
基于迁移学习的客户信用评估模型研究
2015-07-07 15:33贺昌政李慧媛
运筹与管理 2015年2期
朱 兵, 贺昌政, 李慧媛
(四川大学 商学院, 四川 成都 610064)
基于迁移学习的客户信用评估模型研究
朱 兵, 贺昌政, 李慧媛
(四川大学 商学院, 四川 成都 610064)
客户信用评估是银行等金融企业日常经营活动中的重要组成部分。一般违约样本在客户总体中只占少数,而能按时还款客户样本占多数,这就是客户信用评估中常见的类别不平衡问题。目前,用于客户信用评估的方法尚不能有效解决少数类样本稀缺带来的类别不平衡。本研究引入迁移学习技术整合系统内外部信息,以解决少数类样本稀缺带来的类别不平衡问题。为了提高对来自系统外部少数类样本信息的使用效率,构建了一种新的迁移学习模型:以基于集成技术的迁移装袋模型为基础,使用两阶段抽样和数据分组处理技术分别对其基模型生成和集成策略进行改进。运用重庆某商业银行信用卡客户数据进行的实证研究结果表明:与目前客户信用评估的常用方法相比,新模型能更好地处理绝对稀缺条件下类别不平衡对客户信用评估的影响,特别对占少数的违约客户有更好的预测精度。
客户信用评估;类别不平衡;迁移学习;数据分组处理技术
0 引言
客户信用评估是银行等金融企业日常经营活动中的重要组成部分。一个好的客户信用评估模型,能够精确识别出违约客户,使企业规避信用风险,获取更多利润。因此,对客户信用评估模型的研究具有重要的意义。
客户信用评估模型的发展经历了三个阶段:定性分析、统计分析和人工智能分析[1]。定性分析是最早用于信用评估的方法,其后统计方法被逐渐引入到客户信用评估中,例如Orgler[2]最早使用回归分析制定了一个用于信用卡客户评估的评分卡。近年来,随着数据挖掘和人工智能方法的发展,很多方法被陆续引入到信用评估之中。例如,刘京礼等为信用评估提出了自适应最小二乘支持向量机[3],Chang和Yeh使用了一种人工免疫算法[4],肖智和李文娟提出了基于粗糙集和神经网络的客户信用混合评估模型[5],West等使用了集成神经网络进行信用评价[6]。
客户信用评估本质上是一个分类问题,即根据客户数据,将其分成能按时还款和违约两类。在这一分类过程中,两类信用状况客户比例分布常常是不均衡的,俗称类别不平衡,一般违约客户在总体中只占少数,而能按时还款客户占多数。以全球最大的万事达信用卡发行商花旗银行为例,其信用卡客户违约率约为5.3%. 类别的不平衡给客户信用评估带来了极大挑战,例如,在一个按时还款和违约客户比例为9:1的客户信用评估问题中,一般模型很有可能将所有客户都预测成为按时还款的客户,这样得到的模型总体精度可以到达90%[7],但是它却将那些需重点关注的违约客户全部预测错误,这样的结果只会给企业带来巨大信用风险。
为了处理类别不平衡对客户信用评估的影响,学者主要提出了两条解决路径[8]:一是数据层次解决方案,这类研究主要使用向下、向上或者混合抽样等抽样技术来平衡训练集类别分布,然后再建立客户信用评估模型。其中比较有代表性的方法包括了随机向下抽样(Random under-sampling, RUS)和合成过采样技术(Synthetic minority over-sampling technique, SMOTE)[9]。例如吴冲和夏晗[10]提出的基于支持向量机集成的客户信用评估模型中,就采用了向下抽样技术处理类别不平衡。二是算法层次解决方案,这种方案通过改变算法内在分类过程偏置来实现对不同类别客户分类的均衡。最典型的是代价敏感学习,它通过给不同类别客户赋予不同误分代价来处理类别不平衡,如Yang等使用代价敏感核学习技术对客户信用评估问题进行了研究[11]。
不管是数据层次还是算法层次解决方案,它们使用的都是系统内部客户信息,对于相对稀缺带来的不平衡,由于少数类样本数量充足,使用系统内部信息能有效地解决类别不平衡带来的影响。但对于绝对稀缺情况,由于少数类客户样本数量不足,仅使用系统内部信息往往难以解决类别不平衡的影响。绝对稀缺带来的类别不平衡是客户信用评估中的常见现象,一方面,企业可能因受到时间和资金等资源限制,只能收集到少量客户样本,特别是以问卷等形式来获取客户信息;另一方面,当金融企业业务规模较小或是在其业务开展初期,由于本身的客户数量较少也常遇见类似状况。
鉴于此,本研究将系统外部相关领域的客户信息引入到客户信用评估研究中,并尝试使用迁移学习技术整合系统内外部信息,构建一种平衡迁移学习模型,以帮助解决客户信用评估中由绝对稀缺带来的类别不平衡问题。
1 迁移学习方法基础
迁移学习的概念源于心理学[12],是指人类在学习过程中的一种能力,即能够将在相关领域学习中积累的经验和技能运用于新的学习任务,比如会打乒乓球的人,就会更容易学会打网球。上世纪90年代Thrun[13]、Baxter[14]和Caruana[15]等部分学者将其引入到统计学习领域并发展出了一系列迁移学习建模方法。本世纪初,Ben-David和Schuller[16]对学习任务之间的相关性进行了形式化的定义,Mahmud和Ray使用Kolmogorov[17]对迁移学习的上下界进行了分析,这些理论性的探索为迁移学习奠定了理论基础。经过十多年发展,目前已有不少学者将其用于整合系统外部数据,以解决目标领域数据样本不足的问题,并在文本挖掘,信息检索以及图像处理等众多领域得到了成功应用[18]。然而通过已有文献分析发现,现尚未有学者将迁移学习运用到客户信用评估问题中,也尚未有研究将其用于解决类别不平衡问题。
作为一种建模方法,迁移学习的主要思想是利用相近领域中的知识及信息来辅助目标领域中的建模。在众多的迁移学习方法中,基于实例的迁移学习方法是最常用的一种。实例迁移方法假设来自相关领域的数据既包含了有用数据样本,也包含了无用样本。实例迁移方法将相关领域的有用数据样本引入,通过抽样或者加权的方法来处理其与目标领域数据样本的差异性,整合系统内外部信息。例如Dai等学者提出一种基于boosting提升技术来利用相关领域的旧数据[19]。迁移装袋模型(Transfer bagging, TrBagg)是由Kamishima等提出的一种以集成模型Bagging为基础的实例迁移学习技术[20]。 TrBagg假设源数据集中既包含了对目标领域建模有用的样本,也含有无用的样本,因此TrBagg从源数据和目标数据组成的并集中多次抽样,然后训练得到多个基模型,并计算这些基模型在目标数据集上的精度。如果基模型精度较高,则认为被用来训练基模型的源数据集样本是有用的。如果精度不高,则包含的源数据集样本是无用的。TrBagg通过启发式方式将精度较高的基模型选出,再通过多数投票方法得到最后的集成模型。Kamishima等人将TrBagg方法用于文本挖掘领域,得到了比其它迁移学习方法更好的精度。TrBagg模型最大的特点是简单易用,在建模过程不需要进行大量模型参数调节工作,减少了对经验和专家知识的依赖,这使得其非常适合于解决客户信用评估问题,而已有的研究表明作为TrBagg方法的基础的Bagging模型能够比其它集成方法更好地对客户信用进行预测[21]。
2 客户信用评估平衡迁移模型
2.1 客户信用评估问题分析
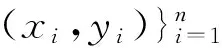
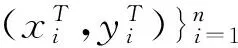
2.2 平衡迁移学习模型构建
在2.1小节所分析的客户信用评估问题中,为了解决绝对稀缺的类别不平衡带来的影响,本研究拟引入系统外部源领域客户信息。一般情况下由于目标数据集中多数类样本Tmaj比较充足,研究中只考虑将源数据集S中的少数类样本Smin引入。由于源数据集S与目标数据集T来自于不同领域,如何处理它们之间差异性成为了整个建模的关键,而迁移学习技术,特别是集成迁移学习技术TrBagg为解决这一问题提供了一个有效框架。
然而,直接使用TrBagg模型并不能完全解决客户信用评估中绝对稀缺带来的类别不平衡。其原因主要有三:第一,在引入系统外部少数类样本后,少数类样本与多数类样本相比仍然可能相对较少,出现相对类别不平衡。而TrBagg模型在基模型的训练过程中使用bootstrap抽样方法直接从源数据和目标数据的并集(T∪S)上获取数据训练基模型,这种抽样方式不会改变样本类别分布,不能保证基模型在相对类别不平衡情况下,在少数类样本上得到好的学习效果;第二,在基模型筛选过程中,TrBagg使用模型在目标数据集上总体精度作为准则,这样选出的基模型同样不能保证在少数类样本上的预测效果;第三,TrBagg在基模型集成过程中使用的是多数投票法,它不能反映每个基模型在目标数据集上分类精度的差异性。
为解决上述不足,本文从两个方面对TrBagg进行了改进:一是使用两阶段抽样获取用于学习基模型的训练集,以更好地对少数类样本进行分类;二是使用数据分组处理技术(Group Method of Data Handling,GMDH)[23]作为基模型集成策略。GMDH是自组织数据挖掘的核心技术,目前已有学者将其用于集成模型研究,并且取得了较好效果[24]。GMDH技术最大特点是能在建模过程中从众多变量中自动选择出重要变量建立非线性模型。因此,将其作为集成策略能够很好地选择出有用的基模型,并进行非线性集成,充分反映各基模型在目标数据上分类精度的差异性。这其中为了更好地筛选在少数类上具有较高分类精度的基模型,本研究为GMDH构建了一种代价敏感外准则(cost sensitive regularity criterion,CSRC)。综合这些改进工作,本研究提出了一种适用于客户信用评估的平衡迁移学习模型B-TrBagg,该模型建模过程分为学习和筛选两个阶段,具体算法步骤如下:
学习阶段:
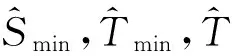
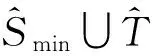
④重复步骤①~③k遍,得到k个初始基模型集F={f1,f2,…,fk}。
筛选阶段:
①把目标数据集T分成两个同等大小的子集:T=A∪B;
②把初始基模型集F中的基模型两两组合,以它们的输出作为输入,使用下面二次多项式生成中间待选模型:
(1)
其中xi=fi,xj=fj(1≤i,j≤k),a0,a1,a2,…,a5是待估计参数,通常使用普通最小二乘法方法估计。以含有5个基模型的基模型集F={f1,f2,…,f5}为例,将基模型两两组合将会得到10个中间模型,其中使用基模型x1=f1和x2=f2将会产生中间模型z11如下:
(2)
③利用公式(3)所示代价敏感外准则CSRC评价每个候选模型,记录当前层外部准则最小值Ri。选择Li个外准则值较低的模型,将它们的输出Zti作为GMDH网络下一层的输入变量(xti=Zti,t=1,…,Li):
(3)
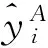
④重复第②~③来产生第二层、第三层,…中间候选模型,直到当前层外准则最小值Ri比前一层大时算法停止。将第i-1层中外准则值最小模型选为最终的集成模型f*。
3 实证研究
本节将新提出的平衡迁移模型应用于银行信用卡客户信用评估问题进行实证研究以检验其有效性。
3.1 数据描述
实证研究数据来自重庆某商业银行数据库的信用卡用户数据。数据采集于2012年12月,原始数据中包含了每位客户的人口地理统计等相关信息。根据客户有无违约记录,将其分类为按时还款客户和违约客户。由于客户信用行为具有时效性,随着经济和银行业务发展,其信用行为也会发生变化。因此,公司期望使用2012年后申请并获取了信用卡的客户数据进行建模,以帮助企业进行营销发卡决策。由于该银行信用卡业务较小,这部分客户中有信用记录客户数量有2502个,其中违约客户数目仅有345个,不仅绝对数量少,而且在总体中的比例仅为13.8%,与此同时,该银行还保存了自开展信用卡业务以来的所有客户数据,其中2012年以前申请并获取了信用卡的客户中有1141个违约客户。我们希望通过这1141个客户的“信息迁移”,以帮助解决类别不平衡问题,提高模型在目标客户中的分类精度。
3.2 实验设置
精密度:取同一稻谷,进行叶黄素提取,连续测定6次,计算出叶黄素提取量的RSD为0.25%,表明精密度良好。
在研究中将历史数据中1141个违约客户作为源数据集S,将近期的2502个客户样本分为两部分,约70%样本(1752个样本)作为目标数据集T用于训练模型,约30%样本(750个样本)作为测试集检验模型效果。将这样的数据划分过程重复20次,并把20次数据划分建模结果进行平均得到最后的结果。在数据划分过程中,保持了两部分样本中的按时还款和违约客户的比例大致相同,即在学习集上有1510个按时还款客户和242个违约客户,而在测试集中有645个按时还款客户和105个违约客户。
由于特征选择对减轻类别不平衡对建模的影响有帮助作用[7],我们使用著名的特征选择方法Relief[25],先选择出一个含有10个自变量的特征子集,再建立信用评估模型,表1给出了10个自变量的相关信息。

表1 自变量列表
我们选择支持向量机(support vector machine, SVM)这种信用评估中常用且效果较好的模型作为基准。为了验证B-TrBagg的有效性,我们从两个方面将其与其它方法进行了比较:一是与使用系统内部信息的基准方法比较。其中为了处理类不平衡,使用随机向下抽样(RUS)、合成过采样SMOTE和代价敏感支持向量机(cost-sensitive support vector machine,CS-SVM)三种技术;二是与其它的迁移学习技术进行比较。主要考虑了另一种著名集成迁移学习方法Tradaboost以及原始的TrBagg。在B-TrBagg和TrBagg模型中,采用决策树作为基模型。
因当数据类别不平衡时,单一的总体精度(Accuracy,Acc)不足以全面地评价模型性能。我们采用了其他四个在类别不平衡条件下常用于衡量模型有效性的度量指标:AUC (Area under curve of the receiver operating characteristic graph)、敏感性(Sensitivity,Se)、特异性 (Specificity,Sp)和G-Mean。其中敏感性Se和特异性Sp分别反映了模型在两类客户中的分类精度,而G-Mean和AUC则反映了在两类客户分类精度上的平衡,所有实验均在Matlab环境中完成。
3.3 结果分析
表2给了实验结果,其中每列粗体数值代表了该指标下的最优值,为了进一步验证新方法B-TrBagg的有效性,我们将B-TrBagg与基准方法在每一个指标下进行了配对t检验,表3给出了统计检验p值结果。从表2、表3中我们可以观察到:
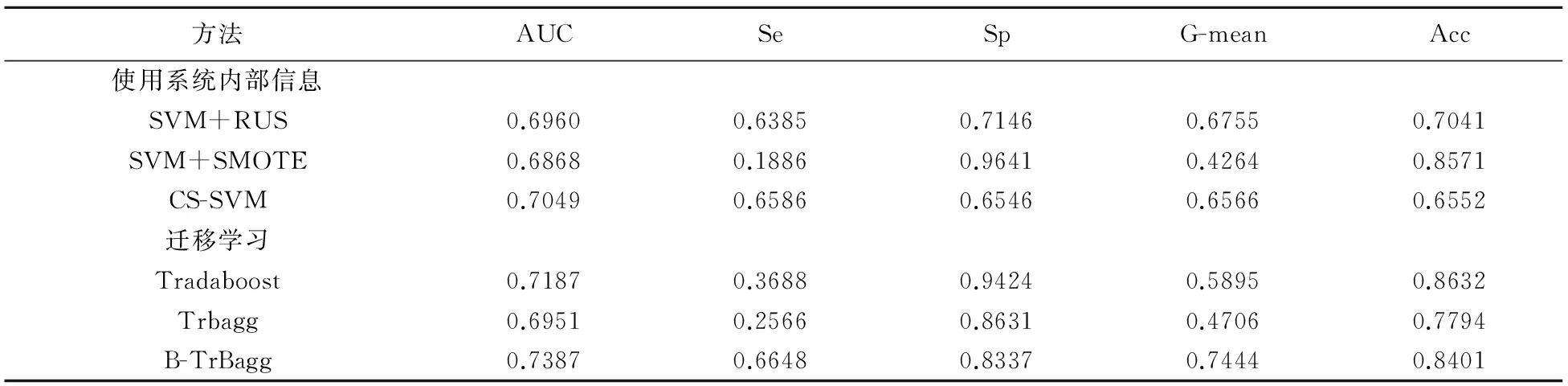
表2 与系统内部信息基准方法对比结果
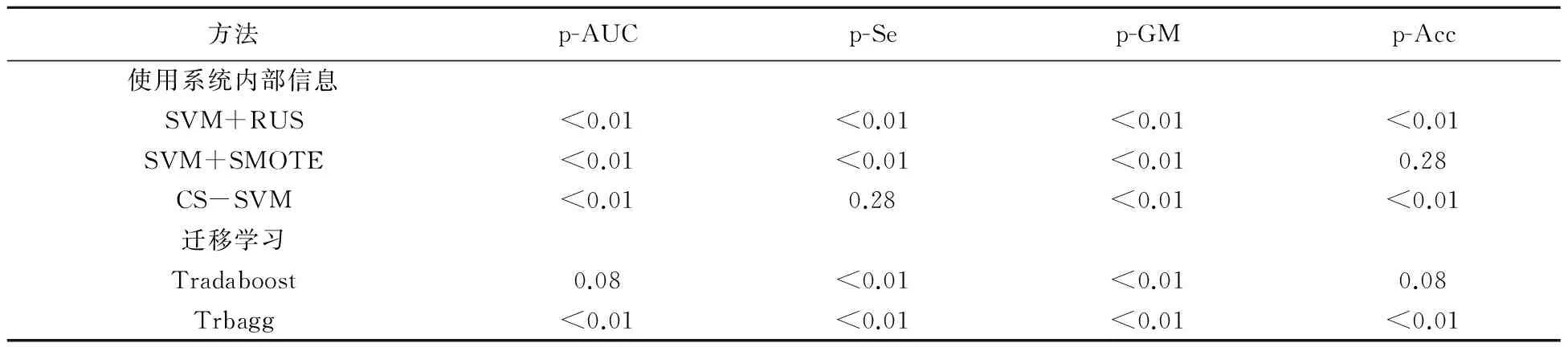
表3 配对t检验结果
从实证研究结果中,我们可以看出B-TrBagg比仅使用系统内部信息处理类别不平衡的方法有效,也明显优于其他迁移学习模型,特别是对少数类违约客户的分类精度较好。为了进一步验证上述的结论,我们使用该银行2011年后申请并获取了信用卡的客户数据作为系统内部数据,而将2011年以前申请并获取了信用卡的客户数据作为系统外部数据进行建模,得到了与上述相类似的结论,实验结果如表4所示。
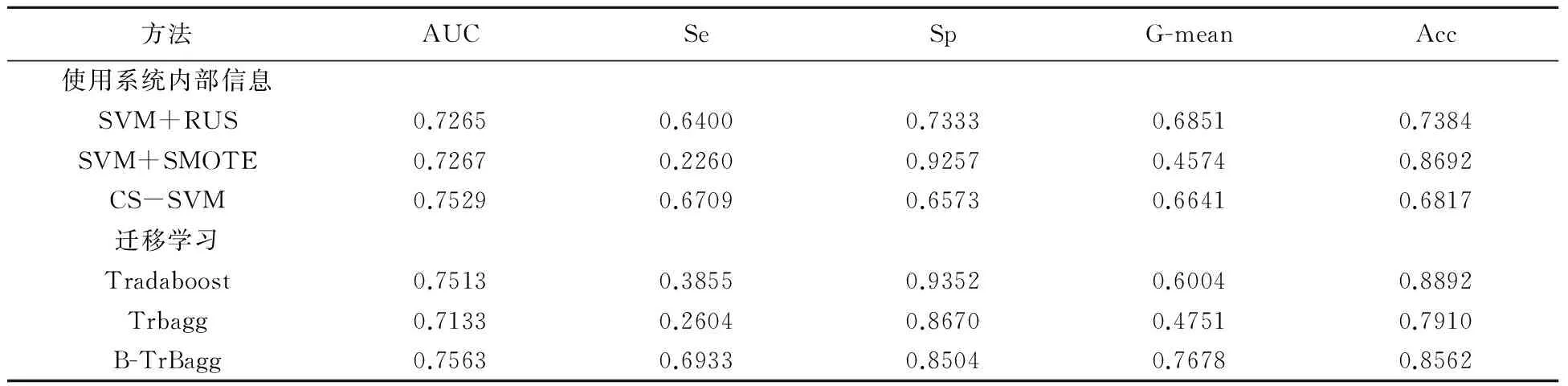
表4 补充实验结果
实验结果表明,引入外部信息后,BT-rBagg与其他的基准模型相比,对两类客户均有较好的预测精度,对少数类违约客户的分类的预测精度有显著提高,而对多类客户的预测精度也较高。通过使用B-TrBagg该银行能够有效预测出有违约可能的客户,提高风险规避能力,对多类按时还款客户的精确预测能够使其减少对这部分客户的风险控制投入的精力,降到运行成本。
4 结论
现有客户信用评估中处理类别不平衡问题主要是通过抽样或者成本敏感学习等手段解决,它们仅使用了来自系统内部的客户信息,不能有效处理绝对稀缺带来的类别不平衡。本文提出了一种新的解决思路,将系统外部客户数据引入,通过迁移学习技术整合系统内外部信息,构建了一种基于集成学习的平衡迁移学习模型,并在重庆地区某商业银行的信用卡客户数据上进行了实证研究。研究结果表明,通过迁移学习技术引入系统外部客户信息来解决客户信用评估问题中由绝对稀缺带来的类别不平衡这一思路是有效的,平衡迁移模型比仅利用系统内部信息的方法以及其它的迁移学习方法能取得更好分类精度,特别是能显著提高少数类违约客户的预测精度,帮助企业规避信用风险。在客户关系管理实践中还存在着很多问题都受到类别不平衡的困扰,比如客户流失预测,在未来研究工作中可以将平衡迁移学习模型应用于解决这些问题。
[1] Crook J N, Edelman D B, Thomas L C. Recent developments in consumer credit risk assessment[J]. European Journal of Operational Research, 2007, 183(3): 1447-1465.
[2] Orgler Y E. A credit scoring model for commercial loans[J]. Journal of Money, Credit and Banking, 1970, 2(4): 435- 445.
[3] 刘京礼,李建平,徐伟宣,石勇.信用评估中的鲁棒赋权自适应Lp最小二乘支持向量机方法[J].中国管理科学,2010,5:28-33.
[4] Chang S Y, Yeh T Y. An artificial immune classifier for credit scoring analysis[J]. Applied Soft Computing, 2012, 12(2): 611- 618.
[5] 肖智,李文娟.RS-ANN在消费信贷个人信用评估中的实证研究[J].软科学,2011,25(4):141-144.
[6] West D, Dellana S, Qian J. Neural network ensemble strategies for financial decision applications[J]. Computers & Operations Research, 2005, 32: 2543-2559.
[7] Haibo H, Garcia E. Learning from imbalanced data[J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263-1284.
[8] Sun Y, Wong A, Kamel M, Classification of imbalanced data: a review[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2009, 23(4): 687-719.
[9] Chawla N V, Bowyer K W, Hall L O, Kegelmeyer W P. SMOTE: Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357.
[10] 吴冲,夏晗.基于支持向量机集成的电子商务环境下客户信用评估模型研究[J].中国管理科学,2008,S1.
[11] Yang Y. Adaptive credit scoring with kernel learning methods[J]. European Journal of Operational Research, 2007, 183(3): 1521-1536.
[12] Skinner B F. Science and human behavior[M]. Colliler-Macmillian, 1953.
[13] Thrun S. Is learning the N-th thing any easier than learning the first?[C]. In: Proc. of NIPS-96, 1996. 640- 646.
[14] Baxter J. A Bayesian/information theoretic model of learning to learn via multiple task sampling[J]. Machine Learning, 1997, 28(1): 7-39.
[15] Caruana R. Multitask learning[J]. Machine Learning, 1997, 28 : 41-75.
[16] Ben-David S, Schuller R. Exploiting task relatedness for multiple task learning[C]. In: Proc. 16th Annual Conference on Computational Learning Theory, Washington, DC, USA, 2003.
[17] Mahmud M, Ray S R. Transfer learning using Kolmogorov complexity: basic theory and empirical evaluations[C]. In: Proc. of the 20th Annual Conference on Neural Information Processing Systems, Cambridge, MA: MIT Press, 2008. 985-992.
[18] Pan S J, Yang Q. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345-1359.
[19] Dai W Y, Yang Q, Xue G R, Yu R. Boosting for transfer learning[C]. In: Proc. of the 24th International Conference on Machine Learning, ACM Press, 2007.193-200.
[20] Kamishima T, Hamasaki M, Akaho S. TrBagg: A simple transfer learning method and its application to personalization in collaborative tagging[C]. In: Proc. of Ninth IEEE International Conference on Data Mining, 2009. 219-228.
[21] Wang G, et al. A comparative assessment of ensemble learning for credit scoring[J]. Expert Systems with Applications, 2011, 38: 223-230.
[22] Weiss G M. Mining with rarity: a unifying framework[J]. ACM SIGKDD Explorations Newsletter, 2004, 6(1): 7-19.
[23] Mueller J A, Lemke F. Self-organizing data mining: an intelligent approach to extract knowledge from data[M]. Hamburg : Libri Books, Berlin, 2000.
[24] Xiao J, He C Z, Jiang X Y, Liu D H. A dynamic classifier ensemble selection approach for noise data[J]. Information Science, 2010, 180(18): 3402-3421.
[25] Kira K, Rendell L A. The feature selection problem: traditional methods and a new algorithm[C]. In: Proc. of Tenth National Conference on Artificial Intelligence, MIT Press, 1992. 129-134.
Research on Credit Scoring Model Based on Transfer Learning
ZHU Bing, HE Chang-zheng, LI Hui-yuan
(BusinessSchoolofSichuanUniversity,Chengdu610064,China)
Customer credit scoring is an important part of daily business activities for financial companies such as banks. Default customers usually makae up the minority of the population while customers of timely repayment make up the majority, which is called a class imbalance problem in the study of customer credit scoring. Existing methods in credit scoring cannot effectively solve the issue of class imbalance caused by absolute scarcity of the minority class. In our study, we introduce the technique of transfer learning to integrate the external information and try to solve the issue of class imbalance caused by absolute scarcity of the minority class. In order to exploit the minority sample outside the system more effectively, a transfer learning model is proposed, which is based on the ensemble transfer learning technology transfer bagging. A two-stage sampling method and the technique of group method of data handling are used in the new model to improve the generation and integration strategy of base models. The empirical results on the credit card dataset from a commercial bank show that the new model can deal with the issue of class imbalance caused by absolute scarcity better in comparison with other commonly used methods in credit scoring and provide a better prediction of the credit status of default customers.
credit scoring; class imbalance; transfer learning; group method of data handling
2013- 08-19
国家自然科学基金资助项目(71401115);教育部人文社会科学基金(13YJC630249);中央高校基本科研业务专项基金(2012SCU11013)
朱兵(1982-),男,四川凉山人,博士,讲师,研究方向:统计学习、商务智能、客户关系管理;贺昌政(1947-),男,四川成都人,教授,博士生导师,研究方向:数据挖掘、客户关系管理。
C931
A
1007-3221(2015)02- 0201- 07
猜你喜欢
一重技术(2021年5期)2022-01-18
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
中国外汇(2019年9期)2019-07-13
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
民族古籍研究(2018年1期)2018-05-21
中国设备工程(2017年5期)2017-05-11
中国设备工程(2017年7期)2017-04-10
瞭望东方周刊(2016年45期)2016-12-07
西夏学(2016年2期)2016-10-26
