
基于日志分析的 MySQL 数据库取证算法*
2015-08-02 03:58:43谭森,郭捷
信息安全与通信保密 2015年3期
谭 森, 郭 捷
(上海交通大学 电子信息与电气工程学院, 上海 200240)
基于日志分析的 MySQL 数据库取证算法*
谭 森, 郭 捷
(上海交通大学 电子信息与电气工程学院, 上海 200240)
MySQL 数据库的使用越来越广泛,MySQL 数据库取证的问题也变得越来越重要。日志是数据库取证最重要的信息依据,MySQL 二进制日志中记录了用户对数据库数据所有的更改操作。 本文提出分析 MySQL 二进制日志结构,使用 KMP 算法对 MySQL 二进制日志进行关键字匹配,检索出我们所需要的信息,对 MySQL 数据库进行取证的算法。 大量实验结果验证了本算法的有效性。
MySQL;二进制日志;信息检索;KMP 算法;数据库取证
0 引言
MySQL 已成为世界上最流行和最成功的开源数据库系统 ,MySQL 数据库的取证问题也变的越来越重要。Peter Fruhwirt,Markus Huber,等人曾提出 InnoDB 数据库取 证[1], 后来Peter Fruhwirt, Peter Kieseberg 等人提出通过分析 InnoDB 的redo log 更具体的取证方法[2],但是这仅仅是针对 InnoDB 的取证,如果 MySQL 数据库使用其他数据库引擎则难以取证了。每一种数据库都会有自带的工具或者功能帮助数据库取证[3],触发器也可以用来帮助数据库取证[4]。日志 是 数 据 库取证最重要的依据,MySQL 数据库的二进制日志中记录了用户对 MySQL 数据库中数据的所有更改操作。 但是 MySQL 自身携带的 mysqlbinlog 工具[5-6]的功能很少也不完备,只有将二进制日志转换成文本文件和按时间段查看二进制日志内容等十分简单的功能。通过这些功能查询出来的信息有很多对于用户而言是不必要的信息,因此该工具不能提供很多对于数据库取证有帮助的信息。如果需要关于某一个关键字的信息就只能通过用户人工的去筛选 mysqlbinlog 查询出来的信息,这样会显得十分繁琐,而且会很容易遗漏信息。
为了快速,有效的检索出 MySQL日志中我们想要的信息,对数据库进行取证。 本文提出通过分析 MySQL 二进制日志的结构,使用 KMP 算法检索关键字,然后提取关键信息从而对 MySQL数据库进行取证的方法。
1 分析 MySQL 二进制日志结构
目前对 MySQL 二进制日志结构的分析几乎没有,如果要了解 MySQL 二进制日志的结构,我们就只能通过分析 MySQL 的源码。 通过阅读 MySQL 的部分源码分析出了 MySQL 二进制的结构,下面进行详细叙述。
1.1 二进制日志的总体结构
每个二进制文件的的开始都是 4 个字节:fe 62 69 6e,该四个字节成为“ 魔数”;其中后面三个字节 就是 bin 的 ascii 码。 然后接下来的就是一条一条的日志记录,如图 1,所示它的的内容由三个部分组成:Common-Header,Post-Header( 不 是每条记 录都有),Body。 Common-Header部分不同版本的大小不一样,4.0 以上的都是 19 个字节。 在这个之后就是 Body,也就是记录的内容。

图1 日志记录的结构(数字表示字段的字节数)
Post-Header只有在 query 类型的记录中才有,如果是其它的记录类型则没有 Post-Header。 记录的类型在 Common-Header中的一个字节标注出来。
1.2 Common-Header结构
Common-Header结构一共有 19 个字节,如图 2 所示,包括 6个部分,分别为:Timestamp,Type,Server-id,Total-size,End-logpos,Flag。

图2 Common-Header的结构
Timestamp:该字段代表该条记录写入的时间,用4个字节表示;
Type:该字段代表记录的类型,比如 QUERY,LOAD-EVENT,FORMAT-DESCRIPTION-EVENT 等类型,其中每个二进制文件的第一条记录的类型都是 FORMAT-DESCRIPTION-EVENT 类型,它记录了该日志文件的相关信息,这些信息对于后序分析日志记录是有用的。 而对于后续的记录,我们主要是对日志的删除更改操作进行查找,固我们只对 QUERY 类型的记录进行解析,QUERY 类型的日志记录主要是记录用户平时的删除更改操作,如:insert,drop,delete, update 等。 Query 的类型值为 2,在记录中为00000010。 该字段用 1 个字节表示;
Server-id:创建这个日志记录的服务器 ID,防止循环主从导致的主机被重写,该字段用4个字节表示;
Total-size:该条日志记录的大小,该字段用 4 个字节表示;
End-log-pos:该条日志记录结束的位置(相对于日志文件的开头位置偏移字节数的数目),也就是该条日志记录最后一个字节的下一个字节的位置,该字段用4个字节表示;
Flag:标志位,该字段用 2 个字节表示。
1.3 Post-Header结构
QUERY 类型的记录除了开始的 Common-Header 之外,在Body 的开头是一个 Post-Header结构,然后之后才是真正的 body内容。 或者可以说 Post-Header就是 Body 的一部分,因为主要是对 QUERY 类型的记录进行解析,这里单独拿 出来分析。 Post-Header结构一共有 13 个字节,如图 3 所示,包括 5 个部分,分别为:Thread-id,Exec-time,Db-len,Error-code,Status-var-len。

图3 Post-Header的结构
Thread-id:表示线程 ID,用来区分用户的临时表,用 4 个字节表示;
Exec-time:表示记录所记录的信息在数据库中执行的时间,用4个字节表示;
Db-len:表示该记录所记录的信息所在的数据库的名字的长度,用1个字节表示;
Error-code:执行出错的错误码,用 2 个字节表示;Status-var-len:Status-var字段的长度,该字段在 Body 结构中,用 2 个字节表示。
1.4 Body 结构
Body结构是日志记录中的实质内容,如图4所示,包括 Status-var,Db,Query 三个部分。 Body 结构中记录了用户对数据库的操作,该结构的长度不是定长的,该结构的长度由前面介绍的结构中的字段决定。

图4 Body的结构
Status-var:表示 Status-var-len 个状态。 一个状态由一个字节表示。 该字段用 Status-var-len(其值大于等于零)个字节表示;
Db:表示用户操作的数据库的名字,用 Db-len+1 个字节表示,是一个以 null字符结尾的字符串;Query:表示一个查询语句,是可变长度的字符串没有尾随 0,延伸至记录结尾(该部分的长度可以通过 Common-Header中的字段计算确定) ,在 MySQL5.0.4版本之后该部分会有4个字节用作校验。
1.5 验证MySQL日志记录结构
为了验证MySQL二进制日志结构分析的正确性,使用二进制文件查看器选取一条记录进行分析,如图 5 所示,小图(a)(b)(c)分别为日志记录(QUERY 类型)中的 Common-Header,Post-Header,Body的三部分,在 MySQL 二进制日志中的编码模式是小端模式。

图5 MySQL 二进制日志记录
1)a段一共19个字 节,E4 F3 2F 53 表示时间,因为二进制是用小尾数表示的所以上面四个字节表示0x532FF3E4=1395651556(十进制),转换成时间就是2014/3/2416:59:16。02表示类型,就是QUERY类型,01 00 00 00 表示server-id,0x00000001=1, 77 00 00 00 表示 total-size,就是 0x00000077= 119;3E 01 00 00 表示记录结束的地方,就是离文件起始位置有0x0000013E=318个字节;00 00 是标识位。
2)b段一共13个字节,17 00 00 00 表示 thread-id, 大小为23;00 00 00 00 表示 exec-time,大小为零;04 表示数据库名字的长度,大小为 4;00 00 表示 error-code,大小为 0,表示无错;21 00表示 status-var-len 的长度大小为 33;
3) c 段一共 87 个字节,这个值可以有 total-size 减去 Common-Header和 Post-Header的长度得出,119-19-23=87,该结果与记录中实际的长度是一样的;00 00 00 00 00 01 00 00 20 50 00 00 00 00 06 03 73 74 64 04 08 00 08 00 21 00 0C 01 74 65 73 74 00这里一共 33 个字节,表示状态的值;74 65 73 74 00 这里一共 5个字节表示,表示数据库的名字,根据 ascii码的转换可以得出该数据库的名字为 test;75 70 64 61 74 65 20 74 73 65 74 20 73 65 74 20 6E 61 6D 65 3D 27 79 61 6C 69 63 65 73 68 69 27 20 77 68 65 72 65 20 69 64 20 3D 20 31 这里 45 个字节,该段二进制内容根据ascii码转换后可以得出字符串为:update tset set name= 'yaliceshi'where id=1,该字符串为 SQL 的命令语句,最后的四个字节 3A CC 18 EC 是校验码,判断整条记录是否正确。
最后用mysqlbinlog[7]将该条记录转换成文本文件,通过比对显示前文对 MySQL 二进制日志的结构分析是正确的。
2 MySQL数据库取证算法
在MySQ二进制日志文件中根据关键字提取关键信息,主要是两步:第一步是否可以匹配到关键字;第二步是在匹配到关键字的情况下提取该记录中相关的信息,进行MySQL数据库取证。
2.1 KMP算法
KMP算法是一种线性时间字符串匹配算法,该算法是是由Knuth、Morris和Pratt三个人共同提出来的[8]。其实KMP算法与BF算法(Brute Force,普通的的模式匹配算法 )的区别就在于KMP算法巧妙的消除了指针i(指在目标串中标记正在匹配的字符的位置)的回溯问题,只需确定下次匹配j的位置即可,使得问题的复杂度由O(mn)下降到O(m+n)。
在KMP算法中,为了确定在匹配不成功时,下次匹配时j的位置,引入了next数组,next[j]的值表示P[0,j-1](P表示需要匹配的字符串)中最长后缀的长度等于相同字符序列的前缀。对于next数组的定义如下:
1)next[j] =-1;j=0
2)next[j] =max(k);0<k<j,P[0,k-1] =P[j-k,j-1]
3)next[j] =0;其他
下面使用一个字符串 ababa 进行说明,由字符串推出next数组,如表1。
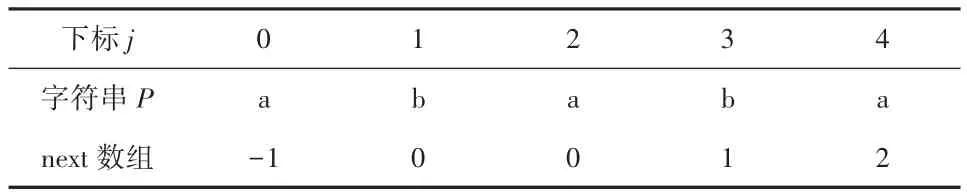
表 1 字符串P与next数组对应表
即 next[j] =k>0 时,表示 P[0…k-1] =P[j-k,j-1]
因此 KMP 算法的思想就是:在匹配过程称,若发生不匹配的情况,如果 next[j] > =0,则目标串的指针 i不变,将模式串的指针j移动到 next[j] 的位置继续进行匹配;若 next[j] =-1, 则 将 i 右移 1 位,并将 j置 0,继续进行比较。
2.2 MySQL 数据库取证算法
首先我们要判断提取信息的文件是不是 MySQL 二进制日志文件,然后进行关键字匹配,然后提取信息,最后输出结果进行取证,流程图如图 6。
1)判断是否是二进制日志文件是不是 MySQL 二进制日志文件是则执行第 2步,否则执行第 8步;
2)读取一条日志记录的 Common-Header部分,也就是流程图中的记录的头部;
3)根据记录的头部判断是否是 QUERY 类型,如果是则执行第4步,否则执行第 7步;
4)根据 Common-Header和 Post-Header的信息定位 Body 部分中的内容实质,在 QUERY 类型中就是 SQL 语句;
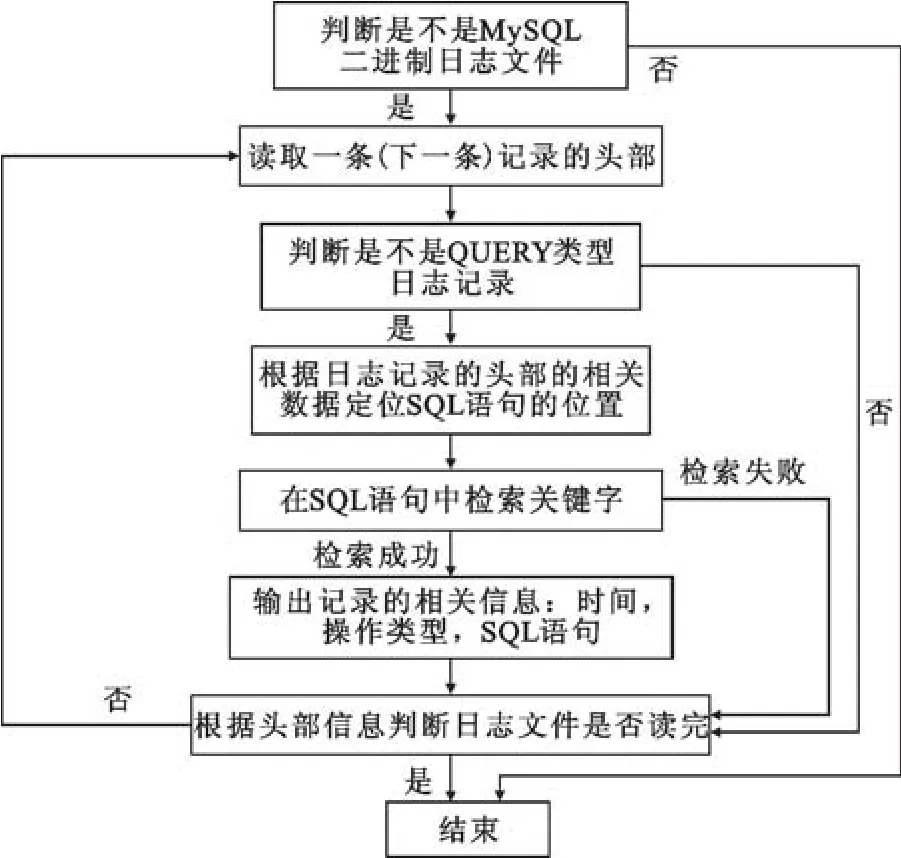
图6 MySQL 数据库取证算法流程图
5)在 SQL 语句中使用 KMP 算法匹配关键字匹配成功则执行第六步;否则执行第7步;
6)输出记录的相关信息:时间、操作类型、SQL 语句;
7)判断文件是否读完,是则执行第 8 步,否则执行第 2 步;
8)结束。
3 实验结果
通过使用上文所述的基于日志分析的 MySQL 数据库取证算法,对 MySQL 数据库进行了取证。 实验使用 VS2010、MySQL 5.6等开发 软 件 在 windows7 系 统 (64bit) , 内 存 8GB, Intel(R) Core (TM) i7-4800MQ CPU@2.70GHz 的环境下对该方法进行了实现,实验结果如图 7。
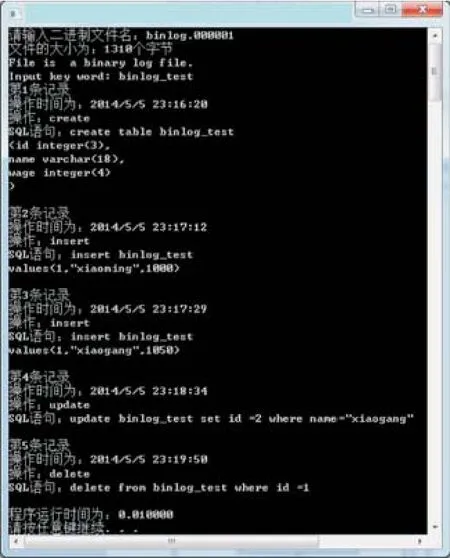
图7 实验结果
从图 7 中可以看出在名为 binlog.000001 的 MySQL 二进制日志文件中;检索出了关于 binlog-test的相关信息,如 insert、create、update、delete 操作。 也可以从实验结果中看出我们的分析的二进制日志记录结构和对数据库取证的算法是正确的。

表 2 不同数量级 MySQL 数据库取证对比表
后续对多个有不同数量级数据的 MySQL 数据库进行了取证实验,得到了表2的对比数据。 这3个数据库中分别有1 000、10 000、100 000条记录,从这些数据库中取证相同的信息。 可以从表中看出该算法对多个不同量级的数据库取证时的正确率都是100%,而且时间上的增长和数据数量的增长基本一致,表 2 的数据验证了本文提出的算法可以对 MySQL 数据库进行有效的取证。
4 结语
本文通过分析 MySQL 二进制日志结构,使用 KMP 算法进行关键字匹配提取出与关键字相关的重要信息,能有效的对MySQL 数据库进行取证;但是目前分析的二进制日志文件都是需要明确的路径的,还不能自动的寻找计算机中的 MySQL 二进制日志文件。 如何自动寻找计算机中所有的 MySQL 二进制日志文件,高效检索多个二进制日志文件中的有效信息从而更全面的对 MySQL 数据库进行取证将是下一步的研究重点。
[1]Peter Fruhwirt,Markus Huber,Martin Mulazzani, etc.InnoDB Database Forensics[C] //Proceedings of the 2010 24th IEEE International Conference on Advanced Information Networking and Applications,Washington DC USA:IEEE Computer Society,2010:1028-1036.
[2]Peter Fruhwirt,Peter Kieseberg,Sebastian Schritwieser,etc.InnoDB Database Forensics: Enhanced reconstruction data manipulation queries from redo logs[J] .Information Security Technical Report: 2013,17(4) :227-238.
[3]Mario A.M.Guimaraes,Richard Austin,Huwida Said etc.Database forensics[C ] //2010 Information Security Curriculum Development Conference.New York USA: Association for Computing Machinery(ACM) , 2010:62-65.
[4]Werner K.,Haugerl,Martin S.The role of triggers in database forensics[C ] //Information Security for South Africa(ISSA )Conference.Washington DC USA:Institute of Electrical and E-lectronics Engineers(IEEE),2014: 1-7.
[5]祝定泽,张海,黄建昌.MySQL 核心内幕[M].清华大学出版社,2010.
[6]Stefan Hinz, Jonathan Stephens, Philip Olson, etc.Overview of MySQL Programs[DB/OL] .2009-11-1[2014-10-13] . http: //dev.mysql.com/doc/refman/5.6/en/programs-overview.html.
[7]Stefan Hinz, Jonathan Stephens, Philip Olson, etc.mysqlbinlog[DB/OL].2009-11-1[2014-10-13 ] .http: //dev. mysql.com/doc/refman/5.6/en/mysqlbinlog.html.
[8]Thomas H.Cormen, Charles E.Leiserson, Clifford Stein, etc.算法导论[M].潘金贵,顾铁成,李成法,等译.机械工业出版社,2006.
MySQL Database Forensics Algorithm based on Log Analysis
TAN Sen, GUO Jie
(School of Electronic Information and Electrical Engineering, SJTU,Shanghai 200240, China)
With its wide use, MySQL database forensics issue becomes increasingly important.Log is the most essential information proof of database forensics, and MySQL binary log records all the data changing operations of database made by users.An analysis of MySQL binary log structure is proposed, and KMP algorithm is used to make keyword matching of MySQL binary log and retrieve the required information, then the forensics algorithm is conducted on MySQL database.Experimental results indicate the effectiveness of this forensics algorithm.
MySQL;binary log;information retrieval;KMP algorithm;database forensics
TP 309.2
A
1009-8054(2015)03-0081-04
谭 森(1990—),男,硕士,硕士研究生,主要研究方向为数据库安全;
2014-11-25
司法部司法鉴定科学技术研究所科研院所公益研究专项(No.GY2013G-3)
郭 捷(1976—),女,博士,副研究员,主要研究方向为数据库安全和流媒体安全。■
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
中等数学(2021年8期)2021-11-22 07:53:38
销售与市场(营销版)(2021年10期)2021-11-21 20:15:03
数学大王·低年级(2019年10期)2019-11-25 08:23:26
中等数学(2019年4期)2019-08-30 03:51:44
销售与市场(营销版)(2019年6期)2019-06-21 01:16:38
网络安全技术与应用(2017年9期)2017-09-20 09:54:28
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
图书馆建设(2014年3期)2014-02-12 15:41:35
