取33个变量作为过程监控变量。在正常工况下,采集960个样本作为训练集;在故障工况下,每个故障采集960 个样本作为测试集,故障均在第160 个采样点加入。所取的置信限均为0.99。在21 种故障中,故障3、9 和15 难以检测且对过程影响较小,因此,本文选取剩余的18 种故障用于检测。
在PCA 方法中,首先对正常工况下的数据进行标准化,然后进行PCA 建模,采用方差贡献度选取主元个数,设定方差贡献度为0.85;在FVI 方法中,同样先对训练集进行标准化,接着进行PCA 分解,得到PCS 和RS,PCS 的维度为9,由交叉验证得到。对33 个夹角值进行K均值聚类,3 个子空间的变量组成如表2所示。表3给出了PCA 方法和FVI方法对18 种故障的平均误报率,表4给出了两种方法对18 种故障的漏报率,表中粗体表示检测结果的最优值。从表4可看出,对于18 种故障,FVI 方法对其中17 种故障均能达到最优的监控结果,仅故障13 较PCA 方法漏报率略高一些。同时可以发现,对于故障1,2,6,7,8,12,13,14,18,PCA方法和FVI 方法的漏报率都很低,这是因为上述故障幅度较大,很容易被检测出来。而对于一些较难检测的故障,如故障5,10,16,19,PCA(T2,SPE)方法的漏报率均超过了65%,而FVI(BIC)方法的漏报率均低于15%。这是因为PCA 方法在降维时丢失了一部分重要的信息,所以很难检测出这些小的扰动。而FVI 方法在降维的同时保存了完整的变量信息,因而检测能力显著提高。

表2 3 个子空间的变量组成Table 2 Variable composition of three subspaces

表3 两种方法的故障平均误报率Table 3 Average fault alarm rate of two methods/%

表4 两种方法的故障漏报率Table 4 Miss alarm rate of two methods/%
5 结 论
本文提出了一种新的基于全变量信息的子空间监控方法。基于PCA 分解,得到PCS 和RS,依据每个变量与PCS 和RS 相似性的高低来构造子空间,并在每个子空间中建立故障监控模型。相较于传统PCA 方法,本文方法保存了全部过程变量,可以更充分地利用过程信息,数值仿真和TE 过程仿真说明了该方法的有效性,过程监控的效果得到了较大的改善。然而,对于实际生产过程,有时很难得到变量在子空间发生故障的先验概率,因此本文方法在实际应用时会存在一定的局限性。
[1]Song Bing (宋冰),Ma Yuxin (马玉鑫),Fang Yongfeng (方永锋),Shi Hongbo (侍洪波).Fault detection for chemical process based on LSNPE method [J].CIESC Journal(化工学报),2014,65 (2):620-627
[2]Zhang Ni (张妮),Tian Xuemin (田学民),Cai Lianfang (蔡连芳).Non-linear process fault detection method based on RISOMAP [J].CIESC Journal(化工学报),2013,64 (6):2125-2130
[3]Kim D S,Lee I B.Process monitoring based on probabilistic PCA [J].Chemometrics and Intelligent Laboratory Systems,2003,67:109-123
[4]Wang Xun,Kruger Uwe,Lennox Barry.Recursive partial least squares algorithms for monitoring complex industrial processes [J].Control Engineering Practice,2003,11:613-632
[5]Kruger Uwe,Dimitriadis Grigorios.Diagnosis of process faults in chemical systems using a local partial least squares approach [J].American Institute of Chemical Engineers,2008,54:2581-2596
[6]Ge Zhiqiang.Improved two-level monitoring system for plant-wide processes [J].Chemometrics and Intelligent Laboratory Systems,2014,132:141-151
[7]Qin S J.Statistical process monitoring:basics and beyond [J].Journal of Chemometrics,2003,17:480-502
[8]Tong Chudong,Song Yu,Yan Xuefeng.Distributed statistical process monitoring based on four-subspace construction and Bayesian inference [J].Industrial and Engineering Chemistry Research,2013,52 (29):9897-9907
[9]Ge Zhiqiang,Zhang Muguang,Song Zhihuan.Nonlinear process monitoring based on linear subspace and Bayesian inference [J].Journal of Process Control,2010,20:676-688
[10]Ge Zhiqiang,Gao Furong,Song Zhihuan.Two-dimensional Bayesian monitoring method for nonlinear multimode processes [J].Chemical Engineering Science,2011,66:5173-5183
[11]Ge Zhiqiang,Song Zhihuan.Distributed PCA model for plant-wide process monitoring [J].Industrial and Engineering Chemistry Research,2013,52:1947-1957
[12]Zhang Muguang (张沐光),Song Zhihuan (宋执环).Subspace fault detection method based on independent component contribution [J].Control Theory and Applications(控制理论与应用),2010,27:296-302
[13]Zhang Yingwei,Chai Tianyou,Li Zhiming,Yang Chunyu.Modeling and monitoring of dynamic processes [J].IEEE Transactions onNeural Networks and Learning Systems,2012,23 (2):277-284
[14]Jiang Qingchao,Yan Xuefeng,Zhao Weixiang.Fault detection and diagnosis in chemical processes using sensitive principal component analysis [J].Industrial and Engineering Chemistry Research,2013,52 (4):1635-1644
[15]Lv Zhaomin,Jiang Qingchao,Yan Xuefeng.Batch process monitoring based on multi-subspace multi-way principal component analysis and time series Bayesian inference [J].Industrial and Engineering Chemistry Research,2014,53 (15):6457-6466
[16]Noriah M,Ian T.Variable Selection and interpretation of covariance principal components [J].Communications in Statistics -Simulation and Computation,2001,30 (2):339-354
[17]Bjorck A,Golub G.Numerical methods for computing angles between linear subspaces [J].Mathematics of Computation,1973,27:579-594
[18]Zhu P,Knyazev A V.Angles between subspaces and their tangents [J].Journal of Numerical Mathematics,2013,21 (4):325-340
[19]Bishop C M.Pattern Recognition and Machine Learning [M].Springer,2006:272-279
[20]Downs J J,Vogel E F.A plant-wide industrial process control problem [J].Computers and Chemical Engineering,1993,17 (3):245-255
[21]Ricker N L.Optimal steady-state operation of the Tennessee Eastman challenge process [J].Computers and Chemical Engineering,1995,19 (9):949-959
[22]Wang J,He Q P.Multivariate statistical process monitoring based on statistics pattern analysis [J].Industrial and Engineering Chemistry Research,2010,49 (17):7858-7869
猜你喜欢
中学生数理化·七年级数学人教版(2020年12期)2021-01-18
高中数学教与学(2020年21期)2020-11-27
初中生学习指导·提升版(2020年11期)2020-09-10
语数外学习·高中版上旬(2020年8期)2020-09-10
西南石油大学学报(自然科学版)(2018年4期)2018-08-02
文理导航(2018年2期)2018-01-22
中国质量监管(2016年10期)2016-07-10
广西电力(2016年5期)2016-07-10
中国当代医药(2015年8期)2015-03-01
卫生职业教育(2014年20期)2014-05-16
