
基于权重规则的图书馆电子文档图像处理研究
2015-07-31 23:34宋路露
微型电脑应用 2015年5期
宋路露
基于权重规则的图书馆电子文档图像处理研究
宋路露
数字图书馆的电子文档图像处理作为一个多学科交叉的研究热点,文档图像识别涉及到了众多邻域,包括人工智能、计算机视觉、图像处理和模式识别等,主要研究了基于智能处理的文档图像识别算法,提出了一种结合权重规则的文档图像识别算法,通过计算文档区域均值像素方差和熵,并由文档分类器获取权值的方法对文档识别有着重要的作用。实验研究证明了方法的有效性。
文档图像处理;模糊系统;图像识别
0 引言
随着图书馆资源管理的信息化和网络化发展,文档图像资料成为图书馆信息资源的重要内容。人们开始利用计算机来进行图书馆电子文档图像资源的处理和管理。直到80年代,对图书馆的文档图像处理主要集中在文档图像检测、文档图像分割、文档辨识算法和单一形式的文档识别[1-7]。
进入21世纪,基于视觉的文档图像识别取得了重大进展,同时对文档图像识别进行了初步探索。Swain 等人[8]将计算机视觉引入视觉处理系统,使得在动态环境中能够进行文档信息识别。该视觉算法表明了多颜色对象的颜色直方图可以作为大模型文档数据库中鲁棒、有效、稳定的目标特征,在文档图像存在模糊、不同拍摄角度的情况下,可以实现多个文档的有效识别。Itti等人提出基于显著度的视觉注意模型实现快速文档分析[9]。该文档模型主要受早期原始人类视觉系统的行为和神经结构启发而进行设计,先将多尺度文档图像特征合并到一个单一拓扑显著图中,再利用动态神经网络得到其位置达到降低显著度的目的。该算法通过快速选择环节使复杂文档理解问题的计算有效性得到突破。Murase 等人[10]提出将文档模型用于3-D目标的视觉学习和识别。每个目标的文档模型在二维图像空间中取决于其形状、反射特性、场景中姿态和光照条件。形状和反射特性对应于对象内在特征,一般条件下是不变的。姿态和光照条件则对应于不同场景,常常是变化的。最后,通过流形中投影得到的精确位置得到文档图像中目标特征。实验结果表明,对复杂文档特征的目标该算法可得到较好的辨识结果。
综上所述,文档图像处理的研究经历了从特征提取及检测、图像分割的单一形式的目标识别,到多类形式的文档识别,以及最后的文档理解等阶段[11-16]。随着信息技术的发展,结合实际的应用需求,最终期望达到的目标是:在不确定信息存在的条件下(文档图像光照的变化,不同噪声对文档图像的污染,文档图像角度的变化等),能够从文档图像中获取有用的信息,设计有效的文档图像处理算法,在保障较高的检测率和正确率前提下,对文档图像进行识别和全局理解。实现该目标的关键技术主要有:文档图像预处理、文档特征提取、文档图像分类、文档图像分割和检测、建立有效的文档图像理解等。
1 文档图像的特征处理和计算
信息熵可以说是系统有序化程度的一个度量,对数字图像而言它可以解释为图像信号颜色分布的随机性度量,因此可以作为图像之间相似度的判据。所以我们需要给不同的区域赋予不同的权值。
1.1 文档图像的编码
经过对输入图像进行预处理后,首先我们必须对图像进行LBP编码,编码后将图像分成m个不同的区域Mj(j=0,1,…,m-1),从每个区域提取直方图Ri,j,Ri,j的提取可以由下面公式获得公式(1):

其中f(x,y)为编码后的图像,i表示第i个灰度级,n为直方图灰度级数,即灰度范围,一般取256。Ri,j表示在区域J具有第i级灰度值得像素数目。函数T{a}如下列公式所示如公式(2):
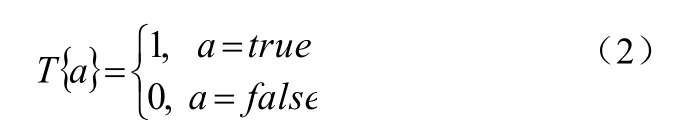
1.2 文档图像的信息熵
信息熵可以由H(X)来表示,X代表图像,当一幅图像的所有像素均为同一个值时,H(X)=0;当一幅图像拥有颜色空间的所有颜色,并且各种颜色出现的概率相等是H(X)值最大,可以用来描述二维图像的不确定性,熵值越大表明子块信息量越多,易于识别,赋以的权值越大。由上述所给知识,求取每个分块区域各个像素点的概率,可以用频数对其进行估计,如公式(3):
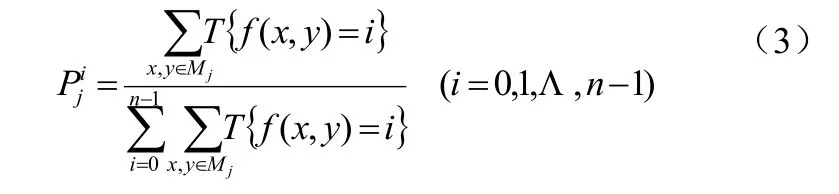
其中 T(a)函数参照公式(3),i表示像素点的灰度值。获得的,可知第j个区域的熵值定义为公式(4):
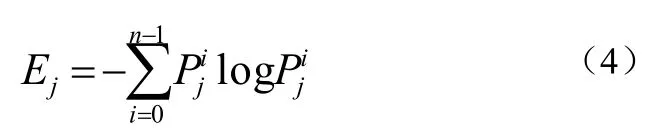
从信息熵的描述可知,熵可以描述文档图像信息,因此,可以将各区域的熵值看做区域信息量大小,信息越丰富,则熵值越大,则该区域对文档识别具有更大作用,应该赋予更大的权值,各分块权值如公式(5):

1.3 文档图像的像素方差
均值像素方差可以表现文档图像的区分度高低,比如纯色的文档图片,其像素方差显然为0,因此像额头等其像素方差必定小,因此可以赋予较小的权重,像素方差越大,表明文档图像区分度高,因此必须强调其重要性,给以较大的权重。文档子图区域 j 均值像素方差2jσ可由公式获得公式(6):
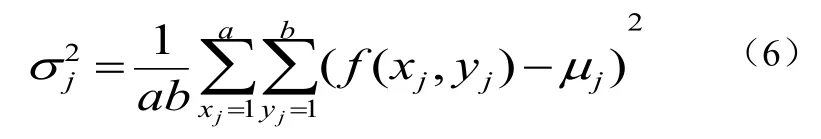
其中f(xj,yj)为经过LBP编码分块后子区域 j 部分的文档图像表示,a表示子图 j 像素宽度,b表示文档子图 j 像素高度,μj表示文档子图 j 部分的均值像素,如公式(7):
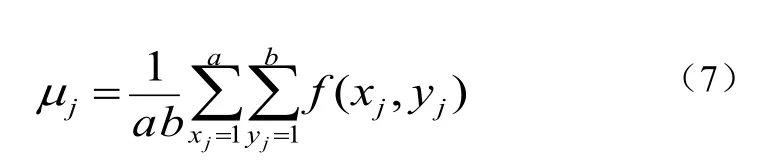
从均值文档像素方差的描述可知,它可以描述文档图像像素是否平缓变化,若变化平缓,甚至只有一个取值,则说明其对识别贡献不大,应赋以较小的权值,反之,则赋以较大权值。
2 文档图像的识别处理框架
文档图像输入包括文档图像预处理,预处理主要是对文档图像进行噪声滤波、归一化等,通过这一步得到的文档图像用于进行特征提取;特征抽取及选择部分是识别中很重要的一部分,本文中特征提取采用的方法是专家规则与LBP结合的方式,通过对主要特征进行加权来强调其识别的重要性以提高识别性能,首先,是对文档图像进行LBP运算,并对运算后的文档图像进行分块,选取何种分块大小最佳可以通过实验对比可知,然后,通过计算文档图像的信息熵和均值像素方差并设计模糊控制器求得的相应文档子块权值并赋以到与其相对应的区域,最后,串接成一个文档特征向量。文档分类器的作用主要是将获得的文档特征与文档数据所拥有的特征进行比对,文档分类器选择的是文档卡方统计,其结构描绘如图1所示:
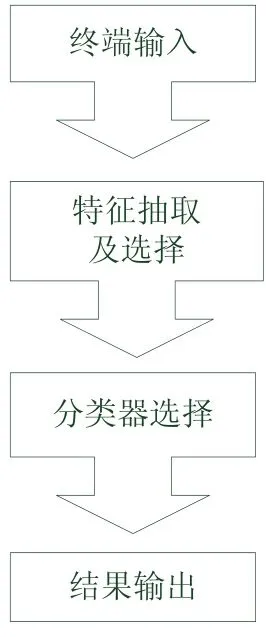
图1 文档图像识别系统结构描述图
算法流程图有一个分块编号问题,将结果LBP编码后的文档图像进行分块,若分成m块,则子块序号可以从i=1到i=m,然后可以在区间[1,m]之间进行循环判断,直到i=m+1为止;当计算出所有权值时,就可以将这些权值赋值到相应区域并将它们串接成一个向量,这个向量就可以作为识别的特征向量来应用;最后,通过同数据库的文档特征向量进行比对,通过分类器输出文档。
3 文档图像识别实验分析
在文档图像数据库上进行有效性验证。利用图像数据库中建立训练模型的训练和测试过程。识别结果的客观评价采用的是多次识别实验的平均值(PSNR和SNR)。
为了比较多种噪声的处理结果,本章采用了3种不同的噪声类型用于图像处理:1)高斯噪声(方差波动范围:0.02-0.06);2)椒盐噪声(密度波动范围:2%-20%);3)混合噪声:高斯噪声(方差波动范围:0.01-0.05)和椒盐噪声(密度波动范围:2%-10%)混合。
在高斯噪声、椒盐噪声和混合噪声情况下,几种处理算法的处理效果,如表1、表2和表3所示:

表1 高斯噪声去噪结果的比较
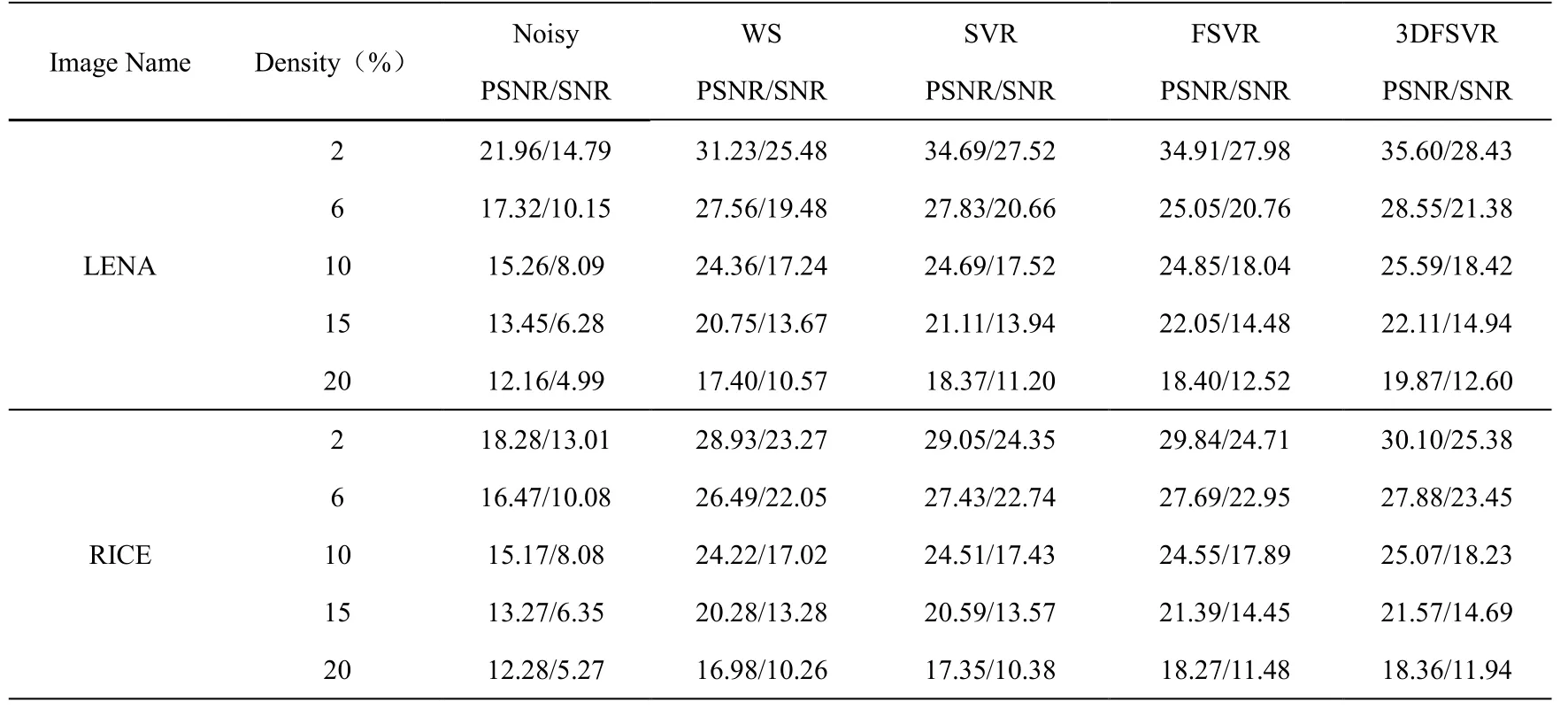
表2 椒盐噪声去噪结果的比较
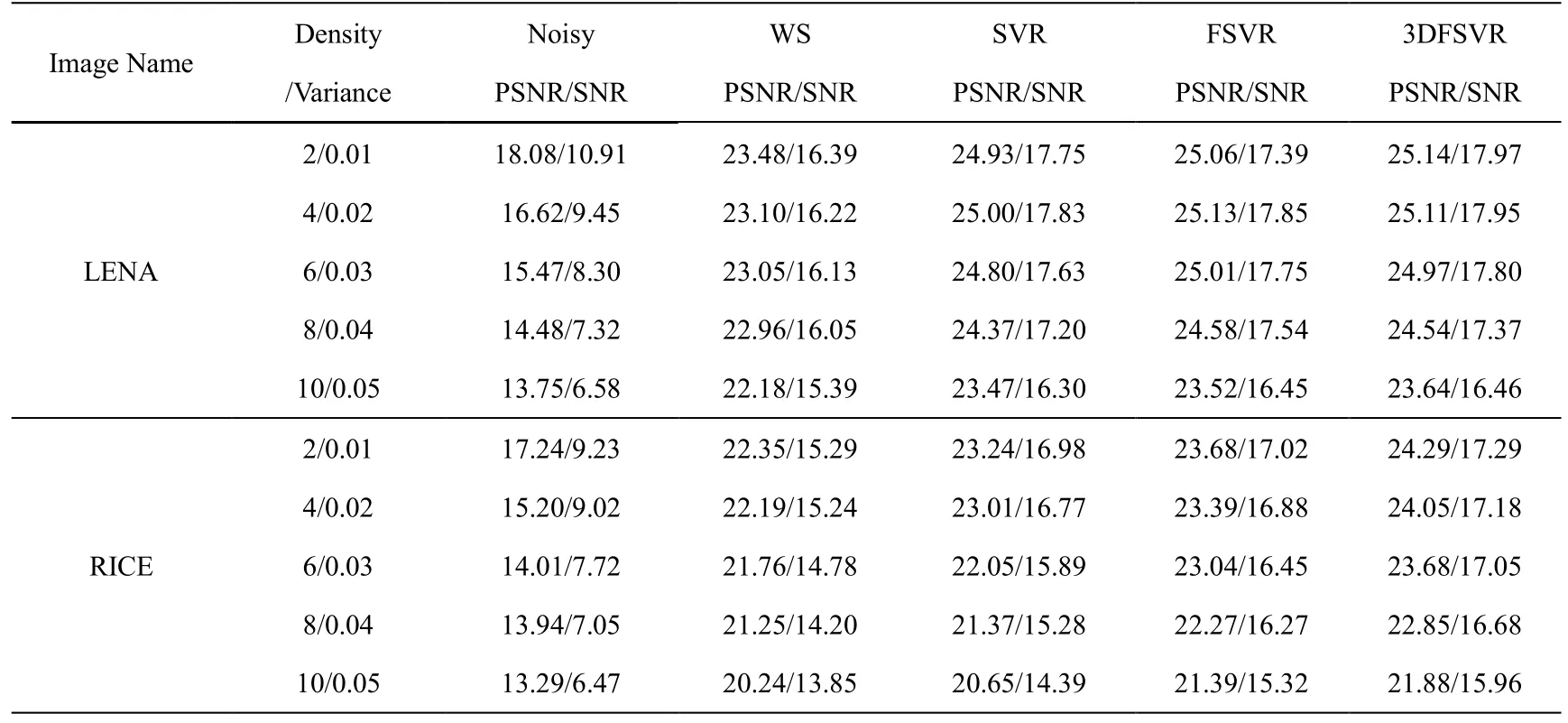
表3 混合噪声去噪结果的比较
从中可以看出,模糊算法的去噪效果比其它的几种去噪算法要好,其根本原因在于在3DFSVR系统结构中嵌入了模糊域用于处理不确定信息比较合适。
为了验证基于模糊规则的文档图像识别算法性能,在文档图像库上进行了实验对比,同时选择3种不同的参数进行多次试验对比,如表4所示:
通过实验验证证明了模糊处理的文档识别算法具有较好的识别率。
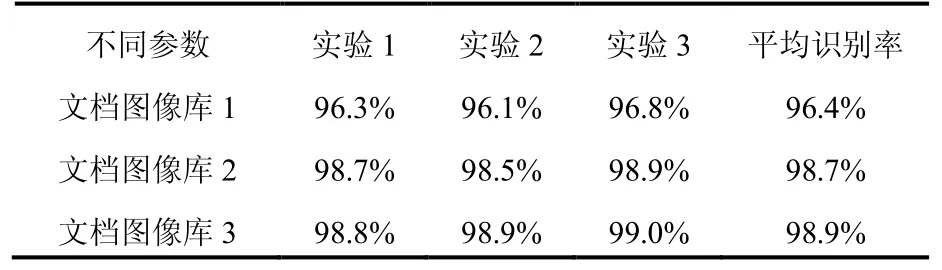
表4 文档图像库上的识别率
4 总结
本文研究了基于模糊处理技术的图书馆电子文档图像管理方法,提出了一种基于模糊规则的文档分类识别算法,首先,对文档图像进行LBP编码,然后,划分文档图像,得到各区域的文档直方图特征向量,分别计算分块区域的均值像素方差和熵值,把这两个值作为模糊控制器的输入获取相应分块区域的权值并赋以之,最后,将待识别样本的加权特征向量与文档数据库中的特征向量进行类比。实验表明,基于模糊规则的文档处理算法能有效的提高去噪率。
[1]Miura K., Kanehiro F., Kaneko K., Kajita S., Yokoi K.. Slip-Turn for Biped Robots [J]. IEEE Trans. on Robotics, 2013, 29(4): 875-887.
[2]Saab L., Ramos O.E., Keith F., Mansard N., Soueres P., Fourquet J.. Dynamic Whole-Body Motion Generation Under Rigid Contacts and Other Unilateral Constraints [J]. IEEE Trans. on Robotics, 2013, 29(2):346-362.
[3]Hong S., Oh Y., Kim D., You B.J.. Real-Time Walking Pattern Generation Method for Humanoid Robots by Combining Feedback and Feedforward Controller [J]. IEEE Trans. on Industrial Electronics, 2014, 61(1): 355-364.
[4]Sunkil Park, Ahra Lee, Myoung-Jun Jeong, et al. A disposable MEMS-based micro-biopsy catheter for the minimally invasive tissue sampling [J]. IEEE/RSJ International Conference on Intelligent Robots and Systems, 2005. (IROS 2005). pp: 2768-2773.
[5]Chen S.Y.. Kalman Filter for Robot Vision: A Survey[J]. IEEE Trans. onIndustrial Electronics, 2012, 59(11):4409-4420.
[6]Yongchun Fang, Xi Liu, Xuebo Zhang. Adaptive Active Visual Servoing of Nonholonomic Mobile Robots [J]. IEEE Trans. on Industrial Electronics, 2012, 59(1):486-497.
[7]Vapnik. V. N. The nature of statistical learning theory.[C]New York: Springer-Verlag, 1995.
[8]哈明虎,王超,张植明,等.不确定统计学习理论[M]. 北京:科学出版社,2010.
[9]Elattar E. E., Goulermas J. Electric load forecasting based on locally weighted support vector regression[J].IEEE Trans on. Systems, Man, and Cybernetics: Part C, 2010,40(4):438-447.
[10]Andreas B., Jamie A.W., Hans G., and Gerhard T. Eye movement analysis for activity recognition using electrooculography [J].IEEE Trans. on Pattern Analysis and Machine Intelligence, 2011, 33(4):741-753.
[11]Pasolli L., Notarnicola C. Prediction of axial DNBR distribution in a hot fuel rod using support vector regression models[J]. IEEE Trans.on Nuclear Science, 2011, 58(4):2084-2090.
[12]Tselios K., Zois E.N., Siores E., Nassiopoulos A., Economou G.. Grid-based feature distributions for off-line signature verificaiton [J]. IET Biometrics,2012, 1(1):72-81.
[13]Kumawat, P., Khatri, A., Nagaria, B.. Offline handwriting recognition using invariant moments and curve let transform with combined SVM-HMM classifier[J]. International Conference on Communication Systems and Network Technologies(CSNT), 2013, 144-148.
[14]Deng Cai, Xiaofei He. Manifold adaptive experimental design for text categorization[J]. IEEE Trans. on Knowledge and Data Engineering, 2012, 24(4):707-719.
[15]Li Dan, Liu Lihua, Zhang Zhaoxin. Research of text categorization on WEKA [J]. The Third International Conference on Intelligent System Design and Engineering Applications (ISDEA), 2013, 1129-1131.
[16]L. Fabien and B.Gerard. Switched and Piecewise Nonlinear Hybrid System Identification[J]. Hybrid Systems: Computation and Control, 2008, 4981:330-343.
Image Processing of Library Electronic Document Based on Weight Rule
Song Lulu
(Library of Guangdong University of Technology, Guangzhou 510006,China)
The image processing of digital library electronic document is regarded as an interdisciplinary research focus. The identification of document image involves many fields, including artificial intelligence, computer vision, image processing and pattern recognition. This paper mainly studies the identification algorithm based on intelligent document image processing, proposing a weight-rule-combining algorithm of document image identification. It obtains weight through the document classifier by calculating the document area mean pixel variance and entropy. This method plays an important role in document recognition. The experimental study demonstrates the effectiveness of the method.
Document Image Processing; Fuzzy System; Image Recognition
TN929.5
A
2015.01.27)
1007-757X(2015)05-0017-04
宋路露(1982-),女,广东工业大学,图书馆助理馆员,大学本科,研究方向:图书馆信息化,数字图书馆,广州,510006
猜你喜欢
房地产导刊(2022年4期)2022-04-19
山东农业工程学院学报(2020年12期)2020-03-19
电子制作(2019年16期)2019-09-27
电子制作(2019年15期)2019-08-27
中国交通信息化(2019年4期)2019-07-13
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年19期)2018-11-14
电子制作(2018年18期)2018-11-14
电子制作(2018年14期)2018-08-21
湖州师范学院学报(2016年2期)2016-08-21
