
一种两层结构集成的协同分类算法
2015-07-31 23:34:21刘宁
微型电脑应用 2015年5期
刘宁
一种两层结构集成的协同分类算法
刘宁
为了提高数据分类性能,提出一种双层分类器集成的协同分类算法CCTL。算法由训练算法和测试算法两部分组成。算法采用双层结构集成,使用多条件进行决策判断。第一层中采用三分类器协同投票一致策略实现对未知样本进行分类,第二层中采用基于正确分类率的分类器加权投票决策实现数据分类,提高分类率高的分类器的权值,减小分类率低的分类器的权值。最后,使用UCI数据集进行实验,结果表明CCTL较好地提高了分类率。
协同学习;分类;集成学习;机器学习;UCI数据集
0 引言
随着计算机技术特别是互联网技术的发展,人们获取信息的能力和渠道得到了极大的拓宽,各行各业都积累了大量的数据。根据Netcraft Web Server Survey在2012年8月的统计结果,全球Web站点已经超过628,170,204个,而且每天还有数以万计的新站点不断涌现。同时,各个站点都拥有大量的数据。海量的数据给人类咨询带来极大的便利,然而,信息的组织、查找与分析给数据处理和分析人员带了极大的挑战。如何快速、准确、方便地从海量的信息库中获取感兴趣、满足需要的信息,一直是人们关心的重要课题。在各种复杂的应用环境下,仅仅通过人工方式对庞大的数据进行分析和处理并不现实[1-3]。
数据挖掘是从海量数据中通过算法搜索隐藏在其中的、有用的知识的过程,是数据库技术自然演化的结果。数据挖掘已广泛应用于金融、医疗和保险等各个行业,并展现出了其强大的知识发现能力。在数据挖掘的研究与应用中,分类算法是一种有监督的学习算法,通过对已知类别训练集的分析,从中发现分类规则,训练并构建一个学习模型,以此实现对未知的新数据的类别的预测[4-5]。
经典分类方法主要包括:决策树、贝叶斯、人工神经网络、K近邻、支持向量机和基于关联规则的分类等[6-8]。这些单一的经典分类算法都在不同的领域取得了成功,具有较好的分类效果。比如决策树分类算法用于医疗诊断、金融分析等广阔领域; 支持向量机分类算法应用于模式识别、语音识别和回归分析等领域; 神经网络广泛应用在字符识别、分子生物学、语音识别和人脸识别等领域。但每种分类算法都存在优缺点,加上数据的多样性以及实际问题的复杂性,使到目前为止,没有哪一种分类算法优于其他分类算法[9]。
集成分类方法是一种被广泛采用的分类方法,通过学习多个分类器,将这些分类器进行组合集成,提高分类性能。它基于这样一个思想:对于一个复杂任务来讲,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断要好。Wang[10]等从理论上证明了集成分类器要优于单个分类器。在集成分类器方法中,基于权重的集成分类器被普遍认为是具有较高分类精度的方法。文献[11]和[12]将集成分类应用到不平衡数据分类领域,实现对信息不均衡数据进行分类,取得了较好的分类效果。文献[13]和[14]将集成分类应用到半监督学习领域,实现对不充分信息数据的分类,也取得了较好的实验效果。文献[15]将集成学习应用到网络数据分类中,有效地提高分类性能。
本文借鉴协同学习思想,提出一种两层结构集成的协同分类算法CCTL(Collaborative classification algorithm based two layers structure integration),通过双层条件判断,使用多个分类器集成、协同投票的方法,挖掘待分类样本的类别信息,实现对数据样本进行分类,降低分类误差,提高正确分类率。最后,通过 UCI数据集进行实验,验证算法的有效性。
1 两层分类器集成的数据分类算法
1.1 训练算法
两层分类器集成的数据分类算法CCTL结构如图1所示:
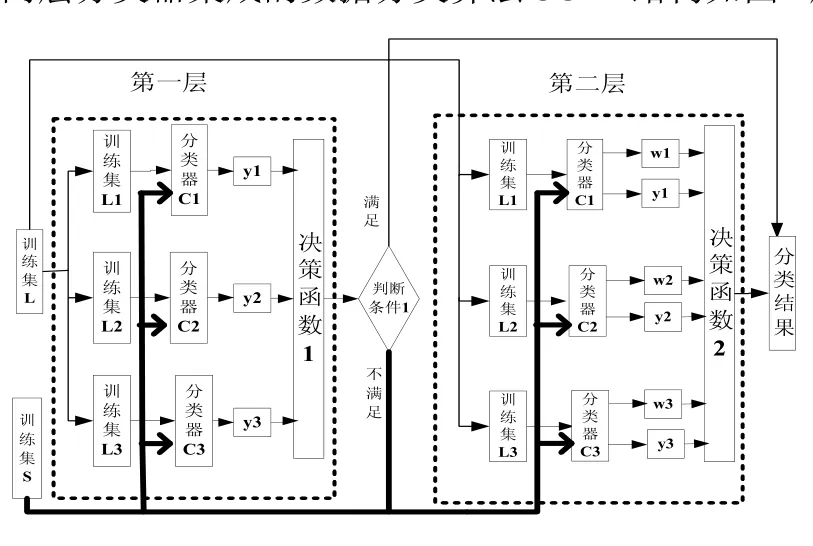
图1 CCTL的结构
训练集包括训练集L和训练集S,训练集L用于训练分类器,训练集S用于确定每个分类器的分类正确率,计算单个分类器的权值。采用随机抽样方法对 L进行自助抽样,产生3个差异性较大的子集L1,L2和L3作为训练集,分别训练生成3个分类器C1、C2和C3。
第一层结构中,使用单分类器C1、C2和C3对训练集S中的样本sample进行预测,假设样本sample对应的预测标记分别为y1、y2和y3,3个分类器采用决策函数1进行投票决策。决策函数1采用3个分类预测一致的方法进行类别决策,即如果3个分类器预测结果一致,将该类别作为样本sample的分类预测类别。接着,使用判断条件1对分类结果进行判断,对于满足判断条件1的分类类别,将其作为sample的最终类别。判断条件1表示决策函数1的预测类别和样本sample的实际标记类别值一致(sample的实际类别已知)。对于不满足判断条件1的样本sample进入第二层结构。
第二层结构中,采用基于各分类器分类正确率加权投票的方法对样本进行分类, 即加大分类正确率高的分类器的权值,使其在表决中起较大作用,减小分类正确率低的分类器的权值,使其在表决中起较小作用。使用分类器C1、C2和C3对训练集S中的样本sample类别进行预测,分别比较预测值和实际值(S中样本的实际类别值已知),得到一个预测正确率,计算各个分类器对应的权值w1、w2和w3,权值计算公式如式(1)所示。使用决策函数 2,通过三个分类器的线性组合,计算基于正确率的加权值,实现对样本sample类别的最终类别决策。其中决策函数2的计算方法如公式(3)所示,公式(3)中的 f(x)由公式(2)计算得到如公式(1):
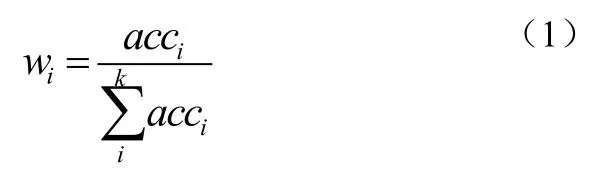
式中,acci表示第i个分类器的正确分类率, wi为第i个分类器对应的权值如公式(2):
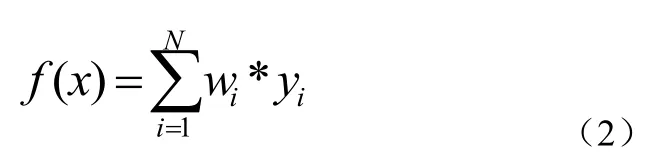
式中,wi为第i个分类器对应的权值,yi为第i个分类器的预测类别,f(x)表示集成分类器的预测值的线性组合,i=1,…N取值为3如公式(3):
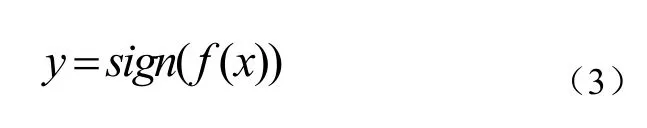
式中,f(x)表示集成分类器的预测值的线性组合,y为集成分类器的预测类别。
算法反复迭代,直到训练集 L为空。最后,使用训练生成的分类器CCTL实现对测试集样本的分类。具体算法如表1所示:

表1 训练算法
1.2 测试算法
测试算法主要使用表1中生成的分类器CCTL,对测试集中测试样本的类别进行预测,通过比较预测类别和实际类别样本,并计算正确分类率。具体操作如表2所示:

表2 测试算法
其中,正确分类率的计算公式如公式(4)所示,通过表2算法对测试集的样本特征值进行预测,将预测类别标记与测试集的样本真实类别标记进行比较,统计预测正确的分类样本数目,计算分类算法的正确分类率如公式(4):

1.3 算法分析
本算法中,采用二层结构的主要目的是提高分类器的正确分类率和分类效率。
与单分类器算法相比,本算法CCTL通过多个分类器协同实现数据的分类,能有效提高正确分类率。第一,单分类器只是通过一个分类器实现对数据的分类,CCTL算法第一层中当3个分类器投票一致时,才使用一致的投票实现对分类类别进行决策,明显提高了算法的正确分类率;第二,CCTL算法第二层中,通过3个分类器进行加权投票,增加分类率高的分类器的决策权,有利于减小分类误差,提高分类器的正确分类率。所以,CCTL分类性能优于单分类器。
与集成分类器算法相比,本算法CCTL能提高效率。当3个分类器对样本的预测一致时,算法不需要进入第二层。
2 实验和结果分析
实验平台选用PC,其配置信息如下:AMD FX(tm)-4300 Quad-Core Processor 3.82GHz CPU、3.12GB内存。软件环境为:安装Windows XP 操作系统、安装MATLAB R2009b 编程环境。基分类器分别选用SVM和RBF进行两次实验,统计实验结果,其中 SVM 采用台湾大学林智仁等人开发的libsvm-mat-2.89-3。
实验采用UCI数据(http://archive.ics.uci.edu/ml/)中常用的4个数据集,如表3所示:
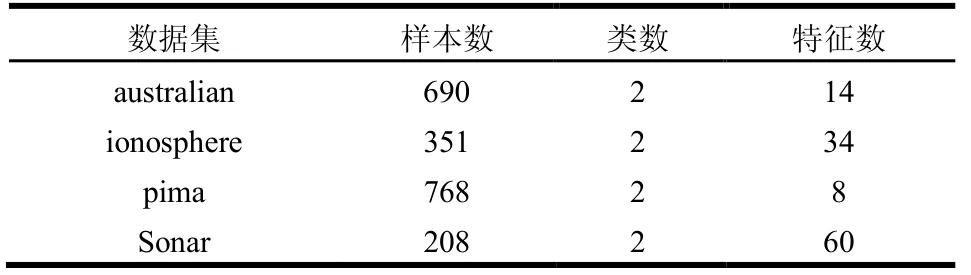
表3 实验数据集
对于表3所选取的样本,将训练集和测试集的样本数目比例设为1:2。训练集分为两部分即训练集L和训练集S,其中L和S的数目比例为设2:1。训练集中的样本都是有标记样本数据,使用这些有标记样本训练生成分类器,使用新生成的分类器CCTL在测试集上进行分类测试,统计正确分类率。其中,在这里,为了方便统计分类结果,测试集中的样本也是有标记样本,作为计算分类器的正确分类率时使用。根据选用的基分类器不同,实验分为两种情况进行,实验结果如表4和表5所示。表4表示第一种实验,即使用SVM作为基分类器时,SVM和CCTL在测试集中的正确分类率。其中,SVM列表示使用训练集训练SVM后,在测试集中的正确分类率,CCTL列表示使用训练集训练CCTL后,在测试集上的正确分类率。如表4所示:
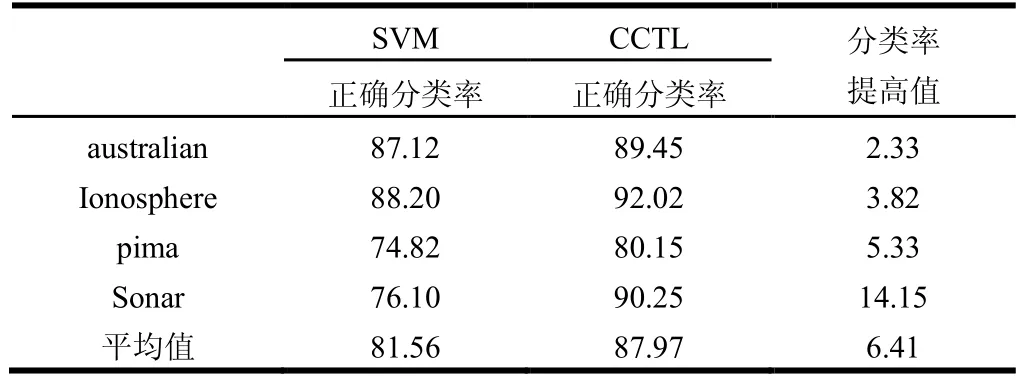
表4 分类率提高值 %
从表4可以看出,CCTL分类算法能较好提高正确分类率,比仅仅使用单分类器SVM进行训练测试,正确分类率提高了6.41%。
第二种实验如表5所示:

表5 分类率提高值 %
使用RBF作为基分类器时,RBF和CCTL在测试集上正确分类器。其中,RBF列表示使用训练集训练RBF后,在测试集中的正确分类率,CCTL列表示使用训练集训练CCTL后,在测试集上的正确分类率。从表5可以看出,CCTL分类算法能较好提高正确分类率,比仅仅使用单分类器RBF进行训练测试,正确分类率提高了4.83%。从实验结果可以看出,文中提出了集成分类器算法CCTL操作简单,具有较好的分类性能,能较好地提高测试数据的正确分类率。
通过多次实验表明,该算法收敛于多分类器集成的分类算法的分类结果。由于该算法采用两层结构,若3个分类器预测一致时,只执行第一层结构,不需要进入第二层结构;若3个分类器预测不一致时,才进入第二层结构。所以,该算法与单分类器算法相比,提高了分类率;与集成分类算法相比,提高了分类效率。
3 总结
本文借鉴协同学习思想,提出一种两层结构、多分类器集成的协同分类算法,通过双层条件判断,分类器协同投票的方法,实现对数据样本进行分类。实验表明,算法操作简单,较容易实现数据样本的分类,性能良好。可以将其应用到样本分类、病例分类、入侵检测、故障检测等各种分类问题领域,有着广阔的应用前景。
[1]Vapnik V. The nature of statistical learning theory[M]. springer, 2000.
[2]张晨光,张燕.半监督学习[M].北京:中国农业科学技术出版社,2013.
[3]薛贞霞.支持向量机及半监督学习中若干问题的研究[D].西安:西安电子科技大学, 2009.
[4]李玲俐.数据挖掘中分类算法综述[J].重庆师范大学学报(自然科学版).2011,28(4):44-47.
[5]刘大有,陈慧灵,齐红,等.时空数据挖掘研究进展[J].计算机研究与发展, 2013, 50(2): 225-239.
[6]宋全有,王雪瑞,龚志恒.基于共有 GP-LV M 和改进型SVM的数据分类算法[J].计算机工程与设计,2014,35(7): 2412-2414.
[7]李兵,董俊,刘鹏远,等.模糊格构造型形态神经网络[J].电子学报, 2014, 42(2): 319-327.
[8]冯建,邱菀华.一种基于信息熵的金融数据神经网络分类方法[J].控制与决策,2012,27(2):211-215.
[9]李勇,刘战东,张海军.不平衡数据的集成分类算法综述[J].计算机应用研究.2014,31(5):1287-1291.
[10]H Wang,et al.Mining concept-drifting data streams using ensemble classifiers[A]. Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].New York: ACM Press,2003.226-235.
[11]欧阳震诤,罗建书,胡东敏,等.一种不平衡数据流集成分类模型[J].电子学报. 2010,1:185-190.
[12]于重重,商利利,谭励,等.半监督学习在不平衡样本集分类中的应用研究[J].计算机应用研究, 2013,30(4):1085-1089.
[13]赵建华,李伟华.一种协同半监督分类算法 Co-S3OM[J].计算机应用研究,2013,30(11):3237-3239.
[14]于重重,商利利,谭励,等.一种增强差异性的半监督协同分类算法[J].电子学报,2013,41(1):35-41.
[15]陆悠,李伟,罗军舟,等.一种基于选择性协同学习的网络用户异常行为检测方法[J].计算机学报, 2014, 37(1):28-40.
A Collaborative Classification Algorithm Based Two Layers Structure Integration
Liu Ning
(School of economics and management, Shangluo University, Shangluo 726000, China)
In order to improve the performance of data classifier, a kind of collaborative classification algorithm CCTL based on two layers structure integration was proposed. The algorithm was composed of training algorithm and test algorithm. CCTL adopted an integration of double layer structure, using multi condition to make a judgment. In the first layer, collaborative voting strategy using three classifiers was to realize the classification of unknown samples. In the second layer, the weighted voting decision strategy based on correct classification rate was used to realize the data classification. The purpose was to improve the weights of classification with higher classification rate and to reduce the weight of classification with lower rate. Finally, experiment was carried out by the UCI data set. The results showed that CCTL could improve the classification rate.
Collaborative Learning; Classification; Ensemble Learning; Machine Learning; UCI Dataset
TP181
A
2014.12.29)
1007-757X(2015)05-0033-03
商洛学院科研项目资助(项目编号:14SKY006)
刘 宁(1981-),女,陕西商洛,商洛学院,经济与管理学院,讲师,硕士,研究方向:机器学习,商洛,726000
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
汽车观察(2019年2期)2019-03-15 06:00:50
电子测试(2018年1期)2018-04-18 11:52:35
中国卫生(2016年5期)2016-11-12 13:25:26
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
生物进化(2014年2期)2014-04-16 04:36:26
电测与仪表(2014年15期)2014-04-04 12:05:20
