
广东省能源需求预测模型构建及实证分析*
2015-07-02 08:08叶艺勇
经济数学 2015年3期
叶艺勇
(五邑大学 经济管理学院 广东 江门 529020)
1 引 言
随着社会经济的快速发展,各行业对能源的需求大幅度增加.据统计,广东省2000年的能源消耗量是7 983万吨标准煤,2013年的能源消耗量上升到25 645万吨标准煤,是2000年消耗量的3.2倍,其中一次能源消费90%依赖省外,二次能源消费中的电力消费有10%也是依赖省外,据估算,未来10年这个比例将达到30%左右.经济快速发展所带来的巨大能源需求与供给不足之间的矛盾越来越严重,能源短缺已成为制约广东省经济持续发展的关键问题,如果不采取有效的措施,将会延缓广东省产业结构的转型升级优化,乃至影响全省经济的稳步增长.系统地分析广东省能源需求的影响因素,准确地预测广东省未来能源需求的数量,进而制定科学合理的能源发展战略,确保广东省经济可持续发展,具有非常重要的现实意义.
2 文献综述
能源系统是一个复杂的非线性系统,其需求量受到众多因素的影响.当前很多学者已经对能源需求问题进行了深入的研究,使用的预测方法包括趋势外推法、消费弹性法、主要消耗部门预测法、回归分析法预测等[1-3],取得了一定的效果.但在预测精度方面还存在一定的差距,一方面是由于能源系统本身的复杂性、非线性、非确定性的特征导致的,另一方面是因为预测方法本身还存在一些不足之处,不足以完全准确反映预测目标和指标体系之间的数量关系.要解决上述问题,除了需要构建科学的预测指标体系,更关键的就是要寻找更加科学有效的预测方法.
鉴于此,部分学者开始研究能源系统的非线性和不确定性等系统特征,如自组织特征、分形特征、混沌特征和模糊性等,并在此基础上引进非线性方法对能源需求进行预测,如非线性/混沌时间序列方法、遗传算法、灰色理论、人工神经网络方法等[4-8],这些方法可以弥补线性模型在预测复杂能源需求时的不足.其中具有代表性的方法是人工神经网络,它是由大量神经元通过极其丰富和完善的连接而构成的自适应、非线性动态系统,它从结构、实现机理和功能上模拟生物神经网络,通过并行分布式的处理方法,克服了传统的基于逻辑符号的人工智能在处理直觉、非结构化信息方面的缺陷,具有自适应、自组织和实时学习的特点[9].它在解决非线性及高维模式识别问题中表现出许多特别的优势,受到学者的青睐.当前,已有众多学者将神经网络及其扩展模型应用于时间序列预测方面,并取得了很好的效果[10-15].
通过对文献的综合分析发现,神经网络及其相关的模型已经被广泛应用到金融、工业、交通等领域,但是在能源需求预测领域的应用较少.针对广东省能源需求系统具有非线性和影响因素众多等特征,建立了基于改进的PSO-BP神经网络的预测模型,给出了方法的基本原理和具体实现步骤,然后通过对广东省1985—2013年能源需求历史数据的建模和仿真,验证了方法的有效性,最后对广东省未来5年的能源需求进行预测,为能源管理者提供决策参考的依据.
3 广东省能源需求影响因素分析
能源需求受到多方面因素的影响,本文结合其他学者的研究成果[16-18],遵循可获得性、可比性、实际性、综合性的原则,从以下几个方面对影响能源需求的因素进行分析.
①经济增长.经济增长是影响能源需求的主要因素,随着广东省社会经济的快速发展和产业结构的持续优化,对能源的需求量将在很长一段时间内保持较高的水平.衡量经济增长的指标本文采用国内生产总值(GDP).
②产业结构调整.三大产业中,工业的发展对经济增长的贡献最大,对能源的需求也最大,第一、第三产业对能源的需求相对较少.工业的快速发展所带来的负面影响是显而易见的.近年来,广东省在产业结构优化和转型升级方面出台了一系列的政策措施,随着我省产业结构的调整,对能源需求数量的必将产生很大的影响.
③能源消费结构.该项指标反映了各种消费能源在消费总量中所占的比例关系,广东省的能源消费以煤为主,据统计,超过50%的能源来自煤炭燃烧.煤炭为不可再生能源,利用率较低,容易污染环境,政府在大力推行开发可再生能源和清洁能源,改善能源消费结构,降低能耗指数.
④技术进步.首先是通过先进技术的应用,改善生产工艺和流程,提高能源的利用率,节约能源消费;其次是将技术应用于新能源开发,从而改变能源消费结构,进而影响能源消费总量.由于技术进步难以量化,本文使用单位GDP的能耗来表示.
⑤人口和城市化.能源是人类生存和发展的物质前提,人类的衣食住行与能源息息相关,人口基数越大,对能源的需求量就越大,随着工业化、城镇化进程的加快,人民生活水平稳步提升,对能源需求的影响更加明显.
⑥居民生活消费水平.居民生活水平的提高,以及消费观念和消费行为的变化,会直接导致产业结构的变动,进而影响能源消费的数量,特别是增加对电力、液体和气体燃料等优质能源的需求.
综上所述,影响能源需求的主要因素有经济的增长(广东省GDP)、产业结构(工业在国民经济中的比重)、能源消费结构(煤炭的消费比重)、技术进步(单位GDP的能耗)、人口(广东省人口数量)、城市化(全省城镇人口所占的比重)、居民人均消费水平,预测对象为广东省每年的能源消费数量.
4 PSO-BP能源需求预测模型构建
4.1 BP神经网络模型
BP神经网络是一种多层前馈神经网络,该网络的主要特点是信号向前传递,误差反向传播.在前向传递中,输入信号从输入层经过隐含层逐层处理,直至输出层.每一层的神经元状态只影响下一层神经元状态.如果输出层得不到期望输出,则转入反向传播,根据预测误差调整网络权值和阈值,从而使BP神经网络预测输出不断逼近期望输出[19].BP神经网络的拓扑结构如图1所示,BP算法如下.
1)各层权值及阈值的初始化.
2)输入训练样本,并利用训练样本对网络进行训练,计算各层输出.
3)求出并记录各层的反向传输误差.
4)按照权值以及阈值修正公式修正各层的权值和阈值.
5)按照新的权值重复2)和3).
6)若误差符合预设要求或者达到最大学习次数,则终止学习.
7)使用训练好的模型对预测样本进行预测.
4.2 标准粒子群优化算法
粒子群优化算法(Particle Swarm Optimization)源于对鸟类捕食行为的研究,鸟类捕食时,每只鸟找到食物最简单有效的方法就是搜寻当前距离食物最近的鸟的周围区域.PSO算法就是从这种生物种群行为特征中得到启发并用于求解优化问题的.算法中每个粒子代表问题的一个潜在解,每个粒子对应一个由适应度函数决定的适应度值.粒子的速度决定了粒子移动的方向和距离,速度随自身及其他粒子的移动经验进行动态调整,从而实现个体在可解空间的寻优[19].
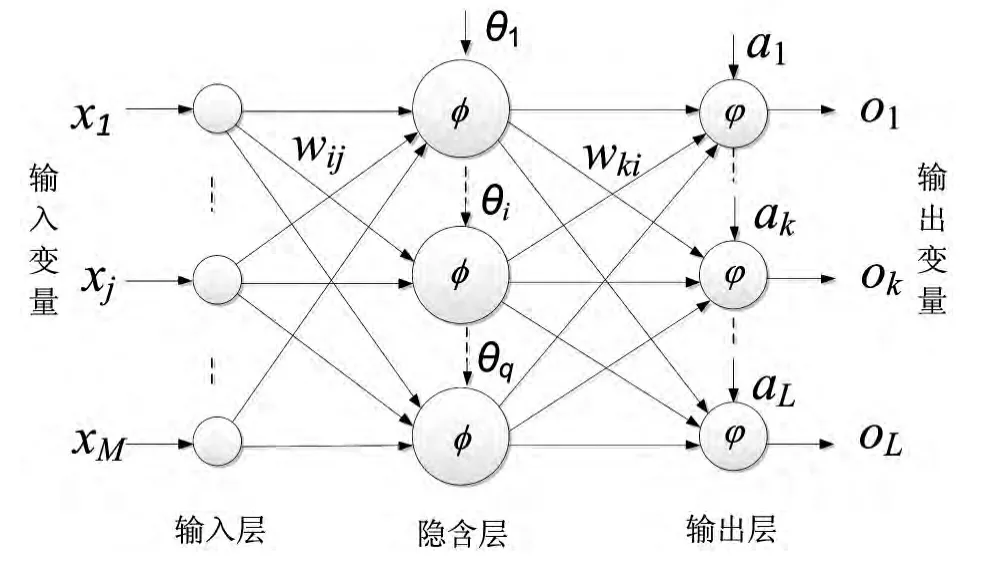
图1 神经网络结构图
假设粒子群的种群规模为Z,搜索空间为Y维,第i个粒子的位置表示为
Xi={xi1,xi2,…,xiY},i=1,2,…,Z,第i个粒子的速度表示为Vi={vi1,vi2,…,viY,第i个粒子的个体极值表示为Pi={pi1,pi2,…,piY,当前的全局极值表示为Pg={pg1,pg2,…,pgY.因此,粒子的速度与位置按下式更新:
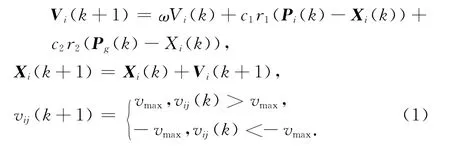
其中,ω为惯性权重,是平衡粒子的全局搜索能力和局部搜索能力的参数;c1和c2为加速因子,是调整粒子自身经验和群体经验对粒子运动轨迹的影响的参数;r1和r2是在[0,1]区间内均匀分布的两个随机数;vmax为粒子的最大速度,是用来限制粒子的速度的参数,vij为第i个粒子在第j维的速度.
4.3 改进的粒子群优化算法
标准的粒子群算法虽然具有收敛速度快、通用性强等优点,但由于算法实现过程仅利用了个体最优和全局最优的信息,因此导致种群的多样性消失过快,出现早熟收敛、后期迭代效率不高、容易陷入局部最优等缺点,增加了寻找全局最优解的难度.要解决上述问题,可以从以下两方面进行改进.
4.3.1 动态调整惯性权重
惯性权重ω用来控制粒子之前的速度对当前速度的影响,它将影响粒子的全局和局部搜索能力.较大的ω值有利于全局搜索,较小ω值有利于局部搜索,但在标准的PSO算法中,ω的值是固定的,在算法运行过程中,根据实际情况给ω赋予动态变化的值,使得算法能够平衡全局和局部搜索能力,这样可以以最少的迭代次数找到最优解.经验参数是将ω初始值设定为0.9,并使其随迭代次数的增加线性递减至0.3,以达到上述期望的优化目的.通过线性转换来完成上述参数值变化的过程.
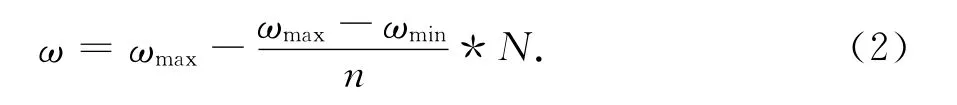
其中ωmax,ωmin分别是ω的最大值和最小值,n和N是当前迭代次数和最大迭代次数,在迭代开始时设ω=ωmax,ω在迭代过程中逐渐减小,直到ω=ωmin.
这样设置使PSO算法能够更好的控制探索与开发的关系,在开始优化时搜索较大的解空间,找到合适的粒子,然后在后期逐渐收缩到较小的区域进行更精细的搜索以加快收敛速度.
4.3.2 增加粒子的多样性
在此借鉴遗传算法中变异的思想,对部分符合条件的粒子以一定的概率重新初始化,目的是通过变异操作来保持种群的多样性,拓展种群的搜索空间,使得粒子能够跳出当前局部最优的位置,在更大的空间继续搜索全局最优值.引入线性动态变异算子:
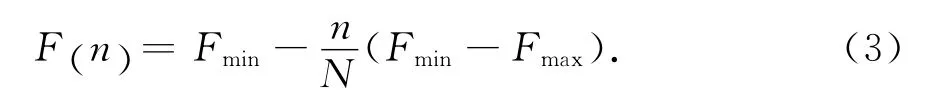
式中,F(n) 为当前的变异概率;n为当前的迭代次数;N为最大的迭代次数;Fmax,Fmin为最大的变异概率和最小的变异概率.
刚开始迭代时,种群以一个极小的概率发生变异,至迭代后期,变异概率迅速扩大,粒子可以迅速跳出当前的搜索区域,在更大的区域内寻找最优解.
4.4 改进的PSO-BP神经网络模型
BP神经网络的学习过程主要是权值和阈值的更新过程,采用的学习算法是以梯度下降为基础的,但梯度下降法的训练效果过于依赖初始权值的选择,且存在训练时间长、易陷入局部极小等问题.而粒子群算法可以避免梯度下降法中要求函数可微、对函数求导的过程,也避免了遗传算法中的选择、交叉等操作,具有收敛速度快、记忆性强和全局搜索能力较强等特点[20],可以将两种算法结合起来,利用PSO算法中粒子的位置来对应神经网络网络中的连接权值和阈值,以神经网络的输出误差作为PSO算法的适应函数,通过PSO算法的优化搜索来训练神经网络的权值和阈值,可以弥补BP网络在学习能力和收敛速度上的不足,既充分发挥了神经网络的非线性映射能力,还可以缩短神经网络的训练时间,提高预测的精度.
PSO优化BP神经网络的主要步骤如下.
1)初始化.根据BP神经网络的输入样本,建立BP神经网络的拓扑结构,输入层节点数,隐含层节点数,输出层节点数;初始化粒子的位置和速度,以及粒子数、最大迭代次数、惯性权重、学习因子等参数.
2)通过网络训练,计算粒子的适应度值,得到粒子的个体最优值与全局最优值.将粒子适应度值与个体最优值和全局最优值相比较,记录当前粒子所经历的最好位置.
3)考察每一个粒子的适应度值.若该值优于个体最优,则将当前值置为个体最优,并更新该粒子的个体最优;若粒子中的个体最优优于当前的全局最优,则将个体最优置为全局最优,并更新全局最优值.
4)将经过PSO优化的权值和阈值作为BP神经网络的初始权值和阈值代入BP网络,训练至满足网络的性能指标,即均方误差小于预先设定的误差要求或达到最大迭代次数时,停止迭代,输出结果,否则转到2,继续迭代直至算法收敛.
5)由训练和测试样本完成神经网络的训练和测试,输出预测值.如图2所示.
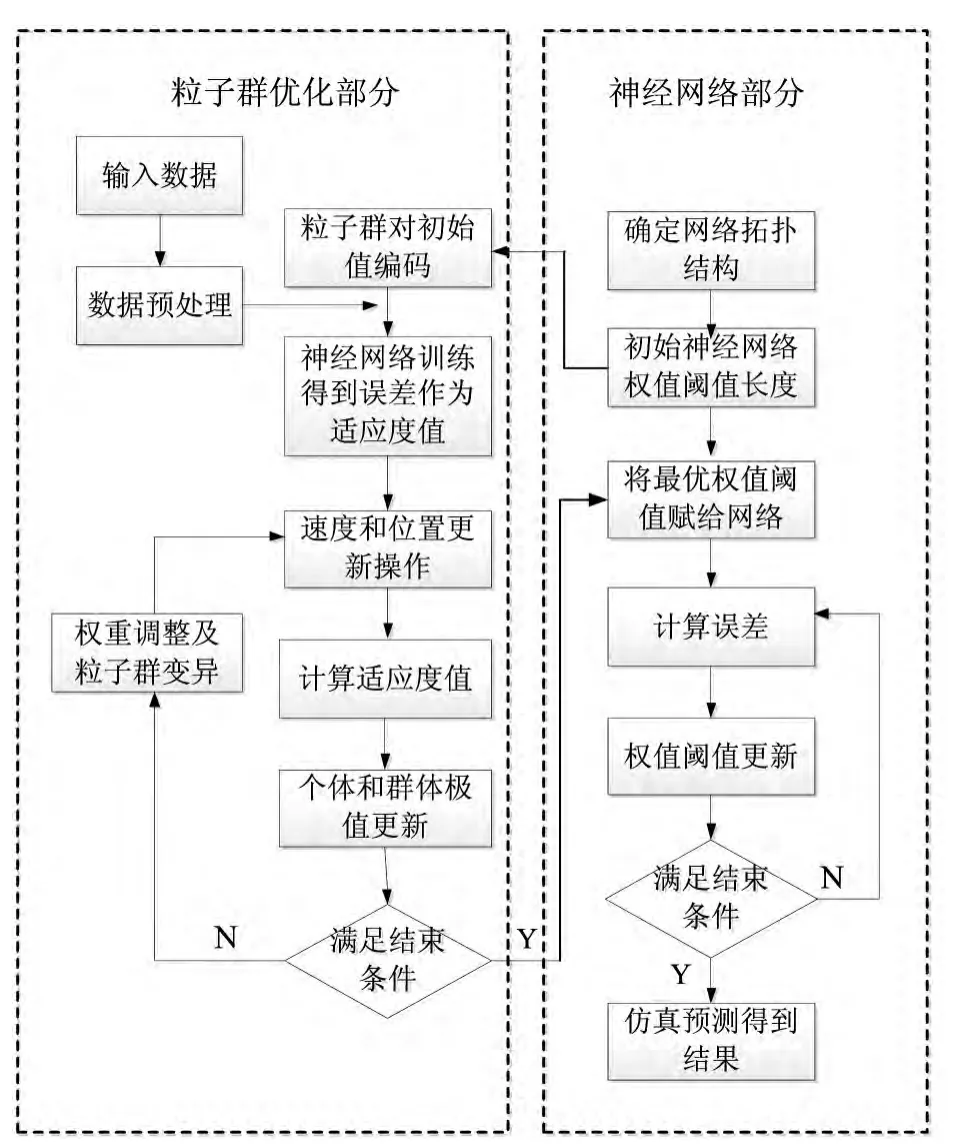
图2 PSO优化BP流程图
5 实证分析
5.1 数据来源
数据来源见表1.
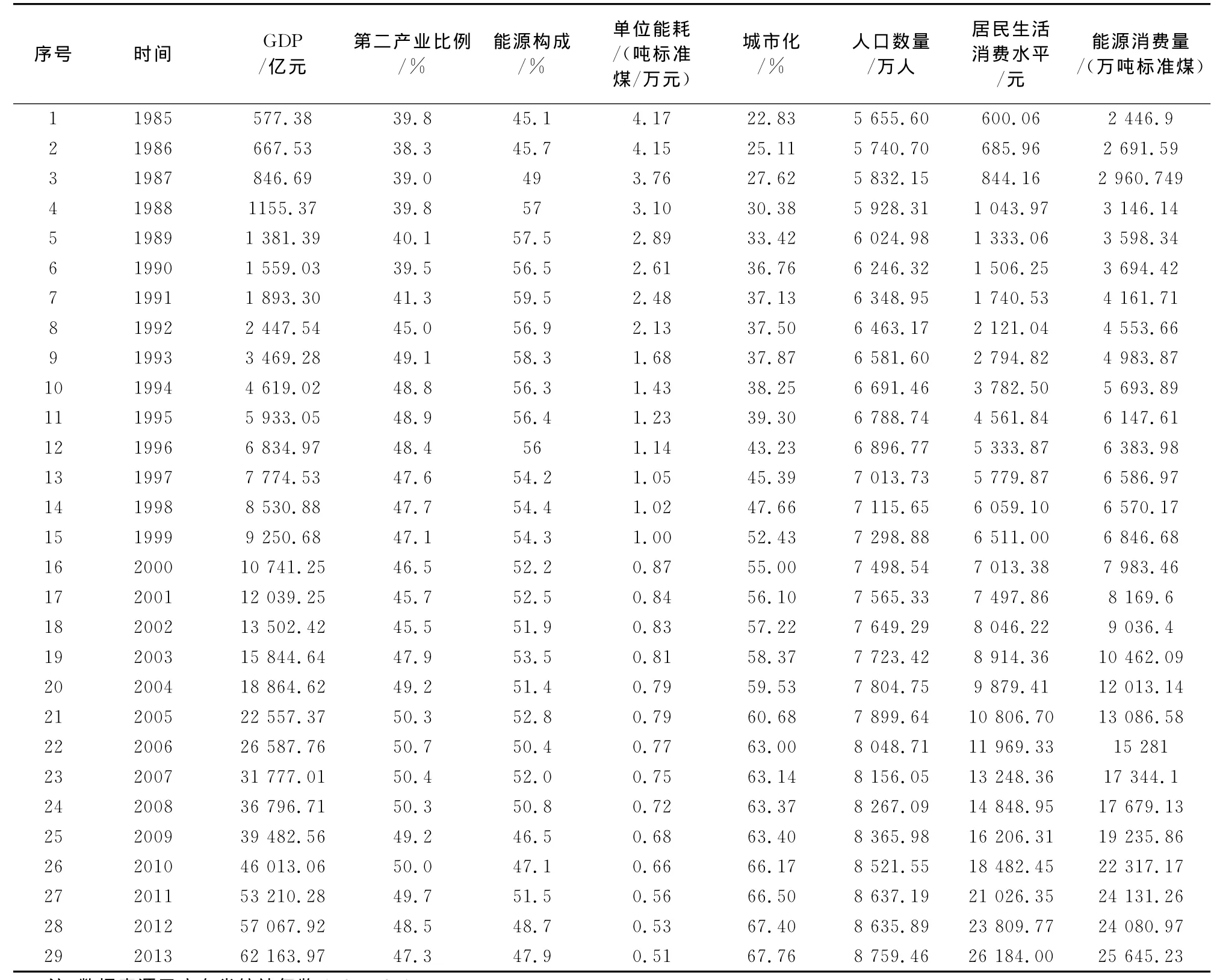
表1 各指标统计数据
5.2 数据预处理
为了消除各指标不同量纲的影响,需要对数据进行标准化处理,以解决指标之间的可比性.本文使用离差标准化的方法,对原始数据进行线性变换,使变换后的值映射到[0,1]之间,并保持原本的数量关系,变换公式如(4)式所示.
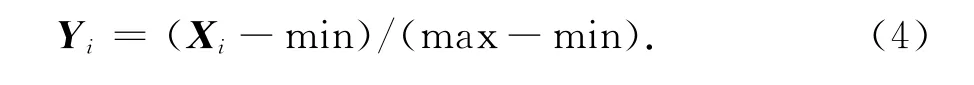
其中,Yi是样本i归一化的值,Xi是样本i的值,min为样本最小值,max为样本最大值.但这个方法有个缺点,当有新的样本数据加入时,数据的最大值和最小值可能会发生变化,需要重新计算Yi值.
在预测或者评价完成后,再使用反归一化的方法对数据进行还原处理,得出其真实值,具体的数据处理过程可以直接调用Matlab工具箱里的Mapminmax函数来完成.
5.3 数据降维
就神经网络的结构而言,预测指标体系越庞大,指标数量越多,模型就越复杂,预测结果的不确定性就越大,相应地,模型的泛化能力会降低,同时也会增加运算的时间.因此有必要对前面确定的影响能源需求的指标进行定量化的分析,在尽量减少信息丢失的前提下减少指标的个数,即完成样本指标的降维.
主成分分析法就是通过线性变换的方法,把原始变量组合成少数几个具有代表意义的指标,使得变换后的指标能够更加集中地反映研究对象特征的一种统计方法[21].对样本的原始数据进行主成分分析,得到各个主成分的特征值和方差贡献率,如表2所示.
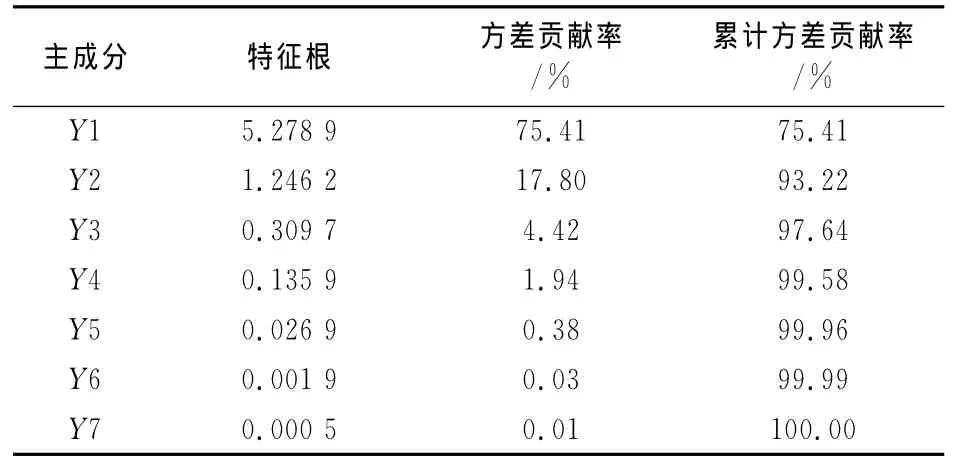
表2 主成分特征值和方差贡献率
从表2的数据可知,当抽取的主成分为Y1,Y2时,主成分的累计方差贡献率已达到93.22%,基本覆盖了原来7个指标所包含的信息.因此可以把Y1,Y2这2个主成分的数据作为模型的输入,这样就大幅度减少了神经网络的输入节点数,降低了模型的复杂程度,同时也有利于前期样本数据的获取.
根据主成分分析法得出前2个主成分的系数如表3所示.

表3 Y1和Y2的主成分系数
因此得出Y1、Y2与原输入指标的关系为:
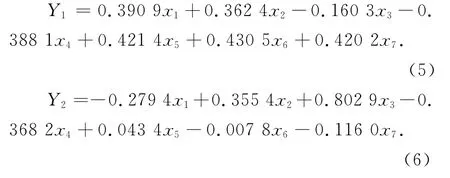
从表达式(5)可以看出,第一主成分Y1与x1、x2、x5、x6、x7均保持了较强的正相关,而与x3,x4呈现出负相关,这个数量关系说明了第一主成分基本反映了上述指标的信息.由于x1、x2、x5、x6、x7是从不同的方面反映了社会经济发展的水平,而x3和x4反映了能源消费的状况,因此,第一主成分Y1是综合反映了经济发展状况和能源需求之间的密切关系.
从表达式(6)可以看出,第二主成分Y2与x1、x2、x3、x4相关性较强,其中与x3(能源结构)是高度相关的,说明第二主成分基本反映了这个指标的信息.
5.4 模型参数设置
神经网络的结构一般由样本的输入和输出指标数量确定,由于使用PCA做数据降维后,样本数据的维数为2,输出数据维数为1,所以确定模型的输入节点数为2,输出节点数为1.本文选用的是三层的BP神经网络模型,关于隐含层数目的确定,目前没有一个通用的方法,只能根据经验或者多次试验来决定.由于隐含层的数量会影响到模型的学习时间、拟合效果以及泛化能力,因此必须确定一个最佳的隐含层单元数,根据相关学者的研究结论,隐含层的数量与问题的要求、输入、输出指标的个数都有关系,且其数量关系符合以下的计算公式[21]:

其中R为隐含层单元数,S1、S2分别为输入层和输出层的数量,a为[1,10]之间的常数.经过循环比较算法,得出R的值为4时,模型具有较好的学习效果和泛化能力,因此本文确定神经网络模型的结构为2-4-1,隐层使用sigmoid函数,输出层使用pureline函数,神经网络的学习效率取0.1,训练次数为150,输出目标值为0.001.粒子群规模为50,迭代次数为100,学习因子c1=1.7,c2=1.5,惯性权重ωmax=0.9,ωmin=0.3,粒子速度最大值为5,最小值为-5.
5.5 模型训练
本文选取前24个样本数据作为训练数据,用于确定模型的相关参数,剩余5个样本作为测试数据,用于检验模型的效果.
将训练数据代入模型进行计算,得到的适应度曲线变化如图3所示,训练值与实际值比较如图4所示,可以看出PSO-BP模型对历史数据的学习情况非常理想,大部分样本的训练值与实际值基本吻合,个别样本有一定的偏差,但在合理的误差范围之内,说明该模型的构建是行之有效的.
5.6 模型测试
将训练后的模型对5个预测样本数据进行预测,并把预测值与实际值进行比较,结果如表4所示,预测结果如图5所示,样本误差如图6所示.可以看到,2009-2013年的预测准确度非常高,平均误差为2.3%,以2009年为例,预测偏差为2.87%,换算成实际的偏差数量就是552.95万吨标准煤,准确的预测结果将为能源规划与实施提供有力的依据.
图3 适应度变化曲线图
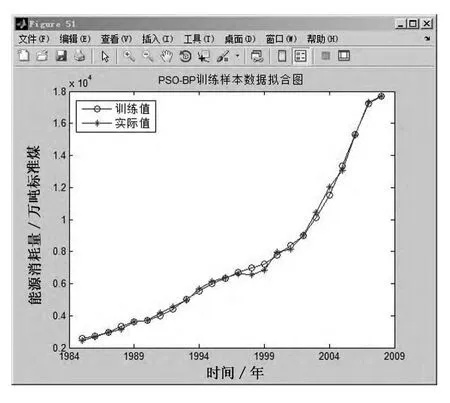
图4 训练值与实际值比较图

表4 预测值与实际值比较 万吨标准煤
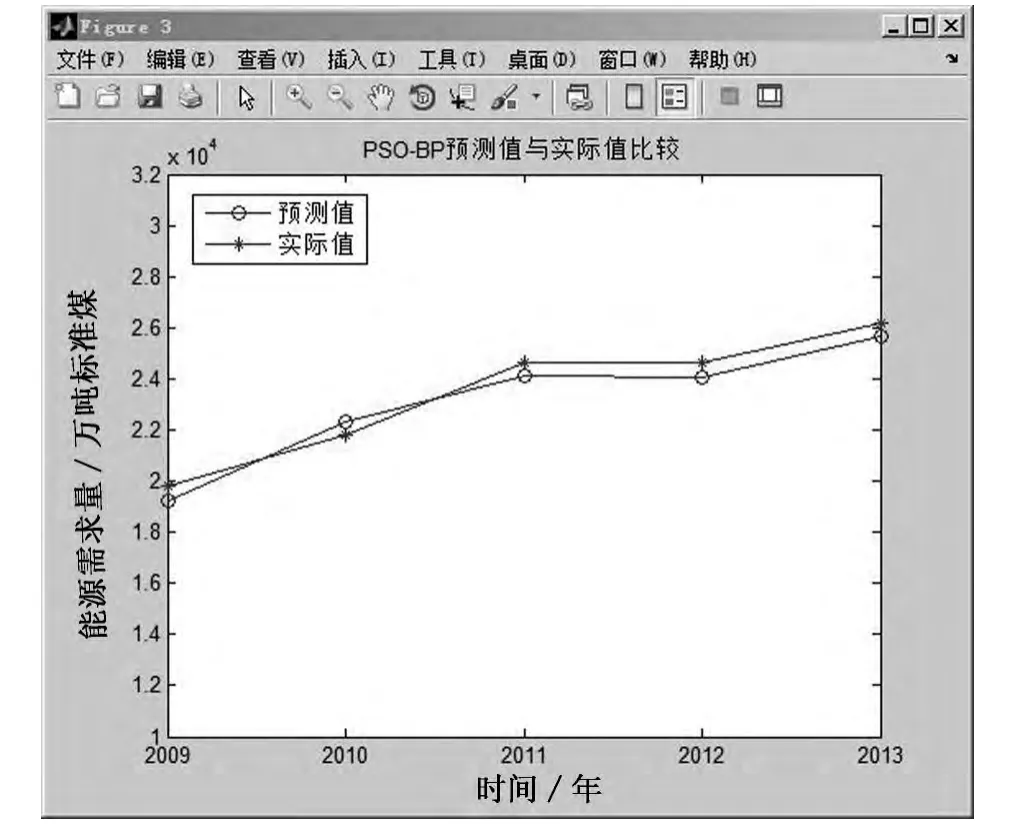
图5 预测值与实际值比较
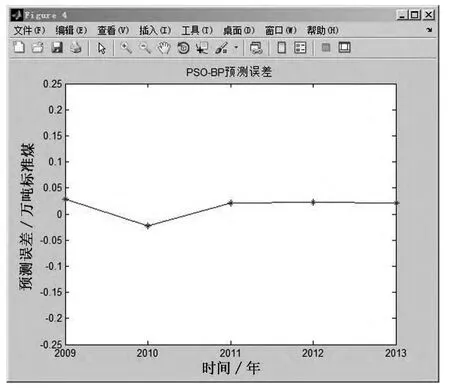
图6 样本误差图
图7为神经网络在训练、验证及测试过程中,均方误差的变化趋势,可以看到,当训练次数达到一定的程度,均方误差将会小于1×10-3,完全符合模型的预设要求.图8为模型对样本数据的拟合程度,根据R的取值,结合图7的均方误差,可知模型的学习能力及预测能力是非常强的,准确度非常高.
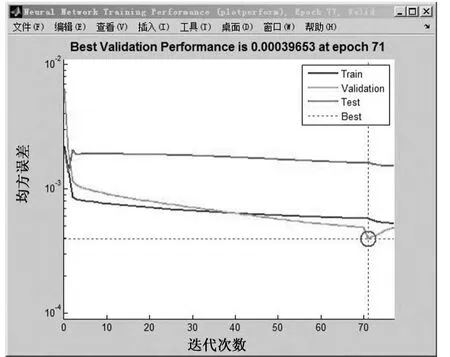
图7 均方误差的变化状态
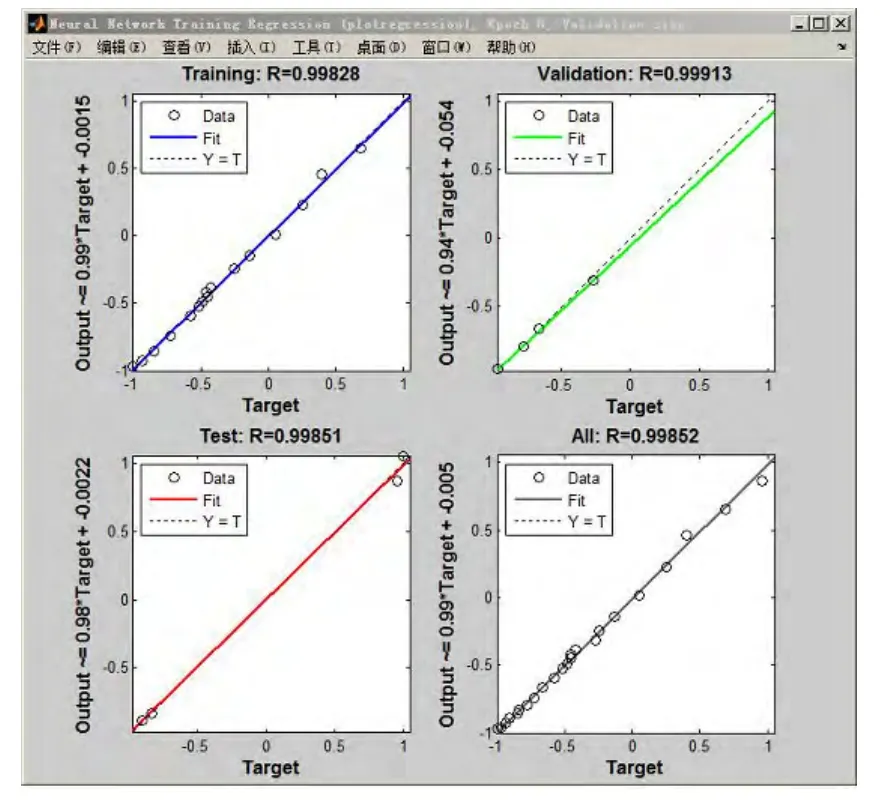
图8 训练、验证及测试的性能状态
5.7 不同方法预测结果比较
为了体现PSO-BP神经网络模型的优势,本文同时使用未经优化的BP神经网络对数据进行训练和预测,并将两种预测结果进行比较,具体数据见表5所示,比较效果如图9和图10所示.

表5 预测值与实际值比较(单位:万吨标准煤)
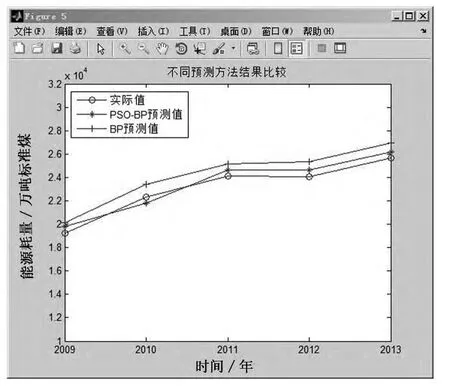
图9 预测结果比较
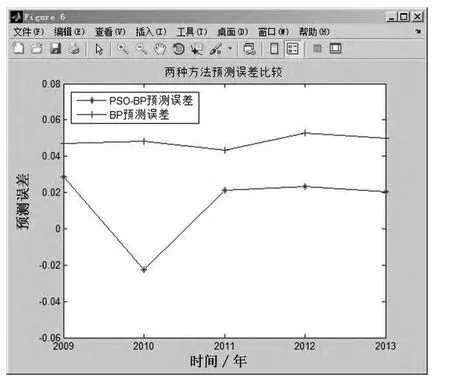
图10 预测误差比较A
由表5可知,PSO-BP模型的预测平均误差为2.3%,BP模型的平均预测误差为4.8%,说明经过粒子群算法优化神经网络参数后,不仅使得模型的收敛速度加快,运算时间减少,同时在预测精度方面也有了很大的提升.
5.8 未来5年能源需求预测
根据上述预测模型和流程,对广东省未来5年的能源需求进行预测,这里假设未来5年各项样本指标均保持当前的增长速度,得出的结果见表6.

表6 2014~2018年能源需求量(单位:万吨标准煤)
从表6可知,未来5年,广东省的能源需求将持续增长,平均保持5.7%的增长率,并且增长的速度逐步加快,2018年的需求量将达到33 842.34万吨标准煤.因此,如何针对快速增长的能源需求,采取有效的措施来解决供需不平衡的矛盾,将是决策者需要考虑的问题.根据广东省发改委2013年底公布的《广东省能源发展十二五规划》,在保证全省能源供应能力的前提下,将进一步加快能源消费结构的调整,构建与科学发展要求相适应的安全、稳定、经济、清洁的现代能源供应保障体系,具体措施是进一步优化能源结构和布局,提升能源利用效率,逐步降低单位GDP能耗,并且争取在新能源的利用开发方面取得突破性进展,从而为全省经济社会发展提供强有力的能源保障.
6 结 论
对广东省的能源需求问题进行了深入的研究,在结合定性和定量分析的基础上,确定了影响能源需求的主要因素,构建了PSO-BP神经网络的能源需求预测模型,并对广东省2014-2018年的能源需求进行了预测.理论分析和实证研究表明,该方法能够很好的反映广东省能源需求的特征,预测结果较为准确合理.但就本文所考虑的预测指标体系而言,以定量的指标为主,如何在模型中把政策法规、环境保护等难以定量的影响因素包含进来,构建更为完善的预测指标体系,以及当样本数量较少的时候,如何保证模型的学习能力和泛化能力,这些问题需要继续完善解决.
[1]林伯强.中国能源需求的经济计量分析[J].统计研究,2001(10):34-39.
[2]韩君.中国能源需求的建模与实证分析[D].兰州商学院,2007.
[3]魏一鸣等.中国能源需求报告(2006):战略与政策研究[M].北京:科学出版社,2006.
[4]A S WEIGEND.Time series analysis and predicationusing gated experts with application to energy demandforecast[J].Applied Articial Intelligence,1996(6):583-624.
[5]V GEVORGIAN ,M KAISER .Fuel distribution andconsumption simulation in the republic of Armenia[J].Simulation,1998(3):154-167.
[6]张玉春,郭宁,任剑翔.基于组合模型的甘肃省能源需求预测研究[J].生产力研究,2012(11):31-34.
[7]冯亚娟,刘晓恺,张波.基于QGA-LSSVM的能源需求预测[J].科技与经济,2014(3):56-61.
[8]芦森.基于组合模型的中国能源需求预测[D].成都:成都理工大学,2010.
[9]李琳娜.基于核主成分分析(KPCA)和神经网络的单目红外图像深度估计[D].上海:东华大学,2013.
[10]张均东,刘澄,孙彬.基于人工神经网络算法的黄金价格预测问题研究[J].经济问题,2010(1):45-48.
[11]熊志斌.ARIMA融合神经网络的人民币汇率预测模型研究[J].数量经济技术经济研究,2011(6):75-81.
[12]龙文,梁昔明,龙祖强,等.基于混合进化算法的RBF神经网络时间序列预测[J].控制与决策,2012(8):20-25.
[13]王庆荣,张秋余.基于随机灰色蚁群神经网络的近期公交客流预测[J].计算机应用研究,2012(6):32-37.
[14]张大斌,李红燕,刘肖,等.非线性时间序列的小波-模糊神经网络集成预测方法[J].中国管理科学,2013(2):81-86.
[15]高玉明,张仁津.基于遗传算法和BP神经网络的房价预测分析[J].计算机工程,2014(4):187-191.
[16]伍秀君.广东省能源需求预测分析及能源发展对策研究[D].广州:暨南大学,2007.
[17]薛黎明.中国能源需求影响因素分析[D].徐州:中国矿业大学,2010.
[18]秦国真.云南能源需求影响因素分析及预测[D].昆明:云南财经大学,2012.
[19]来建波.基于神经网络的路段行程时间预测研究[D].昆明:云南大学,2011.
[20]潘昊;侯清兰.基于粒子群优化算法的BP网络学习研究[J].计算机工程与应用,2006(6):65-69.
[21]郭阳.PSO-BP神经网络在商业银行信用风险评估中的应用研究[D].厦门:厦门大学,2009.
猜你喜欢
英语文摘(2022年3期)2022-04-19
厦门大学学报(哲学社会科学版)(2021年4期)2021-10-14
模具制造(2019年4期)2019-12-29
测控技术(2018年10期)2018-11-25
浙江工业大学学报(2017年5期)2018-01-22
海洋信息技术与应用(2017年2期)2017-06-21
自动化博览(2014年4期)2014-02-28
物理与工程(2014年4期)2014-02-27
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
城市道桥与防洪(2013年6期)2013-03-11
