
BIM中碰撞检测的可扩展性算法设计
2015-07-31 23:34:19胡伟松赵倩纯吴百锋
微型电脑应用 2015年5期
胡伟松,赵倩纯,吴百锋
BIM中碰撞检测的可扩展性算法设计
胡伟松,赵倩纯,吴百锋
建筑信息模型(BIM)是建筑业信息化的一个热点,碰撞检测作为BIM所提供的一个核心功能,其计算复杂度一直受研究界和工业界的关注。随着建筑数据的规模日益扩大,碰撞检测的计算规模也持续增加,由于传统算法在结构上对计算资源的利用不具备可扩展性,难以通过增加处理器核数来持续获得性能的提升,这个问题成为限制BIM进一步发展的一个障碍。为此,提出一种新型算法,该算法以一种全新的大规模数据并行的方式实现碰撞检测,由此与现代众核处理器体系结构有着更好的匹配,其性能能够随着处理器核数的增加而成线性提升,达到理想的可扩展性。实验结果验证了算法的可扩展性和有效性。
建筑信息模型;碰撞检测;大规模数据并行;众核处理器;可扩展性
0 引言
建筑信息模型(BIM,Building Information Modeling)是以三维数字建模为基础,集成了建筑工程项目中所涉及到的各种相关信息的工程数据模型[1]。BIM对于实现全过程工程信息管理乃至建筑生命期管理,提高建筑行业规划、设计、施工、维护管理各阶段的科学技术水平,促进建筑业全面信息化和现代化,具有重要的应用价值和广阔的应用前景。我国目前正在进行着大规模的基本建设,工程项目规模日益扩大,给建筑企业带来了巨大的技术和管理风险。但是,传统的技术手段都无法适应现代化建设的需要,应用BIM技术,为项目全过程提供精细化管理,消除各种可能导致工期拖延和造价浪费的设计隐患,已成为建筑行业的迫切需求。
BIM 提供的具体功能包括如下几个方面:三维协同设计,工程量计算,碰撞检测,施工进度模拟。其中碰撞检测作为BIM中典型的计算密集型应用,随着BIM系统中的数据规模不断扩大,碰撞检测的计算规模呈爆炸式增长,这为BIM系统带来了沉重的计算负担,成为限制BIM应用和推广的一大障碍。
碰撞检测是指提前查找和报告在工程项目中不同部分之间的冲突,通常碰撞问题出现最多的是安装工程中各专业设备管线之间的碰撞、管线与建筑结构部分的碰撞以及建筑结构本身的碰撞[2]。传统项目建设过程中,项目参建各方经常需要耗费巨资来弥补由碰撞问题而引起的拆装、返工及浪费。通过BIM的碰撞检测功能可以完全避免这种浪费,在管线综合设计时,将碰撞信息反馈给设计人员及时做出调整,这样可以大大降低工程成本。
传统的经典碰撞检测算法有 I-COLLIDE、RAPID、QuickCD和SWIFT++,它们都是串行检测算法,只能利用单个处理器核的计算能力,不具备可扩展性。当计算规模增加时,这些算法的性能成几何倍数下降,无法适应BIM持续增长的计算能力要求。近年来,单核处理器芯片在集成度和主频上遇到了瓶颈,促使众核架构成为处理器发展的新方向[3]。众核架构是指在处理器芯片上集成大量的计算核心,NVIDIA公司推出的面向通用计算的GPU和Intel公司推出的基于MIC架构的Xeon Phi都是众核架构的处理器。使用众核处理器对计算密集型应用进行大规模并行处理成为了高性能计算领域的发展趋势,众核架构保证了计算和数据处理能力能随着技术的发展持续提高,然而如何充分利用计算资源,使这种硬件计算能力转变成应用性能的提升,是众核时代面临的重要挑战。文献[4]提出了基于流的实时碰撞检测算法,文献[5]提出了流包围盒碰撞检测算法,文献[6]提出了基于GPU的流碰撞检测算法。这些算法虽然通过使用众核处理器GPU取得了一定程度的加速效果,但它们都是基于流计算模式,而不是大规模数据并行模式,造成数据流之间具有较为复杂的依赖关系,算法整体并行度不高,无法充分利用众核计算资源,同样不具备可扩展性。
在本文中,我们提出了一种新型碰撞检测算法。该算法基于大规模数据并行的思想,对碰撞检测过程进行了重新的算法设计,将碰撞检测转化成了完全的数据并行过程,不但充分利用了众核计算资源,更重要的是使得碰撞检测成为一个完全的可扩展性计算过程,可以通过计算资源的增加而持续获得性能提升,适应了BIM不断增长的计算能力要求。
1 问题描述
给定一个工程项目,项目中所有需要进行碰撞检测的各专业设备管线和建筑结构部分都叫做构件。假设一个项目中的构件数量为n,根据项目规模的不同,目前n的数量级从102到 104不等。用 Ci(1≤i≤n)表示构件 i,则Г={C1,C2,C3,…,Cn}为项目中所有构件的集合。
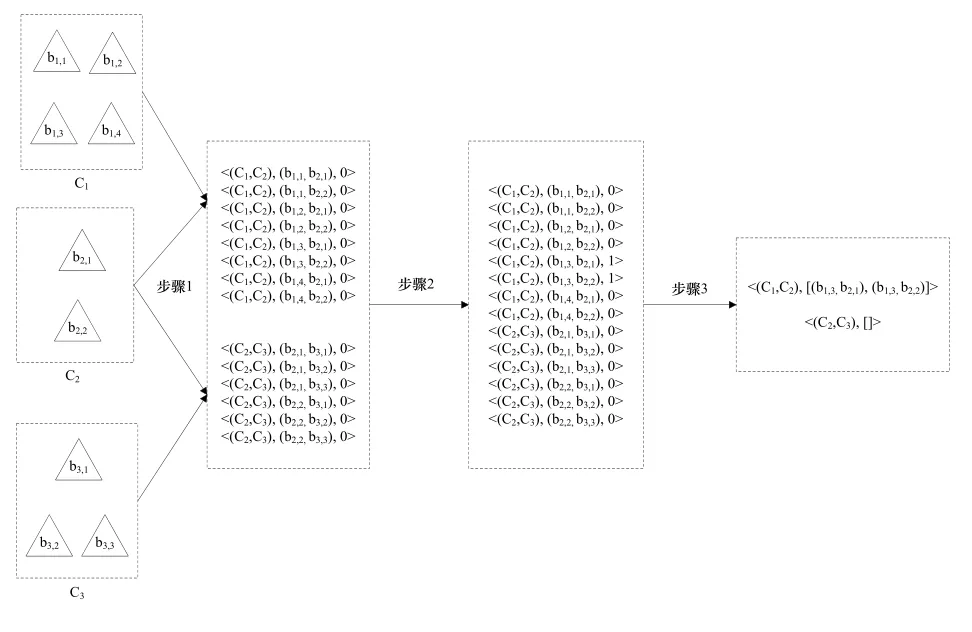
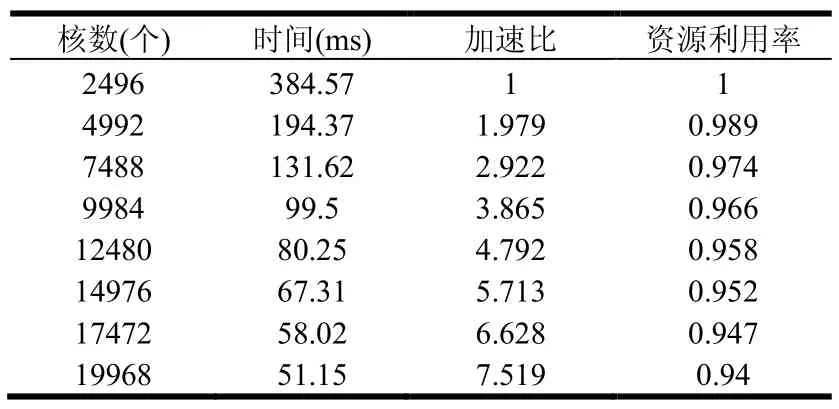
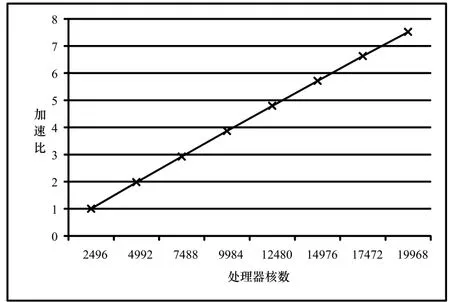
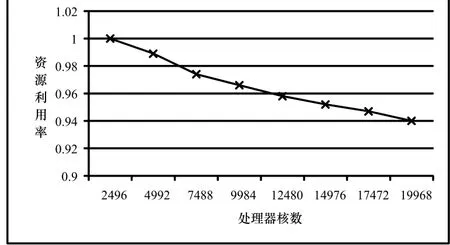
碰撞检测的目标是检测一个项目中哪些构件之间是发生碰撞的,并确定发生碰撞的具体位置。这就需要对这 n个构件两两进行碰撞检测,用Tij(1≤i 每个构件都是由基本几何元素集合组成的,本文采用最常见的三角形作为基本几何元素。用Bi表示Ci的基本几何元素集合,则Bi={bi,1, bi,2, bi,3,…,bi,|Bi|},bi,j(1≤j≤|Bi|)表示组成Ci的第j个三角形,|Bi|表示Bi中的元素个数,即组成Ci的三角形个数,数量级通常是104。对两个构件进行碰撞检测就是将组成两个构件的三角形两两相交测试的过程,当至少有一对三角形相交时,则两个构件发生碰撞,否则两个构件没有发生碰撞。用h表示一对三角形相交测试的平均计算量,则有公式(2): 将公式(2)带入公式(1)得到公式(3): 由式(2)可以看出对两个构件进行碰撞检测的计算量是比较大的,由式(3)可以看出,F(Γ)的复杂度达到O(n2)。理论分析表明BIM中的碰撞检测确实是一个计算密集型问题,并且计算量会随着构件数量的扩大而迅速增长。 为了便于对算法进行性能评估,引入以下定义: 用α表示整个众核架构系统单位时间内完成的计算量,用t表示对整个项目进行碰撞检测所用的时间,则有公式(4): α代表了众核架构系统的实际计算能力。 用β表示处理器核数,用γ表示每个处理器核的平均实际计算能力,则有公式(5): 用η表示每个处理器核的平均利用率,用λ表示一个处理器核的理论计算能力,则有公式(6): 由公式(4)、公式(5)、公式(6)得到公式(7): η代表了资源利用率。 一个项目中的构件数量是巨大的,而有很多构件对是相隔较远而明显没有发生碰撞的,因此,非常有必要快速排除掉这部分构件对,找出潜在相交的构件对,然后再对潜在相交构件对进行精确的相交测试。 基于此,将整个算法分为两个阶段:初步筛选和精确求交。初步筛选阶段的任务是对所有构件两两组成的构件对进行粗略的相交测试,得到潜在相交构件对集合;精确求交阶段的任务是对潜在相交构件对进行精确的相交测试,得到最终的碰撞检测结果。 我们将一个并行处理过程的操作对象叫做并行单元,各个并行单元之间是完全独立的,对并行单元的处理过程不存在核间同步和通信的开销,可以通过完全并行的方式充分利用众核计算资源。根据算法在两个阶段的计算特点,分别对其进行了完全的数据并行化处理,并根据并行单元的不同,将两个阶段进一步划分成了几个子步骤。下面分阶段对算法进行详细的描述。 2.1 初步筛选阶段 由于构件通常是由成千上万的基本几何元素组成的,如果直接对两个构件进行碰撞检测,其计算量是比较大的,这一点可以从公式(2)看出,特别是当两个构件相距较远时,这种计算量是完全可以避免的。所以,在对两个构件进行精确求交测试之前,首先,对其进行粗略求交测试,排除掉那些肯定不会发生碰撞的构件对。 包围盒技术是一种应用非常广泛的粗略求交测试技术[7]。包围盒技术是指利用体积略大而形状规则的包围盒把不规则的构件包裹起来,在进行碰撞检测时首先进行包围盒之间的相交测试,如果包围盒相交,则两个构件可能发生了碰撞,需要进一步检测;如果包围盒不相交,则可判断两个构件一定没有发生碰撞。 包围盒受到简单性和紧密性两个方面的约束,常见的包围盒类型包括球体、轴对齐包围盒(Axis-Aligned Bounding Box: AABB)、方向包围盒(Oriented Bounding Box: OBB)、离散方向多面体(Discrete Orientation Polytopes: k-DOP)等等。初步筛选阶段的目的是快速排除明显未碰撞构件对,因此,我们采用构造方便、相交测试简单的AABB。一个构件的AABB被定义为包含该构件,且边平行于坐标轴的最小六面体。描述一个AABB只需要6个标量,即组成构件的基本几何元素的顶点的3个坐标的最大值和最小值。对两个AABB进行相交测试时,只需要判断两个包围盒在3个坐标轴上的投影是否均发生重叠,若是则两个 AABB相交,否则不相交。 以3个构件C1、C2、C3为例(为了便于说明,这里对模型进行了简化处理,一个工程项目中通常会包含成百上千的构件),初步筛选阶段的处理流程,可以分为如下两个步骤如图1所示: 图1 初步筛选阶段的处理流程 步骤1. 分别为每个构件构造AABB包围盒。由于为各个构件构造包围盒的操作之间是相互独立的,因此,该步骤以构件作为并行单元。 步骤2. 对每两个包围盒组成的包围盒对进行相交测试。如果包围盒对不相交,则可判断包围盒对对应的构件对没有发生碰撞;如果包围盒对相交,则将包围盒对对应的构件对加入潜在相交构件对集合。由于各个包围盒对之间的相交测试是相互独立的,因此,该步骤以包围盒对作为并行单元。 2.2 精确求交阶段 精确求交阶段是指对潜在相交的构件对进行精确求交,精确求交采用基于三角形集合的相交测试算法。精确求交阶段的处理流程如图2所示: 图2 精确求交阶段的处理流程 假设由初步筛选阶段得到两个潜在相交构件对:(C1,C2)和(C2,C3),并且|B1|=4,|B2|=2,|B3|=3(为了便于说明,这里对模型进行了简化处理,真实环境中一个构件通常都是由成千上万个基本几何元素组成的)。精确求交阶段的处理流程可以分为如下3个步骤: 步骤1. 分别对每个潜在相交构件对执行如下操作:将表示两个构件的所有三角形两两组成三角形对,为每个三角形对构造一个三元组,三元组的首元素为该三角形对所属的构件对的标识,中间元素是该三角形对的标识,末尾元素为整数。末尾元素用来表示该三角形对是否相交,0表示不相交,1表示相交。由于对各个潜在相交构件对的操作之间是相互独立的,因此该步骤以潜在相交构件对作为并行单元。 步骤2. 对由步骤1生成的所有三角形对进行相交测试,并将测试结果写入三元组的末尾元素。目前三角形相交测试方法有多种,我们采用效率较高的矢量判别法[8],矢量判别法是通过三角形各顶点构成的行列式正负几何意义来判断三角形的点、线、面之间的相对位置关系,从而判断两三角形是否相交。由于各个三角形对之间的相交测试是完全独立的,因此该步骤以三角形对作为并行单元。 步骤3. 对首元素相同的三元组进行结果汇总,生成一个二元组,二元组的第一个元素仍为构件对的标识,第二个元素是一个集合,包含了所有属于该构件对且相交的三角形对,如果集合为空,表示该构件对没有发生碰撞。由于各个构件对的结果汇总操作之间是相互独立的,因此该步骤以构件对作为并行单元。 这样的两阶段多步骤算法设计将碰撞检测的处理过程转化成了完全的数据并行过程,在两个阶段的各个子步骤中,完全消除了各个并行单元之间的数据依赖关系,对各个并行单元的操作被分配到不同的处理器核上并行执行,大大降低了核间的同步和通信开销,充分利用了众核计算资源。 采用GPU集群作为众核架构的实验环境,并使用MPI加CUDA的混合编程框架对算法进行了实现[9]。MPI是一种标准化可移植的消息传递系统,主要用于基于分布式内存的并行计算机或集群系统,可以将逻辑进程分配到相应的物理节点运行,进程间通过发送和接收消息进行通信。CUDA是针对面向通用计算的GPU的并行计算编程框架,通过将海量线程自动调度到相应的处理器核执行,实现了对众核处理器资源的有效利用。 3.1 实验环境 整个GPU集群包括4个节点,均为DELL PowerEdge R720服务器,每台服务器配有两个Intel Xeon E5-2603四核CPU,16G内存和两个NVIDIA Tesla K20m GPU,每个GPU含有2496个处理器核,集群通过带宽为10Gbps的InfiniBand互联。所有节点均运行64位CentOS 6.4操作系统,MPI选择支持多种体系结构的 MPICH2,版本为 1.2.1p1,CUDA Toolkit版本为5.5,用于开发的GCC版本为4.4.7。 3.2 实验结果与分析 为了对算法的可扩展性进行验证,我们对同一个工程项目分别采用不同数目的处理器核进行碰撞检测,记录下各次的碰撞检测时间,并以使用1个GPU(2496个处理器核)的情况作为基准,计算出其它情况的加速比和资源利用率,其中资源利用率是根据公式(7)计算得到的,实验结果如表1所示: 表1 不同处理器核数情况下的检测时间、加速比和资源利用率 如图3所示: 图3 随着处理器核数增加的加速比 由图3可以看出,加速比是随着处理器核数的增加而近似线性增长的,这证明该算法的性能能够随着处理器核数的增加而成线性提升,具有良好的可扩展性。 如图4所示: 图4 随着处理器核数增加的资源利用率 由图4可以看出,算法的资源利用率较高,一直保持在90%以上,这为算法的可扩展性提供了保证。但是随着处理器核数的增加,资源利用率呈现缓慢下降的趋势,这是由于随着核数的增加,系统管理的开销以及核间的同步和通信开销都会随之增加造成的,这种由核数增加带来的副作用是不可避免的。 众核架构作为处理器的发展方向,将会逐渐成为计算密集型应用的主流应用平台。碰撞检测作为BIM中的核心功能,是一个典型的计算密集型问题,通过重新进行算法设计,将其转化成了完全的数据并行过程。该算法充分契合了众核处理器的体系结构,有效利用了众核计算资源,使其性能能够随着处理器核数的增加而成线性提升,具有良好的可扩展性。我们的后续工作是将这种大规模数据并行的思想应用到BIM 中的其它计算密集型问题,通过具有可扩展性的算法为这些问题提供持续高效的解决方案。 [1]张建平,BIM技术的研究与应用[J].施工技术,2011,40(1):15-18. [2]纪凡荣,徐友全,曾大林,等.BIM 技术在某项目管线综合中的应用[J].施工技术,2013,42(3): 107-109. [3]Borkar S, Chien A A. The future of microprocessors[J].Communications of the ACM,2011, 54(5): 67-77. [4]范昭炜,万华根,高曙明.基于流的实时碰撞检测算法[J].软件学报, 2004,15(10):1505-1514. [5]Zhang X, Kim Y J. Interactive collision detection for deformable models using streaming AABBs[J]. Visualization and Computer Graphics, IEEE Transactions on,2007,13(2):318-329. [6]Tang M, Manocha D, Lin J, et al. Collision-streams: fast gpu-based collision detection for deformable models[C]//Symposium on interactive 3D graphics and games. ACM, 2011:63-70. [7]马登武,叶文,李瑛.基于包围盒的碰撞检测算法综述[J].系统仿真学报,2006,18(4):1058-1061. [8]Guigue P, Devillers O. Fast and robust triangle-triangle overlap test using orientation predicates[J]. Journal of graphics tools, 2003, 8(1): 25-32. [9]许彦芹,陈庆奎.基于SMP集群的MPI + CUDA 模型的研究与实现[J].计算机工程与设计,2010(15):3408-3412. Scalable Algorithm Design for Collision Detection in BIM Hu Weisong, Zhao Qianchun, Wu Baifeng Building Information Modeling (BIM) is a hotspot of informatization in construction industry. Collision detection is the key functionality provided by BIM and its computational complexity has been focused by research community and industry. With the scale of construction data expanding, the calculation scale of collision detection keeps increasing. It is difficult for traditional algorithms of collision detection to achieve performance improvement by increasing the quantity of processor cores because they are unable to use computing resources scalably. This problem has become an obstacle to the further development of BIM. It proposes a novel algorithm which carries out collision detection by a new method of massive data parallel in this paper. It has a better match with the modern many-cores processor architecture. Its performance can be improved by increasing the quantity of processor cores linearly and the ideal scalability is realized. The experimental results verified scalability and effectiveness of the algorithm. BIM; Collision Detection; Massive Data Parallel; Many-cores Processor; Scalability TP393 A 2015.02.02) 1007-757X(2015)05-0005-04 鲁班软件大学合作计划项目 胡伟松(1989-),男,复旦大学,计算机科学技术学院,硕士,研究方向:高性能计算,上海,201203赵倩纯(1989-),女,复旦大学,计算机科学技术学院,硕士研究生,研究方向:高性能计算,上海,201203吴百锋(1963-),男,复旦大学,计算机科学技术学院,教授,硕士,研究方向:高性能计算,嵌入式系统,上海,201203

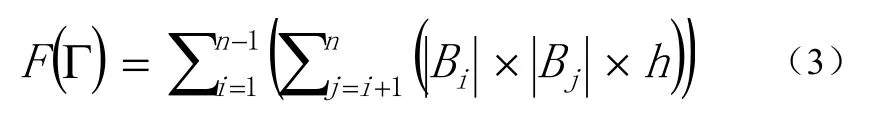
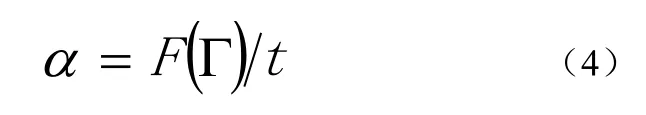



2 算法描述

3 实验及结果分析
4 总结
(School of Compute Science, Fudan University, Shanghai 201203,China)
猜你喜欢
汽车工程师(2021年12期)2022-01-17 02:29:44
铁道通信信号(2020年10期)2020-02-07 01:01:12
电子测试(2018年1期)2018-04-18 11:53:00
汽车零部件(2017年3期)2017-07-12 17:03:58
自动化博览(2017年2期)2017-06-05 11:40:39
电脑知识与技术(2016年14期)2016-06-30 20:29:18
现代工业经济和信息化(2016年12期)2016-05-17 05:38:00
中国工程咨询(2016年12期)2016-01-29 02:21:42
电子设计工程(2015年12期)2015-02-27 12:06:20
汽车零部件(2014年1期)2014-09-21 11:41:11
