
回归方法估算最长频繁模式长度
2015-07-07 01:16史巧硕周慧霞李杨李娟
河北工业大学学报 2015年5期
史巧硕,周慧霞,李杨,李娟
(1.河北工业大学计算机科学与软件学院,天津 300401;2.河北工业大学控制科学与工程学院,天津 300401)
回归方法估算最长频繁模式长度
史巧硕1,周慧霞1,李杨2,李娟1
(1.河北工业大学计算机科学与软件学院,天津 300401;2.河北工业大学控制科学与工程学院,天津 300401)
周期间隙的序列模式挖掘是一种满足Apriori-like性质的序列模式挖掘,其中一项重要工作就是预测最长频繁模式的长度.以往需要人为估计,本文采用回归方法解决这个问题.本文提出一种有效的特征抽取的方法,以获取训练和测试数据.之后分别采用BP神经网络、最小二乘支持向量机和极限学习机进行训练和测试.在DNA序列上进行测试,实验结果表明,ELM具有良好的泛化性能,从而验证了方法的可行性.
序列模式挖掘;BP神经网络;最小二乘支持向量机;极限学习机
machine
0 引言
随着序列模式应用领域越来越细化,传统的序列模式挖掘技术已经不能满足新的挖掘和分析的需求,具有间隙约束的序列模式挖掘是一种特殊形式的序列模式挖掘,是在给定的序列中挖掘出形如a1[M,N]a2[M,N]…am-1[M,N]am的频繁模式,并使其支持率大于给定的阈值[1],其中M和N分别代表模式中两个字符之间允许的最小间隔和最大间隔,间隔中的字符可以为任意字符,因此这是一种较传统的通配符“?”和“*”更加灵活的通配符[2-3],因为如果M与N相同,则可以表示M个“?”;如果M与N分别为0和∞,则可以表示一个“*”.这种间隙约束的存在,一方面使得用户可根据自身的需要,灵活地设定挖掘模式的条件;另一方面可以避免大量无意义的模式被挖掘[1].由于周期间隙约束的序列模式挖掘能够有效地发现具有周期特性的频繁模式,因而吸引了人们的广泛关注,并成为序列模式挖掘的一个重要的研究方向,并且在生物基因序列、Bug挖掘、商业领域、运动模式分析等方面都有着广泛的应用[4-5].这类模式挖掘不仅处理难度更高,而且复杂度多变,目前存在3种形式:一次性条件[1]、无重叠条件[6]和无特殊条件[7-8].尽管基于一次性条件和无重叠条件的周期间隙序列模式挖掘满足Apriori性质,但是由于不能精确地计算一个模式在序列中的支持数[1,6],因而都属于一种近似挖掘算法;无特殊条件的周期间隙序列模式挖掘(简称周期间隙序列模式挖掘)虽然可以精确地计算一个模式在序列中的支持数,是一种精确挖掘,但是需要采用Apriori-like性质进行挖掘[7-8],需先验地估计序列的最长频繁模式长度,如果最长频繁模式估计过短,则会有更长频繁模式不能被挖掘;如果最长频繁模式估计过长,则会进行大量的无效挖掘,降低算法的挖掘速度.为了有效地克服人为估计的不足,本文采用机器学习的方法对最长频繁模式长度进行回归估计研究.
本文结构如下:第1节给出了序列模式挖掘的定义,之后介绍了本文的特征提取方法;第2节简要的介绍了本文所使用的3种回归算法;第3节给出了实验结果与分析;第4节得出本文结论.
1 序列模式挖掘和特征提取
1.1 周期间隙的序列模式挖掘
定义1(目标序列)把从中提取频繁模式的字符序列S=s1s2…sn称为目标序列[7-8].令∑表示所有可能出现在目标序列中的字母表.例如若∑={a,g,t,c}对应于DNA序列,而对于蛋白质序列,∑表示的是20种氨基酸.
定义2(模式[1-3])1个模式P=a1[M,N]a2[M,N]…am-1[M,N]am是由字符和间隙组成的序列,其中1≤i≤m,ai∈∑,M和N分别表示两个字符间通配符可以通配的最小间隙和最大间隙,m是模式P的长度.
定义3(偏移序列)偏移序列是1个下标序列D=<d1,d2,…,dm>,该序列满足模式P的间隙约束,偏移序列总数ofs(P,S)是P在S中的最大可能数.
定义4(出现,支持数)出现I=<i1,…,ij,…,im>是在偏移序列基础上,满足Sij=pj(1≤j≤m and 0≤ij≤n).支持数sup(P,S)是P在S中的出现总数.
定义5(频繁模式)如果模式P的支持率r P,S=sup P,S/ofs P,S不小于用户给定的阈值,那么P是1个频繁模式,否则P是1个非频繁模式.
例如给定序列S=agttt,模式P=a[0,3]g,P的超模式Q=T[0,3]C[0,3]G.可知P和Q的出现分别为<1,2>及<1,2,3>,<1,2,4>和<1,2,5>,即sup(P,S)=1和sup(Q,S)=3.所以1个模式的支持数小于其超模式的支持数.P在S中的偏移序列为<1,2>,<1,3>,<1,4>,<1,5>,<2,3>,<2,4>,<2,5>,<3,4>,<3,5>和<4,5>,Q在S中的偏移序列为<1,2,3>,<1,2,4>,<1,2,5>,<1,3,4>,<1,3,5>,<1,4,5>,<2,3,4>,<2,3,5>,<2,4,5>和<3,4,5>,ofs(P,S)和ofs(Q,S)均为10,因此r(P,S)<r(Q,S).因此周期间隙约束的序列模式挖掘需要采用Apriori-like性质挖掘频繁模式.这需要预先对序列的最长频繁模式的长度进行人为估计,如果该值小于实际最长频繁模式长度,会导致最长频繁模式不能被挖掘;如果该值大于实际最长频繁模式长度,则会有大量候选模式被检测,进而导致挖掘速度的下降.为了避免人为估计的不足,采用机器学习的方法解决此问题.下面小节将要介绍本文使用的特征提取方法.
1.2 特征提取
本文拟解决的问题是在给定两个整数间隙M和N,在指定字符序列S上估算最长频繁模式P的长度m.而机器学习方法不能直接对字符序列进行回归,需要依据S,M和N进行特征提取,为了最大限度保证提取的特征与求解的问题相吻合,本文提出了统计长度为2的所有模式在序列中出现数的形式作为问题的特征.具体求解步骤如下
1)统计模式a1M,N a2在序列中的出现次数F a1M,N a2,这里F函数表示子模式在序列中的出现次数,其计算公式如下.
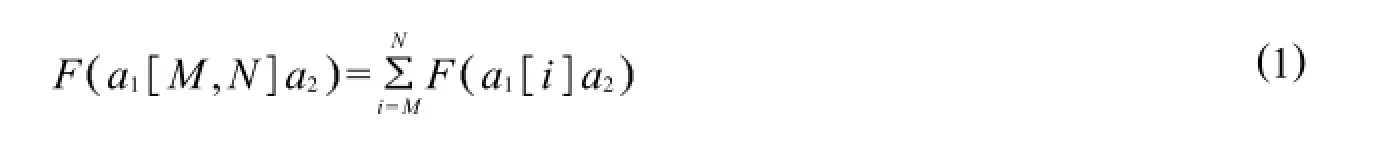
其中:模式a1i a2是两个字符a1和a2之间有i个通配符;F a1i a2是模式a1i a2在序列S中的出现次数.
3)第|∑|*|∑|+1维特征向量采用序列模式挖掘的频繁度阈值;
4)回归的目标为采用MAPD算法[7]挖掘到的频繁模式获得最长频繁模式长度(该算法可从http:// wuc.scse.hebut.edu.cn/msppwg/index.html获取).
例如在DNA序列中,∑是由{a,g,t,c}共4种字符所构成的,因此在DNA序列上,前4×4=16维向量采用上述步骤1)和2)获得,下面举例说明特征提取方法.
给定目标序列S=ttcctccgcgaaggctcctt,设定间隙[M,N]为[0,3].
首先扫描目标序列S,得到aa,a·a,a·a,a··a(其中‘·’表示通配符)在S中出现的次数分别为1、0、0和0,将此4个数值累加得到a[0,3]a在S中出现的次数为1.
然后,依次统计a[0,3]g,a[0,3]t,a[0,3]c,g[0,3]a,g[0,3]g,g[0,3]t,g[0,3]c,t[0,3]a,t[0,3]g,t[0,3]t,t[0,3]c,c[0,3]a,c[0,3]g,c[0,3]t,c[0,3]c在S中出现的次数,分别为4、1、2、4、4、2、6、0、1、6、10、3、7、8和11.这样就得到了16维的模式长度为2的一组统计数据{1,4,1,2,4,4,2,6,0,1,6,10,3,7,8,11},当间隙M和N变化时,这16维数据会相应发生改变.而数据的第17维和回归目标分别按照步骤3)和4)获得.
2 3种回归算法
2.1 BP神经网络
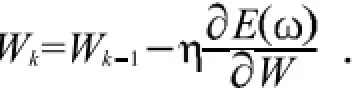
基于梯度下降法的BP存在以下缺点:1)训练速度慢.因为需要多次的迭代,所以时间消耗很长;2)参数选择很敏感,必须选取合适的初值,才能取得理想的结果.若太小,算法收敛很慢,而太大,算法不太稳定甚至不再收敛;3)局部最小值.由于E W非凸,因此在下降过程中可能会陷入局部最小点,无法达到全局最小;4)过渡拟合.在有限样本上训练时,仅以训练误差最小为目标的训练可能导致过渡拟合.2.2最小二乘支持向量机(LS-SVM)
最小二乘支持向量机[9]是对标准SVM的一种扩展.与传统的SVM不同,它是将传统的支持向量机中的不等式约束改为等式约束,且将误差平方和损失函数作为训练集的经验损失,这样LS-SVM算法就将SVM的求解从二次规划问题转换为求解线性方程组问题,提高了SVM的求解效率,降低了SVM的学习难度.
2.3 极限学习机(ELM)
为了解决BP出现问题,Huang等人[10-11]提出了ELM算法,ELM算法是一种新型的单隐层反馈网络.与SVM和传统神经网络相比,ELM的训练速度非常快,需要人工干扰较少,对于异质的数据集其泛化能力很强.该方法通过设置合适的隐藏层结点数,为输入权和隐藏层偏差进行随机赋值,然后输出层权值通过最小二乘法得到,整个过程一次完成,无需迭代,因而具有较快的学习速度[11-12],其网络输出函数可表示为:
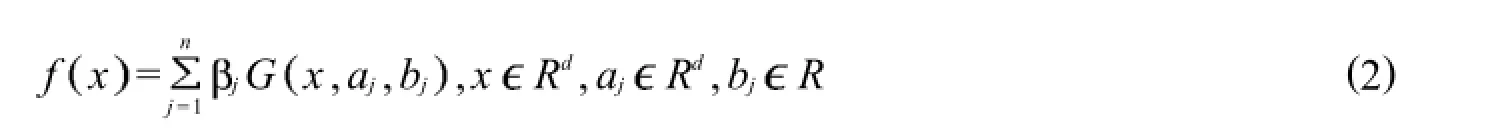
其中:G x,aj,bj为第j个隐层结点的输出函数;j为第j个隐层结点到输出结点的连接权值.与其他多种机器学习方法相似,ELM的隐层结点输出函数可以有多种类型,如加性结点和径向基函数(RBF)结点等.
3 实验结果及分析
实验数据是从生物信息中心网站下载的人类DNA序列(AX829174,AL158070,AB038490),实验数据可分别从http://www.ncbi.nlm.nih.gov/nuccore/AX829174,http://www.ncbi.nlm.nih.gov/nuccore/AL158070.11和http://www.ncbi.nlm.nih.gov/nuccore/AB038490下载.实验运行环境为Intel(R)core(TM)i3CPU,2.00GB内存的计算机上.本文通过不同长度变化,将上述三组DNA序列变化为11个DNA序列,其中S1~S5序列取自AX829174序列,长度分别为1 000、2 000、4 000、8 000以及AX829174序列的实际长度10 011;S68序列取自AL158070序列,长度分别为20 000、40 000和80 000;S911序列取自AB038490序列,长度分别为15 000、30 000和60 000.
3.1 阈值与间隙变化下回归最长频繁模式长度的实验结果分析
通过采用1.2节的特征抽取方法,依据给定阈值和间隙约束,在S1序列上获得了数据集F1,该数据集共有150条数据,随机选择其中的100条数据用于训练,剩余的50条数据用于测试.对于S2~S11序列,采用同种方法随机产生50条测试数据,用于验证F1数据集的学习模型是否可以应用到其它序列中,S2~S11序列产生的测试数据集分别为F2,F3,…,F11.
利用3种回归算法在F1数据集上测试结果如图1和表1所示,在F2~F11数据集上进行测试的均方误差如表2所示.
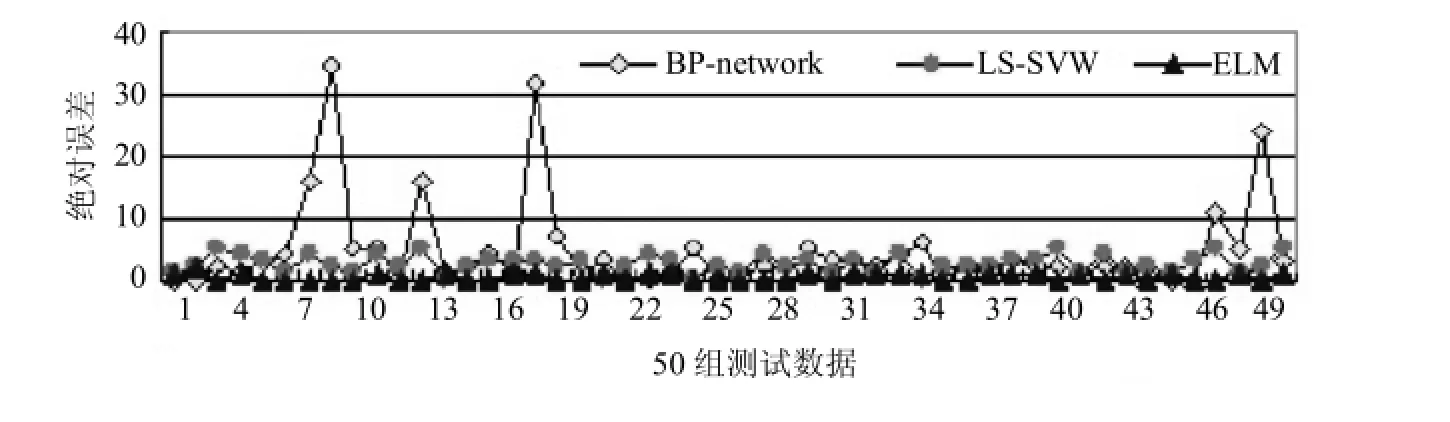
图1 F1数据集测试绝对误差图Fig.1Testing absolute error of data set F1
从图1和表1可以看出,BP神经网络的学习效果最好,但训练时间将近是其它两种算法的2000倍,而且从F1数据集的测试结果来看,由于BP神经网络的不稳定性,它测试的均方误差比ELM大15倍,这说明不能用BP神经网络来预测最长频繁模式长度,它严重不符合实际值.说明BP神经网路陷入过学习问题.而ELM算法具有较好学习速度,并且泛化能力强.从表1中看出,ELM的训练时间仅为11.083ms,而且测试的均方误差仅为0.582,说明ELM算法具有很好的稳定性.不仅如此,在表2中ELM算法在其余10个测试集合上测试均方误差均好于其他两种学习算法,反应出ELM算法具有良好的稳定性.

表13 种算法在F1数据集的训练与测试比较表Tab.1Comparison of the training and testing results of 3 algorithms on data set F1

表2 F2~F11数据集在F1学习模型上的测试均方误差对比表%Tab.2Comparison of testing measure square error of data sets F2~F11 on learning model F1
3.2 阈值与序列变化下回归最长频繁模式长度的实验结果分析
为了探究阈值和序列变化对最长频繁模式长度的影响,对[9,12]这个间隙下产生的数据集进行了学习和测试,为了验证这一学习模型,又分别用[0,4],[3,9],[5,10],[8,11],[10,13]对其进行测试.
设定间隙为[9,12],保持不变,在S1~S11共11个序列上,通过阈值和序列变化利用MAPD算法进行序列模式挖掘,再利用1.2节的特征提取,随机产生50条训练数据和20条测试数据,得到实验所需的数据集F9_12,与3.1节的数据集相类似,3.1节的数据集是阈值和间隙变化,而本小节实验中的数据集是阈值和序列变化,最后还是要预测最长频繁模式长度.为了验证该学习模型,分别用[0,4],[3,9],[5,10],[8,11],[10,13]这5个间隙进行测试,通过阈值和序列变化,在每个间隙下随机产生20条测试数据组成5组测试数据集,分别为F0_4,F3_9,F5_10,F8_11,F10_13.F9_12数据集的学习和测试结果如图2和表3所示,F0_4,F3_9,F5_10,F8_11,F10_13数据集在[9,12]数据集上进行测试的结果如表4所示.

图2 F9_12数据集测试绝对误差图Fig.2Testing absolute error of data set F9_12
从图2和表3与表4可以看出,与上一小节的实验结果相似,ELM算法无论是在训练时间上和泛化能力方面均好于BP神经网络以及LS-SVM算法,并能够有效地避免过学习问题.从表3中可以看出,ELM算法的训练速度大大高于其他两种方法,其训练时间仅为5ms左右,而其他两种算法分别9000ms和17ms左右.此外ELM算法不仅在F9_12数据集上测试均方误差好于其他两种算法,而且从表4中可以看出,其在其他多种测试集上均好于其他两种算法,例如在F0_4数据上,ELM算法测试均方误差为1.1,而其他两种算法均高于此值.这充分地说明了采用机器学习方法可以有效地估算最长频繁模式长度.

表33 种算法在F9_12数据集的训练与测试比较表Tab.3Comparison of the training and testing results of 3 algorithms on data set F9_12

表4 其他数据集在F9_12学习模型上的测试均方误差对比表%Tab.4Comparison of testing measure square error of data sets on learning model F9_12
4 结束语
为了有效地解决周期间隙的序列模式挖掘中最长频繁模式长度需要人为估算的问题,本文采用机器学习的方法有效地估算最长频繁模式.本文采取了统计长度为2的模式串在序列中出现数的方式,实现对字符序列进行有效地特征提取,然后分别采用BP神经网络、LS-SVM和ELM共3种机器学习算法实现对最长频繁模式长度进行了训练及测试.在DNA序列上进行实验,实验结果表明,采用ELM算法具有良好的学习速度和泛化能力,有效地解决了人为估计最长频繁模式长度问题.
为了进一步提高估算的准确率,未来将尝试新的特征提取方法,如将长度为3的模式子串的出现数也作为特征的方式进行特征提取.
[1]吴信东,谢飞,黄咏明,等.带通配符和One-Off条件的序列模式挖掘[J].软件学报,2013,24(8):1804-1815.
[2]武优西,刘亚伟,郭磊,等.子网树求解一般间隙和长度约束严格模式匹配[J].软件学报,2013,24(5):915-932.
[3]武优西,吴信东,江贺,等.一种求解MPMGOOC问题的启发式算法[J].计算机学报,2011,34(8):1452-1462.
[4]XuanJ,JiangH,HuY,etal.Towardseffectivebugtriagewithsoftwaredatareductiontechniques[J].IEEE TransactionsonKnowledgeandData Engineering,2015,27(1):264-280.
[5]Yen S J,Lee Y S.Mining non-redundant time-gap sequential patterns[J].Applied Intelligence,2013,39(4):727-738.
[6]Ding B,LoD,Han J,et al.Efficient miningof closedrepetitivegappedsubsequences from asequence database[C].In:IEEE 25thInternational Conference on Data Engineering(ICDE'2009),Shanghai,China,2009:1024-1035.
[7]Wu Y,Wang L,Ren J,et al.Mining sequential patterns with periodic wildcard gaps[J].Applied Intelligence,2014:41(1):99-116.
[8]ZhangM,KaoB,CheungD,etal.Miningperiodicpatternswithgaprequirementfromsequences[J].ACM TransactionsonKnowledgeDiscovery from Data(TKDD),2007,1(2):7-es.
[9]Suykens J A K,Vandewalle J.Least squares support vector machine classifiers[J].Neural processing letters,1999,9(3):293-300.
[10]Huang GB,Zhu QY,Siew CK.Extreme learning machine:Theory and applications[J].Neurocomputing,2006,70(1-3):489-501.
[11]HuangGB.Learningcapabilityandstoragecapacityoftwohidden-layerfeedforwardnetworks[J].IEEETransactionsonNeuralNetworks,2003,14(2):274-281.
[12]邓万宇,郑庆华,陈琳,等.神经网络极速学习方法研究[J].计算机学报,2010,33(2):279-287.
[责任编辑 田丰夏红梅]
Using regression methods to estimate the length of the longest frequent patterns
SHI Qiaoshuo1,ZHOU Huixia1,LI Yang2,LI Juan1
(1.School of Computer Science and Engineering,Hebei University of Technology,Tianjin 300401,China;2.School of Control Science and Engineering,Hebei University of Technology,Tianjin 300401,China)
Predicting thelength of longestfrequentpatternsisan importanttask of sequential patterns miningwith periodic wildcard gaps which satisfies the Apriori-like property.The traditional method is to estimate the length artificially.To tackle this problem,the regression methods are employed.An effective method for feature selection is presented to obtain the training and testing data sets.Then BP neural network,Least Squares Support Vector Machines(LS-SVM),and Extreme Learning Machine(ELM)are employed respectively for the data training and testing.Experiments on DNAsequences confirm that ELM has better performance than other competitive algorithms and experimental results show the method is feasible.
sequential patterns mining;BP neural network;least squares support vector machine;extreme learning
TP319
A
1007-2373(2015)05-0045-06
10.14081/j.cnki.hgdxb.2015.05.009
2015-01-03
河北省自然科学基金(F2013202138);河北省教育厅重点项目(ZH2012038);河北省教育厅青年基金(QN2014192)
史巧硕(1974-),女(汉族),副教授.
数字出版日期:2015-10-19数字出版网址:http://www.cnki.net/kcms/detail/13.1208.T.20151019.1031.010.html
猜你喜欢
小资CHIC!ELEGANCE(2022年2期)2022-01-11
航空发动机(2020年3期)2020-07-24
数学物理学报(2020年2期)2020-06-02
制造技术与机床(2019年9期)2019-09-10
电子制作(2019年15期)2019-08-27
西南交通大学学报(2018年6期)2018-12-18
电子制作(2018年19期)2018-11-14
河北遥感(2017年2期)2017-08-07
自动化学报(2017年11期)2017-04-04
广西电力(2016年4期)2016-07-10
